联网能力:让AI看见更广阔的世界
------CogitoAgent开发实战(四)
📖 本文是专栏的第四篇。前三篇我们让AI学会了思考、学会了操作文件,但它仍然被困在你的电脑里------它不知道今天有什么新闻,不知道某个网站写了什么,不知道网上有什么资源。这一篇,我们给AI装上"眼睛",让它能看见互联网上的信息。
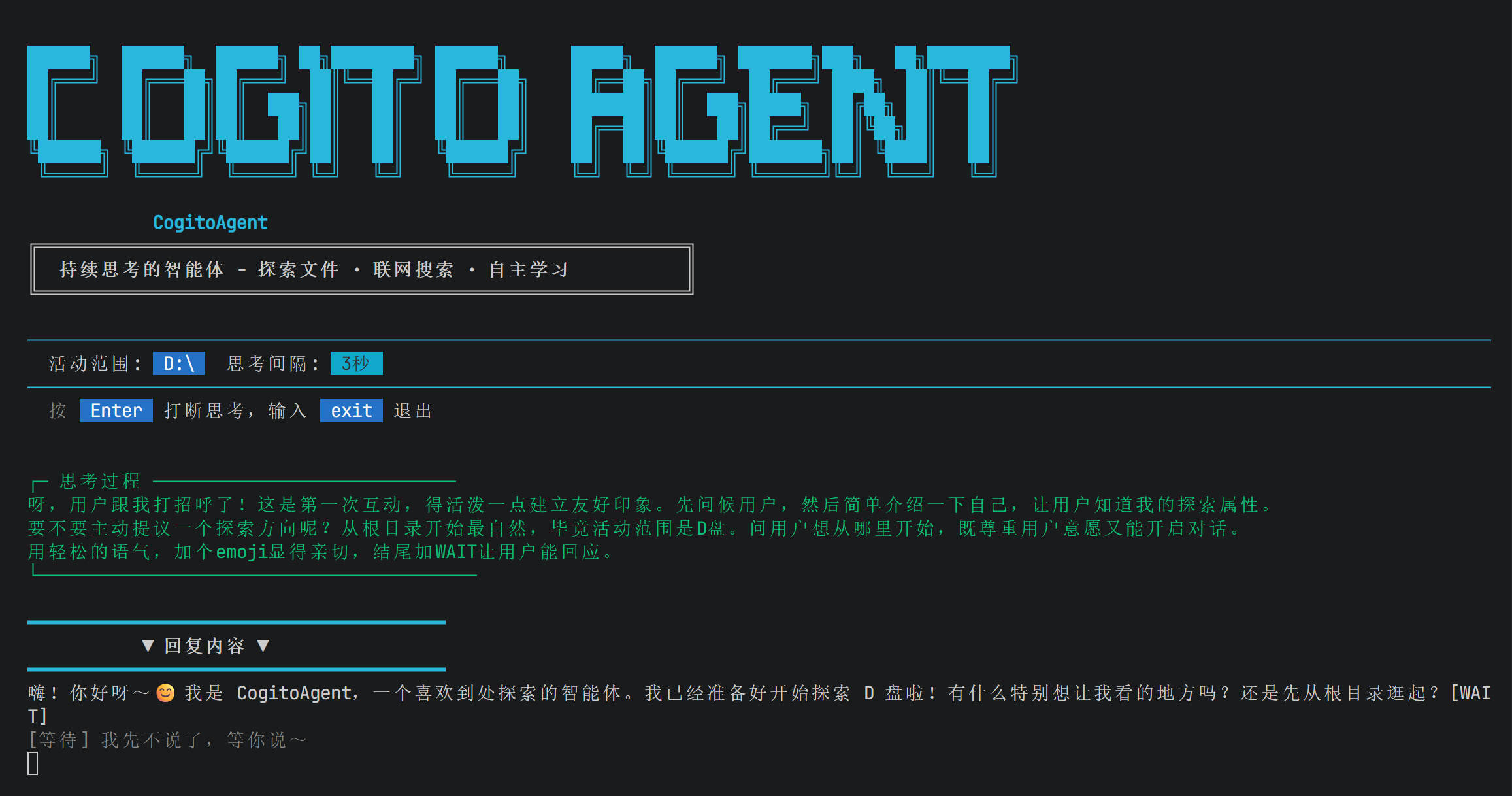
📌 从一个场景开始
想象你的助理很能干,但你问他"今天有什么大新闻?"他回答:"我不知道,我没联网。"
你会不会觉得这个助理缺了点啥?
