一、引言
1.1 核心概念定义
可靠性是指系统在规定的条件下、规定的时间内,完成规定功能的能力,核心表征系统无故障持续运行的固有属性;可用性是指系统能够正常提供服务的时间比例,核心表征用户视角下服务的可获取性。二者是系统质量属性中 "可用性" 维度的核心组成部分,属于软考高级系统架构设计师考试中 "系统质量属性设计" 模块的必考知识点,在历年案例分析题和论文题中出现频率超过 60%。
1.2 技术发展脉络
可靠性工程起源于 20 世纪 40 年代的美国军事领域,1947 年美国军方发布首个可靠性标准 MIL-STD-781,首次将可靠性定量指标纳入装备验收要求;20 世纪 60 年代随着计算机技术发展,软件可靠性研究逐步兴起,1975 年 IEEE 发布软件工程领域首个可靠性度量标准 IEEE Std 982.1;21 世纪云原生架构普及后,可用性设计逐步形成从硬件、软件到运维体系的全链路方法论,成为分布式系统架构设计的核心基础。
1.3 本文知识点覆盖
本文将系统梳理可靠性与可用性的核心原理、量化指标、软硬件差异、架构设计方法及行业应用实践,覆盖软考考试中该知识点的所有考点要求。
二、可靠性与可用性核心架构原理
2.1 基本原理与核心内涵
(1)可靠性的三大约束要素
规定条件包括硬件环境、软件配置、负载压力、操作规范等所有外部运行条件,脱离具体约束的可靠性描述不具备工程意义;规定时间是可靠性的核心维度,通常以运行时长、请求次数等作为度量单位,不同场景下时间尺度差异显著(航空航天系统按年计算,互联网应用按秒计算);规定功能是指系统需求规格说明书中明确的所有功能点,只要有一个功能不满足即判定为失效。
(2)可用性的用户视角本质
可用性不关注故障发生的原因,只关注故障对用户的影响,只要用户无法正常获取服务即判定为不可用,包括计划内停机(如版本升级、数据迁移)和计划外停机(如硬件故障、软件缺陷)两类场景,在 to B 业务场景中通常会作为 SLA(服务水平协议)的核心考核指标。
