1、概述
ARM 架构的应用二进制接口(ABI)为所有原生可执行代码模块制定了一套必须遵循的基础规则,以确保它们能够正确地进行协同工作。在此基础上,针对特定的编程语言(如 C++),ABI 还会提供额外的补充规范。此外,不同的操作系统或运行环境(例如 Linux)为了满足自身的特定需求,也可能会在 ARM ABI 基础规范之上,进一步定义附加的规则。
就 AArch64 架构而言,其 ABI 主要由以下几个核心组件构成:
ELF(可执行与可链接格式)
AArch64 架构的 ELF 规范(ELF for the ARM 64-bit Architecture)专门定义了该架构下的目标文件(Object file)和可执行文件的二进制格式。
PCS(过程调用标准)
AArch64 ABI 的过程调用标准(AAPCS64)规定了子程序如何被独立编写、编译和汇编,并最终实现无缝协同工作。它明确了调用方与被调用方之间的"契约",或者说是例程与其运行环境之间的交互规则。例如,发起函数调用时必须履行的义务,以及栈内存的具体布局方式等。
DWARF(调试信息格式)
DWARF 是一种广泛使用的标准化调试数据格式。AArch64 的 DWARF 规范基于 DWARF 3.0 版本,但增加了一些针对 ARM 架构的附加规则。(更多细节请参阅 DWARF for the ARM 64-bit Architecture (AArch64) 官方文档)。
C/C++ 库
ARM C/C++ 编译器及浮点支持用户指南(ARM Compiler ARM C and C++ Libraries and Floating-Point Support User Guide)详细描述了 ARM 提供的标准 C/C++ 运行时库及其底层支持。
C++ ABI
AArch64 架构的 C++ 应用二进制接口标准(C++ Application Binary Interface Standard for the ARM 64-bit Architecture)定义了通用的 C++ ABI 规范,确保不同编译器生成的 C++ 代码能够正确链接和交互。
这篇文章主要关注 AAPCS64,因为它和性能分析、汇编阅读、跨语言互调、异常处理、任务切换都直接相关。。
2、AArch64 过程调用标准中的寄存器使用规范
深入理解寄存器使用的底层规范是非常有价值的。只有掌握了参数是如何在寄存器间传递和分配的,你才能:
- 编写出性能更优、更贴近硬件特性的 C/C++ 代码。
- 在阅读反汇编代码时游刃有余,快速理清程序逻辑。
- 亲自编写或优化底层的汇编语言代码。
- 实现跨语言的无缝互调(例如在 C 语言中正确调用汇编或 Rust 编写的函数)。
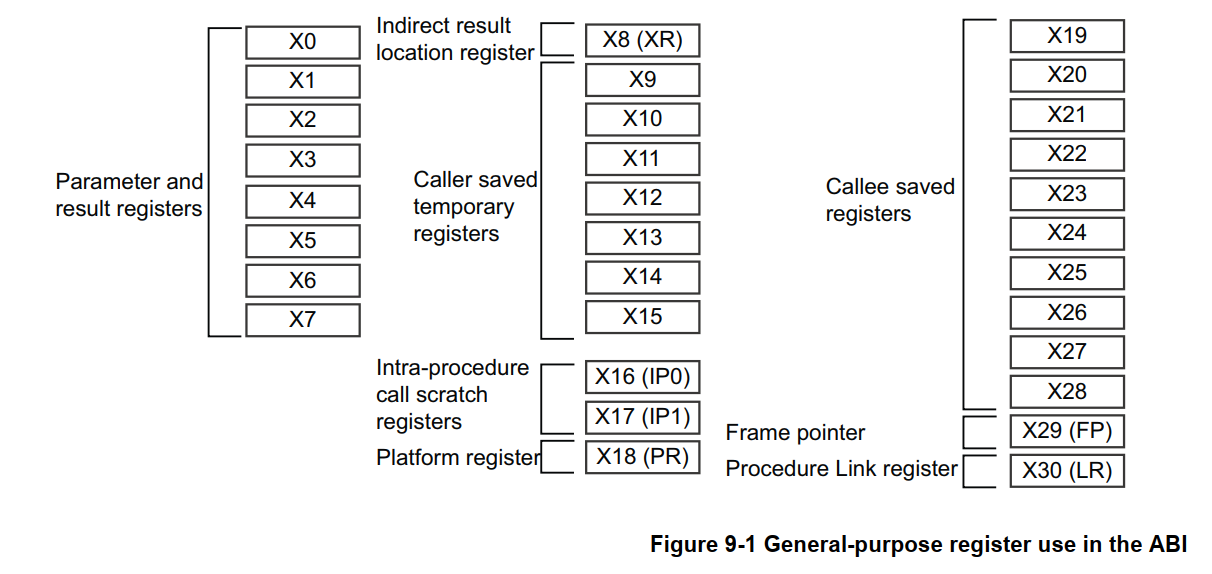
2.1 通用寄存器(General-Purpose Registers)中的参数传递
对于函数调用(function call)而言,通用寄存器(general-purpose registers)被划分为四类:
参数寄存器 (Argument registers, X0-X7)
这些寄存器用于:
- 向函数传递参数
- 返回函数结果
它们也可以作为:
- scratch registers(临时工作寄存器)
- caller-saved register variables(调用者保存的寄存器变量------和后面的 Caller-saved temporary registers 一个意思)
用于在一个函数内部、以及对其他函数调用之间保存中间值(intermediate values)。
由于提供了 8 个参数寄存器,因此相比 AArch32,大幅减少了为了传递参数而将数据 spill 到 stack 的需求。
Caller-saved 临时寄存器 (Caller-saved temporary registers, X9-X15)
如果调用者(caller)希望这些寄存器中的值在调用其他函数后仍然保持不变,那么调用者必须在自己的 stack frame 中保存这些寄存器。