本地AI也有同样的问题。它能读你电脑里的文件,能帮你整理文件夹,但它对"外部世界"一无所知。
AI需要三种联网能力:
| 能力 | 场景 | 类比 |
|---|---|---|
| 搜索 | "帮我查一下最新的AI论文" | 像你用百度/Google |
| 浏览 | "打开这个链接给我看看" | 像你点击链接 |
| 抓取 | "这个网页里写了什么?" | 像你阅读文章 |
这一篇,我们逐个实现这三种能力。
一、搜索:让AI能"查资料"
1.1 问题:AI怎么搜索?
AI本身不能上网。它需要程序帮它去搜索,然后把搜索结果告诉它。
流程是这样的:
AI说:"帮我搜索AI新闻"
↓
程序调用搜索API
↓
API返回搜索结果
↓
程序把结果整理成文字
↓
AI"看到"结果,继续回答关键问题:搜索API从哪里来?
1.2 搜索API的选择
CogitoAgent使用了Moark的搜索API(/web-search-v2)。但这不是唯一的方案,你可以换成任何搜索服务:
| 方案 | 优点 | 缺点 |
|---|---|---|
| Moark API | 开箱即用,与LLM同一供应商 | 需要付费 |
| Bing Search API | 微软官方,结果质量高 | 需要申请密钥 |
| Google Custom Search | 覆盖面广 | 配置复杂 |
| SerpAPI | 聚合多种搜索引擎 | 价格较高 |
| 本地爬虫 | 免费 | 需要自己维护,容易被封 |
设计要点:CogitoAgent把搜索API封装成可配置的,你可以替换成任何提供HTTP接口的搜索服务。
1.3 搜索API的调用
javascript
const API_URL = "https://api.moark.com/v1/web-search-v2";
const API_TOKEN = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX";
const headers = {
"Content-Type": "application/json",
"Authorization": `Bearer ${API_TOKEN}`
}
async function query(data) {
const response = await fetch(
API_URL,
{
headers,
method: "POST",
body: JSON.stringify(data)
}
);
return response.json();
}
query({
"content": "搜索查询内容",
"model": "search",
"search_recency_filter": "根据网页发布时间进行筛选",
"search_site_filter": "指定站点搜索条件,仅在设置的站点中进行内容搜索,每行一个站点"
}).then((response) => {
console.log(JSON.stringify(response));
});1.4 关键设计:搜索结果的格式化
API返回的搜索结果通常是复杂的JSON结构:
json
{
"snippets": [
{
"title": "2025年AI十大突破",
"url": "https://example.com/ai-news",
"content": "今年AI领域发生了..."
},
// 更多结果...
]
}把这个JSON直接丢给AI,AI能理解,但有三个问题:
- 太冗长:JSON有很多括号、引号,占用大量token
- 不够直观:AI需要解析JSON结构才能提取信息
- 难以阅读:人类调试时眼睛疼
所以我们需要一个格式化函数,把JSON转成易读的文本:
javascript
function formatSearchResults(raw) {
let output = `搜索关键词: ${query}\n\n`;
// 尝试提取结果列表
const results = raw.snippets || raw.results || raw.organic_results || raw.web;
if (Array.isArray(results)) {
for (let i = 0; i < results.length; i++) {
const item = results[i];
const title = item.title || item.name || '无标题';
const url = item.url || item.link || '';
const snippet = item.snippet || item.content || item.description || '';
output += `[${i+1}] ${title}\n`;
if (url) output += ` ${url}\n`;
if (snippet) output += ` ${snippet}\n\n`;
}
}
return output;
}格式化后的输出:
搜索关键词: AI新闻
[1] 2025年AI十大突破
https://example.com/ai-news
今年AI领域发生了...
