文章目录
- 前言
-
- [一、核心定位:数仓的 "黑匣子" 与 "隔离墙"](#一、核心定位:数仓的 “黑匣子” 与 “隔离墙”)
-
- [1. 它的三个核心身份](#1. 它的三个核心身份)
- [2. 惨痛教训(反面案例)](#2. 惨痛教训(反面案例))
- [二、ODS 层数据更新存储模式深度思考](#二、ODS 层数据更新存储模式深度思考)
-
- [1. 全量覆盖更新(无快照、无增量)](#1. 全量覆盖更新(无快照、无增量))
- [2. 适用业务场景(仅允许这 3 类)](#2. 适用业务场景(仅允许这 3 类))
- [3. 三种更新模式核心对比](#3. 三种更新模式核心对比)
- [4. 实战结论](#4. 实战结论)
- [三、核心难题:全量 vs 增量 ------ 如何平衡成本与效率?](#三、核心难题:全量 vs 增量 —— 如何平衡成本与效率?)
-
- [1. 全量快照(Full Snapshot):适合 "慢数据"](#1. 全量快照(Full Snapshot):适合 “慢数据”)
- [2. 增量流水(Incremental Stream):适合 "热数据"](#2. 增量流水(Incremental Stream):适合 “热数据”)
- [3. 最优落地策略:三级存储体系](#3. 最优落地策略:三级存储体系)
- [🔥 实战案例:某汽车集团降本实录](#🔥 实战案例:某汽车集团降本实录)
- [四、复杂环境落地:多系统 Schema 隔离与合规](#四、复杂环境落地:多系统 Schema 隔离与合规)
-
- [1. Schema 隔离策略:让数据井水不犯河水](#1. Schema 隔离策略:让数据井水不犯河水)
- [2. 命名规范:统一语言](#2. 命名规范:统一语言)
- [3. 合规红线(必做动作)](#3. 合规红线(必做动作))
- [五、结语:ODS 层是数仓的 "生命线"](#五、结语:ODS 层是数仓的 “生命线”)
- 一、为什么要把这三种策略单独拿出来讲?
- 二、最常见的三大误区(大多数的人都混淆了)
- 三、三种模式深度拆解(配实战案例)
-
- 1)全量更新(覆盖式,无历史)
- 2)全量快照(保留历史状态)
- [3)增量同步(CDC / 日志同步)](#3)增量同步(CDC / 日志同步))
- 四、决策矩阵:到底该怎么选?
-
- 1)全量快照:库存每日历史归档
- [2)全量更新:主数据 / 标准参考数据](#2)全量更新:主数据 / 标准参考数据)
