写在前面
你好,我是 Evan。一名正在摸爬滚打的 Java 后端开发者,也是这个专栏的作者。
在智答 Agent 项目中,我踩过最大的坑不是模型选错、不是 Prompt 调不好,而是架构没有为 AI 预留扩展点 。最初我们直接硬编码调用 OpenAI 的 API,后来要切换成通义千问、DeepSeek,甚至要同时支持流式和非流式输出,还要统计每个用户的 Token 消费、缓存常见问题、支持异步回调......每一次变更都像在重构。
痛定思痛,我设计了一套"AI 能力底座"------将大模型相关的能力抽象成可插拔的扩展点。今天我就把这套设计思路分享出来,从缓存策略、流式响应、Token 计费到回调机制,手把手教你如何让后端优雅地拥抱 AI,而不是被 AI 拖着走。
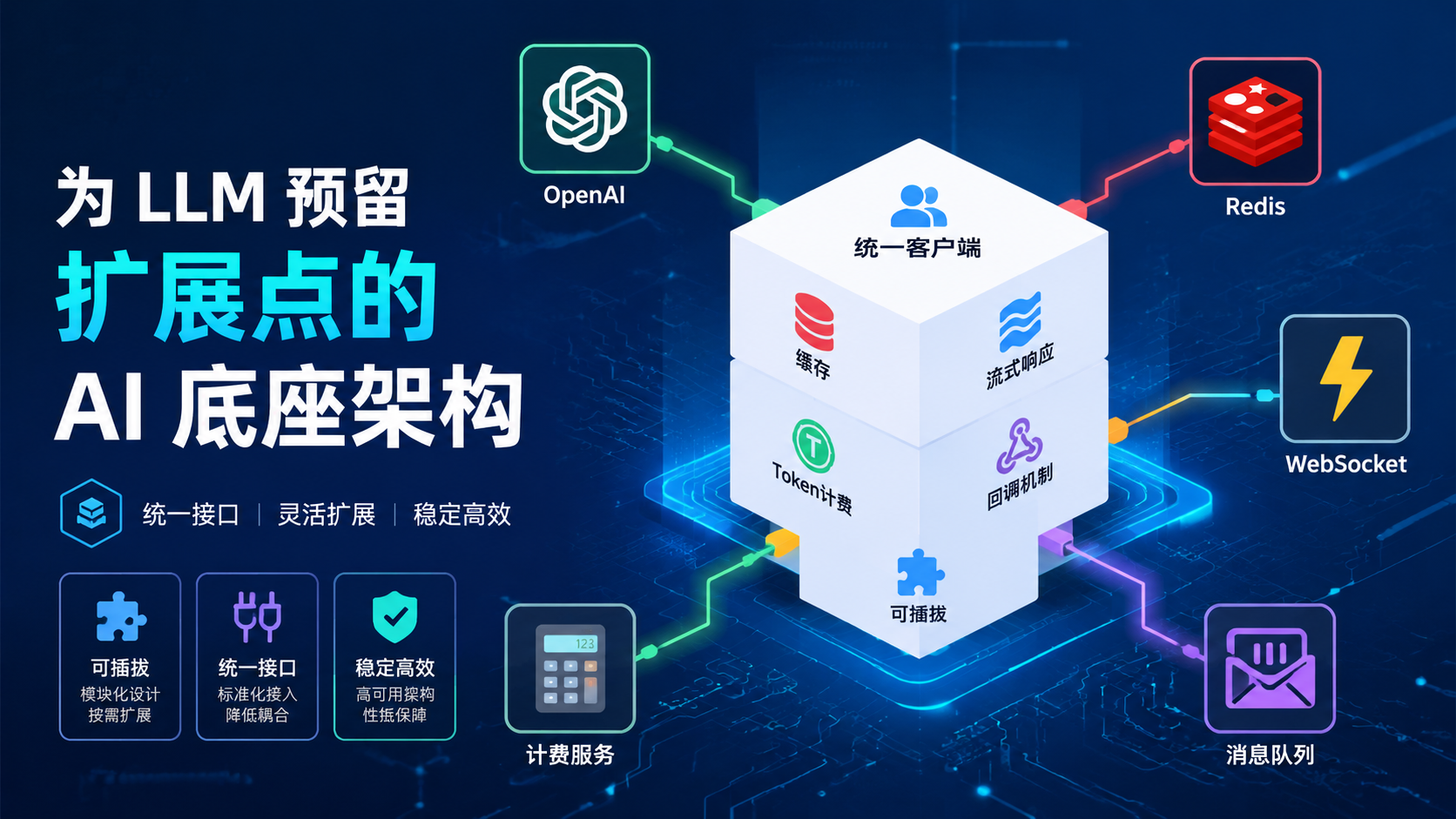
一、为什么你的后端需要"AI 扩展点"?