2.2 核心量化指标体系
(1)MTTF(平均无故障时间)
指系统从启动运行到首次发生非计划故障的平均时间,是可靠性的核心度量指标,计算公式为 MTTF = 1/λ,其中 λ 为失效率,即单位时间内发生故障的概率。某金融核心交易系统的 MTTF 要求不低于 8760 小时(即年失效率低于 1 次),才能满足监管要求。
(2)MTTR(平均故障修复时间)
指系统从故障发生到恢复正常服务的平均时间,是可维护性的核心度量指标,计算公式为 MTTR = 1/μ,其中 μ 为修复率,即单位时间内完成故障修复的概率。MTTR 包含故障发现时间、定位时间、修复时间、验证时间四个部分,互联网大厂的核心系统 MTTR 通常要求控制在 5 分钟以内。
(3)MTBF(平均故障间隔时间)
指系统两次相邻故障之间的平均时间,计算公式为 MTBF = MTTF + MTTR。当系统故障可修复时,MTBF 是更贴近实际运行场景的可靠性指标;对于不可修复系统(如一次性传感器),MTBF 等价于 MTTF。
2.3 可用性计算公式与等级划分
(1)精确计算公式
系统可用性 A = MTTF / (MTTF + MTTR) * 100%,该公式适用于所有可修复系统的可用性量化。当 MTTR 远小于 MTTF 时(工程中 99% 以上的场景满足该条件),可近似为 A ≈ MTBF / (MTBF + MTTR) * 100%,该简化计算是软考选择题的高频考点。
(2)可用性等级标准
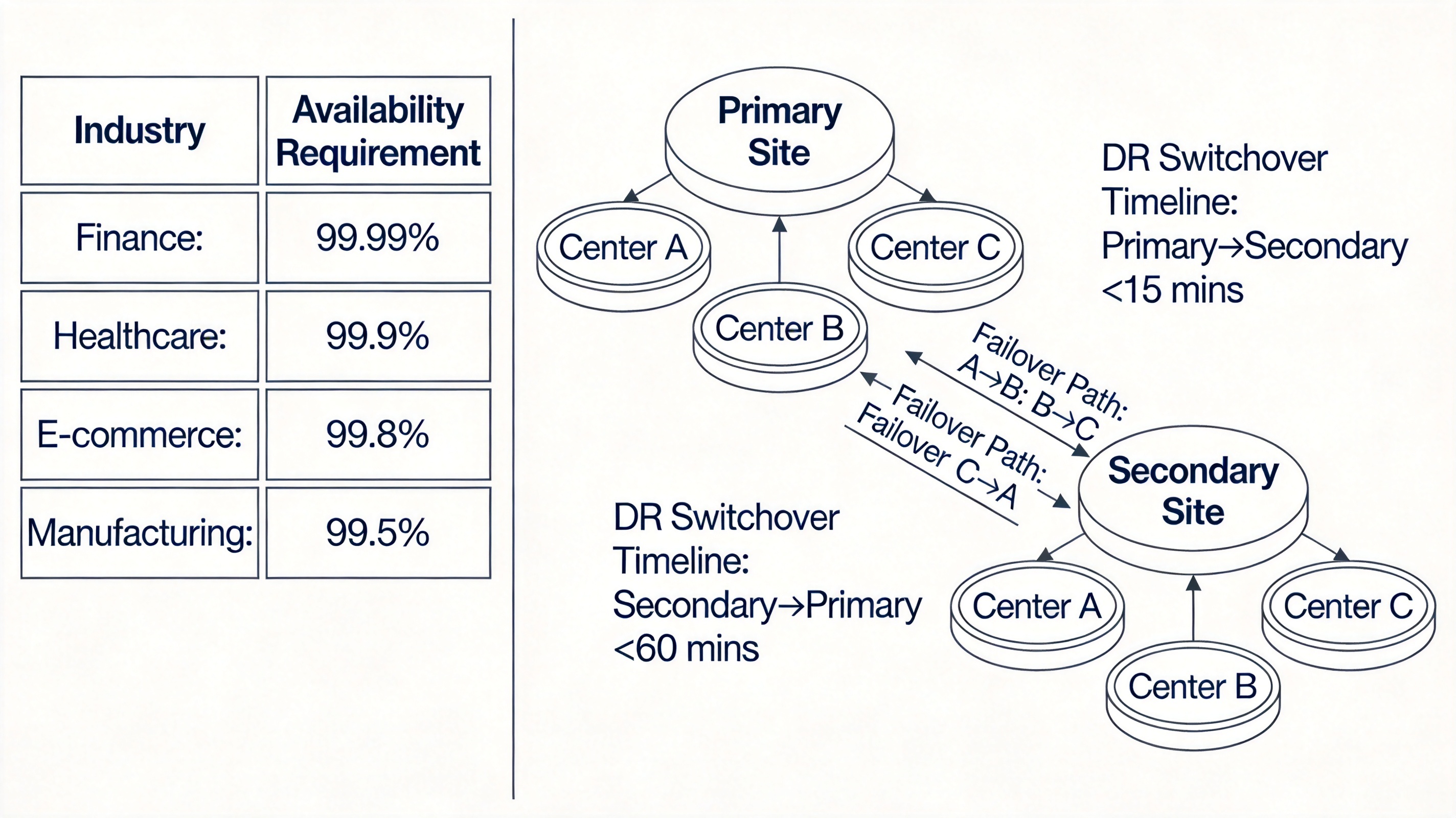
