上一篇: AI医疗分诊与健康咨询助手agent开发------(1)从零搭建SpringBoot与AI对话系统:后端骨架 + 前端对话页 + SSE流式输出
前面搞定了基础对话,但AI回的话没法直接用------它给了一些建议,初步建议该挂什么科,还会说头疼的问题有很多。如果没有约束规则,AI甚至还会"建议你吃XXX药"。这哪行?
医疗场景下,AI自由发挥太危险了。用户输入"胸口疼",AI可能回一段500字的健康科普,也可能直接告诉你"可能是心梗,建议服用阿司匹林"。前者没用,后者要命。
所以这一篇,我主要解决两个问题:让AI输出结构化JSON ,以及在AI前后加上安全网。顺带把多轮追问也做了**(分诊的功能**),因为用户只说"头疼"你就推荐科室,也太草率了。
一、让AI输出结构化JSON
为什么需要结构化输出
AI返回自然语言,前端没法用。你说"建议挂心内科",前端要展示什么?科室标签、紧急程度标签、置信度进度条......这些都需要结构化字段。
更关键的是,自然语言没法做规则判断。你没法从一段话里可靠地提取"这个用户是不是急症"。结构化输出是后续所有逻辑的基础。
TriageResponse的设计
这是最终返回给前端的结构体:
java
@Data @Builder
public class TriageResponse {
private boolean needEmergency; // 是否需要急诊
private String urgencyLevel; // IMMEDIATE/URGENT/OUTPATIENT/OBSERVATION
private String primaryDepartment; // 首选科室
private List<String> alternativeDepartments; // 备选科室
private double confidenceScore; // 0-1置信度
private boolean needClarification; // 是否需要追问
private List<String> clarificationQuestions; // 追问问题列表
private String reasoningSummary; // 推理过程简述
private List<String> preparationAdvice; // 就诊前准备建议
private List<String> warningSigns; // 需警惕的危险信号
private String disclaimer; // 免责声明
private String sessionId; // 会话ID
private String stage; // 当前阶段
private int clarificationRound; // 当前追问轮次
}字段不少,但每个都有用。needEmergency和urgencyLevel决定前端是弹红色警告还是普通展示;needClarification和clarificationQuestions驱动追问流程;confidenceScore让前端知道这个推荐靠不靠谱。
紧急程度分4级,从轻到重:
- OBSERVATION(观察):症状轻微,可以先自己观察观察,比如偶尔轻微头痛
- OUTPATIENT(门诊):建议去门诊看看,不紧急,比如持续头痛伴恶心
- URGENT(急诊):建议去急诊,比如剧烈头痛伴呕吐
- IMMEDIATE(立即急救):别犹豫了,直接打120,比如胸痛+呼吸困难
注意没有"EMERGENCY"这个级别------急症不是紧急程度的一个级别,而是一种特殊状态,命中急症规则后会直接走急症流程,不走分诊。
Prompt怎么约束AI返回JSON
核心就是在System Prompt里硬性规定输出格式,然后给一个示例:
你必须返回严格的JSON格式,不要包含任何其他文字。
返回格式如下:
{
"needEmergency": boolean,
"urgencyLevel": "IMMEDIATE|URGENT|OUTPATIENT|OBSERVATION",
"primaryDepartment": "科室名称",
...
}听起来很美好对吧?实际跑起来就知道,AI根本不老实。
IntakeAgent的Prompt核心约束
举个小例子,IntakeAgent的Prompt核心约束长这样:
typescript
/**
* IntakeAgent系统提示词
*/
@Bean
public String intakeAgentPrompt() {
return """
你是一名专业的医疗接诊助手。你的任务是收集患者的症状信息,判断信息是否充分。
【需要收集的信息项及权重】
| 信息项 | 权重 | 优先级 | 说明 |
|--------|------|--------|------|
| 主要不适部位和具体感受 | 25% | 必须 | 如"头痛""胸口闷" |
| 症状持续时间 | 20% | 必须 | 如"3天""2小时" |
| 症状严重程度 | 20% | 必须 | 如"轻微""剧烈""影响睡眠" |
| 伴随症状 | 15% | 必须 | 如"伴恶心""伴发热" |
| 年龄和性别 | 10% | 重要 | 影响科室倾向 |
| 既往病史 | 5% | 参考 | 相关慢性病史 |
| 近期用药情况 | 5% | 参考 | 当前服用的药物 |
【infoCompleteness计算规则】
根据用户已提供的信息,按权重累加得分:
- 该信息项已明确提供 → 加该项满分权重
- 该信息项部分提供(如只说"头痛"没说具体感受) → 加该项一半权重
- 该信息项未提供 → 加0
最终得分为各项累加之和,即为infoCompleteness值。
示例:用户说"我头痛3天了,有点恶心"
- 部位(25%) + 持续时间(20%) + 伴随症状(15%) = 0.60
- 严重程度未提供(0) + 年龄性别未提供(0) + 既往病史未提供(0) + 用药未提供(0)
- infoCompleteness = 0.60
【infoCompleteness分档】
- 0.8-1.0: 核心信息齐全,可以进行分诊,needClarification=false
- 0.5-0.8: 缺少部分核心信息,需追问1-2个问题,needClarification=true
- 0.0-0.5: 核心信息严重不足,需追问关键问题,needClarification=true
【输出要求】
请严格按照以下JSON格式返回,不要包含任何其他文字:
{
"infoCompleteness": 0.0-1.0,
"needClarification": false,
"missingInfo": ["缺失的信息项名称"],
"clarificationQuestions": ["追问的问题"],
"symptomSummary": "标准化后的症状描述"
}
【追问规则】
- 每次最多生成2个追问问题
- 优先追问权重最高的缺失项(严重程度 > 持续时间 > 伴随症状 > 年龄性别 > 既往病史 > 近期用药情况)
- 患者已经提供的信息、已经回答的问题,不要重复问
- 不要问跟症状无关的隐私
【绝对红线】
- 绝不猜测或暗示疾病名称
- 绝不建议药物或治疗方案
- 绝不用"你可能得了..."这种话
请用中文回复。
""";
}你看,Prompt里把"必须做什么"和"绝对不能做什么"写得清清楚楚。AI就像个实习生,你不说清楚它就乱来。
踩坑:AI返回的JSON经常格式不对
【其实这里已经再提示词中对AI进行约束,告诉AI要返回什么格式的,但是为了避免AI不按要求来,还是要用StructuredOutputParser容错进行兜底】
这是我遇到的三种典型情况:
1. 被Markdown代码块包裹
AI返回的是:
根据症状分析,建议如下:
```json
{"needEmergency": false, ...}
前面带一段废话,JSON还被` ```json ````包着。直接用ObjectMapper解析必炸。2. 缺少字段
AI有时候会"自作主张"省略它觉得不重要的字段,比如alternativeDepartments直接不返回。Jackson默认遇到null字段会报错。
3. 直接返回自然语言
偶尔AI完全不按格式来,直接回一句"根据您的症状,建议您前往神经内科就诊"。连JSON的影子都没有。
StructuredOutputParser的容错策略
针对上面的问题,我写了一个解析器,策略是:提取 -> 解析 -> 填充默认值 -> 兜底。
java
/**
* 结构化输出解析器
* 将AI模型输出解析为结构化分诊响应
*/
@Component
public class StructuredOutputParser {
private static final Logger log = LoggerFactory.getLogger(StructuredOutputParser.class);
private final ObjectMapper objectMapper;
//ObjectMapper要配置成忽略未知属性、允许缺失字段:
public StructuredOutputParser() {
this.objectMapper = new ObjectMapper();