传统后端调用 AI 模型,通常就是一个 HTTP 请求 + JSON 解析。但当你真正把 AI 能力落地到生产时,会发现远远不够:
-
模型随时可能切换:从 OpenAI 到国产模型,甚至自建私有模型。
-
输出方式多样:流式响应 vs 阻塞式响应,前端体验天差地别。
-
成本需要控制:Token 计费、缓存高频问题、限制恶意刷接口。
-
异步场景复杂:AI 生成长文可能耗时几十秒,不能让 HTTP 连接一直等着。
如果你的代码把模型调用、缓存、计费等逻辑全部耦合在一起,任何一处变动都会牵一发而动全身。"AI 优先的架构" 核心思想就是:把 AI 能力抽象成一个个可插拔的组件,通过配置或依赖注入灵活组合。
下面这张图展示了整体架构:
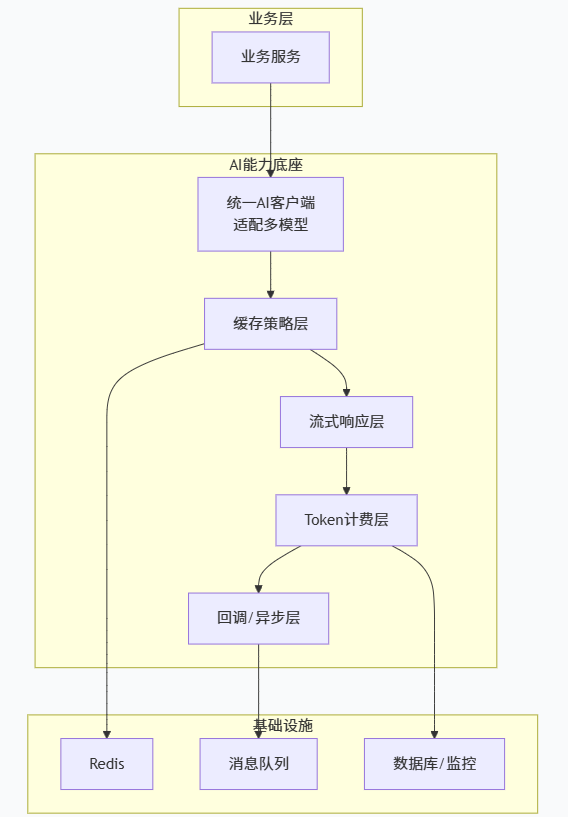
接下来我们逐个拆解这些扩展点。
二、扩展点一:统一 AI 客户端 ------ 让模型切换无痛
最基础也最重要的扩展点是抽象出统一的 AI 客户端接口。无论底层是 OpenAI、通义千问、DeepSeek 还是本地部署的 Llama,上层业务代码只依赖接口。
java
public interface AiClient {
// 阻塞式调用
String chat(String prompt, List<Message> history);
// 流式调用
void chatStream(String prompt, List<Message> history, StreamCallback callback);
// 获取模型信息(用于计费)
ModelInfo getModelInfo();
}通过 Spring 的 @ConditionalOnProperty,可以根据配置文件动态注入不同的实现:
javascript
ai:
