机器人运动控制算法全解:采样、优化与学习三大流派深度对比与实战
你有没有好奇过,春晚上整齐划一跳舞的人形机器人、工厂里毫米级精度装配的机械臂、仓库里穿梭自如的AGV小车,它们是怎么精准控制每一个动作的?很多人以为机器人控制算法多如牛毛、复杂到劝退,但其实拨开技术迷雾,机器人任务级上层运动控制算法本质上只有三大流派:采样、优化和学习。

今天我们就用最接地气的类比,结合严谨的数学公式、可运行的核心代码和真实工业案例,把这三大流派讲得明明白白,让你一眼看懂不同机器人背后的控制逻辑。
一、采样算法:快速试错的"野路子"玩家
1.1 核心思想与通俗类比
采样算法的核心逻辑非常朴素:不求最好,但求最快能用。
大白话类比:就像你第一次打篮球投篮,没人教动作也不懂力学,你就站在罚球线用不同力度、不同手腕姿势瞎试,投个几十次总能蒙进一个。下次篮筐升高了10厘米,你也不用学新理论,再重新试几十次就行。
专业解释:采样算法通过在状态空间 中随机或有策略地采样大量候选解,快速筛选出满足约束条件的可行解。它不追求全局最优,只追求在最短时间内找到能完成任务的解。
通俗备注:状态空间就是机器人所有可能的状态组合,比如机械臂6个关节的角度、AGV的位置和朝向,相当于一个巨大的"可能性地图"。采样就是在这个地图上随机扔飞镖,扎到能用的位置就停下。
1.2 数学原理:RRT快速探索随机树
RRT(快速探索随机树)是采样算法中最经典的代表,被广泛应用于机器人路径规划和抓取姿态生成。它通过不断扩展一棵"搜索树"来探索整个状态空间,直到树的节点到达目标区域。
xnew=xnearest+ϵ⋅xrand−xnearest∥xrand−xnearest∥x_{new} = x_{nearest} + \epsilon \cdot \frac{x_{rand} - x_{nearest}}{\|x_{rand} - x_{nearest}\|}xnew=xnearest+ϵ⋅∥xrand−xnearest∥xrand−xnearest
其中:
- xnewx_{new}xnew:新生成的树节点(机器人的一个候选状态)
- xnearestx_{nearest}xnearest:当前搜索树中离随机采样点最近的节点
- xrandx_{rand}xrand:在状态空间中随机采样得到的点
- ϵ\epsilonϵ:步长参数,控制每次树扩展的距离
- ∥xrand−xnearest∥\|x_{rand} - x_{nearest}\|∥xrand−xnearest∥:两个点之间的欧氏距离(直线距离)
公式解释:每次在整个状态空间随机选一个点xrandx_{rand}xrand,找到树上离它最近的节点xnearestx_{nearest}xnearest,然后从xnearestx_{nearest}xnearest朝着xrandx_{rand}xrand的方向走一小步ϵ\epsilonϵ,得到新节点xnewx_{new}xnew并加入树中。重复这个过程,直到树延伸到目标点附近。
1.3 核心代码:二维RRT路径规划实现
python
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
class RRTPlanner:
def __init__(self, start, goal, obstacles, map_size, step=0.5, max_iter=1000):
"""
初始化RRT路径规划器
参数:
start: 起点坐标 [x, y]
goal: 终点坐标 [x, y]
obstacles: 障碍物列表,每个元素为 [x, y, 半径]
map_size: 地图尺寸 [宽度, 高度]
step: 每次扩展的步长
max_iter: 最大迭代次数
"""
self.start = np.array(start)
self.goal = np.array(goal)
self.obstacles = obstacles
