1、纯向量检索为什么会答非所问?
1.1 向量检索的工作方式
向量检索(Dense Retrieval)是目前 RAG 系统的主流做法。它的核心思想是:将文档和用户问题都转换成高维数值向量(Embedding),然后通过计算两个向量之间的余弦相似度,找出语义上最接近的文档片段。
用户提问-->Embedding 模型转换为向量-->向量数据库余弦相似度检索-->返回语义最近的TOP-K文档片段-->LLM
1.2 向量检索的问题
向量检索的问题在于,它擅长理解意思相近的内容,却不擅长精确匹配特定词汇。当用户搜索:
-
iPhone 14 Pro Max→ 可能返回所有手机相关文档,而非这款机型的具体参数 -
订单号 ORD-20241201-9527→ 向量模型根本无法理解这串编号的独特性 -
Apache Kafka 2.8.0 版本变更→ 版本号"2.8.0"在语义空间里和"2.7.1"几乎一样近
IMPORTANT
向量模型学到的是语义相似度,而非字符精确性。对于专有名词、产品编号、版本号、人名,纯向量检索的召回率会显著下降,这是结构性缺陷,不是调参能解决的。
2、BM25:经典关键词检索的核心原理
2.1 BM25 是什么
BM25(Best Match 25)是信息检索领域最经典的排序算法之一,也是 Elasticsearch、Lucene 等搜索引擎的默认排序算法。它的名字里的"25"来自算法的第 25 次迭代版本。
一句话类比:BM25 就像图书馆管理员。你说要找"苹果手机",他会扫描所有书的索引,数一数每本书提到"苹果"和"手机"多少次,优先推荐那些反复提到这两个词、且整本书不太厚(避免被长书稀释)的书籍。
BM25 的评分综合三个核心因子:
|---------|-----------------------------------|---------------------|----------------------|
| 因子 | 全称 | 作用 | 举例 |
| TF | Term Frequency(词频) | 词在文档中出现越多,相关性越高 | "苹果"出现 5 次 > 出现 1 次 |
| IDF | Inverse Document Frequency(逆文档频率) | 词在所有文档中越罕见,越有辨别力 | "苹果"比"的"更有价值 |
