**帧间运动补偿预测(Inter-frame Motion Compensated Prediction, MCP)*是 H.265/HEVC 视频编码标准中降低*时域冗余、实现高压缩比的关键支撑。
视频序列中,相邻帧之间往往包含极大的相似性(如运动的物体、平移的背景)。帧间预测的核心思想就是:不直接编码当前的图像,而是通过运动矢量(MV)指向已经编码完成的参考帧,只编码当前块与参考块之间的"差值"(残差)。
HEVC 在上一代 H.264 的基础上,对帧间预测的块架构、运动矢量预测机制、插值滤波等进行了颠覆性的升级,使其在同等画质下比 H.264 节省了近 50% 的码率。
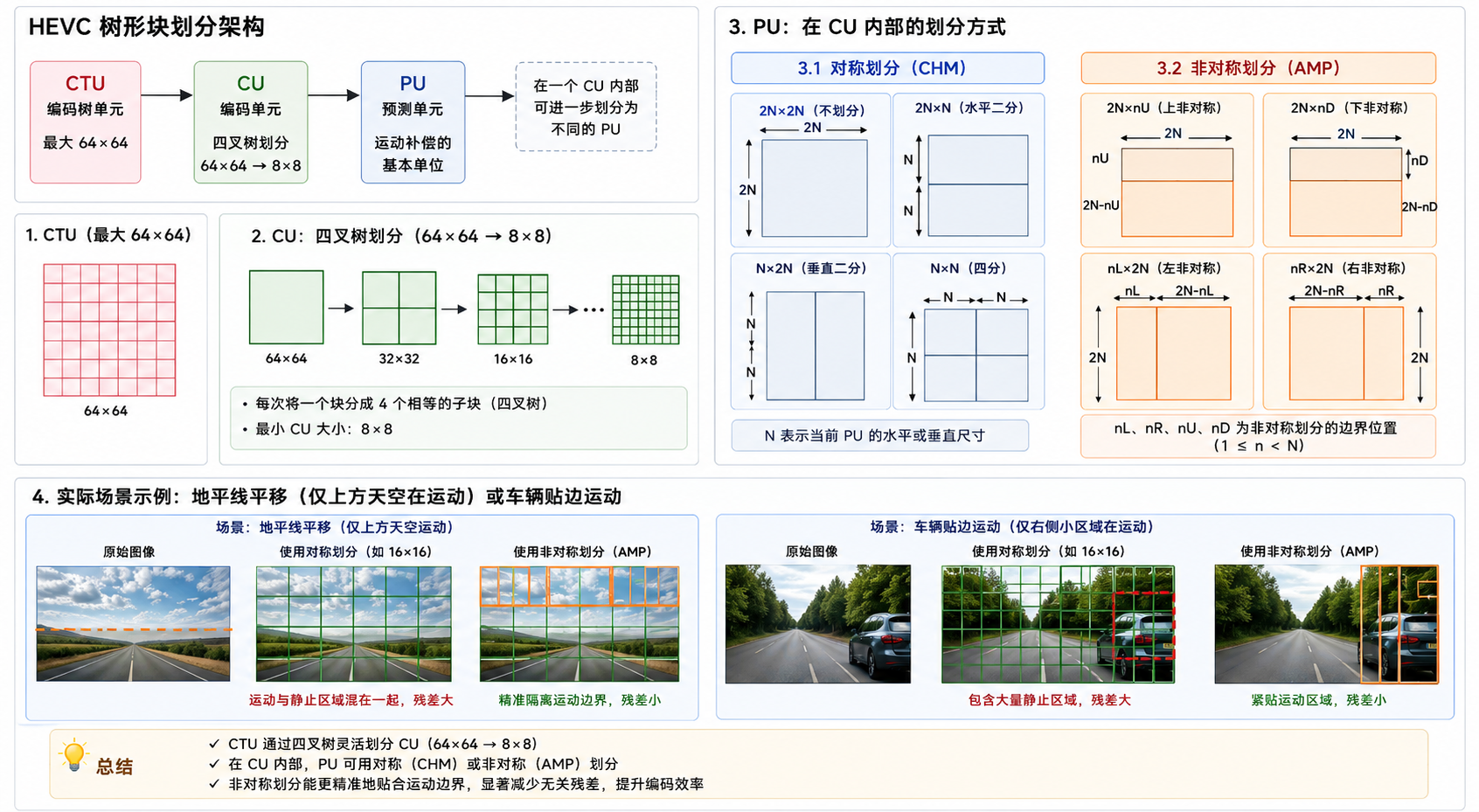
基于 CTU 架构的灵活块划分
H.264 时代的运动补偿局限于最大 16×1616 \times 1616×16 的宏块(Macroblock)。面对 4K、8K 等高分辨率视频,微小的宏块会导致运动估计产生大量的冗余运动矢量。
HEVC 引入了全新的树形块划分架构:
- CTU(编码树单元) :最大支持 64×6464 \times 6464×64。
- CU(编码单元) :CTU 通过四叉树逐步划分,大小可从 64×6464 \times 6464×64 降至 8×88 \times 88×8。
- PU(预测单元) :是帧间运动补偿的最终基本单位。在一个 CU 内部,可以进一步划分为不同的 PU。
HEVC 提供了两类 PU 划分方式:
- 对称划分(CHM) :如 2N×2N2N \times 2N2N×2N(不划分)、2N×N2N \times N2N×N、N×2NN \times 2NN×2N、N×NN \times NN×N。
