全栈 AI 必修课:基于 Node.js 与 LLM 的渐进式提示词工程实践
- [一、 引言](#一、 引言)
- [二、 基础工程架构与大模型环境配置](#二、 基础工程架构与大模型环境配置)
-
- [1. 环境变量配置 (`.env`)](#1. 环境变量配置 (
.env)) - [2. 客户端实例化 (`client.mjs`)](#2. 客户端实例化 (
client.mjs)) - [3. 通用文本生成接口 (`completion.mjs`)](#3. 通用文本生成接口 (
completion.mjs))
- [1. 环境变量配置 (`.env`)](#1. 环境变量配置 (
- [三、 核心 Prompt 的编写规则与设计哲学](#三、 核心 Prompt 的编写规则与设计哲学)
-
- [1. 清晰且具体的指令](#1. 清晰且具体的指令)
- [2. 给定输出格式](#2. 给定输出格式)
- [3. 给出具体示例 (Few-shot)](#3. 给出具体示例 (Few-shot))
- [4. 分步骤引导大模型](#4. 分步骤引导大模型)
- [四、 渐进式演进历程:NLP 核心任务的代码实现与演进分析](#四、 渐进式演进历程:NLP 核心任务的代码实现与演进分析)
-
- [1. 情感分类与多维推理演进](#1. 情感分类与多维推理演进)
-
- [阶段 A:基础情感分类](#阶段 A:基础情感分类)
- [阶段 B:限制输出字数与范围 (规则 2)](#阶段 B:限制输出字数与范围 (规则 2))
- [阶段 C:格式化为以逗号分隔的列表 (规则 2)](#阶段 C:格式化为以逗号分隔的列表 (规则 2))
- [阶段 D:特定情绪定向判定](#阶段 D:特定情绪定向判定)
- [阶段 E:特定关键信息提取与标准 JSON 输出 (规则 1、2)](#阶段 E:特定关键信息提取与标准 JSON 输出 (规则 1、2))
- [阶段 F:复合型多任务并行处理 (规则 1、2、4)](#阶段 F:复合型多任务并行处理 (规则 1、2、4))
- [2. 主题推断与多主题匹配任务](#2. 主题推断与多主题匹配任务)
-
- [任务 A:自主多主题提炼](#任务 A:自主多主题提炼)
- [任务 B:零样本多标签分类](#任务 B:零样本多标签分类)
- [3. 聚焦特定维度的文本总结与批量文本流处理](#3. 聚焦特定维度的文本总结与批量文本流处理)
-
- [维度 A:通用信息概括 (字数约束)](#维度 A:通用信息概括 (字数约束))
- [维度 B:聚焦产品运输 (定向信息压缩)](#维度 B:聚焦产品运输 (定向信息压缩))
- [维度 C:聚焦价格与质量](#维度 C:聚焦价格与质量)
- [维度 D:多样本批量并行循环化处理](#维度 D:多样本批量并行循环化处理)
- [五、 结论](#五、 结论)
一、 引言
在传统自然语言处理(NLP)领域,构建情感分类、信息提取或文本总结等系统是一项系统性工程。传统的机器学习工作流涵盖数据标注、特征工程、模型训练及反复调优,通常需要熟练的算法工程师耗费数天乃至数周的时间。
随着大语言模型(LLM)的普及,Prompt(提示词)工程开辟了全新的技术范式。开发者通过设计精准的自然语言指令,即可在数分钟内构建出高可用性的推理系统。这种技术的"平权"极大地降低了开发门槛。本文将结合具体的 Node.js 项目工程代码,深入解析如何通过工程化 Prompt 实现各类核心 NLP 任务,并总结高效提示词的核心编写原则。
二、 基础工程架构与大模型环境配置
为实现高效的文本推理,项目采用了基于 Node.js(ES Modules)的模块化架构,利用 openai SDK 对接大语言模型(如 DeepSeek 接口)作为底层推理引擎。
在基于大语言模型(LLM)的全栈开发中,env、client 和 completion 承担着不同的职责,它们共同构成了应用程序与大模型交互的基础通道。
我们可以把它们的关系理解为:env 负责提供大门钥匙,client 是连接大模型的"门禁与通道",而 completion 是通过通道去执行特定任务的"执行者"。
1. 环境变量配置 (.env)
env 是项目的基础环境配置文件 (通常表现为 .env 文件)。它的主要作用是将大模型调用所需的 API 密钥、接口基础路径以及指定的模型版本等敏感数据和可变参数,从业务代码中彻底抽离出来。它为后续客户端的初始化提供了最底层的配置支撑。
javascript
DEEPSEEK_API_KEY=sk-666666
DEEPSEEK_API_BASE_URL=https://api.deepseek.com
DEEPSEEK_MODEL=deepseek-v4-flash2. 客户端实例化 (client.mjs)
client 是通过大模型官方 SDK(如 openai 库)创建的一个核心客户端对象 。它直接读取 env 中配置的参数,其主要作用是配置基础连接信息 并建立通信通道。
- 身份验证(Authentication):持有访问凭证,向大模型服务器验证当前请求的合法性。
- 通路配置(Endpoint Configuration):指定请求的基础路径,明确将网络请求导向哪台远程服务器。
