文章目录
- 前言
- 一、环境准备
- 二、完整代码
- 三、代码详解
- 数据读取
- [模型 1:逻辑回归](#模型 1:逻辑回归)
- [模型 2:随机森林](#模型 2:随机森林)
- [模型 3:支持向量机(SVM)](#模型 3:支持向量机(SVM))
- [模型 4:AdaBoost](#模型 4:AdaBoost)
- [模型 5:高斯朴素贝叶斯(GaussianNB)](#模型 5:高斯朴素贝叶斯(GaussianNB))
- [模型 6:XGBoost](#模型 6:XGBoost)
- [模型 7:神经网络(PyTorch 实现)](#模型 7:神经网络(PyTorch 实现))
- 结果汇总与分析
- 总结
前言
在机器学习中,分类问题是最常见的任务之一。比如根据病人的各项指标判断病情等级、根据用户行为预测会员等级等。
本文使用一个已经预处理好的多分类数据集(标签为 0、1、2、3),分别用 7 种经典的分类算法进行建模,并对比它们在测试集上的表现。
本文以众数填充为例子。
每个文件的第一列是标签(y),后面的列是特征(x)
一、环境准备
c
pip install pandas scikit-learn xgboost torch openpyxlpandas:数据读取、清洗、处理(Excel/CSV 必备)
scikit-learn:经典机器学习(分类、回归、聚类)
xgboost:梯度提升树,竞赛 / 工业界常用强模型
torch:PyTorch 深度学习框架
openpyxl:读写 Excel 文件(.xlsx)
二、完整代码
c
import pandas as pd
from sklearn import metrics
train_data = pd.read_excel(r'.//temp_data//训练数据集[众数填充].xlsx')
train_data_x = train_data.iloc[:,1:]
train_data_y = train_data.iloc[:,0]
test_data = pd.read_excel(r'.//temp_data//测试数据集[众数填充].xlsx')
test_data_x = test_data.iloc[:,1:]
test_data_y = test_data.iloc[:,0]
result_data = {}
##逻辑回归模型
from sklearn.linear_model import LogisticRegression
LR_result = {}
lr = LogisticRegression(C=0.001,max_iter=1000,solver='lbfgs')
lr.fit(train_data_x,train_data_y)
train_predicted = lr.predict(train_data_x)
print('LR的train:\n',metrics.classification_report(train_data_y,train_predicted))
test_predicted = lr.predict(test_data_x)
print('LR的test:\n',metrics.classification_report(test_data_y,test_predicted))
a = metrics.classification_report(test_data_y,test_predicted,digits=6)
b = a.split()
LR_result['recall_0'] = float(b[6])#添加类别为0的召回率
LR_result['recall_1']= float(b[11])#添加类别为1的召回率
LR_result['recall_2'] = float(b[16])#添加类别为2的召回率
LR_result['recall_3'] = float(b[21])#添加类别为3的召回率
LR_result['acc'] = float(b[25])#衫加accuracy的结果
result_data['LR']= LR_result#result_data是总体的结果,
print('Lr结束')
##随机森林实现
from sklearn.ensemble import RandomForestClassifier
RF_result = {}
rf = RandomForestClassifier(bootstrap=False,
max_depth=20,
min_samples_leaf=1,
min_samples_split=2,
n_estimators=50,
random_state=487)
rf.fit(train_data_x,train_data_y)
train_predicted = rf.predict(train_data_x)
test_predicted = rf.predict(test_data_x)
print('RF的train:\n',metrics.classification_report(train_data_y,train_predicted))
print('RF的test:\n',metrics.classification_report(test_data_y,test_predicted))
rf_test_report = metrics.classification_report(test_data_y,test_predicted,digits=6)
