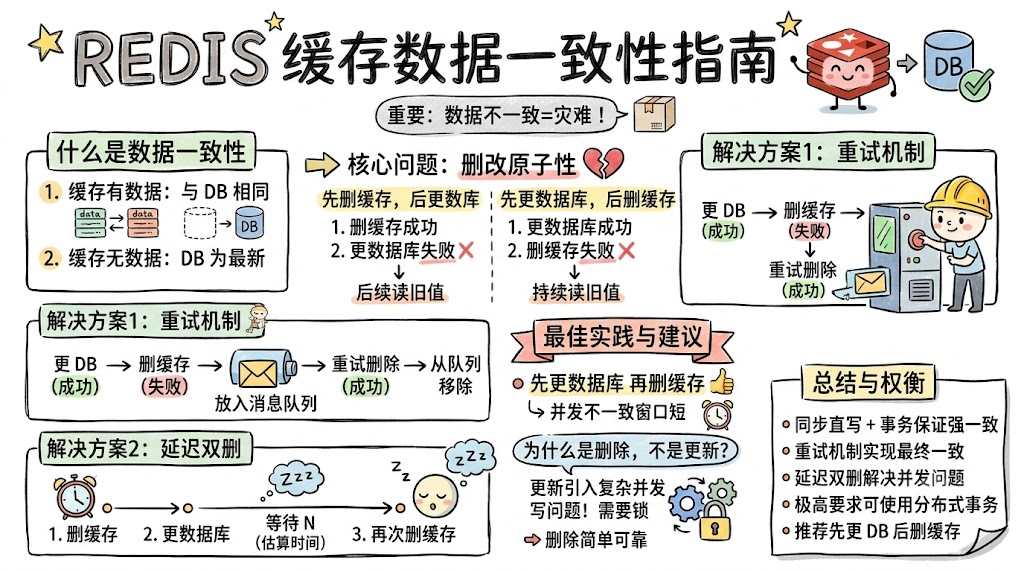
文章目录
- 引言
- 什么是数据一致性
- 读写缓存的一致性
- 只读缓存的一致性问题
- 解决方案一:重试机制
- 解决方案二:延迟双删
- 两种顺序的对比与建议
- [更新缓存 vs 删除缓存](#更新缓存 vs 删除缓存)
- 总结
引言
只要使用 Redis 缓存,就必然面对一个问题:缓存中的数据和数据库中的数据如何保持一致?这不是一个可选话题,而是缓存应用中的"必答题"。
如果库存信息在缓存中是 100,数据库中已经变成 0,业务层还在允许下单------这种不一致带来的后果是灾难性的。理解不一致的成因和应对方案,是 Redis 缓存实战的核心能力。
什么是数据一致性
缓存和数据库的"一致性"包含两种情况:
- 缓存中有数据:缓存的值必须和数据库中的值相同
- 缓存中没有数据:数据库中的值必须是最新值
