一.Typescript
1.TS 项目初始化
初始化项目目录与 package.json
# 创建项目文件夹
mkdir ai-frontend-mastery
# 进入项目目录
cd ai-frontend-mastery
# 快速生成package.json(所有选项默认)
npm init -y可指定 package.json中TS和zod的版本,然后下载
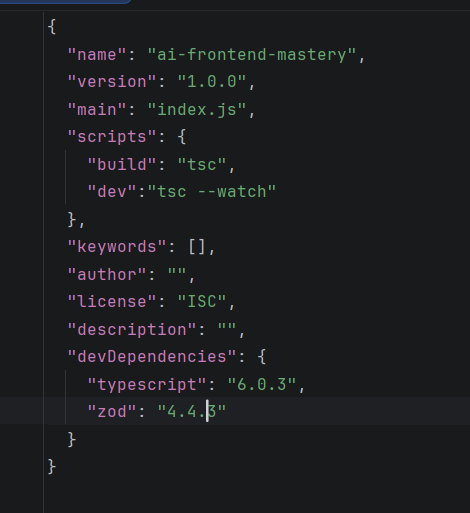
安装核心开发依赖 推荐使用 pnpm(速度更快、磁盘占用更低),也可使用 npm
# pnpm方式(推荐)
pnpm add -D typescript @types/node tsx
# npm方式
npm install -D typescript @types/node tsx编译项目:
生成并配置 tsconfig.json
# 自动生成tsconfig.json文件
npx tsc --init修改定 package.json
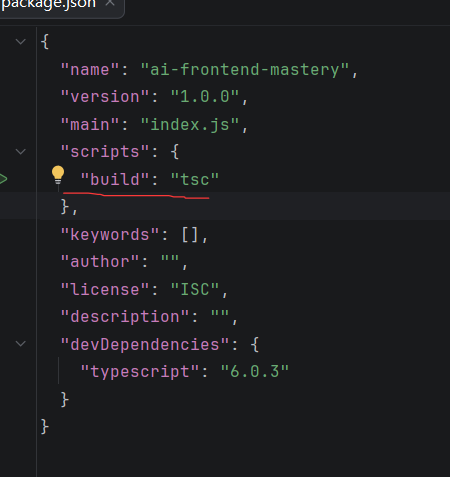
执行:npm run build
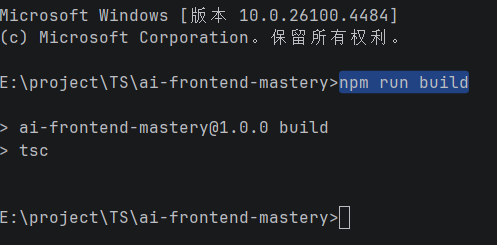
监听模式:
核心配置文件:tsconfig.json
这是 AI 开发中最重要的配置文件,错误的配置会导致大量第三方库(如 LangChain、OpenAI)无法正常使用。
{
"compilerOptions": {
/* 基础配置 - AI后端专属 */
"target": "ESNext", // AI后端通常运行在较新的Node版本,直接输出现代语法,性能更好
"module": "NodeNext", // 关键:配合package.json的type: module,彻底解决ESM兼容问题
"moduleResolution": "NodeNext", // 关键:确保能正确解析LangChain等纯ESM库
"outDir": "./dist", // 编译输出目录
"rootDir": "./src", // 源码目录
/* 严格模式 - AI全栈的生命线 */
"strict": true, // 开启所有严格检查
"noImplicitAny": true, // 拒绝隐式any,逼迫你写出高质量的Prompt接口定义
"strictNullChecks": true, // 防止数据处理中的"Cannot read property of undefined"运行时错误
/* 开发体验优化 */
"skipLibCheck": true, // 跳过node_modules的类型检查,显著提升编译速度
"esModuleInterop": true, // 允许默认导入非ESM模块
"resolveJsonModule": true, // 允许直接import JSON文件(加载配置文件时很常用)
"forceConsistentCasingInFileNames": true // 防止文件名大小写导致的跨平台构建失败
},
"include": ["src/**/*"],
"exclude": ["node_modules"]
}关键配置解析:
"module": "NodeNext":这是 AI 开发中最容易出错的配置。很多同学在引入 langchain 或 openai 库时报错,90% 是因为这个没配对。现代 AI 栈强烈依赖 ESM 规范。
"strict": true:在 AI 开发中,类型安全尤为重要。大模型返回的数据结构非常动态,严格的类型检查能帮你在编译阶段就发现大量潜在错误。
调整 package.json
为了让 Node.js 识别现代 ES Module 语法(使用import而不是require),必须在 package.json 中显式声明。
