【LLM】第四章:项目实操案例:文本情感分析
本案例是基于LSTM架构,搭建一个文本情感分析模型,对评论内容进行二分类判断(正面或负面)。
说明:本篇是根据https://www.bilibili.com/video/BV1k44LzPEhU?spm_id_from=333.788.videopod.episodes&vd_source=b6780e06031ac609460f6fbf017bbb39&p=73 案例重构而成,致谢原作者!
一、训练数据集
到github上搜ChineseNLPCorpus--文本分类--online_shopping_10_cats.csv
这是一份网购评论数据,有10个类别,共6万条评论数据,其中正、负向评论各约3万条。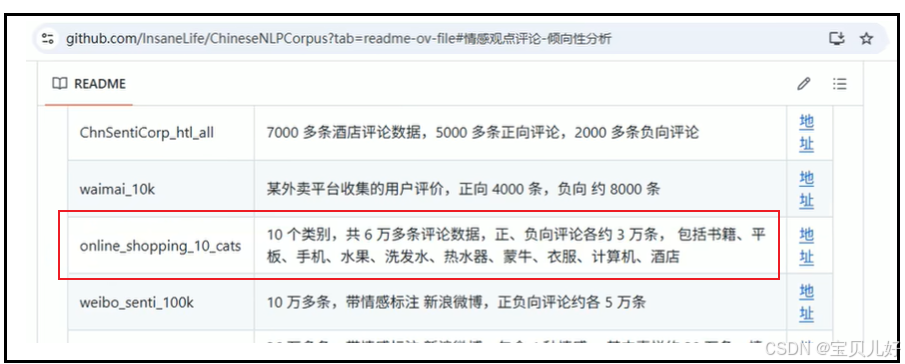
二、项目架构
本项目的架构设置和智能输入法项目 的架构是一样的,当时对这个架构的设计有详细说明,所以这里不再重复。
智能输入法项目博文链接:【LLM】第三章:项目实操案例:智能输入法项目-CSDN博客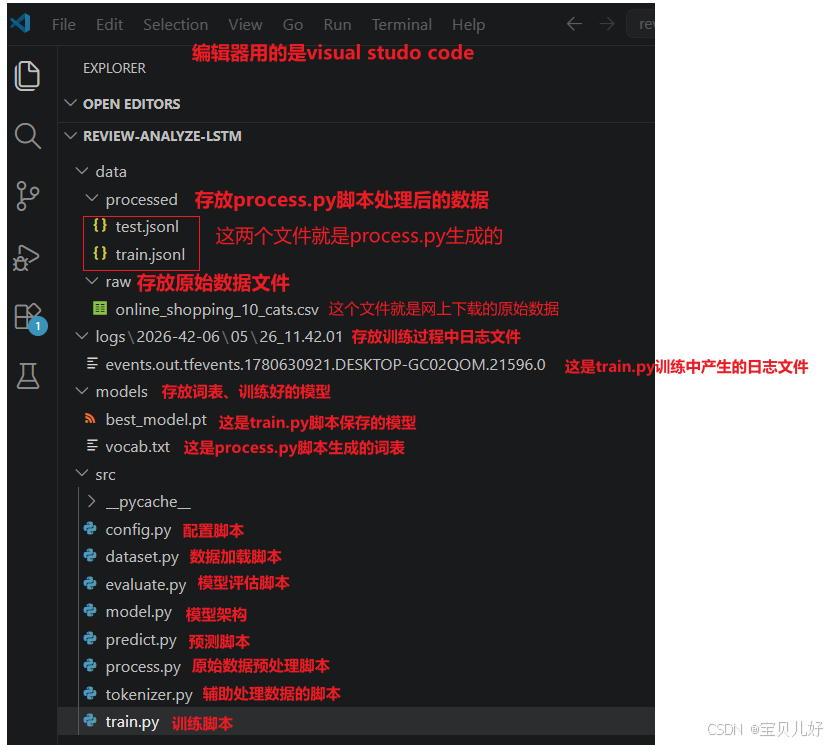
三、脚本代码、及其关键点详解
(一)配置文件:config.py 脚本
python
from pathlib import Path
ROOT_DIR = Path(__file__).parent.parent
RAW_DATA = ROOT_DIR/'data'/'raw'
PROCESSED_DATA = ROOT_DIR/'data'/'processed'
LOGS_DIR = ROOT_DIR/'logs'
MODELS_DIR = ROOT_DIR/'models'
BATCH_SIZE = 5
EMBEDDING_DIM = 128
HIDDEN_SIZE = 256
LEARING_RATE = 1e-3
EPOCHS = 10(二)tokenizer.py 脚本
python
import jieba
from tqdm import tqdm
class JiebaTokenizer:
unk_token = '<unk>' #这是类的属性
pad_token = '<pad>'
def __init__(self, vocab_list):
self.vocab_list = vocab_list
self.vocab_size = len(vocab_list)
self.index2word = {index:word for index, word in enumerate(vocab_list)}
self.word2index = {word:index for index, word in enumerate(vocab_list)}
self.unk_token_index = self.word2index[self.unk_token]
self.pad_token_index = self.word2index[self.pad_token]
@staticmethod #静态方法,可以用JiebaTokenizer.tokenize()来调用这个方法,也可以通过实例来调用
def tokenize(text):
return jieba.lcut(text)
def encode(self, text):
tokens = self.tokenize(text)
return [self.word2index.get(token, self.unk_token_index) for token in tokens]
@classmethod #类方法,和类绑定的方法,可以通过类来调用,可以访问类的属性和类方法
def build_vocab(cls, sentences, vocab_path): #承接的是句子列表
vocab_set = set()
for sentence in tqdm(sentences, desc='构建词表'):
vocab_set.update(jieba.lcut(sentence))
vocab_list = [cls.pad_token, cls.unk_token] + [token for token in vocab_set if token.strip() != ''] #切出完有空格,去掉空格
print(f'词表大小:{len(vocab_list)}')
with open(vocab_path, 'w', encoding='utf-8') as f:
save = f.write('\n'.join(vocab_list))
print('词表保存成功!' if save != 0 else '词表保存失败!')
@classmethod
def from_vocab(cls, vocab_path): #根据外部文件构建一个JiebaTokenizer对象
with open(vocab_path, 'r', encoding='utf-8') as f:
vocab_list = [line.strip() for line in f.readlines()]
return cls(vocab_list)1、这个脚本的功能是:封装和词表相关的数据和操作。这个脚本可以看作是一个工具脚本,因为process.py要用到、train.py、predict.py、evaluate.py都要用到。
2、因为是对文本进行二分类判别,有的文本长一些,有的短一些。所以生成的序列数据的长短就不一样了,这就无法把序列数据embedding后送如lstm层中。所以我们得提前处理一下句子长短不一的问题。所以这里添加了pad标识符。也就是我们打算把喂入模型的batch数据,按照所在batch中的最长句子的长度,对短句子进行padding操作。
3、这里面的类方法、实例方法、静态方法中包含的Python语法知识非常多,使用的也非常精巧,大家可以多琢磨一下。
(三)原始数据预处理文件:process.py 脚本
python
import pandas as pd
import config, tokenizer
from sklearn.model_selection import train_test_split
from pathlib import Path
def process():
#1、读取语料文件 --- 只要标签和文本,有一行的文本是空的,所以要dropna()
df = pd.read_csv(config.RAW_DATA/'online_shopping_10_cats.csv', usecols=['label', 'review']).dropna().sample(frac=0.2, random_state=0)
#2、划分数据集--stratify是分层抽样的意思。就是在标签是0的样本中2-8抽样,在标签是1的样本中2-8抽样
train,test = train_test_split(df, test_size=0.2, random_state=0, stratify=df['label'])
#3、基于训练集构建词表
tokenizer.JiebaTokenizer.build_vocab(train['review'].tolist(), config.MODELS_DIR/'vocab.txt')
#4、构建训练集并保存
my_tokenizer= tokenizer.JiebaTokenizer.from_vocab(config.MODELS_DIR/'vocab.txt')
train_data = train.copy()
train_data['review'] = train_data['review'].apply(lambda x: my_tokenizer.encode(x))
train_data.to_json(config.PROCESSED_DATA/'train.jsonl', orient='records', lines=True)
print('训练集保存成功!' if (Path(config.PROCESSED_DATA/'train.jsonl').exists() and Path(config.PROCESSED_DATA/'train.jsonl').stat().st_size != 0) else '训练集保存失败!')