不满足这两个条件的,就是数据不一致。
读写缓存的一致性
对于读写缓存(增删改都在缓存中进行),一致性取决于写回策略:
同步直写:写缓存时同步写数据库,两者保持一致。但需要用事务机制保证原子性------要么都更新成功,要么都不更新。
异步写回:写缓存时不写数据库,等数据被淘汰时再写回。如果数据还没写回就发生故障,数据库就缺少最新数据。
结论:读写缓存要保证一致性,必须用同步直写 + 事务。异步写回只适合对一致性要求不高的场景(如商品的非关键属性、视频的创建时间等)。
只读缓存的一致性问题
只读缓存是更常见的使用模式。新增数据直接写数据库,删改数据时写数据库并删除缓存。
新增数据:天然一致
新增数据直接写入数据库,缓存中本来就没有这条数据。符合一致性的第二种情况(缓存无数据,数据库是最新值),不存在不一致问题。
删改数据:问题所在
删改操作需要同时做两件事:更新数据库 + 删除缓存。这两个操作无法保证原子性,就会出问题。
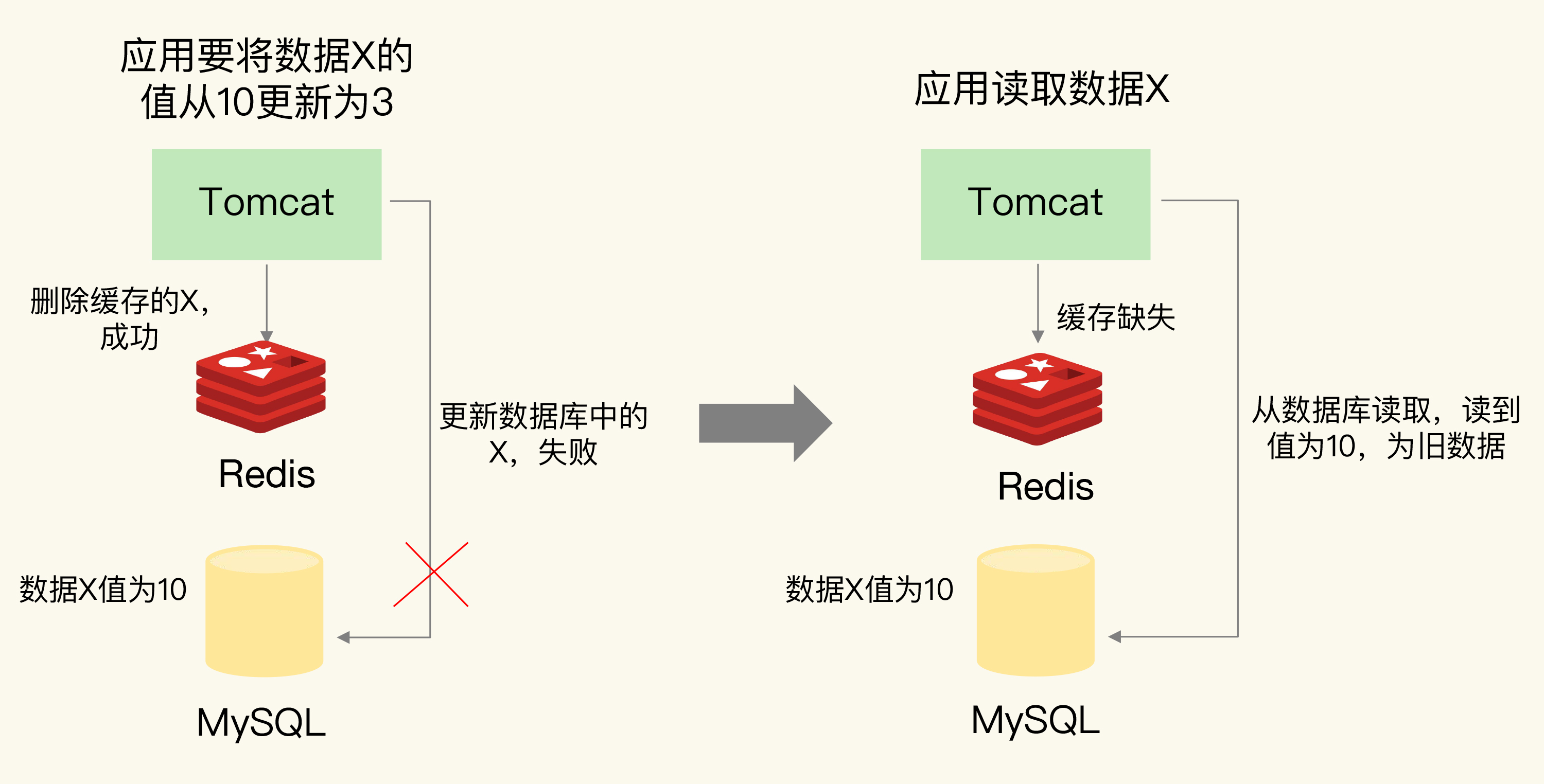
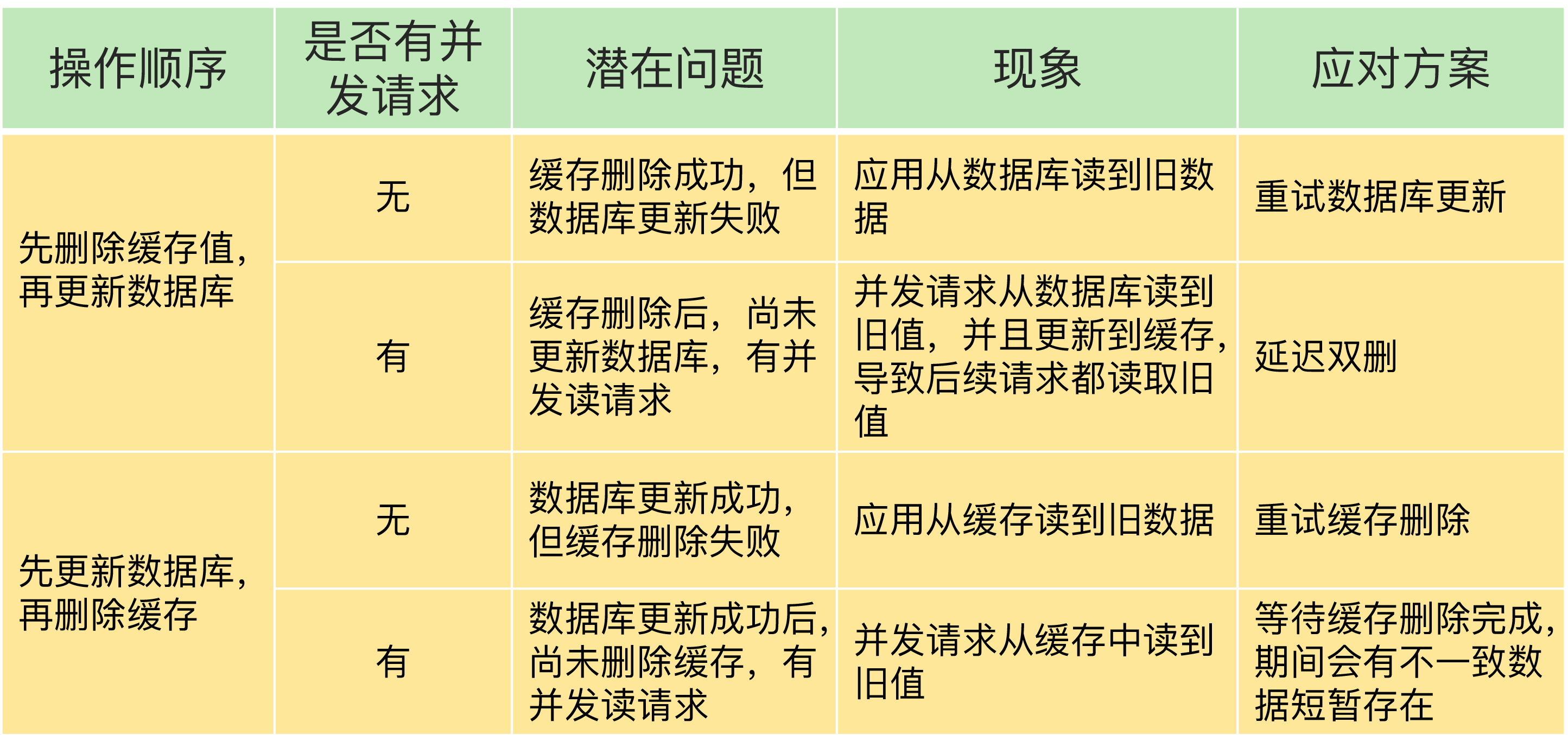
场景一:先删缓存,再更新数据库
如果缓存删除成功,但数据库更新失败:
1. 应用删除 Redis 中 X 的缓存值(成功)
2. 应用更新数据库中 X 的值(失败)
3. 其他请求查询 X → 缓存缺失 → 查数据库 → 读到旧值数据库没更新成功,但缓存已经被删了,后续请求从数据库读到的是旧值。
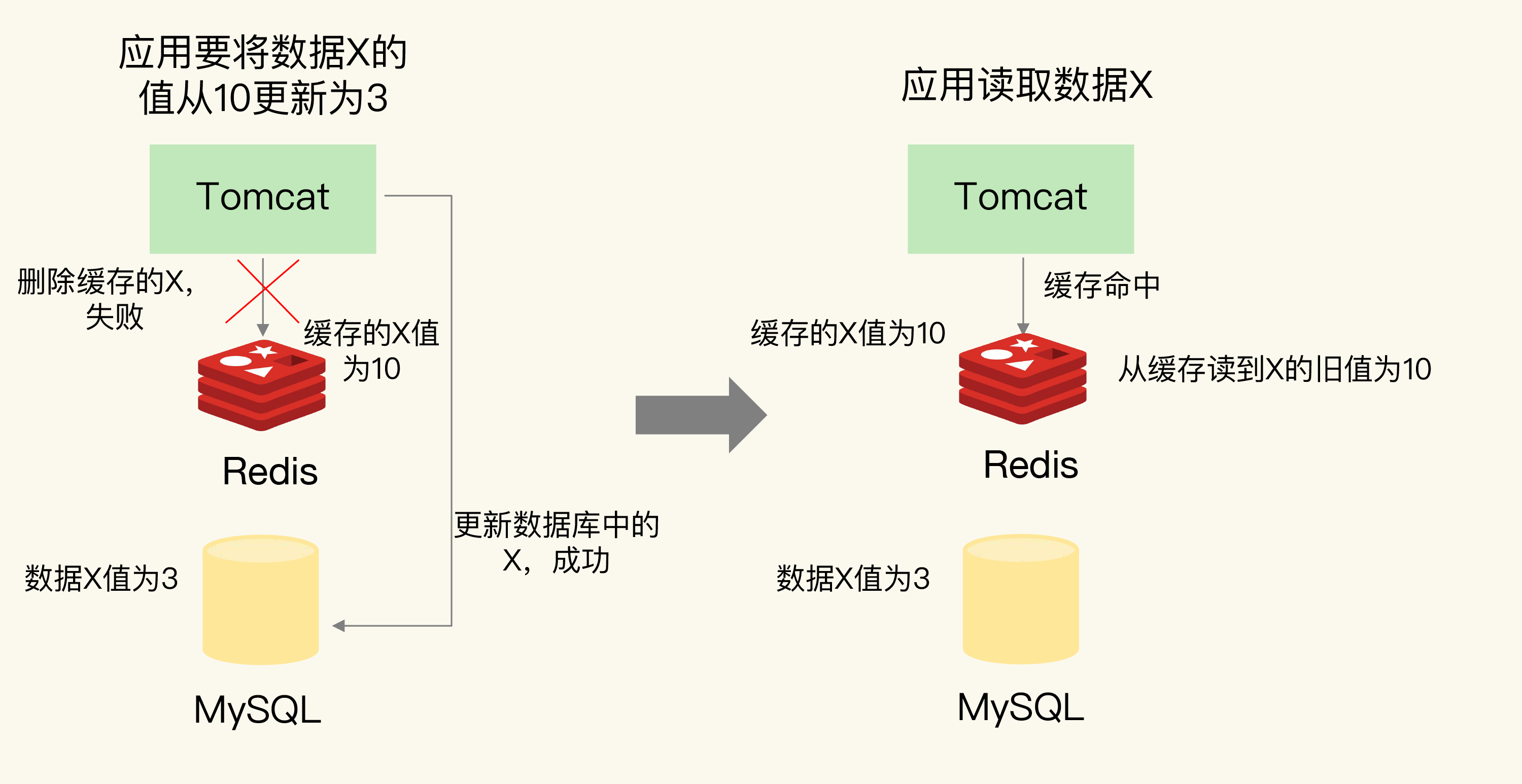
场景二:先更新数据库,再删缓存
如果数据库更新成功,但缓存删除失败:
1. 应用更新数据库中 X 的值为 3(成功)
2. 应用删除 Redis 中 X 的缓存值(失败)