{
"name": "ai-frontend-mastery",
"type": "module", // <--- 必须添加,声明这是一个ESM项目
"scripts": {
"dev": "tsx watch src/index.ts", // 监听模式,修改代码自动重启
"build": "tsc",
"start": "node dist/index.js"
},
"devDependencies": {
"typescript": "^5.0.0",
"@types/node": "^20.0.0",
"tsx": "^4.0.0"
}
}脚本说明:
npm run dev:开发环境使用,tsx 会自动监听文件变化并重启服务,无需手动编译npm run build:生产环境构建,将 TypeScript 编译为 JavaScriptnpm run start:运行构建后的生产代码
推荐目录结构
构建一个清晰的目录结构,为后续的 Zod Schema 和 LangGraph 逻辑做准备。
ai-frontend-mastery/
├── src/
│ ├── config/ # 存放环境变量、AI模型配置
│ ├── schemas/ # 存放Zod定义(Structured Output的核心)
│ ├── agents/ # 存放LangGraph智能体逻辑
│ ├── utils/ # 工具函数
│ └── index.ts # 入口文件
├── package.json
├── tsconfig.json
└── .env # 稍后用于存放API Key验证环境
编写测试代码验证环境是否正常工作。
// src/index.ts
interface AIConfig {
modelName: string;
temperature: number;
tags: string[];
}
// 模拟一个简单的AI配置对象
const config: AIConfig = {
modelName: "gpt-4o",
temperature: 0.7,
tags: ["coding", "assistant"]
};
console.log(`🚀 AI Environment Ready! Model: ${config.modelName}`);
console.log(`Running in ${process.env.NODE_ENV || 'development'} mode`);运行项目:
npm run dev如果控制台输出了🚀 AI Environment Ready! ...,说明 TypeScript 基础环境已经搭建完毕。
2.AI 开发必备 TypeScript 核心语法
在 AI 应用开发(尤其是 LangChain/LangGraph 源码级开发)中,你需要处理极其动态的数据结构。本节聚焦 4 个构建 AI 架构最核心的概念,掌握这些,你才能看懂 AI 框架的源码,才能写出优雅的 Zod Schema。
1. 核心基础类型
在 AI 开发中,我们最常打交道的不是简单的字符串,而是浮点数(温度、概率)和向量数组。
// 1. 基础原始类型
const modelName: string = "gpt-4o-mini";
const temperature: number = 0.7; // 浮点数也是number
const isStream: boolean = true;
// 2. 数组(Array)- 处理Prompt列表或Tags
const stopSequences: string[] = ["User:", "AI:"];
// 或者使用泛型写法
const tags: Array<string> = ["coding", "general"];
// 3. 元组(Tuple)- AI开发中极为重要!