this.objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
}
/**
* 将AI模型响应解析为TriageResponse
*
* @param aiOutput AI模型原始输出
* @return 解析后的TriageResponse或降级响应
*/
public TriageResponse parse(String aiOutput) {
if (aiOutput == null || aiOutput.isBlank()) {
log.warn("AI output is null or blank, returning low confidence fallback");
return TriageResponse.lowConfidenceFallback("AI模型返回为空,建议前往全科门诊就诊。");
}
try {
// 尝试从输出中提取JSON
String json = extractJson(aiOutput);
if (json == null) {
log.warn("No JSON found in AI output, returning low confidence fallback");
return TriageResponse.lowConfidenceFallback("AI模型返回格式异常,建议前往全科门诊就诊。");
}
// 解析JSON
TriageResponse response = objectMapper.readValue(json, TriageResponse.class);
// 验证并设置默认值
return validateAndSetDefaults(response);
} catch (JsonProcessingException e) {
log.error("Failed to parse AI output as JSON: {}", e.getMessage());
return TriageResponse.lowConfidenceFallback("AI模型返回JSON解析失败,建议前往全科门诊就诊。");
} catch (Exception e) {
log.error("Unexpected error parsing AI output: {}", e.getMessage(), e);
return TriageResponse.lowConfidenceFallback("处理AI模型响应时发生异常,建议前往全科门诊就诊。");
}
}
/**
* 从AI输出中提取JSON字符串
* 处理JSON被markdown代码块或其他文本包裹的情况
*/
public String extractJson(String output) {
// 首先尝试在代码块中查找JSON
Pattern codeBlockPattern = Pattern.compile("```(?:json)?\\s*\\n?(\\{[\\s\\S]*?\\})\\s*\\n?```");
Matcher codeBlockMatcher = codeBlockPattern.matcher(output);
if (codeBlockMatcher.find()) {
return codeBlockMatcher.group(1);
}
// 尝试直接查找JSON对象
Pattern jsonPattern = Pattern.compile("\\{[\\s\\S]*\\}");
Matcher jsonMatcher = jsonPattern.matcher(output);
if (jsonMatcher.find()) {
return jsonMatcher.group();
}
return null;
}
/**
* 验证并为缺失字段设置默认值
*/
private TriageResponse validateAndSetDefaults(TriageResponse response) {
// 如果缺少免责声明则设置默认值
if (response.getDisclaimer() == null || response.getDisclaimer().isBlank()) {
response.setDisclaimer("本系统仅提供就诊方向参考,不构成医疗诊断。");
}
// 如果缺少状态则设置默认值
if (response.getStatus() == null || response.getStatus().isBlank()) {
response.setStatus("success");
}
// 验证紧急程度
if (response.getUrgencyLevel() == null || response.getUrgencyLevel().isBlank()) {
response.setUrgencyLevel("OUTPATIENT");
} else {
String level = response.getUrgencyLevel().toUpperCase();
if (!List.of("OBSERVATION", "OUTPATIENT", "URGENT", "IMMEDIATE").contains(level)) {
// 非法值,降级为门诊
response.setUrgencyLevel("OUTPATIENT");
} else {
response.setUrgencyLevel(level);
}
}
// 验证置信度分数
if (response.getConfidenceScore() < 0 || response.getConfidenceScore() > 1) {
response.setConfidenceScore(0.5);
}
// 如果缺少主推科室则设置默认值
if (response.getPrimaryDepartment() == null || response.getPrimaryDepartment().isBlank()) {
response.setPrimaryDepartment("全科门诊");
}
// 如果列表为null则设置默认空列表
if (response.getAlternativeDepartments() == null) {
response.setAlternativeDepartments(new ArrayList<>());
}
if (response.getClarificationQuestions() == null) {
response.setClarificationQuestions(new ArrayList<>());
}
if (response.getPreparationAdvice() == null) {
response.setPreparationAdvice(new ArrayList<>());
}
if (response.getWarningSigns() == null) {
response.setWarningSigns(new ArrayList<>());
}
return response;
}
}这里有个细节:ObjectMapper要配置成忽略未知属性、允许缺失字段:
java
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);不然AI多返回一个你没定义的字段,解析直接报错。
lowConfidenceFallback()返回一个置信度为0.3的兜底结果,前端看到低置信度会提示用户"建议重新描述症状"。总比页面报错强。
java
/**
* 创建低置信度降级响应(默认兜底)
*/
public static TriageResponse lowConfidenceFallback(String reasoningSummary) {
return TriageResponse.builder()
.needEmergency(false)
.urgencyLevel("OUTPATIENT")
.primaryDepartment("全科门诊")
.alternativeDepartments(List.of())
.confidenceScore(0.3)
.needClarification(false)
.clarificationQuestions(List.of())
.reasoningSummary(reasoningSummary)
.preparationAdvice(List.of("建议携带既往病历资料", "记录症状发作时间"))
.warningSigns(List.of("症状加重", "出现新症状"))
.disclaimer("本系统仅提供就诊方向参考,不构成医疗诊断。")
.status("success")
.build();
}二、急症规则------AI之前的安全网
为什么规则要在AI前面
AI慢。一次API调用少说1-2秒,多的话5-6秒。用户输入"意识不清、大出血",你还要等AI返回JSON再判断是不是急症?人命等不起。
