论文链接:https://arxiv.org/pdf/2405.11315
Code: https://github.com/cnulab/MediCLIP
来源: Medical Image Computing and Computer Assisted Intervention -- MICCAI 2024
摘要:
引言和问题背景:
- 重要性: 在医疗决策领域中,对医学图像进行精确的 异常检测(anomaly detection) 对于辅助临床医生至关重要,它扮演着核心角色。
- 现有工作的局限性: 然而,以往的工作过度依赖大规模数据集来训练异常检测模型,这大大增加了开发成本。
- 本文关注的重点及意义: 本文首次将重点放在 少样本医学图像异常检测(few-shot medical image anomaly detection) 任务上。这对于医疗领域具有极其重要的意义,因为医学数据的收集和标注都非常昂贵。
提出的方法(MediCLIP):
- 核心创新: 论文提出了一种创新的方法------MediCLIP。
- 方法概述: MediCLIP通过自监督微调(self-supervised fine-tuning)的方式,将著名的CLIP模型(作为视觉-语言模型)适配到少样本医学图像异常检测任务中。
解决CLIP在医学领域局限性的策略:
- 挑战: 尽管CLIP作为视觉-语言模型,在各种下游任务中展现了出色的零样本(zero-shot)/少样本性能,但在医学图像的异常检测方面仍存在不足。
- 解决方案: 为了解决这一问题,研究人员设计了一系列医学图像异常合成任务。这些合成任务旨在模拟医学成像中常见的疾病模式,从而将CLIP强大的泛化能力有效地迁移到医学图像异常检测任务上。
实验结果和结论:
- 主要成果: 在仅提供少量正常医学图像 进行训练的情况下,MediCLIP在异常检测和定位方面均达到了优于现有方法的最先进性能(state-of-the-art performance)。
- 验证: 通过在三个不同的医学异常检测任务上进行广泛的实验,证明了该方法的优越性。
1. 引言
医学图像异常检测任务的定义和重要性:
- 任务内容: 医学图像异常检测任务涉及区分正常图像和包含各种病变区域的异常图像,并准确定位这些病变区域。
- 重要性: 这项任务为医学专业人员提供重要的临床决策依据,能够大大降低决策风险并提高工作效率。
传统方法的局限性与挑战:
- 数据稀缺性导致的训练设置: 由于病变(异常)图像稀缺,该领域的研究主要集中在无监督异常检测设置,即模型仅使用正常图像进行训练,任何对正常模式的细微偏差都被识别为异常。
- 高开发成本: 尽管近年来医学图像异常检测取得了显著进展,但在某些任务中甚至达到了或超过了专业临床医生的性能。然而,这些方法通常需要数千张甚至更多的医学图像来训练模型,这增加了开发成本并阻碍了快速部署。
本文的关注点:Few-shot 医学图像异常检测
- 挑战与目标: 本文专注于一个更具挑战性的任务------少样本(few-shot)医学图像异常检测。
- 设置: 对于每个医学异常检测任务,模型训练只提供少量(few-shot)的正常图像 ,并且不提供任何异常图像和像素级标签。
- 优势: 这种设置显著降低了医学异常检测模型的开发成本,并避免了昂贵的医疗数据收集和标注过程。
MediCLIP 方法的提出与创新:
- 利用 CLIP 的强大泛化能力: CLIP (Contrastive Language--Image Pre-training) 模型通过将自然图像和原始文本映射到统一的表征空间,展现出强大的泛化能力。虽然一些方法将 CLIP 应用于医学图像分类,但它们在识别和定位病变区域方面存在不足。
