1. 图像基础知识
1.1 图像的基本概念
图像是由像素点组成的,每个像素点的取值范围为: 0, 255 。像素值越接近于0,颜色越暗,接近于黑色;像素值越接近于255,颜色越亮,接近于白色。
我们使用的图像大多是彩色图,彩色图由RGB3个通道组成
什么是RGB3个通道?
RGB:red、green、blue 三原色
HWC ->heiget, width, channel
3通道指转换后数组的格式为 heiget, width, 3
数据示例:
HWC ->heiget, width, channel ->(640, 640, 3):
\[\[212 113 94
212 113 94
212 113 94
...
115 40 63
108 34 57
103 31 55\]
\[212 113 94
212 113 94
212 113 94
...
107 32 55
99 27 51
94 24 48\]
\[212 113 94
211 112 93
211 112 93
...
96 23 50
88 18 44
84 15 43\]
...
\[205 183 196
205 183 196
205 183 195
...
229 193 205
231 193 204
231 193 204\]
\[240 230 239
240 230 238
240 230 238
...
251 230 237
251 230 237
250 229 236\]
\[255 252 255
255 253 255
255 253 255
...
255 249 253
255 248 252
255 247 251\]\]
1.2 使用matplotlib加载图片方法
plt.imshow(img) # 加载
img = plt.imread(r'./data/img.jpg') # 读取本地图片,转换为HWC 格式数据
python
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
matplotlib.use("TkAgg")
# img = np.zeros(shape=[300, 200, 3])
# img = np.full(shape=[300, 200, 3], fill_value=255)
# plt.imshow(img)
# plt.show()
# 读取本地图片,并加载展示
img = plt.imread(r'./data/img.jpg')
print(img.shape)