这些寄存器可以被被调用函数(called subroutine)自由修改,并且无需在返回调用者之前执行 save/restore 操作。
换句话说:
X9-X15 属于 caller-saved registers,被调用函数可以直接覆盖(clobber)它们。
Callee-saved 寄存器 (Callee-saved registers, X19-X29)
这些寄存器由被调用函数栈帧(callee frame) 保存。
被调用函数可以修改这些寄存器,但前提是:
- 在使用之前先保存(save)
- 在返回之前恢复(restore)
从 ABI 的角度来说:
被调用函数必须保证 X19-X29 在函数返回时保持与进入函数时相同的值。
具有特殊用途的寄存器 (Registers with a special purpose: X8, X16-X18, X29, X30)
- X8:Indirect result register(间接结果寄存器)。用于传递间接结果的地址位置,例如当函数需要返回一个大型结构体时。
- X16 和 X17:IP0 和 IP1,即 Intra-procedure-call temporary registers(过程内调用临时寄存器)。它们可被 Call veneers(调用跳板代码)及类似代码使用,或作为子程序调用之间的中间值临时寄存器。它们会被函数修改(Corruptible)。Veneers 是由链接器自动插入的小段代码,例如当分支目标超出了 Branch instruction(分支指令)的范围时。
- X18:Platform register(平台寄存器),专为 Platform ABIs 保留。在未对其赋予特殊含义的平台上,它可以作为一个额外的临时寄存器使用。
- X29:Frame pointer register (FP),即 Frame pointer(帧指针寄存器)。
- X30:Link register (LR),即 Link register(链接寄存器)。
图 9-1 显示了 64 位 X 寄存器。有关寄存器的更多信息,请参阅 深入理解 ARMv8-A|处理器模式与寄存器。
2.2 间接结果位置 X8
再次说明,X8(XR)寄存器用于传递间接结果的存储位置。以下是部分代码:
c
struct struct_A
{
int i0;
int i1;
double d0;
double d1;
} AA;
struct struct_A foo(int i0, int i1, double d0, double d1)
{
struct struct_A A1;
A1.i0 = i0;
A1.i1 = i1;
A1.d0 = d0;
A1.d1 = d1;
return A1;
}
void bar()
{
AA = foo(0, 1, 1.0, 2.0);
}可以使用如下命令编译、反汇编:
c
~/Desktop/ARM_ToolChin/gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu/bin/test$ ls
test.c
~/Desktop/ARM_ToolChin/gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu/bin/test$ ../aarch64-linux-gnu-gcc -c test.c
~/Desktop/ARM_ToolChin/gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu/bin/test$ ls
test.c test.o
~/Desktop/ARM_ToolChin/gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu/bin/test$ ../aarch64-linux-gnu-objdump -S test.o
test.o: file format elf64-littleaarch64
Disassembly of section .text:
0000000000000000 <foo>:
// 函数 foo 开始:返回一个较大的结构体