provider: deepseek # 或 openai, qwen, mock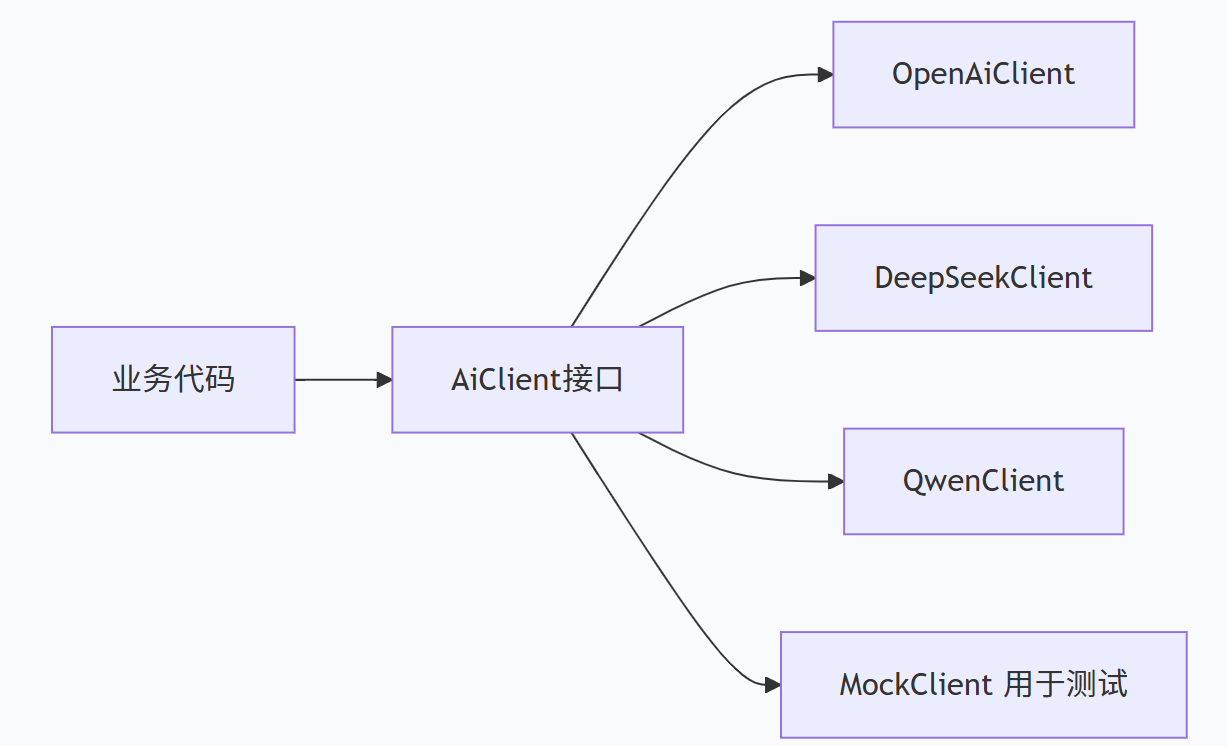
这样做的好处是:
-
切换模型只需要改配置文件,无需修改业务代码。
-
新模型接入只需新增一个实现类。
-
单元测试时可以用 MockClient 完全脱离真实 API。
三、扩展点二:缓存策略 ------ 省钱又提速
大模型调用昂贵且缓慢,对于重复或相似的问题,缓存能极大降低成本。但传统精确匹配(key = 完整 prompt)太死板,我们需要语义缓存:意思相近的问题命中同一缓存。

在 Java 中可以用 Redis 配合 RediSearch 模块或 pgvector 来实现。一个简单但有效的缓存键设计:
java
public class CacheKey {
private String prompt;
private String modelName; // 不同模型答案不同
private Double temperature; // 参数影响输出
// 甚至可以包含历史对话的哈希
}扩展点设计 :定义 CacheStrategy 接口,允许切换不同实现(无缓存、精确缓存、语义缓存)。
java
public interface CacheStrategy {
Optional<String> get(String prompt, AiContext ctx);
void put(String prompt, String answer, AiContext ctx);
}四、扩展点三:流式响应 ------ 让用户不再干等
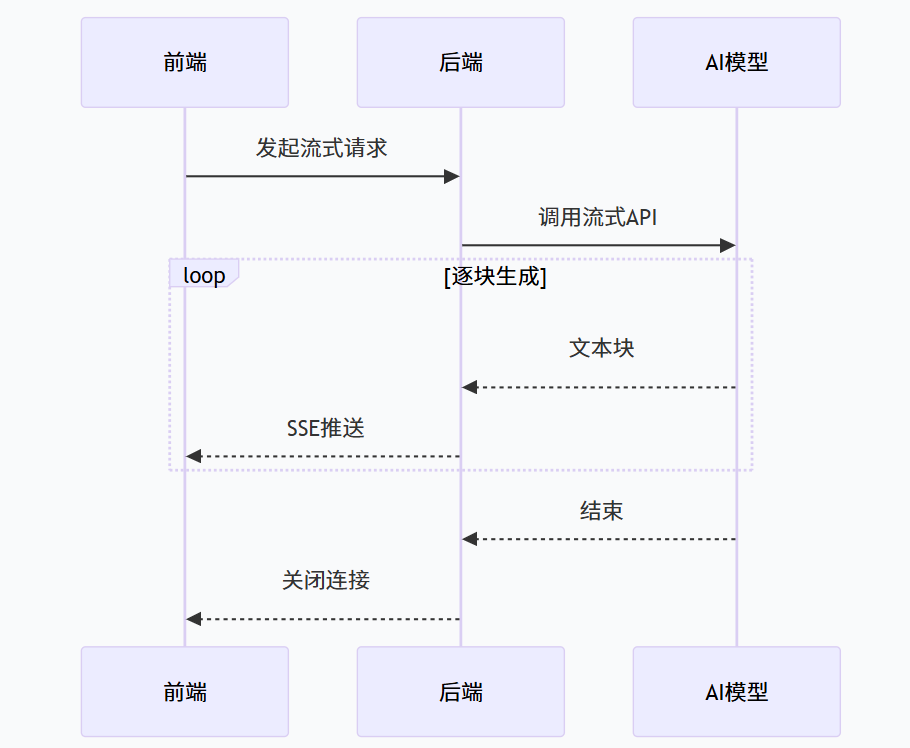
AI 生成内容通常需要几秒甚至几十秒。阻塞式接口会让用户体验极差,而流式响应(SSE 或 WebSocket)能逐字输出,大幅提升感知速度。