self.map_w, self.map_h = map_size
self.step = step
self.max_iter = max_iter
# 初始化搜索树:存储节点坐标和父节点索引
self.nodes = [self.start]
self.parents = [-1]
def is_collision(self, point):
"""检查点是否与障碍物碰撞"""
for (ox, oy, r) in self.obstacles:
if np.linalg.norm(point - np.array([ox, oy])) <= r:
return True
return False
def get_random_point(self):
"""在地图范围内随机采样一个点"""
x = np.random.uniform(0, self.map_w)
y = np.random.uniform(0, self.map_h)
return np.array([x, y])
def get_nearest_index(self, point):
"""找到离随机点最近的树节点索引"""
distances = [np.linalg.norm(node - point) for node in self.nodes]
return np.argmin(distances)
def extend(self, from_node, to_point):
"""从from_node向to_point方向扩展一步"""
direction = to_point - from_node
direction = direction / np.linalg.norm(direction) # 单位化方向向量
return from_node + self.step * direction
def plan(self):
"""执行路径规划,返回找到的路径(None表示未找到)"""
for _ in range(self.max_iter):
# 1. 随机采样一个点
rand_point = self.get_random_point()
# 2. 找到树上最近的节点
nearest_idx = self.get_nearest_index(rand_point)
nearest_node = self.nodes[nearest_idx]
# 3. 扩展一步得到新节点
new_node = self.extend(nearest_node, rand_point)
# 4. 碰撞检测,碰撞则跳过本次迭代
if self.is_collision(new_node):
continue
# 5. 将新节点加入搜索树
self.nodes.append(new_node)
self.parents.append(nearest_idx)
# 6. 检查是否到达目标区域
if np.linalg.norm(new_node - self.goal) <= self.step:
# 回溯生成路径
path = [self.goal]
current_idx = len(self.nodes) - 1
while current_idx != -1:
path.append(self.nodes[current_idx])
current_idx = self.parents[current_idx]
path.reverse()
return np.array(path)
# 迭代结束未找到路径
return None
# 测试代码
if __name__ == "__main__":
# 起点、终点
start_pos = [0, 0]
goal_pos = [10, 10]
# 障碍物:三个圆形障碍
obstacle_list = [[3, 3, 1], [5, 7, 1.5], [8, 4, 1]]
