
1.1思路分析
完全二叉树 知识点分析
1 度为2 最大有两个孩子节点
2 且 度为1的节点 最多是1 可以没有 N1 只可以是1 or 0
3 度为0 与 度为2 之间的 关系 N0 = N2+1;
4 度小于2 的节点的数目加起来等于 总结点数 N0 + N1+N2 = N
有了以上的知识点 还得联系起来
1.2 解题
n0+n1+n2 = 2n
n0 = n2 +1; n2 = n0-1;
回代 n2 就是 n0 +n0-1+n1 = 2n
n0 +n0-1+n1 = 2n
此时 你得观察 式子的特点
右边 小学知识 任何数字 的 2倍都是偶数
所以 等式的特点 是****左右两边的数值 相等 且 性质 相同
故 2n0 +n1-1 = 2n;
变化一下 就是 偶数 + n1-1 = 偶数
要使得 左右两边的性质 相同 只有当n1 = 1时 就是 n1-1=0
故 消掉 变量 n1 得到 最终 式子 2n0 = 2n --> n0 = n;
1.3 类比出题 改变量条件
如果 节点总数是 奇数 只要 改变最后那个式子 的n1的 判断
即 2n0 +n1-1 = 奇数 同类题改条件
则 n1 = 0 使得 偶数 - 1 得到奇数