b = rf_test_report.split()
RF_result['recall_0'] = float(b[6])#添加类别为0的召回率
RF_result['recall_1'] = float(b[11])#添加类别为1的召回率
RF_result['recall_2'] = float(b[16])#添加类别为2的召回率
RF_result['recall_3'] = float(b[21])#添加类别为3的召回率
RF_result['acc'] = float(b[25])#衫加accuracy的结果
result_data['RF']= RF_result#result_data是总体的结果,
print('RF结束')
##svm算法实现
from sklearn.svm import SVC
SVM_result = {}
# svm = SVC(C=1,coef0=0.1,degree=4,gamma=1,kernel='poly',probability=True,random_state=100)
svm = SVC(kernel='rbf', C=1, gamma='scale', random_state=100)
svm.fit(train_data_x,train_data_y)
test_predicted = svm.predict(test_data_x)
print('SVM的test:\n',metrics.classification_report(test_data_y,test_predicted))
a = metrics.classification_report(test_data_y,test_predicted,digits=6)
b = a.split()
print(a)
SVM_result['recall_0'] = float(b[6])#添加类别为0的召回率
SVM_result['recall_1'] = float(b[11])#添加类别为1的召回率
SVM_result['recall_2'] = float(b[16])#添加类别为2的召回率
SVM_result['recall_3'] = float(b[21])#添加类别为3的召回率
SVM_result['acc'] = float(b[25])#衫加accuracy的结果
result_data['SVM']= SVM_result#result_data是总体的结果,
print('SVM结束')
## #AdaB00St算法实现代码
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
AdaBoost_result = {}
abf = AdaBoostClassifier(
estimator = DecisionTreeClassifier(max_depth=2),
n_estimators=200,
learning_rate=1.0,
random_state=0)
abf.fit(train_data_x,train_data_y)
train_predicted = abf.predict(train_data_x)
test_predicted = abf.predict(test_data_x)
print('AdaBoost的train:\n',metrics.classification_report(train_data_y,train_predicted))
print('AdaBoost的test:\n',metrics.classification_report(test_data_y,test_predicted))
a = metrics.classification_report(test_data_y,test_predicted,digits=6)
b = a.split()
AdaBoost_result['recall_0'] = float(b[6])#添加类别为0的召回率
AdaBoost_result['recall_1'] = float(b[11])#添加类别为1的召回率
AdaBoost_result['recall_2'] = float(b[16])#添加类别为2的召回率
AdaBoost_result['recall_3'] = float(b[21])#添加类别为3的召回率
AdaBoost_result['acc'] = float(b[25])#衫加accuracy的结果
result_data['AdaBoost']= AdaBoost_result#result_data是总体的结果,
print('AdaBoost结束')
###GNB算法实现代码
from sklearn.naive_bayes import GaussianNB
GNB_result = {}
gnb = GaussianNB()
gnb.fit(train_data_x,train_data_y)
train_predicted = gnb.predict(train_data_x)
test_predicted = gnb.predict(test_data_x)
print('GNB的train:\n',metrics.classification_report(train_data_y,train_predicted))
print('GNB的test:\n',metrics.classification_report(test_data_y,test_predicted))