# 创建规划器并规划路径
rrt = RRTPlanner(start_pos, goal_pos, obstacle_list, map_size=[10, 10])
planned_path = rrt.plan()
# 绘制结果
plt.figure(figsize=(8, 8))
# 绘制障碍物
for (ox, oy, r) in obstacle_list:
circle = plt.Circle((ox, oy), r, color='red', alpha=0.5, label='障碍物')
plt.gca().add_patch(circle)
# 绘制搜索树
for i in range(1, len(rrt.nodes)):
plt.plot([rrt.nodes[i][0], rrt.nodes[rrt.parents[i]][0]],
[rrt.nodes[i][1], rrt.nodes[rrt.parents[i]][1]], 'k-', linewidth=0.5)
# 绘制路径
if planned_path is not None:
plt.plot(planned_path[:, 0], planned_path[:, 1], 'blue', linewidth=2, label='规划路径')
# 绘制起点和终点
plt.plot(start_pos[0], start_pos[1], 'go', markersize=10, label='起点')
plt.plot(goal_pos[0], goal_pos[1], 'ro', markersize=10, label='终点')
plt.xlim(0, 10)
plt.ylim(0, 10)
plt.xlabel('X坐标 (m)')
plt.ylabel('Y坐标 (m)')
plt.title('RRT算法路径规划结果')
plt.legend()
plt.grid(True)
plt.show()1.4 算法可视化与结果分析
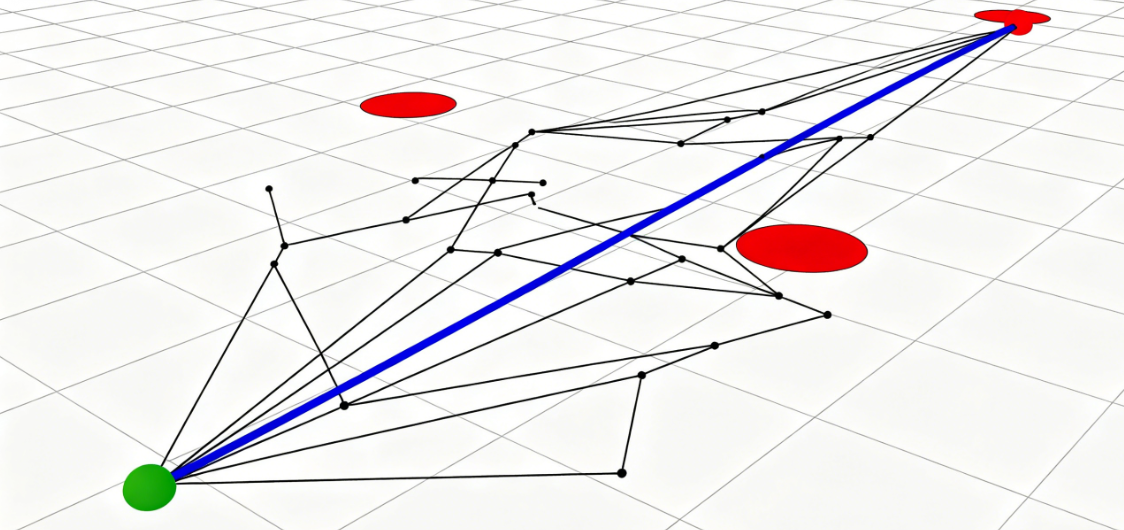
RRT算法路径搜索过程示意图
图片分析:图中黑色细线是RRT算法随机扩展生成的搜索树,蓝色粗线是最终找到的可行路径。可以看到:
- RRT通过随机采样快速探索整个空间,即使有障碍物也能快速找到绕开的路径
- 生成的路径是可行的,但不是最短路径,而且每次运行结果都不一样
- 算法在障碍物稀疏的区域扩展很快,在障碍物密集的区域需要更多迭代
1.5 优缺点与典型应用
✅ 优点 :算法简单易实现,计算量小,对环境变化适应性强,不需要精确的环境模型
❌ 缺点:解不是全局最优,路径可能曲折;重复性差;在极端复杂环境中可能找不到解
真实案例:
- 亚马逊Kiva仓库AGV:使用RRT*(RRT的优化版)进行路径规划,能快速避开其他AGV和货架
- 火星探测器毅力号:在未知地形中使用采样算法生成安全行驶路径,避免陷入陨石坑
二、优化算法:科班出身的"教练指导"派
2.1 核心思想与通俗类比
优化算法的核心逻辑是:基于精确模型,一步步迭代出最优解。
大白话类比:就像你请了一个NBA级别的篮球教练教你投篮。教练会先给你建立完整的投篮力学模型(出手角度、力度、手腕动作的最优组合),然后在你训练时不断纠正你的动作,让你的投篮越来越准。如果篮筐变高了,教练会根据力学公式直接调整你的出手角度,不需要你重新试错。
专业解释:优化算法首先建立机器人和环境的精确数学模型,然后将控制问题转化为一个带约束的优化问题,通过求解这个优化问题得到最优的控制输入序列。
通俗备注:数学模型就像是教练脑子里的"投篮公式",知道用多大的力、什么角度投出去球会飞到哪里。优化问题就是在"不能犯规、不能受伤"的约束下,找到让球最精准入网的动作组合。
2.2 数学原理:MPC模型预测控制
MPC(模型预测控制)是优化算法中应用最广泛的代表,被大量用于工业机器人、自动驾驶和四足机器人控制。它采用"滚动优化"的策略,在每个控制周期都重新预测未来一段时间的系统状态并求解优化问题。