- 解决现有基于 CLIP 方法的限制: 现有的零样本/少样本异常检测方法(如 [28](https://arxiv.org/abs/2310.18961), [8](https://arxiv.org/abs/2311.00453), [7](https://arxiv.org/abs/2305.17382), [10](https://arxiv.org/abs/2403.12570))需要一个包含真实异常图像及其像素级异常标签的辅助数据集进行训练,这在医疗领域通常难以获得。
- MediCLIP 的核心创新------合成异常图像: MediCLIP 通过使用合成异常图像 进行模型训练,而不是依赖辅助数据集。这些合成图像是通过一系列精心设计的异常合成任务创建的,能够有效地模拟医学成像中观察到的各种异常模式。
- 技术细节:
实验验证和结果:
- 数据集: MediCLIP 在三个不同的医学成像数据集上进行了验证:胸部 X 射线图像数据集 CheXpert、脑部 MRI 图像数据集 BrainMRI和乳腺超声图像数据集 BUSI。
- 性能提升: 在少样本学习设置下,MediCLIP 相较于现有最先进的方法,性能提高了约 10%。
- 高效性: 在最具挑战性的 CheXpert 数据集上,MediCLIP 在使用不到 1% 的训练图像的情况下,达到了先进的全样本(full-shot)医学图像异常检测方法 SQUID 性能水平的 94%。
- 零样本泛化能力: MediCLIP 展现出令人印象深刻的零样本泛化能力。通过在一个医学异常检测任务中训练获得的异常检测能力可以转移到其他医学异常检测任务中。
- 结论: 这表明 MediCLIP 有潜力成为一个统一的医学异常检测模型。通过广泛的实验,证明了 MediCLIP 具有低成本和高性能的特点,能够有效协助专业医生进行实际医疗决策。
2. 方法
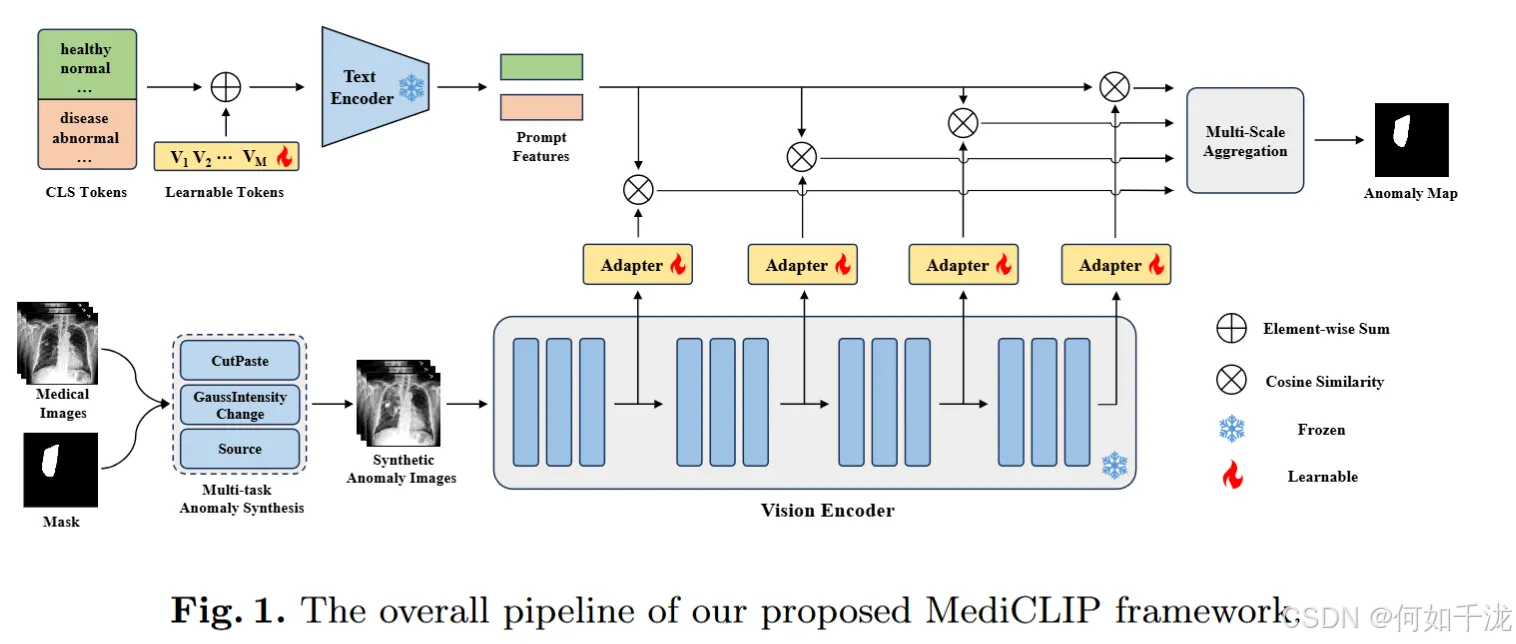
2.1 问题定义
少样本学习设置 (Few-shot learning setting):
- n-way k-shot episode: 这种设置是少样本学习中的标准术语。
- n-way 指的是任务或类别(tasks/classes)的数量。
- k-shot 指的是每个任务或类别中提供的支持样本(support samples)的数量。
支持集 D (Support Set):
- 支持集 D = ⋃ i = 1 n T i D=⋃_{i=1}^nT_i D=⋃i=1nTi 包含来自 n n n 个任务(tasks)的正常(normal)图像。
- T i T_i Ti 是第 i i i 个任务的图像集合,其中包含 k k k 张正常图像。
- 简而言之,模型在训练阶段只能接触到这些极少数( k k k 张)的正常图像来进行学习。
测试阶段 (Test Phase):
- 在测试阶段,会提供来自 n n n 个任务的查询图像(query images)。
- 模型的训练目标是完成两个任务:
- 识别异常 (Identify anomalous): 判断这些查询图像是否异常(anomalous)。
- 指示异常区域的位置 (Indicate the location of the anomalous regions): 如果图像是异常的,指出异常区域的具体位置。
本文中的具体设置 (Specific Setting in This Paper):
- 鉴于各种医学异常检测任务之间存在显著差异,并且为了满足医疗系统的实际需求,作者在论文中将 n n n 设置为 1 ( n = 1 n=1 n=1)。