print(img)
plt.imshow(img)
plt.show()2. CNN概述
2.1 什么是卷积神经网络?
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络。 卷积层的作用就是用来自动学习、提取图像的特征.
用途:大多用来处理图像
2.2 卷积神经网络组成部分
CNN网络主要由三部分构成:卷积层、池化层和全连接层构成:
卷积层负责提取图像中的局部特征;
池化层用来大幅降低参数量级(降维);
全连接层用来输出想要的结果
3. 卷积层------提取图像中的局部特征
3.1 掌握卷积层计算过程
3.1.1 单通道卷积计算
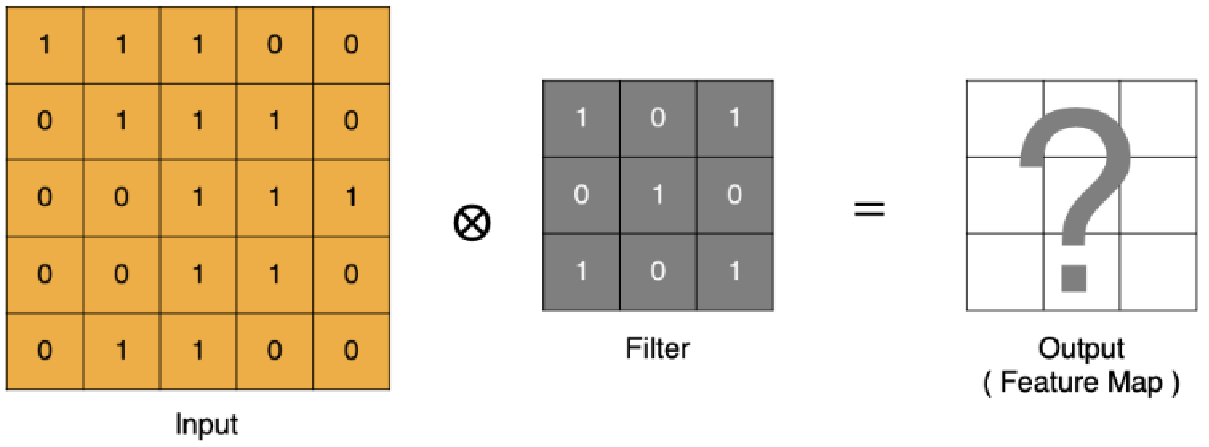
input 表示输入的图像
filter 表示卷积核, 也叫做卷积核(滤波矩阵)
input 经过 filter 得到输出为最右侧的图像,该图叫做特征图(feature map)
计算过程:
卷积运算本质上就是在卷积核和输入数据的局部区域间做点积。
4 = (1x1 + 1x0 + 1x1) + (0x1+1x1+1x0) + (0x1+0x0+1x1)
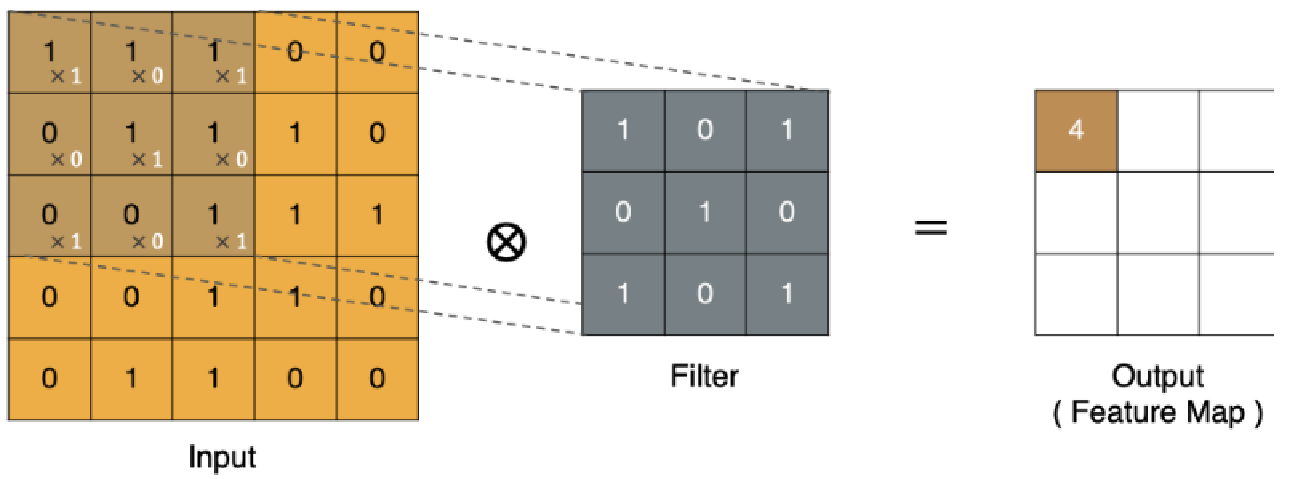
最终的特征图结果为:
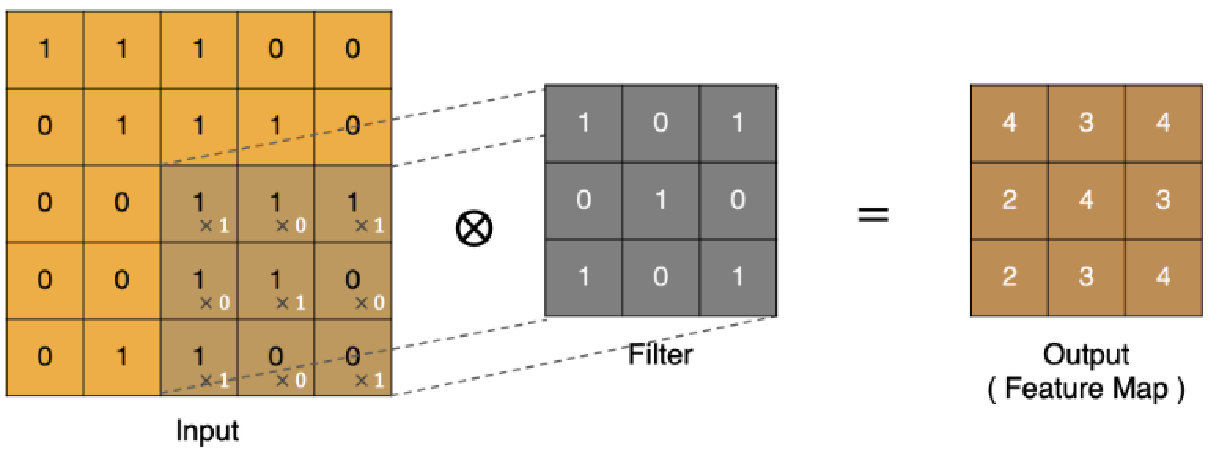
Padding:
作用:中间的数据可以多次扫描,边上的只能扫描一次。通过在边上添加一圈0的方式,实现对边上的数据实现多次扫描
Stride(步长):
移动卷积核的步长,一般步长都为1
3.1.2 多通道卷积计算:
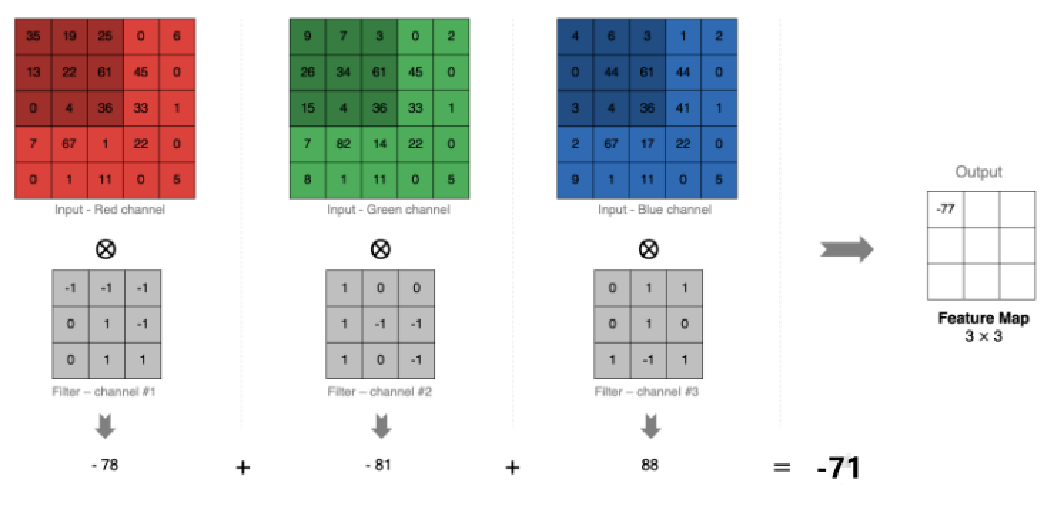
计算过程:
① 分别计算各个通道的卷积 (-78, -81,88)
② 各个通道的结果相加,得最后结果 (相加得 -71)
3.1.3 多卷积核卷积:
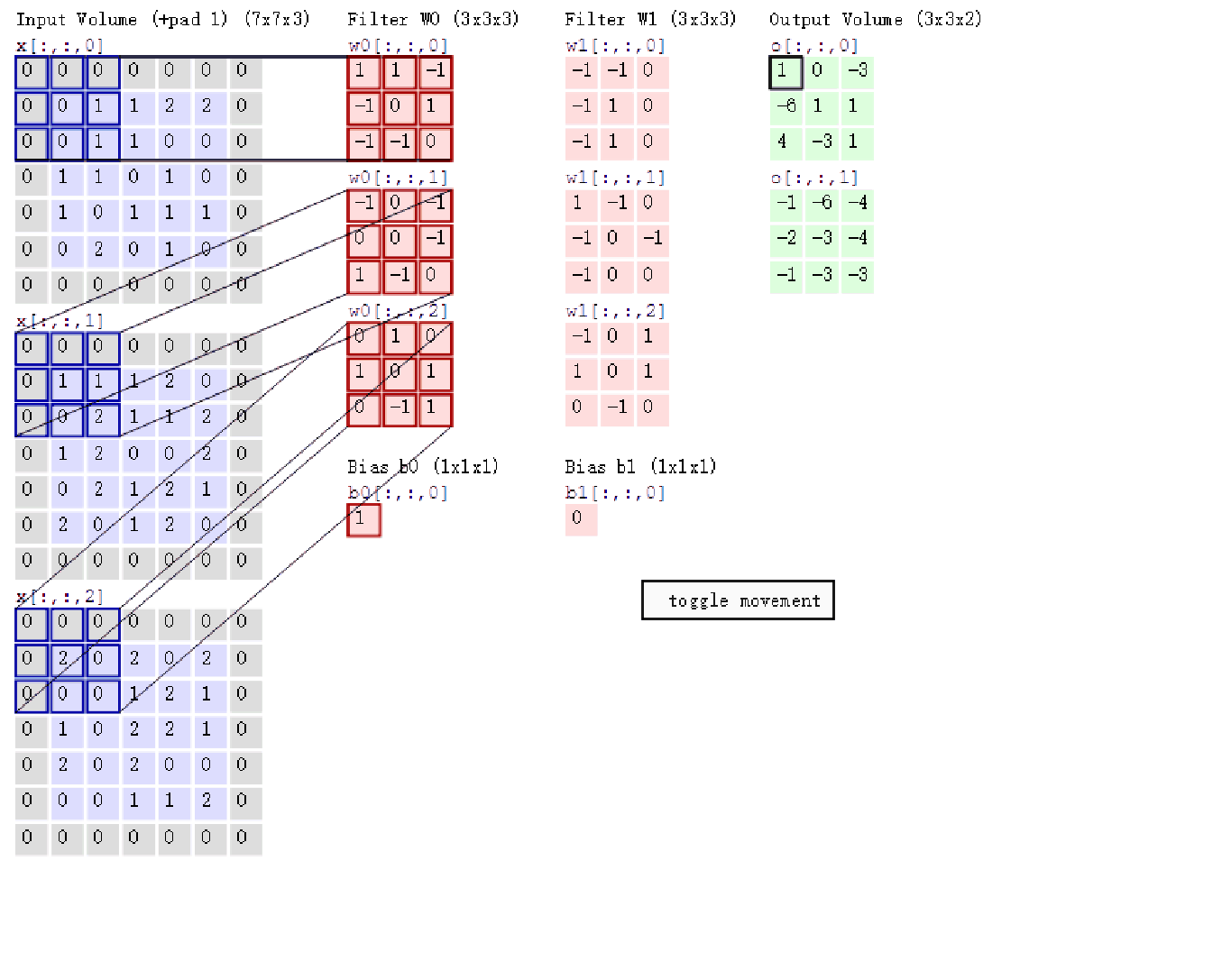
计算过程:
① 两个卷积核:w0,w1
② 分别对w0,w1做多通道卷积
③ 最终得到两个结果
多卷积核卷积会形成多个结果
3.2 【掌握】特征图大小计算方法
输出特征图的大小与以下参数息息相关:
size: 卷积核/过滤器大小,一般会选择为奇数,比如有 1*1 、3*3、5*5
Padding: 零填充的方式
Stride: 步长
计算方法如下图所示:
输入图像大小: W x W
卷积核大小: F x F
Stride: S
Padding: P