技术选型 :推荐使用 SSE(Server-Sent Events),它基于 HTTP,实现简单,自动重连,非常适合单向流式输出。
java
@GetMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter streamChat(String prompt) {
SseEmitter emitter = new SseEmitter(30000L);
aiClient.chatStream(prompt, history, chunk -> {
emitter.send(chunk);
});
emitter.onCompletion(() -> log.info("Stream finished"));
return emitter;
}扩展点设计 :AiClient 的 chatStream 方法就是一个天然的扩展点。不同的模型底层实现流式的方式不同(OpenAI 用 Server-Sent Events,通义用 WebSocket),但上层业务只看到回调。
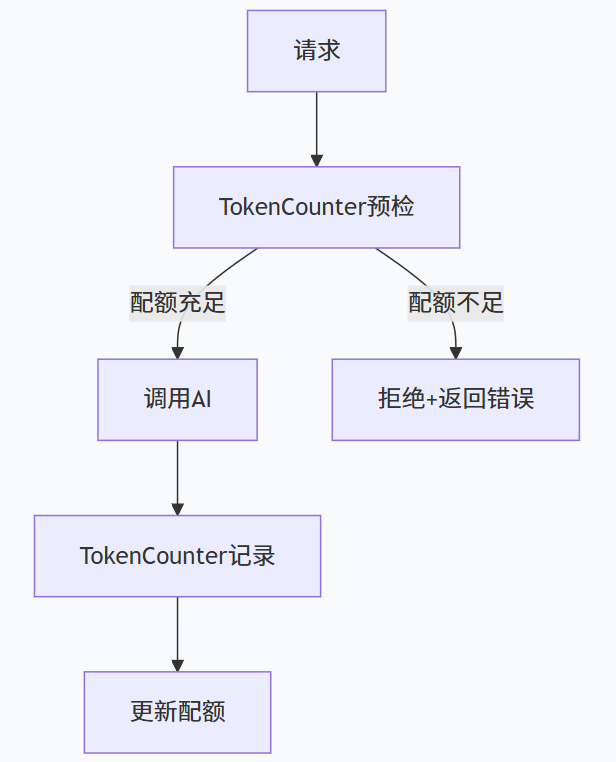
五、扩展点四:Token 计费 ------ 成本可观测、可限制
Token 是调用大模型的计价单位。没有计费模块,你既不知道每个用户花了多少钱,也无法防止恶意刷接口。
核心设计:在调用 AI 之前和之后分别统计输入 Token 和输出 Token(可以从 API 响应中获取,或本地估算)。然后将消费记录写入数据库,并实时检查用户配额。
java
public class TokenCountingProxy implements AiClient {
private final AiClient delegate;
private final TokenUsageRepository repository;