- 非对称划分(AMP) :如 2N×nU2N \times nU2N×nU、2N×nD2N \times nD2N×nD、nL×2NnL \times 2NnL×2N、nR×2NnR \times 2NnR×2N。这在处理画面中边缘仅有一小部分在运动(如地平线平移、车辆贴边运动)时,能极其精准地隔离运动边界,防止引入无关的残差。
创新的运动信息预测机制
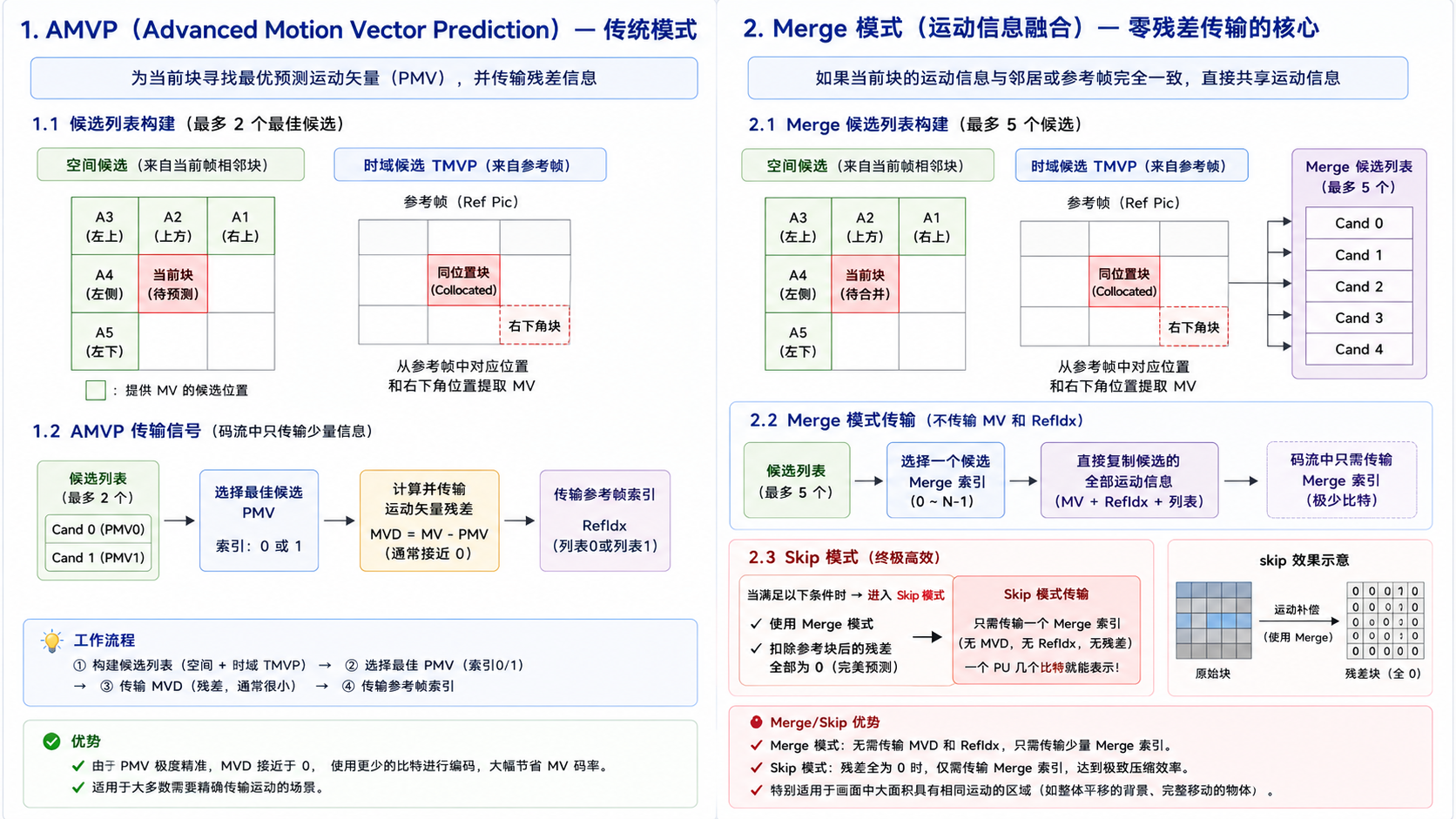
在帧间编码中,每个 PU 都需要传输运动矢量(MV)和参考帧索引(RefIdx)。如果对每个块都直接传输真实的 MV,MV 本身就会吃掉海量的码率。为此,HEVC 设计了两套天才的运动矢量预测机制:AMVP 模式 和 Merge 模式。
AMVP(Advanced Motion Vector Prediction,高级运动矢量预测)
AMVP 用于传统模式,即编码器仍然需要传输运动残差。它的核心任务是为当前块寻找一个最准的预测运动矢量(PMV)。
- 候选列表构建 :AMVP 建立一个包含 2 个最佳候选 MV 的列表:
- 空间候选:检查当前块左下方、左侧、右上方、上方、左上方相邻块的 MV。
- 时域候选(TMVP):检查相邻参考帧中,与当前块同位置(Collocated)的块及右下角块的 MV。
- 传输信号 :编码器只需在码流中传输:
候选列表索引(0或1)+运动矢量残差(MVD = 真实MV - PMV)+参考帧索引。由于 PMV 极度精准,MVD 通常接近于 0,大幅节省了 MV 码率。
Merge 模式(运动信息融合)
