
🔥个人主页:爱和冰阔乐
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

🏠博主简介

文章目录
- 前言
- [一、Ollama 是什么](#一、Ollama 是什么)
- 二、硬件配置与模型选型
- 三、安装与存储路径配置
-
- [3.1 安装](#3.1 安装)
- [3.2 迁移模型目录](#3.2 迁移模型目录)
- [3.3 启动校验](#3.3 启动校验)
- 四、模型下载与基础操作
- [五、Modelfile 定制模型](#五、Modelfile 定制模型)
- 六、代码调用
- 七、构建最小RAG知识库
- 八、常见问题与排查
- 总结
前言
去年做课设时,导师要求搭建一个本地知识库,将实验室上百份实验报告和技术文档接入AI辅助检索与摘要。调研后发现大多方案都强依赖云端API------实验室机器部署在内网环境,没有外网访问权限,这条路直接堵死。
后来接触到Ollama,安装后执行 ollama run qwen3:4b,终端返回第一行回复时,体验相当直观:自己的设备、本地模型、无需网络、零调用成本。更关键的是,数据全程在本地流转,不存在隐私合规方面的顾虑。
经过几个月的实际使用,从磕磕绊绊的环境配置到稳定运行的RAG系统,踩了不少坑也积累了一些可复用的经验。这篇文章是一份复盘笔记,聚焦几个核心问题:Windows环境配置、模型存储路径规划、模型选型策略、命令行与API调用方式,以及最小可用的本地RAG知识库实现。
说明:本文不是模型性能测评。不同硬件环境下的运行效果差异显著------CPU、内存、显存、量化版本和上下文长度均会影响实际体验,请将文中建议作为参考路线,结合自身设备条件灵活调整。
一、Ollama 是什么
Ollama 是一个本地大模型运行管理工具,统一处理模型下载、存储、加载、命令行交互和HTTP API服务。以往在本地部署大模型需要手动配置CUDA、驱动、权重文件和推理框架,不同模型还有各自的依赖链,环境搭好半天就过去了。Ollama将这些步骤封装为统一命令,显著降低了上手门槛。
安装后本机运行一个后台服务,默认监听:
text
http://localhost:11434交互方式有两种:终端内通过 ollama run 模型名 直接对话,或通过 /api/chat、/api/generate、/api/embed 等接口在代码中调用。架构上,应用层发送HTTP请求,Ollama服务负责模型加载与推理,两者职责分离,便于集成到现有项目中。
为什么选择本地部署而非云端API?
结合项目中的实际体会,三个场景下本地模型优势明显:
- 数据不出域。实验数据、内部文档、个人笔记等敏感内容全程在本地处理,无需上传第三方平台,满足基本的隐私保护需求。对于涉及未公开研究成果或商业机密的场景,这一点尤为关键。