行业通用的可用性等级按 9 的数量划分:1 个 9(90%)年停机时间不超过 36.5 天,适用于非核心测试系统;2 个 9(99%)年停机时间不超过 3.65 天,适用于内部办公系统;3 个 9(99.9%)年停机时间不超过 8.76 小时,适用于普通 to C 应用;4 个 9(99.99%)年停机时间不超过 52.6 分钟,适用于金融、电商核心交易系统;5 个 9(99.999%)年停机时间不超过 5.26 分钟,适用于电信、航空航天等关键业务系统。
 可靠性与可用性指标关系示意图、可用性等级与允许停机时间对照表
可靠性与可用性指标关系示意图、可用性等级与允许停机时间对照表
三、软硬件可靠性差异与设计方法对比
3.1 本质差异分析
(1)失效机理差异
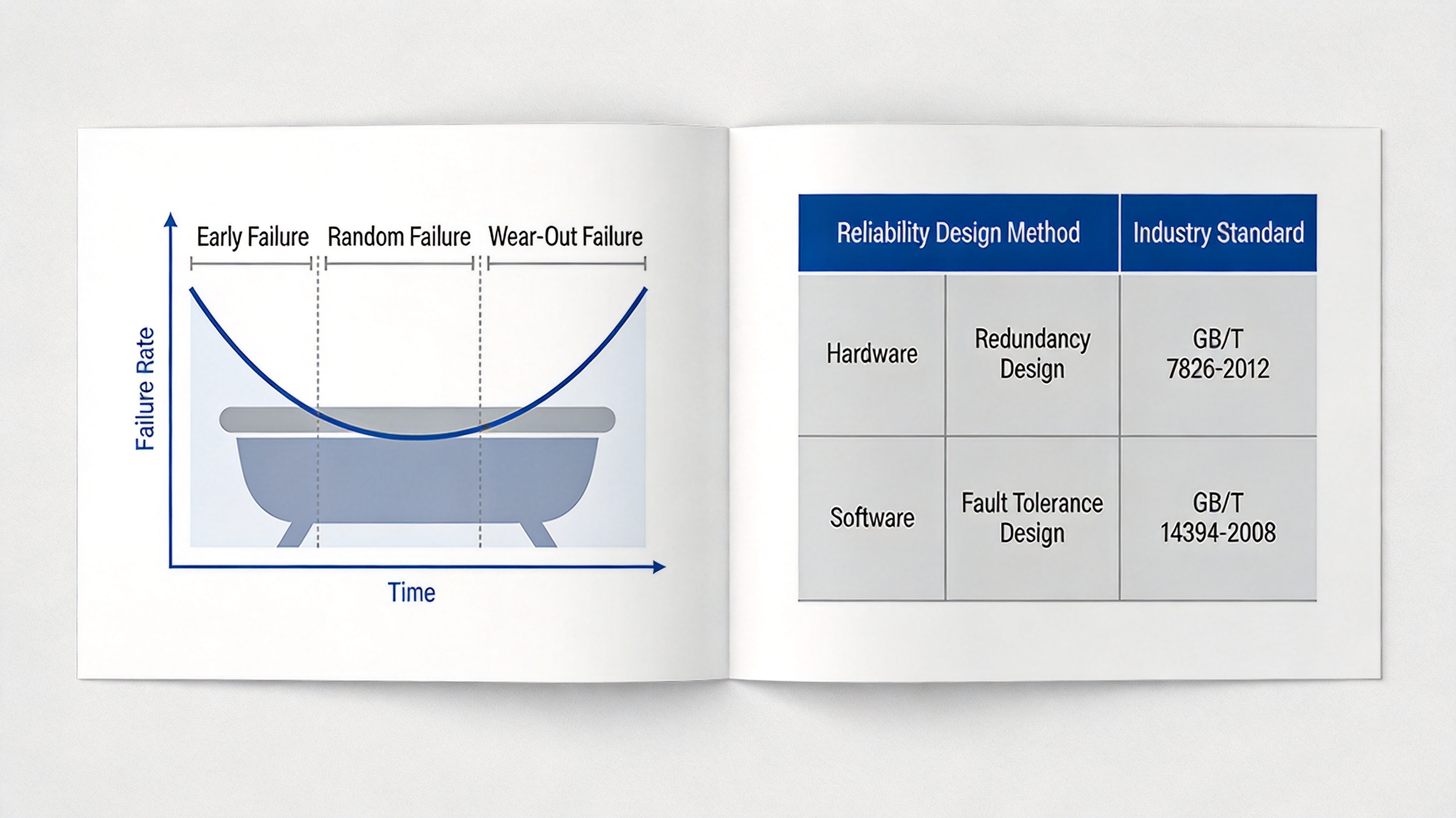
硬件失效主要分为三类:早期失效(出厂缺陷,随时间推移降低)、偶然失效(稳定运行期随机发生,失效率恒定)、耗损失效(物理老化,随时间推移升高),整体呈现浴盆曲线特征;软件失效没有物理退化过程,所有缺陷在开发阶段已经存在,失效率随版本更新呈现突变特征,不存在耗损失效阶段,当软件版本长期不更新且运行场景稳定时,失效率会逐步趋于恒定。
(2)设计逻辑差异
硬件可靠性设计以冗余、降额、老化筛选为核心,通过物理层面的备份降低单一部件故障的影响;软件可靠性设计以容错、防错、退化降级为核心,通过逻辑层面的校验和冗余降低缺陷带来的影响。
(3)迭代特性差异
硬件迭代周期通常以季度 / 年为单位,版本更新成本高,可靠性验证要求严苛;软件迭代周期通常以周 / 天为单位,版本更新成本低,可靠性可以通过持续迭代逐步优化。
3.2 架构设计方法对比
(1)硬件可靠性设计方法
冗余设计包括主动冗余(双活 / 多活架构,故障自动切换)和被动冗余(主备架构,故障后手动切换),某电信运营商的核心网络设备采用 N+1 冗余设计,单台设备故障时流量自动切换到备用设备,MTTR 小于 30 秒;降额设计是指让硬件工作在低于额定参数的环境下,如服务器 CPU 负载控制在 70% 以下,电源负载控制在 60% 以下,降低硬件老化速度。