Merge 模式是 HEVC 的杀手锏。如果当前块的运动状态和它周围的块或前一帧一模一样(例如一辆车作为一个整体在移动),那它就完全不需要传输任何 MVD 和参考帧索引。
- 共享运动参数:Merge 模式构建一个包含最多 5 个候选者的列表(同样包含空间和时域候选)。当前块直接"复制"选中候选者的全部运动信息(包括前向/后向 MV、参考帧表)。
- Skip 模式 :如果当前块不仅运动信息和邻居一样(使用 Merge),而且由于运动估计太精准,导致扣除参考块后的残差像素全部为 0 ,那么这个块就会进入 Skip(跳过)模式。此时整个 PU 在码流中只需要传输一个 Merge 索引,用几个比特就能代表一个巨大的图像块,这是 HEVC 展现极致压缩率的最高光时刻。
高阶亚像素插值滤波
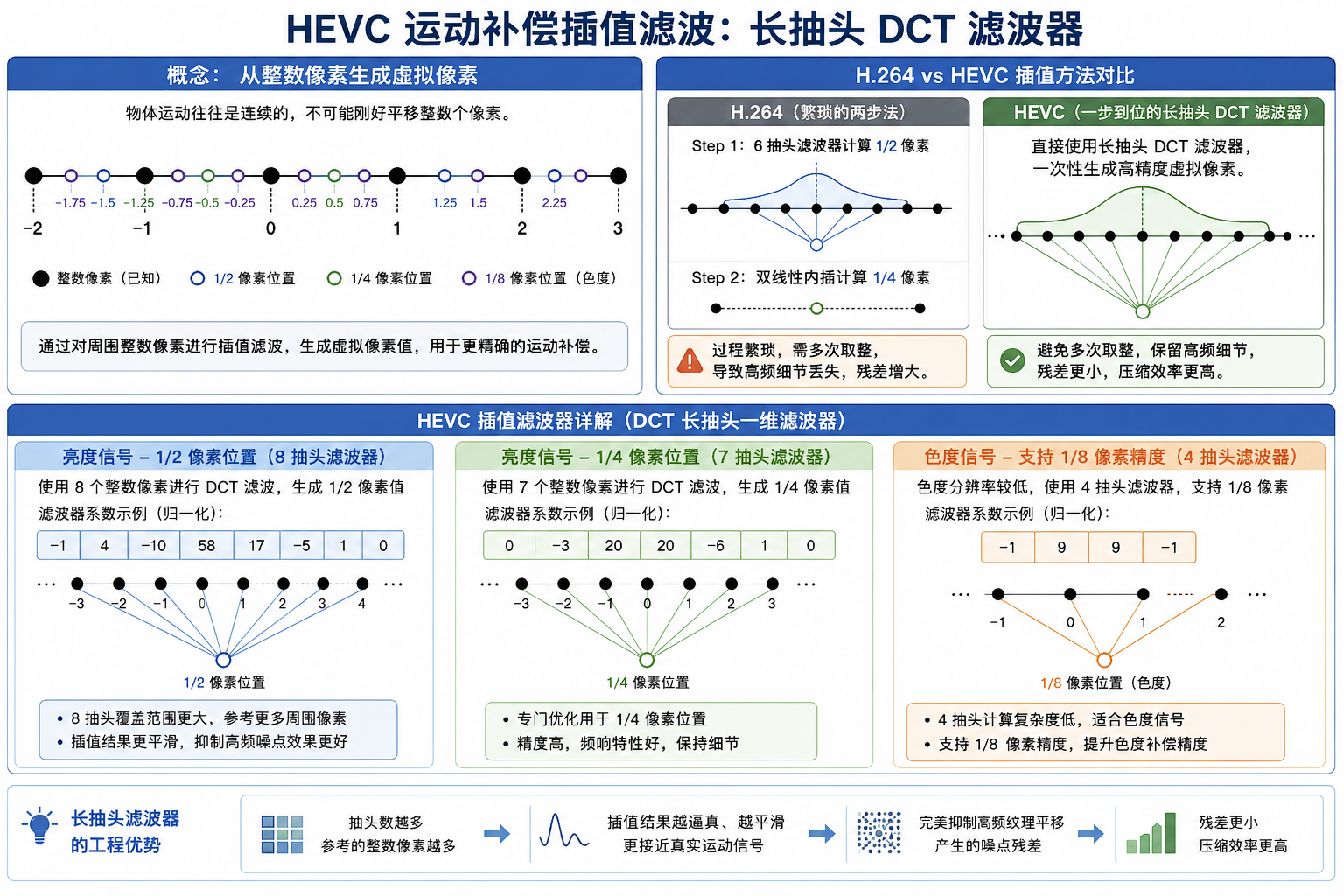
在物理世界中,物体的运动往往是连续的,不可能刚好每次都平移整数个像素(Pixel)。为了捕捉微小的运动,HEVC 的运动补偿支持 1/41/41/4 像素精度(Quarter-Pel)。
为了获取 1/4 或者是 1/2 处的虚拟像素值,编码器必须对周围的整数像素进行插值滤波(Interpolation Filtering)。
- H.264 的做法:采用 6 抽头(Tap)滤波器计算 1/2 像素,再用双线性内插计算 1/4 像素。过程繁琐且多次取整会导致高频细节丢失。
- HEVC 的全升级 :直接采用一维长抽头 DCT(离散余弦变换)滤波器 。
- 亮度信号 :1/2 像素位置使用 8 抽头 滤波器,1/4 像素位置使用 7 抽头 滤波器。
