5.13 YaRN:如何让大模型"读懂"超长文本?
在处理大语言模型(LLM)时,我们经常遇到一个核心痛点:训练时设定的最大上下文长度(比如 4K)限制了它的发挥。 如果我们在推理时输入 10K 的文本,由于位置编码(Position Embedding)不具备外推性,模型会直接"抓瞎",效果急剧下降。
YaRN (Yet another RoPE extensioN) 正是为了解决这一问题而生的长文本外推技术,它让模型在不重新进行大规模训练的前提下,能够以极高的效率处理超长序列。
1. 为什么位置编码会限制长度?
在 Transformer 中,为了让模型理解句子的顺序,我们需要给每个 Token 加上"位置标签"。RoPE(旋转位置编码)是目前最主流的方案。
但 RoPE 有一个隐藏特性:它是基于"旋转"的。当我们试图用它处理比训练时更长的文本时,它会出现"旋转角过大"的问题,导致模型无法识别这些从未见过的位置信息,从而性能崩溃。
2. 核心思路:从"完全外推"到"高频外推,低频内插"
为了扩展长度,业界尝试了两种方案: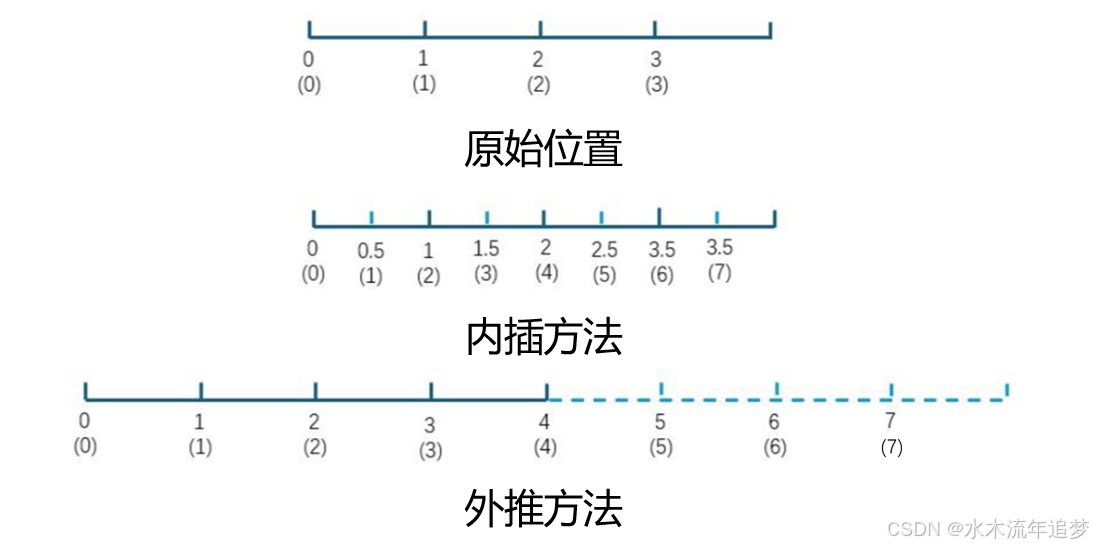
- 外推法(Extrapolation): 强行把原本旋转角度较小的 RoPE 矩阵硬扩充到更大的角度。结果:低频信息丢失,模型把位置 1 和 3 的差异误判为 1 和 2,逻辑错乱。
- 内插法(Interpolation / PI): 把长文本强行缩放到短文本的区间内。结果:高频分量(精细位置差异)被抹平,模型难以区分细微的相对位置关系。
YaRN 的天才解法:结合两者优势!
