从线性分类器到两层神经网络:为什么我们需要非线性?
在学习 CS231n 的过程中,前面我们一直在使用线性分类器。它的形式非常简单:
python
f = W x这里的 x 是输入数据,比如一张图片展开后的向量;W 是权重矩阵;f 是每个类别对应的分数。
对于 CIFAR-10 这种 10 分类任务,f 可以理解为模型对 10 个类别分别打出的分数。哪个类别的分数最高,模型就预测它属于哪个类别。
这种模型的优点是简单、直观、计算快。但它也有一个很大的限制:它只能表示线性的分类边界。
1. 线性分类器的局限
线性分类器的形式是:
python
f = W x它本质上只做了一次线性变换。
如果数据本身可以用一条直线、一个平面,或者更高维空间中的一个超平面分开,那么线性分类器就可以工作得不错。
但如果数据本身不是线性可分的,线性分类器就会遇到困难。
比如有这样一组二维数据:
- 红色点集中在中间
- 蓝色点围在外圈
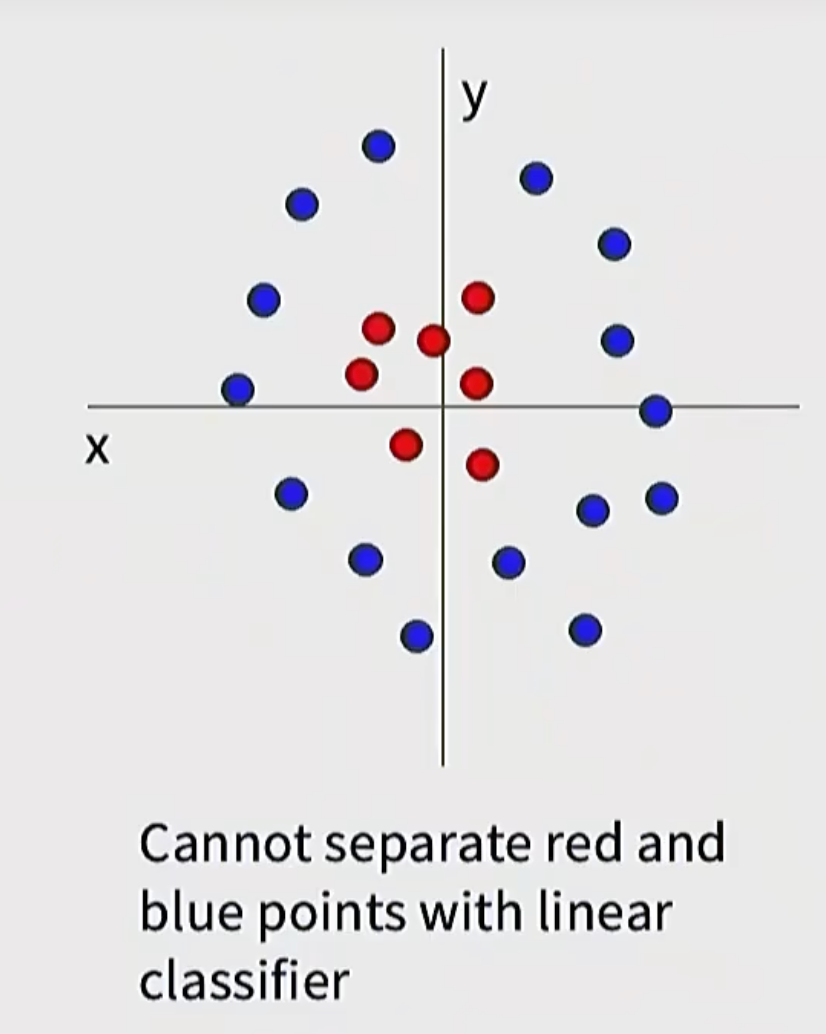
这种情况下,不管你怎么画一条直线,都无法把中间的红点和外圈的蓝点完全分开。
这就是线性分类器的限制:
它只能在原始输入空间中画线性边界。
2. 用特征变换解决线性不可分问题
如果原始空间中数据线性不可分,我们可以考虑换一个表示方式。
例如,原来每个点用二维坐标表示:
python
(x, y)我们可以把它变换成极坐标:
text
(r, θ)其中:
text
r 表示点到原点的距离
θ 表示点相对于原点的角度在原来的 (x, y) 空间中,红点在中间,蓝点在外面,看起来无法用直线分开。
但是转换到 (r, θ) 空间后,情况就变简单了:
- 红点的
r比较小 - 蓝点的
r比较大
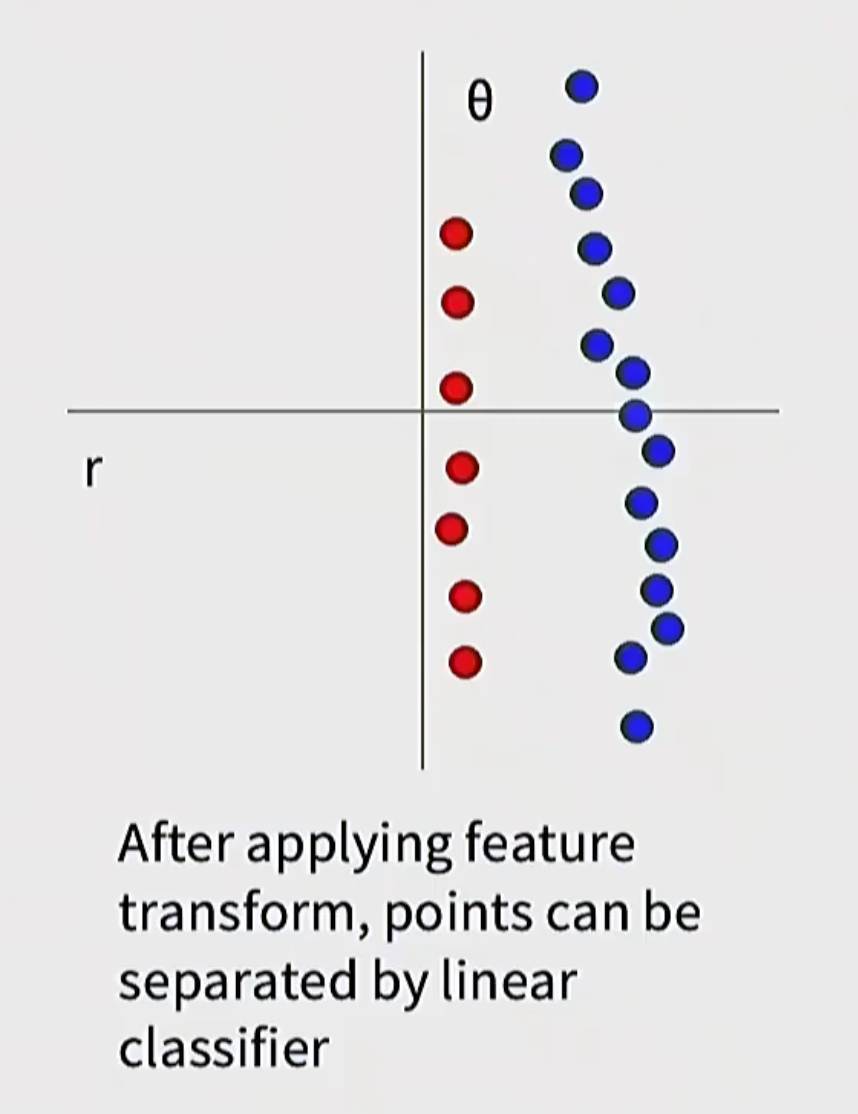
于是我们只需要根据 r 的大小,就可以把两类点分开。
也就是说:
text
原始空间中线性不可分的数据
经过特征变换后
可能在新的特征空间中变得线性可分这就是非线性特征变换的价值。
3. 两层神经网络在做什么?
两层神经网络可以写成:
python
f = W2 max(0, W1 x)它可以拆成几步来看:
python
h = W1 x
h_relu = max(0, h)
f = W2 h_relu其中:
W1 x是第一层线性变换max(0, W1 x)是 ReLU 非线性激活函数W2是第二层线性变换f是最后输出的类别分数
所以两层神经网络的结构可以理解为:
text
输入 x
↓
第一层线性变换 W1x
↓
ReLU 非线性变换 max(0, W1x)
↓
第二层线性变换 W2
↓
输出类别分数 f4. ReLU 是什么?
