摘要
RADIO-ViPE 是一个面向动态环境的在线语义 SLAM 系统,能够将任意自然语言查询与三维场景中的局部区域和物体关联起来(开放词汇语义定位)。与现有方法依赖标定好的 RGB-D 输入不同,RADIO-ViPE 直接处理原始单目 RGB 视频流,不需要相机内参、深度传感器或位姿初始化。其核心创新在于:将来自 RADIO 聚合基础模型的多模态嵌入(视觉+语言)与几何场景信息在初始化、优化和因子图连接三个层面进行紧耦合融合,并通过时序一致的自适应鲁棒核处理动态物体干扰。在 TUM-RGBD 动态基准测试上取得了 1.63 cm 的平均 ATE,刷新了动态 SLAM 的 SOTA;在 Replica 数据集上的 3D 语义分割排名前三,且不依赖任何标定信息。
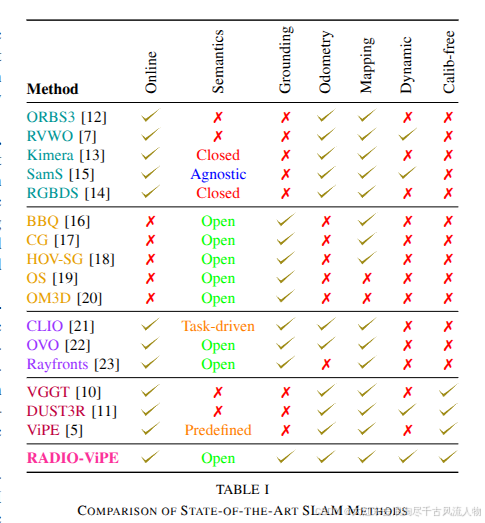
图 0:RADIO-ViPE 效果展示 -- 从未标定的单目 RGB 视频中,通过自然语言查询(如 "Locate Spoon")在 3D 语义地图中定位目标物体。来源:RADIO-ViPE Fig 1,仅供学习
一、问题背景:为什么现有语义 SLAM 不够用?
知识映射(Knowledge Mapping)-- 将自由形式的语言概念投射到三维几何表示上 -- 是通用机器人的基础能力。互联网规模的视频是天然的训练数据源,覆盖了多样的室内外场景、物体外观和人类活动。但这类数据天然无结构、未标定 ,缺乏现有三维场景理解方法所需的深度、位姿和语义标注。更关键的是,真实环境中存在大量动态干扰 -- 从行走的人到被搬动的家具 -- 会破坏数据关联并降低定位精度。
现有方法按四类划分,各有缺陷:
| 类别 | 代表方法 | 核心局限 |
|---|---|---|
| 几何 SLAM | ORB-SLAM3, RVWO | 无语义理解,无法处理开放词汇查询 |
| 离线开放词汇理解 | BBQ, ConceptGraphs, HOV-SG | 无在线里程计,假设静态场景,无法实时部署 |
| 实时开放词汇 SLAM | CLIO, OVO-SLAM, RayFronts | 无动态场景鲁棒性 |
| 前馈式 SLAM | VGGT, DUSt3R | 假设场景刚性,缺乏高层语义表示 |
RADIO-ViPE 是唯一同时具备全部七项能力的系统:在线运行、开放词汇语义、自由形式定位、里程计、建图、动态场景处理、免标定部署。
二、核心方法
2.1 系统整体架构(8 阶段流水线)
RADIO-ViPE 接受未标定的单目 RGB 视频流,在滑动窗口因子图优化框架内统一了光流位姿估计、基础模型单目深度、RADIO 多模态嵌入三条信号通路,整体运行在 8-10 FPS。
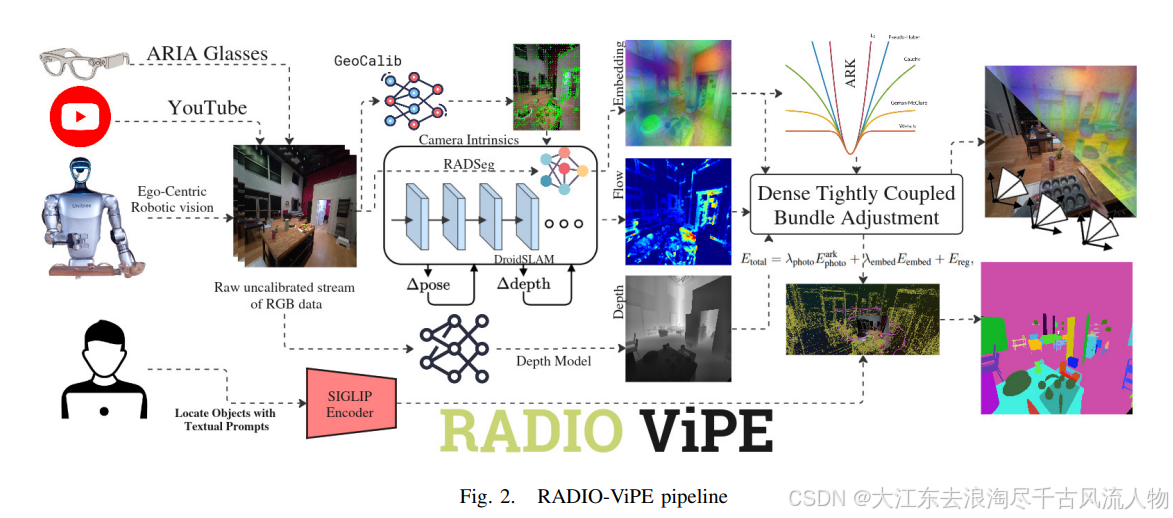
图 1:RADIO-ViPE 系统架构 -- 8 阶段流水线从原始单目 RGB 视频到开放词汇语义 3D 地图。重点关注 Bundle Adjustment 阶段的三项能量项紧耦合。重绘自 design skill
图 1b:论文原始流水线图 -- 展示从多种输入源到 Dense Tightly Coupled BA 再到语义定位的完整数据流。来源:RADIO-ViPE Fig 2,仅供学习
八个阶段:
- 相机初始化:用 GeoCalib 从均匀采样帧自举内参,无需标定板
- 关键帧选择 :加权稠密光流估计帧间相对运动,超过阈值的帧加入因子图 G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G=(V,E)
- 多模态特征提取 :RADSeg 提取稠密多模态嵌入,上采样到 ( H / 8 , W / 8 ) (H/8, W/8) (H/8,W/8),PCA 压缩到 D = 256 D=256 D=256 维
- 深度估计:基础深度模型生成逐关键帧度量深度,转为逆深度表示
- 语义光流初始化:语义相似度增强几何重投影先验
- Bundle Adjustment:联合优化位姿、视差和内参
- 非关键帧位姿估计:通过光度对齐恢复位姿
- 开放词汇定位:解码压缩后的 RADIO 特征到 SigLIP 潜空间,与文本查询匹配