// 场景:向量数据库的Embedding或者是坐标
// 这是一个固定长度、固定类型的数组
const embeddingVector: [number, number, number] = [0.12, 0.98, -0.55];
// 4. Any vs Unknown(面试官考点)
// ❌ try not to use any:放弃类型检查,甚至会污染后续代码
let badData: any = "hello";
badData = 123; // 编译器闭嘴了,但运行时可能炸
// ✅ use unknown:表示"我暂时不知道这是啥,但在使用前我必须检查"
let apiData: unknown = fetchResponse();
if (typeof apiData === 'string') {
console.log(apiData.toUpperCase()); // 安全
}2. 接口(Interface)vs 类型别名(Type)
这是新手最纠结的问题。在 99% 的应用开发场景下,它们可以混用。
核心区别:
- Interface(接口):主要用于定义对象的形状(Shape),支持继承(extends),更像面向对象
- Type(类型别名):更灵活,可以定义对象,也可以定义联合类型(Union Types)
实战推荐 :定义数据模型用interface,定义复杂组合逻辑用type。
// 定义一个对象结构
interface User {
id: string;
name: string;
}
// 继承扩展
interface AdminUser extends User {
permissions: string[];
}
// 定义一个简单的字面量联合类型(Type擅长的领域)
// 限制model只能是这两个字符串之一,防止拼写错误
type SupportedModel = "gpt-3.5-turbo" | "gpt-4";3. 函数类型定义
函数是逻辑的载体。在 TS 中,我们需要约束入参和返回值。
// 基础写法
function calculateCost(tokens: number, pricePerK: number): number {
return (tokens / 1000) * pricePerK;
}
// 箭头函数写法
const buildPrompt = (system: string, user: string): string => {
return `${system}\n\nHuman: ${user}\nAI:`;
};
// 异步函数(返回值自动推导为Promise)
async function fetchCompletion(): Promise<string> {
return "AI response...";
}4. 两个兜底符号:? 和!
处理 AI 接口返回的数据时,这两个符号能极大减少代码量。
可选属性(?)
有些字段 API 不一定返回(比如 usage 统计字段)。
interface AIResponse {
content: string;
usage?: { // 加了问号,表示该字段可能是undefined
tokens: number;
};
}
const res: AIResponse = { content: "Hi" }; // 不写usage也不报错
// 可选链(Optional Chaining)- 安全访问
// 如果usage不存在,直接返回undefined,而不会报错crash
console.log(res.usage?.tokens);非空断言(!)
当你比 TS 编译器更清楚 "这个变量一定有值" 时使用。慎用!
const apiKey = process.env.OPENAI_API_KEY;
// TS可能会报错说apiKey可能是undefined
// 如果你确定环境变量里配了,可以加!强制通过
const client = new OpenAI({ apiKey: apiKey! });3. AI 开发必备 TypeScript 高级特性
泛型(Generics):打造通用的 AI 交互协议
泛型是 TypeScript 中的 **"参数化类型"**,允许你在定义类型时不指定具体类型,而是在使用时动态传入。核心痛点
LLM 的返回结果往往有固定的外层结构(如status、usage、latency),但核心的data字段千变万化(可能是文章摘要、代码生成结果、工具调用参数等)。如果为每种返回结果都写一个完整的接口,代码会极度冗余且难以维护。
实战场景:定义通用的 LLM 响应包装器
// T 代表具体的数据结构,默认any,但强烈建议传入具体类型
interface LLMResponse<T> {
status: "success" | "error";
latency: number; // 接口耗时
usage: {
promptTokens: number;
completionTokens: number;
};
// 核心:data的类型由使用时决定
data: T;
}
// 定义一个具体的业务数据结构:文章摘要
interface ArticleSummary {
title: string;
summary: string;
keywords: string[];
}
// 使用泛型:让TS自动推导data必须符合ArticleSummary结构
function handleAIResponse(res: LLMResponse<ArticleSummary>) {
// 此处输入res.data.时,编辑器会自动提示title、summary、keywords字段
console.log(res.data.title);
console.log(res.data.keywords.join(", "));
}工具类型(Utility Types):精准控制上下文(Context)