- [3)增量同步:需追溯 / 审计的过程数据](#3)增量同步:需追溯 / 审计的过程数据)
- 六、总结与思考
-
- [1. 核心结论](#1. 核心结论)
- [2. 数仓底线](#2. 数仓底线)
- [3. 最终思考](#3. 最终思考)
前言
系列文章完整串联业务系统 + 数据集成 + 数据仓库 + BI 落地全链路。
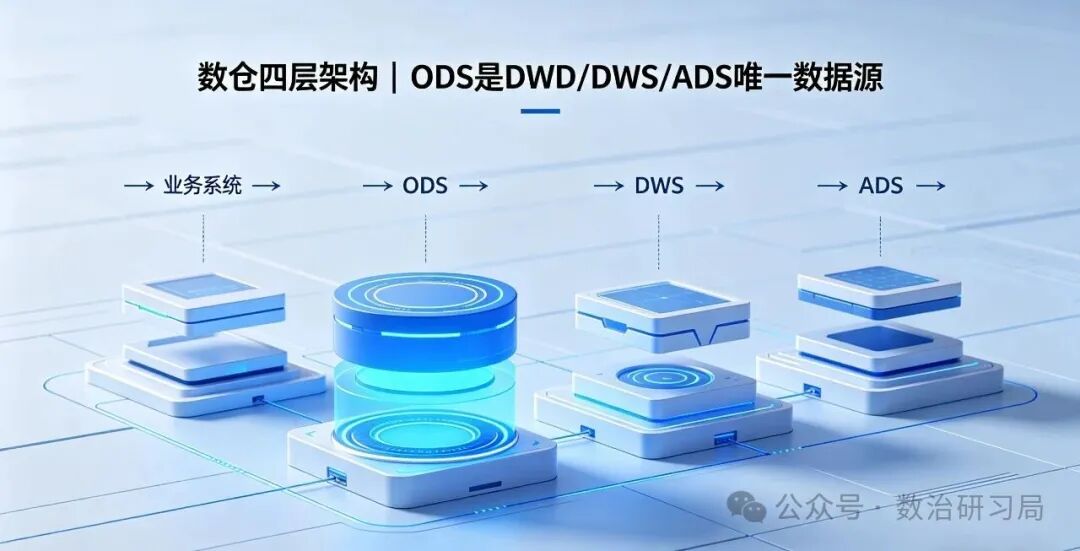
深度拆解企业标准四层数仓架构 :ODS 原始层→DW 明细层→DIM 维度层→DM 主题层,详解每层设计逻辑、字段规范、脱敏规则、落地开发要点,搭配汽车流通 / 航空制造 ERP/MOM 真实业务案例 ,讲透如何把杂乱的原始数据,沉淀为企业可复用、可对账、可赋能的标准数据资产。
ODS 原始数据层
ODS 是数仓地基,直接决定追溯能力与存储成本。ODS 是 "原材料仓库"
在数仓建设中,流传着一个 "恐怖的二八定律" :80% 的数据治理返工、200% 的存储成本超标、100% 的审计合规风险,根源都始于 ODS 层设计 的一念之差。
如果说数据仓库是整个 BI 系统的底座,那 ODS(Operational Data Store) 就是这座底座的基石。它是所有数据进入数仓的第一站,也是唯一能保留原始形态的 "黑匣子"。如果 ODS 层没建好,上层 DWD/DWS 做得再精美,也是建立在流沙之上的城堡 --- 数据不可溯、资产不可信、合规存隐患。
见过太多项目因 ODS 层 "偷懒" (只存增量不存快照)或 "任性" (所有表全量快照),导致后续数仓上层变成 "垃圾数据的加工流水线"。
直接拆解 ODS 层的核心定位、全量 / 增量的博弈策略、以及多系统合规落地的实操方案。
ODS 原始数据层 ------ 数仓底座的生存与发展策略
全量快照 vs 增量流水怎么选?
ODS建设标准及风险合规管理
全量更新适用场景分析
冷热分离如何把成本降低 80%?
一、核心定位:数仓的 "黑匣子" 与 "隔离墙"
在进入具体技术选型前,我们必须达成一个共识:ODS 层不是业务库的简单搬运工,而是数仓的 "守门员" 和 "资产的第一粒纽扣"。
1. 它的三个核心身份
-
数据的 "黑匣子"
:1:1 留存业务库原始状态,不增不减,不修不改。它是数据的 "出生证明",确保任何时候都能回溯源头。
-
业务的 "防护墙"
:所有数仓加工必须从 ODS 读取,严禁直连业务库。这道屏障能有效避免 BI 查询占用业务库 CPU/IO 资源,防止 ERP/MES 系统因分析压力而卡顿、瘫痪。