- 色度信号 :由于 HEVC 支持 1/81/81/8 像素精度的色度运动补偿,引入了 4 抽头 滤波器。
长抽头的工程优势:抽头数越多,参考的整数像素就越多,插值出来的虚拟像素就越逼真、越平滑,能够完美抑制由于画面高频纹理平移产生的噪点残差。
时域 MVP 与 DPB 约束
帧间预测的强大离不开后台的仓储管理------DPB(Decoded Picture Buffer,解码图像缓冲区)。HEVC 通过构建 List0(前向/主要)和 List1(后向)两个参考列表来管理多参考帧。
时域运动矢量预测(TMVP)的隐患与解决
前面提到,AMVP 和 Merge 都会去前一帧的同位置块(Collocated Block)偷取 MV。这在带来性能增益的同时,导致了解码器的硬件带宽危机。因为解码器在处理当前帧时,必须从外部内存(DDR)中把前一帧的所有 MV 数据(称为 Motion Field)全部读出来。
- HEVC 优化(Motion Data Compression) :为了降低这部分内存带宽开销,HEVC 在存储前一帧的运动信息时,强制对其进行 16×1616 \times 1616×16 的下采样(压缩) 。每 16×1616 \times 1616×16 的区域只保留一个顶层 MV,使时域 MV 的内存开销暴跌了 16 倍,完美解放了 4K/8K 播放时的芯片总线带宽。
重叠块运动补偿(OBMC)与边界平滑
在 PU 块级别进行独立的运动补偿,容易在 PU 的边界处产生由于运动不一致导致的"不连续性",从而在进入变换量化阶段时产生高频噪声。HEVC 的环路滤波机制(去块滤波、SAO)会在运动补偿完成后对这些边界进行平滑,确保画面融为一体。