AI 上下文窗口(Context Window)是极其昂贵的资源。我们经常需要对现有数据类型进行裁剪 或弱化,只把必要的字段发给 LLM,或者处理流式输出的残缺数据。
TypeScript 内置了一系列工具类型,专门用于快速转换已有类型,无需重复定义。
实战场景 1:发送给 AI 的上下文(剔除敏感字段)
使用Omit<T, K>工具类型,从类型 T 中删除指定的 K 属性。
interface UserProfile {
id: string;
name: string;
email: string; // 隐私数据,不发给AI
passwordHash: string; // 敏感数据,绝不可发
preferences: string[];
}
// 从UserProfile中删除passwordHash和email字段
type AIContextProfile = Omit<UserProfile, "passwordHash" | "email">;
// 现在AIContextProfile只包含id、name、preferences三个字段
const userContext: AIContextProfile = {
id: "user_123",
name: "张三",
preferences: ["编程", "AI"]
};实战场景 2:处理流式输出(Streaming)
使用Partial<T>工具类型,将类型 T 的所有属性变为可选(?)。 因为 AI 是一个字一个字吐出来的,解析中间状态的 JSON 时,很多字段可能还没生成完成。
// 基于上面的AIContextProfile
type StreamingProfile = Partial<AIContextProfile>;
// 流式输出的中间状态,只有name字段生成了,其他字段还没到
const currentStream: StreamingProfile = {
name: "User",
// preferences可能还没生成出来,不会报错
};其他 AI 开发常用工具类型
Pick<T, K>:与 Omit 相反,只保留类型 T 中的 K 属性Required<T>:将类型 T 的所有属性变为必选Readonly<T>:将类型 T 的所有属性变为只读
联合类型与可辨识联合(Discriminated Unions):Agent 的状态机
这是LangChain/LangGraph 处理消息历史的核心模式。一个智能体的消息可能是用户的输入、AI 的回复,也可能是工具(Tool)调用的结果。如何在类型层面安全地区分它们?原理
可辨识联合要求联合类型中的每个成员都包含一个相同名称的字面量类型字段(称为 "可辨识特征" 或 "标签"),TypeScript 可以通过这个字段自动收窄类型。
实战场景:区分不同角色的 Chat Message
interface UserMessage {
role: "user"; // 核心:可辨识的特征字段(Discriminant)
content: string;
}
interface AIMessage {
role: "assistant";
content: string | null;
tool_calls?: any[]; // AI可能会调用工具
}
interface ToolMessage {
role: "tool";
tool_call_id: string; // 对应AI的tool_call_id
content: string; // 工具执行的结果
}
// 定义消息总类型
type ChatMessage = UserMessage | AIMessage | ToolMessage;
// 渲染不同类型的消息
function renderMessage(msg: ChatMessage) {
// TS的强大之处:通过判断role,自动收窄类型
if (msg.role === "tool") {
// 在这个代码块里,msg被自动推导为ToolMessage类型
// 可以安全访问msg.tool_call_id,而不用担心报错
console.log(`Tool Output [${msg.tool_call_id}]: ${msg.content}`);
} else if (msg.role === "assistant") {
// 在这个代码块里,msg被自动推导为AIMessage类型
console.log(`AI: ${msg.content}`);
if (msg.tool_calls) {
console.log(`AI调用了${msg.tool_calls.length}个工具`);
}
} else {
// 在这个代码块里,msg被自动推导为UserMessage类型
console.log(`User: ${msg.content}`);
}
}4、typeof 与类型推导:为 Zod 做铺垫
typeof操作符是实现这一模式的基础,它可以从一个已有的值中推导出它的类型。
实战场景:从配置对象推导类型
// 假设这是一个配置对象(在Zod中这将是一个Schema)
const defaultModelConfig = {
model: "gpt-4o",
temperature: 0.7,
maxTokens: 4096,
features: {
streaming: true,
jsonMode: true
}
};
// 不需要手动写interface ModelConfig = { ... }
// 直接让TS帮我们不费吹灰之力推导出来
type ModelConfig = typeof defaultModelConfig;
// 此时ModelConfig的类型已经是精确的结构了
function initModel(config: ModelConfig) {
// 传入的config必须和defaultModelConfig的结构完全一致
console.log(`初始化模型:${config.model}`);