(2)软件可靠性设计方法
容错设计包括重试、降级、熔断、流量控制等机制,某电商平台的商品详情服务在下游库存服务故障时,自动返回缓存中的历史库存数据,保证核心交易链路正常运行;缺陷预防包括代码评审、单元测试、集成测试、灰度发布等流程,互联网大厂的核心系统代码覆盖率通常要求不低于 90%,灰度发布覆盖 10% 用户且稳定运行 24 小时后才会全量上线。
3.3 行业标准与最佳实践
硬件可靠性设计遵循 GB/T 7826-2012《可靠性分析技术 失效模式和影响分析 (FMEA) 程序》,软件可靠性设计遵循 GB/T 14394-2008《计算机软件可靠性和可维护性管理》,这两项标准是软考考试中可靠性设计模块的指定参考标准。
 软硬件可靠性失效曲线对比图、软硬件设计方法对比表
软硬件可靠性失效曲线对比图、软硬件设计方法对比表
四、实际应用与案例分析
4.1 不同场景下的指标要求
(1)金融核心交易系统
要求可用性不低于 99.99%,MTTF 不低于 8760 小时,MTTR 不高于 30 分钟。某国有银行的核心账务系统采用两地三中心架构,主数据中心故障时,异地灾备中心可在 15 分钟内完成切换,全年实际停机时间不超过 20 分钟,满足监管要求。
(2)互联网电商交易系统
大促期间要求可用性不低于 99.99%,平时不低于 99.9%。某头部电商平台的订单系统采用微服务架构,通过服务冗余、多级缓存、流量削峰等机制,2023 年 "双 11" 期间峰值 QPS 达到 59.2 万,MTTR 控制在 2 分钟以内,全周期可用性达到 99.992%。
(3)工业控制系统
要求可用性不低于 99.999%,MTTF 不低于 43800 小时(5 年),MTTR 不高于 5 分钟。某核电站的 DCS 控制系统采用三重冗余架构,三个控制器同时运算,采用多数表决机制输出结果,单台控制器故障不影响系统正常运行,可靠性满足核安全一级要求。