所以我的方案是:规则引擎在前,AI在后。用户输入先过规则引擎,命中急症关键词就直接返回,根本不调AI。只有规则引擎没命中的,才走AI分诊。
EmergencyRuleService设计
规则分两类:单关键词和组合关键词。【这里先用硬编码的形式,先看到效果,后续肯定是要有一个类似知识库的东西,不能直接再代码中写死!!】
java
/**
* 急症规则服务
* 在调用AI模型前检查急症症状
*/
@Service
public class EmergencyRuleService {
private static final Logger log = LoggerFactory.getLogger(EmergencyRuleService.class);
/**
* 急症规则模式
* 每个条目包含必须全部出现才能触发的关键词列表
*/
private static final List<List<String>> EMERGENCY_RULES = List.of(
// 胸痛 + 呼吸困难
List.of("胸痛", "呼吸困难"),
List.of("胸口疼", "喘不过气"),
List.of("胸闷", "气短"),
List.of("心口疼", "呼吸困难"),
// 意识不清
List.of("意识不清"),
List.of("昏迷"),
List.of("失去意识"),
List.of("晕倒"),
List.of("晕厥"),
// 大出血
List.of("大出血"),
List.of("出血不止"),
List.of("血流不止"),
List.of("大量出血"),
// 自杀倾向
List.of("自杀"),
List.of("不想活"),
List.of("轻生"),
List.of("想死"),
// 剧烈头痛 + 肢体无力
List.of("剧烈头痛", "肢体无力"),
List.of("头痛剧烈", "手脚无力"),
List.of("头疼厉害", "无力"),
// 剧烈腹痛 + 持续呕吐
List.of("剧烈腹痛", "持续呕吐"),
List.of("肚子剧痛", "呕吐不止"),
List.of("腹痛剧烈", "一直吐"),
// 心脏相关急症
List.of("心脏骤停"),
List.of("心肺复苏"),
List.of("心梗"),
List.of("心肌梗塞"),
// 中风症状
List.of("中风"),
List.of("脑梗"),
List.of("脑出血"),
List.of("口角歪斜"),
List.of("言语不清", "肢体无力"),
// 过敏性休克
List.of("过敏性休克"),
List.of("过敏", "呼吸困难"),
List.of("过敏", "休克"),
// 其他急症
List.of("高热", "抽搐"),
List.of("体温", "40"),
List.of("高烧", "抽搐"),
List.of("触电"),
List.of("溺水"),
List.of("中毒"),
List.of("窒息")
);
/**
* 单关键词急症触发器
*/
private static final List<String> SINGLE_KEYWORD_EMERGENCIES = List.of(
"心脏骤停",
"心肺复苏",
"自杀",
"轻生",
"不想活",
"想死",
"触电",
"溺水",
"中毒",
"窒息",
"大出血",
"出血不止"
);
/**
* 检查消息是否包含急症症状
*
* @param message 患者症状描述
* @return 包含是否检测到急症及原因的EmergencyCheckResult
*/
public EmergencyCheckResult checkEmergency(String message) {
if (message == null || message.isBlank()) {
return EmergencyCheckResult.noEmergency();
}
String lowerMessage = message.toLowerCase();
// 首先检查单关键词急症
for (String keyword : SINGLE_KEYWORD_EMERGENCIES) {
if (lowerMessage.contains(keyword.toLowerCase())) {
log.warn("Emergency detected with single keyword: {}", keyword);
return EmergencyCheckResult.emergency(
"检测到急症关键词:" + keyword + "。请立即拨打120或前往最近的急诊科!"
);
}
}
// 检查多关键词急症
for (List<String> rule : EMERGENCY_RULES) {
boolean allMatch = rule.stream()
.allMatch(keyword -> lowerMessage.contains(keyword.toLowerCase()));
if (allMatch) {
log.warn("Emergency detected with rule: {}", rule);
return EmergencyCheckResult.emergency(
"检测到急症症状组合:" + String.join("、", rule) + "。请立即拨打120或前往最近的急诊科!"
);
}
}
return EmergencyCheckResult.noEmergency();
}
/**
* 急症检查结果
*/
public static class EmergencyCheckResult {
private final boolean isEmergency;
private final String message;
private EmergencyCheckResult(boolean isEmergency, String message) {
this.isEmergency = isEmergency;
this.message = message;
}
public static EmergencyCheckResult emergency(String message) {
return new EmergencyCheckResult(true, message);
}
public static EmergencyCheckResult noEmergency() {
return new EmergencyCheckResult(false, null);
}
public boolean isEmergency() {
return isEmergency;
}
public String getMessage() {
return message;
}
}
}为什么要有组合关键词?因为"胸痛"单独出现不一定急症,可能是肌肉拉伤;但"胸痛"+"呼吸困难"同时出现,大概率是心肺问题,必须按急症处理。
命中后直接返回,不调AI。响应时间从2秒降到2毫秒。
在Orchestrator中的调用顺序
java
/**
* 输入:用户消息 + 会话上下文
* 输出:是否急症、信息完整度、追问问题、症状摘要
* @param input Agent输入
* @return
*/
@Override
public IntakeOutput execute(IntakeInput input) {
long startTime = System.currentTimeMillis();
String inputSummary = "用户消息: " + truncate(input.getUserMessage(), 100);
try {
// Step 1: 先用规则检查急症(不调AI,速度快)
EmergencyRuleService.EmergencyCheckResult emergencyResult =
emergencyRuleService.checkEmergency(input.getUserMessage());
if (emergencyResult.isEmergency()) {
log.warn("[IntakeAgent] 急症检测命中: {}", emergencyResult.getMessage());
IntakeOutput output = IntakeOutput.builder()
.emergencyDetected(true)
.emergencyMessage(emergencyResult.getMessage())
.needClarification(false)
.infoCompleteness(1.0)
.symptomSummary(input.getUserMessage())
.build();
recordTrace(inputSummary, "急症检测命中", startTime, true, null);
return output;
}
// Step 2: 调用AI判断信息完整度
log.info("[IntakeAgent] 调用AI判断信息完整度");