- 调试成本可控。知识库问答的提示词需要反复迭代优化,每次调云端API都产生费用。本地模型无调用次数限制,适合频繁测试和原型验证,对个人开发者和学生群体非常友好。
- 离线可用。答辩、竞赛、内网部署等无网络环境下的运行需求,本地模型天然支持,无需担心网络波动或服务中断。
二、硬件配置与模型选型
新手容易一开始就拉取大参数模型------下载耗时长,推理速度慢,实际体验与预期落差明显。
选型原则:先确定可用内存和显存,再匹配模型规格。量力而行比一味追求大参数更务实。
| 硬件配置 | 推荐模型 | 适用任务 |
|---|---|---|
| 8GB内存 / 无独显 | Qwen3 0.6B / 1.7B、Llama 3.2 1B | 流程验证、简单问答、文本摘要 |
| 16GB内存 / 6-8GB显存 | Qwen3 4B / 8B、DeepSeek-R1 7B、Gemma 3 4B | 知识库问答、代码辅助、日常主力 |
| 32GB内存 / 12-16GB显存 | Qwen3 14B、DeepSeek-R1 14B、Gemma 3 12B | 长文分析、复杂推理、论文研读 |
| 64GB+ / 24GB+显存 | Qwen3 30B+、DeepSeek-R1 32B | 生产服务、高并发调用 |
实测参考:16GB内存轻薄本,Qwen3 4B + Q4_K_M量化,常规问答响应速度可接受,代码生成与文档摘要质量满足日常开发需求。不建议盲目追求大参数------数据质量和提示词设计往往比模型规模更影响最终效果。很多时候,花时间整理好输入数据比升级模型带来的提升更大。
量化版本选择:q4_K_M 是综合最优解。 体积与速度均衡,精度损失在实际使用中难以察觉。显存充足可升级至 q8_0,研究场景可用 fp16。常规开发与学习使用 q4_K_M 即可,无需为理论上的精度差异付出额外的存储和推理时间成本。
嵌入模型推荐 nomic-embed-text,体积约数百MB,CPU即可流畅运行,满足RAG场景的向量化需求。无需追求更大的嵌入模型,此方案在中小规模知识库上效果足够。
关于模型来源的选择建议。 Ollama模型库涵盖Qwen、Llama、DeepSeek、Gemma等主流系列。中文场景优先考虑Qwen3和DeepSeek-R1系列,对中文理解和生成的支持更为成熟。英文或代码场景Llama和Gemma表现也不错。建议初期选定一个系列深入使用,熟悉后再横向对比,避免在不同模型间反复横跳浪费时间。
三、安装与存储路径配置
3.1 安装
ollama.com 下载Windows安装包,按引导完成。有一个容易被忽略但后果严重的配置:
默认模型存储路径为 C:\Users\<用户名>\.ollama。 单个7B模型约4~5GB,下载三到四个模型后C盘空间即告急。建议安装完成后的第一件事就是迁移目录,不要等C盘变红再处理。
