
链式哈希表(Chaining Hash Table / 拉链法哈希表)
链式哈希表是最经典、工业界应用最广的哈希表实现方案之一,核心作用是解决哈希冲突问题:当不同的Key经过哈希函数计算后,映射到同一个桶位置时,用「链表挂载」的方式把所有冲突的键值对挂在同一个桶下,避免数据覆盖。
一、底层结构组成
它的整体结构是 「固定大小的桶数组 + 每个桶挂载的动态链表」 的两层设计:
组成部分 说明 桶数组(Slot Array) 底层是一个连续内存的数组,长度为 m(也叫槽数/容量),数组的每个位置称为一个「桶」,初始状态所有桶都是空指针桶挂载的链表 每个桶不直接存键值对,而是作为链表的头节点,所有经过哈希计算落到该桶的 (Key, Value)对,都以链表节点的形式追加到这个链表中负载因子 α核心调控指标: α = 已存储元素个数 n / 桶数量 m,用来衡量哈希表的拥挤程度,也是触发扩容的核心判断条件
二、代码结构与核心定义
我们先来看一下代码的基础骨架。
1. 节点结构 (HashNode)
cpptemplate<class K, class V> struct HashNode { pair<K, V> _kv; // 存储键值对 HashNode<K, V>* _next; // 指向下一个冲突节点 HashNode(const pair<K, V>& kv) :_kv(kv) , _next(nullptr) {} };每个节点存储一个
pair<K, V>和一个指向下一个节点的指针。这是一个典型的单链表节点。2. 哈希表主体 (HashTable)
cpptemplate<class K, class V, class Hash = HashFunc<K>> class HashTable { typedef HashNode<K, V> Node; private: vector<Node*> _tables; // 桶数组 size_t _n = 0; // 表中实际元素个数 };这里使用了
vector<Node*>作为桶数组,而不是vector<list<pair<K,V>>>。这样做的好处是减少了 list 容器的额外开销,更加贴近底层实现。
三、关键算法详解
1. 哈希函数与取模
为了将 Key 映射到桶下标,我们需要两步:
将 Key 转换为整数(
HashFunc)。对桶大小取模(
%)。Hash hs;
size_t hashi = hs(key) % _tables.size();这里的
Hash是一个仿函数(Functor),允许用户自定义哈希规则。2. 插入操作 (Insert)
插入逻辑分为三步:检查重复 -> 检查扩容 -> 头插。
负载因子与扩容策略
这是哈希表性能的精髓。代码中设定了独特的扩容阈值:
cppbool Insert(const pair<K, V>& kv) { if (Find(kv.first)) return false; Hash hs; // 负载因子==1扩容 if (_n == _tables.size()) { vector<Node*> newtables(__stl_next_prime(_tables.size() + 1)); for (size_t i = 0; i < _tables.size(); i++) { Node* cur = _tables[i]; // 当前桶的节点重新映射挂到新表 while (cur) { Node* next = cur->_next; // 插入到新表 size_t hashi = hs(cur->_kv.first) % newtables.size(); cur->_next = newtables[hashi]; newtables[hashi] = cur; cur = next; } _tables[i] = nullptr; } _tables.swap(newtables); } size_t hashi = hs(kv.first) % _tables.size(); // 头插 Node* newNode = new Node(kv); newNode->_next = _tables[hashi]; _tables[hashi] = newNode; ++_n; return true; }解析:
负载因子 (Load Factor) α = 元素个数 / 桶个数 (α=sizen)。
大多数语言(如 Java)默认阈值是 0.75,但这份代码采用了 1.0。
为什么是 1.0? 因为底层使用了质数作为桶大小(见下文),配合质数取模,冲突分布相对均匀,允许更高的负载因子而不至于性能急剧下降。
Rehash(重哈希)
扩容时,桶的大小变为原来的若干倍(通常是下一个质数),并遍历旧表将所有节点重新计算位置插入新表。
cppvector<Node*> newtables(__stl_next_prime(_tables.size() + 1)); for (size_t i = 0; i < _tables.size(); i++) { Node* cur = _tables[i]; while (cur) { Node* next = cur->_next; //保存下一个链节点的地址,防止断链 size_t hashi = hs(cur->_kv.first) % newtables.size();//找到新表的桶位置 // 头插到新表桶 cur->_next = newtables[hashi]; //将当前链节点next指针指向新表桶位置,等于接上链 newtables[hashi] = cur; //将接上后的链再接入表节点 cur = next; //指针往后走,继续断链接链 } _tables[i] = nullptr;//修改完成,原表置空 } _tables.swap(newtables);注意细节:这里在搬运节点时,并没有重新