// 在 ARM64 中,当返回的结构体过大无法放入寄存器时,
// 调用者会在栈上分配空间,并将该空间的地址通过 x8 寄存器隐式传递给被调用者
0: d10103ff sub sp, sp, #0x40 // 为当前函数分配 64 字节 (0x40) 的栈空间
4: aa0803e2 mov x2, x8 // 将 x8 中隐式传入的"返回值内存地址"保存到 x2 中
8: b9001fe0 str w0, [sp, #28] // 将第1个参数 i0 (w0) 存入当前栈帧
c: b9001be1 str w1, [sp, #24] // 将第2个参数 i1 (w1) 存入当前栈帧
10: fd000be0 str d0, [sp, #16] // 将第3个参数 d0 (d0) 存入当前栈帧
14: fd0007e1 str d1, [sp, #8] // 将第4个参数 d1 (d1) 存入当前栈帧
// 开始组装结构体 A1,并直接写入调用者提供的内存地址 (x2)
18: b9401fe0 ldr w0, [sp, #28] // 读取参数 i0
1c: b9002be0 str w0, [sp, #40] // 暂存到栈上 (编译器生成的临时变量/局部变量)
20: b9401be0 ldr w0, [sp, #24] // 读取参数 i1
24: b9002fe0 str w0, [sp, #44] // 暂存到栈上
28: fd400be0 ldr d0, [sp, #16] // 读取参数 d0
2c: fd001be0 str d0, [sp, #48] // 暂存到栈上
30: fd4007e0 ldr d0, [sp, #8] // 读取参数 d1
34: fd001fe0 str d0, [sp, #56] // 暂存到栈上
38: aa0203e3 mov x3, x2 // 将目标返回地址 (x2) 复制到 x3,准备进行内存拷贝
3c: 9100a3e2 add x2, sp, #0x28 // x2 指向栈上暂存的结构体数据的起始地址 (sp + 40)
40: a9400440 ldp x0, x1, [x2] // 从栈上加载前 16 字节 (i0, i1, d0的前半部分) 到 x0, x1
44: a9000460 stp x0, x1, [x3] // 将这 16 字节存入目标返回地址 (x3)
48: f9400840 ldr x0, [x2, #16] // 从栈上加载剩余的 8 字节 (d1) 到 x0
4c: f9000860 str x0, [x3, #16] // 将这 8 字节存入目标返回地址的偏移 16 处
50: 910103ff add sp, sp, #0x40 // 销毁当前栈帧,释放 64 字节栈空间
54: d65f03c0 ret
0000000000000058 <bar>:
// 函数 bar 开始:调用 foo 并接收结构体返回值
58: a9bc7bfd stp x29, x30, [sp, #-64]! // 保存上一级函数的帧指针(x29)和返回地址(x30),并分配 64 字节栈空间
5c: 910003fd mov x29, sp // 更新当前栈帧指针 x29 指向当前栈顶
60: f9000bf3 str x19, [sp, #16] // 保存被调用者保存寄存器 x19 (x19 后面会用于保存全局变量 AA 的地址)
// 注意,这里·不会保存所有的 Callee-saved 寄存器,只会保存,本函数后面可能破坏的 Callee-saved 寄存器
64: 90000000 adrp x0, 18 <foo+0x18> // 获取全局变量 AA 所在内存页的基地址
68: 91000013 add x19, x0, #0x0 // 计算全局变量 AA 的精确地址,并保存到 x19 中
//从这里就知道,不管后面怎么进行函数调用,调用者 <bar> 认为 x19 寄存器都是不会被破坏的,所以放心的用来存储自己想要的值
6c: 910083a0 add x0, x29, #0x20 // 在当前栈帧中分配 32 字节作为 foo 的临时返回值接收区,x0 指向该区域