3. 其他请求查询 X → 缓存命中 → 读到旧值 10数据库已经是新值 3,但缓存中还是旧值 10,后续请求直接命中缓存读到旧值。
无论哪种顺序,只要有一个操作失败,就会导致不一致。

解决方案一:重试机制
针对操作失败导致的不一致,核心思路是重试直到成功。
具体做法:把要删除的缓存值或要更新的数据库值暂存到消息队列(如 Kafka)。如果操作失败,从消息队列重新读取并重试。成功后从队列中移除,避免重复操作。超过重试次数仍失败,则向业务层报错。
1. 应用更新数据库(成功)
2. 应用删除缓存(失败)
3. 将删除操作写入消息队列
4. 消费者从队列取出,重试删除缓存
5. 删除成功,从队列移除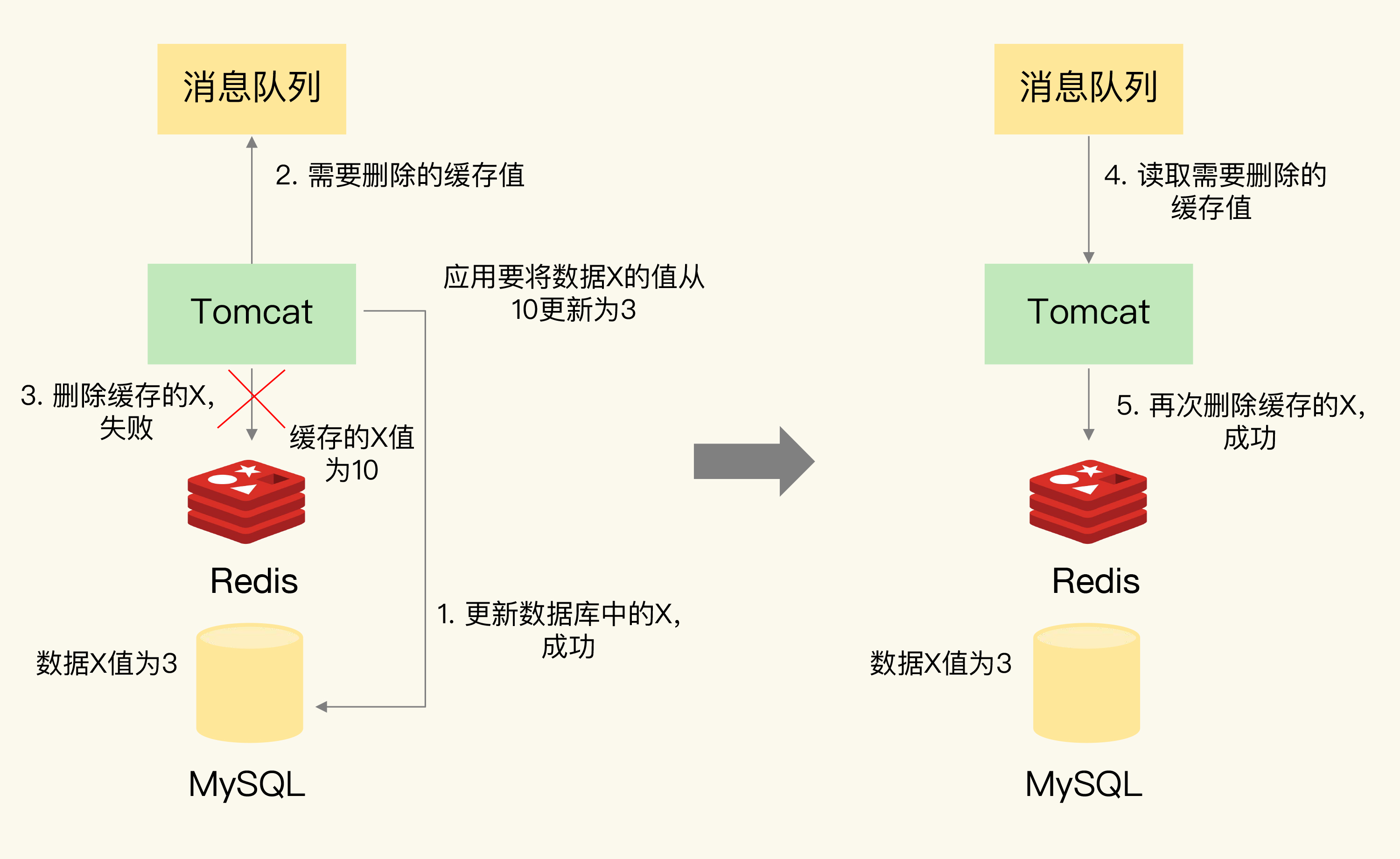
重试机制保证了最终一致性------即使某次操作失败,通过重试最终能达到一致状态。
解决方案二:延迟双删