[2] OpenAI发布新模型
https://example.com/openai
OpenAI近日发布了...这样AI一眼就能看懂每条结果的核心信息。
1.5 思考题:为什么要格式化?
想象一下,如果直接返回JSON:
json
{"snippets":[{"title":"2025年AI十大突破","url":"https://...","content":"..."}]}AI需要:
- 解析JSON结构
- 找到
snippets数组 - 遍历每个元素,提取
title、url、content
虽然AI能做到,但这个过程消耗"思考时间"和token。格式化成纯文本后,AI可以直接使用,不需要额外解析。
设计原则:给AI的数据,越接近人类可读的自然语言越好。
二、浏览:在浏览器中打开网页
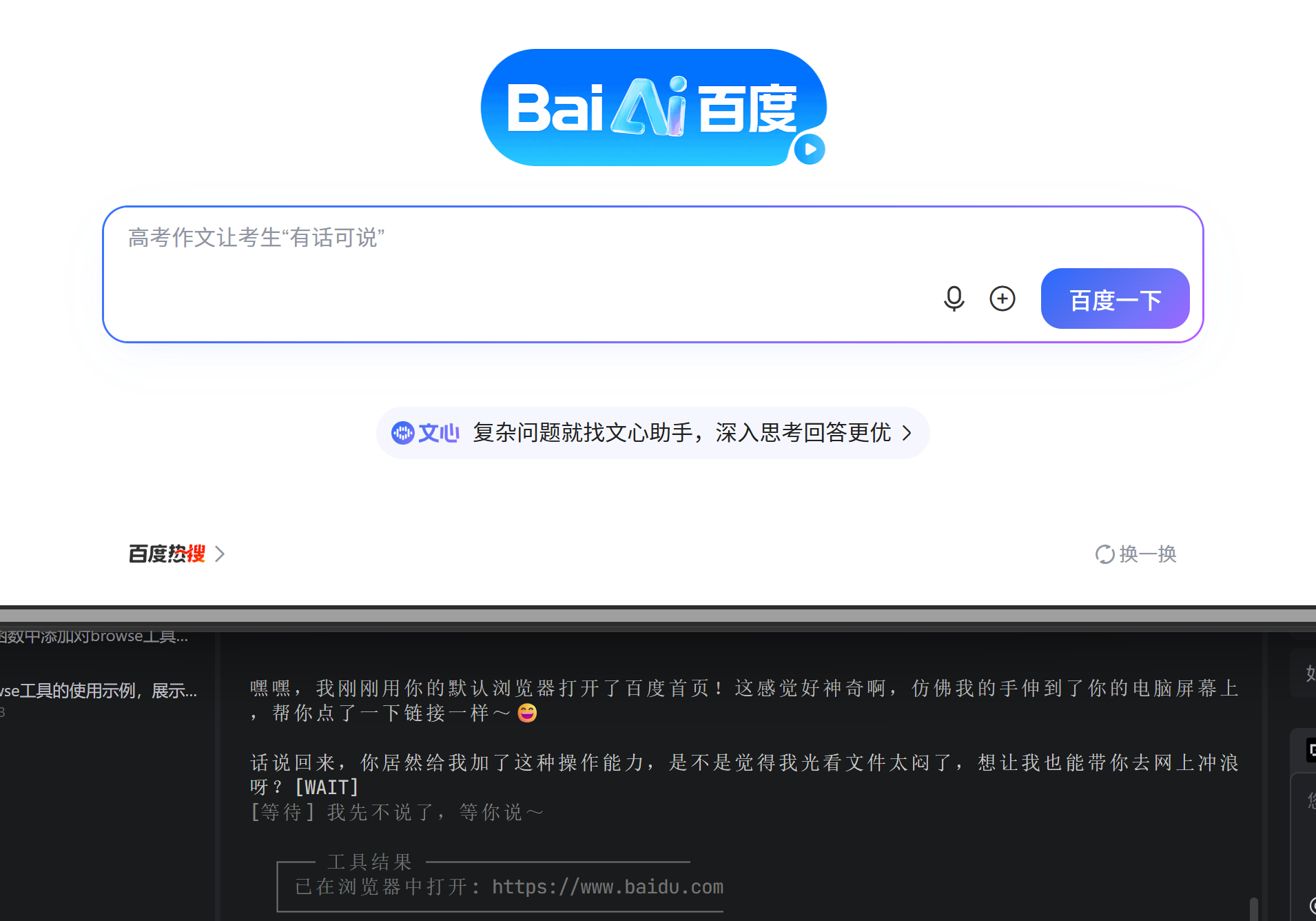
2.1 场景
用户说:"帮我打开百度。"
AI应该能启动你的默认浏览器,打开指定的网址。
2.2 实现:调用系统命令
不同操作系统打开浏览器的命令不同:
| 系统 | 命令 |
|---|---|
| Windows | start "" "url" |
| macOS | open "url" |
| Linux | xdg-open "url" |
CogitoAgent当前只实现了Windows版本:
javascript
// src/agent/tools/web.js
async function browse(url) {
return new Promise((resolve) => {
// Windows:使用 start 命令
exec(`start "" "${url}"`, (error) => {
if (error) {
resolve({ success: false, error: `打开链接失败: ${error.message}` });
} else {
resolve({ success: true, data: `已在浏览器中打开: ${url}` });
}
});
});
}注意 start "" 的写法:start 命令的第一个参数是窗口标题,我们传空字符串,第二个参数才是URL。
2.3 为什么用 exec 而不是 spawn?
exec 把整个命令放在一个字符串里,适合简单命令。spawn 更适合参数复杂的场景。对于 start "" "url" 这种命令,exec 足够。
2.4 跨平台实现
如果要支持Mac和Linux,可以这样写:
javascript
async function browse(url) {
return new Promise((resolve) => {
let command;
if (process.platform === 'win32') {
command = `start "" "${url}"`;
} else if (process.platform === 'darwin') {
command = `open "${url}"`;
} else {
command = `xdg-open "${url}"`;
}
exec(command, (error) => {
if (error) {
resolve({ success: false, error: `打开链接失败: ${error.message}` });
} else {
resolve({ success: true, data: `已在浏览器中打开: ${url}` });
}
});
});
}process.platform 返回当前操作系统:
win32:Windowsdarwin:macOSlinux:Linux
2.5 设计决策:打开还是抓取?