#5、构建测试集并保存
test_data = test.copy()
test_data['review'] = test_data['review'].apply(lambda x: my_tokenizer.encode(x))
test_data.to_json(config.PROCESSED_DATA/'test.jsonl', orient='records', lines=True)
print('测试集保存成功!' if (Path(config.PROCESSED_DATA/'test.jsonl').exists() and Path(config.PROCESSED_DATA/'test.jsonl').stat().st_size != 0) else '训练集保存失败!')
if __name__ == '__main__':
process()1、因为原始文件中的数据,我们只要'label'和'review'两列,所以读的时候就只读这两列。
2、因为原始数据中还有一行是空行,所以要用dropna()。
3、划分训练集和测试集的时候:由于是二分类任务,所以我们希望不管是训练数据还是测试数据,其样本都是均衡的,就是标签是0和标签是1的样本数量大致是1:1的状态,所以要用stratify参数 。stratify=df'label'标识按照label列进行分层抽样 。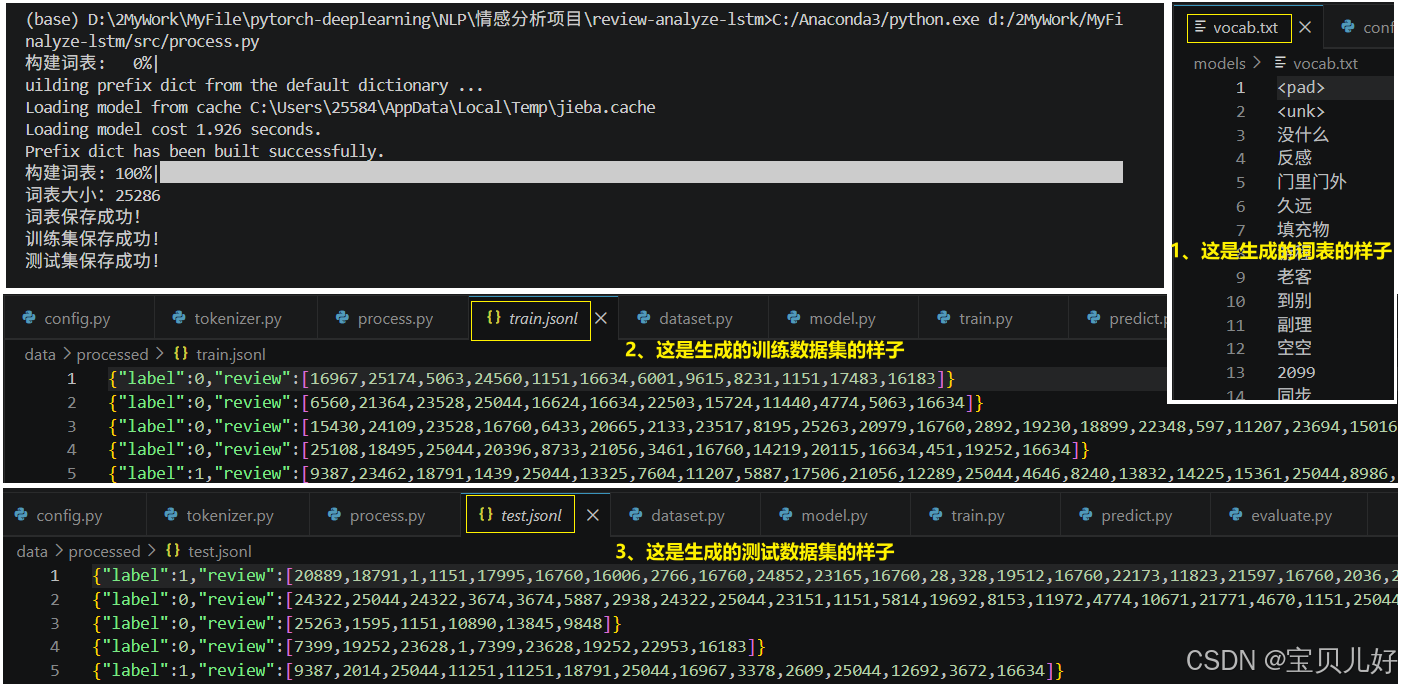
(四)生成可以直接加载到模型的训练和测试数据:dataset.py 脚本
python
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import pandas as pd
import config
import torch.nn.functional as F
# 封装数据
class ReadData(Dataset):
def __init__(self, path):
super(ReadData, self).__init__()
self.data = pd.read_json(path, lines=True, orient='records')
def __getitem__(self, index):
input_tensor = torch.tensor(self.data.iloc[index]['review'], dtype=torch.long)
target_tensor = torch.tensor(self.data.iloc[index]['label'], dtype=torch.float64) #二分类的损失函数要求标签是float类型的
input_len = len(input_tensor) #多返回一个训练序列的长度
return input_tensor, target_tensor, input_len
def __len__(self):
return len(self.data)
def collate_fn(batch): #传的参是一个batch的__getitem__
input_data = [item[0] for item in batch] #从batch中把特征拿到
target_data = [item[1] for item in batch] #从batch中把标签拿到
input_data_len = [item[2] for item in batch] #从batch中把特征的长度拿到
max_len = max(len(s) for s in input_data) #找到这个batch中的最长句子的长度
for i,s in enumerate(input_data): #对batch中的句子进行填充
paddings = (0, max_len-len(s))
input_data[i] = F.pad(s, paddings)
input_tensor = torch.stack(input_data)
return input_tensor, torch.tensor(target_data).reshape(-1,1), input_data_len
# 分小批次batch
def get_batchdata(train=True):
path = config.PROCESSED_DATA / ('train.jsonl' if train else 'test.jsonl')
dataset = ReadData(path)
batchdata = DataLoader(dataset, batch_size=config.BATCH_SIZE, collate_fn=collate_fn, shuffle=True, drop_last=True)
return batchdata1、这个脚本是本项目的难点。难在处理句子长短不一 的逻辑,基本就写在这个脚本中。脚本中的collate_fn函数就是对短序列进行0填充的逻辑。把collate_fn函数传入到DataLoader类中就可以实现了。这是一个如何使用DataLoader 加载变长加载训练数据的典型示例。
2、第二个技巧是ReadData类中的__getitem__,我让它返回了3个值,其中第3个值是记录句子的长度的。所以训练模型时我们就是for x, y,z in DataLoader了。