即使两个操作都没失败,在高并发场景下仍然可能出现不一致。
并发问题:先删缓存,再更新数据库
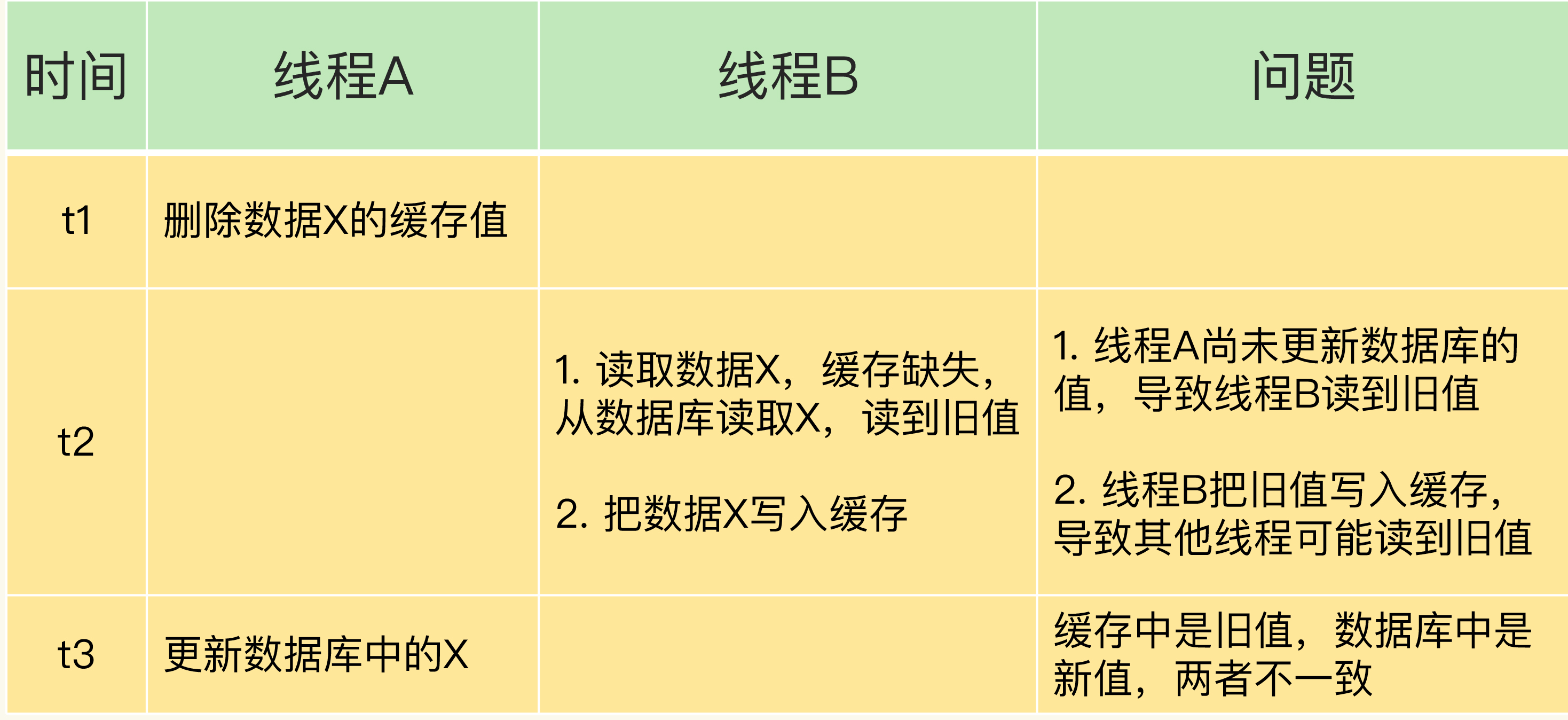
时间线:
T1: 线程 A 删除缓存中 X 的值
T2: 线程 B 读取 X → 缓存缺失 → 从数据库读到旧值 → 写入缓存
T3: 线程 A 更新数据库中 X 的值结果:缓存中是旧值(线程 B 写入的),数据库中是新值(线程 A 更新的),不一致。
延迟双删方案:线程 A 更新完数据库后,sleep 一小段时间,再次删除缓存。
java
redis.delKey(X); // 第一次删除
db.update(X); // 更新数据库
Thread.sleep(N); // 等待线程 B 完成读取和写缓存
redis.delKey(X); // 第二次删除sleep 的时间 N 需要大于线程 B 读数据库 + 写缓存的时间。这个时间可以通过统计业务运行时的读写耗时来估算。