2.1 节点个数 与 树高 (层数)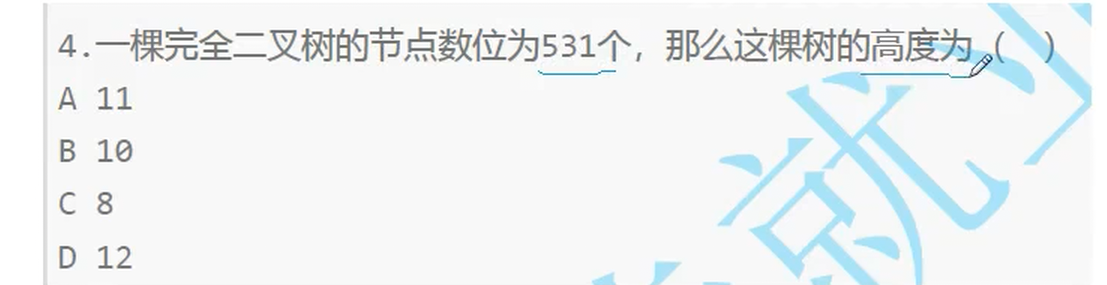
2.1.1知识点思路分析
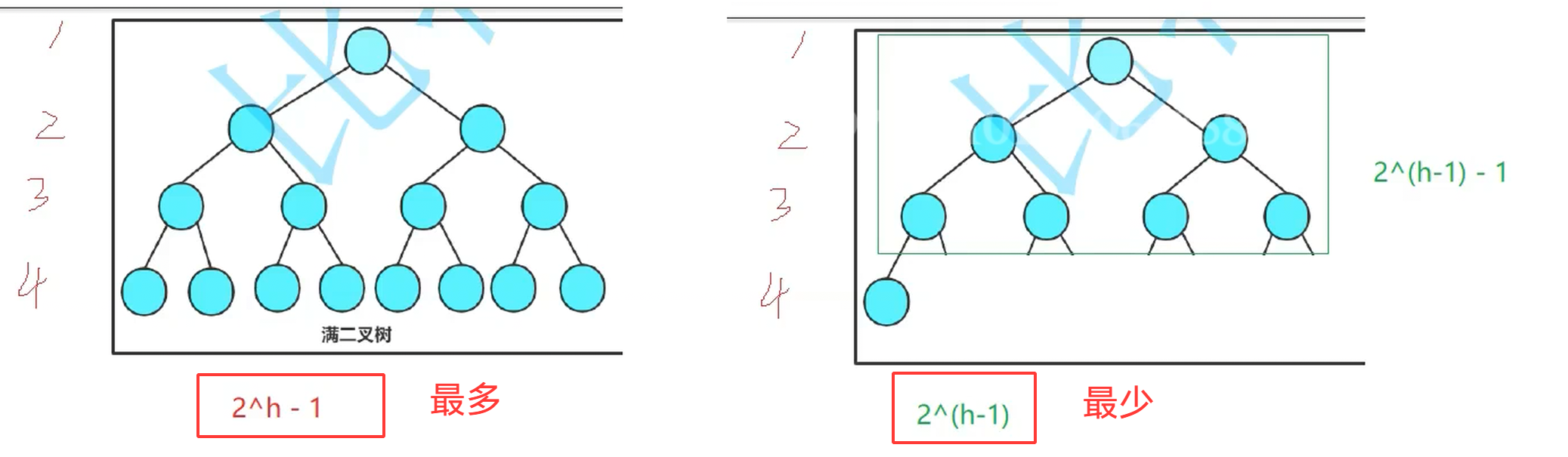
1 最多情况 满二叉树 是特殊的完全二叉树 类似正方形是特殊的长方形
观察 高度和节点数之间的关系 得出结论N = 2^h -1
接下来只要代数 即可 技巧 先代 11
最少是2^(11-1) = 1024 大于 531 不符合 即 12也不可以
代 8 求最大 2^8-1 = 255 小于 531 排除 即选 B
2.2 提炼解题通解
画图 利用性质定义 找对应规律 列关系式子 联合消元 再化简 即可
3.1 排序概念
排序的定义
排序是将一组数据按照特定规则(如升序或降序)重新排列的过程。
排序的目标是提高数据的可读性、搜索效率或满足特定算法需求。
3.1.0 排序的目的
总的来说 就是 将无序的一组数据 变得有序
商品的 价格 销量 评论数 上架时间 还有回购率 等等
数据 的升序 或降序排序 获得变化规律 和 找到最值
方便查找数据 提高数据的处理效率 使得数据更加有条理 、易于分析
3.1.1 基础排序分类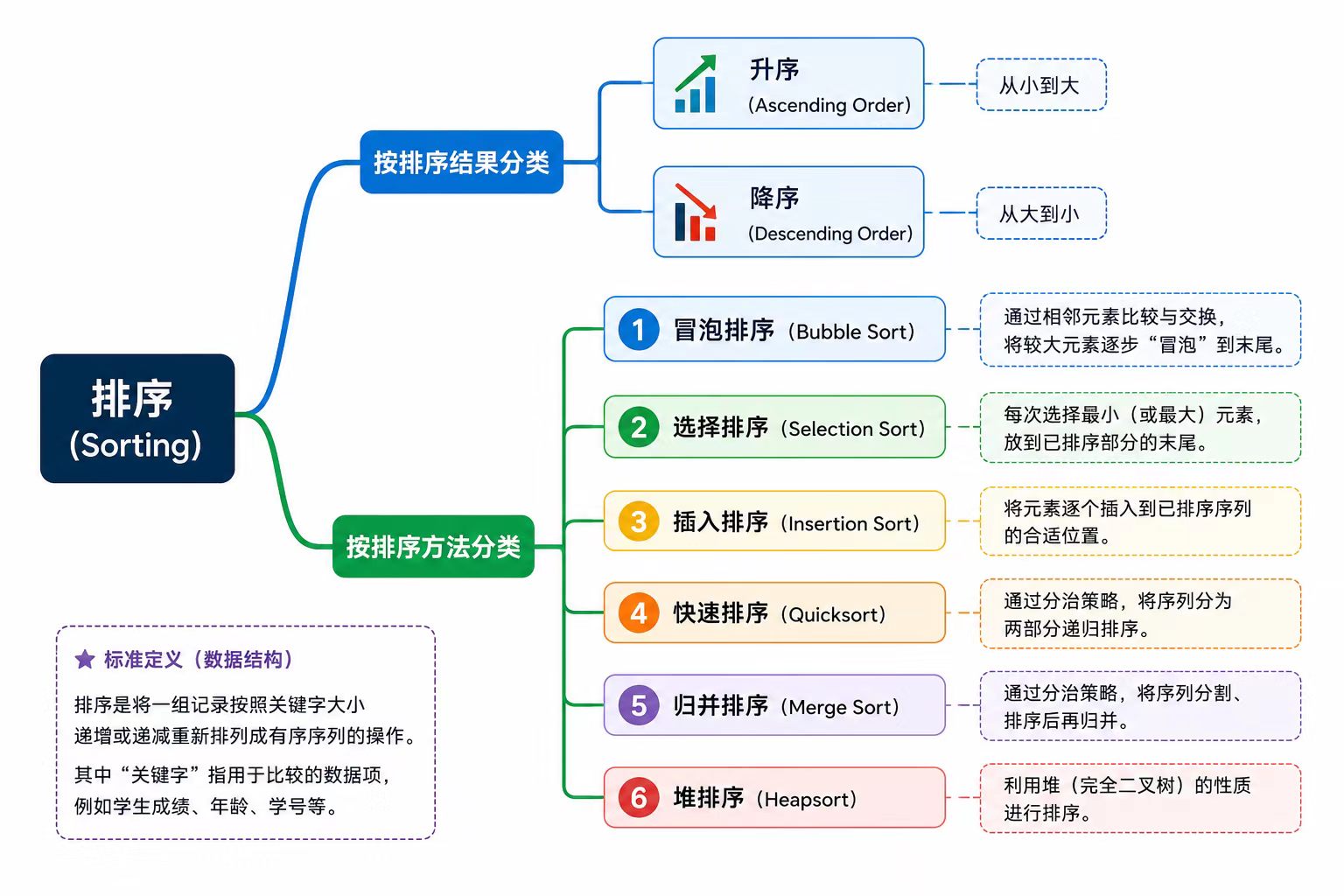