#mermaid-svg-aR2rTDOQtdwsVJ2L{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-aR2rTDOQtdwsVJ2L .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-aR2rTDOQtdwsVJ2L .error-icon{fill:#552222;}#mermaid-svg-aR2rTDOQtdwsVJ2L .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-aR2rTDOQtdwsVJ2L .marker{fill:#333333;stroke:#333333;}#mermaid-svg-aR2rTDOQtdwsVJ2L .marker.cross{stroke:#333333;}#mermaid-svg-aR2rTDOQtdwsVJ2L svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-aR2rTDOQtdwsVJ2L p{margin:0;}#mermaid-svg-aR2rTDOQtdwsVJ2L .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-aR2rTDOQtdwsVJ2L .cluster-label text{fill:#333;}#mermaid-svg-aR2rTDOQtdwsVJ2L .cluster-label span{color:#333;}#mermaid-svg-aR2rTDOQtdwsVJ2L .cluster-label span p{background-color:transparent;}#mermaid-svg-aR2rTDOQtdwsVJ2L .label text,#mermaid-svg-aR2rTDOQtdwsVJ2L span{fill:#333;color:#333;}#mermaid-svg-aR2rTDOQtdwsVJ2L .node rect,#mermaid-svg-aR2rTDOQtdwsVJ2L .node circle,#mermaid-svg-aR2rTDOQtdwsVJ2L .node ellipse,#mermaid-svg-aR2rTDOQtdwsVJ2L .node polygon,#mermaid-svg-aR2rTDOQtdwsVJ2L .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-aR2rTDOQtdwsVJ2L .rough-node .label text,#mermaid-svg-aR2rTDOQtdwsVJ2L .node .label text,#mermaid-svg-aR2rTDOQtdwsVJ2L .image-shape .label,#mermaid-svg-aR2rTDOQtdwsVJ2L .icon-shape .label{text-anchor:middle;}#mermaid-svg-aR2rTDOQtdwsVJ2L .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-aR2rTDOQtdwsVJ2L .rough-node .label,#mermaid-svg-aR2rTDOQtdwsVJ2L .node .label,#mermaid-svg-aR2rTDOQtdwsVJ2L .image-shape .label,#mermaid-svg-aR2rTDOQtdwsVJ2L .icon-shape .label{text-align:center;}#mermaid-svg-aR2rTDOQtdwsVJ2L .node.clickable{cursor:pointer;}#mermaid-svg-aR2rTDOQtdwsVJ2L .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-aR2rTDOQtdwsVJ2L .arrowheadPath{fill:#333333;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-aR2rTDOQtdwsVJ2L .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-aR2rTDOQtdwsVJ2L .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-aR2rTDOQtdwsVJ2L .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-aR2rTDOQtdwsVJ2L .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-aR2rTDOQtdwsVJ2L .