- 这意味着:"一个模型针对一个任务"(one model for one task)。模型在训练时是针对特定的医学异常检测任务进行优化的,而不是同时处理多个任务。
2.2 提示学习
传统 CLIP 提示的局限性:
- 在原始的 CLIP 模型 中,常用的提示模板(如:"A photo of a CLS")主要用于描述自然图像的整体语义信息。
- 然而,这种提示方式难以捕捉到医学图像中微小的细节(subtle details),这对于医学异常检测至关重要。
引入可学习提示 (Adopting Learnable Prompts):
- 为了解决上述问题,作者放弃了手动设计的提示(manually designed prompts),转而使用可学习提示(learnable prompts)进行异常检测。
- 这样做的目的是:
- 确保文本嵌入(text embeddings)能够在医学图像中有效地泛化。
- 避免提示工程(prompt engineering)的复杂性,即不需要人工精心设计最佳文本描述。
可学习提示的格式 (Format of the Learnable Prompt):
- 作者采用了如下的提示格式:
p = V 1 V 2 . . . V M C L S p=V_1V_2...V_M CLS p=V1V2...VMCLS
- 其中:
- V V V (即 V 1 . . . V M V_1...V_M V1...VM)代表可学习的词嵌入(learnable word embeddings)。
- CLS 代表提示模板中不可学习的类别嵌入(non-learnable class embeddings)。
- M 表示可学习标记(tokens)的数量。
类别标记的选择 (Selection of Class Tokens):
- 对于类别标记(class tokens),作者使用了医学相关的术语 :
- 正常情况 (Normal cases): 使用 healthy 和 normal 等。
- 异常情况 (Anomalies): 使用 disease 等。
构建提示集和特征表示 (Constructing Prompt Sets and Feature Representations):
- 基于这些类别标记,作者定义了正常情况和异常情况的提示集合:
- 正常提示集: P n = { p n 1 , p n 2 , . . . , p n I } P_n=\{p_{n_1},p_{n_2},...,p_{n_I}\} Pn={pn1,pn2,...,pnI}
- 异常提示集: P a = { p a 1 , p a 2 , . . . , p a E } P_a=\{p_{a_1},p_{a_2},...,p_{a_E}\} Pa={pa1,pa2,...,paE}
- I I I 和 E E E 分别代表 P n P_n Pn 和 P a P_a Pa 中包含的类别标记数量。
文本编码器 (Text Encoder):
- 将 CLIP 的文本编码器定义为 F ( ⋅ ) F(⋅) F(⋅),它将提示 p p p 映射为其特征表示 F ( p ) ∈ R C F(p)∈R^C F(p)∈RC。
- C C C 表示提示特征的维度。
平均特征表示 (Mean Feature Representations):
- 最终,通过对各自集合中的所有提示特征取平均,得到代表正常和异常的平均特征向量:
- 正常特征平均值 f n = 1 I ∑ i = 1 I F ( p n i ) f_n=\frac {1} {I}∑{i=1}^IF(p{n_i}) fn=I1∑i=1IF(pni)