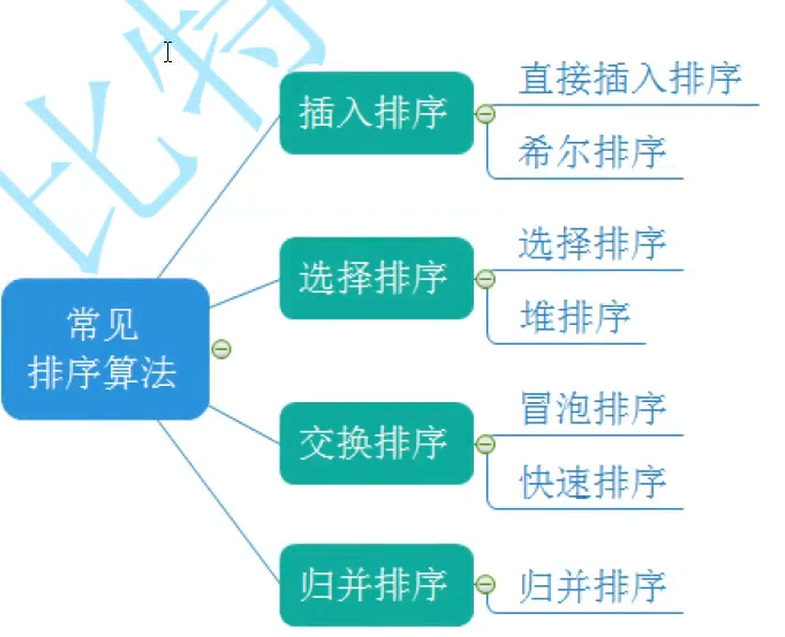
3.1.2. 基础比较排序(适合小规模数据) 教学意义
冒泡排序:通过相邻元素的反复比较和交换,让较大的元素像气泡一样逐渐"浮"到数列尾部。
选择排序:每次从未排序部分中找到最小(或最大)的元素,放到已排序部分的末尾。无论数据初始状态如何,比较次数都不变。
插入排序:构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。在数据基本有序时效率极高。
3.1.3. 高效比较排序(适合大规模数据)
快速排序:采用分治法,选择一个"基准"元素,将数组分为比基准小和比基准大的两部分,然后递归排序。它是实际工程中最常用的内部排序算法。
归并排序:同样采用分治法,将数组对半拆分直到只剩一个元素,然后将有序的子数组向上两两合并。它在处理链表这类数据结构的排序时表现非常优异。
堆排序 :巧妙利用了"堆"这种完全二叉树的数据结构。通过构建大顶堆(或小顶堆),不断将堆顶元素与末尾元素交换并调整堆,从而实现 O(1) 的极低空间消耗。(在上期博客里讲过)
3. 1.4 非比较排序(适合特定分布的数据)