3.2 迁移模型目录
powershell
# 1. 退出Ollama(托盘右键退出,或在服务管理器中停止)
# 2. 将 C:\Users\<用户名>\.ollama 目录整体移动至目标磁盘
# 3. 配置系统环境变量
[此电脑] → [属性] → [高级系统设置] → [环境变量] → 新建系统变量:
变量名:OLLAMA_MODELS
变量值:D:\ollama_models
# 4. 重新启动Ollama验证配置是否生效:
bash
ollama list
# 确认显示的路径指向目标磁盘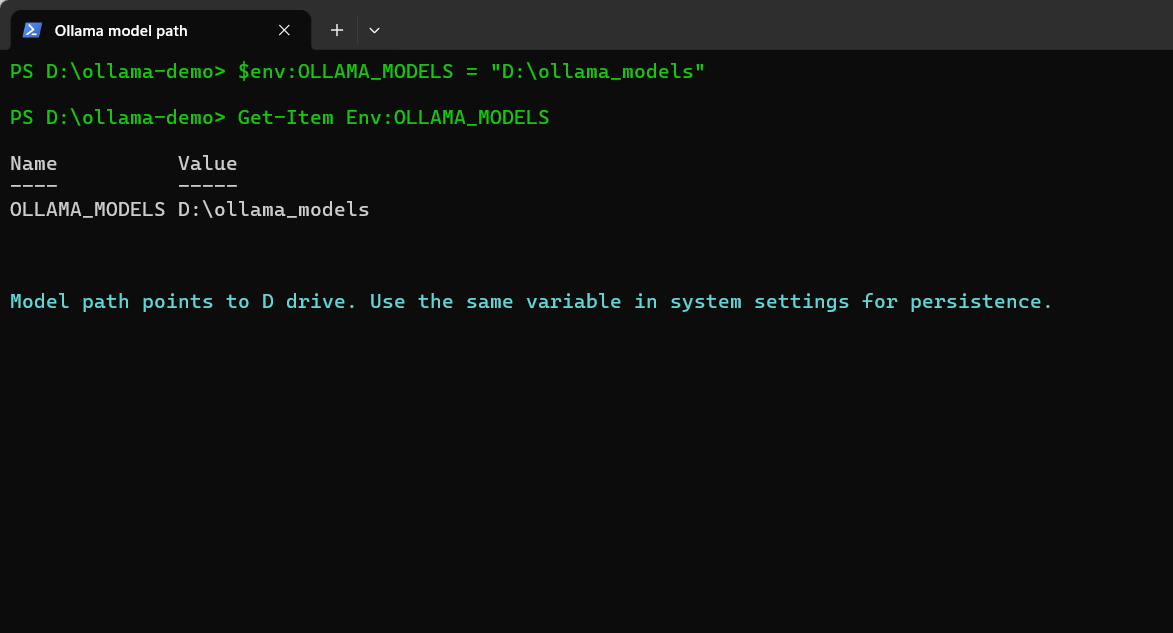
建议在首次下载模型前完成迁移。若已下载模型,迁移后需将已下载的模型文件一并移动至新路径,否则Ollama会认为模型不存在而重新下载。
3.3 启动校验
bash
ollama --version
ollama serveOllama默认配置为开机自启。若修改了端口或环境变量,建议手动启动一次确认配置不报错。日常使用时服务在后台静默运行,无需额外关注。
四、模型下载与基础操作
bash
# 下载模型
ollama pull qwen3:4b
# 启动对话
ollama run qwen3:4b
# >>> 出现即表示就绪,输入问题即可
# /bye 退出常用管理命令一览:
| 命令 | 功能 |
|---|---|
ollama list |
查看本地已下载模型 |
ollama ps |
查看当前运行模型及资源占用 |
ollama rm <模型名> |
删除指定模型释放空间 |
ollama show <模型名> |
查看模型参数、模版与许可证 |
ollama pull <模型名> |
下载或更新模型 |
ollama cp <旧名> <新名> |
复制模型副本便于备份 |
下面是我在 Windows Terminal 中执行 ollama list 和 ollama show 的实际输出。可以直接看到模型大小、参数规模、上下文长度以及量化类型。
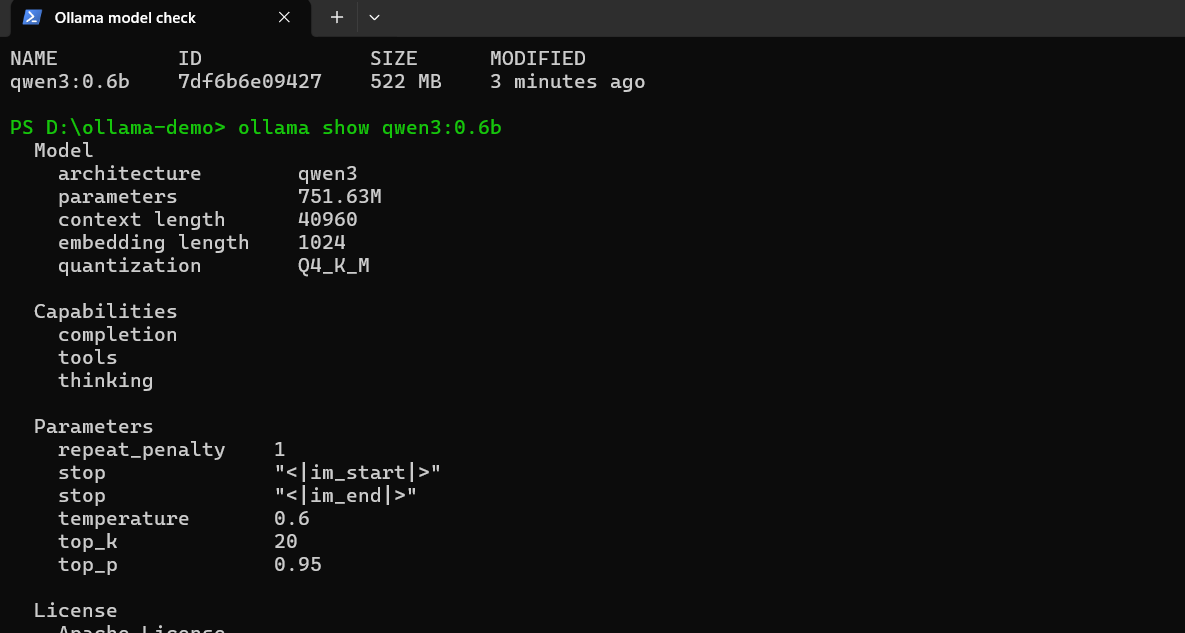
对话内参数调节:
bash
# 温度(0~1),值越低输出越稳定确定
>>> /set parameter temperature 0.3
# 上下文长度,处理长文本时适当调大,注意内存开销同步增加
>>> /set parameter num_ctx 8192
# 查看当前生效参数
>>> /show非交互式调用,适合脚本和管道场景,无需进入对话模式:
bash
ollama run qwen3:4b "用Python实现快速排序"