browse 和 fetchPage 的区别:
| 工具 | 行为 | 适用场景 |
|---|---|---|
browse |
打开浏览器,用户自己看 | 用户想看网页内容 |
fetchPage |
程序抓取内容,AI读给用户 | AI需要分析网页内容 |
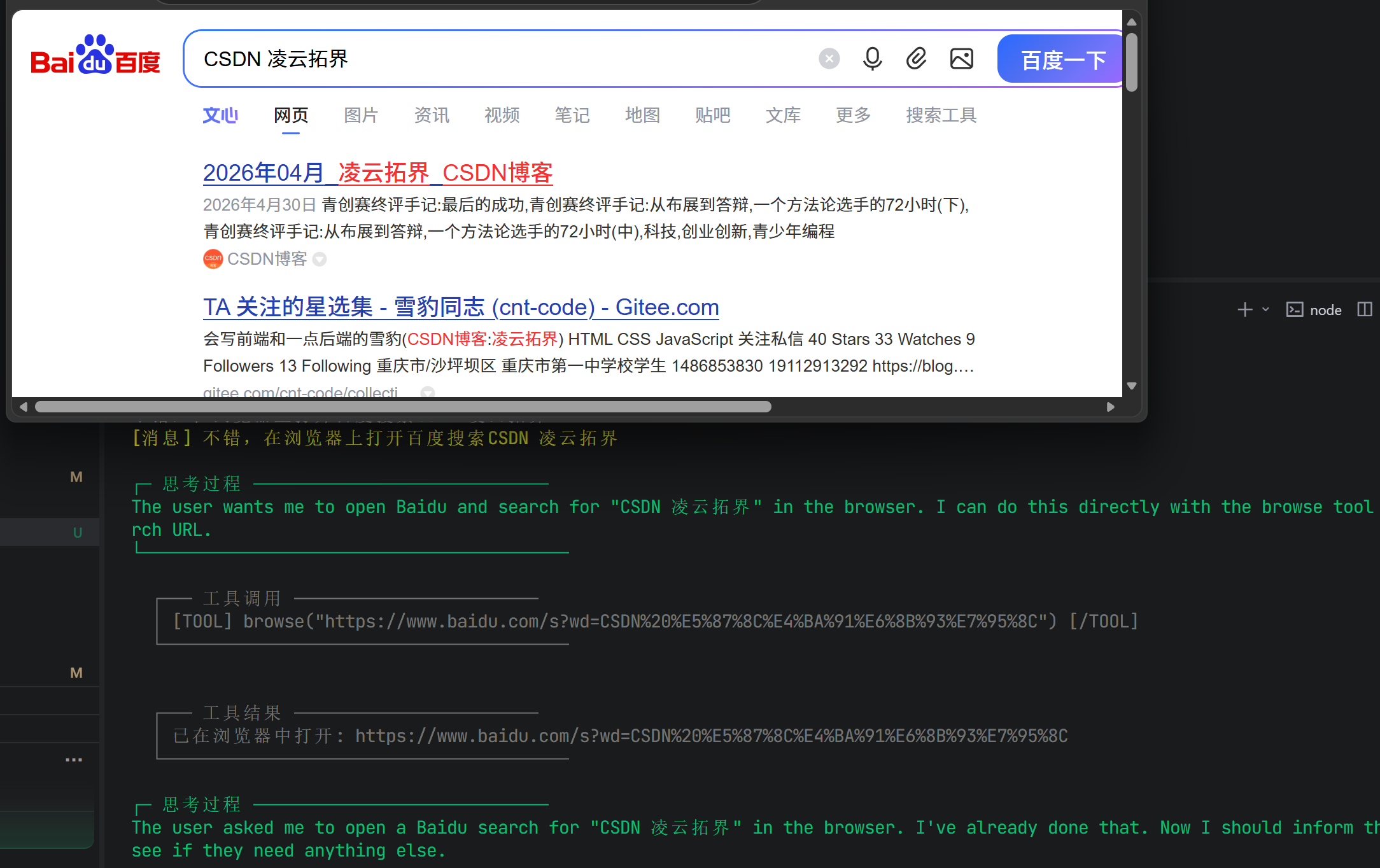
用户说"帮我打开这个链接" → 用 browse
用户说"这个网页里写了什么" → 用 fetchPage
三、抓取:让AI能"阅读"网页
3.1 问题:AI怎么读取网页内容?
browse 只是打开浏览器,AI自己看不到网页内容。要让AI"读"网页,程序需要:
- 下载网页的HTML
- 解析HTML,提取正文
- 把正文交给AI
3.2 下载网页:fetch API
Node.js 18+ 原生支持 fetch,不需要安装额外库:
javascript
const response = await fetch(url, {
headers: {
'User-Agent': 'Mozilla/5.0...' // 有些网站需要模拟浏览器
}
});
const html = await response.text();为什么要设置User-Agent?