70: aa0003e8 mov x8, x0 // 【关键】将临时接收区的地址放入 x8,作为隐式参数传给 foo
74: 1e601001 fmov d1, #2.0 // 准备第4个参数 d1 = 2.0
78: 1e6e1000 fmov d0, #1.0 // 准备第3个参数 d0 = 1.0
7c: 52800021 mov w1, #0x1 // 准备第2个参数 i1 = 1
80: 52800000 mov w0, #0x0 // 准备第1个参数 i0 = 0
84: 94000000 bl 0 <foo> // 调用 foo 函数
// foo 返回后,将结构体数据从栈上的临时接收区拷贝到全局变量 AA 中
88: aa1303e3 mov x3, x19 // 将全局变量 AA 的地址 (x19) 放入 x3 作为拷贝目标
8c: 910083a2 add x2, x29, #0x20 // x2 指向栈上 foo 返回的临时结构体数据起始地址
90: a9400440 ldp x0, x1, [x2] // 从栈上加载前 16 字节
94: a9000460 stp x0, x1, [x3] // 写入全局变量 AA
98: f9400840 ldr x0, [x2, #16] // 从栈上加载剩余的 8 字节
9c: f9000860 str x0, [x3, #16] // 写入全局变量 AA 的剩余部分
a0: d503201f nop
a4: f9400bf3 ldr x19, [sp, #16] // 恢复之前保存的 x19 寄存器
a8: a8c47bfd ldp x29, x30, [sp], #64 // 恢复上一级函数的帧指针和返回地址,并释放 64 字节栈空间
ac: d65f03c0 ret // 返回到调用 bar 的地方在本例中,由于结构体大小(24字节)超出了 AAPCS64 规范的 16 字节寄存器直接返回阈值,编译器采用了一套"隐式指针传参 + 内存拷贝"的底层机制,其精妙之处体现在:
- X8 寄存器的隐式传参:bar() 在栈上为返回值预分配内存,并将其地址通过 X8 传给 foo()。X8 作为专用的"间接结果寄存器",不会挤占 X0-X7 的常规参数传递通道,保证了参数传递的可用性。
- 防御性的寄存器转移:由于 X8 属于通用寄存器,foo() 内部随时可能将其作为临时变量而"损坏"。因此 foo() 在入口处第一时间将 X8 转移至 X2 寄存器进行保护,而 bar() 则直接通过 SP 寻址访问返回结构,确保绝对安全。
- 跨调用的寄存器复用(X19):bar() 需要获取全局变量 AA 的地址并在调用 foo() 后继续使用。编译器巧妙地选用了 callee-saved 寄存器 X19 来保存该地址,既避免了被 foo() 破坏,又避免了使用 caller-saved 寄存器带来的额外压栈开销。
- 零拷贝的内存搬运:foo() 组装完结构体后,利用 ARM64 强大的内存操作指令(ldp/stp 和 ldr/str),以 16 字节和 8 字节为单位,将数据按块批量拷贝到目标内存,极大减少了 CPU 指令周期。
- foo 函数之所以没有保存 FP(x29)和 LR(x30),是因为它在函数调用链中属于 "叶子函数(Leaf Function)"
图 9-2 展示了一个 AAPCS64 栈帧的结构。帧指针(X29)应指向保存在栈上的上一级帧指针,且保存的链接寄存器(LR,即 X30)应紧随其后存储。栈帧链中的最后一个(即最底层的)帧指针应被设置为 0。此外,栈指针(SP)必须始终保持 16 字节对齐。栈帧的具体布局可能会存在一定差异,特别是在处理可变参数函数或无栈帧函数(frameless functions)时。如需了解详细信息,请参阅 AAPCS64 规范文档。
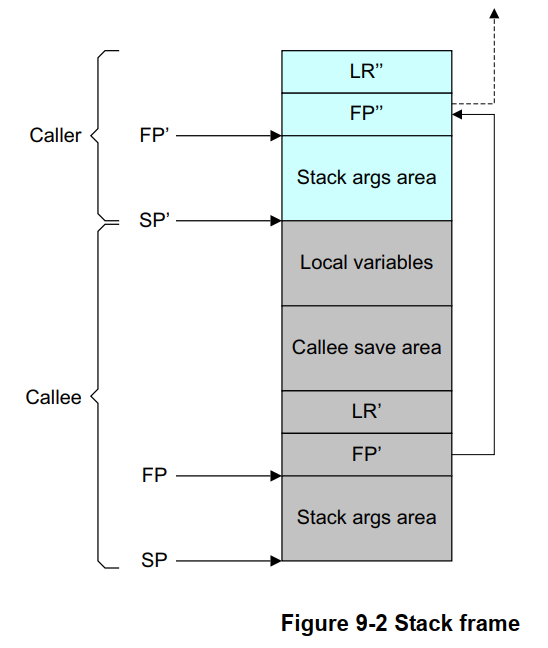
注意:AAPCS(ARM 架构过程调用标准)仅规定了 FP 和 LR 保存块的布局,以及这些块之间如何链接。至于图 9-2 中的其他所有内容(包括两个函数栈帧之间边界的确切位置),规范均未作限定,编译器可以自由选择其布局方式。