输出图像大小: N x N
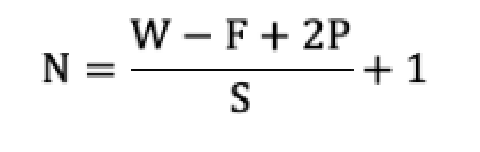
3.3 掌握PyTorch卷积层API
torch.nn.Conv2d(in_channels=3, out_channels=5, kernel_size=(3, 5), padding=0, stride=(1, 2))
参数:
in_channels: 输入图像大小
out_channels: 输出图像大小
kernel_size: 卷积核
padding: 添加0的圈数
stride: 步长
python
import torch
import matplotlib.pyplot as plt
# 图像获取、数据处理
img = plt.imread(r'./data/img.jpg')
print(img.shape)
data = torch.tensor(img, dtype=torch.float32).permute(2, 0, 1).unsqueeze(0)
print(data.shape)
# 卷积层
conver_layer = torch.nn.Conv2d(in_channels=3, out_channels=5, kernel_size=(3, 5), padding=0, stride=(1, 2))
feature_map = conver_layer(data)
print(feature_map.shape)
# 卷积层2
conver_layer2 = torch.nn.Conv2d(in_channels=5, out_channels=2, kernel_size=3, padding=0, stride=1)
feature_map2 = conver_layer2(feature_map)
print(feature_map2.shape)
'''
输出:
(640, 640, 3)
torch.Size([1, 3, 640, 640])
torch.Size([1, 5, 638, 318])
torch.Size([1, 2, 636, 316])
'''4. 池化层------大幅降低参数量级(降维)
4.1【掌握】池化层计算过程
4.1.1 【常用】最大池化
取选中区域(池化窗口内)的最大值,0,1,3,4 中的最大值

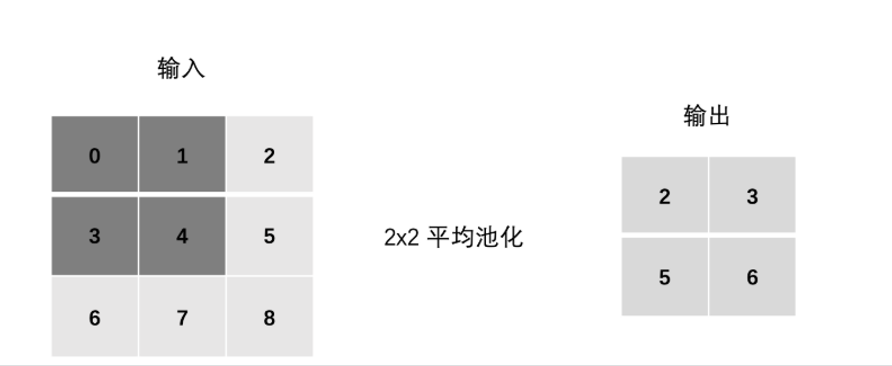
4.1.2 【了解】平均池化
取选中区域(池化窗口内)的平均值,0,1,3,4 中的平均值
