一、CLIP
1.1 CLIP 模型整体结构
CLIP 的整体结构其实非常简单:
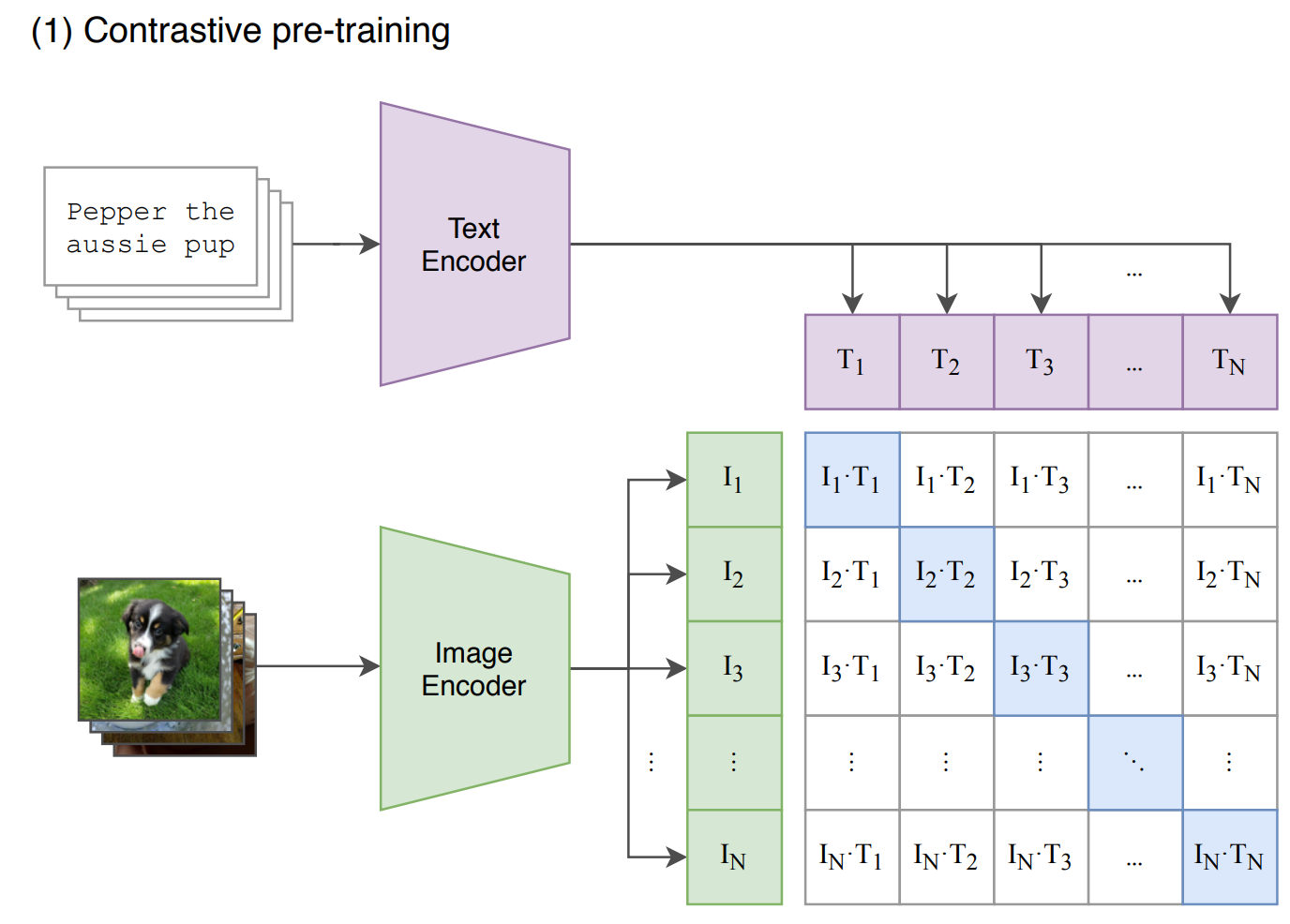
-
假设一个 batch 输入 N 对图文 I - T
-
输入的图文分别文本编码(bert)和图像编码(ViT、ResNet)获取各自特征
-
计算图和文之间的两两特征相似度
-
矩阵对角线为正样本,其余是负样本,即有 N 个正和 N*(N-1)个负样本
-
优化目标:最大化配对图文的相似度(对角线) 并最小化失配的图文相似度
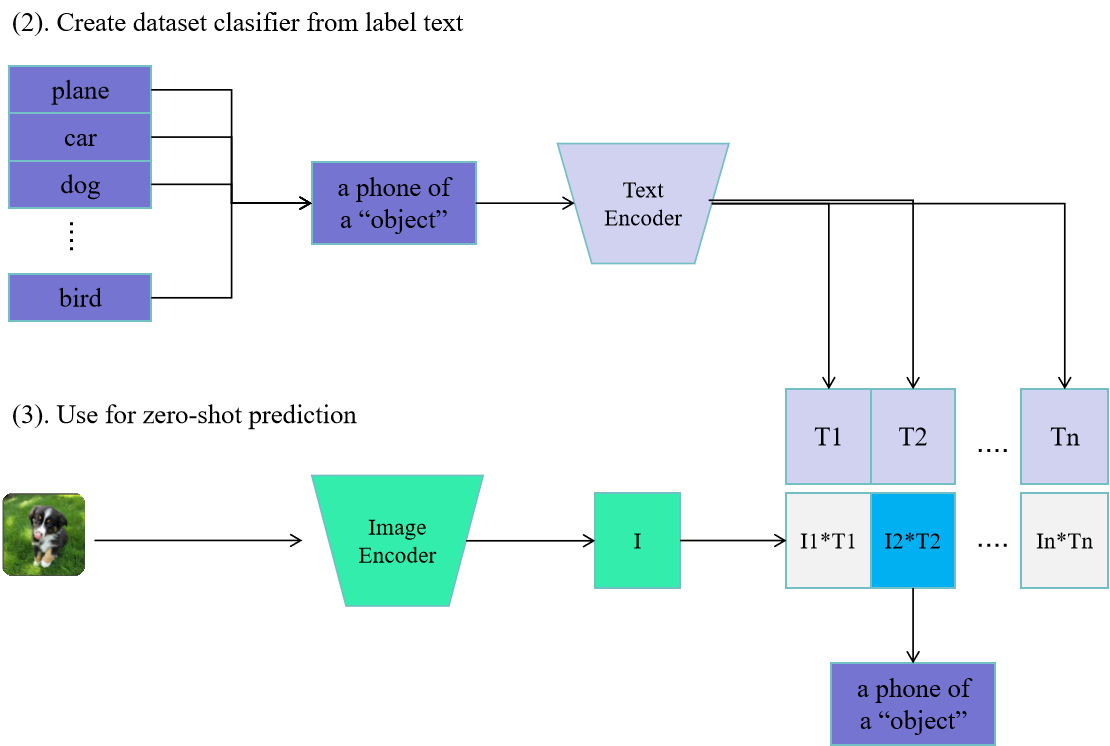
结合以上两幅图,CLIP的编码流程为:
"CLIP 预训练了一个图像编码器和一个文本编码器,以预测数据集中哪些图像与哪些文本配对。然后,利用这一机制将 CLIP 转化为零样本分类器。我们将数据集中的所有类别转换为诸如"一张狗的照片"这样的描述文本,并预测 CLIP 认为与给定图像最匹配的类别描述。"
CLIP的训练目标是:让正确图文对的 embedding 更接近;让错误图文对的 embedding 更远离。本质上,CLIP在学习"视觉与语言之间的语义对应关系"。
1.2 CLIP 的重要创新
1) 统一 Embedding Space,实现了图像与文本的语义对齐
传统视觉模型中:图像空间 ≠ 文本空间
CLIP :图像 embedding ≈ 文本 embedding
即图像第一次被映射到了 "语言语义空间" 。
2)CLIP 可实现零样本分类器
传统分类模型:classifier = 固定类别参数
CLIP:没有固定 classifier,将类别语言话,直接写成 :
python
"a photo of a dog"
"a photo of a cat"
"a photo of a red panda"在训练推理时,text -> text embedding;image -> image embedding;