(五)搭建模型架构:model.py 脚本
python
import config
import torch
class ModelLstm(torch.nn.Module):
def __init__(self, vocab_size):
super().__init__()
self.embedding = torch.nn.Embedding(num_embeddings=vocab_size, embedding_dim=config.EMBEDDING_DIM, padding_idx=0) #padding初始化时都是0,也不会计算padding向量的梯度,也不更新padding向量。
self.lstm = torch.nn.LSTM(input_size=config.EMBEDDING_DIM, hidden_size=config.HIDDEN_SIZE) #一定要变换数据结构(sequence, batch, dim)
self.linear = torch.nn.Linear(config.HIDDEN_SIZE, 1) #二分类任务
def forward(self, x, len_x): #这里的x是(batch, sequence)
embed = self.embedding(x)
embed = embed.transpose(1, 0) #变换数据结构(sequence, batch, dim)
output, (ht,ct) = self.lstm(embed)
len_index = [x-1 for x in len_x]
if len(len_x)>1:
last_hidden_state = output[len_index, torch.arange(config.BATCH_SIZE)] ##截取batch中的每个sequence的最后一个输出
else:
last_hidden_state = output[-1] #如果batch中只有一个序列的情况
yhat = self.linear(last_hidden_state) # #(batch, vocab_size_dim)
return yhat1、下面是lstm层的输入和输出:
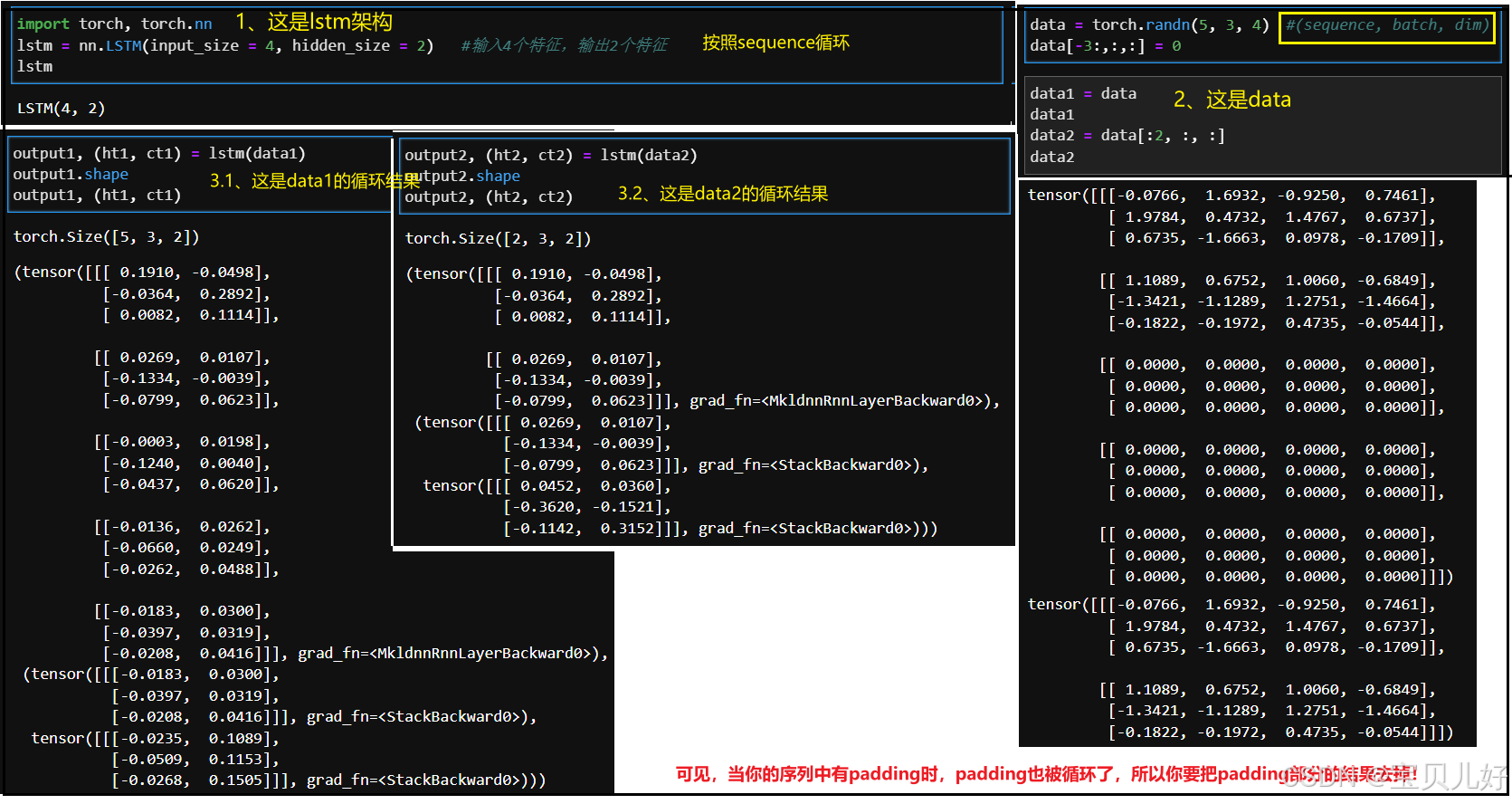 lstm层的返回值是一个sequence中所有时间步的输出,所以我们还得根据句子长度,提取对应的结果。也所以这里的forward函数多了一个参数len_x,len_x就是句子的长度,用来当做切片提取lstm层的返回值。
lstm层的返回值是一个sequence中所有时间步的输出,所以我们还得根据句子长度,提取对应的结果。也所以这里的forward函数多了一个参数len_x,len_x就是句子的长度,用来当做切片提取lstm层的返回值。
2、前向传播的时候分两种情况,因为在模型训练过程中是按batch传播的,但是在模型预测阶段,我们大概率是输入一个句子,然后让模型预测,所以此时就是单条样本前向传播。所以我们在dataset.py脚本中设计的技巧,如果遇到单条样本,这里的逻辑就无法适用了,所以这里我加入了if else的判断。
(六)训练模型:train.py 脚本
python
import torch, torch.nn
import dataset, tokenizer, model, config
from torch.utils.tensorboard import SummaryWriter
import time
from tqdm import tqdm
def train():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_dataloader = dataset.get_batchdata()
my_tokenizer = tokenizer.JiebaTokenizer.from_vocab(config.MODELS_DIR/'vocab.txt')
lstm_model = model.ModelLstm(my_tokenizer.vocab_size)
criterion = torch.nn.BCEWithLogitsLoss(reduction='sum')
opt = torch.optim.Adam(lstm_model.parameters(), lr=config.LEARING_RATE)
writer = SummaryWriter(log_dir=config.LOGS_DIR/time.strftime('%Y-%M-%D_%H.%M.%S'))
#开始训练
lstm_model.train()
epoch_loss = []
best_loss = float('inf')
for epoch in range(config.EPOCHS):
print("="*10, f" Epoch: {epoch+1} ", "="*10)
total_loss = 0
for x, y, z in tqdm(train_dataloader, desc='训练中:'):
x = x.to(device)
y = y.to(device)
yhat = lstm_model(x,z)
loss = criterion(yhat, y)