String contextSummary = buildContextForIntake(input.getSession(), input.getUserMessage());
String aiOutput = aiChatClient.chat(intakePrompt, contextSummary);
// Step 3: 解析AI输出
IntakeOutput output = parseIntakeOutput(aiOutput, input.getUserMessage());
log.info("[IntakeAgent] 信息完整度: {}, 需要追问: {}",
output.getInfoCompleteness(), output.isNeedClarification());
recordTrace(inputSummary,
String.format("完整度:%.2f, 追问:%s", output.getInfoCompleteness(), output.isNeedClarification()),
startTime, true, null);
return output;
} catch (Exception e) {
log.error("[IntakeAgent] 执行异常: {}", e.getMessage(), e);
IntakeOutput fallback = IntakeOutput.builder()
.emergencyDetected(false)
.needClarification(false)
.infoCompleteness(0.5)
.symptomSummary(input.getUserMessage())
.build();
recordTrace(inputSummary, "执行异常: " + e.getMessage(), startTime, false, e.getMessage());
return fallback;
}
}这个顺序很重要。规则引擎是第一道防线,AI是第二道。千万别反过来。
三、安全过滤------AI说了不该说的怎么办
禁词列表
AI有时候会"越界",输出一些医疗场景下不该说的话。我列了一个禁词表:
- 诊断类:"确诊"、"诊断为"、"你患有"
- 处方类:"建议服用"、"处方"、"用药"
- 药物剂量类:"mg"、"ml"(在药物上下文中)
- 治疗方案类:"治疗方案"、"手术方式"
validateResponse方法
AI返回结果后,过一遍安全过滤**【这里先用硬编码的形式,后续会优化!!】**:
java
/**
* 安全过滤:检查并替换禁止内容
*/
private TriageResponse validateResponse(TriageResponse response) {
// 安全过滤:将禁止内容替换为安全表述,而非整段丢弃
String summary = response.getReasoningSummary();
if (summary != null) {
String filtered = sanitizeText(summary);
if (!filtered.equals(summary)) {
log.warn("[TriageAgent] reasoningSummary包含禁止内容,已替换为安全表述");
response.setReasoningSummary(filtered);
}
}
if (response.getPreparationAdvice() != null) {
response.setPreparationAdvice(response.getPreparationAdvice().stream()
.map(this::sanitizeText)
.toList());
}
if (response.getWarningSigns() != null) {
response.setWarningSigns(response.getWarningSigns().stream()
.map(this::sanitizeText)
.toList());
}
return response;
}
/**
* 将文本中的禁止内容替换为安全表述,保留其余内容不变
*/
private String sanitizeText(String text) {
if (text == null) return null;
// 诊断性表述 → 安全替代
text = text.replaceAll("确诊为(.+?)([,。,\\.\\s]|$)", "症状与$1相关,请就医确认$2");
text = text.replaceAll("诊断为(.+?)([,。,\\.\\s]|$)", "症状提示$1可能,请就医确认$2");
text = text.replaceAll("你可能得了(.+?)([,。,\\.\\s]|$)", "症状可能与$1相关,请就医确认$2");
text = text.replaceAll("你患有(.+?)([,。,\\.\\s]|$)", "存在$1相关症状,请就医确认$2");
text = text.replaceAll("你患了(.+?)([,。,\\.\\s]|$)", "出现$1相关症状,请就医确认$2");
text = text.replaceAll("你患的是(.+?)([,。,\\.\\s]|$)", "症状与$1相关,请就医确认$2");
text = text.replaceAll("这是(.+?)病的症状", "这些症状与$1相关");
// 处方性表述 → 安全替代
text = text.replaceAll("建议服用(.+?)([,。,\\.\\s]|$)", "请咨询医生是否需要使用$1$2");
text = text.replaceAll("推荐药物[::]?(.+?)([,。,\\.\\s]|$)", "请咨询医生关于$1等药物的使用$2");
text = text.replaceAll("用量[为是]?(.+?)([,。,\\.\\s]|$)", "具体用量请遵医嘱$2");
text = text.replaceAll("剂量[为是]?(.+?)([,。,\\.\\s]|$)", "具体剂量请遵医嘱$2");
text = text.replaceAll("处方[::]?(.+?)([,。,\\.\\s]|$)", "请咨询医生获取处方$2");
text = text.replaceAll("建议吃(.+?)([,。,\\.\\s]|$)", "请咨询医生是否需要服用$1$2");
text = text.replaceAll("服用(\\d+\\.?\\d*)(mg|ml)", "遵医嘱使用$1$2");
// 用药频率与周期 → 安全替代
text = text.replaceAll("(每[日天][\\d一两三四五六七八九十1234567890]+次)", "用药频率请遵医嘱");
text = text.replaceAll("(连续[\\d一两三四五六七八九十1234567890]+天)", "用药周期请遵医嘱");
// 治疗方案 → 安全替代
text = text.replaceAll("建议手术", "请咨询医生是否需要手术治疗");
text = text.replaceAll("治疗方案[::]?(.+?)([,。,\\.\\s]|$)", "请咨询医生制定治疗方案$2");
text = text.replaceAll("需要做(.+?)治疗", "请咨询医生是否需要$1治疗");
return text;
}命中禁词后怎么处理?不是直接拦截,而是替换成安全表述。比如"确诊为高血压"改成"症状与高血压相关,请就医确认"。
免责声明自动追加
不管AI输出什么,所有回复必须带免责声明。这不是可选的,是必须的:
java
private static final String DISCLAIMER_TEXT =
"本系统仅提供分诊建议,不构成医疗诊断。请以医生面诊结果为准。如有紧急情况,请立即拨打120。";
// 构建TriageResponse时始终追加
.disclaimer(DISCLAIMER_TEXT)踩坑:AI会绕过禁词
这是最头疼的。你禁了"确诊",AI改成"你的症状与XXX相符";你禁了"建议服用",AI改成"临床上常使用XXX来缓解此类症状"。
单纯的关键词匹配根本防不住。AI太聪明了,它会换着法子表达同一个意思。
我目前的做法是两层防御:
- 关键词过滤:拦截最明显的违规表述
- Prompt约束:在System Prompt里反复强调"你只能提供分诊建议,不能给出诊断、处方或治疗建议"
第二层其实更有效。与其事后过滤,不如从源头减少违规输出。但也不能完全依赖Prompt,所以两层都要有。
- 后续考虑其他方面的的优化【关键词(快速过滤)+ Embedding(语义兜底)+ LLM(人工审核辅助】,用另一个AI来判断输出是否违规。
- 但那是后话了,当前的关键词+Prompt方案先顶着。
- 后续可能是,先预想一下:
- 将硬编码正则提取到YAML配置文件,支持热更新
- 引入数据库+本地缓存,建立规则管理后台
- 接入语义识别,建立完整的安全过滤服务体系
- 人工兜底?