minu0,u1,...,uN−1∑k=0N−1∥xk−xref,k∥Q2+∑k=0N−2∥uk∥R2\min_{u_0, u_1, ..., u_{N-1}} \sum_{k=0}^{N-1} \|x_k - x_{ref,k}\|Q^2 + \sum{k=0}^{N-2} \|u_k\|_R^2u0,u1,...,uN−1mink=0∑N−1∥xk−xref,k∥Q2+k=0∑N−2∥uk∥R2
s.t.xk+1=f(xk,uk)\text{s.t.} \quad x_{k+1} = f(x_k, u_k)s.t.xk+1=f(xk,uk)
umin≤uk≤umax\quad \quad u_{min} \leq u_k \leq u_{max}umin≤uk≤umax
xmin≤xk≤xmax\quad \quad x_{min} \leq x_k \leq x_{max}xmin≤xk≤xmax
其中:
- NNN:预测时域长度,即预测未来多少步的系统状态
- xkx_kxk:第kkk步的系统状态(如机器人的位置、速度、加速度)
- xref,kx_{ref,k}xref,k:第kkk步的参考状态(我们希望机器人到达的状态)
- uku_kuk:第kkk步的控制输入(如电机转速、油门开度、关节力矩)
- QQQ:状态误差权重矩阵,值越大表示越看重状态跟踪精度
- RRR:控制输入权重矩阵,值越大表示越希望控制量平滑、节能
- f(xk,uk)f(x_k, u_k)f(xk,uk):系统状态转移方程,即我们建立的数学模型
- umin,umaxu_{min}, u_{max}umin,umax:控制输入的物理约束(如电机最大转速)
- xmin,xmaxx_{min}, x_{max}xmin,xmax:系统状态的安全约束(如机器人不能超出工作空间)
公式解释:目标函数由两部分组成,第一部分是未来N步内状态与参考轨迹的误差平方和(希望越小越好),第二部分是控制输入的平方和(希望越小越好,避免剧烈动作)。约束条件保证了所有控制量和状态都在物理安全范围内。
2.3 核心代码:一阶系统MPC控制器实现
python
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
class MPCController:
def __init__(self, A, B, Q, R, horizon):
"""
初始化MPC控制器
参数:
A: 状态转移矩阵
B: 控制输入矩阵
Q: 状态误差权重矩阵
R: 控制输入权重矩阵
horizon: 预测时域长度N
"""
self.A = A
self.B = B
self.Q = Q
self.R = R
self.N = horizon
self.nx = A.shape[0] # 状态维度
self.nu = B.shape[1] # 控制输入维度
def cost(self, u_seq, x0, x_ref):
"""计算MPC目标函数值"""
u_seq = u_seq.reshape(self.N, self.nu)
x = x0.copy()
total_cost = 0.0
for k in range(self.N):
# 状态误差项
total_cost += np.dot((x - x_ref).T, np.dot(self.Q, (x - x_ref)))
# 控制输入项
total_cost += np.dot(u_seq[k].T, np.dot(self.R, u_seq[k]))
# 状态转移
x = np.dot(self.A, x) + np.dot(self.B, u_seq[k])
return total_cost
def compute(self, x_current, x_reference):
"""计算当前时刻的最优控制输入"""
# 初始化控制序列为0
u_init = np.zeros(self.N * self.nu)