loss.backward()
opt.step()
opt.zero_grad()
total_loss += loss.item()
epoch_loss_temp = total_loss/len(train_dataloader)
print(f'本次epoch的平均损失:{epoch_loss_temp}')
epoch_loss.append(epoch_loss_temp)
writer.add_scalar('epoch_loss', epoch_loss_temp, epoch)
if epoch_loss_temp < best_loss:
best_loss = epoch_loss_temp
torch.save(lstm_model.state_dict(), config.MODELS_DIR/'best_model.pt')
print('模型保存成功')
writer.close()
if __name__ == '__main__':
train()由于是二分类任务,所以模型最后一个线性层的输出只有一个神经元。所以输出也没有进行sigmoid变换,所以损失函数要使用torch.nn.BCEWithLogitsLoss()这个是带sigmoid变换的损失函数。鉴于文章的连贯性,本文末尾 我将对深度学习的损失函数进行一个全面的补充,下面是我训练过程的部分截图: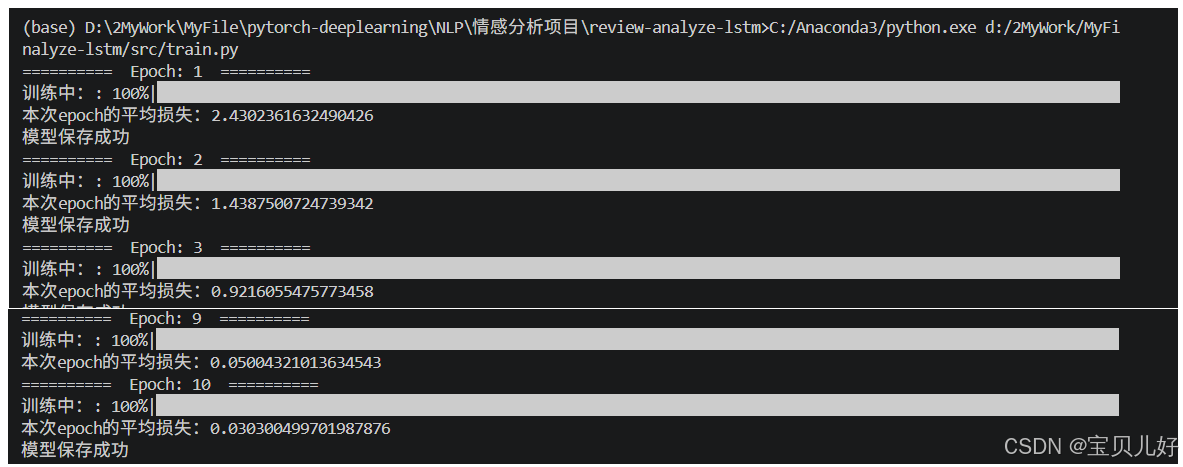
(七)预测:predict.py 脚本
python
import torch
import config, tokenizer
import model
def predict(text, tokenizer, Model, device):
tokens = tokenizer.encode(text)
input_tensor = torch.tensor([tokens], dtype=torch.long).to(device)
len_index = [len(tokens)]
Model.eval()
with torch.no_grad():
output = Model(input_tensor, len_index)
output = torch.sigmoid(output)
predict_re = f'正向评价(置信度{output})' if output>=0.5 else f'负向评价(置信度{1-output})'
return predict_re
def run_predic():
print('欢迎使用情感分析模型(输入q或者quit退出)')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #设备
my_tokenizer = tokenizer.JiebaTokenizer.from_vocab(config.MODELS_DIR/'vocab.txt')
lstm_model = model.ModelLstm(my_tokenizer.vocab_size).to(device)
lstm_model.load_state_dict(torch.load(config.MODELS_DIR/'best_model.pt'))
word2index = my_tokenizer.word2index
while True:
user_input= input('请输入>>> ')
if user_input in ['q', 'quit']:
print('欢迎下次再来!')
break
if user_input.strip() == '':
print('请输入内容')
continue
predict_re = predict(user_input, my_tokenizer, lstm_model, device)
print(predict_re)
if __name__=='__main__':
run_predic()置信度指标中,一是要把output进行sigmoid变换;二是负向评价要记得是1-output。
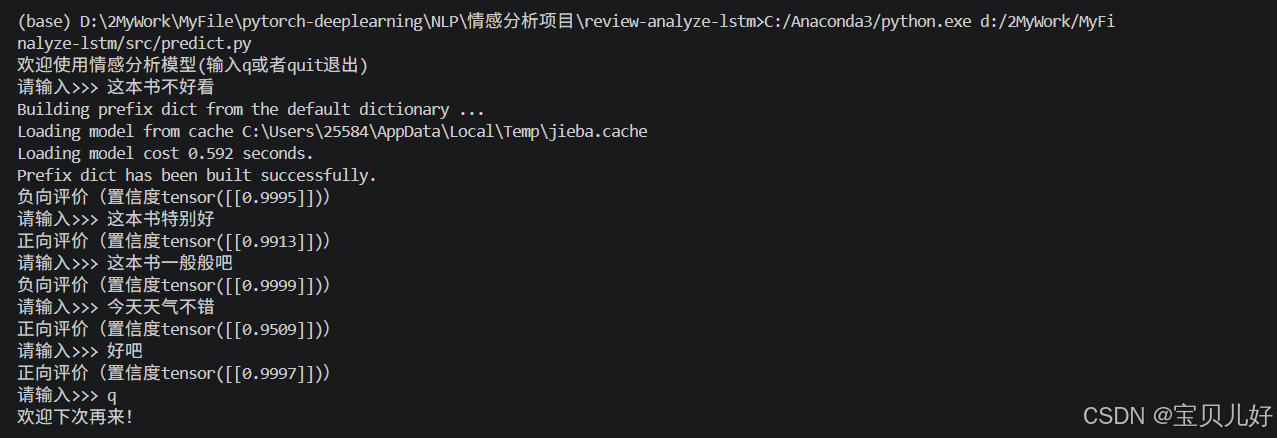
(八)评估脚本:evaluate.py
python
# evaluate.py模块的具体代码如下:
import torch
import config, model, dataset, tokenizer
def run_evaluate():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #设备
my_tokenizer = tokenizer.JiebaTokenizer.from_vocab(config.MODELS_DIR/'vocab.txt')
print('词表加载成功!!!' if my_tokenizer != None else '词表加载失败!')
Model = model.ModelLstm(vocab_size=my_tokenizer.vocab_size).to(device) #模型
Model.load_state_dict(torch.load(config.MODELS_DIR/'best_model.pt'))
print('模型加载成功!!!')