- 异常特征平均值 f a = 1 E ∑ i = 1 E F ( p a i ) f_a=\frac {1} {E}∑{i=1}^EF(p{a_i}) fa=E1∑i=1EF(pai)
- 这些平均特征 f n f_n fn 和 f a f_a fa 将用于后续与图像特征进行相似度计算,从而实现异常检测。
2.3 异常检测CLIP适配器
CLIP的局限性与适配器的引入:
- 原始的CLIP模型主要设计用于零样本/少样本的图像-文本分类任务,不能直接应用于异常检测和定位。
- 为了解决这个问题,MediCLIP在原始CLIP模型中引入了适配器(Adapters),通过少量可学习参数将其改造用于少样本异常检测。
合成异常图像的生成:
- 对于支持集 D D D 中的一张医学图像 X ∈ R H × W × 3 X∈R^{H×W×3} X∈RH×W×3,模型随机采样一个异常区域掩码 Y ∈ R H × W Y∈R^{H×W} Y∈RH×W。
- 通过一系列异常合成任务 Ψ ( ⋅ ) Ψ(⋅) Ψ(⋅),生成对应的合成异常图像 X ^ = Ψ ( X , Y ) \hat X=Ψ(X,Y) X^=Ψ(X,Y)。
多尺度特征提取和通道对齐:
- 使用CLIP的视觉编码器 G j ( ⋅ ) G_j(⋅) Gj(⋅) 提取图像 X ^ \hat X X^的第 j j j 层特征 G j ( X ^ ) ∈ R H j × W j × C j G_j(\hat X)∈R^{H_j×W_j×C_j} Gj(X^)∈RHj×Wj×Cj。
- 图像 X ^ \hat X X^ 获得了一个多尺度视觉特征集 { G 1 ( X ^ ) , G 2 ( X ^ ) , . . . , G J ( X ^ ) } \{G_1(\hat X),G_2(\hat X),...,G_J(\hat X)\} {G1(X^),G2(X^),...,GJ(X^)}。
- 对于每个中间层特征 G j ( X ^ ) G_j(\hat X) Gj(X^),使用一个适配器 ϕ j ( ⋅ ) ϕ_j(⋅) ϕj(⋅) 将其映射到与提示特征 f n f_n fn 和 f a f_a fa 相同的通道数,得到 g j = ϕ j ( G j ( X ^ ) ) g_j=ϕ_j(G_j(\hat X)) gj=ϕj(Gj(X^)),其中 g j ∈ R H j × W j × C g_j∈R^{H_j×W_j×C} gj∈RHj×Wj×C。
相似性计算(异常得分):
- 计算 g j g_j gj 与正常提示特征 f n f_n fn 和异常提示特征 f a f_a fa 在空间位置 ( h , w ) (h, w) (h,w) 上的相似性得分:
S ( h , w ) n j = e x p ( < g ( h , w ) j , f n > / τ ) ∑ f ∈ { f n , f a } e x p ( < g ( h , w ) j , f > / τ ) , S ( h , w ) a j = e x p ( < g ( h , w ) j , f a > / τ ) ∑ f ∈ { f n , f a } e x p ( < g ( h , w ) j , f > / τ ) S_{(h,w)}^{nj}=\frac {exp(<g_{(h,w)}^j,f_n>/τ)} {∑{f∈\{f_n,f_a\}}exp(<g{(h,w)}^j,f>/τ)}, S_{(h,w)}^{aj}=\frac {exp(<g_{(h,w)}^j,f_a>/τ)} {∑{f∈\{f_n,f_a\}}exp(<g{(h,w)}^j,f>/τ)} S(h,w)nj=∑f∈{fn,fa}exp(<g(h,w)j,f>/τ)exp(<g(h,w)j,fn>/τ),S(h,w)aj=∑f∈{fn,fa}exp(<g(h,w)j,f>/τ)exp(<g(h,w)j,fa>/τ)