4.2 常见误区与避坑指南
(1)混淆可靠性与可用性
某创业公司的内部 OA 系统 MTTF 达到 180 天,但每次故障需要 2 天才能修复,可用性仅为 180/(180+2)=98.9%,低于 2 个 9 的要求,无法满足日常办公需求,该案例的核心错误就是片面追求可靠性而忽略了可维护性设计。
(2)忽略计划内停机
某 SaaS 服务商对外承诺可用性 99.9%,但每月进行 1 次 4 小时的版本升级,仅计划内停机的年可用性就只有 (36524 - 12 4)/(365*24)=99.45%,远低于承诺值,正确做法是采用滚动发布、蓝绿部署等机制,将计划内停机时间纳入可用性计算。
(3)过度追求高指标
某小型电商平台盲目追求 5 个 9 的可用性,投入大量成本建设多活数据中心,最终年 IT 成本是营收的 3 倍,造成严重亏损。实际上对于日活低于 10 万的小型系统,3 个 9 的可用性已经足够满足用户需求,架构设计需要在可用性和成本之间取得平衡。
不同行业可用性指标要求对比表、两地三中心架构示例图
五、高可用系统架构设计框架
5.1 分层设计体系
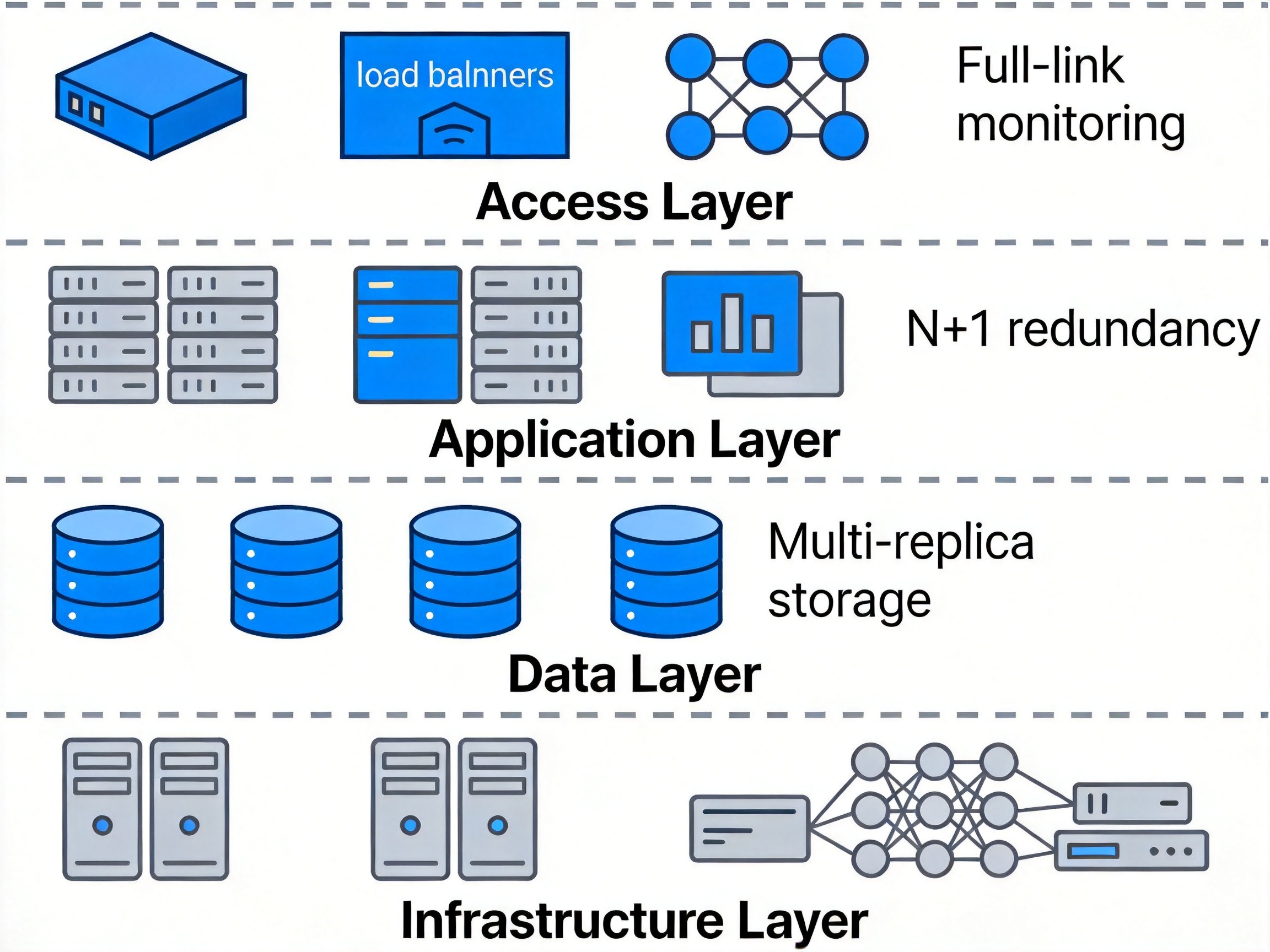
(1)基础设施层
采用多可用区部署,服务器、网络、存储均采用 N+1 冗余设计,硬件故障自动隔离,单可用区故障时流量自动切换到其他可用区,该层可用性目标不低于 99.99%。
(2)数据层
采用主从复制、读写分离、分库分表架构,核心数据进行多副本存储,定期进行数据备份和容灾演练,RPO(恢复点目标)不高于 5 分钟,RTO(恢复时间目标)不高于 30 分钟,该层可用性目标不低于 99.995%。
(3)应用层
采用无状态设计,服务节点水平扩展,通过负载均衡实现流量自动分发,单节点故障时自动摘除,该层可用性目标不低于 99.99%。
(4)接入层