test_dataloader = dataset.get_batchdata(train=False) #测试数据
total_sample=0
predict_correct = 0
Model.eval()
with torch.no_grad():
for x, y, z in test_dataloader:
output = Model(x,z) #正向传播
output = torch.sigmoid(output)
result = [[0 if i[0]<0.5 else 1] for i in output]
total_sample += len(x)
for yhat, y_true in zip(result, y):
if yhat[0] == y_true[0]:
predict_correct += 1
print(f'模型在测试集的效果:准确率{predict_correct/total_sample:.4f}')
if __name__ == '__main__':
run_evaluate()二分类任务的评估指标有:准确率、精确率、召回率、F1等,这些指标都可以。所以我们先科普一下二分类模型的一些评估指标: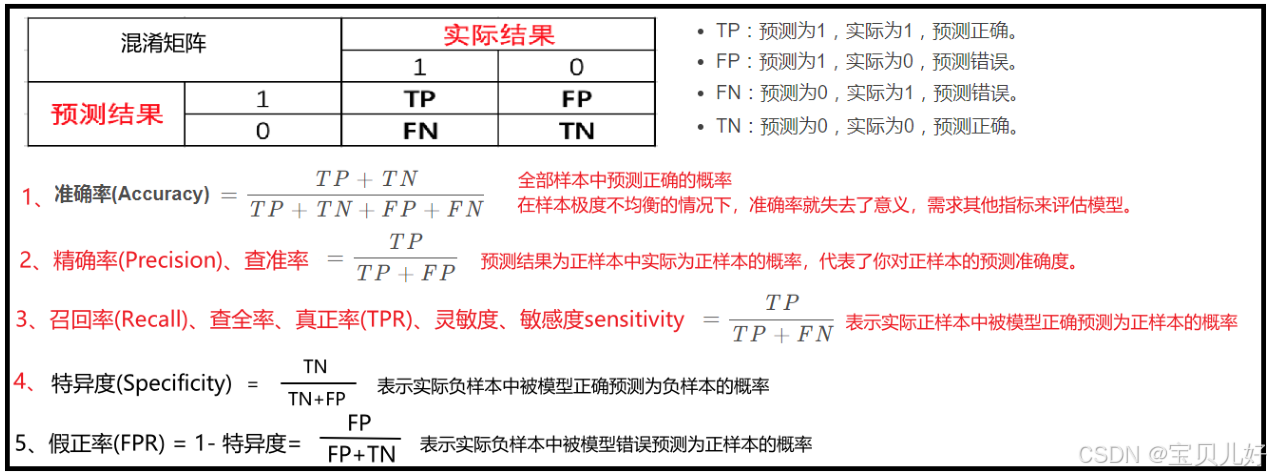
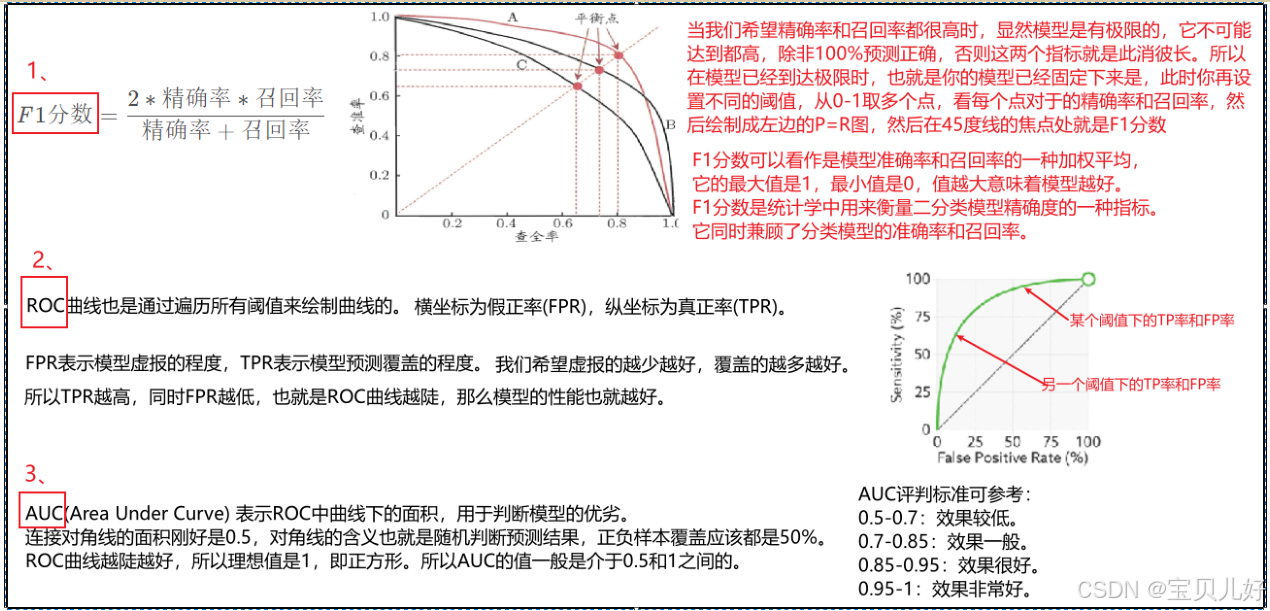

本项目中只用了准确率这个一个指标。其他指标可对照上面的定义自行计算。下面是我训练了10个epoch后的模型效果:

至此,文本情感分析项目的开发就结束了。
四、补充:损失函数 ¶
建立一个深度学习模型的过程就是:定义模型架构->定义损失函数->定义优化算法->以最小化损失函数为目标,求解出最优的模型参数->新样本带入模型进行预测。这里我单独把损失函数拿出做个总结:
1、确定损失函数L(w)
当我们的模型是回归类模型的时候,也就是标签是一组连续的数据的时候,损失函数一般都用SSE,sum of the squared errors, 总体的误差平方和,或者用均方误差 MSE=1/m SSE。
当我们的模型是分类模型时,也就是分类任务时,我们一般都用交叉熵损失函数。
确定了损失函数后,我们求损失函数的最小值的过程就是解模型wb的过程。就是我们要找到一组wb,在这组wb下,模型对样本的预测结果和样本的真实结果相差最小。所以,损失函数的值越小,说明模型的预测值和真实值最接近,如果损失函数的值越大,说明模型预测得越差。 而求解损失函数最小值就是一个数学问题。一般情况下,第一步都是先把损失函数转化为凸函数(但是神经网络就不需要这步),常见的就是拉格朗日变换。第二步就是求这个凸函数的最小值,这步就是优化的过程,用到的算法就叫优化算法,最常见的就是梯度下降优化算法。
当然,我这里说的mse、交叉熵损失函数都是深度学习中的损失函数的入门级损失函数,或者说是最常见的损失函数,除此之外还有很多其他的损失函数。但是,选择什么样的损失函数还是主要是看你的需求的,比如是否时候你的任务、是否适合你的算法、以及是否要考虑梯度下降的时间效率等。