console.log(`温度:${config.temperature}`);
}
// 正确调用
initModel(defaultModelConfig);
// 错误调用(会在编译阶段报错)
// initModel({ model: "gpt-3.5-turbo", temperature: "0.7" }); // temperature类型错误二. Zod 基础与进阶:AI 开发的运行时类型安全屏障
Zod 是AI 开发中不可或缺的核心工具,它解决了 TypeScript 最大的痛点:类型只存在于编译阶段,无法阻挡运行时错误。在大模型返回数据不可靠的 AI 场景下,Zod 是保护你应用不崩溃的最后一道防线。
传统 Web 开发 vs AI 开发的本质区别
- 传统 Web 开发:后端 API 返回通常是确定的,类型和字段基本固定
- AI 开发 :大模型是概率模型,它可能返回:
- 错误的字段类型(比如你要数字,它返回字符串 "100")
- 缺失的字段
- 多余的无关字段
- 甚至是一段只有一半的无效 JSON
Zod 的核心哲学
先定义 Schema(数据蓝图),再自动推导出 TS 类型
这彻底解决了新手最容易犯的错误:写一遍 Interface,再写一遍 Validation 逻辑。这种做法不仅累,还极易导致两边不一致,引入难以排查的 bug。
1.Zod 基础:单一数据源(Single Source of Truth)
安装 Zod
npm install zod
# 或者
pnpm add zod2. 定义 Schema(既是验证逻辑,也是类型定义)
Schema 定义了数据的结构、类型和验证规则,是 Zod 的核心。
import { z } from "zod";
// 定义简历信息Schema(AI提取简历信息场景)
const ResumeSchema = z.object({
name: z.string().min(2, "名字太短了"), // 字符串,且至少2个字符
age: z.number().int().positive(), // 必须是正整数
skills: z.array(z.string()), // 字符串数组
isOpenToWork: z.boolean().default(true), // 默认为true
// .optional()表示该字段AI可能不返回
linkedIn: z.string().url().optional(),
});3. 自动推导 TypeScript 类型(魔法发生的地方)
不需要手动写interface Resume = { ... },Zod 会自动从 Schema 中推导出完全一致的 TypeScript 类型。
// 从Schema自动推导类型
type Resume = z.infer<typeof ResumeSchema>;
// 此时,Resume类型完全等同于:
// interface Resume {
// name: string;
// age: number;
// skills: string[];
// isOpenToWork: boolean;
// linkedIn?: string | undefined;
// }4. 运行时校验:.parse () vs .safeParse ()
当拿到 LLM 的响应(通常是 JSON 字符串)后,我们需要验证它是否符合预期。Zod 提供了两种校验方式:
| 方法 | 行为 | 适用场景 |
|---|---|---|
.parse(data) |
验证失败会直接抛出错误(Throw Error) | 你确定数据必须正确,否则程序无法运行的场景 |
.safeParse(data) |
AI 开发首选 。不会抛出错误,而是返回一个包含success状态的对象 |
所有 AI 接口调用场景,大模型返回的数据永远不可信 |
// 模拟一个AI返回的"脏数据"(年龄是字符串,而不是数字)
const aiResponse = {
name: "Alex",
age: "28", // 错误类型
skills: ["React", "AI"]
};
// 使用safeParse进行校验
const result = ResumeSchema.safeParse(aiResponse);
if (!result.success) {
// 优雅降级:处理错误,或者让AI重试
console.error("AI格式错误:", result.error.format());
} else {
// 这里的data已经是被TS认可的Resume类型
// 编辑器会自动提示所有字段,类型安全有保障
console.log("验证通过:", result.data.name);
console.log("技能:", result.data.skills.join(", "));
}Zod 进阶:专门为 AI 场景打造的核心技巧
在对接 OpenAI Function Calling 或 Structured Outputs 时,以下几个 Zod 特性是必学的。
1. z.coerce:宽容模式(自动纠错)
大模型经常会犯低级错误,比如你想要数字100,它给你返回字符串"100";你想要布尔值true,它给你返回字符串"true"。
使用z.coerce可以让 Zod 尝试自动转换这些错误类型,大大提高校验成功率。
const FlexibleSchema = z.object({
// 如果输入是"100",会自动转为数字100
age: z.coerce.number(),
// 如果输入是"true",会自动转为布尔值true
isActive: z.coerce.boolean()
});
// 测试:字符串"28"会被自动转为数字28
const result = FlexibleSchema.safeParse({ age: "28", isActive: "true" });
console.log(result.success); // true