a = metrics.classification_report(test_data_y,test_predicted,digits=6)
b = a.split()
GNB_result['recall_0'] = float(b[6])#添加类别为0的召回率
GNB_result['recall_1'] = float(b[11])#添加类别为1的召回率
GNB_result['recall_2'] = float(b[16])#添加类别为2的召回率
GNB_result['recall_3'] = float(b[21])#添加类别为3的召回率
GNB_result['acc'] = float(b[25])#衫加accuracy的结果
result_data['GNB']= GNB_result#result_data是总体的结果,
print('GNB结束')
####XGBoost算法实现代码
import xgboost as xgb
XGBoost_result = {}
xgb_model = xgb.XGBClassifier(learning_rate=0.05,
n_estimators=200,
num_class = 5,
max_depth=7,
min_child_weight=1,
gamma=0,
subsample=0.6,
colsample_bytree=0.8,
objective='multi:softmax',
seed = 0
)
xgb_model.fit(train_data_x,train_data_y)
train_predicted = xgb_model.predict(train_data_x)
test_predicted = xgb_model.predict(test_data_x)
print('XGBoost的train:\n',metrics.classification_report(train_data_y,train_predicted))
print('XGBoost的test:\n',metrics.classification_report(test_data_y,test_predicted))
a = metrics.classification_report(test_data_y,test_predicted,digits=6)
b = a.split()
XGBoost_result['recall_0'] = float(b[6])#添加类别为0的召回率
XGBoost_result['recall_1'] = float(b[11])#添加类别为1的召回率
XGBoost_result['recall_2'] = float(b[16])#添加类别为2的召回率
XGBoost_result['recall_3'] = float(b[21])#添加类别为3的召回率
XGBoost_result['acc'] = float(b[25])#衫加accuracy的结果
result_data['XGBoost']= XGBoost_result#result_data是总体的结果,
print('XGBoost结束')
'''#################神经网络算法实现代码####################'''
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(13, 32)
self.fc2 = nn.Linear(32, 64)
self.fc3 = nn.Linear(64, 4)
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
x = self.fc3(x)
return x
X_train = torch.tensor(train_data_x.values, dtype=torch.float32)
Y_train = torch.tensor(train_data_y.values, dtype=torch.long) # 修正:使用 long 类型
X_test = torch.tensor(test_data_x.values, dtype=torch.float32)
Y_test = torch.tensor(test_data_y.values, dtype=torch.long) # 修正
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
def evaluate_model(model, X_data, Y_data, train_or_test):
model.eval()
with torch.no_grad():
predictions = model(X_data)
correct = (predictions.argmax(1) == Y_data).type(torch.float).sum().item()
acc = correct / len(X_data)
print(f"{train_or_test}:\t Accuracy: {acc*100:.2f}%")
model.train()
return acc
epochs = 1500
accs = []
for epoch in range(epochs):
outputs = model(X_train)
loss = criterion(outputs, Y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')