2、回归类模型的损失函数SSE、MSE

这里我们主要不是讲数学,主要讲如何代码实现: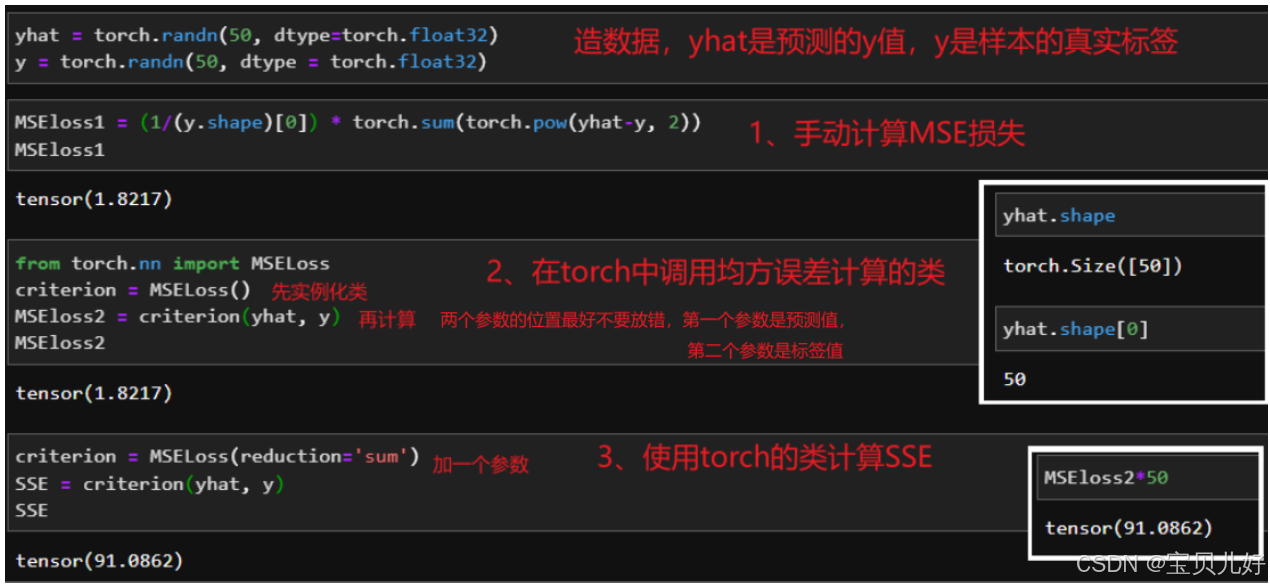
3、二分类损失函数
在二分类和多分类中,我们经常用二分类交叉熵损失函数:binary cross entropy loss,也叫对数损失log loss, 作为损失函数。 有人说要看二分类模型效果如何,只要对比模型结果和标签结果之间的差异,比如准确率即可,但是这样不可行!因为准确率不可导,就不可迭代,这个指标只关注最后结果而没有重时计算的过程。
我们在分类模型中,一般的分类方式是计算出各种分类的类概率值、伪概率值,或者仅仅就是一个0-1直接的数值,然后根据这个值再返回分类类型。所以只要我们最后计算的结果越靠近那个分类就说明分对那个类的概率越大,也就是越有把握分类成功。转化成数学就是: 如果一个事件的发生概率很大,那这个事件就很容易发生。假设现在存在事件A,其发生的概率受条件w的影响,为使事件A最大可能的发生,我们就要寻找令其最大可能发生的w。这个寻找的w就是极大似然估计maximum likelihood estimate ,MLE。所以,极大似然就是"最大概率",估计的就是权重w。
所以,二分类:
P0 = P(yhat=0|x,w)=sigma
P1 = P(yhat=1|x,w)=1-sigma
我们希望P(yhat|x,w)=P0*P1最小,也即L(w) = - ( yi*ln(sigma) + (1-yi)*ln(1-sigma) )最小, 就是我们想要的最好预测结果。
一个二分类数据集,标签是0和1。
当一条样本的标签是0时,如果我们预测的sigma越接近0,此时L(w)就越小,就是损失越小。我都预测对了当然损失越小了。如果我们预测的sigma越接近1,就是我们预测错了,此时L(w)就越接近无穷大。预测错了损失就非常大。
同理,当一条样本的标签是1时,如果我们预测的sigma越接近0,就是预测错了,此时L(w)就越接近无穷大,就是损失很大。如果我们预测的sigma越接近1,就是我们预测对了,此时L(w)就越接近0,就是没有损失。
有人问w在哪儿?当我们的神经网络架构创建好后,我们实例化这个架构后,就随机生成了一组参数w,b。当样本特征数据喂进去后,xw相差相加加截距、并且经过激活函数变换,最后出来的数据sigma就是带wb参数的。所以这个损失函数L(w)就是一个关于wb的一个函数。但是神经网络的线性变换和激活函数的非线性变换很多次,我们是无法写出显式的函数。所以后面我们求L(w)最小值的时候一般都用梯度下降方法去找一个相对满意的最小值。
下面展示代码如何实现交叉熵的计算:
(1)手动计算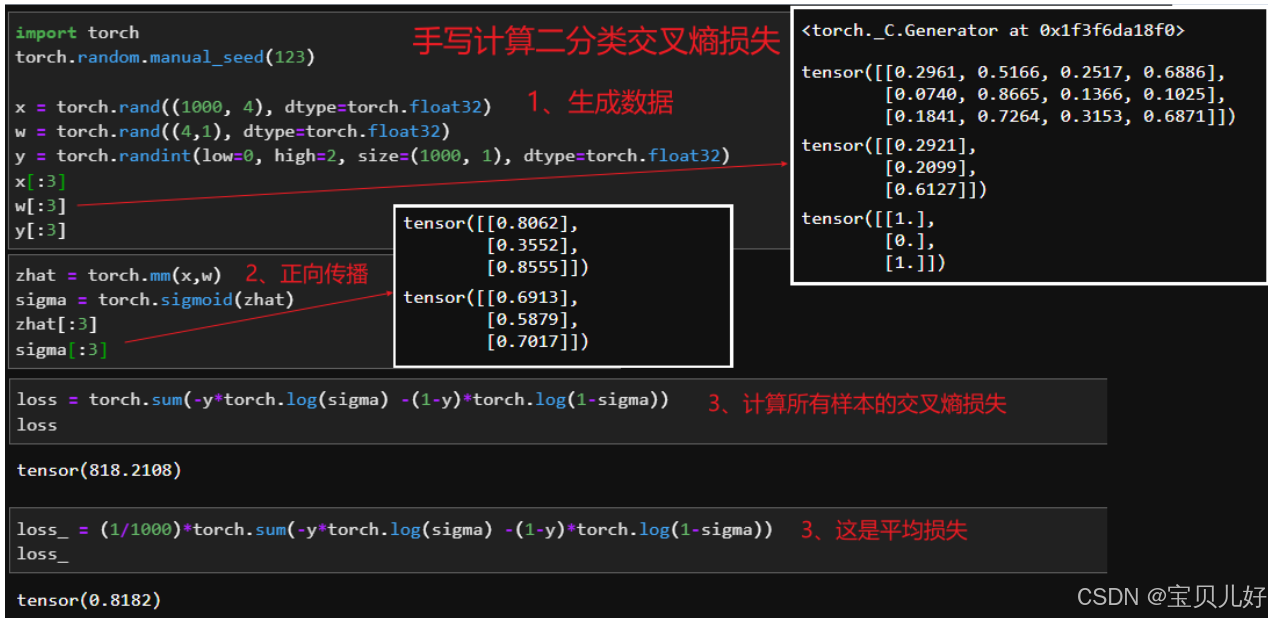
(2)调用类计算交叉熵损失