console.log(result.data.age); // 28 (number类型)2. z.describe ():用代码写 Prompt
这是Zod 在 AI 领域最强大的功能。你可以给字段添加描述,这些描述会被转换成 JSON Schema 发送给 AI,告诉 AI 这个字段的含义和要求。
const SentimentSchema = z.object({
score: z.number()
.min(0).max(10)
.describe("情感打分,0分代表极度负面,10分代表极度正面"), // 给AI看的说明书
reasoning: z.string()
.describe("简短解释为什么给出这个分数,不超过50个字")
});当我们配合 LangChain 或 OpenAI 使用时,AI 不仅知道要返回number类型,还能读懂.describe()里的业务逻辑,从而大幅提高输出的准确率。
3. 结构化输出(Structured Output)实战(OpenAI 原生支持)
OpenAI 和 Vercel AI SDK 现在的标准做法是将 Zod Schema 直接转换为 JSON Schema,强制大模型按照指定格式输出。
这是目前 AI 开发中处理结构化输出的最佳实践,能让解析成功率接近 100%。
import { zodResponseFormat } from "openai/helpers/zod";
import OpenAI from "openai";
const openai = new OpenAI();
// 定义步骤Schema
const StepSchema = z.object({
step_title: z.string(),
code_snippet: z.string(),
});
// 定义教程Schema
const TutorialSchema = z.object({
title: z.string(),
steps: z.array(StepSchema)
});
// 调用OpenAI时直接使用
const completion = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "user", content: "写一个使用React Hooks的简单计数器教程" }
],
// 核心:强制AI必须按照Zod的定义输出
response_format: zodResponseFormat(TutorialSchema, "tutorial_generation"),
});
const rawContent = completion.choices[0].message.content;
// 此时parse几乎100%成功,因为AI被Zod约束住了
const tutorial = TutorialSchema.parse(JSON.parse(rawContent!));
console.log("教程标题:", tutorial.title);
console.log("步骤数:", tutorial.steps.length);4. 验证器(Refinement):编写自定义业务逻辑
有时候,简单的类型检查不够用,我们需要添加自定义的业务逻辑验证,比如 "结束时间必须晚于开始时间"。
const DateRangeSchema = z.object({
start: z.string().date(),
end: z.string().date()
})
.refine((data) => {
// 自定义验证逻辑:结束时间必须晚于开始时间
return new Date(data.end) > new Date(data.start);
}, {
message: "结束时间不能早于开始时间", // 错误信息
path: ["end"] // 错误标记在哪个字段上
});
// 测试:结束时间早于开始时间,会触发自定义错误
const result = DateRangeSchema.safeParse({
start: "2024-01-01",
end: "2023-12-31"
});
if (!result.success) {
console.log(result.error.format().end?._errors); // ["结束时间不能早于开始时间"]
}三. 智能用户信息提取实战(Ollama + LangChain + Zod)
这是 AI 开发中最经典、最实用的场景之一 :从用户的自然语言输入中精准提取结构化的用户画像信息。我们将使用本地大模型 Ollama(无需 API 密钥)配合 LangChain 和 Zod,构建一个工业级的信息提取智能体。架构
1. 实战目标
从用户的自然语言描述(如 "我是合一,今年 18 岁,想找个工作看看机会")中,自动提取出姓名、年龄、潜在意图等结构化信息,并保证类型安全。
2. 工业级流水线架构
我们的智能体将遵循以下标准流程,这也是所有 AI 信息提取系统的通用架构:
| 步骤 | 名称 | 作用 |
|---|---|---|
| 1 | Input | 接收用户的自然语言输入 |
| 2 | LLM Brain | 加载本地大模型(如 Qwen/Llama),负责理解语义 |
| 3 | Zod Schema | 强制模型按照我们定义的结构思考和输出 |
| 4 | Validation | 自动校验数据类型和格式,过滤脏数据 |
| 5 | Output | 返回类型安全的 JSON 对象,供前端直接渲染或后端入库 |
. 前置准备
-
安装并运行 Ollama :从Ollama 官网下载安装,然后拉取对 JSON 支持较好的模型:
ollama pull qwen2.5:7b
或者使用llama3
ollama pull llama3
安装依赖包:
npm install @langchain/ollama zod # 或者 pnpm add @langchain/ollama zod