2.3、NEON 和浮点寄存器中的参数
ARM64 架构同样拥有 32 个寄存器(v0-v31),它们可供 NEON 和浮点运算使用。访问这些寄存器时,使用的名称会随之改变,以指示当前操作的位宽大小。
与 AArch32 架构不同,在 AArch64 中,NEON 和浮点寄存器的 128-bit 视图和 64-bit 视图并不会跨越多个寄存器。因此,q1、d1 和 s1 实际上指向的是寄存器组(register bank)中的同一个物理寄存器。
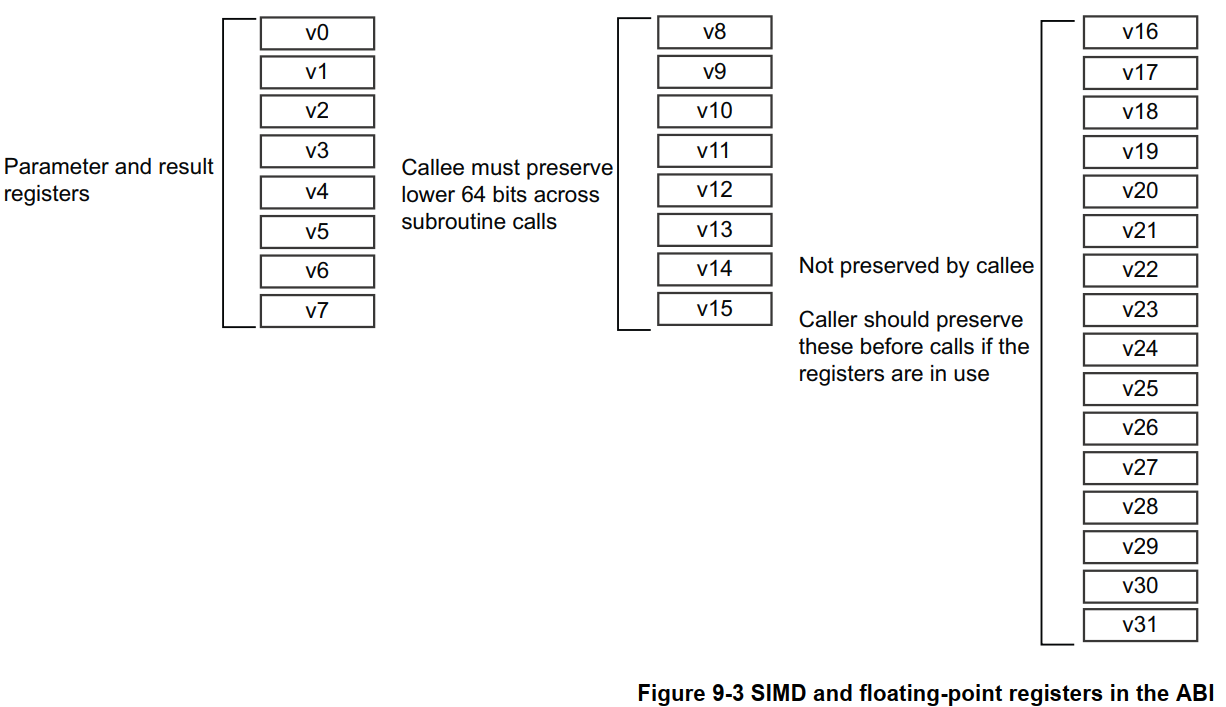
在 AAPCS64 规范中,这些浮点/SIMD 寄存器的使用规则如下:
- V0-V7:用于向子程序传递参数值,以及从函数返回结果值。它们也可用于在例程内部保存中间计算值(但通常仅在两次子程序调用之间有效)。
- V8-V15:属于 callee-saved 寄存器,被调用者(callee)在子程序调用期间必须保留它们。不过,只需保留这些寄存器中存储值的低 64 bits(即 d8-d15)即可。
- V16-V31:属于 caller-saved 寄存器,无需被调用者保留(如果需要跨调用保存,则由调用者 caller 自行负责)。
3、从 ABI 走到内核实现:SylixOS 上下文切换
到这里为止,我们说的都还是"普通函数调用"的 ABI。内核调度和异常处理会更进一步:它们要把"寄存器里的执行现场"保存到内存里,再在未来某个时刻恢复回来。
这时就不只是 AAPCS64 了,还会叠加一层由操作系统自己定义的"上下文 ABI"。
3.1 软件上下文长什么样
arch_regs.h 里定义了 ARCH_REG_CTX:
c
typedef struct {
ARCH_REG_T REG_ulSmallCtx;
ARCH_REG_T REG_ulReg[31];
ARCH_REG_T REG_ulSp;
ARCH_REG_T REG_ulPc;
ARCH_REG_T REG_ulPstate;
ARCH_REG_T REG_ulTPIDR_EL0;
} ARCH_REG_CTX;它表达了两层含义:
REG_ulReg[] + SP + PC + PSTATE:这是一个"可恢复执行流"的最小集合REG_ulSmallCtx:标记当前保存的是 small context 还是 big context
在这套实现里:
REG_ulSmallCtx == 1:small contextREG_ulSmallCtx == 0:big context
注意,REG_ulPstate 在这里保存的并不是"完整 PSTATE 的所有位",而是实现真正关心的那部分状态。比如 SAVE_PSTATE 宏里实际抓的是 NZCV 和 DAIF,恢复时再拼上 EL1h 所需模式位写回 SPSR_EL1。
3.2 任务第一次启动:small context 从何而来
arm64Context.c 里的 archTaskCtxCreate() 会为新任务构造初始上下文:
c
PLW_STACK archTaskCtxCreate (ARCH_REG_CTX *pregctx,
PTHREAD_START_ROUTINE pfuncTask,
PVOID pvArg,
PLW_CLASS_TCB ptcb,
PLW_STACK pstkTop,
ULONG ulOpt)
{
......
pstkTop = (PLW_STACK)ROUND_DOWN(pstkTop, ARCH_STK_ALIGN_SIZE);
pregctx->REG_ulSmallCtx = 1;
pregctx->REG_ulReg[0] = (ARCH_REG_T)pvArg;
pregctx->REG_ulLr = (ARCH_REG_T)pfuncTask;
pregctx->REG_ulPc = (ARCH_REG_T)pfuncTask;
pregctx->REG_ulSp = (ARCH_REG_T)pfpctx;
......