二分类交叉熵损失,nn提供了2个类:
class BCEWithLogitsLoss里面内置了sigmoid函数和交叉熵函数,它会自动计算输入值的sigmoid值,因此只需要输入zhat与真实标签即可。
class BCELoss 只有交叉熵函数没有sigmoid层,因此需要输入sigma与真实标签。
BCE,表示binary cross entropy loss
真实标签在第二个参数。预测值和真实标签的数据类型及结构shape必须相同。
上面两个类还有第三个参数reduction,默认是mean, 所以也可以设置reduction='sum'就是求总体误差。如果设置reduction='none'就求出来的是一个1000行1列的矩阵,就是每个样本的误差。
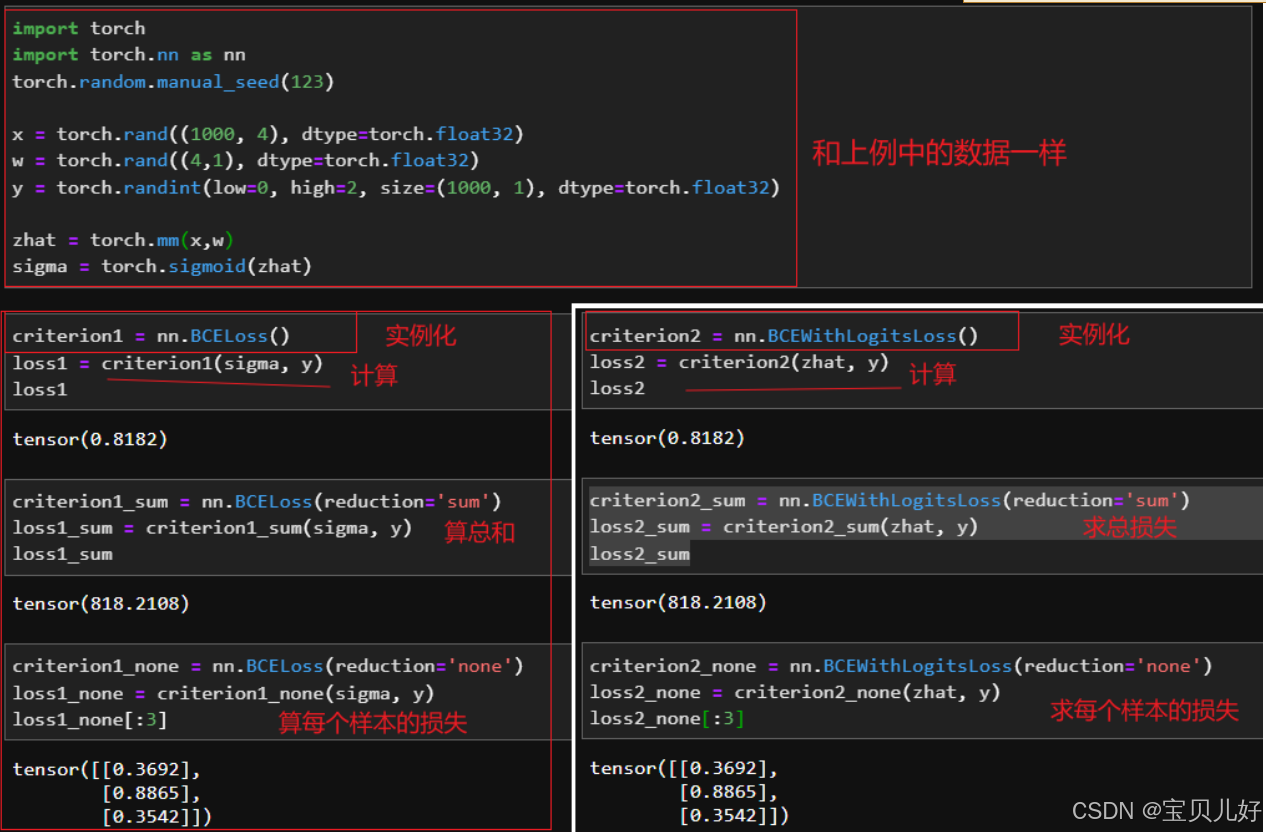
为什么求一个误差就要提供两个类呢?因为sigmoid函数是存在精度问题的。所以torch提供BCEWithLogitsLoss()的类中计算的sigmoid结果的精度要比我们自己计算的sigmoid精度要高。所以当我们有很高的精度要求的时候要用BCEWithLogitsLoss()
(3)从nn.functional库中调用函数计算交叉熵损失
除了类,nn.functional库中还有2个函数可以计算交叉熵损失:binary_cross_entropy_with_logits和binary_cross_entropy 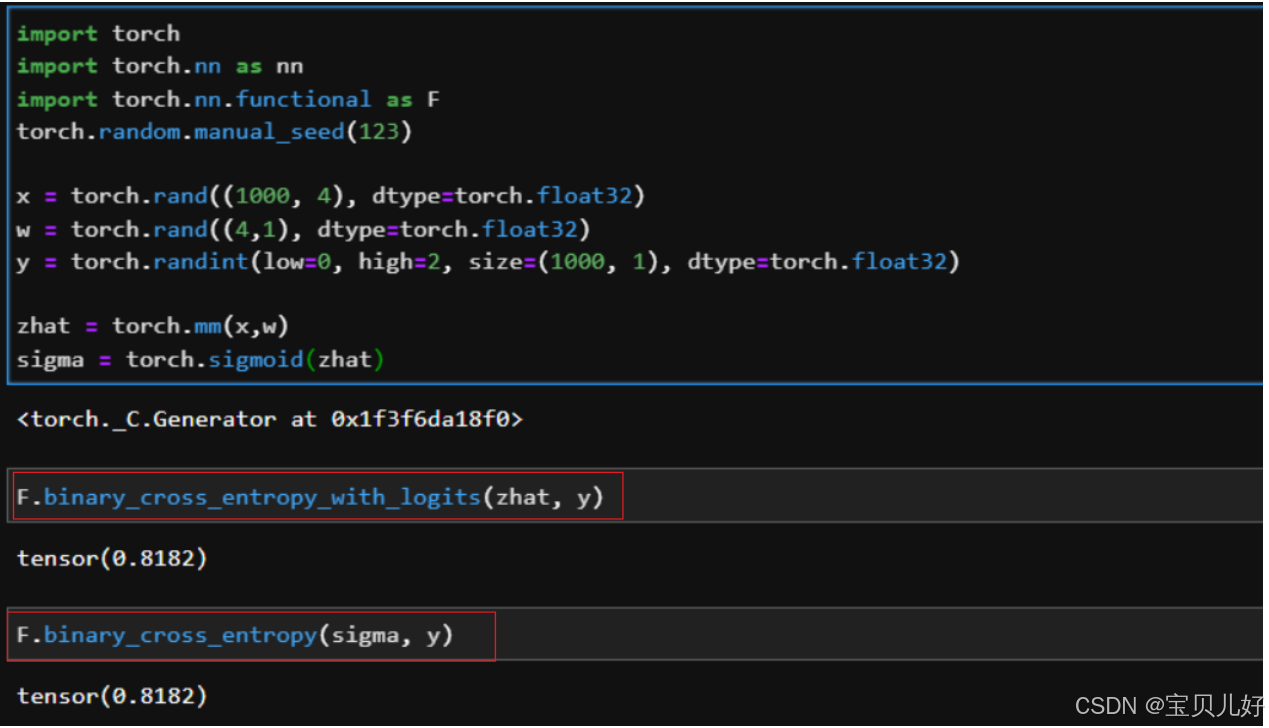
4、多分类交叉熵损失函数
多分类标签,比如有1,2,3三个分类类别,我们就要先把标签向量变成one-hot矩阵,就是做哑变量,就是把标签做成样本数,3,3列的一个one-hot矩阵。这个矩阵中用1表示真实标签的位置,用0表示不是真实标签。
多标签情况下,神经网络最后一层输出层的神经元个数就是标签类别的个数,一般多分类输出层的激活函数都是softmax函数,所以softmax函数返回就是标签类别个数量的类概率值。
多标签模型的损失函数就是-sum(yi*lnsigmai) , 这就是多分类交叉熵损失函数。可以看出,二分类交叉熵损失函数就是多分类交叉熵损失函数的一种特殊情况。这个推导和二分类一样都是从似然函数推出,不懂的可以自己查资料,网上有大量的资料。
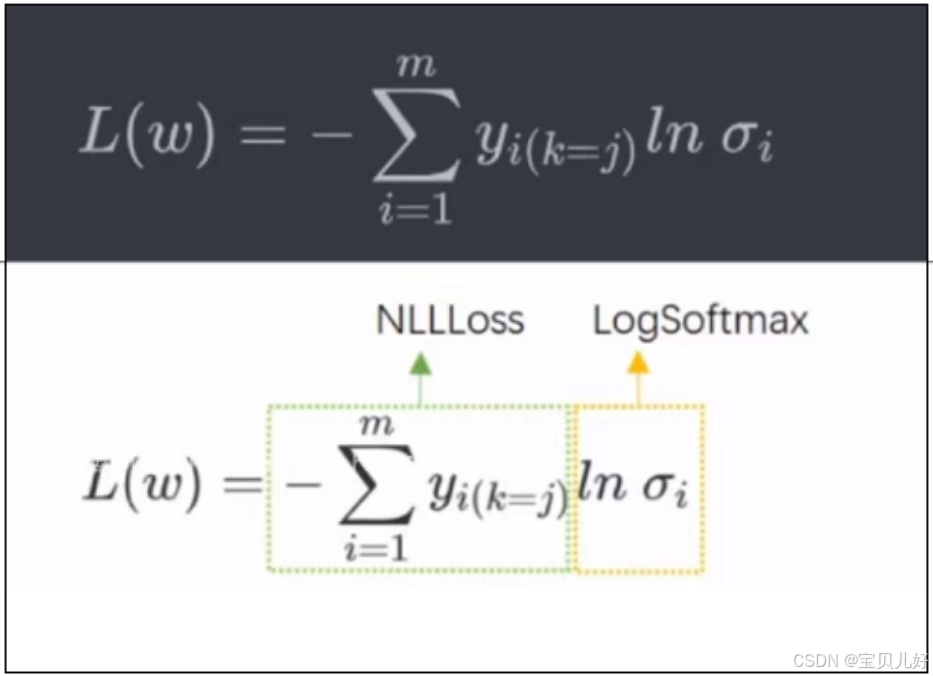
所以pytorch在计算多分类交叉熵的时候是取了个巧,没按常规方法计算。所以我们调用pytorch类来计算多分类交叉熵的时候是:
(1)先调用nn.logsoftmax类的功能,把zhat假如1000个样本,3分类标签,就是1000,3先计算softmax变成1000,33列的一个类概率(每行和是1),然后再取ln,得到还是1000,3这么一个矩阵。