new节点,而是直接改变了节点的_next指针指向,这是一种高效的"指针窃取"操作。3. 查找与删除
查找和删除都需要先定位桶,然后遍历链表。
查找 (Find)
cppNode* Find(const K& key) { size_t hashi = hs(key) % _tables.size(); Node* cur = _tables[hashi];//定义链指针 while (cur) { if (cur->_kv.first == key) return cur; cur = cur->_next; } return nullptr; }删除 (Erase)
删除单链表节点需要处理两种情况:删除头节点和删除中间节点。
cppNode* prev = nullptr; Node* cur = _tables[hashi]; while (cur) { if (cur->_kv.first == key) { if (prev == nullptr) // 头删 _tables[hashi] = cur->_next; else // 中间删 prev->_next = cur->_next; delete cur; return true; } prev = cur; cur = cur->_next; }
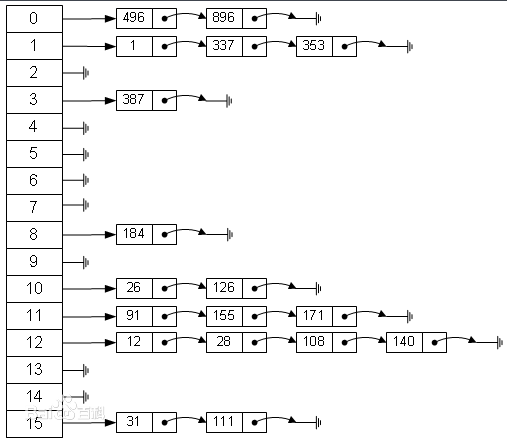
完整代码
cppnamespace SeparateChaining { template<class K, class V> struct HashNode { pair<K, V> _kv; HashNode<K, V>* _next; HashNode(const pair<K, V>& kv) :_kv(kv) , _next(nullptr) { } }; template<class K, class V, class Hash = HashFunc<K>> class HashTable { typedef HashNode<K, V> Node; public: HashTable() :_tables(__stl_next_prime(1), nullptr) , _n(0) { } ~HashTable() { for (size_t i = 0; i < _tables.size(); i++) { Node* cur = _tables[i]; // 当前桶的节点重新映射挂到新表 while (cur) { Node* next = cur->_next; delete cur; cur = next; } _tables[i] = nullptr; } } bool Insert(const pair<K, V>& kv) { if (Find(kv.first)) return false; Hash hs; // 负载因子==1扩容 if (_n == _tables.size()) { vector<Node*> newtables(__stl_next_prime(_tables.size() + 1)); for (size_t i = 0; i < _tables.size(); i++) { Node* cur = _tables[i]; // 当前桶的节点重新映射挂到新表 while (cur) { Node* next = cur->_next; // 插入到新表 size_t hashi = hs(cur->_kv.first) % newtables.size(); cur->_next = newtables[hashi]; newtables[hashi] = cur; cur = next; } _tables[i] = nullptr; } _tables.swap(newtables); } size_t hashi = hs(kv.first) % _tables.size(); // 头插 Node* newNode = new Node(kv); newNode->_next = _tables[hashi]; _tables[hashi] = newNode; ++_n; return true; } Node* Find(const K& key) { Hash hs; size_t hashi = hs(key) % _tables.size(); Node* cur = _tables[hashi]; while (cur) { if (cur->_kv.first == key) return cur; cur = cur->_next; } return nullptr; } bool Erase(const K& key) { Hash hs; size_t hashi = hs(key) % _tables.size(); Node* prev = nullptr; Node* cur = _tables[hashi]; while (cur) { if (cur->_kv.first == key) { if (prev == nullptr) { _tables[hashi] = cur->_next; } else { prev->_next = cur->_next; } delete cur; return true; } prev = cur; cur = cur->_next; } return false; } private: //vector<list<pair<K, V>>> _tables; vector<Node*> _tables; size_t _n = 0; // 实际存储的数据个数 }; }