-
资产的 "暂存区"
:它是原始数据进入数仓的第一站,为上层 DWD/DWS 提供未经加工的 "原材料"。
2. 惨痛教训(反面案例)
-
汽车流通场景
:某集团未保留 ODS 原始快照,当财务月结数据与业务端数据出现差异时,双方互相甩锅。因无法回溯原始订单快照,最终无法定位问题,导致年度审计失败。
-
航空制造场景
:某航企因 ODS 未做合规脱敏,导致包含供应商银行账号的生产数据被非授权人员导出,面临合规罚款和行业信誉危机等。
-
二、ODS 层数据更新存储模式深度思考
在实际落地中,很多企业会使用 "全量覆盖更新"(不存快照、不记增量,每次直接覆盖),这种模式极易踩坑,必须单独拎清边界。
1. 全量覆盖更新(无快照、无增量)
-
核心逻辑
:每次同步直接覆盖上一次数据,不保留历史、不记录变更,只存当前最新状态。
-
优点
:存储成本极低、同步逻辑最简单、查询速度最快
-
缺点
:无历史回溯、不支持审计、数据覆盖无法找回
2. 适用业务场景(仅允许这 3 类)
-
临时统计、一次性报表、非核心辅助数据
-
无审计要求、无对账需求的内部参考数据
-
源头系统每日重置、本身不保留历史的数据
3. 三种更新模式核心对比

4. 实战结论
-
核心业务、审计数据、流水数据 严禁用全量覆盖
-
能用增量就不用全量快照,能用快照就不用全量覆盖
-
ODS 层的核心价值是可追溯,为了省成本放弃追溯,是本末倒置。
三、核心难题:全量 vs 增量 ------ 如何平衡成本与效率?
这是 ODS 层设计最纠结的问题。盲目全量导致存储爆炸,盲目增量导致无法溯源。
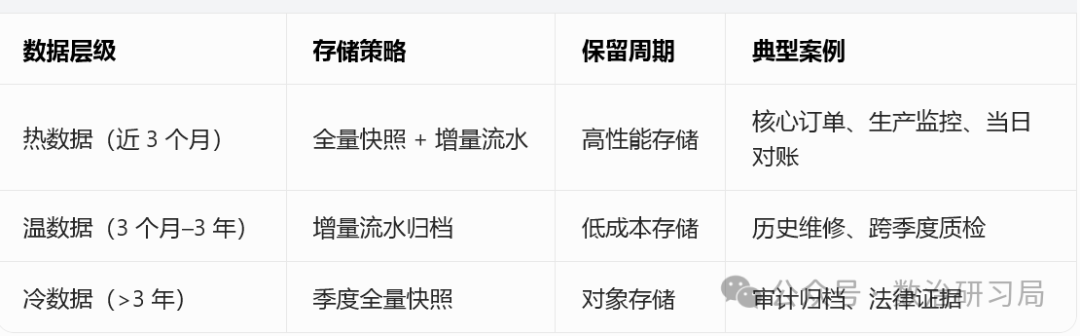
10 年实战总结:**没有单一的 "银弹" 策略,只有 "冷热分级" 的组合拳。**我们需要根据数据的访问频率和业务价值,来决定它的存储形态和保留周期。
1. 全量快照(Full Snapshot):适合 "慢数据"
-
适用:维度表、主数据(车型、门店、产线、零部件)
-
优势:查询快、支持任意时间点回溯
-
劣势:存储成本高、大表同步耗时长
2. 增量流水(Incremental Stream):适合 "热数据"
-
适用:海量流水表(订单、维修、生产工序、质检)
-
优势:省存储、同步快、适合高频变更
-
劣势:需拼接还原,开发稍复杂
3. 最优落地策略:三级存储体系
🔥 实战案例:某汽车集团降本实录
-
痛点
:所有表每日全量快照,月增 12TB,存储爆炸
-
优化
:维度表保留快照,流水表改为增量 + 冷热分级