public String chat(String prompt, List<Message> history) {
var start = System.nanoTime();
String answer = delegate.chat(prompt, history);
var tokens = estimateTokens(prompt, answer);
repository.save(new TokenUsage(userId, tokens.input, tokens.output));
checkQuota(userId);
return answer;
}
}扩展点设计 :TokenCounter 接口可以有不同的实现(精确从 API 获取、近似估算、甚至使用第三方计费服务)。还可以与 Sentinel 结合实现令牌桶限流,按 Token 消耗速率限制。
六、扩展点五:回调机制 ------ 让异步成为一等公民
有些 AI 任务耗时很长(如生成万字报告、分析百页 PDF),不适合同步等待。这时需要回调机制:用户发起任务后立即返回任务 ID,AI 处理完成后主动通知用户。
架构设计:
-
客户端发起请求,后端返回
taskId。 -
后台将任务丢入消息队列,由专门的 Worker 消费并调用 AI。
-
AI 完成后的结果通过回调 URL(由客户端注册)或 WebSocket 推送给用户。
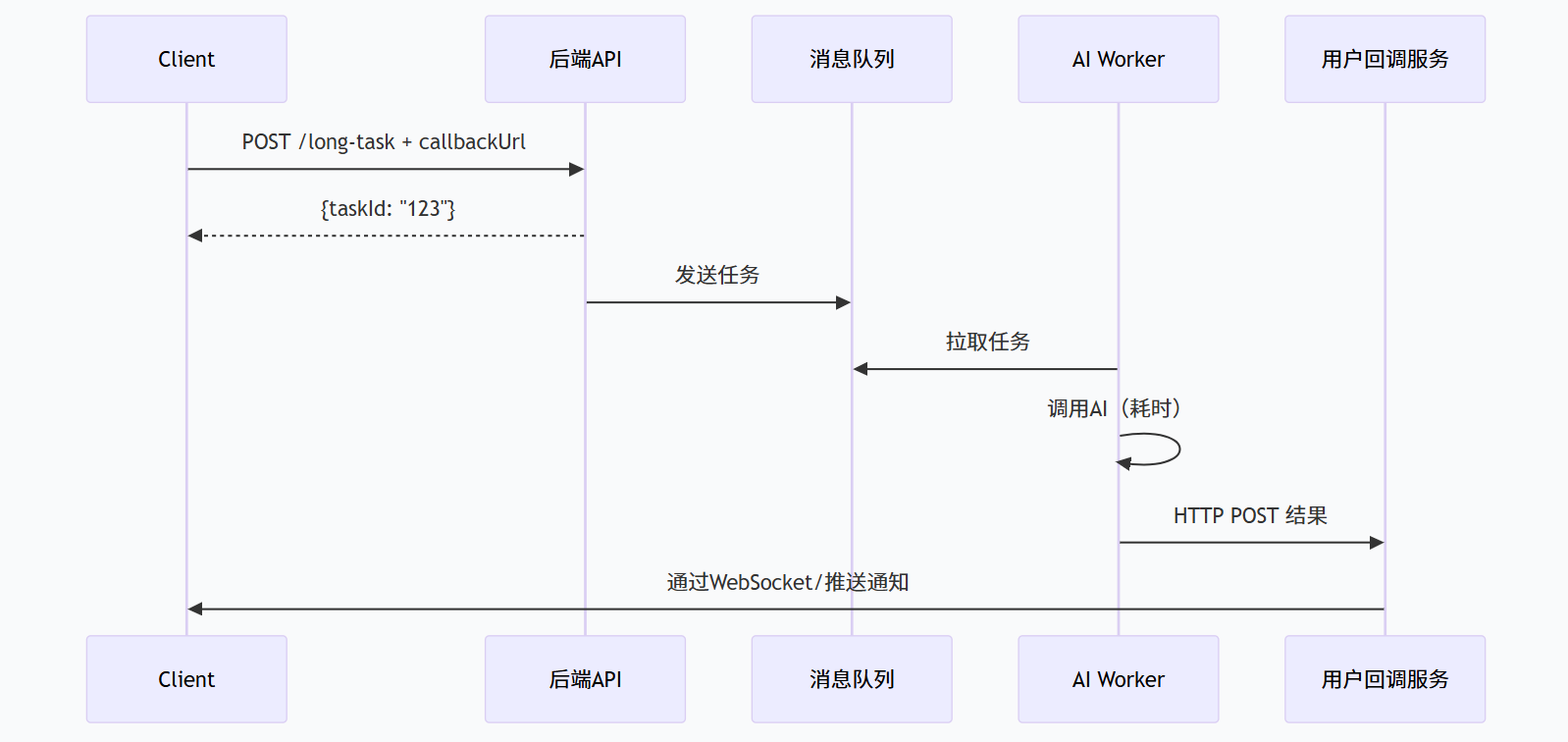
扩展点设计 :定义 AsyncTaskHandler 接口,支持不同的任务存储(Redis、数据库)、不同的回调方式(HTTP、WebSocket、消息队列)。
七、将这些扩展点组合成一个"底座"
有了以上扩展点,我们可以组装一个完整的 AI 能力底座。下面是一个 Spring Boot 自动配置的示意:
java
@Configuration