}这段代码很值得细看:
- 新任务一开始就是
small context x0预置为任务入口参数LR和PC都被设置为任务入口函数SP指向已经对齐并准备好的初始栈顶
后续 archTaskCtxStart() 只需要根据 CTX_TYPE 选择恢复 small 或 big context,然后通过 ERET 进入该任务即可。
asm
FUNC_DEF(archTaskCtxStart)
LDR X8, [X0]
LDR X9, [X8, #CTX_TYPE_OFFSET]
CMP X9, #0
B.NE _RestoreSmallCtx
RESTORE_BIG_REG_CTX这里有一个容易让人停顿的细节:为什么 RESTORE_SMALL_REG_CTX 会执行 LDP X0, X1, [X8, #XGREG_OFFSET(0)],而 SAVE_SMALL_REG_CTX 却没有去保存全部易失寄存器?
关键点在于,small context 同时服务于两条路径:
- 普通任务切换
- 新任务首启
对"新任务首启"来说,x0 是有明确语义的,它在 archTaskCtxCreate() 里被预填为任务入口参数;而 x1 在这条路径上通常没有额外的 ABI 语义要求,它只是因为恢复宏采用了成对装载指令 ldp,顺手和 x0 一起被加载出来。
换句话说,这里真正需要关心的是:
x0必须正确,因为它承载任务入口参数x1被一起恢复,更多是实现上的统一和指令配对便利,并不表示 small context 必须像 big context 一样严肃地保存全部 caller-saved 现场
3.3 为什么正常任务切换只保存 small context
看 arm64ContextAsm.S:
asm
FUNC_DEF(archTaskCtxSwitch)
LDR X8, [X0]
SAVE_SMALL_REG_CTX
MOV X19, X0
BL _SchedSwp
LDR X8, [X19]
LDR X9, [X8, #CTX_TYPE_OFFSET]
CMP X9, #0
B.NE _RestoreSmallCtx
RESTORE_BIG_REG_CTXSAVE_SMALL_REG_CTX 的核心内容是:
asm
MOV X9, #1
STR X9, [X8, #CTX_TYPE_OFFSET]
STP X19, X20, [X8, #XGREG_OFFSET(19)]
STP X21, X22, [X8, #XGREG_OFFSET(21)]
STP X23, X24, [X8, #XGREG_OFFSET(23)]
STP X25, X26, [X8, #XGREG_OFFSET(25)]
STP X27, X28, [X8, #XGREG_OFFSET(27)]
STP X29, LR, [X8, #XGREG_OFFSET(29)]
SAVE_PSTATE
MOV X9, SP
STR X9, [X8, #XSP_OFFSET]
STR LR, [X8, #XPC_OFFSET]为什么这里只存 x19-x29、LR、SP 和必要状态?