# 直接输出结果,可用于批处理和自动化脚本五、Modelfile 定制模型
通过Modelfile固化角色设定和推理参数,避免每次对话重复配置。写好后一条命令构建,后续直接使用。
dockerfile
FROM qwen3:4b
PARAMETER temperature 0.3
PARAMETER num_ctx 8192
SYSTEM """
你是一个C++编程助手,回答要求:
- 提供完整可编译运行的代码
- 解释核心逻辑与设计考量
- 涉及C++11/17/20特性时标注版本
- 主动指出潜在问题(内存管理、线程安全等)
"""构建并使用:
bash
ollama create my-cpp-helper -f Modelfile
ollama run my-cpp-helper此后 my-cpp-helper 即为固定的编程助手,每次对话自动应用角色和参数设定。团队协作时,Modelfile置入项目仓库,成员拉取后一条命令即可获得一致的模型配置。Modelfile还支持终止词、top_p/top_k采样参数、输出长度限制等扩展配置项,可按需查阅官方文档补充,但上述模板已覆盖多数日常场景。
六、代码调用
Python环境安装依赖:
bash
pip install ollama基础对话调用,几行代码即可完成:
python
import ollama
response = ollama.chat(
model="qwen3:4b",
messages=[{"role": "user", "content": "用C++实现线程安全的单例模式"}]
)
print(response["message"]["content"])流式输出,逐token返回,降低首字延迟,交互体验更好:
python
stream = ollama.chat(
model="qwen3:4b",
messages=[{"role": "user", "content": "解释RAII与智能指针的关系"}],
stream=True
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)HTTP直接调用,适用于Java、JavaScript、Go等语言,无需特定SDK:
python
import requests
resp = requests.post("http://localhost:11434/api/chat", json={
"model": "qwen3:4b",
"messages": [{"role": "user", "content": "介绍一下你自己"}],
"stream": False
})
print(resp.json()["message"]["content"])通过API检查服务版本和模型列表时,终端输出如下。只要 /api/version 和 /api/tags 能正常返回,说明Ollama服务端已经可以被上层应用访问。
