为什么要在本地跑大模型?
OpenClaw 是一个非常好用的 AI 助手平台,但它默认依赖云端 API。用量确实很大,费用真的不便宜,每月至少几百块打底。
而本地模型呢?一次硬件投入,零边际成本。 数据不出门,连隐私问题也一并解决了。
于是我搞了一套方案:一台电脑跑 OpenClaw,另一台电脑跑 Ollama 提供模型服务,局域网内互通。 下面是我完整的配置记录,包含 5 个真实踩坑和解决方案。
一、环境准备
设备分工
| 设备 | 角色 | IP | 软件 |
|---|---|---|---|
| 主机 A | OpenClaw 客户端 | 192.168.1.69 | OpenClaw 2026.3.2 |
| 主机 B | Ollama 服务端 | 192.168.1.189 | Ollama + 3 个模型 |
服务端(主机 B)要做的事
- 安装 Ollama
- 下载模型:
qwen3-vl:8b(多模态)、qwen3.5:latest(日常文本)、deepseek-r1:14b(强推理) - 启动 Ollama API 服务(默认端口 11434)
- 配置防火墙开放 11434 端口------这条后面会反复提到
- 配置:
CPU:Intel® Core™ i5-14600KF
内存:32G
GPU:NVIDA GeForce RTX 4060(8G)
客户端(主机 A)要做的事
- 安装 OpenClaw 2026.3.2
- 添加本地 Ollama 提供商
- 设置默认模型
二、核心配置
在 OpenClaw 的配置文件中添加本地 Ollama 提供商:
json
"local-ollama": {
"baseUrl": "http://192.168.1.179:11434",
"apiKey": "local",
"api": "ollama",
"models": [
{"id": "qwen3-vl:8b", "name": "Qwen 3 VL 8B", "contextWindow": 64000, "maxTokens": 8192},
{"id": "qwen3.5:latest", "name": "Qwen 3.5", "contextWindow": 32000, "maxTokens": 4096},
{"id": "deepseek-r1:14b", "name": "DeepSeek R1", "contextWindow": 32000, "maxTokens": 4096}
]
}然后设置默认模型并重启:
powershell
# 设置默认模型
openclaw config set agents.defaults.model.primary "local-ollama/qwen3-vl:8b"
# 重启 OpenClaw Gateway
openclaw gateway stop
openclaw gateway三、踩坑实录:5 个问题及解决方案
这才是最有价值的部分。下面是我逐个排查、逐个解决的真实过程。
坑 1:API 格式不兼容,直接 404
现象: 配置完启动,OpenClaw 报 404,Ollama 服务端没有任何请求日志。
原因: OpenClaw 默认把请求包装成 OpenAI API 格式(/v1/chat/completions),但 Ollama 用的是自己的原生格式(/api/chat)。格式不匹配,Ollama 直接拒绝。
解决: 把 api 类型从 openai-completions 改成 ollama:
powershell
openclaw config set models.providers.local-ollama.api "ollama"这是最关键的一步,也是文档里最容易漏掉的配置。
坑 2:防火墙挡住连接,超时到天荒地老
现象: API 类型改对了,但请求一直超时,没有任何响应。
原因: Windows 防火墙默认拦截 11434 端口的外部访问。本机访问没问题,局域网另一台机器过来就不行。
解决: 在服务端执行:
powershell
New-NetFirewallRule -DisplayName "Ollama" -Direction Inbound -Protocol TCP -LocalPort 11434 -Action Allow放行后再测试,秒通。