因为任务切换发生在一个普通函数调用边界上。当前任务主动进入调度器时,它遵守的就是 AAPCS64:
- caller-saved 寄存器本来就不保证跨调用保留
- callee-saved 寄存器必须恢复
这里顺手解释一下术语:ABI 语境里的 volatile / non-volatile 说的是"跨一次函数调用后,寄存器中的值是否允许被破坏"。
volatile register:可以被被调用者直接覆盖,通常对应 caller-savednon-volatile register:被调用者若要使用,必须先保存、返回前再恢复,通常对应 callee-saved
它和 C 语言里的 volatile 关键字不是一回事。
所以对"从一个普通执行点切到调度器,再从调度器切到另一个任务"这件事来说,保存 non-volatile 集合已经足够。
这正是 ABI 对操作系统最直接的帮助:调度器不需要在每一次线程切换时都无脑保存全部寄存器。
不过要注意两点:
-
small context不是"只含x19-x29"- 实现里还保存了恢复控制流必需的
SP、PC/LR、PSTATE - 某些配置下还会保存
x18或TPIDR_EL0
- 实现里还保存了恢复控制流必需的
-
RESTORE_SMALL_REG_CTX用的是ERET,不是ret- 这说明这里恢复的不只是"函数返回地址"
- 还包括异常返回寄存器
ELR_EL1/SPSR_EL1
也就是说,这套线程恢复路径虽然借用了 AAPCS64 的寄存器保存责任,但最终落地成的是"异常返回式"的线程切入。
对应的恢复代码如下,注意它不仅恢复 x19-x29,还会恢复 SP、ELR_EL1、SPSR_EL1,最后走 ERET:
asm
MACRO_DEF(RESTORE_SMALL_REG_CTX)
LDR X1, [X8, #XSP_OFFSET]
MOV SP, X1
RESTORE_PSTATE
LDR X1, [X8, #XPC_OFFSET]
MSR ELR_EL1, X1
LDP X0, X1, [X8, #XGREG_OFFSET(0)]
LDP X19, X20, [X8, #XGREG_OFFSET(19)]
LDP X21, X22, [X8, #XGREG_OFFSET(21)]
LDP X23, X24, [X8, #XGREG_OFFSET(23)]
LDP X25, X26, [X8, #XGREG_OFFSET(25)]
LDP X27, X28, [X8, #XGREG_OFFSET(27)]
LDP X29, LR, [X8, #XGREG_OFFSET(29)]
ERET3.4 为什么异常入口必须保存 big context
再看 arm64ExcAsm.S 的 IRQ 入口:
asm
FUNC_DEF(archEL1IrqEntry)
EXC_SAVE_VOLATILE
BL API_InterEnter
CMP X0, #1
BNE 1f
BL API_ThreadTcbInter
EXC_COPY_VOLATILE
EXC_SAVE_NON_VOLATILE
BL API_InterStackBaseGet
MOV SP, X0
2:
BL bspIntHandle
BL API_InterExit
MOV X8, SP
RESTORE_BIG_REG_CTXEXC_SAVE_VOLATILE 和 EXC_SAVE_NON_VOLATILE 分别做两件事:
asm
MACRO_DEF(EXC_SAVE_VOLATILE)
MRS X18, TPIDR_EL1
SUB X18, X18, ARCH_REG_CTX_SIZE
...
STP X0, X1, [X18, #XGREG_OFFSET(0)]
...
STP X16, X17, [X18, #XGREG_OFFSET(16)]
STP X29, LR, [X18, #XGREG_OFFSET(29)]
MRS X2, SPSR_EL1
STR X2, [X18, #XPSTATE_OFFSET]
MOV X2, SP
STR X2, [X18, #XSP_OFFSET]
MRS X2, ELR_EL1
STR X2, [X18, #XPC_OFFSET]
MOV SP, X18
asm
MACRO_DEF(EXC_COPY_VOLATILE)
LDP X9, X10, [SP, #XGREG_OFFSET(0)]
STP X9, X10, [X0, #XGREG_OFFSET(0)]
...
LDP X9, X10, [SP, #XSP_OFFSET]
STP X9, X10, [X0, #XSP_OFFSET]
LDR X9, [SP, #XPSTATE_OFFSET]
STR X9, [X0, #XPSTATE_OFFSET]
MACRO_DEF(EXC_SAVE_NON_VOLATILE)
MOV X1, #0
STR X1, [X0, #CTX_TYPE_OFFSET]
STP X19, X20, [X0, #XGREG_OFFSET(19)]
STP X21, X22, [X0, #XGREG_OFFSET(21)]
STP X23, X24, [X0, #XGREG_OFFSET(23)]
STP X25, X26, [X0, #XGREG_OFFSET(25)]
STP X27, X28, [X0, #XGREG_OFFSET(27)]这三段代码合起来,刚好对应了异常入口的三个阶段:
EXC_SAVE_VOLATILE:先把x0-x17、x29/LR、SP/PC/PSTATE抢救到异常临时栈EXC_COPY_VOLATILE:再把这份临时现场拷贝到最终的ARCH_REG_CTXEXC_SAVE_NON_VOLATILE:补齐x19-x28,并把CTX_TYPE标为 big context