| 文档长度归一化 | Document Length Normalization | 长文档中词出现多次不一定比短文档更相关 | 防止长文档"霸榜" |
2.2 BM25 公式详解
BM25 的核心得分公式如下:
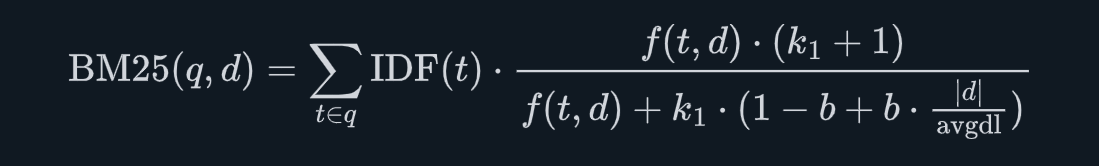
参数说明:
|---------|-------------------|------------|
| 参数 | 含义 | 典型默认值 |
| f(t, d) | 词 t 在文档 d 中的出现次数 | --- |
| |d| | 文档长度(词数) | --- |
| avgdl | 语料库中文档的平均长度 | --- |
| k1 | 词频饱和参数(防止高频词无限加分) | 1.2 ~ 2.0 |
| b | 文档长度归一化系数 | 0.75 |
NOTE
k1 参数引入了"词频饱和"效应:一个词出现 1 次和出现 100 次,给文档带来的加分不是线性增长的,而是越来越慢趋向饱和。这避免了某个词反复堆砌就能刷高分的问题。
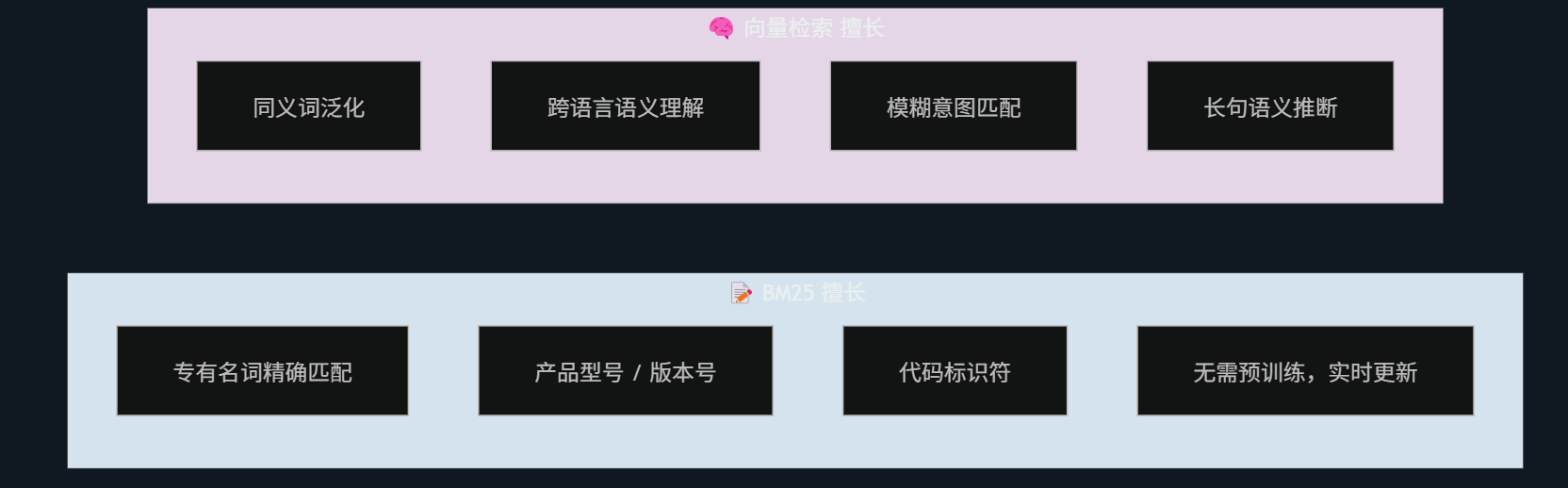
2.3 BM25 vs 向量检索:互补而非替代
3、RRF 算法:公平地融合两路结果
3.1 分数融合的难题
当 BM25 和向量检索各返回了 20 条结果后,我们面临一个棘手的问题:两路的分数不在同一个量纲上。
-
BM25 返回的得分可能是
12.7、8.3、5.1......(无上限) -
向量检索的余弦相似度是
0.93、0.87、0.82......(在 0~1 之间)
直接把这两个分数加权相加(如 0.5 × BM25分 + 0.5 × 向量分)会有严重问题:BM25 分数的绝对量级远大于余弦相似度,导致向量检索的贡献被完全淹没,且需要大量调参和归一化工作。
3.2 RRF 算法:只看排名,不看分数
RRF(Reciprocal Rank Fusion,倒数排名融合)是由滑铁卢大学和 Google 联合研究提出的算法,其核心思想极其优雅:
不管你的原始分数是多少,我只关心你在各自榜单里排第几名。
RRF 对每个文档 d 的最终得分计算公式为:
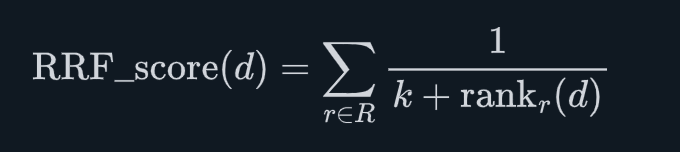
|-----------|---------------------------------|
| 符号 | 含义 |