坑 3:会话文件被锁,卡住不动
现象: 某次异常退出后重启,OpenClaw 卡在加载会话阶段,超时报错 session file locked。
原因: 异常退出时会话文件的锁没释放,新进程拿不到锁就死等。
解决: 找到 session 目录,删掉 .lock 文件:
powershell
Remove-Item "C:\Users\Administrator\.openclaw\agents\main\sessions\*.lock" -Force如果你也遇到类似问题,先别急着重装,大概率是锁没释放。
坑 4:Token 使用率飙到 94%,对话突然中断
现象: 长对话跑着跑着突然报错 tokens 937k/1.0m (94%),然后就没下文了。
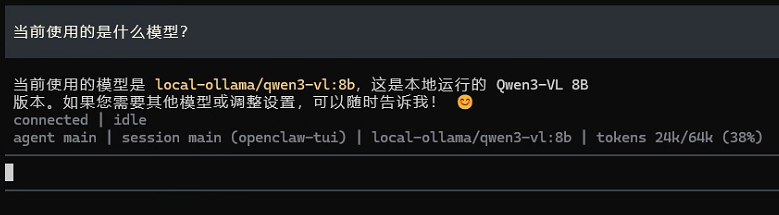
原因: 对话历史越来越长,累积的 token 快超过模型的上下文窗口上限。OpenClaw 的自动压缩机制还没来得及触发。
解决: 手动清理旧会话释放空间:
powershell
Remove-Item "C:\Users\Administrator\.openclaw\agents\main\sessions\*.jsonl" -Force预防策略:
- 定期清理会话,保持 token 使用率在 80% 以下
- 长任务分段执行,每次新开对话
- 合理设置上下文窗口(不要盲目设大,32K~64K 够用)
坑 5:模型响应超时,15 分钟是底线
现象: 给本地模型发请求,等了几分钟直接超时报错。
原因: 本地模型有两个耗时大头:一是首次加载(30-60 秒),二是推理生成。默认超时时间(通常 5 分钟)不够用。
解决: 把超时拉到 15 分钟:
powershell
openclaw config set agents.defaults.timeoutMs 900000对于 14B 的大模型,第一次加载尤其慢。给它足够的时间,后续请求会快很多。
四、三款模型怎么选
| 模型 | 参数量 | 类型 | 适用场景 |
|---|---|---|---|
| qwen3-vl:8b | 8.8B | 多模态 | 图文理解、截图分析 |
| qwen3.5:latest | 9.7B | 纯文本 | 日常对话、简单任务 |
| deepseek-r1:14b | 14.8B | 推理 | 复杂逻辑、代码分析 |
省钱策略: 简单问题用 qwen3.5,省算力;复杂推理切 deepseek-r1,物尽其用。多台机器的话,可以按任务类型自动路由------这就是下面的分布式推理。
五、延伸构想:局域网分布式推理架构
单机方案跑通之后,我产生了一个想法:能不能把多台机器的算力拼起来?
思路很简单:局域网里不止一台机器有 GPU,如果能统一调度,就能实现更大规模、更低延迟的推理。
架构设想:
- 调度中心:一台机器作为调度器,接收来自 OpenClaw 的请求
- 工作节点:多台机器各自运行 Ollama,加载不同的模型
- 智能路由:根据任务类型、各节点负载、模型可用性,动态分配请求
- 容错机制:单节点挂掉不影响整体,自动切换到备用节点
举个例子:用户发来一个图片分析请求 → 调度器识别为多模态任务 → 路由到跑 qwen3-vl 的节点。同时另一台机器在处理纯文本对话,互不干扰。
这个架构还在设计中,核心要解决的是任务拆分粒度 和节点间通信效率。但方向是明确的:用廉价硬件堆出高性能的本地推理集群,彻底告别云 API 的按量计费。
六、总结
| 要点 | 说明 |
|---|---|
| 成本 | 一台旧电脑跑 Ollama,边际成本为零 |
| 隐私 | 数据全程不出局域网 |
| 配置门槛 | 核心就两步:api 类型改成 ollama,防火墙放行端口 |
| 踩坑 | 404、超时、锁文件、token 爆表、加载慢------全是可解的 |
| 扩展性 | 从单机到分布式,算力可水平扩展 |
关键参数速查:
- API 类型:
ollama(不是 openai-completions) - 端口:
11434 - 超时:至少 900 秒
- 上下文窗口:32K~64K(按需调整)
如果你也在用 OpenClaw 或者对本地部署感兴趣,欢迎交流。省下来的 API 费,够买好几台二手主机了。