这里要特别强调:EXC_SAVE_VOLATILE 和 EXC_COPY_VOLATILE 不是重复保存,而是两个不同阶段。
-
EXC_SAVE_VOLATILE的目标是立刻抢救现场- 异常一进来,处理代码马上就要执行
BL API_InterEnter - 一旦发生
BL,x0-x17这类 caller-saved / volatile 寄存器就可能被后续函数合法覆盖 - 所以必须先把这批最容易丢失的寄存器,连同
ELR_EL1、SPSR_EL1、原始SP一起,先存到一个绝对安全的临时位置
- 异常一进来,处理代码马上就要执行
-
EXC_COPY_VOLATILE的目标是把刚才抢救下来的快照搬到最终归宿- 对第一次进入中断的情况,最终归宿是当前线程的
ARCH_REG_CTX - 对中断嵌套的情况,最终归宿是异常栈上新开出来的那块上下文区
- 它拷贝的是"刚才保存在临时区里的旧现场",不是再次从 CPU 当前寄存器里重新取一遍值
- 对第一次进入中断的情况,最终归宿是当前线程的
换句话说,这里的设计不是"保存两次同一份活数据",而是:
- 先在异常入口第一时间把易失寄存器抢下来
- 等代码拿到最终目的地址之后,再把这份快照搬过去
之所以只有 volatile 部分需要这样两阶段处理,是因为 x19-x28 这类 non-volatile 寄存器在 AAPCS64 下本来就要求被调用者保持不变,所以即使异常入口先执行了几个 BL,它们的值按约定仍然应该保持为"被打断现场"的值,稍后再执行 EXC_SAVE_NON_VOLATILE 仍然来得及。
这和任务切换完全不是一个场景。
异常是异步打断。CPU 可能在以下任意时刻被中断:
- 函数尚未建立完整栈帧
- caller-saved 寄存器里还放着关键中间值
- 参数寄存器
x0-x7仍然承载着当前计算现场 ELR_EL1/SPSR_EL1刚刚被硬件写入,等待软件接管
所以异常入口不能依赖"caller-saved 反正可以丢"这套函数调用思维。它要做的是:
- 先把易失部分尽快搬到安全区
- 再补齐 non-volatile 部分
- 最终形成一份可完整恢复的 big context
这也是 CTX_TYPE 在异常路径里被设置为 0 的原因。
3.5 异常退出时为什么仍然先看 CTX_TYPE
异常退出的加载入口是 archIntCtxLoad():
asm
FUNC_DEF(archIntCtxLoad)
LDR X8, [X0]
LDR X9, [X8, #CTX_TYPE_OFFSET]
CMP X9, #0
B.NE _RestoreSmallCtx
RESTORE_BIG_REG_CTX这里最关键的一点是:异常退出时,准备恢复的"目标任务"并不一定就是刚才被中断打断的那个任务。
一次中断或异常处理过程中,调度器完全可能重新选择当前任务。因此当 archIntCtxLoad() 被调用时,它面对的是"当前 CPU 最终决定要继续运行的那个 TCB",而这个 TCB 里的上下文来源可能有几种:
-
它可能就是刚才被异常打断的当前任务
这种情况下,它的现场是在异常入口通过
EXC_SAVE_VOLATILE + EXC_SAVE_NON_VOLATILE保存下来的,因此是 big context -
它也可能是另一个早就处于就绪态、但之前是通过普通任务切换被换下去的任务
这种情况下,它保存下来的通常是 small context
-
它甚至可能是一个刚创建、还没有真正跑起来过的新任务
这种情况下,
archTaskCtxCreate()预先构造的也是 small context
所以,archIntCtxLoad() 这里判断 CTX_TYPE,本质上不是在问:
- "我是不是正在从异常返回?"
而是在问:
- "我即将恢复的这个目标任务,它手里的那份上下文,到底是按 small context 保存的,还是按 big context 保存的?"
只有先回答这个问题,后面才能决定:
- 是调用
RESTORE_SMALL_REG_CTX - 还是调用
RESTORE_BIG_REG_CTX
换句话说,异常退出路径是统一入口,但目标任务的上下文来源并不统一 。这就是它即使发生在"异常返回"阶段,仍然必须先看 CTX_TYPE 的根本原因。
而 RESTORE_BIG_REG_CTX 的关键骨架如下:
asm
MACRO_DEF(RESTORE_BIG_REG_CTX)
LDR X1, [X8, #XSP_OFFSET]
MOV SP, X1
RESTORE_PSTATE
LDR X1, [X8, #XPC_OFFSET]
MSR ELR_EL1, X1
LDP X0, X1, [X8, #XGREG_OFFSET(0)]
LDP X2, X3, [X8, #XGREG_OFFSET(2)]
LDP X4, X5, [X8, #XGREG_OFFSET(4)]
LDP X6, X7, [X8, #XGREG_OFFSET(6)]
...
LDP X29, LR, [X8, #XGREG_OFFSET(29)]
LDR X8, [X8, #XGREG_OFFSET(8)]
ERET恢复宏的关键动作有三类:
- 恢复软件上下文中的通用寄存器
- 把保存下来的
PC写回ELR_EL1 - 把保存下来的状态写回
SPSR_EL1 - 最后执行
ERET
这说明异常返回不是普通的 ret:
ret只跳到LReret同时恢复异常级返回地址和处理器状态
因此,只要你在反汇编里看到 ELR_EL1、SPSR_EL1、ERET 这一组组合,就应该立刻意识到:现在谈论的已经不是普通函数 ABI,而是异常级控制流恢复。