四、多轮追问------信息不足别急着给结论
为什么需要追问
用户说"头疼",你就推荐神经内科?太草率了。头疼的原因多了去了------偏头痛、颈椎病、高血压、脑部病变......没有更多信息,推荐什么科室都不靠谱。
所以当信息不够的时候,系统应该追问,而不是硬着头皮给结论。
信息完整度怎么算
那"信息够不够"怎么判断?我定义了7项核心信息,每项有个权重:
| 信息项 | 权重 | 优先级 | 说明 |
|---|---|---|---|
| 主要不适部位和具体感受 | 25% | 必须 | 如"头痛""胸口闷" |
| 症状持续时间 | 20% | 必须 | 如"3天""2小时" |
| 症状严重程度 | 20% | 必须 | 如"轻微""剧烈""影响睡眠" |
| 伴随症状 | 15% | 必须 | 如"伴恶心""伴发热" |
| 年龄和性别 | 10% | 重要 | 影响科室倾向 |
| 既往病史 | 5% | 参考 | 相关慢性病史 |
| 近期用药情况 | 5% | 参考 | 当前服用的药物 |
举个例子:用户只说了"头疼",那只有主要不适0.25分,完整度0.25,远低于0.6阈值,必须追问。用户说"头疼两天了,有点恶心",部位(25%) + 持续时间(20%) + 伴随症状(15%) = 0.60,大于等于0.6了,可以分诊了。
不过这个计算不是硬编码的,是让AI自己评估的。0.6阈值是硬性条件------AI说不够但完整度已经到0.7了,那就直接分诊,不再追问。
ConsultationSession会话模型
java
/**
* 会话模型实体类
* 表示一个完整的问诊会话及其历史记录
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ConsultationSession {
/**
* 会话唯一标识
*/
private String sessionId;
/**
* 当前问诊阶段
*/
private ConsultationStage stage;
/**
* 追问轮次(0-3)
*/
private int clarificationRound;
/**
* 最大追问轮次
*/
private static final int MAX_CLARIFICATION_ROUNDS = 3;
/**
* 消息历史记录
*/
private List<ConsultationMessage> messages;
/**
* 症状摘要
*/
private String symptomSummary;
/**
* 信息完整度(0.0-1.0)
*/
private double infoCompleteness;
/**
* 缺失信息列表
*/
private List<String> missingInfo;
/**
* 标准化症状摘要
*/
private String normalizedSummary;
/**
* 是否检测到急症
*/
private boolean emergencyDetected;
/**
* 急症关键词列表
*/
private List<String> emergencyKeywords;
/**
* 会话创建时间
*/
private LocalDateTime createdAt;
/**
* 最后更新时间
*/
private LocalDateTime updatedAt;
/**
* 创建新会话
*/
public static ConsultationSession createNew() {
LocalDateTime now = LocalDateTime.now();
return ConsultationSession.builder()
.sessionId(UUID.randomUUID().toString())
.stage(ConsultationStage.INTAKE)
.clarificationRound(0)
.messages(new ArrayList<>())
.symptomSummary("")
.infoCompleteness(0.0)
.missingInfo(new ArrayList<>())
.normalizedSummary("")
.emergencyDetected(false)
.emergencyKeywords(new ArrayList<>())
.createdAt(now)
.updatedAt(now)
.build();
}
/**
* 添加消息到会话
*/
public void addMessage(ConsultationMessage message) {
if (messages == null) {
messages = new ArrayList<>();
}
messages.add(message);
updatedAt = LocalDateTime.now();
}
/**
* 检查是否可以继续追问
*/
public boolean canAskClarification() {
return clarificationRound < MAX_CLARIFICATION_ROUNDS;
}
/**
* 增加追问轮次
*/
public void incrementClarificationRound() {
clarificationRound++;
}
/**
* 重置追问轮次(分诊完成后调用,允许新一轮追问)
*/
public void resetClarificationRound() {
clarificationRound = 0;
}
/**
* 获取格式化的对话历史
*/
public String getFormattedHistory() {
if (messages == null || messages.isEmpty()) {
return "";
}
StringBuilder sb = new StringBuilder();
for (ConsultationMessage msg : messages) {
sb.append(msg.getRole()).append(": ").append(msg.getContent()).append("\n");