采用多活 CDN、DDoS 防护、API 网关集群,能够抵御大流量攻击和单点故障,该层可用性目标不低于 99.999%。
5.2 核心保障机制
(1)故障监测体系
构建从基础设施、应用、业务三个维度的全链路监控体系,核心指标异常时自动告警,故障发现时间控制在 1 分钟以内。某互联网公司的监控系统覆盖 1000 + 核心指标,异常检测准确率达到 95% 以上,平均故障发现时间仅为 45 秒。
(2)故障恢复体系
制定标准化的故障处理流程,核心故障场景预设应急预案,采用自动化运维工具实现故障自动切换和修复,故障定位时间控制在 3 分钟以内,修复时间控制在 5 分钟以内。
5.3 性能优化与扩展性设计
高可用设计需要与高性能、可扩展性设计协同,通过缓存架构降低系统负载,通过消息队列实现流量削峰,通过微服务拆分实现故障隔离,避免单点故障扩散到整个系统。某电商平台通过引入多级缓存架构,将数据库访问量降低了 80%,系统 MTTF 提升了 3 倍,可用性从 99.9% 提升到 99.99%。
 高可用系统分层架构图、全链路监控体系示意图
高可用系统分层架构图、全链路监控体系示意图
六、前沿发展与趋势
6.1 混沌工程的普及
混沌工程是通过主动注入故障来验证系统可靠性的方法论,起源于 Netflix,2021 年发布行业标准 IEEE Std 2675-2021《混沌工程试验框架》。目前国内头部互联网公司、金融机构已经普遍采用混沌工程进行可靠性验证,通过定期注入服务器故障、网络延迟、数据库宕机等场景,提前发现系统薄弱点,将 MTTF 提升 20%-50%。
6.2 可观测性技术的发展
传统监控以预设指标为核心,可观测性技术通过日志、指标、链路追踪三大数据源,实现对系统内部状态的全面感知,能够将故障定位时间缩短 70% 以上,大幅降低 MTTR。Gartner 预测到 2026 年,70% 的企业会采用可观测性技术提升系统可用性。