- 其中, ⟨ ⋅ , ⋅ ⟩ ⟨⋅,⋅⟩ ⟨⋅,⋅⟩ 代表余弦相似度, τ τ τ 是温度参数。
- 通过适配器投影后的每个视觉特征 g j g_j gj 都可以得到相似性矩阵 S n j , S a j ∈ R H j × W j S_{nj},S_{aj}∈R^{H_j×W_j} Snj,Saj∈RHj×Wjj。
多尺度聚合和损失函数:
- 对多尺度相似性矩阵集 { S n 1 , S n 2 , . . . , S n J } \{S_{n_1},S_{n_2},...,S_{n_J}\} {Sn1,Sn2,...,SnJ} 和 { S a 1 , S a 2 , . . . , S a J } \{S_{a_1},S_{a_2},...,S_{a_J}\} {Sa1,Sa2,...,SaJ} 执行聚合操作。
- 将它们上采样到与原始图像相同的空间分辨率 H × W H×W H×W,并计算它们的平均值,得到 S n , S a ∈ R H × W S_n,S_a∈R^{H×W} Sn,Sa∈RH×W。
- 为了优化可学习提示和适配器中的参数,定义损失函数:
L = L f o c a l ( S n , S a , Y ) + L d i c e ( S a , Y ) L=L_{focal}(S_n,S_a,Y)+L_{dice}(S_a,Y) L=Lfocal(Sn,Sa,Y)+Ldice(Sa,Y)
推理阶段:
- 在推理阶段,移除异常合成任务,使用查询图像作为 X ^ \hat X X^。
- 使用 S a S_a Sa 作为像素级的异常图(pixel-level anomaly map),并且 S a S_a Sa 中的最大值被用作图像级的异常得分(image-level anomaly score)。
2.4 多任务异常合成机制
多任务异常合成的目的是基于给定的原始图像 X X X 和目标遮罩 Y Y Y 来生成合成异常图像 X ^ \hat X X^。论文引入了三种不同类型的异常合成任务,分别模拟医学影像中常见的不同异常模式:
- CutPaste: 对应图像融合(image blending),模拟移位或缺失。
- GaussIntensityChange: 对应强度变化(intensity variation),模拟密度变化。
- Source: 对应形变(deformation),模拟增生。
CutPaste 任务 (图像融合)
- 机制: CutPaste 任务随机选择一个图像块,并将其粘贴到图像的目标位置。
- 技术细节: 论文使用了增强版本,通过 泊松图像编辑(Poisson image editing) 技术实现图像块的无缝融合,使合成的异常看起来更自然。
- 模拟的异常类型: CutPaste 任务可以模拟医学影像中类似错位(misplacement-like)的异常,例如骨折(fractures)。
GaussIntensityChange 任务 (强度变化)
- 机制: 该任务通过改变像素强度来模拟医学影像中的密度变化(density variations)。
- 合成过程 :
- 首先,从标准高斯分布 N ( 0 , I ) N(0, I) N(0,I) 中采样噪声 σ σ σ。
- 然后,基于阈值 0 0 0 对 σ σ σ 进行二值化(binarize),并通过高斯滤波器处理得到 σ ^ \hat σ σ^。