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-aR2rTDOQtdwsVJ2L .cluster text{fill:#333;}#mermaid-svg-aR2rTDOQtdwsVJ2L .cluster span{color:#333;}#mermaid-svg-aR2rTDOQtdwsVJ2L div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-aR2rTDOQtdwsVJ2L .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-aR2rTDOQtdwsVJ2L rect.text{fill:none;stroke-width:0;}#mermaid-svg-aR2rTDOQtdwsVJ2L .icon-shape,#mermaid-svg-aR2rTDOQtdwsVJ2L .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-aR2rTDOQtdwsVJ2L .icon-shape p,#mermaid-svg-aR2rTDOQtdwsVJ2L .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-aR2rTDOQtdwsVJ2L .icon-shape .label rect,#mermaid-svg-aR2rTDOQtdwsVJ2L .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-aR2rTDOQtdwsVJ2L .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-aR2rTDOQtdwsVJ2L .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-aR2rTDOQtdwsVJ2L :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} Raw RGB Video
GeoCalib
Camera Init
Keyframe
Selection
RADSeg
Feature Extraction
Depth
Estimation
Semantic Flow
Initialization
Dense BA
VLG Fusion
Non-KF
Pose Est.
Open-Vocab
Grounding
SigLIP: 'Locate Spoon'
2.2 视觉-语言-几何联合 Bundle Adjustment
这是系统最核心的创新。BA 的总目标函数由三项组成:
E total = γ photo E photo ark + γ embed E embed + E reg E_{\text{total}} = \gamma_{\text{photo}} E_{\text{photo}}^{\text{ark}} + \gamma_{\text{embed}} E_{\text{embed}} + E_{\text{reg}} Etotal=γphotoEphotoark+γembedEembed+Ereg
联合优化相机位姿 { T i } \{\mathbf{T}_i\} {Ti}、视差图 { d i } \{\mathbf{d}_i\} {di} 和内参 { K q } \{\mathbf{K}_q\} {Kq},其中 T i ∈ S E ( 3 ) \mathbf{T}_i \in SE(3) Ti∈SE(3), K q = f x , f y , c x , c y ⊤ \mathbf{K}_q = f_x, f_y, c_x, c_y^\top Kq=fx,fy,cx,cy⊤。
(1) 稠密光度光流项 E photo E_{\text{photo}} Ephoto
沿用 DROID-SLAM 的光度一致性约束。对因子图中每条边 ( i , j ) (i,j) (i,j),像素 u \mathbf{u} u 投影到帧 j j j:
μ i j = Π q ( T j T i − 1 ∘ Π q − 1 ( u , d i ( u ) ) ) \mu_{ij} = \Pi_q\!\left(\mathbf{T}_j \mathbf{T}_i^{-1} \circ \Pi_q^{-1}(\mathbf{u}, d_i(\mathbf{u}))\right) μij=Πq(TjTi−1∘Πq−1(u,di(u)))