这类算法突破了基于比较的 O(n \log n) 时间下限,但通常需要牺牲一定的内存空间,且对数据特征(如必须是整数)有严格要求。
计数排序:适用于极值范围不大的整数序列,通过统计每个元素出现的次数来确定其在最终数组中的位置。
桶排序:将数据分到有限数量的桶里,每个桶再分别排序(通常借用插入排序),最后依次输出拼接。
基数排序:按位进行排序(如先排个位,再排十位),内部通常借助计数排序或桶排序来实现稳定的分配和收集。
4.1 插入排序 
直接插入排序(Insertion Sort) 是一种简单直观、且在部分场景下极度高效的比较排序算法。
它的工作原理非常类似于我们打扑克牌时整理手牌的过程:每次拿到一张新牌,都会在已经排好序的手牌中从后往前扫描,找到它合适的位置并插入 进去。
核心工作原理
插入排序将待排序的数组在逻辑上分为两个部分:
已排序区间(Sorted Subarray) :初始时通常只包含数组的第一个元素(一个元素天然有序)。
未排序区间(Unsorted Subarray):除第一个元素以外的其余所有元素。
算法执行步骤:
1 从未排序区间中取出第一个元素,作为当前需要插入的"基准元素"。
2 在已排序区间中从后向前进行扫描、比较。