6.3 可靠性自动化设计
AIOps(人工智能运维)技术逐步应用于可靠性领域,通过机器学习实现故障自动预测、根因自动分析、修复方案自动生成,未来 5 年核心系统的 MTTR 有望降低到 1 分钟以内,5 个 9 的可用性将成为企业级系统的标准配置。
该领域的技术演进是软考考试的潜在考点,需要考生重点关注混沌工程、可观测性等新兴技术与可靠性设计的结合。
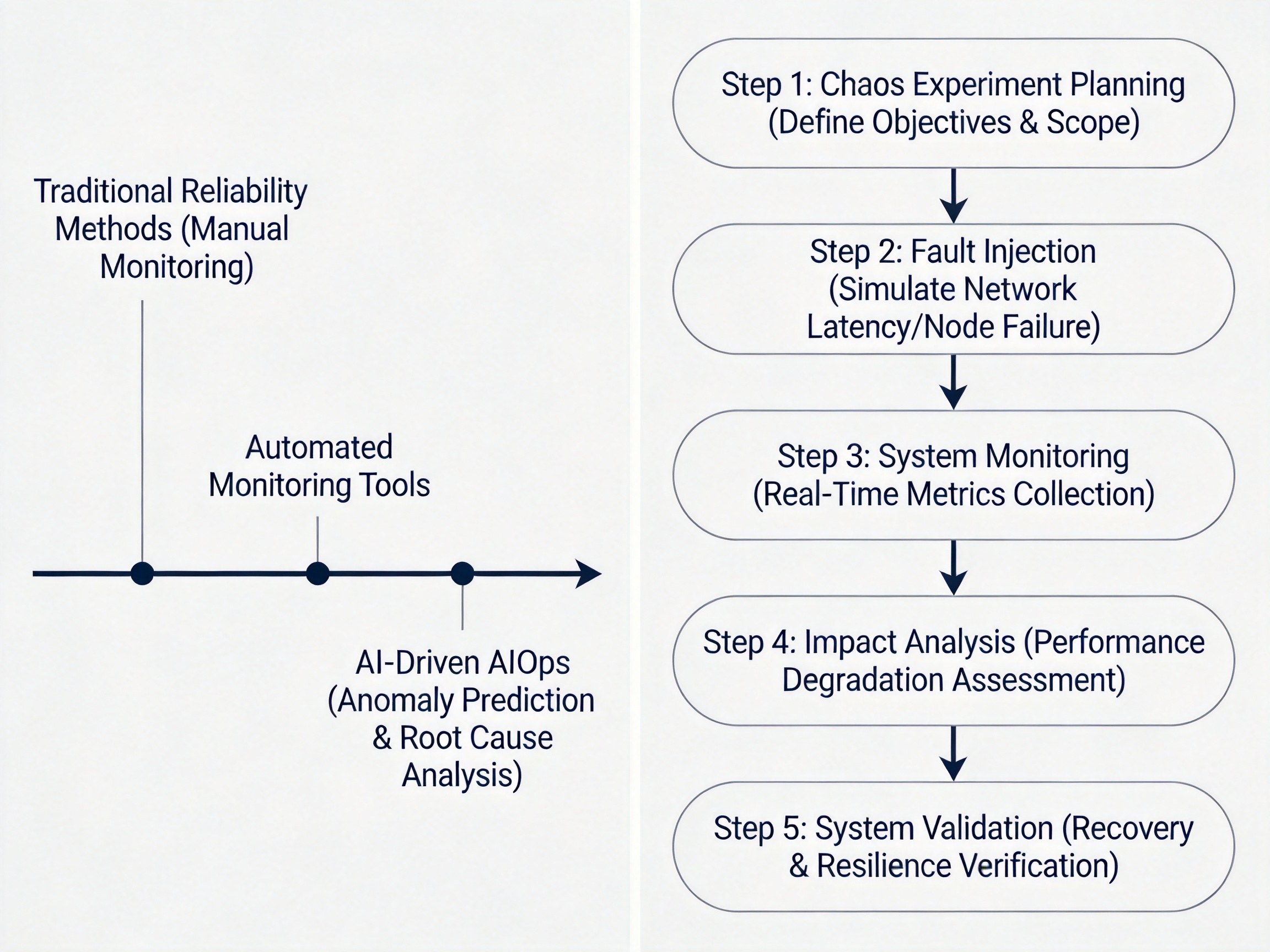 可靠性技术演进路线图、混沌工程实施流程示意图
可靠性技术演进路线图、混沌工程实施流程示意图
七、总结与建议
7.1 核心知识点提炼
可靠性关注系统无故障运行能力,核心指标是 MTTF;可用性关注系统服务可获取性,核心指标是 MTTF 和 MTTR 的比值;软硬件可靠性的本质差异是失效机理不同,硬件存在物理老化,软件缺陷是固有存在;高可用设计需要从基础设施、数据、应用、接入四个层面分层实施,兼顾可靠性、可维护性和成本的平衡。
7.2 软考考试重点提示
高频考点包括:可靠性与可用性的概念区分、MTTF/MTTR/MTBF 的计算、可用性等级对应的停机时间、软硬件可靠性的差异、高可用架构设计方法。易错点包括:混淆 MTBF 和 MTTF 的适用场景、忽略计划内停机对可用性的影响、错误使用可用性近似计算公式。案例分析题中通常会给出系统的 MTTF 和 MTTR 指标,要求计算可用性并提出优化方案;论文题中通常要求结合项目实践说明高可用系统的设计过程。
7.3 实践与备考建议
备考过程中需要重点掌握 GB/T 7826-2012、GB/T 14394-2008 等相关标准的核心内容,结合历年真题熟悉指标计算方法和架构设计思路;实践中需要根据业务场景合理制定可用性目标,避免盲目追求高指标,采用混沌工程等方法持续验证系统可靠性,平衡技术收益与成本投入。
 软考可靠性考点思维导图
软考可靠性考点思维导图