光流网络预测残差稠密流场 Ω i j \Omega_{ij} Ωij 及逐像素置信权重 w ( u ) w(\mathbf{u}) w(u),光度项为:
E photo = ∑ u w ( u ) ⋅ ∥ Ω i j prior − Ω i j ( u ) ∥ 2 E_{\text{photo}} = \sum_{\mathbf{u}} w(\mathbf{u}) \cdot \left\|\Omega_{ij}^{\text{prior}} - \Omega_{ij}(\mathbf{u})\right\|^2 Ephoto=u∑w(u)⋅ Ωijprior−Ωij(u) 2
(2) RADIO 嵌入相似性项 E embed E_{\text{embed}} Eembed(核心创新)
将语义一致性引入优化,强制几何约束下的跨视角特征对齐。对每条边 ( i , j ) (i,j) (i,j),源像素 u \mathbf{u} u 投影到目标帧找到对应像素 v = P i , j ( u ) \mathbf{v} = P_{i,j}(\mathbf{u}) v=Pi,j(u),通过双线性插值获取目标嵌入:
Z ^ j ( P i , j ( u ) ) = ∑ ( l , m ) ∈ N ( P i , j ( u ) ) w l m ( P i , j ( u ) ) ⋅ Z l m j \hat{\mathbf{Z}}j(P{i,j}(\mathbf{u})) = \sum_{(l,m) \in \mathcal{N}(P_{i,j}(\mathbf{u}))} w_{lm}(P_{i,j}(\mathbf{u})) \cdot \mathbf{Z}^j_{lm} Z^j(Pi,j(u))=(l,m)∈N(Pi,j(u))∑wlm(Pi,j(u))⋅Zlmj
计算 ℓ 2 \ell_2 ℓ2 归一化后的余弦相似度:
c s i j ( u ) = Z i ( u ) ⊤ Z ^ j ( P i , j ( u ) ) ∥ Z i ( u ) ∥ ⋅ ∥ Z ^ j ( P i , j ( u ) ) ∥ cs_{ij}(\mathbf{u}) = \frac{\mathbf{Z}_i(\mathbf{u})^\top \hat{\mathbf{Z}}j(P{i,j}(\mathbf{u}))}{\|\mathbf{Z}_i(\mathbf{u})\| \cdot \|\hat{\mathbf{Z}}j(P{i,j}(\mathbf{u}))\|} csij(u)=∥Zi(u)∥⋅∥Z^j(Pi,j(u))∥Zi(u)⊤Z^j(Pi,j(u))
嵌入残差转换为光度量级的形式:
r embed ( u ) = λ embed 2 ( 1 − c s i j ( u ) ) r_{\text{embed}}(\mathbf{u}) = \lambda_{\text{embed}} \sqrt{2\bigl(1 - cs_{ij}(\mathbf{u})\bigr)} rembed(u)=λembed2(1−csij(u))
其中 λ embed = 2 \lambda_{\text{embed}} = 2 λembed=2,使嵌入残差与经典光度 SLAM 的强度差异量级可比。完整嵌入项:
E embed = ∑ u w ( u ) ⋅ r embed 2 ( u ) E_{\text{embed}} = \sum_{\mathbf{u}} w(\mathbf{u}) \cdot r_{\text{embed}}^2(\mathbf{u}) Eembed=u∑w(u)⋅rembed2(u)
(3) 视差正则化项 E reg E_{\text{reg}} Ereg
E reg ( d i ) = α disp ∑ u ∥ d i ( u ) − d i prior ( u ) ∥ 2 E_{\text{reg}}(\mathbf{d}i) = \alpha{\text{disp}} \sum_{\mathbf{u}} \|d_i(\mathbf{u}) - \mathbf{d}_i^{\text{prior}}(\mathbf{u})\|^2 Ereg(di)=αdispu∑∥di(u)−diprior(u)∥2
约束优化后的视差不偏离基础深度模型先验太远(实验中 α disp = 1.0 \alpha_{\text{disp}} = 1.0 αdisp=1.0),防止漂移同时允许多视图一致性修正。