ReLU 是一个非常常见的激活函数,定义为:
python
ReLU(x) = max(0, x)它的规则很简单:
text
如果 x > 0,输出 x
如果 x <= 0,输出 0例如:
python
[-2, 3, -1, 5]经过 ReLU 后变成:
python
[0, 3, 0, 5]虽然 ReLU 看起来很简单,但它非常重要,因为它给神经网络引入了非线性。
5. 为什么一定要有非线性?
假设我们没有 ReLU,两层网络就会变成:
text
f = W2 W1 x但是矩阵乘矩阵的结果还是一个矩阵。
也就是说:
text
W2 W1 = W所以:
text
f = W2 W1 x = W x这其实还是一个线性分类器。
所以,如果没有非线性激活函数,即使堆很多层,本质上也只是一个线性模型,表达能力不会真正变强。
真正让神经网络变强的是中间的非线性函数,比如:
text
max(0, W1x)它让模型不再只是简单地画直线,而是可以学习更复杂的决策边界。
6. 从另一个角度理解两层神经网络
两层神经网络可以理解为两件事:
第一层:
text
W1 + ReLU负责学习一个新的特征表示。
第二层:
text
W2负责在新的特征空间里做线性分类。
所以它和我们前面手动做特征变换的思想很像。
只不过以前我们可能手动设计:
text
(x, y) → (r, θ)而神经网络会自己学习:
text
x → max(0, W1x)这就是神经网络的强大之处:
它可以自动学习有用的特征表示。
7. 维度解释
两层神经网络写成:
text
f = W2 max(0, W1x)并且有:
text
x ∈ R^D
W1 ∈ R^(H × D)
W2 ∈ R^(C × H)这里:
D是输入维度H是隐藏层维度,也就是隐藏层神经元数量C是类别数量
举个例子,如果是 CIFAR-10:
text
D = 3073
C = 10
H = 100那么:
text
x.shape = (3073,)
W1.shape = (100, 3073)
W1x.shape = (100,)
W2.shape = (10, 100)
f.shape = (10,)最后的 f 就是 10 个类别的分数。
8. 总结
线性分类器的形式是:
text
f = W x它简单高效,但只能学习线性决策边界。
两层神经网络的形式是:
text
f = W2 max(0, W1x)它比线性分类器多了一层隐藏层,并且通过 ReLU 引入了非线性。
这使得模型可以先把输入数据变换到一个新的特征空间,再在这个空间中进行分类。
一句话总结:
线性分类器只能在原始空间中画直线;两层神经网络可以通过隐藏层和非线性激活函数学习新的特征表示,从而处理更加复杂、线性不可分的数据。