@ConditionalOnProperty("ai.enabled")
public class AiAutoConfiguration {
@Bean
@ConditionalOnMissingBean
public AiClient aiClient(AiProperties props,
List<CacheStrategy> caches,
List<TokenCounter> counters) {
AiClient client = createClientByProvider(props.getProvider());
// 装饰器模式叠加能力
client = new CachingAiClient(client, caches);
client = new TokenCountingAiClient(client, counters);
return client;
}
}这样,业务代码只需要注入 AiClient,底层自动拥有了缓存、计费等能力,且各个策略都可以通过配置灵活开关。
八、总结:AI 底座不是过度设计,而是长期主义
很多开发者会问:"我的项目一开始只用了一个模型,有必要这么复杂吗?"
我的答案是:这取决于你对未来的预期。如果你的 AI 功能只是一次性的 Demo,当然可以硬编码。但只要你的业务会持续迭代、模型会升级、成本需要控制,那么花一点时间设计扩展点,长远看绝对值得。
核心扩展点回顾:
-
✅ 统一 AI 客户端:让模型切换成为配置项。
-
✅ 缓存策略:降低延迟和成本,支持语义复用。
-
✅ 流式响应:提升用户体验,消除白屏等待。
-
✅ Token 计费:成本可视化,防止滥用。
-
✅ 回调机制:支持长任务异步化,释放 HTTP 线程。
最后送你一句话:不要让你的后端代码被某一个 AI 模型"绑架"。为未来预留插座,才能在技术浪潮中从容转身。