- 最终的异常图像 X ^ \hat X X^ 通过以下公式定义: X ^ = X ⊙ ( 1 − Y ) + ( X + γ σ ^ ) ⊙ Y \hat X=X⊙(1−Y)+(X+γ\hat σ)⊙Y X^=X⊙(1−Y)+(X+γσ^)⊙Y
- ⊙ 表示元素级的乘法。
- 公式表明:在非异常区域 ( 1 − Y ) (1 - Y) (1−Y),像素保持不变 X X X。在异常区域 Y Y Y 内,像素强度被修改为 X + γ σ ^ X+γ\hatσ X+γσ^。
- 参数 γ γ γ: γ γ γ 是强度变化因子 。当 γ > 0 γ>0 γ>0 时,强度增加(图像变亮/变密);当 γ < 0 γ<0 γ<0 时,强度减少(图像变暗/稀疏)。
- 模拟的异常类型: 该任务特别有效地模仿了放射影像中肿瘤(tumors)或囊肿(cysts)等病灶的密度变化。
Source 任务 (形变)
-
机制: 旨在模拟增生性异常 ,通过将遮罩 Y Y Y 内的所有点从一个中心点 c c c 向外推开,制造出组织扩张的形变效果。
-
形变计算 :
- 定义 Y Y Y 在某一方向上的半径为 r r r。对于源位置 l l l,目标位置 l ^ \hat l l^ 被计算如下
l ^ = c + r ( l − c ∥ l − c ∥ 2 ( ∥ l − c ∥ 2 r ) α ) \hat l=c+r(\frac {l-c} {∥l−c∥^2} (\frac {∥l−c∥_2} {r})^α) l^=c+r(∥l−c∥2l−c(r∥l−c∥2)α)
- 参数 α α α: α α α 控制着从中心点 c c c 向外推斥的强度(intensity of repulsion)。 α α α 越大,推斥力越强,形变越显著。
- 像素替换: 最终,源位置 l l l 的像素被目标位置 l ^ \hat l l^的像素所取代( x l ^ = x l ^ \hat {x_l} =x_{\hat l} xl^=xl^),从而在图像中创建扩张形变。
-
模拟的异常类型: 模拟医学影像中的增生性异常(proliferative anomalies) ,例如心脏肥大(cardiomegaly),即器官体积异常增大。
3. 实验
3.1 实验设置
数据集 (Datasets)
作者在三个不同的医疗图像数据集上进行了广泛的实验,包括:
- 斯坦福CheXpert数据集 : 包含来自斯坦福医院临床患者的胸部X光图像。这个数据集涵盖了12种不同的疾病,例如心脏肥大(Cardiomegaly)、水肿(Edema)、胸腔积液(Pleural Effusion)等。
- BrainMRI数据集: 包含2D人体脑部MRI图像,包括正常病例和受肿瘤影响的病例。
- BUSI数据集: 包含年龄在25至75岁的女性患者的乳房超声图像。这些图像分为正常(normal)、良性(benign)和恶性(malignant)三类,并提供了像素级别的标注来标记病灶位置。
在这项研究中,所有疾病图像(良性、恶性或CheXpert中的12种疾病)都被视为异常(anomalies)。
Few-shot设置和测试数据:
- 训练(支持集): 对于每个数据集,模型训练只使用了极少量的正常图像,即 k={4,8,16,32} 张正常图像。
- 测试(查询集): 在测试阶段,三个数据集分别包含的正常图像数量和异常图像数量如下:
- CheXpert:250张正常图像,250张异常图像。
- BrainMRI:65张正常图像,155张异常图像。
- BUSI:101张正常图像,647张异常图像。
实施细节 (Implementation Details)
- 预训练模型: 使用ViT-L/14 作为预训练的CLIP模型。