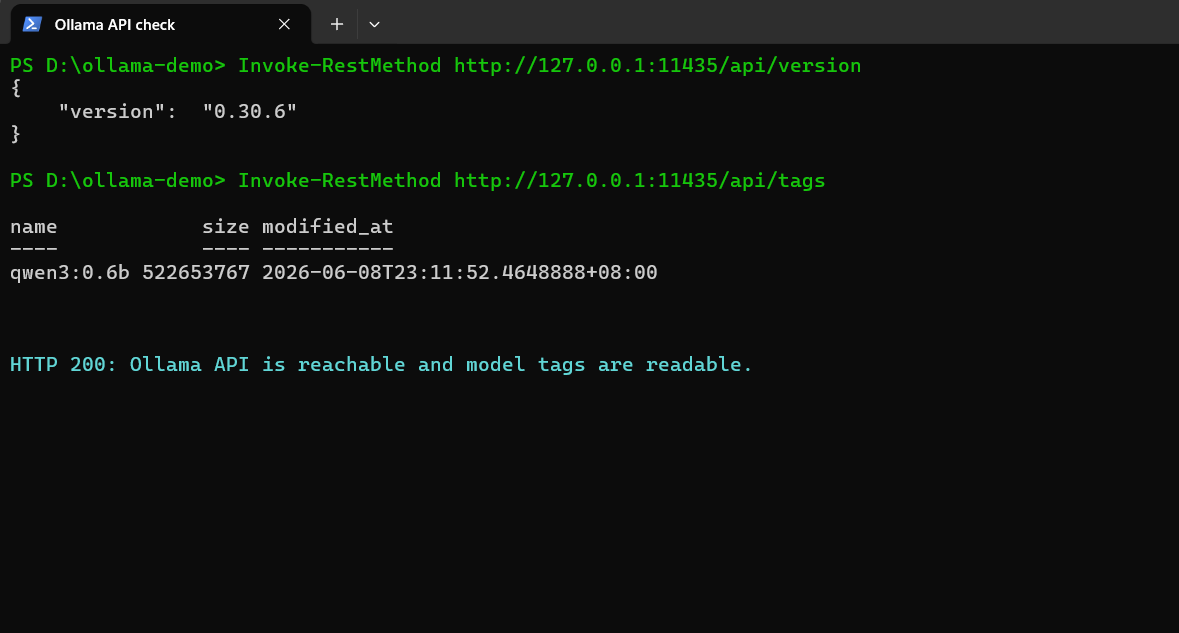
Ollama兼容OpenAI接口规范。将
base_url设为http://localhost:11434/v1,api_key填入任意字符串,即可用openai库直接调用本地模型。已基于OpenAI接口开发的项目,修改一行配置即可迁移到本地模型,迁移成本极低。对于使用LangChain、LlamaIndex等框架的项目,同样只需替换base_url即可接入。
生成嵌入向量,RAG的核心前置步骤:
python
resp = ollama.embed(model="nomic-embed-text", input="Ollama默认端口是11434")
print(len(resp["embeddings"][0])) # 输出768维向量七、构建最小RAG知识库
RAG核心流程:文档切分 → 向量化存储 → 查询时检索相关片段 → 拼接上下文提交模型生成回答。
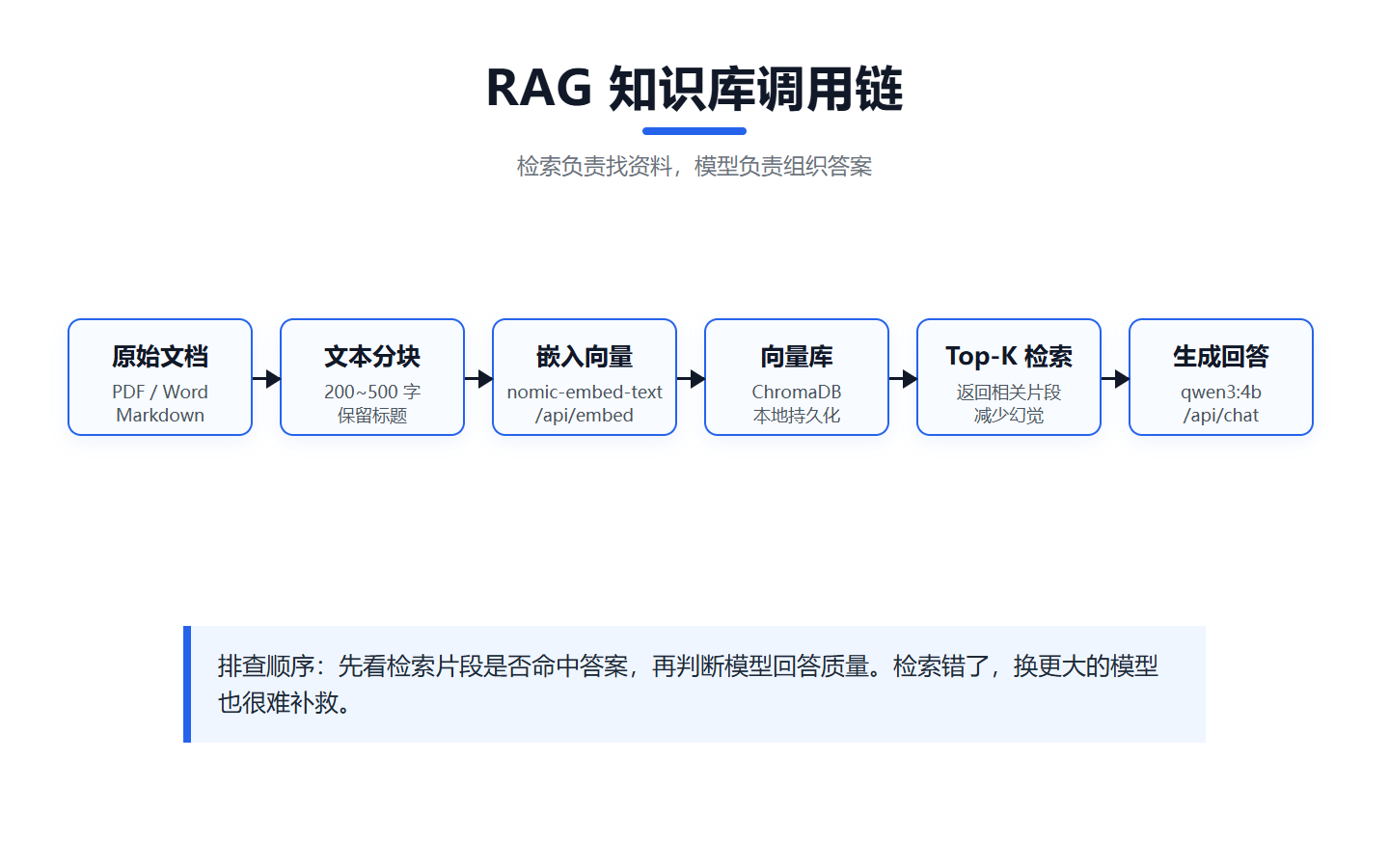
以下为可直接运行的最小实现,约70行代码,完整跑通检索增强生成的链路:
python
import ollama
import chromadb
# 1. 文档准备(实际项目替换为文件读取与分块逻辑)
docs = [
"Ollama默认API端口为11434。",
"通过OLLAMA_MODELS环境变量可修改模型存储路径。",
"量化版本q4_K_M在速度与精度之间取得最佳平衡。",
"Modelfile用于固化模型的系统提示词和参数配置。",
"Ollama通过/api/embed接口生成文本嵌入向量。",
"模型下载使用ollama pull,对话使用ollama run。",
"Ollama兼容OpenAI的API格式,可无缝迁移已有项目。",
]
# 2. 初始化向量数据库(本地持久化存储)
client = chromadb.PersistentClient(path="./my_knowledge_db")
collection = client.get_or_create_collection("ollama_docs")
# 3. 文档向量化并写入数据库
for i, doc in enumerate(docs):
emb = ollama.embed(model="nomic-embed-text", input=doc)["embeddings"][0]
collection.add(ids=[str(i)], embeddings=[emb], documents=[doc])
# 4. 检索增强查询------将检索结果作为上下文注入prompt
def ask(question):