帧间预测的参数配置与算力权衡
在工业级编码器(如 x265)中,帧间运动补偿(特别是运动估计运动搜索阶段)占据了整个视频编码器 60% 以上的 CPU 算力。
运动搜索策略控制
编码器需要决定如何在参考帧里找运动块:
--me <integer/string>:运动搜索算法。dia(菱形搜索)/hex(六边形搜索):速度极快,适合实时直播(Low-Delay)。umh(非均匀多层次十字交叉搜索)/star(星型搜索):全面搜寻,能挖掘出极致的残差红利,但极度消耗算力,适合点播离线转码。
亚像素精度的妥协
--subme <integer>:亚像素控制等级。决定了插值滤波的精细程度(从仅整数像素搜索到完全开启 8/7 抽头 1/4 像素搜索)。调高此参数能显著降低码率,但会成倍拉长编码时间。
bash
# 高清实时直播流配置示例(兼顾帧间压缩与编码速度)
ffmpeg -i input.mp4 -c:v libx265 -x265-params me=hex:subme=2:ref=3:no-amp=1 output.mp4
# (通过使用六边形搜索、降低亚像素级、限制参考帧为3、关闭非对称AMP划分来榨取速度)总结
HEVC 的帧间运动补偿预测技术是一套以 "大块(CTU)动态裁剪" 铺路、由 "Merge/Skip 免传运动矢量" 控流、并经 "8抽头高阶滤波" 精雕细琢的立体架构。
它深刻洞察了高分辨率视频中像素位移的统计学规律,通过复杂的时域/空间候选预测建立了一套信息共享网络。正是这套精密复杂的运动补偿矩阵,让 H.265/HEVC 在面对高动态、超高清的现代多媒体场景时,依然能够把网络带宽牢牢压制在极低的红线之内。