- 特征提取: 保留了视觉编码器(visual encoder)的第12、18和24层的特征用于异常检测。
- 可学习提示 (Learnable Tokens): 可学习的tokens数量 M 设置为8。
- 适配器 (Adapter): 使用线性层作为适配器。
- 温度参数: 温度参数 τ τ τ 设置为0.07。
- 异常合成任务参数:
- GaussIntensityChange (高斯强度变化): 强度变化因子 γ γ γ 在 [ − 0.6 , − 0.4 ) ∪ [ 0.4 , 0.6 ) [−0.6,−0.4)∪[0.4,0.6) [−0.6,−0.4)∪[0.4,0.6) 范围内均匀采样。
- Source (源任务): 排斥强度控制参数 α α α 在 [ 2 , 4 ) [2,4) [2,4) 范围内均匀采样。
- 异常形状:
- 对于CutPaste和GaussIntensityChange任务,使用Perlin噪声生成器 来捕捉各种异常形状,并将其二值化为异常掩码 Y Y Y。
- 对于Source任务,由于需要计算异常区域在任意方向上的半径,因此使用具有随机尺寸和旋转角度的椭圆或矩形作为异常掩码 Y Y Y。
- 合成策略: 三种异常合成任务(CutPaste、GaussIntensityChange和Source)以等概率用于异常合成。
- 输入图像尺寸: 输入图像大小统一为 224 × 224 224×224 224×224 像素。
- 实验一致性: 三个数据集使用了相同的超参数设置。
- 重复实验: 为了确保结果的可靠性,每次实验独立进行三次,并对不同的支持集进行采样来训练MediCLIP。
基线和指标 (Baselines and Metrics)
- 基线
- 评估指标:
- 异常检测性能: 使用 Image-AUROC(图像级别异常检测的曲线下面积)进行评估。
- 异常定位性能: 使用 Pixel-AUROC(像素级别异常定位的曲线下面积)进行评估。
3.2 实验结果
少样本异常检测性能对比 (Table 1):
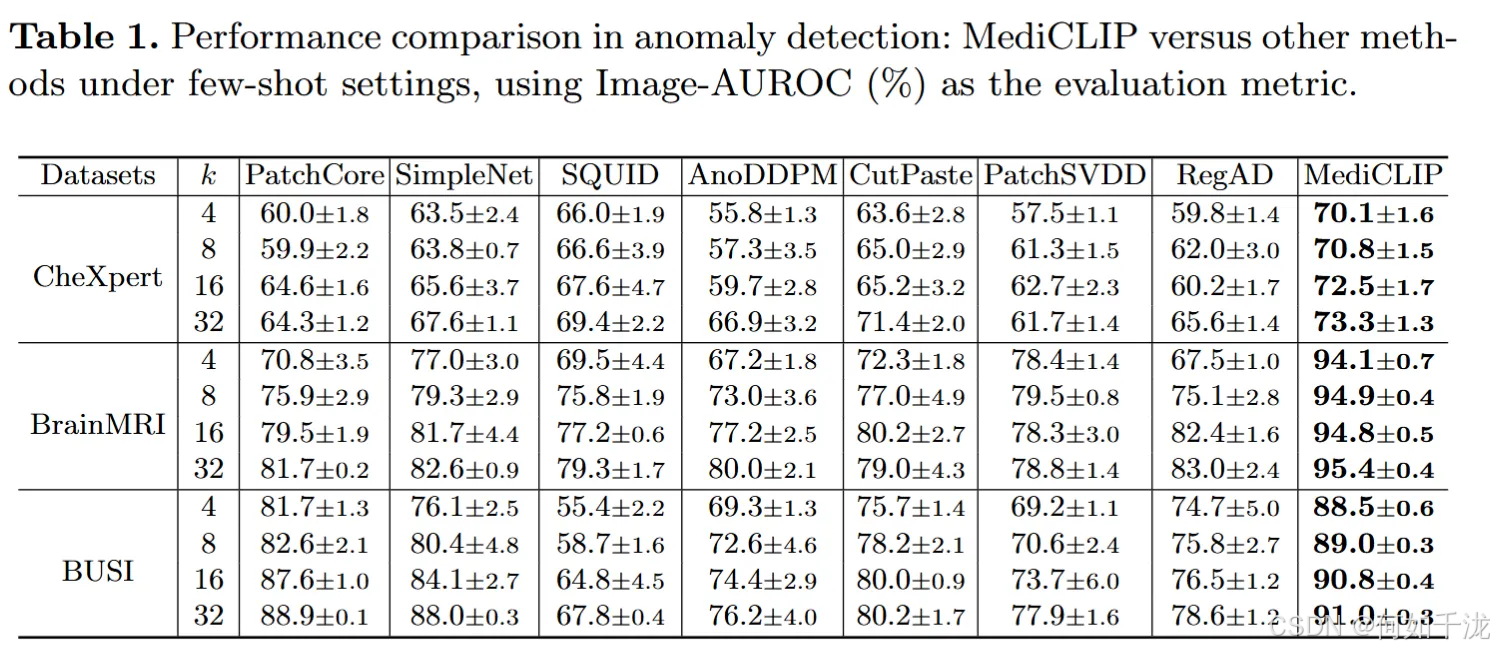
- 对比基础: 研究人员在三个不同的医学数据集上将MediCLIP的异常检测性能与其他现有方法进行了比较,结果呈现在表1中。
- 其他方法的局限性: 在少样本(即训练图像极少)的设置下,其他方法由于正常图像的稀缺性,难以实现良好的泛化能力。
- MediCLIP的优势: 相比之下,MediCLIP通过一系列精心设计的异常合成任务(anomaly synthesis tasks),成功地将CLIP模型强大的泛化能力转移到了医学异常检测任务上。
- 性能提升: MediCLIP的异常检测性能比其他方法提高了大约10%。
异常定位性能对比 (Table 2 & Fig. 3):
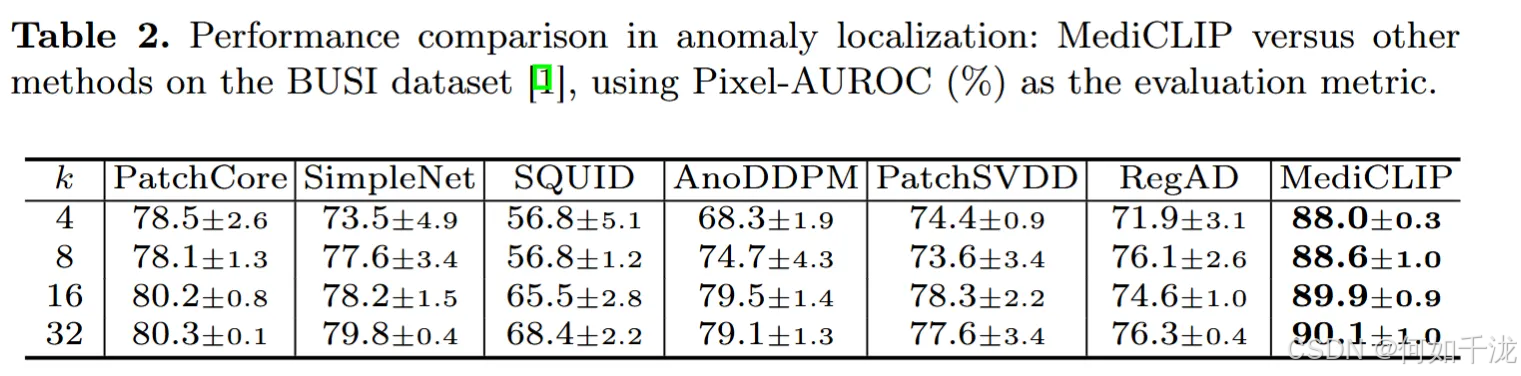
- 定位任务: 表2展示了MediCLIP与其他方法在BUSI数据集上的异常定位性能。
- 定位优势: 结果表明,MediCLIP在定位病灶区域方面更有效。
- 可视化效果 (图3): 图3提供了MediCLIP异常定位结果的可视化示例,展示了该模型能够准确识别异常区域,从而为真实的医疗决策提供了有价值的参考。
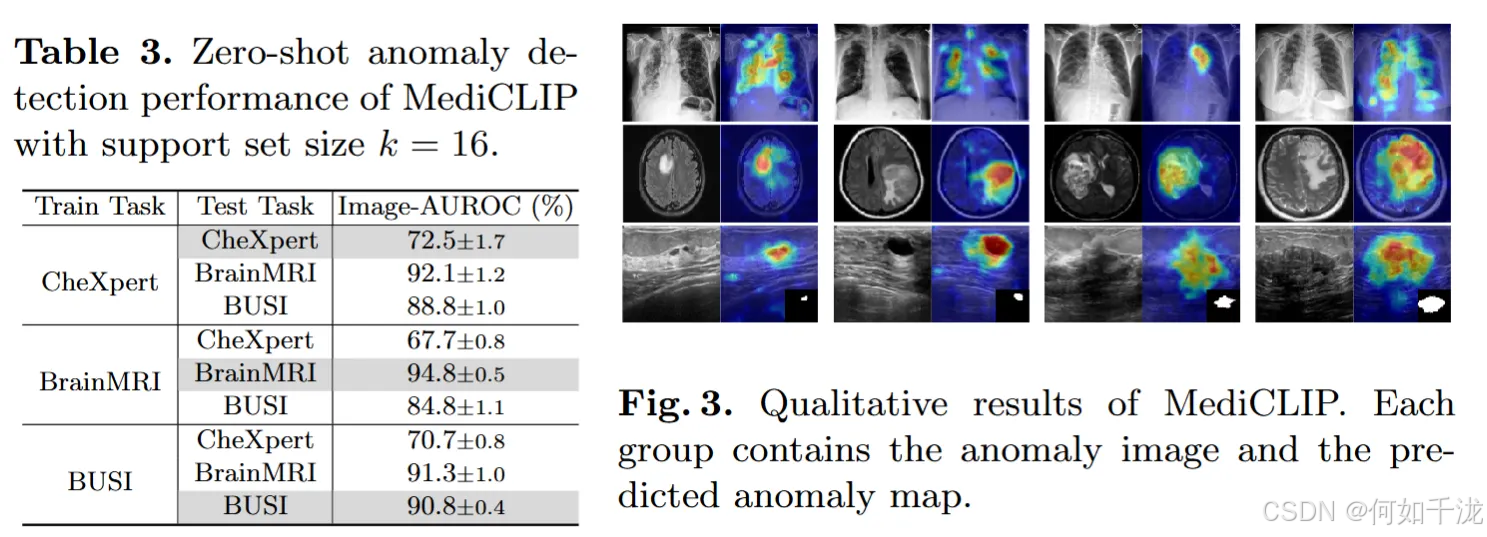
零样本泛化能力 (Table 3):
- 零样本检测: 表3展示了MediCLIP在不同数据集上的 零样本(zero-shot) 异常检测性能。
- 跨任务泛化: 实验结果表明,MediCLIP的异常检测能力可以泛化到不同的任务之间。