}
return sb.toString();
}
/**
* 获取最近N条消息用于上下文
*/
public List<ConsultationMessage> getLastMessages(int n) {
if (messages == null || messages.isEmpty()) {
return new ArrayList<>();
}
int start = Math.max(0, messages.size() - n);
return new ArrayList<>(messages.subList(start, messages.size()));
}
}会话阶段用枚举定义:
java
/**
* 会话阶段枚举
* 表示医疗问诊的当前阶段
*/
public enum ConsultationStage {
/**
* 初始问诊 - 收集症状信息
*/
INTAKE,
/**
* 追问阶段 - 询问补充问题
*/
CLARIFICATION,
/**
* 分诊完成 - 提供科室推荐
*/
TRIAGE,
/**
* 急症 - 检测到紧急症状
*/
EMERGENCY,
/**
* 问诊结束
*/
COMPLETED
}追问轮次控制
在Orchestrator里,判断要不要追问的逻辑:
java
// 分支2: 追问流程(信息完整度低于阈值且AI建议追问且追问次数未达上限)
double COMPLETENESS_THRESHOLD = 0.6;
boolean infoInsufficient = intakeOutput.getInfoCompleteness() < COMPLETENESS_THRESHOLD
|| intakeOutput.isNeedClarification();
if (infoInsufficient && session.canAskClarification()) {
log.info("[Orchestrator] 信息不足,进入追问流程");
session.incrementClarificationRound();
sessionContextService.updateStage(session, ConsultationStage.CLARIFICATION);
TriageResponse response = TriageResponse.builder()
.needEmergency(false)
.urgencyLevel("OBSERVATION")
.primaryDepartment("待定")
.alternativeDepartments(new ArrayList<>())
.confidenceScore(intakeOutput.getInfoCompleteness())
.needClarification(true)
.clarificationQuestions(intakeOutput.getClarificationQuestions())
.reasoningSummary("信息不足,需要进一步了解症状详情")
.preparationAdvice(new ArrayList<>())
.warningSigns(new ArrayList<>())
.disclaimer("本系统仅提供就诊方向参考,不构成医疗诊断。")
.status("success")
.build();
response.setAgentTrace(traces);
setSessionInfo(response, session);
// 记录助手消息
String assistantContent = String.join("; ", intakeOutput.getClarificationQuestions());
sessionContextService.addAssistantMessage(session, assistantContent);
log.info("========== Agent编排完成(追问流程) ==========");
return response;
}
// 分支3: 信息不足但追问已达上限,强制分诊
if (infoInsufficient && !session.canAskClarification()) {
log.info("[Orchestrator] 追问已达上限,强制进入分诊");
}注意这里的判断条件是两个都要看 :完整度阈值是硬性判断,AI的needsMoreInfo是软性判断。
| 条件 | completeness < 0.6 | isNeedClarification | 结果 |
|---|---|---|---|
| 场景1 | ✔ true | ✗ false | infoInsufficient = true → 进入追问 |
| 场景2 | ✗ false (≥0.6) | ✔ true | infoInsufficient = true → 进入追问 |
| 场景3 | ✗ false (≥0.6) | ✗ false | infoInsufficient = false → 不追问, 直接分诊 |
-
即使 completeness ≥ 0.6,只要 AI 返回 isNeedClarification=true,且追问次数还没用完,就会继续追问。这意味着追问并不是固定3次,而是受两个因素共同控制:
- AI 自身判断 --- isNeedClarification 是否为 true
- 追问上限 --- session.canAskClarification() 是否还有余额
-
举个例子:
- 如果第1次 completeness 就达到 0.8 且 isNeedClarification=false,那就直接跳过追问,进入分诊,不会强制追问3次。
- 反过来,如果 AI 每次都返回 isNeedClarification=true,那就会一直追问直到达到上限才强制分诊(分支3)。
-
为什么要用COMPLETENESS_THRESHOLD = 0.6这个硬性阈值?又为什么要设置追问次数上限?接着看踩坑。
踩坑:AI几乎总是返回needsMoreInfo=true