-
结果
:存储成本 直降 85%,审计与合规完全达标
四、复杂环境落地:多系统 Schema 隔离与合规
企业里 ERP、MES、CRM、MOM 系统林立,字段乱、编码乱、权限乱。ODS 层必须做好 "物理隔离" 和 "规范管控",否则就是一锅粥。
1. Schema 隔离策略:让数据井水不犯河水
核心原则:一个系统一个 Schema,绝不混放
-
汽车流通
:ods_erp、ods_crm、ods_oam
-
航空制造
:ods_mes、ods_wms、ods_qms、ods_oa
2. 命名规范:统一语言
-
表名:系统缩写_业务域_表类型(如
ods_erp_sal_order) -
字段:保留原名字,仅统一格式(小写 + 下划线)
3. 合规红线(必做动作)
-
权限管控
:ODS 只读,禁止写入与越权访问
-
数据脱敏
:入口即脱敏(手机号、银行卡、供应商信息)
-
生命周期
:没有标准要求一般按企业需求(比如汽车流通 5 年,航空制造 10 年等)

五、结语:ODS 层是数仓的 "生命线"
ODS 层的建设,考验的不是代码能力,而是 架构思维、业务理解与合规意识。
记住这三条 "保命" 铁律:
- 只读不写
:ODS 是历史的见证者,不是参与者。严禁在 ODS 层做逻辑加工。
- 冷热分级
:不要用一种存储策略对抗所有数据,该省的省,该花的花。
- 合规先行
:Schema 隔离、脱敏、生命周期管理,是数仓工程师的职业底线。
只有筑牢了 ODS 这座基石,上层的 DWD 清洗、DWS 聚合才能如鱼得水,BI 报表才能成为企业唯一的真理之源。
ODS 原始数据层 ------ 决定数仓底层准确性的生死抉择

数仓 80% 的数据不准、对账失败、审计不过,根源都在这三种同步策略选错。这不仅是技术选型,更是对准确性、成本、合规三者平衡的生死博弈。
一、为什么要把这三种策略单独拿出来讲?
ODS 层是数仓的底座,同步策略一旦选错,底层数据直接报废,上层应用再华丽也是空中楼阁。
-
数据准确性之殇:全量覆盖会丢失历史版本,导致无法回溯;增量同步若不懂 CDC(变更数据捕获),只插不改不删,数据状态永远滞后。
-
业务影响之痛:库存、工单、财务数据一旦错漏,直接导致月底对账差异、生产追溯中断、合规审计不通过。
真实惨痛案例
-
案例 A:某汽车集团用 "全量更新" 同步每日库存,月底盘点发现库存对不上,因无历史记录,无法排查是系统 Bug 还是人为失误,损失惨重。
-
案例 B:某航空制造企业用 "全量快照" 同步高频工单,仅三个月存储爆盘,查询性能下降 50%。