3 如果已排序区间中的元素比基准元素大,就将该元素向后移动一个位置,为基准元素腾出空间。
4 重复步骤 3,直到找到一个小于或等于基准元素的元素,或者扫描完整个有序区间。
5 将基准元素插入到该空出的位置。
6 重复上述步骤,直到未排序区间没有元素,此时整张表排序完成。
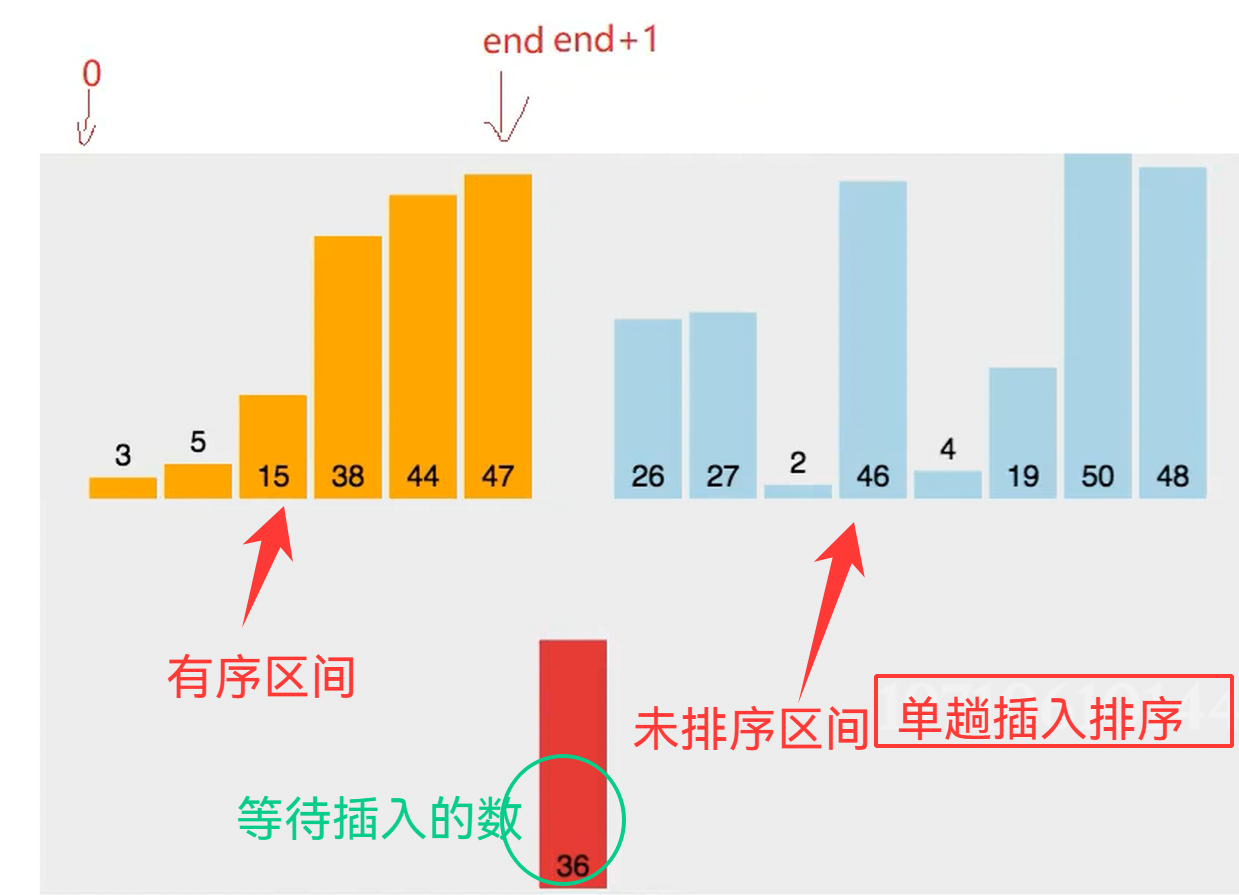
4.1.2 单趟插入排序 (动图)
实际上就是使得 单趟使得 有序空间增大 无顺序空间 数据量减少的 操作 最后整体就会有序 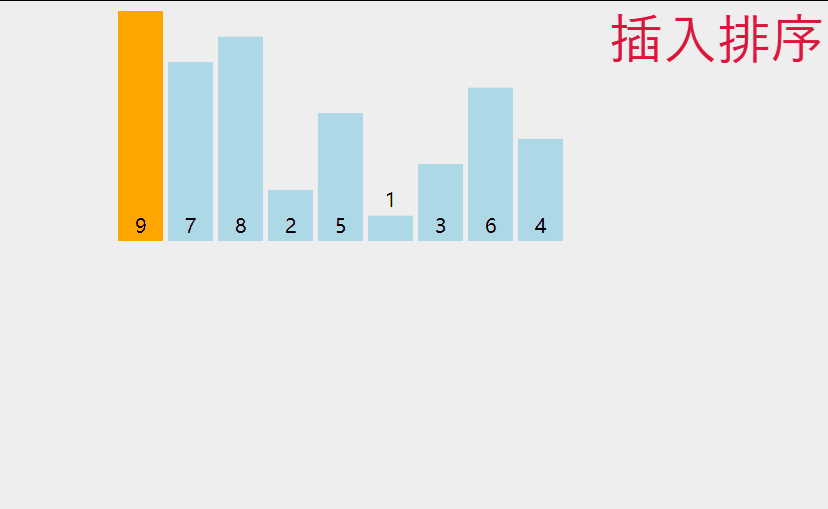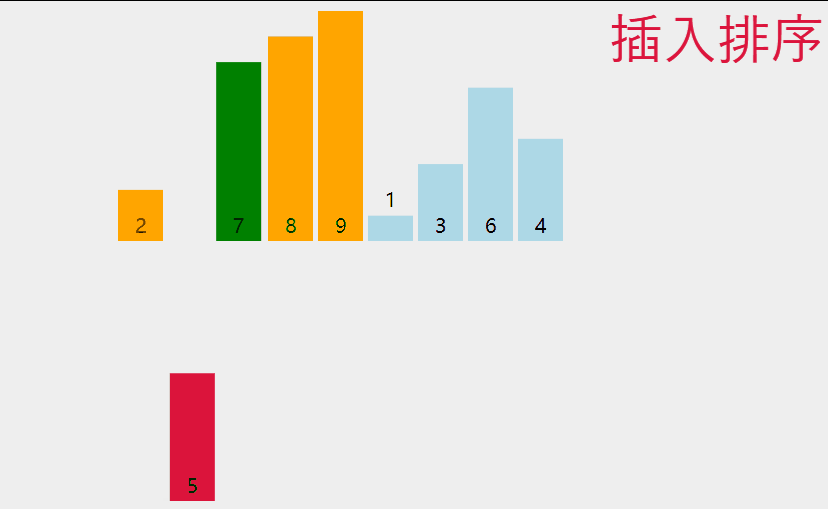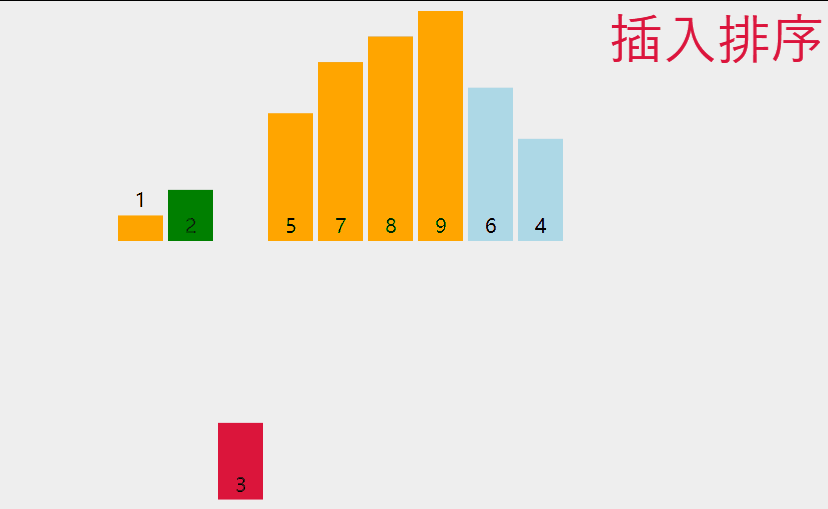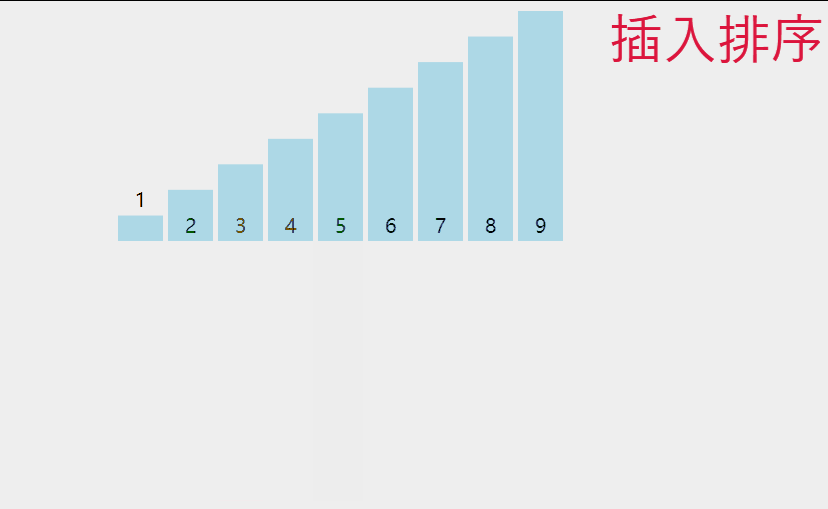
动图 的 理解 介绍
黄色 表示的是 已排序区间
绿色 表示 要挪动的数据
蓝色 表示 未排序区间
红色 表示 待插入的数据
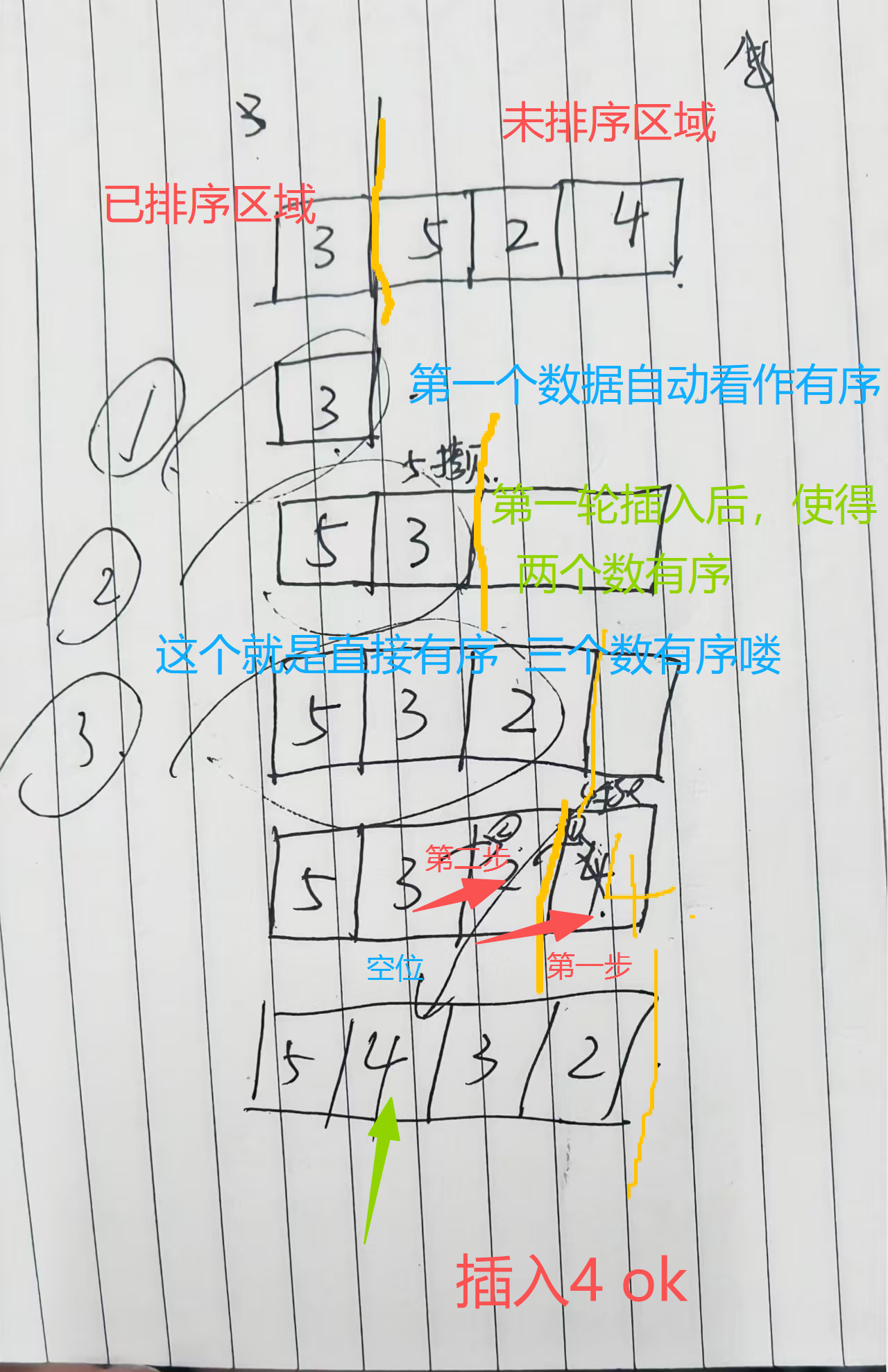
4.1.2.1 思路分析 + 手绘图解
第一个数据 直接视作有序 (天然有序)