train_acc = evaluate_model(model, X_train, Y_train, 'train')
test_acc = evaluate_model(model, X_test, Y_test, 'test') # 修正:标签改为 test
accs.append(test_acc * 100) # 修正:存入准确率
net_result = {}
net_result['acc'] = max(accs)
result_data['net'] = net_result三、代码详解
数据读取
c
import pandas as pd
from sklearn import metrics
# 读取训练集
train_data = pd.read_excel(r'./temp_data/训练数据集[众数填充].xlsx')
train_data_x = train_data.iloc[:, 1:] # 特征:从第2列开始
train_data_y = train_data.iloc[:, 0] # 标签:第1列
# 读取测试集
test_data = pd.read_excel(r'./temp_data/测试数据集[众数填充].xlsx')
test_data_x = test_data.iloc[:, 1:]
test_data_y = test_data.iloc[:, 0]
result_data = {} # 用于保存各个模型的评估结果iloc 是 Pandas 中按位置索引的方法。:, 1: 表示所有行、从索引1开始的列
模型 1:逻辑回归
逻辑回归虽然名字带有"回归",但实际上是一种分类算法。它通过 Sigmoid 函数将线性回归的输出压缩到 0,1 之间,用来表示属于某个类别的概率。对于多分类问题,可以使用 一对多(One-vs-Rest) 策略。
c
from sklearn.linear_model import LogisticRegression
LR_result = {}
lr = LogisticRegression(C=0.001, max_iter=1000, solver='lbfgs')
lr.fit(train_data_x, train_data_y)
train_pred = lr.predict(train_data_x)
test_pred = lr.predict(test_data_x)
print('LR 训练集报告:\n', metrics.classification_report(train_data_y, train_pred))
print('LR 测试集报告:\n', metrics.classification_report(test_data_y, test_pred))
# 提取测试集的召回率和准确率(用于后续对比)
a = metrics.classification_report(test_data_y, test_pred, digits=6)
b = a.split()
LR_result['recall_0'] = float(b[6]) # 类别0的召回率
LR_result['recall_1'] = float(b[11])
LR_result['recall_2'] = float(b[16])
LR_result['recall_3'] = float(b[21])
LR_result['acc'] = float(b[25]) # 整体准确率
result_data['LR'] = LR_result
print('逻辑回归训练完成')C=0.001:正则化强度的倒数,值越小正则化越强。
max_iter=1000:最大迭代次数。
solver='lbfgs':适合多分类的优化算法。
模型 2:随机森林
随机森林是一种基于决策树的集成学习算法。它通过 Bagging 思想生成多棵决策树,每棵树使用随机选择的样本和特征进行训练,最后投票决定最终类别。优点是抗过拟合能力强,能处理高维数据。
c
from sklearn.ensemble import RandomForestClassifier
RF_result = {}
rf = RandomForestClassifier(
bootstrap=False, # 不使用自助采样(实际通常为True,这里按代码设置)
max_depth=20, # 树的最大深度
min_samples_leaf=1, # 叶节点最少样本数
min_samples_split=2, # 内部节点再划分所需最少样本数
n_estimators=50, # 树的数量
random_state=487
)
rf.fit(train_data_x, train_data_y)
test_pred = rf.predict(test_data_x)
a = metrics.classification_report(test_data_y, test_pred, digits=6)
b = a.split()
# ... 同样方式提取指标存入 RF_result
result_data['RF'] = RF_result
print('随机森林完成')我们主要管理的就是树的最大深度,叶节点最少样本数和树的数量,通过这三个数和随机森林的准确率息息相关。
模型 3:支持向量机(SVM)
支持向量机 的核心思想是找到一个超平面,使得不同类别之间的间隔(margin)最大化。对于非线性问题,SVM 通过核函数将数据映射到高维空间。常用的核有线性核、多项式核、RBF(径向基)核。