-
案例 C:某企业用 "时间戳" 做增量同步,漏掉了同毫秒内的多次状态变更,导致生产追溯链条断裂。
这三种模式是 ODS 最容易踩坑、最影响数据质量、最关乎成本与合规的核心,必须独立讲透。
二、最常见的三大误区(大多数的人都混淆了)
**1. 把 "全量更新" 等同于 "全量快照"**以为都是 "全量同步",结果前者不存历史,审计直接挂;后者存历史,成本爆炸。
**2. 以为 "增量同步" 就是 "只同步新增"**不懂 CDC,只插不改不删。一旦源系统发生 Update/Delete,ODS 层数据就会与业务库彻底脱节。
**3. 所有表 "一刀切"**主数据、流水表、状态表全部用一种策略,要么成本炸裂,要么数据不可追溯。

三、三种模式深度拆解(配实战案例)
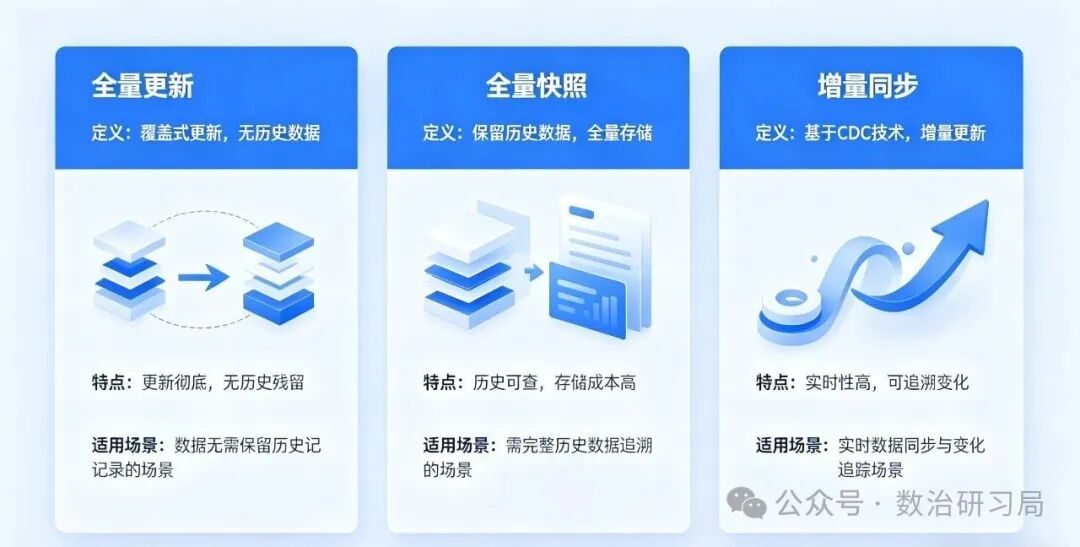
1)全量更新(覆盖式,无历史)
-
定义:每次同步直接覆盖旧数据,ODS 层只保留一份 "当前最新" 的数据快照。
-
特点:成本最低、实现最简单、无回溯能力。
-
适用场景:
-
主数据 / 维表:如汽车品牌基础信息、供应商表、门店配置表。
-
源头已管过程:源系统本身有完善的变更日志,ODS 只需保持最新状态一致。
-
避坑指南:严禁用于任何需要 "对账" 或 "审计" 的业务表。
2)全量快照(保留历史状态)
-
定义:按时间点(如每天 24 点)完整备份一份数据,形成 dt=20231001、dt=20231002 的分区。
-
特点:可审计、开发简单(直接查某天分区即可)、存储成本高(数据量是增量的 N 倍)。
-
适用场景:
-
状态余额类:每日库存余额、每日账户余额、每日门店业绩。
-
合规要求高:财务月结数据、资产盘点数据。
-
避坑指南:对于超大表(如亿级流水),慎用此法,否则存储成本会拖垮集群。
3)增量同步(CDC / 日志同步)
-
定义:只同步增、删、改操作,记录完整的变更链路。
-
特点:省存储、实时性高、可追溯,但技术门槛高(需依赖 Binlog/Kafka)。
-
关键技术区分:
-
基于时间戳:有坑!容易漏掉同毫秒的更新,且无法感知删除。
-
基于日志(CDC):推荐!如 Flink CDC、Canal,能捕获所有 Insert/Update/Delete 操作。
-
适用场景:
-
高频流水:生产工单、出入库记录、质检记录、销售流水。
-
需追溯过程:订单状态流转(创建 -> 支付 -> 发货)。
四、决策矩阵:到底该怎么选?