2.3 时序一致的自适应鲁棒核(Temporally Consistent ARK)
这是第二个核心创新:仅靠单条边的嵌入余弦相似度无法区分静态表面、可移动物体和主动运动体。需要跨多条边的时序聚合。
时序稳定性场
对关键帧 i i i 的每个像素 u \mathbf{u} u,利用所有连接边 N ( i ) \mathcal{N}(i) N(i) 计算余弦相似度的均值和方差:
c s ˉ i ( u ) = 1 ∣ N ( i ) ∣ ∑ j ∈ N ( i ) c s i j ( u ) \bar{cs}i(\mathbf{u}) = \frac{1}{|\mathcal{N}(i)|} \sum{j \in \mathcal{N}(i)} cs_{ij}(\mathbf{u}) csˉi(u)=∣N(i)∣1j∈N(i)∑csij(u)
σ i 2 ( u ) = 1 ∣ N ( i ) ∣ ∑ j ∈ N ( i ) ( c s i j ( u ) − c s ˉ i ( u ) ) 2 \sigma_i^2(\mathbf{u}) = \frac{1}{|\mathcal{N}(i)|} \sum_{j \in \mathcal{N}(i)} \bigl(cs_{ij}(\mathbf{u}) - \bar{cs}_i(\mathbf{u})\bigr)^2 σi2(u)=∣N(i)∣1j∈N(i)∑(csij(u)−csˉi(u))2
时序稳定性场定义为:
S i ( u ) = c s ˉ i ( u ) ⋅ ( 1 − σ i 2 ( u ) ) ∈ 0 , 1 \mathcal{S}_i(\mathbf{u}) = \bar{cs}_i(\mathbf{u}) \cdot \bigl(1 - \sigma_i^2(\mathbf{u})\bigr) \in 0, 1 Si(u)=csˉi(u)⋅(1−σi2(u))∈0,1
S i ( u ) ≈ 1 \mathcal{S}_i(\mathbf{u}) \approx 1 Si(u)≈1 表示静态表面(高均值、低方差); S i ( u ) ≈ 0 \mathcal{S}_i(\mathbf{u}) \approx 0 Si(u)≈0 表示动态物体或被移动的物体(低均值或高方差)。
三段式 Barron 损失映射
将 S i ( u ) \mathcal{S}i(\mathbf{u}) Si(u) 映射到 Barron 通用损失 ρ α \rho\alpha ρα 的形状参数 α \alpha α,用可微分段线性映射:
α i ( u ) = { 2 , S i ( u ) ≥ θ s 1 + S i ( u ) − θ m θ s − θ m , θ m ≤ S i ( u ) < θ s α dyn + S i ( u ) θ m ( 1 − α dyn ) , S i ( u ) < θ m \alpha_i(\mathbf{u}) = \begin{cases} 2, & \mathcal{S}_i(\mathbf{u}) \ge \theta_s \\ 1 + \dfrac{\mathcal{S}_i(\mathbf{u}) - \theta_m}{\theta_s - \theta_m}, & \theta_m \le \mathcal{S}i(\mathbf{u}) < \theta_s \\ \alpha{\text{dyn}} + \dfrac{\mathcal{S}i(\mathbf{u})}{\theta_m}\bigl(1 - \alpha{\text{dyn}}\bigr), & \mathcal{S}_i(\mathbf{u}) < \theta_m \end{cases} αi(u)=⎩ ⎨ ⎧2,1+θs−θmSi(u)−θm,αdyn+θmSi(u)(1−αdyn),Si(u)≥θsθm≤Si(u)<θsSi(u)<θm
其中 α dyn ≤ 0 \alpha_{\text{dyn}} \le 0 αdyn≤0, θ s = 0.75 \theta_s = 0.75 θs=0.75, θ m = 0.35 \theta_m = 0.35 θm=0.35。
| 稳定性 | α \alpha α | 对应损失 | 语义含义 |
|---|---|---|---|
| S ≥ 0.75 \mathcal{S} \ge 0.75 S≥0.75 | α = 2 \alpha = 2 α=2 | ℓ 2 \ell_2 ℓ2 | 静态表面,全信任 |