c
from sklearn.svm import SVC
SVM_result = {}
# svm = SVC(C=1,coef0=0.1,degree=4,gamma=1,kernel='poly',probability=True,random_state=100)
svm = SVC(kernel='rbf', C=1, gamma='scale', random_state=100)
svm.fit(train_data_x,train_data_y)
test_predicted = svm.predict(test_data_x)
print('SVM的test:\n',metrics.classification_report(test_data_y,test_predicted))
a = metrics.classification_report(test_data_y,test_predicted,digits=6)
b = a.split()
print(a)
SVM_result['recall_0'] = float(b[6])#添加类别为0的召回率
SVM_result['recall_1'] = float(b[11])#添加类别为1的召回率
SVM_result['recall_2'] = float(b[16])#添加类别为2的召回率
SVM_result['recall_3'] = float(b[21])#添加类别为3的召回率
SVM_result['acc'] = float(b[25])#衫加accuracy的结果
result_data['SVM']= SVM_result#result_data是总体的结果,
print('SVM结束')kernel='rbf':高斯径向基核,最常用的非线性核。
C=1:惩罚系数,控制对误分类的容忍度。
gamma='scale':核函数的系数,影响单个训练样本的影响力范围。
模型 4:AdaBoost
AdaBoost(Adaptive Boosting) 是一种串行集成方法:先训练一个基学习器(通常是决策树),然后根据错误率调整样本权重,让后续学习器更关注被分错的样本,最后加权投票得到结果。
c
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
AdaBoost_result = {}
ada = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=2), # 弱学习器:最大深度2的决策树
n_estimators=200, # 迭代次数
learning_rate=1.0, # 学习率
random_state=0
)
ada.fit(train_data_x, train_data_y)
# ... 预测和提取指标模型 5:高斯朴素贝叶斯(GaussianNB)
朴素贝叶斯 基于贝叶斯定理,假设特征之间相互独立("朴素"的含义)。对于连续特征,通常假设其服从高斯分布,即 GaussianNB。该算法简单、快速,对小数据量表现良好。
c
from sklearn.naive_bayes import GaussianNB
GNB_result = {}
gnb = GaussianNB()
gnb.fit(train_data_x, train_data_y)
# ... 预测和提取指标预测和提取指标的操作都是相同的,不过多赘述
模型 6:XGBoost
XGBoost(极端梯度提升) 是如今竞赛中的"大杀器"。它基于 Gradient Boosting 框架,但加入了正则化项、列采样、缺失值自动处理等优化,速度与精度都很出色。
c
import xgboost as xgb
XGBoost_result = {}
xgb_model = xgb.XGBClassifier(
learning_rate=0.05, # 学习率(步长)
n_estimators=200, # 树的数量
num_class=5, # 类别数(这里设置为5,实际数据是4类,可改为4)
max_depth=7, # 树的最大深度
min_child_weight=1, # 最小叶子节点样本权重和
gamma=0, # 分裂所需的最小损失减少量
subsample=0.6, # 每棵树使用的样本比例
colsample_bytree=0.8, # 每棵树使用的特征比例
objective='multi:softmax', # 多分类目标函数
seed=0
)
xgb_model.fit(train_data_x, train_data_y)
# ... 预测和提取指标代码中 num_class=5,但你的标签只有 0,1,2,3 共 4 类,建议改为 4。不过 XGBoost 会自动处理,若不匹配会报警告。
模型 7:神经网络(PyTorch 实现)
神经网络 通过多层神经元(输入层 → 隐藏层 → 输出层)和非线性激活函数来学习复杂的特征表示。这里使用 PyTorch 搭建一个简单的 3 层全连接网络,用 交叉熵损失 和 Adam 优化器 训练。
c
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 1. 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(13, 32) # 输入特征数=13,输出32
self.fc2 = nn.Linear(32, 64) # 隐藏层64