4.2【掌握】PyTorch池化层API
最大池化:torch.nn.MaxPool2d(kernel_size=3, stride=1)
平均池化:torch.nn.AvgPool2d(kernel_size=3, stride=1)
参数:
kernel_size:池化窗口,类似于卷积核
stride:步长
python
import torch
data = torch.tensor([[[[1, 3, 4, 5],
[2, 6, 8, 10],
[7, 9, 6, 2],
[6, 5, 8, 1]
],
[[1, 3, 4, 5],
[2, 6, 8, 10],
[7, 9, 6, 2],
[6, 5, 8, 1]
]
]], dtype=torch.float32)
print(data.shape)
# 最大池化
pool_max = torch.nn.MaxPool2d(kernel_size=3, stride=1)
print(pool_max(data))
print(pool_max(data).shape)
# 平均池化
pool_avg = torch.nn.AvgPool2d(kernel_size=3, stride=1)
print(pool_avg(data))
print(pool_avg(data).shape)
'''
输出:
torch.Size([1, 2, 4, 4])
tensor([[[[ 9., 10.],
[ 9., 10.]],
[[ 9., 10.],
[ 9., 10.]]]])
torch.Size([1, 2, 2, 2])
tensor([[[[5.1111, 5.8889],
[6.3333, 6.1111]],
[[5.1111, 5.8889],
[6.3333, 6.1111]]]])
torch.Size([1, 2, 2, 2])
Process finished with exit code 0
'''5. 图像分类案例
构建一个卷积神经网络, 并训练该网络实现图像分类
1、使用CIFAR10 数据集
2、卷积神经网络
3、使用下边指定网络结构
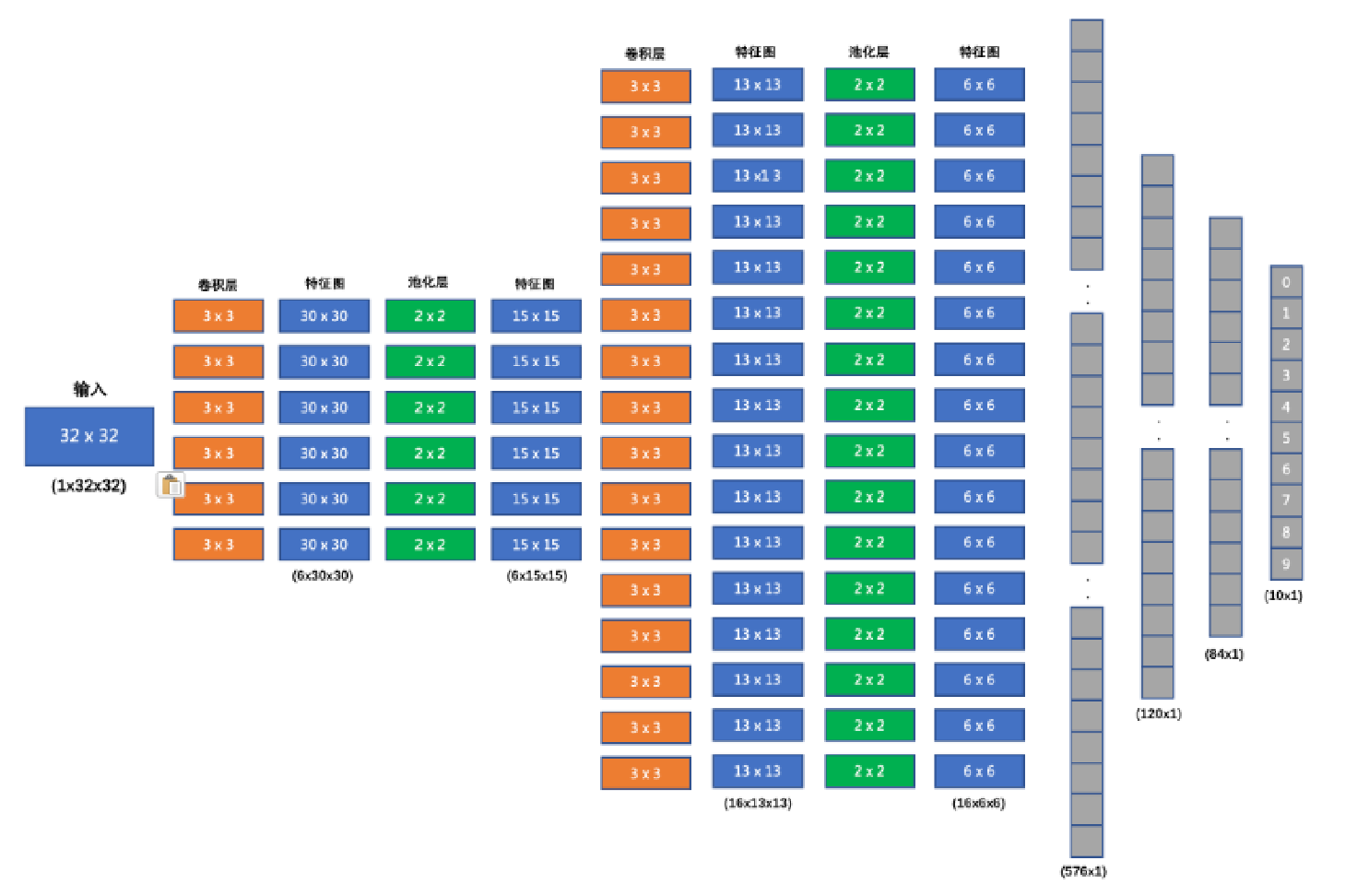
python
import time
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor, Compose
import matplotlib.pyplot as plt
import matplotlib