| R | 所有检索结果列表的集合(这里是 BM25 列表和向量检索列表) |
| rank_r(d) | 文档 d 在列表 r 中的排名(从 1 开始) |
| k | 平滑常数,业界标准值为 60,防止低排名文档得分趋近于 0 |
3.3 用一个例子彻底理解 RRF
假设检索"苹果14 售价",两路各召回 5 条结果:
|-------|-------------------|-------------------|
| 排名 | BM25 结果 | 向量检索结果 |
| 第 1 名 | 文档A(iPhone 14 参数) | 文档C(苹果产品历史) |
| 第 2 名 | 文档B(手机价格比较) | 文档A(iPhone 14 参数) |
| 第 3 名 | 文档C(苹果产品历史) | 文档D(苹果公司财报) |
| 第 4 名 | 文档D(苹果公司财报) | 文档B(手机价格比较) |
| 第 5 名 | 文档E(Android 手机推荐) | 文档E(Android 手机推荐) |
使用 k=60 计算各文档的 RRF 分:
|-----|---------|------|------------------------------|------------|
| 文档 | BM25 排名 | 向量排名 | RRF 得分 | 最终排名 |
| 文档A | 1 | 2 | 1/(60+1) + 1/(60+2) = 0.0321 | 🥇 第 1 |
| 文档C | 3 | 1 | 1/(60+3) + 1/(60+1) = 0.0321 | 🥈 第 1(同分) |
| 文档B | 2 | 4 | 1/(60+2) + 1/(60+4) = 0.0317 | 🥉 第 3 |
| 文档D | 4 | 3 | 1/(60+4) + 1/(60+3) = 0.0317 | 第 4 |
| 文档E | 5 | 5 | 1/(60+5) + 1/(60+5) = 0.0308 | 第 5 |
TIP
文档 A(iPhone 14 参数)在两路结果中都排名靠前,RRF 算法将其综合排名拉到最高,完美体现了"两路都认可的文档更可信"的直觉。k=60 的作用是让第 1 名和第 2 名的得分差距适中,防止排名极度集中。
4、混合检索架构全局视图
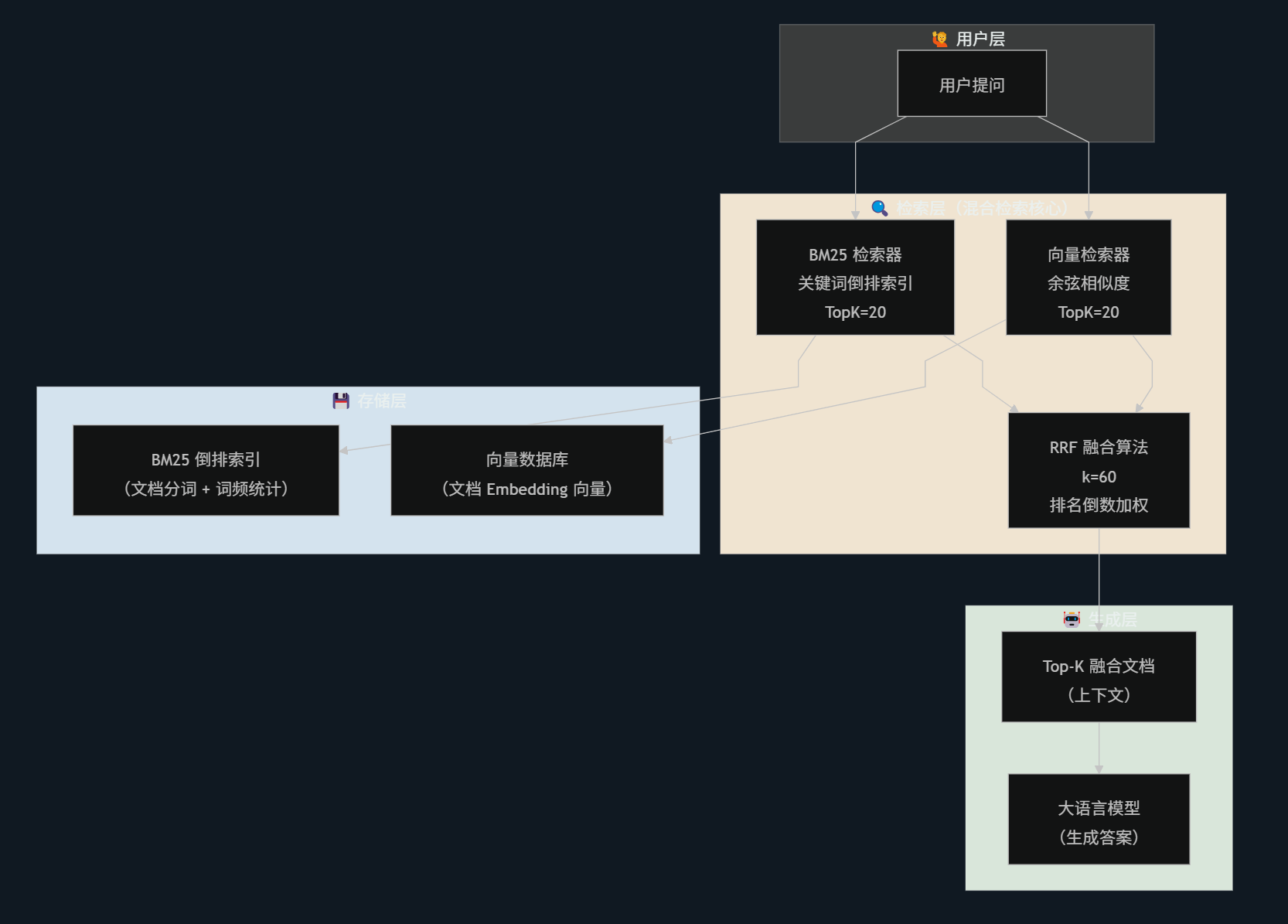