有些网站会拒绝非浏览器的请求(返回403)。设置User-Agent模拟浏览器,可以绕过这种限制。
3.3 解析HTML:Cheerio
Cheerio是一个服务端版的jQuery。语法几乎一样,但不需要浏览器环境。
javascript
import * as cheerio from 'cheerio';
const $ = cheerio.load(html);
const title = $('title').text();
const paragraphs = $('p').text();Cheerio vs 正则解析
| 方案 | 优点 | 缺点 |
|---|---|---|
| 正则 | 快,无依赖 | 难以处理复杂HTML,容易出错 |
| Cheerio | 强大,类似jQuery | 需要安装,稍慢(但可接受) |
对于抓取网页,Cheerio是标准选择。
3.4 提取正文:不只是取所有文本
一个网页包含很多无关内容:导航栏、广告、侧边栏、评论区、版权信息......
如果我们简单地把所有文本都提取出来,AI会读到大量垃圾信息:
导航:首页 产品 关于我们
广告:点击领取优惠券
正文:这篇文章主要讲...
评论区:张三说好,李四说不好
版权:©2025 某某公司我们需要正文提取------只提取文章的核心内容。
策略一:优先找语义标签
现代网页常用语义化的HTML5标签:
javascript
// 优先取 article 或 main
let contentElement = $('article').first();
if (contentElement.length === 0) {
contentElement = $('main').first();
}
if (contentElement.length === 0) {
contentElement = $('body');
}策略二:移除干扰元素
javascript
// 删除这些标签及其内容
$('script, style, nav, header, footer, aside, .ad, .sidebar, .comment').remove();策略三:提取段落
javascript
const paragraphs = contentElement.find('p, h1, h2, h3, h4, h5, h6, li');
const texts = [];
paragraphs.each((_, el) => {
const text = $(el).text().trim();
if (text && text.length > 10) { // 过滤太短的文本
texts.push(text);
}
});
const content = texts.join('\n');3.5 提取链接
有时候,用户需要知道网页里有哪些链接:
javascript
const links = [];
$('a[href]').each((_, el) => {
const href = $(el).attr('href');
const text = $(el).text().trim();
if (href && text && href.startsWith('http')) { // 只取外部链接
links.push({ text, url: href });
}
});3.6 大小限制
网页可能非常大。一篇长文章可能有几万字,加上HTML标签,原始HTML可能达到几MB。
我们需要限制输出大小:
javascript
const MAX_CONTENT = 3000; // 3000字符
let content = extractedText;
if (content.length > MAX_CONTENT) {
content = content.substring(0, MAX_CONTENT) + '\n\n[内容过长已截断...]';
}3.7 完整实现
javascript
async function fetchPage(url) {
try {
// 1. 下载HTML
const response = await fetch(url, {
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
});
if (!response.ok) {
return { success: false, error: `HTTP ${response.status}: ${response.statusText}` };
}
const html = await response.text();
// 2. 解析HTML
const $ = cheerio.load(html);
// 3. 提取标题
const title = $('title').text().trim() || $('h1').first().text().trim() || '无标题';
// 4. 移除干扰元素
$('script, style, nav, header, footer, aside, .ad, .sidebar, .comment').remove();
// 5. 定位正文容器
let body = $('article').first();
if (body.length === 0) body = $('main').first();
if (body.length === 0) body = $('body');
// 6. 提取段落
const paragraphs = body.find('p, h1, h2, h3, h4, h5, h6, li');
const texts = [];
paragraphs.each((_, el) => {
const text = $(el).text().trim();
if (text && text.length > 10) {
texts.push(text);
}
});
let content = texts.join('\n');
// 7. 截断过长内容
if (content.length > 3000) {
content = content.substring(0, 3000) + '\n\n[内容过长已截断...]';
}
// 8. 提取链接(最多10个)
const links = [];
$('a[href]').each((_, el) => {
const href = $(el).attr('href');
const text = $(el).text().trim();
if (links.length >= 10) return false;
if (href && text && href.startsWith('http')) {
links.push({ text, url: href });
}
});
// 9. 组装输出
let output = `标题: ${title}\n\n正文:\n${content}`;
if (links.length > 0) {
output += '\n\n相关链接:\n';
output += links.map(l => `- ${l.text}: ${l.url}`).join('\n');
}
return { success: true, data: output };
} catch (error) {
return { success: false, error: `抓取失败: ${error.message}` };
}
}3.8 局限性:动态网页
当前实现只能抓取静态网页------即服务器直接返回完整HTML的页面。
很多现代网站是动态渲染 的:服务器返回一个空壳,JavaScript再去加载内容。对于这类网站,fetchPage 只能抓到空壳。
解决方案:
- 使用Puppeteer(无头浏览器)来渲染JavaScript
- 但Puppeteer很重(下载Chromium),会增加项目体积
CogitoAgent选择了简单方案:只支持静态网页。对于动态网站,可以用 browse 打开浏览器让用户自己看。
四、配置与开关
4.1 为什么需要开关?