接下来 看第二个数据 比较第一个数据
两种可能 第一种情况 满足顺序(无论降序升序)是标准的有序数组(前两项) 无需调整
2 1 3 4 7 6 只看前两项满足降序的顺序 就不调整 不插入 用下一个位置继续比较
第二种情况 (插入排序算法) 先用临时变量tmp 存住第二个位置的数据 再挪动第一个数据到第二个位置
将第一个数据的位置就空 出来了 所以有位置 了 直接插入刚刚存了的tmp 就好
4.1.3代码实现
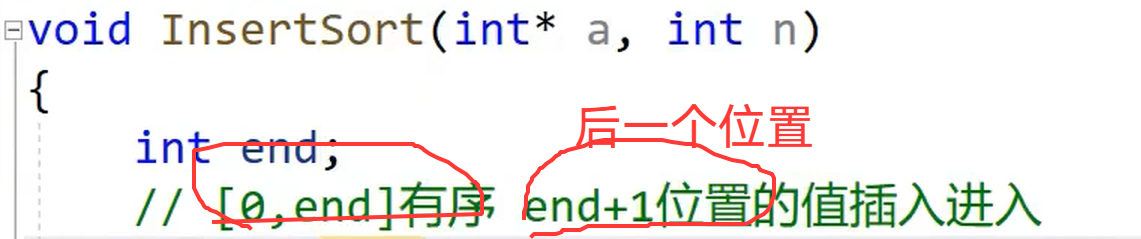
单趟代码
4.1.3.1逐帧 画图拆解 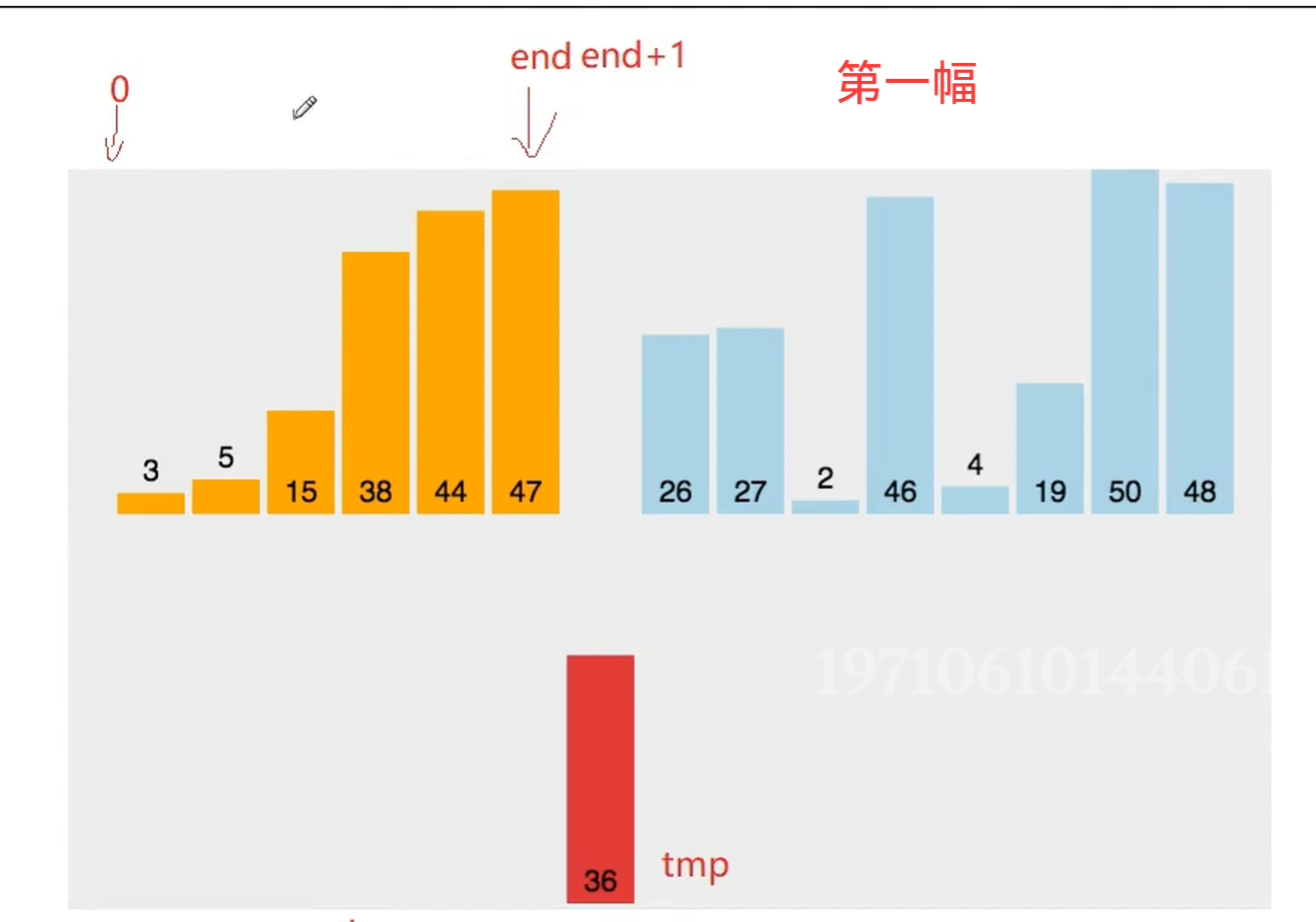
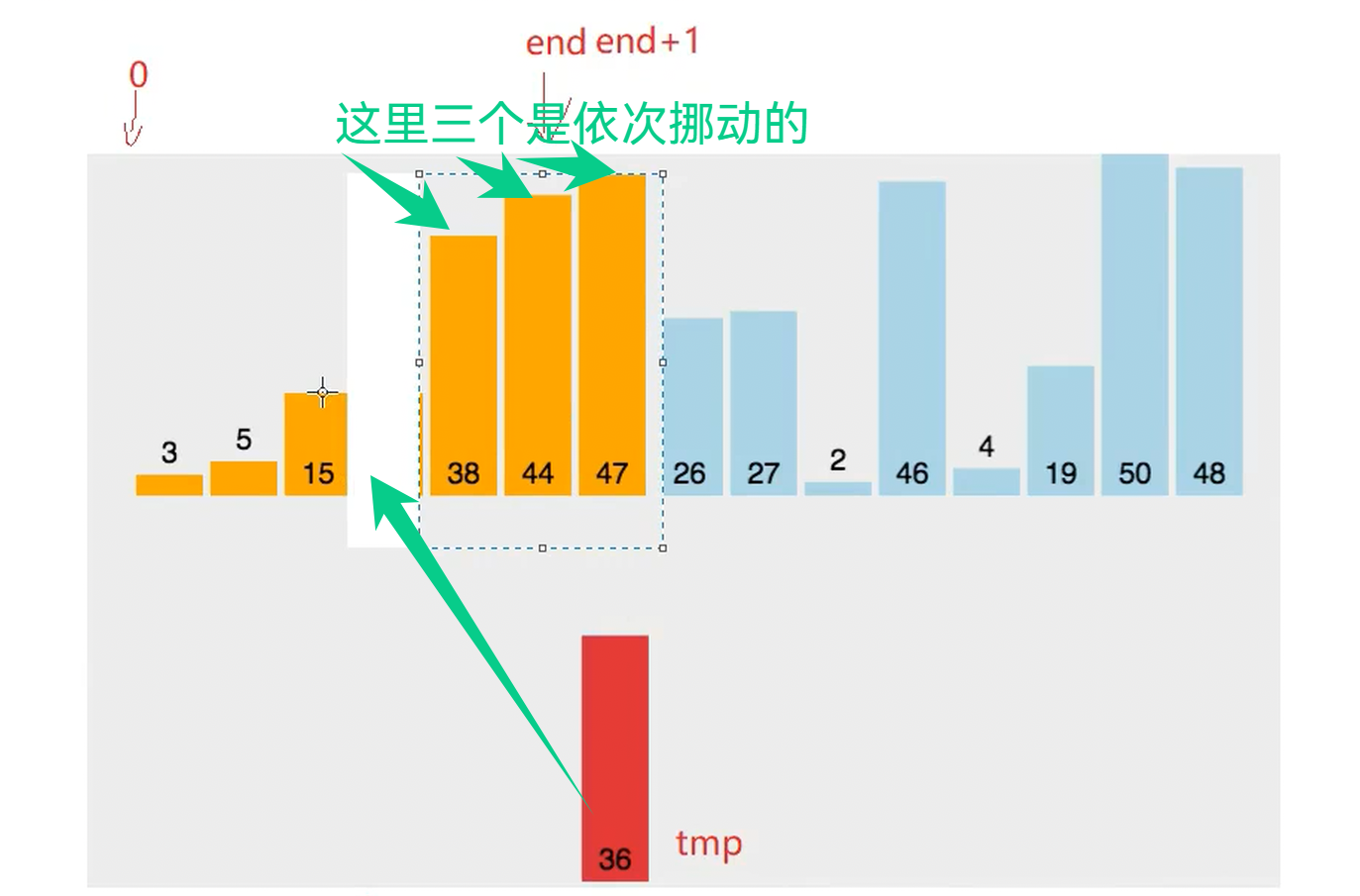
第一次挪动
因为 47 >36 所以需要向后移动 直接覆盖掉了原来的36 为了解决这一弊端 使用临时变量 tmp
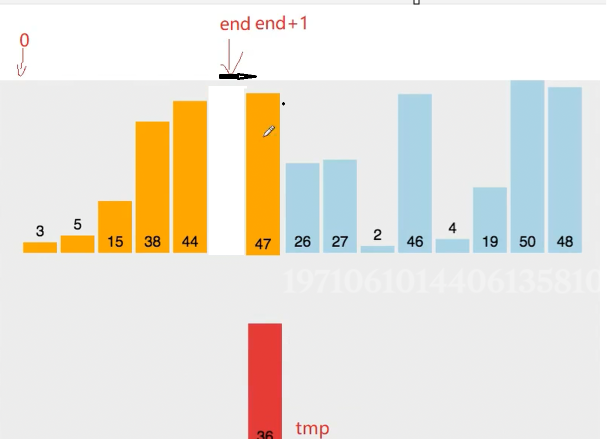
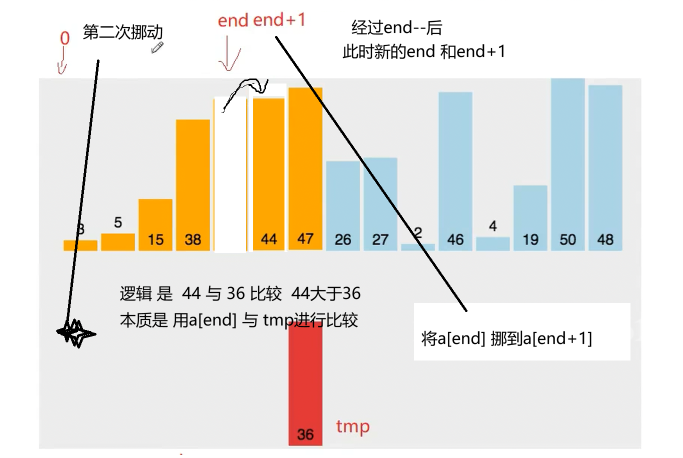
第三次挪动 比较可知 38 大于36 所以往后移动一个