(2)然后再调用nn.NLLLoss类进行第二步计算。nn.NLLLoss类是把乘以标签yi、加和、取负这3个过程打包起来,而这3个过程就是负对数似然函数negative log likelihood function, 所以我们要调用nn.NLLLoss来进行损失函数的第二步计算。
pytorch之所以要这么设计,我个人认为是为了提高速度吧。下面是代码实现展示:
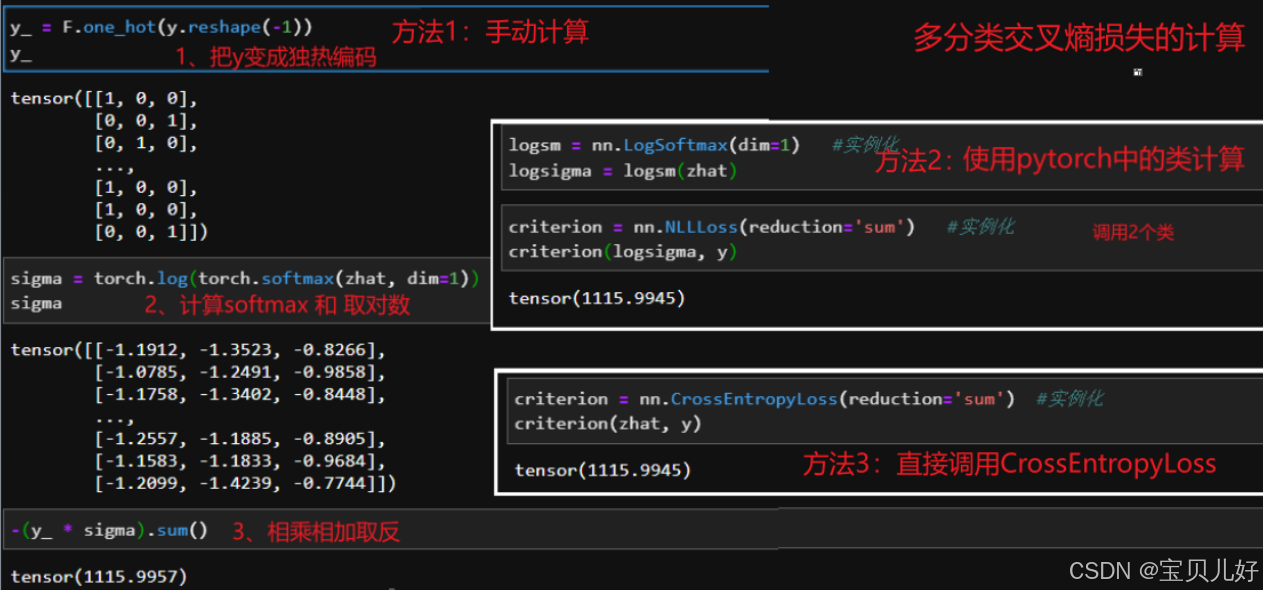
说明,上面的NLLLoss()和CrossEntropyLoss()都有参数reduction='mean'/'sum'/'none'。从上面可以看出,pytorch计算损失有这么多类和函数,好像很多余。其实不是的,这都是为了后面我们更加灵活的设置我们的网络架构,以及更方便的输出我们的中间结果,方便我们查看和分析。或者说,主要是我们有这个需求,所以才设计出多个类和函数以满足我们的需求。这方面在后面就会有更深刻的体会。
5、小结
神经网络的优化过程就是,首先定义损失函数,然后找到使损失函数取得最小值的一组权重w,就是优化的过程。我们一般的做法就是将损失函数转化成凸函数,然后求导,令导函数=0,得出的w就是凸函数的最小值。
或者从另外一个角度来说:我们建模的目的就是要预测,就是要预测效果非常好。那预测的效果就体现在损失函数上,因为我们的损失函数就是衡量预测值和真实标签之间的差距的。所以如果你的损失函数值为0,那就说明你都预测对了。所以损失越小,预测效果越好。也所以这就是一个数学问题:求损失函数的最小值。
也所以,你的损失函数一定要和你的预测效果挂钩,所以我们有了SSE/MSE/交叉熵损失这些损失函数,都是衡量预测值和真实标签之间的差距的函数。同时,我们的损失函数也正是我们的参数的函数,所以求到损失函数的最小值对应的那组参数就是我们模型的参数。也就是在这组参数下,模型的损失函数最小,也就是模型的预测效果最好。
损失函数我们讲了3种,第一种是回归的损失函数SSE/MSE, 第二种是二分类的二分类交叉熵损失函数,第三种是多分类的多分类交叉熵损失,又叫做负对数似然损失+log softmax。
其中,多分类交叉熵损失函数CELoss=-所有样本的加和(yik *ln sigma)其中,yik表示第i个样本它的真实标签是k类别,就是说yi的标签是k类别但它已经变成onehot变量,就是说它的标签类别是k类别但是是k类别下面的1,其他非k类别的都是0。后面再乘以lnsigma,就是softmax返回的在k类别下的概率值。
由于神经网络的权重w非常的多,如果对每个w求导求其最小值就非常费力,所以我们要采取迭代的思维,逐渐接近损失函数的最小值,这就是梯度下降 算法。欲知相关详情,请参照:【深度学习】第四章:反向传播-梯度计算-更新参数_反向传播参数更新-CSDN博客
深度学习的整个算法流程请参照:https://blog.csdn.net/friday1203/category_12824284.html?spm=1001.2014.3001.5482