q_emb = ollama.embed(model="nomic-embed-text", input=question)["embeddings"][0]
results = collection.query(query_embeddings=[q_emb], n_results=2)
context = "\n".join(results["documents"][0])
prompt = f"根据以下资料回答问题,若资料中无相关信息则明确说明:\n\n{context}\n\n问题:{question}"
return ollama.chat(model="qwen3:4b", messages=[{"role": "user", "content": prompt}])
# 验证效果
print(ask("Ollama默认端口是多少?")["message"]["content"])
print(ask("如何修改模型存储路径?")["message"]["content"])
print(ask("Ollama支持哪些量化版本?")["message"]["content"])环境准备,首次运行需安装依赖并下载嵌入模型:
bash
pip install ollama chromadb
ollama pull nomic-embed-textRAG效果的关键在检索质量,而非模型规模。注意以下要点:嵌入模型需统一(查询与文档必须使用同一个模型,否则向量空间不对齐)、文档分块不宜过细(200500字/块效果较稳定,过短丢失上下文,过长检索精度下降)、Top-K取值25即可,过多会引入噪声。建议先用小规模数据验证检索链路------确认返回片段确实包含目标信息,再扩展至大规模文档库。很多时候检索环节没做对,换再大的对话模型也弥补不了。
进阶方向:支持PDF/Word/Markdown等多格式文档解析、基于标题或段落的智能分块策略、添加简单的前端交互界面,可逐步构建完整可用的本地知识库系统。
八、常见问题与排查
网络原因下载缓慢
国内网络直连模型仓库偶有速度瓶颈。可通过代理下载模型,完成后切回直连。也可从已配置好的机器直接复制模型目录(位于OLLAMA_MODELS路径下),复制后执行 ollama list 即可识别,无需重新下载。
显存不足导致OOM
切换更低量化版本,如 qwen3:4b-instruct-q4_0 比默认的q4_K_M更省显存。或将上下文长度减小到4096。纯CPU推理完全可用,仅推理速度会下降,对于非实时场景可以接受。
API端口无法访问
先检查防火墙是否拦截了11434端口。若需更换端口:
powershell
$env:OLLAMA_HOST="0.0.0.0:8080"