| 0.35 ≤ S < 0.75 0.35 \le \mathcal{S} < 0.75 0.35≤S<0.75 | 1 < α < 2 1 < \alpha < 2 1<α<2 | Huber 区 | 可移动物体,部分降权 |
| S < 0.35 \mathcal{S} < 0.35 S<0.35 | α ≤ 0 \alpha \le 0 α≤0 | Cauchy 区 | 主动运动体,强抑制 |
图 2:自适应鲁棒核机制 -- 时序稳定性场 S \mathcal{S} S 驱动 Barron 损失形状参数 α \alpha α 的选择,实现静态/可移动/动态三类像素的差异化处理。重绘自 design skill
图 2b:论文原始 ARK 可视化 -- 左侧为 RADSeg 语义分割与余弦相似度热图,右侧为 Barron 通用损失在不同 α \alpha α 取值下的函数曲线。来源:RADIO-ViPE Fig 3,仅供学习
2.4 语义光流初始化与开放词汇定位
语义光流初始化 :在无纹理区域,纯光度重投影先验不可靠。RADIO-ViPE 用 PCA 压缩的 RADIO 嵌入计算像素间语义相似度场 Ω sem ( u ) \Omega^{\text{sem}}(\mathbf{u}) Ωsem(u),与光度先验混合:
Ω prior ( u ) : = β Ω ˉ prior ( u ) + ( 1 − β ) Ω sem ( u ) \Omega^{\text{prior}}(\mathbf{u}) := \beta \, \bar{\Omega}^{\text{prior}}(\mathbf{u}) + (1 - \beta) \, \Omega^{\text{sem}}(\mathbf{u}) Ωprior(u):=βΩˉprior(u)+(1−β)Ωsem(u)
β \beta β 基于光流网络的光度置信度峰值动态调整。
嵌入共可见性连接 :因子图的连通性不仅基于几何邻近,还通过嵌入共可见性增强 -- 对每个关键帧均值池化 RADSeg 嵌入得到全局描述子, ℓ 2 \ell_2 ℓ2 归一化后与非相邻关键帧做余弦相似度匹配,超过阈值 η \eta η 的帧对加入双向边。
开放词汇定位:通过将压缩的 RADIO 特征解码并投影到 SigLIP 潜空间,与任意文本查询进行匹配,实现实时 3D 语义查询。
三、关键设计分析
3.1 为什么选择 RADIO + RADSeg?
RADIO 是聚合基础模型(Agglomerative Foundation Model),通过多教师蒸馏在单一学生模型中保留了多个教师的能力。RADSeg 进一步将其扩展为稠密分割模型。关键优势:
- 嵌入同时包含视觉和语言对齐信息,可直接用于开放词汇查询
- 在编码器特征空间(非语言对齐空间)做 PCA 降维到 256 维,保留空间判别力的同时大幅降低内存( Δ \Delta ΔmIoU < 1%)
- 滑动窗口推理 + 自注意力精化,覆盖重叠区域,保证空间一致性
3.2 为什么嵌入残差要转换为光度量级?
公式 r embed = λ embed 2 ( 1 − c s ) r_{\text{embed}} = \lambda_{\text{embed}} \sqrt{2(1 - cs)} rembed=λembed2(1−cs) 将余弦相似度差异转换为与光度残差量级可比的形式( λ embed = 2 \lambda_{\text{embed}} = 2 λembed=2)。这样在联合 BA 中两项可以用统一的权重框架处理,避免量纲不匹配导致优化被某一项主导。
3.3 时序稳定性场 vs 单帧动态检测
单帧方法(如基于语义分割的动态物体掩码)只能检测预定义类别的运动体。时序稳定性场 S \mathcal{S} S 通过多帧余弦相似度的统计特性,能同时检测:
- 主动运动体(如行走的人)-- 低均值
- 被移动的物体(如被搬动的椅子)-- 高方差
- 无需预定义任何物体类别
四、实验分析
4.1 动态 SLAM 精度(TUM-RGBD)
| 方法 | fr3/w/xyz | fr3/w/rpy | fr3/w/half | fr3/w/static | fr3/s/xyz | fr3/s/rpy | fr3/s/half | fr3/s/static | 平均 ATE (cm) |
|---|---|---|---|---|---|---|---|---|---|
| Dyna-SLAM | 1.64 | 3.54 | 2.96 | 0.68 | 1.27 | - | 1.86 | - | 2.00 |