# 求解约束优化问题
result = minimize(self.cost, u_init, args=(x_current, x_reference), method='SLSQP')
# 只执行控制序列的第一个元素
return result.x.reshape(self.N, self.nu)[0]
# 测试:控制一个一阶系统 x(k+1) = 0.9*x(k) + 0.1*u(k)
if __name__ == "__main__":
# 系统模型
A = np.array([[0.9]])
B = np.array([[0.1]])
# 权重矩阵:Q大表示看重跟踪精度,R小表示允许较大控制量
Q = np.array([[10.0]])
R = np.array([[0.1]])
# 预测时域:预测未来10步
horizon = 10
# 创建MPC控制器
mpc = MPCController(A, B, Q, R, horizon)
# 模拟控制过程
x = np.array([0.0]) # 初始状态
x_ref = np.array([10.0]) # 目标状态
dt = 0.1
time_steps = np.arange(0, 5, dt)
x_history = []
u_history = []
for t in time_steps:
u = mpc.compute(x, x_ref)
x_history.append(x[0])
u_history.append(u[0])
# 更新系统状态
x = np.dot(self.A, x) + np.dot(self.B, u)
# 绘制结果
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(time_steps, x_history, 'b-', linewidth=2, label='系统状态')
plt.plot(time_steps, [x_ref[0]]*len(time_steps), 'r--', linewidth=2, label='目标状态')
plt.xlabel('时间 (s)')
plt.ylabel('状态值')
plt.title('MPC状态跟踪效果')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(time_steps, u_history, 'g-', linewidth=2, label='控制输入')
plt.xlabel('时间 (s)')
plt.ylabel('控制量')
plt.title('MPC控制输入变化')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()2.4 算法可视化与结果分析
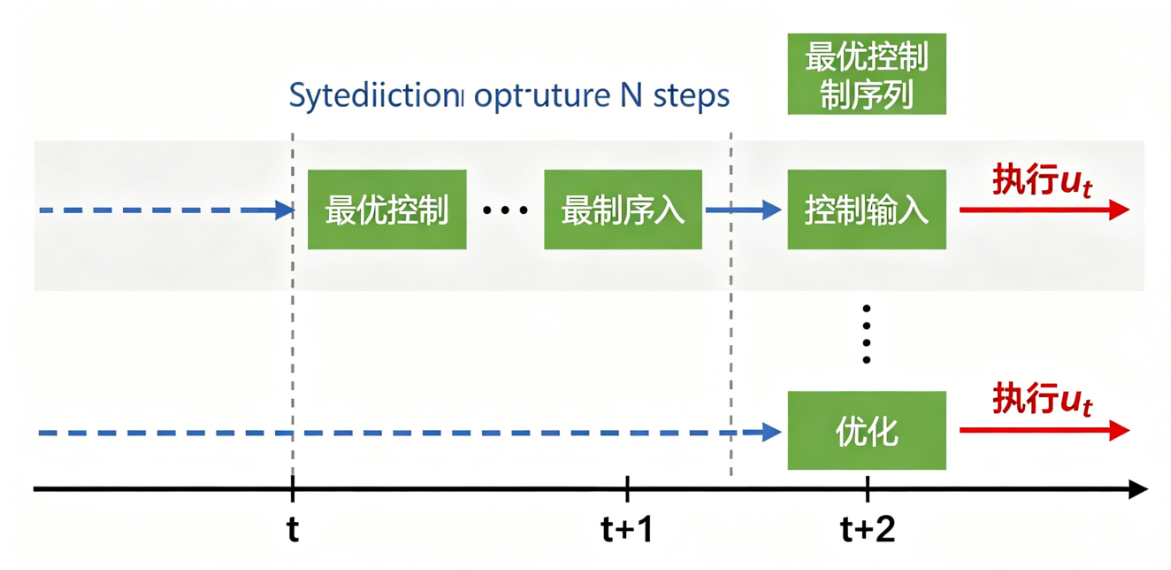
MPC模型预测控制滚动优化原理图
图片分析:图中展示了MPC的核心"滚动优化"机制:
- 在时刻t,MPC预测未来N步的系统状态(蓝色虚线)
- 求解优化问题得到未来N步的最优控制序列(绿色方块)
- 只执行第一个控制输入utu_tut,然后到时刻t+1
- 根据新的系统状态,重复步骤1-3
这种机制让MPC能够很好地处理模型误差和突发干扰,同时始终保证控制量在安全约束内。
2.5 优缺点与典型应用
✅ 优点 :控制精度高,轨迹平滑,能显式处理各种物理约束,解是全局最优的
❌ 缺点:极度依赖精确的数学模型,模型不准会导致控制效果急剧下降;计算量大,需要高性能处理器
真实案例:
- 特斯拉Autopilot:使用MPC算法进行轨迹跟踪和车辆控制,优化出最安全、最舒适的行驶轨迹
- 库卡工业机器人:采用全身控制(WBC)优化算法,实现毫米级的焊接和装配精度
- 波士顿动力Spot机器人:通过优化算法实时调整每条腿的落地位置和力度,保持在复杂地形上的平衡
三、学习算法:台下十年功的"天才选手"