YaRN 提出了一种"各取所需"的策略:
- 高频分量(对位置敏感)使用外推: 保持精细的位置分辨能力。
- 低频分量(对位置不敏感)使用内插: 将其压缩到训练区间的范围内。
这种方法被称为 NTK-by-parts 插值 ,通过一个调节参数 α\alphaα 来动态平衡。
3. 数学本质:通用的位置编码公式
无论 RoPE 怎么变,本质上都可以被一个统一的公式描述:
fWl(xm,m,θd)=fW(xm,g(m),h(θd))f_{W}^{l}(x_{m},m,\theta_{d})=f_{W}(x_{m},g(m),h(\theta_{d}))fWl(xm,m,θd)=fW(xm,g(m),h(θd))
- xmx_{m}xm: 输入向量。
- mmm: 位置索引。
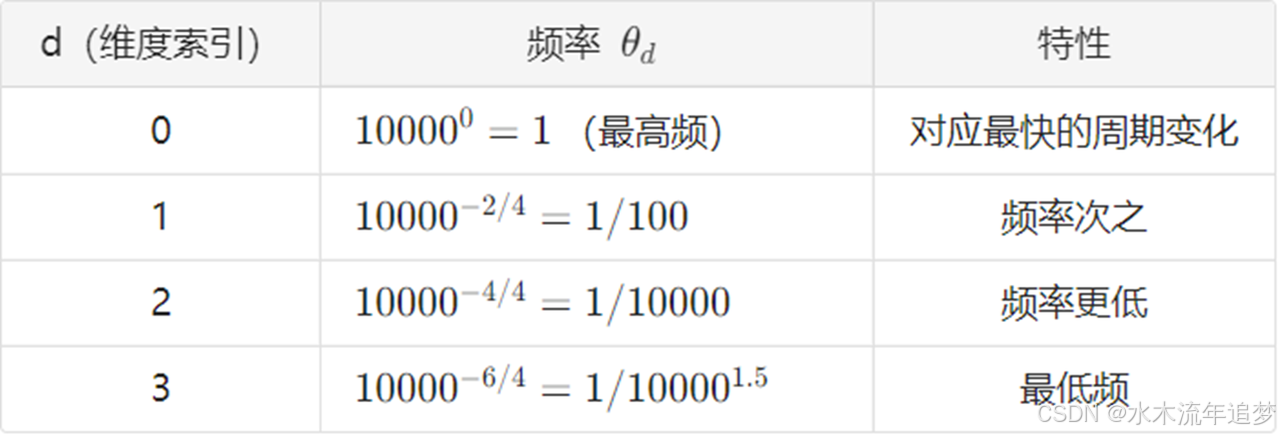
- θd\theta_{d}θd: 频率参数(控制旋转速度)。
- g(m)g(m)g(m) 和 h(θd)h(\theta_{d})h(θd): 可调函数,决定了如何对位置和频率进行变换。
YaRN 的核心就是通过精心设计 h(θd)h(\theta_{d})h(θd),让频率参数随着序列长度的变化而动态调整。
4. 为什么要避开"极低频分量"?
YaRN 论文中有一个非常硬核的发现:在 RoPE 的训练过程中,存在一些极其低频的分量(旋转极慢),它们的波长长到甚至在训练过程中都没有完成一个完整的旋转周期。
对于这些分量,我们根本不应该对它们进行任何形式的外推! 因为外推只会引入训练阶段从未见过的"伪旋转角",反而导致模型效果下降。
因此,YaRN 实现了智能分层管理:
- 正常的低频分量:进行内插。
- 极端低频分量:原样保留,不做任何修改。
- 高频分量:进行外推。
5. 总结与实践建议
YaRN 的强大之处在于它将绝对位置编码的确定性 与相对位置编码的灵活性结合在了一起。
如果你正在进行大模型的长文本适配,建议关注以下几点:
- 无需大规模重新训练: 相比于重新从头训练模型,YaRN 只需要在少量长文本数据上进行微调(Fine-tuning),即可实现数倍的长度扩展。
- 频率分配是关键: 对不同维度的频率分量采用不同的插值策略是提升效果的核心。
- 保持高频信息: 在任何位置编码扩展中,保护高频分量的信息不被损失,是维持模型推理精度的前提。
通过这种"高频外推 + 低频内插"的组合拳,YaRN 成功解决了大模型长文本处理中的"位置漂移"问题,是目前工业界处理超长文本上下文最稳妥、高效的方案之一。
bash
print('hello')