self.fc3 = nn.Linear(64, 4) # 输出4个类别
def forward(self, x):
x = torch.sigmoid(self.fc1(x)) # 激活函数 sigmoid
x = torch.sigmoid(self.fc2(x))
x = self.fc3(x) # 最后一层无激活,后面接 CrossEntropyLoss
return x
# 2. 将数据转为 PyTorch 张量
X_train = torch.tensor(train_data_x.values, dtype=torch.float32)
Y_train = torch.tensor(train_data_y.values, dtype=torch.long) # 注意:交叉熵要求标签为 long 类型
X_test = torch.tensor(test_data_x.values, dtype=torch.float32)
Y_test = torch.tensor(test_data_y.values, dtype=torch.long)
# 3. 实例化模型、损失函数、优化器
model = Net()
criterion = nn.CrossEntropyLoss() # 多分类交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 4. 定义评估函数
def evaluate_model(model, X_data, Y_data, mode):
model.eval()
with torch.no_grad():
preds = model(X_data)
correct = (preds.argmax(1) == Y_data).sum().item()
acc = correct / len(X_data)
print(f"{mode} 准确率: {acc*100:.2f}%")
model.train()
return acc
# 5. 训练循环
epochs = 1500
accs = [] # 记录每一百轮的测试准确率
for epoch in range(epochs):
outputs = model(X_train)
loss = criterion(outputs, Y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每100轮打印一次损失和准确率
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
train_acc = evaluate_model(model, X_train, Y_train, 'train')
test_acc = evaluate_model(model, X_test, Y_test, 'test')
accs.append(test_acc * 100) # 保存测试准确率
# 6. 保存最佳测试准确率
net_result = {}
net_result['acc'] = max(accs)
result_data['net'] = net_resultCrossEntropyLoss 内部会自动对最后一层输出做 Softmax,所以网络最后一层不需要额外加激活函数。
使用 torch.long 作为标签类型。
model.eval() 和 with torch.no_grad() 关闭 Dropout/BatchNorm 的动态行为和梯度计算,提高评估效率。
结果汇总与分析
评估模型主要看准确率(acc)
平均数填充,XGBoost模型效果最好,测试集准确率为 95.53%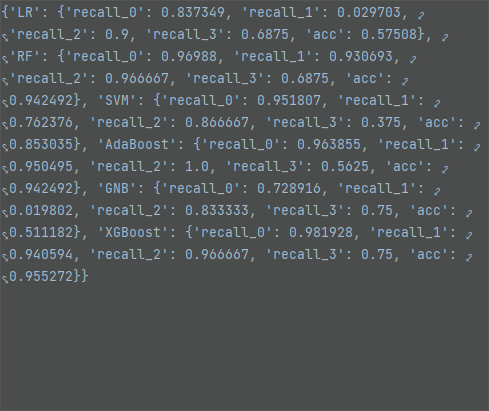
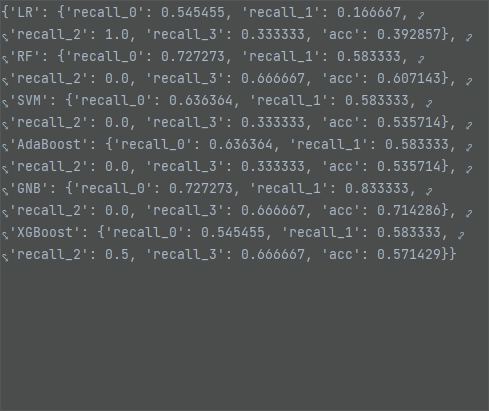
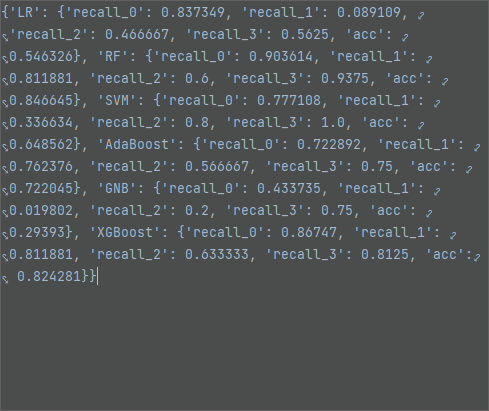
删除空数据行,GNB模型效果最好,测试集准确率为 71.43%
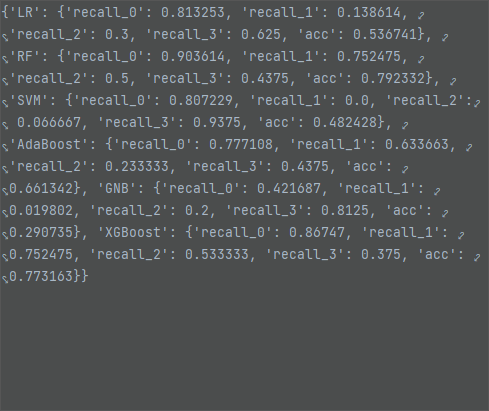
逻辑回归填充,随机森林模型效果最好,测试集准确率为 79.23%
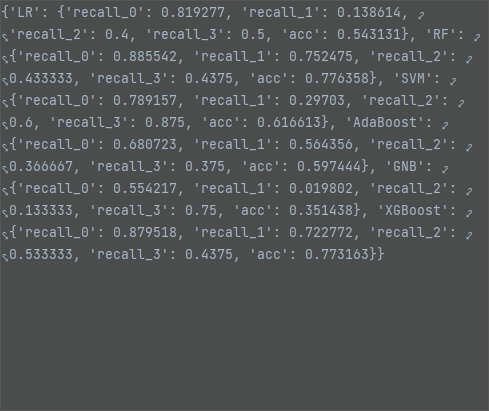
随机森林填充,随机森林模型效果最好,测试集准确率为 77.64%
中位数填充,XGBoost和AdaBoost模型效果最好,测试集准确率均为 95.53%
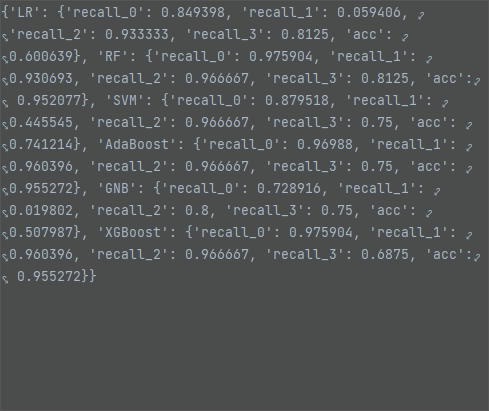
众数填充,随机森林模型效果最好,测试集准确率为 84.66%
-
XGBoost 和 随机森林 在表格数据上表现优异。
-
神经网络 如果调好超参(层数、学习率、epoch)也能取得不错的效果。
-
朴素贝叶斯 虽然简单,但在特征独立性强时速度快且效果尚可。
-
SVM 在小数据集上表现稳定,但计算量随样本数增长较快。
总结
上述代码实现了一个完整的机器学习多分类项目,从数据读取(Pandas)、七种主流模型(逻辑回归、随机森林、SVM、AdaBoost、朴素贝叶斯、XGBoost、PyTorch神经网络)的训练评估,到结果汇总的全流程;通过通俗的原理解析和逐行代码注释,帮助新手理解不同算法的核心思想(如逻辑回归的Sigmoid函数、随机森林的Bagging集成、SVM的核技巧、AdaBoost的串行加权、朴素贝叶斯的独立性假设、XGBoost的提升优化、神经网络的全连接与反向传播),并学会用分类报告中的召回率、准确率等指标对比模型效果,是一份适合入门的多分类实战教程。