3.1 核心思想与通俗类比
学习算法的核心逻辑是:提前在仿真中练会所有情况,部署时直接输出最优动作。
大白话类比:就像你有一个超级大脑,在上篮球场之前,已经在脑子里模拟了1000万次不同位置、不同风向、不同篮筐高度的投篮情况,总结出了一套万能的"投篮反应公式"。上场之后,不管遇到什么情况,你都不需要试错,也不需要教练指导,看到篮筐的瞬间就能自动做出最优的投篮动作。
专业解释:学习算法将控制问题转化为一个数据驱动的学习问题。通过在仿真环境中进行海量的试错训练,让机器人从数据中学习到一个从状态到动作的映射(即策略)。训练完成后,机器人可以直接将学到的策略应用到真实环境中,不需要在线求解复杂的优化问题。
通俗备注:仿真环境就是机器人的"训练馆",1000万次的模拟训练就是"台下十年功"。学到的策略就像是机器人的"肌肉记忆",遇到相似的情况就能条件反射般做出正确反应。
3.2 数学原理:强化学习马尔可夫决策过程
强化学习是学习算法中最成功的代表,被广泛应用于人形机器人和四足机器人的运动控制。它将控制问题建模为一个马尔可夫决策过程(MDP),通过最大化长期回报来学习最优策略。
Gt=∑k=0∞γkRt+k+1G_t = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1}Gt=k=0∑∞γkRt+k+1
π∗(a∣s)=argmaxπEGt∣st=s,π\pi^*(a|s) = \arg\max_{\pi} \mathbb{E}G_t \| s_t = s, \\piπ∗(a∣s)=argπmaxEGt∣st=s,π
其中:
- GtG_tGt:时刻ttt的长期回报,即未来所有时刻获得回报的加权和
- γ\gammaγ:折扣因子,取值在0到1之间,越远的回报权重越小
- Rt+k+1R_{t+k+1}Rt+k+1:时刻t+k+1t+k+1t+k+1获得的即时回报(如机器人到达目标获得正回报,摔倒获得负回报)
- π(a∣s)\pi(a|s)π(a∣s):策略函数,表示在状态sss下采取动作aaa的概率
- π∗\pi^*π∗:最优策略,即能最大化长期回报的策略
- E⋅\mathbb{E}\\cdotE⋅:期望运算符,表示对所有可能的未来轨迹取平均
公式解释:第一个公式定义了我们的目标------最大化长期回报。第二个公式定义了最优策略,就是找到一个策略,使得机器人在任何状态下按照这个策略行动,都能获得最大的长期回报。
3.3 核心代码:Q-learning网格世界寻路实现
python
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
class QLearningAgent:
def __init__(self, n_states, n_actions, lr=0.1, gamma=0.9, epsilon=0.1):
"""
初始化Q-learning智能体
参数:
n_states: 状态总数
n_actions: 动作总数
lr: 学习率
gamma: 折扣因子γ
epsilon: 探索率,用于ε-贪婪策略
"""
self.n_states = n_states
self.n_actions = n_actions
self.lr = lr
self.gamma = gamma
self.epsilon = epsilon
# 初始化Q表:存储每个状态-动作对的价值
self.Q = np.zeros((n_states, n_actions))
def choose_action(self, state):
"""根据ε-贪婪策略选择动作"""
if np.random.uniform(0, 1) < self.epsilon:
# 探索:随机选择动作,尝试新的可能性
return np.random.choice(self.n_actions)
else:
# 利用:选择当前Q值最大的动作,利用已有经验
return np.argmax(self.Q[state, :])