这是个大坑。你问AI"信息够不够",它几乎永远说"不够,再问问吧"。因为AI天生倾向于想要更多信息------多问一句总比少问一句安全嘛。
但用户体验受不了。用户都说了"头疼、恶心、血压160/100",信息明明够了,AI还说"需要追问:请问头疼持续多久了?"这就过度了。
所以我加了COMPLETENESS_THRESHOLD = 0.6这个硬性阈值。AI说不够,但完整度已经到0.7了,那就直接分诊,不再追问。AI的建议是参考,不是圣旨。
追问技巧
追问不是随便问的,问得好用户愿意配合,问得不好用户直接关页面。几个实操技巧:
-
用选择题代替开放题。"头痛是持续性的还是间歇性的?"比"头痛是什么样的?"好回答多了。开放题用户不知道说什么,选择题点一下就行。
-
结合已知信息追问。用户提到"血压偏高",那就问"请问目前是否在服用降压药?"------这比干巴巴问"您在吃什么药?"有针对性得多。
-
关注时间维度。"症状是从什么时候开始的?持续了多久?"------时间信息对分诊特别重要,急性发作和慢性反复完全是两码事。
-
绝不诱导性提问。不能问"是不是心脏不舒服?",这会引导用户朝特定方向描述。应该问"除了胸痛,还有没有其他不舒服?",让用户自己说。
踩坑:分诊完成后clarificationRound没重置
这里先分享一下分诊提示词,这篇文章分诊我说的很少,具体业务到下一篇章再去更新吧(到时候3agent编排一起说更清晰)
java
@Bean
public String triageAgentPrompt() {
return """
你是一名专业的医疗分诊助手。请根据用户描述的症状,返回结构化的分诊建议。
【重要规则】
1. 不要进行疾病诊断,只提供就诊方向建议
2. 不要开具处方或推荐具体药物
3. 不要提供药物剂量
4. 不要使用"你可能得了某某病"这样的表述
5. 只推荐科室,不推荐具体医生
6. 你是在信息已充分的情况下被调用的,needClarification 必须为 false,clarificationQuestions 必须为空数组,不要追问
【输出要求】
请严格按照以下JSON格式返回,不要包含任何其他文字:
{
"needEmergency": false,
"urgencyLevel": "OUTPATIENT",
"primaryDepartment": "推荐的科室",
"alternativeDepartments": ["备选科室1", "备选科室2"],
"confidenceScore": 0.7,
"needClarification": false,
"clarificationQuestions": [],
"reasoningSummary": "分析原因",
"preparationAdvice": ["建议1", "建议2"],
"warningSigns": ["警示症状1", "警示症状2"],
"disclaimer": "本系统仅提供就诊方向参考,不构成医疗诊断。"
}
【urgencyLevel取值说明】
- IMMEDIATE: 立即拨打120急救
- URGENT: 建议急诊就诊
- OUTPATIENT: 建议门诊就诊
- OBSERVATION: 症状轻微,可自行观察
请用中文回复。
""";
}这个bug藏得很深。现象是:用户完成一次分诊后,再输入新症状,系统直接返回"追问已达上限",不给分诊结果。
排查后发现,clarificationRound在分诊完成后没有重置。第一轮分诊追问了3次,clarificationRound=3,然后分诊完成。用户输入新症状,进来一判断canAskClarification()返回false(因为3 >= 3),直接跳过追问走分诊------但这时候AI拿到的信息又不够,分诊结果置信度很低。
修复很简单,分诊完成后重置计数器:
java
public void resetClarificationRound() {
clarificationRound = 0;
}在分诊完成的逻辑里调用一下就行。但这个bug让我意识到,会话状态管理比想象中容易出错。每个阶段切换的时候,都要想想哪些状态需要重置。
前端localStorage保存sessionId
- 会话状态存在后端内存里,前端通过
sessionId来关联,最终知道这是第几轮会话。 - 问题是用户刷新页面后,
sessionId就丢了,后端的会话数据还在,但前端找不到了。 - 简单说: 没有sessionId,每次请求都是全新会话,多轮追问就崩了 。
| 场景 | 有sessionId | 没有sessionId |
|---|---|---|
| 刷新页面后 | 从localStorage恢复,继续同一轮对话 | 丢失会话,重新开始 |
| 追问轮次 | 后端知道是第几轮,不会超3次 | 每轮都是第1轮,无限追问 |
| 历史消息 | 后端有完整上下文 | 每次只有当前一条消息 |
解决方法是在前端用localStorage持久化:
javascript
// 发起分诊请求
async function startTriage(symptom) {
const sessionId = localStorage.getItem('triage_session_id');
const response = await fetch('/api/v1/triage', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
message: symptom,
sessionId: sessionId || null
})
});
const result = await response.json();
// 保存sessionId
localStorage.setItem('triage_session_id', result.sessionId);
return result;
}然后在页面加载时再从localStorage 读取 triage_session_id :
javascript