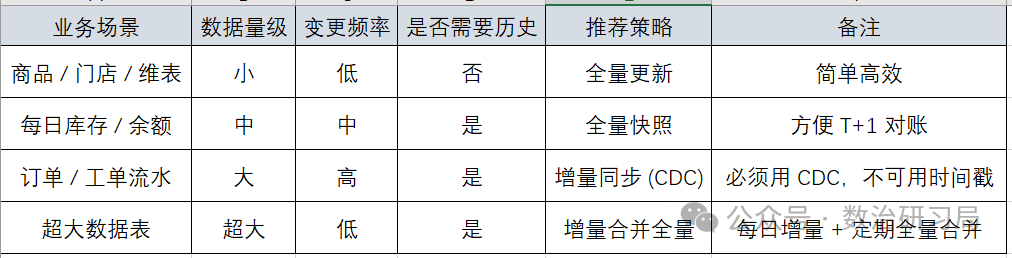
五、业务场景还原(落地思路直接用)
1)全量快照:库存每日历史归档
-
业务:需要每天库存余额,用于对账、复盘、审计。
-
离线思路:每日 24 点执行快照,归档当天全量库存到 dt=yyyy-MM-dd 分区。
-
实时思路:Flink 实时消费 Binlog 去重统计库存,24 点统一归档落地。
2)全量更新:主数据 / 标准参考数据
-
业务:车型、供应商、物料、组织架构等。
-
思路:有专门主数据平台管理过程,ODS 只需保持一致,不存历史、不做快照,每天凌晨覆盖即可。
3)增量同步:需追溯 / 审计的过程数据
-
业务:生产工单、材料出入库、质检记录、维修履历。
-
思路:用 CDC 工具(Flink CDC)抓取数据库 Binlog,增删改全同步到 ODS,保证完整可追溯。
-
注意:必须处理 "晚到数据" 和 "乱序数据",确保数据一致性。
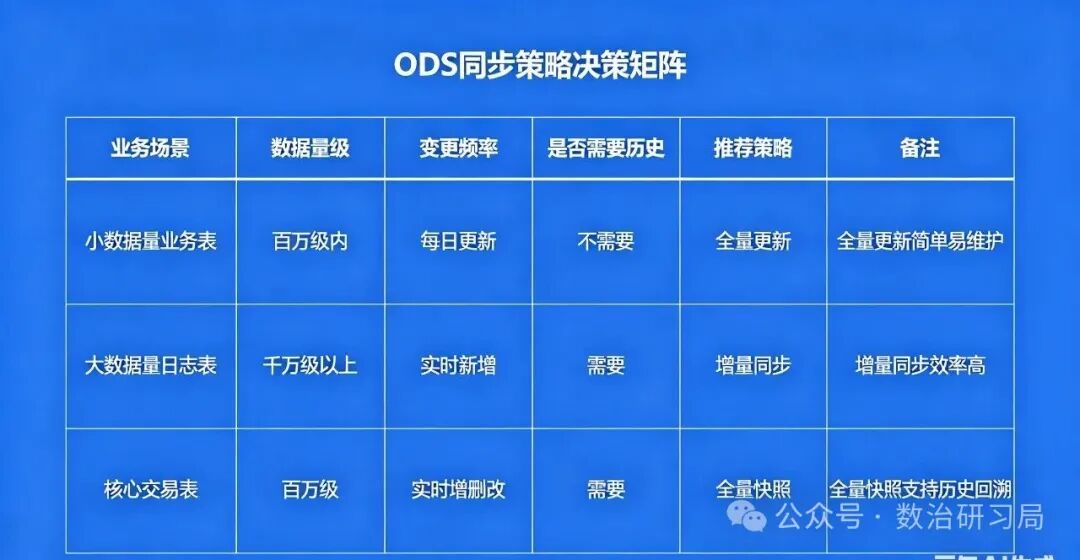
六、总结与思考
1. 核心结论
-
要历史可回溯、方便对账 → 全量快照
-
要过程可审计、实时性高 → 增量同步(CDC)
-
只要最新状态、无合规要求 → 全量更新
2. 数仓底线
-
核心业务数据严禁只用全量更新。
-
流水与过程数据优先增量 CDC,不要试图用时间戳 "碰运气"。
-
维度与主数据按需快照或覆盖,避免资源浪费。
3. 最终思考
ODS 层的选择,本质是准确性、成本、合规三者平衡。策略选对,数仓底座稳;策略选错,上层建设全部白费。不要为了省存储而牺牲数据可追溯性,也不要为了省事而盲目全量快照。

本文的引用仅限自我学习如有侵权,请联系作者删除。
参考知识
数仓实战第二篇:ODS 原始数据层 ------ 数仓底座的生存与发展策略