import { ChatOllama } from "@langchain/ollama";
import { z } from "zod";
// ==========================================
// Step 1: 定义数据契约(The Contract)
// ==========================================
// 这里的describe非常关键,它就是写给AI看的Prompt
const PersonInfoSchema = z.object({
name: z.string().describe("用户的姓名,如果是昵称也提取"),
age: z.number().int().describe("用户的年龄,必须是数字"),
// 增加意图推断字段,展示Zod的强大能力
intent: z.enum(["交友", "求职", "闲聊"])
.describe("根据用户语气判断其潜在意图")
.optional(),
});
// 自动推导TypeScript类型,供后续业务逻辑使用
type PersonInfo = z.infer<typeof PersonInfoSchema>;
// ==========================================
// Step 2: 构建智能体(The Agent)
// ==========================================
const createExtractionAgent = async () => {
// 1. 初始化本地大模型
const model = new ChatOllama({
model: "qwen2.5:7b", // 建议使用较新的模型以获得更好的指令遵循能力
temperature: 0, // 设为0,因为我们需要精确提取,不需要发散创造
});
// 2. 绑定结构化输出(Structured Output)
// 这是LangChain现代版本最核心的API
// 它会自动将Zod Schema转为Function Calling或JSON Schema发给模型
const structuredLlm = model.withStructuredOutput(PersonInfoSchema);
return structuredLlm;
};
// ==========================================
// Step 3: 执行与验证(Execution)
// ==========================================
const invoke = async () => {
try {
console.log("🚀 Agent 启动中...");
const agent = await createExtractionAgent();
// 模拟用户输入
const userInput = "你好呀,我是合一,我今年刚好18岁,想找个工作看看机会。";
console.log(`👤 用户输入: "${userInput}"`);
// 调用AI
// 这里的res已经被TS自动推导为PersonInfo类型!
const res = await agent.invoke(userInput);
// 此时,res就是纯粹的JS对象,可以直接入库或渲染
console.log("\n✅ 提取成功 (Structured Data):");
console.log(JSON.stringify(res, null, 2));
// 演示类型安全的使用
if (res.age < 18) {
console.log("⚠️ 提示: 用户未成年");
} else {
console.log(`🎉 欢迎 ${res.name} 加入社区! 检测意图: ${res.intent}`);
}
} catch (error) {
console.error("❌ 提取失败:", error);
}
};
// 运行智能体
invoke();1. 为什么使用 withStructuredOutput 而不是简单的 Prompt?
在旧版本的 LangChain 中,我们需要手动在 Prompt 中写 "请返回 JSON 格式...",但这种方式有很多问题:
- 模型经常不遵守格式,返回无效 JSON
- 需要手动处理
JSON.parse和异常 - 没有类型安全保障
现代最佳实践:使用 model.withStructuredOutput(schema)
- 原理:它利用了 LLM 的 Tool Calling(工具调用)或 JSON Mode 能力,这是模型原生支持的功能
- 优势 :
- 极大降低了模型 "胡说八道" 的概率
- 自动完成了
JSON.parse和Zod.parse的过程 - 直接返回类型安全的对象,无需额外处理
2. Zod Schema 在其中的作用
- 作为数据契约:同时定义了 AI 的输出格式和 TypeScript 类型
- 作为 Prompt 的一部分 :
.describe()方法的内容会被发送给 AI,告诉它每个字段的含义 - 作为验证器:即使模型返回了错误的数据,Zod 也会在运行时捕获并抛出错误
3. 这里的 LangGraph 体现在哪里?
虽然上述代码是一个单一的 Chain,但在复杂的 LangGraph 应用中,这个invoke过程就是一个标准的Node(节点)。
你可以很容易地将其扩展为一个完整的工作流:
- Node A(提取器):运行上述代码提取用户信息
- Edge(判断逻辑) :如果
age < 18,跳转到 Node B(拒绝服务);否则跳转到 Node C(推荐职位) - Node B(拒绝服务):返回 "抱歉,我们的服务仅限成年人使用"
- Node C(推荐职位):根据用户的意图和技能推荐合适的职位
这正是 AI Agent 能够处理复杂业务逻辑的基础。