ollama serve若需局域网内其他设备访问,将 0.0.0.0 替换为实际IP,并同步配置防火墙入站规则放行对应端口。
RAG回答不准确
按以下顺序逐级排查:文档是否被正确解析(检查切分后的片段内容)→ 切分片段是否包含正确答案 → 查询与文档是否使用同一嵌入模型 → Top-K是否命中相关片段 → prompt是否明确约束了回答范围。每步确认正确后再排查下一步,避免跳跃式猜测。
长时间对话响应变慢
对话历史持续累积导致上下文膨胀,每次推理都需要处理完整历史。定期 /bye 重启会话,或通过 num_ctx 限制上下文窗口大小,或在应用层手动裁剪历史消息仅保留最近几轮。
模型更新后行为变化
模型版本更新可能改变输出风格或能力表现。建议项目中使用固定版本标签(指定具体hash的版本而非latest),Modelfile中FROM字段锁定具体版本号,确保不同时间、不同机器上模型的输出行为一致可复现。版本锁定对于需要稳定输出的生产场景尤其重要。
总结
本文基于Ollama在Windows环境下的实际部署经验,覆盖了安装配置、存储规划、模型选型、API调用和RAG知识库构建的核心流程。本地大模型的价值不在于取代云端服务,而在于提供一种数据可控、成本可预期、离线可用的补充方案。
几点关键经验:
- 从最小可用系统起步。先用小模型跑通命令行和API调用,再逐层扩展功能,避免一开始就陷入复杂架构设计。
- 存储路径提前规划。通过OLLAMA_MODELS环境变量将模型目录指向空间充裕的磁盘,这个操作花两分钟,省去后续大量麻烦。
- 模型选择匹配硬件。16GB内存配置下4B~8B量化模型已可覆盖多数学习和开发场景,不要被"参数越大越好"的思路带偏。
- RAG优先优化检索链路。检索质量决定了知识库效果的上限,先确认检索正确再考虑升级对话模型,否则就是舍本逐末。
- Modelfile固化配置。角色设定、推理参数和提示词模板统一管理,便于个人复用和团队协作,也方便版本控制。
本地大模型的应用场景远不止对话------代码助手、文档问答、课程AI模块、离线数据提取、智能客服原型等均可基于上述基础链路构建。模型是系统中的一部分,文档解析、提示词设计、接口封装和前端交互同样决定最终效果。先把基础链路跑通,后面再逐步扩展,比一上来就追求完美架构要高效得多。
不同硬件配置、模型选择和实际场景会导致差异化的使用体验,欢迎在评论区交流你的配置方案与实践心得。
参考资料
- Ollama 官方文档:https://docs.ollama.com/
- 模型库:https://ollama.com/library
- API 文档:https://docs.ollama.com/api/introduction
- Modelfile 参考:https://docs.ollama.com/modelfile