然后计算 image 和 text 的余弦相似度,谁最接近预测就是谁。
因此:CLIP 本质上不是在学习"类别参数",而是在学习"语言语义"。即使模型从未专门训练过的类别,只要语言空间中存在相关语义,CLIP 就有机会完成识别,即模型具备零样本学习能力,这也是 CLIP 与传统分类器最大的本质区别。
1.3 CLIP 的不足
1.3.1 batch 所引起的问题
CLIP 在训练时,采用的是 Softmax-based Contrastive Loss,其核心思想是:
python
给定 batch:N 个 image-text pair
需要计算:N × N similarity matrix
然后:对 image 做 softmax
让:正确 text 的概率最大
然后:对 text 再做一次 softmax
让:正确 image 的概率最大所以,CLIP 实际需要两次 batch-level nomalization,有以下问题:
1)计算时必须 "看到" 整个batch
因此,CLIP Loss 强依赖于全局batch。
2)Distributed Training(分布式训练) 很复杂
因为:每张 GPU只能看到局部 batch。
所以:必须跨 GPU 通信,同步:
python
similarity matrix
max value
normalization term这是 CLIP 非常重的工程负担。
3)batch size 与 loss 强耦合
CLIP 的 performance 高度依赖:大 batch
因为需要更多 negative samples。
所以:CLIP 才用了batch size = 32768 甚至更大。
1.3.2 强语义、弱空间