| DLD-SLAM | 1.85 | 4.24 | 2.19 | 0.56 | - | - | - | - | 2.21 |
| V3D-SLAM | 1.53 | 7.81 | 2.29 | 0.65 | 0.87 | 1.69 | 1.47 | 0.58 | 2.10 |
| DynaMON | 1.4 | 3.9 | 2.0 | 1.4 | 0.9 | 2.1 | 1.9 | 0.5 | 1.76 |
| ViPE (SAM) | 2.4 | 3.46 | 2.52 | 0.54 | 1.43 | 3.80 | 2.57 | 0.6 | 2.17 |
| RADIO-ViPE | 1.55 | 3.39 | 1.96 | 0.50 | 0.98 | 2.65 | 1.44 | 0.56 | 1.63 |
RADIO-ViPE ark _{\text{ark}} ark(含自适应鲁棒核)取得 1.63 cm 平均 ATE,超越此前最优的 DynaMON (1.76 cm)。值得注意的是,ViPE (SAM) 依赖 Grounding DINO + SAM 做动态掩码,而 RADIO-ViPE 仅通过嵌入统计就实现了更好的鲁棒性。
4.2 3D 语义分割(Replica)
| 方法 | 无背景 mIoU | 无背景 f-mIoU | 无背景 Acc | 有背景 mIoU | 在线 | 免标定 | 免深度 | 免位姿 |
|---|---|---|---|---|---|---|---|---|
| RayFronts | 39.37 | 62.03 | 68.80 | 27.73 | Yes | No | No | No |
| RADIO-ViPE GT _{\text{GT}} GT | 29.51 | 52.24 | 59.80 | 28.19 | Yes | No | No | No |
| RADIO-ViPE | 24.25 | 50.63 | 59.25 | 19.00 | Yes | Yes | Yes | Yes |
RADIO-ViPE 在不依赖任何标定、深度或位姿先验的条件下,排名前三。与 RADIO-ViPE GT _{\text{GT}} GT(使用真值标定)的差距仅约 1-2% mIoU,证明免标定管线的代价很小。
4.3 PCA 维度消融
PCA 压缩维度从完整维度到 32 维的消融实验表明, D = 256 D=256 D=256 在 mIoU 和 Accuracy 上与完整维度基线差距小于 1%,是效率与精度的最佳平衡点。 D = 128 D=128 D=128 开始出现明显下降, D = 32 D=32 D=32 则严重退化。
图 3:PCA 特征维度消融实验 -- Replica 数据集上不同 PCA 压缩维度的 mIoU 和 Accuracy 雷达图。 D = 256 D=256 D=256(红色实线)几乎与全维度基线重合。来源:RADIO-ViPE Fig 4,仅供学习
图 4:Replica 数据集定性结果 -- 使用不同自然语言查询(Table、Pillow、Shelf、Cabinet)在 3D 场景中的语义定位效果,绿框为系统定位结果。来源:RADIO-ViPE Fig 5,仅供学习
小结
三个核心贡献的工程价值:
-
VLG 紧耦合 BA -- 将多模态嵌入直接嵌入稠密 BA 的能量函数,而非后处理式拼接。这是与 CLIO、OVO-SLAM 等方法的本质区别。嵌入残差的光度量级转换( λ embed = 2 \lambda_{\text{embed}} = 2 λembed=2)是让联合优化收敛的关键工程细节。
-
时序自适应鲁棒核 -- 通过多帧嵌入统计构建时序稳定性场,驱动 Barron 通用损失的形状参数自适应切换。无需语义分割预定义类别即可处理动态场景,这比 ViPE + SAM 的方案更优雅也更有效。
-
免标定部署 -- GeoCalib 自举内参 + BA 内联合优化,使得系统可以直接处理互联网视频或未标定的机器人视频流。从 Replica 实验看,免标定带来的精度损失仅 1-2%,部署便利性的提升远超这点代价。
局限性:有背景类别(墙壁、地板等结构化类别)的分割精度下降明显,这是当前系统依赖视觉相似度而非几何先验进行类别区分的固有弱点。运行速度 8-10 FPS 对于需要高帧率的机器人应用仍有提升空间。
个人判断:RADIO-ViPE 的核心洞察 -- "多模态嵌入不应是 SLAM 的后处理装饰,而应深度参与几何优化本身" -- 代表了语义 SLAM 的正确发展方向。时序稳定性场的设计简洁而有效,比基于检测或分割的动态处理方案更具泛化潜力。