def update(self, state, action, reward, next_state, done):
"""更新Q表"""
# 计算目标Q值
if done:
target = reward
else:
target = reward + self.gamma * np.max(self.Q[next_state, :])
# 时序差分更新
self.Q[state, action] += self.lr * (target - self.Q[state, action])
# 4x4网格世界环境:起点(0,0),终点(3,3),陷阱(1,1)和(2,2)
class GridWorldEnv:
def __init__(self):
self.size = 4
self.start = (0, 0)
self.goal = (3, 3)
self.traps = [(1, 1), (2, 2)]
self.state = self.start
def reset(self):
"""重置环境到起点"""
self.state = self.start
return self._state_to_idx(self.state)
def step(self, action):
"""执行动作,返回(下一个状态, 回报, 是否结束)"""
x, y = self.state
# 动作定义:0=上,1=下,2=左,3=右
if action == 0:
x = max(0, x - 1)
elif action == 1:
x = min(self.size - 1, x + 1)
elif action == 2:
y = max(0, y - 1)
elif action == 3:
y = min(self.size - 1, y + 1)
self.state = (x, y)
# 计算回报
if self.state == self.goal:
reward = 100 # 到达终点获得大的正回报
done = True
elif self.state in self.traps:
reward = -100 # 掉入陷阱获得大的负回报
done = True
else:
reward = -1 # 每走一步获得小的负回报,鼓励走最短路径
done = False
return self._state_to_idx(self.state), reward, done
def _state_to_idx(self, state):
"""将坐标(x,y)转换为状态索引"""
return state[0] * self.size + state[1]
# 训练Q-learning智能体
if __name__ == "__main__":
env = GridWorldEnv()
agent = QLearningAgent(n_states=16, n_actions=4)
n_episodes = 1000 # 训练回合数
reward_history = []
for episode in range(n_episodes):
state = env.reset()
total_reward = 0
done = False
while not done:
action = agent.choose_action(state)
next_state, reward, done = env.step(action)
agent.update(state, action, reward, next_state, done)
state = next_state
total_reward += reward
reward_history.append(total_reward)
# 每100回合打印一次平均回报
if (episode + 1) % 100 == 0:
avg_reward = np.mean(reward_history[-100:])
print(f"回合 {episode+1:4d} | 平均回报: {avg_reward:6.2f}")
# 绘制训练曲线
plt.figure(figsize=(10, 5))
plt.plot(reward_history, alpha=0.3, label='每回合回报')
plt.plot(np.convolve(reward_history, np.ones(50)/50, mode='valid'),
'r-', linewidth=2, label='50回合滑动平均')
plt.xlabel('训练回合')
plt.ylabel('总回报')
plt.title('Q-learning训练过程')
plt.legend()
plt.grid(True)
plt.show()
# 打印训练完成的Q表
print("\n训练完成的Q表:")
print(agent.Q.round(2))3.4 算法可视化与结果分析
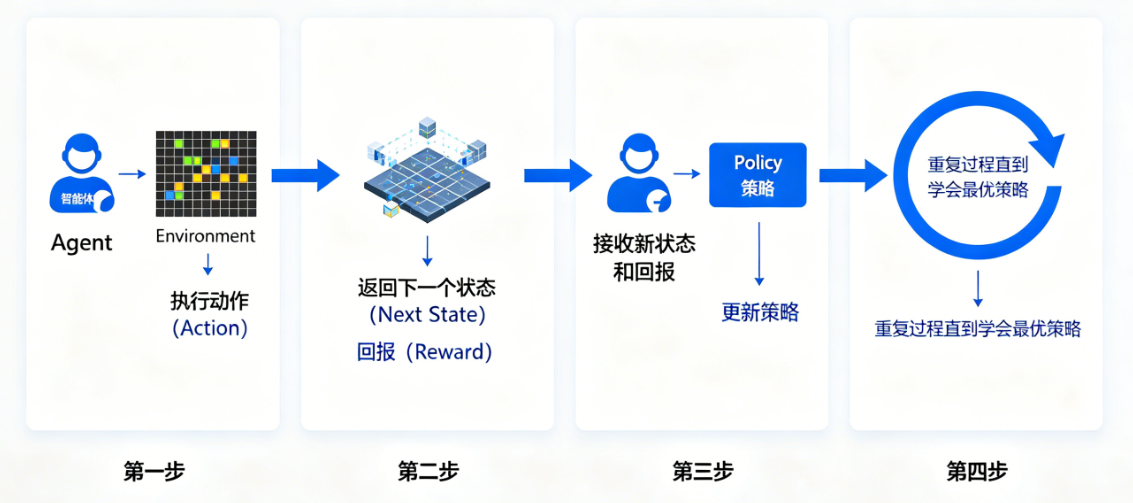
强化学习训练流程示意图
图片分析:图中展示了强化学习的完整训练流程:
- 智能体在环境中执行动作
- 环境返回下一个状态和回报
- 智能体根据回报更新自己的策略
- 重复步骤1-3,直到智能体学会最优策略
从训练曲线可以看到,随着训练回合数的增加,智能体获得的平均回报逐渐上升并趋于稳定,说明它已经学会了从起点到终点的最优路径。
3.5 优缺点与典型应用
✅ 优点 :不需要精确的数学模型,能处理高度复杂和非线性的系统;部署时计算量极小,响应速度极快
❌ 缺点:训练成本极高,需要海量的计算资源和仿真时间;泛化能力有限,环境变化太大时需要重新训练
真实案例:
- 波士顿动力Atlas人形机器人:使用强化学习训练跑、跳、后空翻等复杂动作
- OpenAI Dactyl:通过强化学习训练机械手解魔方,能适应不同的魔方大小和摩擦力
- 宇树Unitree四足机器人:使用强化学习训练在复杂地形上的行走和奔跑能力
四、三大流派横向对比与选型指南
为了让大家更直观地对比三大流派的差异,我们整理了下面的对比表格:
| 流派 | 核心思想 | 代表算法 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|---|
| 采样算法 | 快速试错找可行解 | RRT、PRM | 简单易实现,无需模型,响应快 | 解非最优,重复性差 | AGV导航、机器人抓取、未知环境探索 |
| 优化算法 | 基于模型求最优解 | MPC、WBC | 精度高,轨迹平滑,可处理约束 | 依赖精确模型,计算量大 | 工业机器人、自动驾驶、四足机器人平衡 |
| 学习算法 | 数据驱动学最优策略 | 强化学习、模仿学习 | 无需模型,部署快,可处理复杂系统 | 训练成本高,泛化有限 | 人形机器人运动、灵巧手操作、复杂地形导航 |
选型建议:
- 如果你的任务是快速原型验证,或者环境变化频繁且难以建模,优先选择采样算法
- 如果你的任务对精度和稳定性要求极高,并且能建立精确的数学模型,优先选择优化算法
- 如果你的任务非常复杂,难以用数学模型描述,并且有充足的计算资源用于训练,优先选择学习算法
总结
今天我们系统地拆解了机器人运动控制的三大上层算法流派:
- 采样算法是"野路子",靠快速试错解决问题,简单粗暴但有效
- 优化算法是"科班生",靠精确模型和数学推导得到最优解,稳定可靠
- 学习算法是"天才选手",靠海量训练提前学会所有情况,部署时行云流水
需要注意的是,这三大流派并不是互斥的。在实际的机器人系统中,往往是多种算法结合使用。比如自动驾驶汽车会用采样算法做全局路径规划,用优化算法做局部轨迹跟踪,用学习算法做障碍物检测和行为预测。
当然,这些都属于任务级的上层控制算法。在它们之下,还有我们之前讲过的PID控制等底层执行算法。只有上下层算法完美配合,才能让机器人做出精准、流畅的动作。