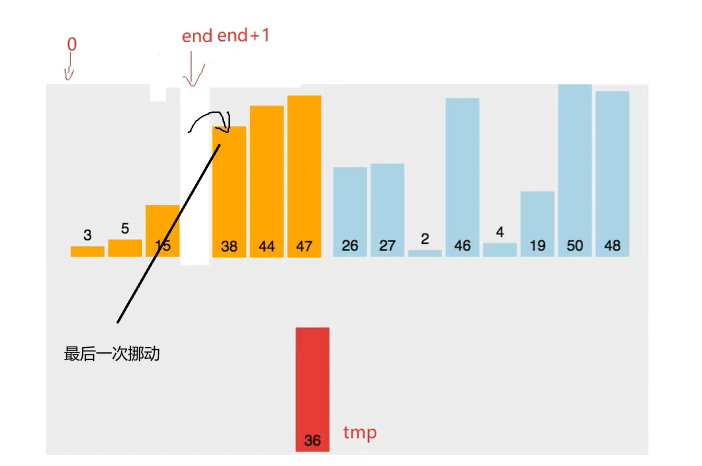 此时关键 空出了重要位置
此时关键 空出了重要位置 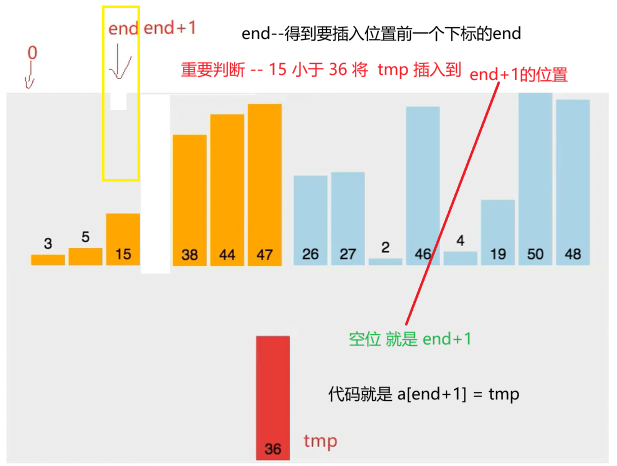
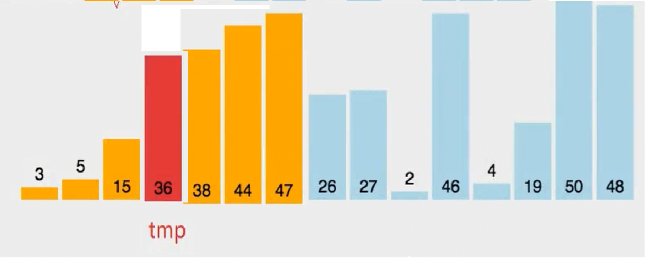
完成一轮的插入 就是 实现了该位置以前的数据 实现了局部有序了
由此 得出第一个结束条件 次数控制 总共 sz -1 次就会实现排序
就是当除了第一个数外 都实现了 这种 一趟的插入 就全部有序了
假设 tmp ==1 时候 继续画图 5到47 都是依次往后挪动的
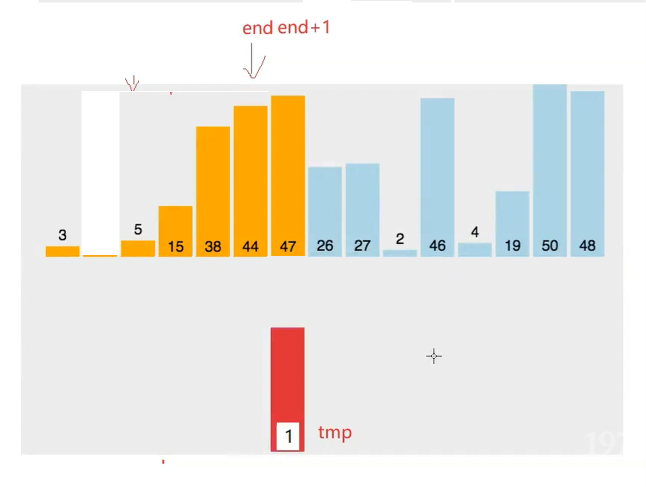
发现 3 也比1小 所以 还要挪动 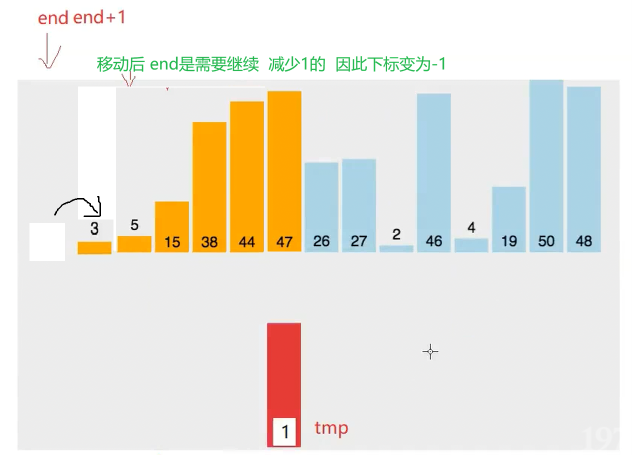
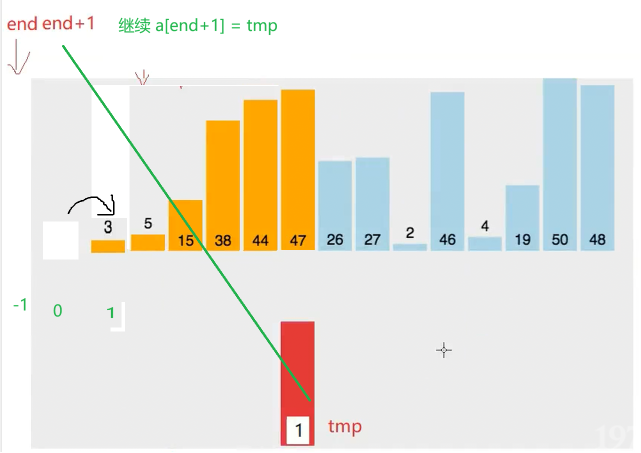
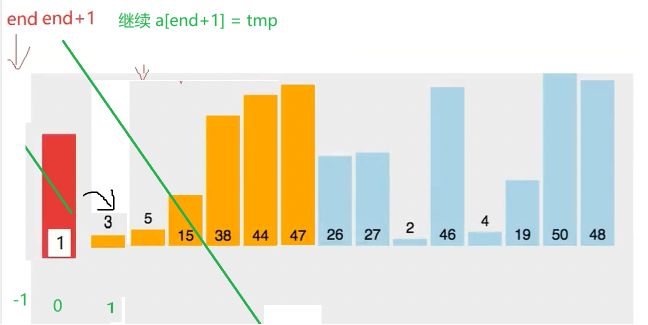
实际的目的就是
使得tmp 插入到 前面有序 的【0,end】里 并且 保持有序
有序空间增大 无序空间减少 直到0

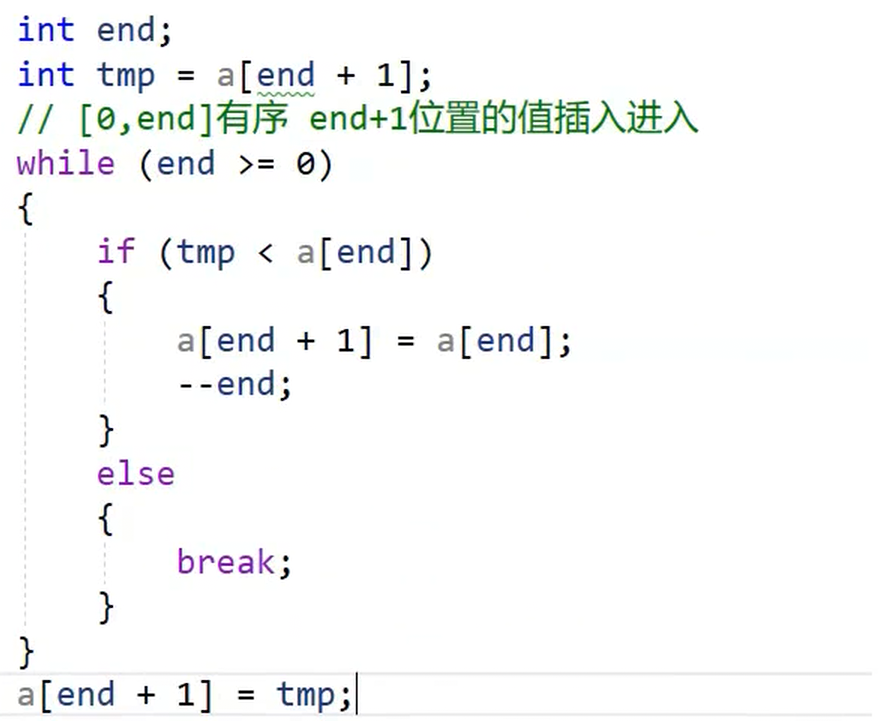
对比之后发现 可以合并在一起
代码一样 功能都是插入 tmp处的值
最重要 的是 时机刚好也可以在一起处理了
1在不满足时的空位 利用break退出循环后 就也是需要 在空位赋值 tmp
2 如果全满足If条件 循环结束后 会空出a0 这个位置
此时end ==-1 需要用到 aend+1 = tmp;来插入空位哦
总结 将插入逻辑都放到 循环外面实现就好 '
4.1.4 逐语句 的分析代码
1 。先讲外层控制趟数 的循环 n个数 最多 只要n-1次就会有序
首先 n个数的数组 下标是 0,n-1
有序空间 是从0,end--- 0,0---- 0,1----0,2----0,**n-2** 后面还有最后一个数据 就是 an-1****
需要插入到前面有序的空间内****因此end的最大值是 n-2
所以在限制总循环次数时候 可以用 i<n-1 等价于 i<=n-2
还可以这样理解就是 第一个数 是天然有序的 就没插入
剩下的每个数都会和前面的新形成的有序区间 比较后 插入
就是 总个数 -1 ==== n-1 === 总次数 使得下标与数组的定义 平齐时 就是 【0,n-2 】
0------n-2 共有n-1个数字