- 连接复用(Connection Reuse) :在整个工程架构中,客户端只需要在
client.mjs中初始化一次并默认导出。其他所有需要调用大模型的业务模块直接复用该实例,避免了重复配置与连接资源的浪费。
javascript
import { OpenAI } from 'openai';
import dotenv from 'dotenv';
dotenv.config();
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_API_BASE_URL,
});
export default client;3. 通用文本生成接口 (completion.mjs)
completion(在代码中表现为 client.chat.completions.create)是大模型最核心的文本生成与逻辑推理接口。它负责承载具体的指令并捕获大模型的输出结果。
- 指定模型大脑 :在发起调用的同时,明确指定本次推理任务所启用的具体模型版本(同样动态读取自
env的配置)。 - 管理上下文与角色(Messages) :通过结构化的数组传递对话上下文。例如,通过
{ role: 'user', content: prompt }声明当前输入的文本属于用户指令,引导大模型进行针对性推理。 - 提取结构化响应 :大模型 API 返回的数据通常包含丰富的元数据(如 Token 消耗、结束标识等)。
completion函数的作用在于剥离外壳,通过路径response.choices[0].message.content精准提取出大模型真正吐出来的文本回复。
javascript
import client from './client.mjs';
/**
* 封装大模型文本生成接口
* @param {string} prompt - 输入的提示词
* @returns {Promise<string>} - 模型返回的文本内容
*/
export async function getCompletion(prompt) {
const response = await client.chat.completions.create({
model: process.env.DEEPSEEK_MODEL,
messages: [
{ role: 'user', content: prompt }
]
});
return response.choices[0].message.content;
}三、 核心 Prompt 的编写规则与设计哲学
在利用大模型处理 NLP 任务时,Prompt 的设计直接决定了输出结果的稳定性与准确性。优秀的提示词工程应当严格遵循以下四大核心规则:
1. 清晰且具体的指令
大模型虽然具备强大的泛化推理能力,但模糊的指令会导致输出失控。指令必须明确告诉模型"做什么"以及"不能做什么"。
- 原则:使用明确的动作谓词,如"识别"、"提取"、"判定"、"概括",并通过明确的分隔符(如三个反引号 ```)将指令与待处理的文本数据完全隔开,避免指令混淆(Prompt Injection)。
2. 给定输出格式
在企业级全栈开发中,大模型的输出结果通常需要被后台程序进一步解析和处理。因此,必须约束模型的输出格式(如单单词、列表、JSON 对象、布尔值等),并限制字数。
- 应用示例 :要求大模型仅输出 "正面" 或 "负面";或者要求其输出带有固定键名(如
sentiment、product)的标准 JSON 字符串,以便通过JSON.parse()转换为程序结构。
3. 给出具体示例 (Few-shot)
当面对复杂的推理逻辑或需要特定输出风格时,通过在提示词中提供一个或多个"输入-输出"对的示例(即 Few-shot Prompting),能够显著提升模型的类比学习能力与格式对齐率。
4. 分步骤引导大模型
对于需要处理多项任务的复杂逻辑,应当采用类似思维链(Chain of Thought)的逻辑,将大任务拆解为清晰的子步骤,引导模型按部就班地进行推理。例如:先判定情感 → \rightarrow → 再识别愤怒情绪 → \rightarrow → 随后提取商品与品牌 → \rightarrow → 最后组装输出。
四、 渐进式演进历程:NLP 核心任务的代码实现与演进分析
以下内容完整还原了从简单任务到复杂场景的工程化演进过程。通过不同的 Prompt 阶段,体现了如何逐步应用上述四大编写规则。
1. 情感分类与多维推理演进
在实际业务(如电商客服质检、产品反馈监控)中,系统需要对用户评论进行自动化处理。以下首先展示作为输入源的原始文本数据定义:
javascript
const lamp_review_zh = '我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!';基于该文本源,Prompt 通过增加限制与规则逐步升级:
阶段 A:基础情感分类
- 意图:利用分隔符对评论进行基础情感倾向判定。
javascript
const prompt=`
以下用三个反引号分隔的产品评论的情感是什么?
评论文本:\`\`\`${lamp_review_zh}\`\`\`
`输出:

阶段 B:限制输出字数与范围 (规则 2)
- 意图:消除模型的冗余解释,使其仅返回标准状态,便于后台程序直接分类。
javascript
const prompt=`
以下用三个反引号分隔的产品评论的情感是什么?
用一个单词回答:正面 或 负面
评论文本:\`\`\`${lamp_review_zh}\`\`\`
`输出:

阶段 C:格式化为以逗号分隔的列表 (规则 2)
- 意图:控制输出密度,提取多个情感标签并以结构化符号分割。
javascript
const prompt=`
识别以下用三个反引号分隔的产品评论的作者表达的情感。
包含不超过五个项目。
将答案格式化为以逗号分隔的单词列表。
评论文本:\`\`\`${lamp_review_zh}\`\`\`
`输出:

阶段 D:特定情绪定向判定
- 意图:用于售后后台的紧急预警模块,快速筛选客户是否表达了"愤怒"情绪。
javascript
const prompt=`
以下用三个反引号分隔的产品评论是否表达了愤怒?
给出是或否的答案。
评论文本:\`\`\`${lamp_review_zh}\`\`\`
`输出:

阶段 E:特定关键信息提取与标准 JSON 输出 (规则 1、2)
- 意图 :实现信息提取(Information Extraction)任务。将非结构化文本转化为带有固定键名(
product,brand)的 JSON 对象,若信息不存在则填充默认值。
javascript
const prompt=`
从评论文本中识别以下项目:
- 评论者购买的商品
- 制造该商品的公司
评论文本用三个反引号分隔。将你的响应格式以"物品"(product)和"品牌"(brand)为键 的JSON对象。
如果信息不存在,请使用**未知**作为值。
评论文本:\`\`\`${lamp_review_zh}\`\`\`
`输出:

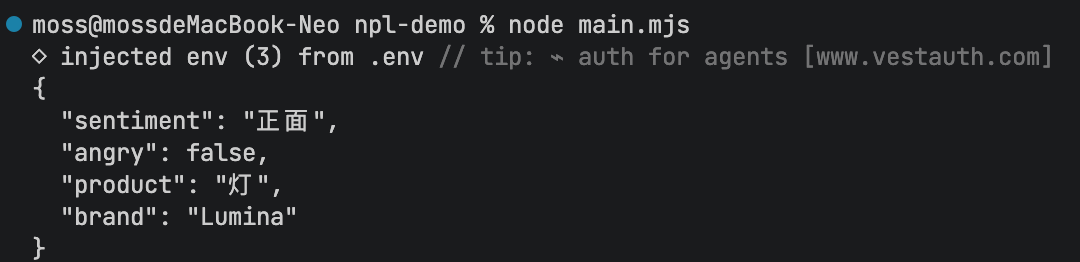
阶段 F:复合型多任务并行处理 (规则 1、2、4)
- 意图:将情感倾向、情绪判定、实体提取组合为一个复合任务。通过分步骤的明确限制,强制要求将特定字段转换为布尔值,并压缩输出体积。
javascript
const prompt=`
从评论文本中识别以下项目:
- 情绪(正面或负面)
- 是否表达了愤怒(是或否)
- 评论者购买的商品
- 制造该物品的公司
评论用三个反引号分隔。
将您的响应格式化为JSON对象。以"sentiment"、"angry"、"product"、"brand"为键。
如果信息不存在,请使用**未知**作为值。
让你的回复尽可能简短。
将anger值格式化为布尔值
评论文本:\`\`\`${lamp_review_zh}\`\`\`
`输出:
2. 主题推断与多主题匹配任务
主题推断任务可以对海量文本(如新闻、政务报告)进行自动标签化分类,用于内容索引或推荐系统。以下为分析所使用的新闻文本:
javascript
const story_zh = `
在政府最近进行的一项调查中,要求公共部门的员工对他们所在部门的满意度进行评分。
调查结果显示,NASA 是最受欢迎的部门,满意度为 95%。
一位 NASA 员工 John Smith 对这一发现发表了评论,他表示:
"我对 NASA 排名第一并不感到惊讶。这是一个与了不起的人们和令人难以置信的机会共事的好地方。我为成为这样一个创新组织的一员感到自豪。"
NASA 的管理团队也对这一结果表示欢迎,主管 Tom Johnson 表示:
"我们很高兴听到我们的员工对 NASA 的工作感到满意。
We拥有一支才华横溢、忠诚敬业的团队,他们为实现我们的目标不懈努力,看到他们的辛勤工作得到回报是太棒了。"
调查还显示,社会保障管理局的满意度最低,只有 45%的员工表示他们对工作满意。
政府承诺解决调查中员工提出的问题,并努力提高所有部门的工作满意度。
`任务 A:自主多主题提炼
- 意图:让模型自主提炼出五个核心主题,并严格限制每个主题的字数与分隔符号。
javascript
const prompt=`
确定一下给定文本中讨论的五个主题。
每个主题用1-2个单词概括。
输出时用逗号分隔。
给定文本:${story_zh}
`输出:

任务 B:零样本多标签分类
- 意图 :给定一个标准的主题候选列表(
topicList),让模型批量判断文本是否提及了该话题,并输出由0或1组成的匹配列表。
javascript
const topicList=[
'美国国家航空航天局','地方政府','工程','员工满意度','联邦政府'
]
const prompt=`
判断主题列表中每一项是否是给定文本中的一个话题
以列表的形式给出答案,每个主题用0或1。
主题列表:${topicList.join(',')}
给定文本L:${story_zh}
`输出:

3. 聚焦特定维度的文本总结与批量文本流处理
文本总结(Summarization)是行政、编辑以及管理岗位降本增效的核心场景。利用同一个文本源(熊猫公仔评论 prod_review_zh),可以通过改变提示词的焦点,实现完全不同侧重点的摘要。
javascript
const prod_review_zh = `
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
`维度 A:通用信息概括 (字数约束)
- 意图:在 30 个词汇内对评论进行高度压缩。
javascript
const prompt=`
您的任务是从点赞商务网站上生成一个产品评论的简短摘要。
请对三个反引号之间的评论文本进行概括,最多30个词汇。
评论文本:\`\`\`${prod_review_zh}\`\`\`
`输出:

维度 B:聚焦产品运输 (定向信息压缩)
- 意图:过滤并仅提取物流、快递相关的服务表现。
javascript
const prompt=`
您的任务是从点赞商务网站上生成一个产品评论的简短摘要。
请对三个反引号之间的评论文本进行概括,最多30个词汇。
并且聚焦在产品运输上。
评论文本:\`\`\`${prod_review_zh}\`\`\`
`输出:

维度 C:聚焦价格与质量
- 意图:引导大模型筛选性价比与材质质量相关的文本片段。
javascript
const prompt=`
您的任务是从点赞商务网站上生成一个产品评论的简短摘要。
请对三个反引号之间的评论文本进行概括,最多30个词汇。
并且聚焦在产品价格和质量上。
评论文本:\`\`\`${prod_review_zh}\`\`\`
`输出:

维度 D:多样本批量并行循环化处理
- 意图 :在实际工程中,数据往往以数组形式成批出现。通过 JavaScript 的
for...of循环遍历不同的产品评论,在同一个结构化 Prompt 内实现高吞吐量的信息提炼。以下展示了其余的多品类原始评论文本定义:
javascript
const review_1=prod_review_zh;
const review_2 = `
我想为我的卧室找一个漂亮的灯,这款灯还有额外的存储空间,价格也不太高。\
购买后很快就收到了,两天就送到了。但在运输过程中,灯的拉链断了,公司态度\
很好,发来了一条新的。新的拉链也在几天内就到了。这个灯非常容易装配。后来,我\
发现缺少一个部分,所以我联系了他们的客户支持,他们很快就给我寄来了缺失的部件\
!我觉得这是一家非常关心他们的客户和产品的好公司。
`
// review for an electric toothbrush
const review_3 = `
我的牙科卫生师推荐我使用电动牙刷,这就是我购买这款牙刷的原因。目前为止,我发现电池的\
续航时间颇为令人印象深刻。在初次充电并在第一周保持充电器插头插入以调节电池状态之后,我\
已经将充电器拔掉,并在过去的3周里,每天两次刷牙都使用同一次充电。然而,这款牙刷的刷头实\
在太小了。我见过的婴儿牙刷都比这个大。我希望牙刷头能做得更大一些,搭配不同长度的刷毛更好\
地清洁牙齿间缝,因为现有的无法做到这一点。总的来说,如果你能以大约50美元的价格购入这款电动\
牙刷,那它就物超所值。厂家配套的替换刷头价格相当昂贵,但你可以买到价格更为合理的通用款。\
使用这款牙刷让我感觉像每天都去看了牙医一样,我的牙齿感觉洁净如新!
`
// review for a blender
const review_4 = `
他们还在11月把17件套系统以大约$49的优惠价格销售,几乎是五折。但不明原因(轻易就可以归咎为价格欺诈)\
在到了12月第二周,同一套系统的价格一下儿飙升到了$70-$89之间。11件套系统的价格也从之前的优惠价$29上\
升了大概$10。看上去还算公道,但如果你仔细观察底部,会发现刀片锁定的部位相比几年前的版本要略逊一筹,所\
以我打算非常小心翼翼地使用(例如,我会将像豆子、冰块、大米之类的硬质食材先用搅拌机压碎,然后调到我需要\
的份量,再用打发刀片研磨成更细的粉状,制作冰沙时我首选交叉刀片,如果需要更细腻些或者少些浆糊状,我会换成\
平刀)。在制作果昔时,把将要用的水果和蔬菜切片冷冻是个小技巧(如果你打算用菠菜,要先稍微焖炖软,再冷冻,\
制作雪葩时,用一个小到中号的食品加工器就行)这样就不用或者很少加冰块到你的果昔了。大约一年后,电机开始发出\
一些可疑的声音。我联系了客服,但保修期已经过期,所以我只好另购一台。友情提示:这类产品的整体质量都在下滑,\
所以他们更多的是利用品牌知名度和消费者的忠诚度来保持销售。我在两天之后就收到了它。
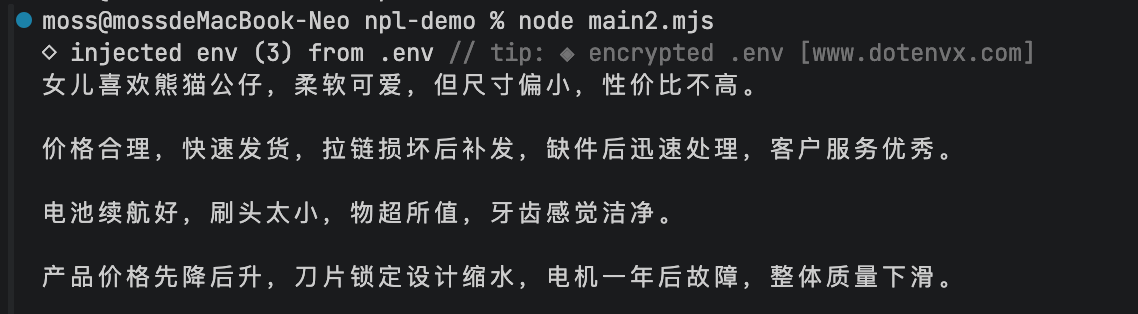
`通过构建数组,执行批量文本摘要提取:
javascript
const reviews=[review_1,review_2,review_3,review_4];
for(let review of reviews){
const prompt=`
你的任务是从电子商务网站上的产品评论中提取相关信息。
请对三个反引号之间的评论文本进行概括,最多20个词汇。
评论文本:\`\`\`${review}\`\`\`
`
const response = await getCompletion(prompt);
console.log(response,'\n');
}输出:
五、 结论
通过上述从单任务到流处理的工程实践可以发现,大模型时代的 NLP 开发核心已从"编写复杂的特征算法"转变为"设计高质量的结构化指令"。
在企业 LLM 能力接入的过程中,只要严格遵循清晰具体指令 、预设输出格式 、引入示例对齐 以及拆解复杂步骤这四大基本原则,开发者便能以极低的成本,快速构建出具备工业级鲁棒性的情感推断、信息抽取与定制化摘要系统,为企业后台业务流带来颠覆性的生产力提升。