from torch.utils.data import DataLoader
from torch import nn
import torch
from torchsummary import summary
matplotlib.use("TkAgg")
def get_data():
data_train = CIFAR10(root=r"./data/", train=True, transform=Compose([ToTensor()]))
data_test = CIFAR10(root=r"./data/", train=False, transform=Compose([ToTensor()]))
return data_train, data_test
class BuildNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.linear1 = nn.Linear(in_features=576, out_features=120)
self.linear2 = nn.Linear(in_features=120, out_features=84)
self.linear_out = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = self.pool1(x)
x = torch.relu(self.conv2(x))
x = self.pool2(x)
x = x.reshape(x.shape[0], -1)
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
out = self.linear_out(x)
return out
def train(model, dataloader):
# 损失函数
error = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.99))
# 循环遍历
epochs = 100
for epoch in range(epochs):
start_time = time.time()
loss_sum = 0
iter_num = 0
for x, y in dataloader:
# 结果预测
y_pred = model(x)
# 损失计算
loss = error(y_pred, y)
loss_sum += loss.item()
iter_num += 1
# 反向传播
# 更新梯度
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"epoch:{epoch},loss:{loss_sum / iter_num},time:{time.time() - start_time}")
torch.save(model.state_dict(), r'./data/model_img.gth')
def evaluate(model, dataloader):
# 模型加载训练好的参数
weight = torch.load(r'./data/model_img.gth',weights_only=True)
model.load_state_dict(weight)
# 模型预测、准确度计算
correct_sum = 0
for x, y in dataloader:
y_pred = model(x)
y_pred = torch.argmax(y_pred, dim=-1)
correct_sum += (y_pred == y).sum()
acc = correct_sum/len(dataloader.dataset)
print(f"准确率:{acc}")
if __name__ == '__main__':
train_dataset, valid_dataset = get_data()
print("数据集类别:", train_dataset.class_to_idx)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, shuffle=True)
test_dataloader = DataLoader(dataset=valid_dataset, batch_size=10, shuffle=True)
# for x, y in train_dataloader:
# print(x.shape)
# print(y)
# break
model = BuildNetwork()
# print(summary(model=model, input_size=(3, 32, 32), batch_size=10, device="cpu"))
train(model=model, dataloader=test_dataloader)
evaluate(model=model, dataloader=test_dataloader)
# 输出: 准确率:0.9904000163078308