- 策略有效性: 这证明了其采用的多任务异常合成策略能够有效地模拟各种医学图像中常见的异常模式。
3.3 消融实验
核心组件的有效性验证 (表 4)
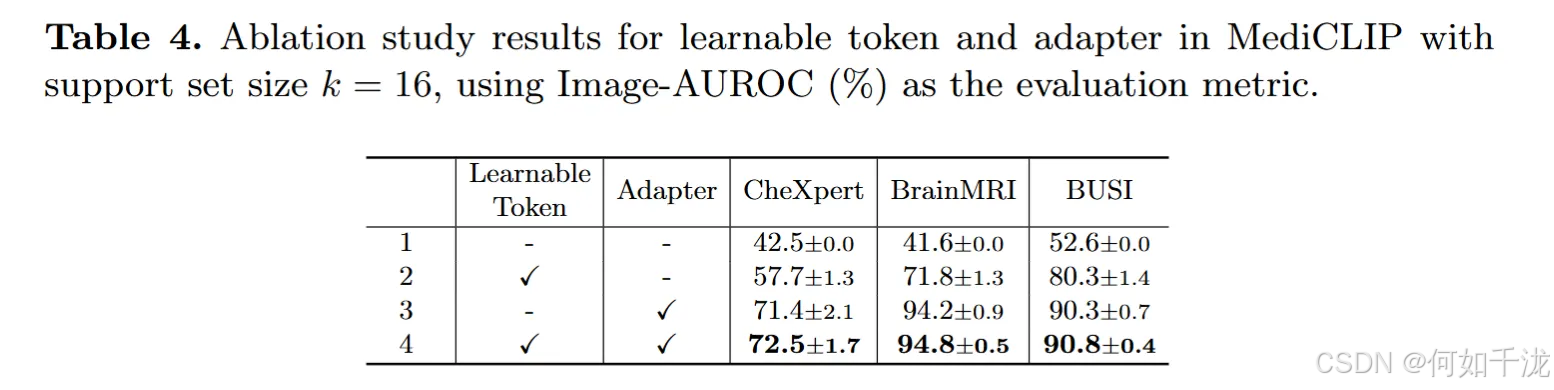
- 目的: 表4的目的是验证MediCLIP框架中两个关键组成部分------可学习标记(learnable token)和适配器(adapter)------的有效性和重要性。
- 对比实验设计:
- 替换可学习标记: 研究人员用硬性提示模板(hard prompt templates,例如"A photo of the CLS",源自文献12)替换了可学习标记。硬性提示通常难以捕捉医学图像的细微细节。
- 替换适配器: 研究人员使用**沿通道的平均池化(average pooling along the channel)**来代替适配器(Adapter)。适配器的作用是调整和对齐CLIP视觉编码器中间层的特征与可学习文本特征。
- 实验结果结论: 表4的实验结果有力地证明了可学习标记和适配器是不可替代的(irreplaceability)。这意味着这两个专门为医学图像异常检测设计的组件对于维持MediCLIP的高性能至关重要。
训练设置和异常合成任务的性能对比 (表 5)
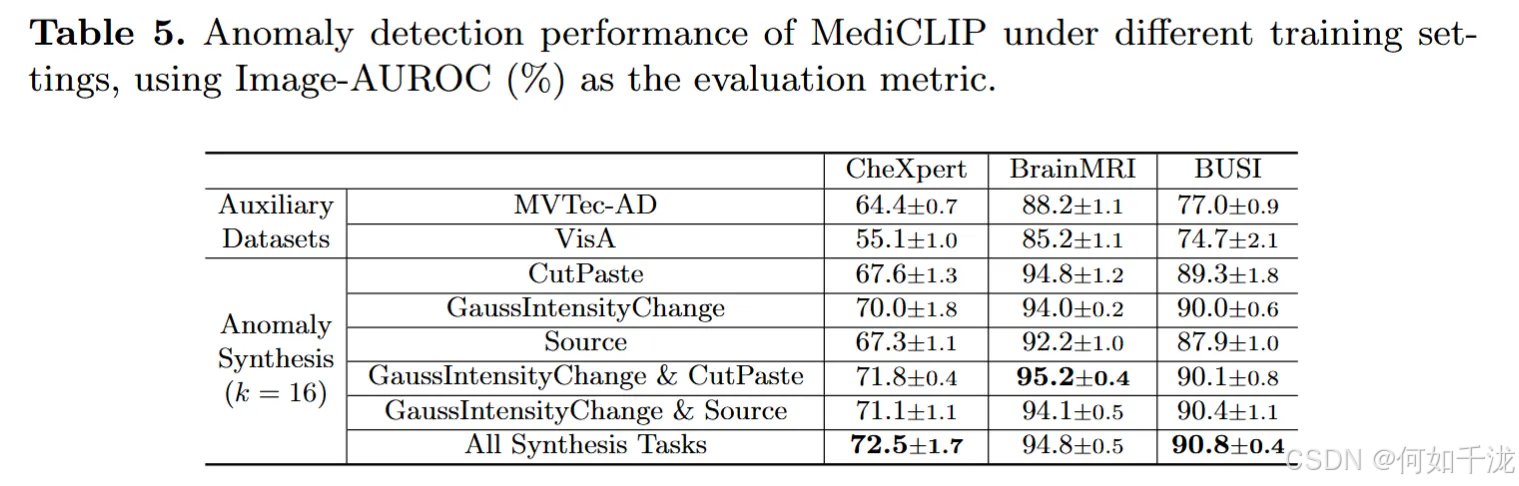
- 目的: 表5比较了MediCLIP在不同训练设置下的异常检测性能。
- 辅助数据集对比:
- 设置: 遵循先前研究 的设置,研究人员使用了工业异常检测数据集(如MVTec-AD 和 VisA )作为辅助数据集进行模型训练,然后评估模型在医学图像上的异常检测性能。
- 结论: 与使用这些辅助数据集相比,MediCLIP采用的医学异常合成任务 (medical anomaly synthesis task)取得了更好的泛化性能。这表明专门为医学领域设计的合成策略更适合此任务。
- 异常合成任务的组合效果:
- 表5还对比了单一异常合成任务(如CutPaste、GaussIntensityChange、Source)以及它们不同组合(如GaussIntensityChange & CutPaste)的性能。
- 结论: 实验结果显示,多个合成任务的组合(如"All Synthesis Tasks")可以进一步增强MediCLIP的异常检测性能。这支持了多任务合成策略(Multi-task Anomaly Synthesis)的有效性。
4. 结论
- 首次全面探索少样本医学图像异常检测任务: 本文首先全面深入地探索了少样本医学图像异常检测(few-shot medical image anomaly detection)这一任务。这是一个具有广泛应用前景但尚未得到充分研究的领域。
- 提出了MediCLIP模型:提出了一个名为 MediCLIP 的创新方法。它是对强大的 CLIP 模型进行调整和适应,使其专门适用于医学异常检测任务。MediCLIP 的核心特点是它集成了多任务异常合成(multi-task anomaly synthesis)策略。
- MediCLIP的特性和能力:MediCLIP 的特点是高效 (efficiency)且拥有卓越的性能 (superior performance)。它能够有效地检测各种不同的疾病 ,并且适用于不同类型的医学影像数据。
- 实验验证和实际潜力:通过在三个医学数据集 上进行的全面实验,验证并强调了 MediCLIP 在准确异常检测 和异常定位方面的强大能力。MediCLIP能够用极少的训练样本(few-shot)达到接近使用全部数据(full-shot)方法的性能,大大降低了开发成本。