第二次删除之后,其他线程再读取时会触发缓存缺失,从数据库读到最新值。
并发问题:先更新数据库,再删缓存
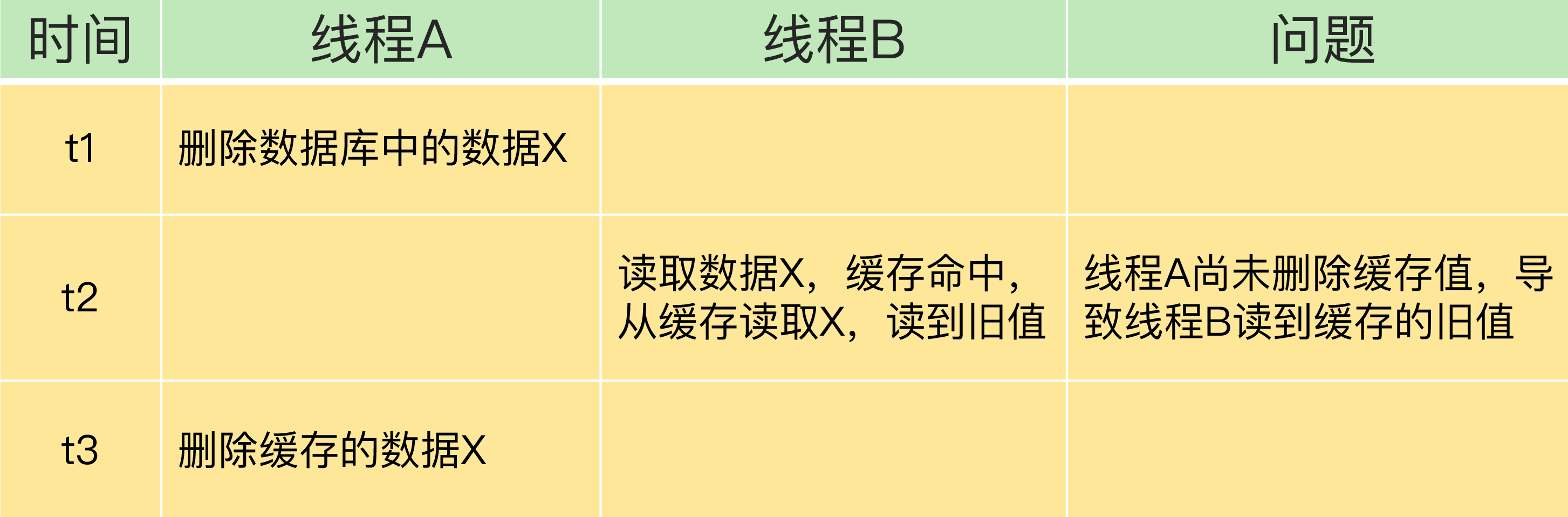
时间线:
T1: 线程 A 更新数据库中 X 的值
T2: 线程 B 读取 X → 缓存命中 → 读到旧值
T3: 线程 A 删除缓存中 X 的值这种情况下,线程 B 确实读到了旧值,但影响范围有限:
- 只有在 T1 到 T3 这个短暂窗口内的请求会读到旧值
- 线程 A 很快就会删除缓存,后续请求会从数据库加载最新值
- 不会像"先删缓存"那样,旧值被写入缓存长期驻留
这也是为什么推荐"先更新数据库,再删缓存"的原因。
两种顺序的对比与建议
| 操作顺序 | 单操作失败 | 并发问题 | 影响程度 |