CLIP的训练目标本质上是:global semantic alignment,导致模型更关注:图里有什么,整体语义是什么;而不是:精确坐标、左右上下关系、几何结构、物体距离。
二、SigLip系列
2.1 SigLig-v1
基于 CLIP,区别是训练损失改成了 sigmoid,SigLip 提出不做softmax,改成pairwise sigmoid loss。即:每个 image-text pair,独立计算 loss。而不是在整个 batch 上归一化。
二者的本质区别:
CLIP:谁是 batch 中唯一正确答案,多分类问题;
SigLip:这个 image-text pair 是否匹配,是一种二分类问题。
解决的问题:CLIP 对比学习中用 softmax 需要存储更多的计算结果和更多计算量(N^2,N=32k),SIGLIP是直接单独计算每个图文对之间的 sigmoid 相似度进行二分类(在输入数据构建正负样本对),减少了大量的计算和GPU通讯,从而提升训练效率。
2.2 SigLig-v2
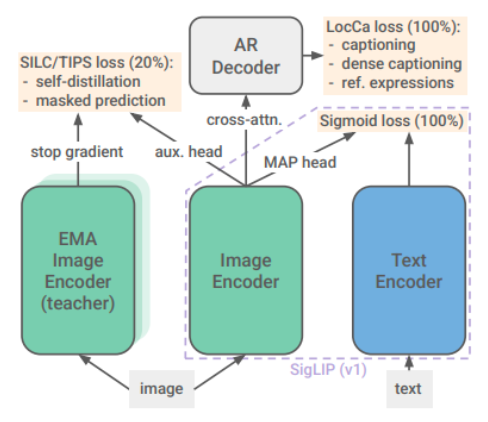
在v1的基础上,额外增加多个(加权)损失(v1 只有 sigmoid)。
-
在训练的后20%增加了 caption 预训练损失
-
在训练的后20%增加自蒸馏损失
local-to-global consistency loss: 局部到全局的一致性损失,视觉模型作为学生只获取图像的一部分,然后用学生模型上一步训练更新的权重经过指数移动平均(根据近期数据趋势预测下一步数据)作为教师模型,获取全局图像特征,计算局部特征和全局特征的一致性。
masked prediction loss:全图分别输入学生和教师模型,但学生的图像 mask 50%,计算学生和教师输出的特征一致性损失
-
可变分辨率(后 5%训练)
适应不同类型和分辨率的图像(现在已经有更好的动态分辨率了,参考Internvl)