5、最佳实践与调参指南
5.1 topK 与 rrfK 参数如何设置
这两个参数是混合检索中最常调整的,理解其含义能避免踩坑:
|------------|--------------|---------------------|--------------|----------|
| 参数 | 作用 | 过小的问题 | 过大的问题 | 推荐起点 |
| bm25TopK | BM25 侧召回候选数量 | 漏掉关键词相关文档 | 噪声增加,后续重排负担重 | 20 |
| vectorTopK | 向量侧召回候选数量 | 漏掉语义相关文档 | 同上 | 20 |
| rrfK | RRF 平滑常数 | 结果过度集中于两路都排名 #1 的文档 | 低排名噪声文档得分变高 | 60(业界标准) |
TIP
bm25TopK 和 vectorTopK 的值建议设为最终返回文档数的 4~5 倍。例如你想最终给大模型 5 条上下文,那两路各召回 20 条,经 RRF 融合后取前 5,这样有足够的候选池来保证质量。
5.2 常见错误:不做去重直接合并
❌ 错误做法:直接将两路结果简单拼接,不经过 RRF 或去重
// ❌ 错误:两路各 20 条,合并后 40 条全塞给大模型
List<TextSegment> bm25Results = bm25.retrieve(query);
List<TextSegment> vectorResults = vector.retrieve(query);
List<TextSegment> combined = new ArrayList<>();
combined.addAll(bm25Results);
combined.addAll(vectorResults); // 可能包含大量重复文档,且未按质量排序
✅ 正确做法:通过 hybridContentRetriever(ContentRetriever Bean)统一调用,RRF 自动处理去重与排序
// ✅ 正确:hybridContentRetriever 内部完成两路召回 + RRF 融合 + 去重
List<Content> results = hybridContentRetriever.retrieve(Query.from(userQuery));
// results 已按 RRF 分数降序排列,无重复文档