|---|---|---|---|
| 先删缓存,再更新数据库 | 旧值被读取 | 旧值被写入缓存长期驻留 | 较大 |
| 先更新数据库,再删缓存 | 旧值被读取 | 短暂窗口内读到旧值 | 较小 |
建议优先使用"先更新数据库,再删缓存",原因:
- 先删缓存会导致请求因缓存缺失而涌向数据库,增加数据库压力
- 延迟双删中的等待时间不好精确设置,设短了不一致,设长了影响性能
- 先更新数据库再删缓存的并发不一致窗口很短,对大多数业务可以接受
如果业务要求强一致性,可以在更新数据库期间,暂存 Redis 客户端的并发读请求,等数据库更新完、缓存删除后再放行读请求。
更新缓存 vs 删除缓存
有人会问:为什么是删除缓存而不是直接更新缓存?
直接更新缓存相当于把 Redis 当读写缓存用,会引入额外的并发问题:
- 写+写并发:线程 A 和 B 同时修改同一数据,更新数据库的顺序是 A→B,但更新缓存的顺序可能变成 B→A,导致缓存中是 A 的旧值
- 解决方案:需要引入分布式锁,保证同一资源的修改操作串行执行
删除缓存的好处是简单可靠:不管并发怎么交错,删除后下次读取一定从数据库加载最新值。代价是多了一次缓存缺失和数据库查询。
总结
缓存与数据库一致性问题的核心:
- 读写缓存用同步直写 + 事务保证一致性
- 只读缓存中,新增数据天然一致,删改数据需要处理两步操作的原子性
- 操作失败导致的不一致 → 消息队列 + 重试机制
- 并发导致的不一致 → 延迟双删(先删缓存场景)或接受短暂不一致(先更新数据库场景)
- 推荐"先更新数据库,再删缓存"的操作顺序
没有完美的方案,只有适合业务场景的权衡。对一致性要求极高的场景(如金融交易),可能需要引入分布式事务(2PC、TCC、消息队列事务)来保证强一致。对大多数互联网业务,最终一致性 + 合理的重试机制已经足够。