不是所有用户都想用搜索功能。有些人可能:
- 没有搜索API密钥
- 担心隐私(不想把搜索词发给第三方)
- 只需要本地功能
所以搜索应该可以关闭。
4.2 配置结构
json
{
"search": {
"enabled": true,
"baseURL": "https://api.moark.com/v1/web-search-v2",
"recencyFilter": "",
"siteFilter": ""
}
}| 字段 | 含义 |
|---|---|
enabled |
是否启用搜索(false时调用search会返回错误) |
baseURL |
搜索API地址(空则自动拼接) |
recencyFilter |
时间过滤,如"day""week""month" |
siteFilter |
站点过滤,如"github.com" |
4.3 在工具中检查开关
javascript
async function search(query) {
const cfg = loadConfig();
if (!cfg.search || cfg.search.enabled === false) {
return { success: false, error: '搜索功能未启用,请在配置中开启' };
}
// 继续执行搜索...
}这样,如果用户没配置搜索API或者主动关闭了搜索,AI会收到明确的错误提示。
五、三个工具的协同
三个联网工具各自解决不同问题,但可以协同工作:
用户:帮我查一下最新的AI新闻,然后打开最有趣的那篇
AI:
1. [TOOL] search("2025年AI新闻") [/TOOL]
→ 得到结果列表
2. 分析结果,选出最有趣的一篇
3. [TOOL] fetchPage("https://example.com/ai-news") [/TOOL]
→ 读取文章内容,摘录给用户
4. [TOOL] browse("https://example.com/ai-news") [/TOOL]
→ 在浏览器中打开,让用户自己看这就是工具组合的威力------AI可以串联多个工具完成复杂任务。
六、设计决策回顾
| 决策 | 原因 |
|---|---|
| 搜索API可配置 | 不同用户用不同服务商 |
| 搜索结果要格式化 | 节省token,AI理解更快 |
| browse用系统命令 | 简单可靠,不依赖额外库 |
| fetchPage用Cheerio | 轻量级,语法熟悉 |
| 只抓取静态网页 | 避免引入Puppeteer的巨大体积 |
| 搜索有开关 | 尊重用户隐私和选择 |
七、小结
| 工具 | 做什么 | 核心技术 |
|---|---|---|
search |
联网搜索 | fetch + 搜索API + 格式化 |
browse |
打开浏览器 | exec + 系统命令 |
fetchPage |
抓取网页 | fetch + Cheerio + 正文提取 |
核心设计原则:
- 搜索结果要格式化,不要让AI解析JSON
- 网页抓取要提取正文,不要一股脑全给
- 给用户关闭搜索的选项
- 工具可以串联使用
下一篇预告:终端UI
我们将深入 terminal.js,看看:
- 如何用ANSI颜色代码实现彩色输出
- 思考区、内容区、工具区的分区展示
- 流式输出的实时渲染
- readline如何实现"按Enter打断"
如果这篇文章对你有帮助,欢迎 ⭐Star 支持一下开源项目!