const currentSessionId = ref<string | null>(localStorage.getItem('triage_session_id'))所以刷新后 currentSessionId 自动恢复为 'abc-123' ,下次 sendTriage 就会带上它。【但要注意一个边界情况: 用户结束一次问诊后,再次打开页面 ,localStorage里还留着旧的sessionId。这会导致新对话继续用旧会话,历史消息混在一起。这个后续优化一下,允许用户自己去结束问诊,然后清空localStorage】
typescript
页面刷新前 ──→ localStorage.setItem('triage_session_id', 'abc-123')
↓ 刷新
页面加载 ──→ localStorage.getItem('triage_session_id') → 'abc-123'
↓
currentSessionId = 'abc-123'后端的SessionContextService在收到请求时,先看有没有sessionId,有的话从内存Map里取会话,没有就创建新的:
java
@Service
public class SessionContextService {
// 内存存储,简单粗暴,后续可以换Redis
private final Map<String, ConsultationSession> sessions = new ConcurrentHashMap<>();
public ConsultationSession getOrCreateSession(String sessionId) {
if (sessionId != null && sessions.containsKey(sessionId)) {
return sessions.get(sessionId);
}
ConsultationSession newSession = ConsultationSession.builder()
.sessionId(UUID.randomUUID().toString())
.stage(ConsultationStage.INTAKE)
.clarificationRound(0)
.messages(new ArrayList<>())
.build();
sessions.put(newSession.getSessionId(), newSession);
return newSession;
}
}用ConcurrentHashMap是因为后续可能加多线程。当前单实例够用,真要上集群就得换Redis了,但那是部署层面的事,接口不用改。
前端还需要显示追问进度,让用户知道还能回答几轮:
javascript
// 显示追问标签
if (result.needClarification) {
showClarificationTag(`追问 ${result.clarificationRound}/3`);
displayQuestions(result.clarificationQuestions);
}五、验收和效果
写完这些逻辑,跑几个测试用例看看效果。
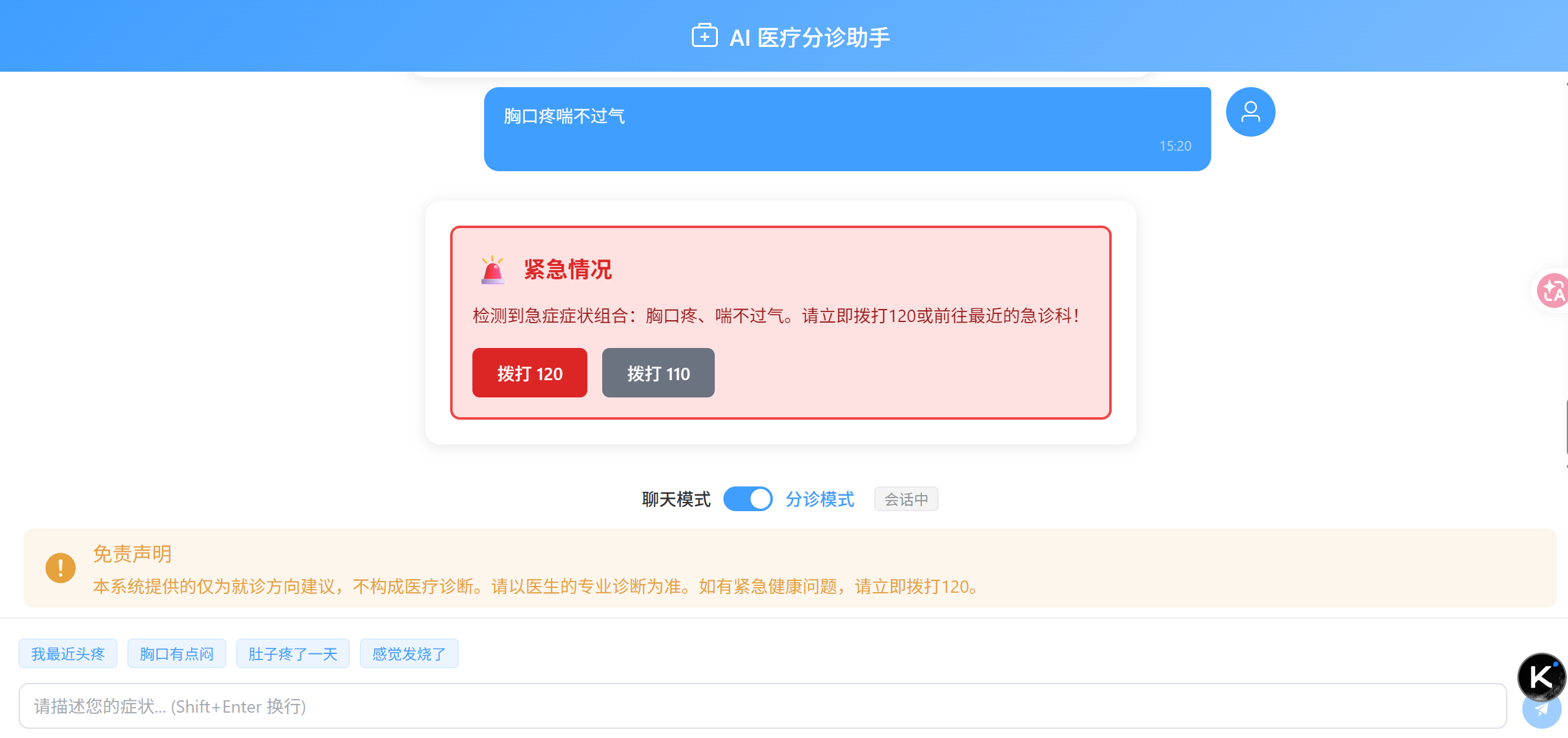
测试1:"胸口疼喘不过气" → 急症拦截
输入:"胸口疼喘不过气"
流程:用户输入 → EmergencyRuleService.check() → 命中组合规则"胸痛+呼吸困难" → 直接返回急症结果,不调AI
返回:
json
{
"needEmergency": true,
"urgencyLevel": "IMMEDIATE",
"primaryDepartment": "急诊科",
"confidenceScore": 1.0,
"reasoningSummary": "命中急症规则: 胸痛伴呼吸困难",
"disclaimer": "本系统仅提供分诊建议,不构成医疗诊断。请以医生面诊结果为准。如有紧急情况,请立即拨打120。"
}响应时间:2ms。如果走AI的话至少1-2秒。这就是规则引擎的价值。
测试2:只说"我最近头疼" → 追问→ 分诊→ 科室推荐
(1)第一轮:
-
输入:
{
"message": "我最近头疼"
} -
流程:用户输入 → EmergencyRuleService.check() → 未命中 → AI分析 → 信息完整度0.25 < 0.6 → 追问
-
返回:
json
{
"needEmergency": false,
"urgencyLevel": "OBSERVATION",
"primaryDepartment": "待定",
"alternativeDepartments": [],
"confidenceScore": 0.25,
"needClarification": true,
"clarificationQuestions": [
"头痛大概持续多长时间了?能具体说一下是几天还是几周吗?",
"头痛的程度怎么样?是轻微隐痛还是比较剧烈?有没有影响您的日常活动或睡眠?"
],
"reasoningSummary": "信息不足,需要进一步了解症状详情",
"preparationAdvice": [],
"warningSigns": [],
"disclaimer": "本系统仅提供就诊方向参考,不构成医疗诊断。",
"emergencyMessage": null,
"errorMessage": null,
"status": "success",
"sessionId": "ff5fd677-65b1-4723-a323-6c3515d2a127",
"stage": "CLARIFICATION",
"clarificationRound": 1,
"agentTrace": [
{
"agentName": "IntakeAgent",
"inputSummary": "用户消息: 我最近头疼",
"outputSummary": "完整度:0.25, 追问:true",
"durationMs": 15199,
"modelName": null,
"success": true,
"errorMessage": null
}
]
}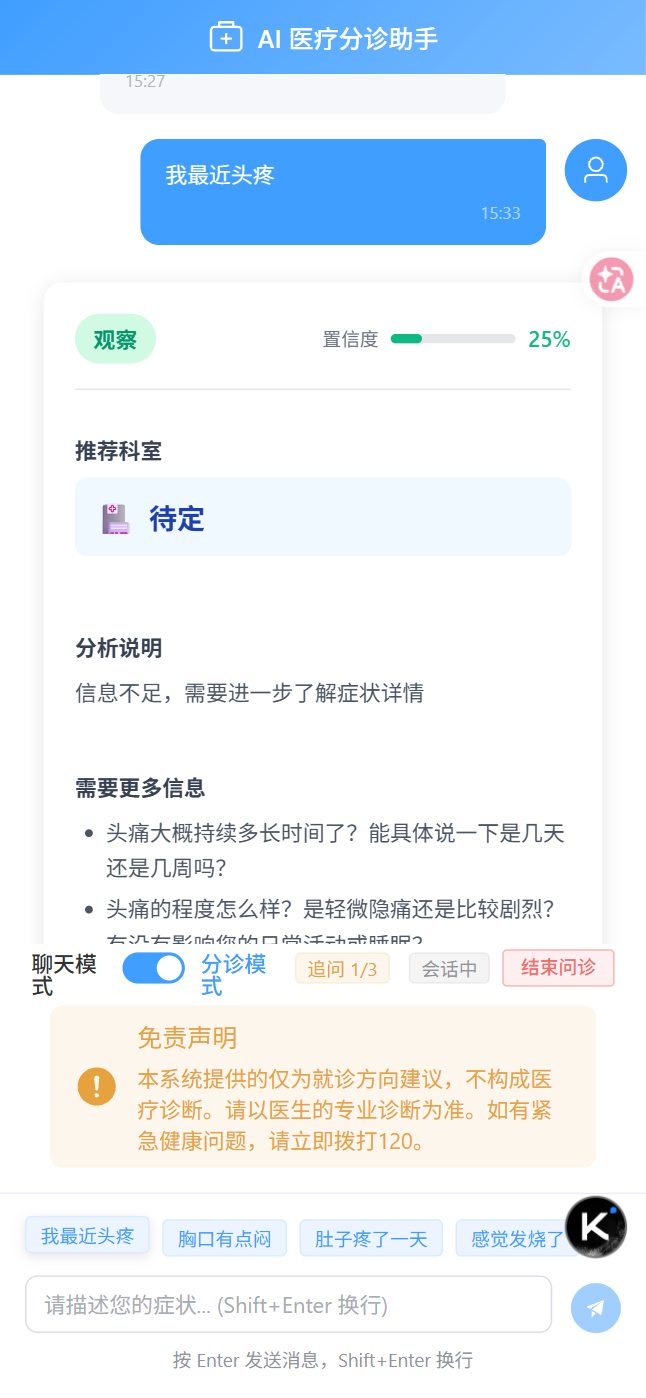
前端展示追问标签"追问 1/3",用户回答后带着sessionId继续请求,后端从会话中恢复上下文,进入第2轮追问或直接分诊。
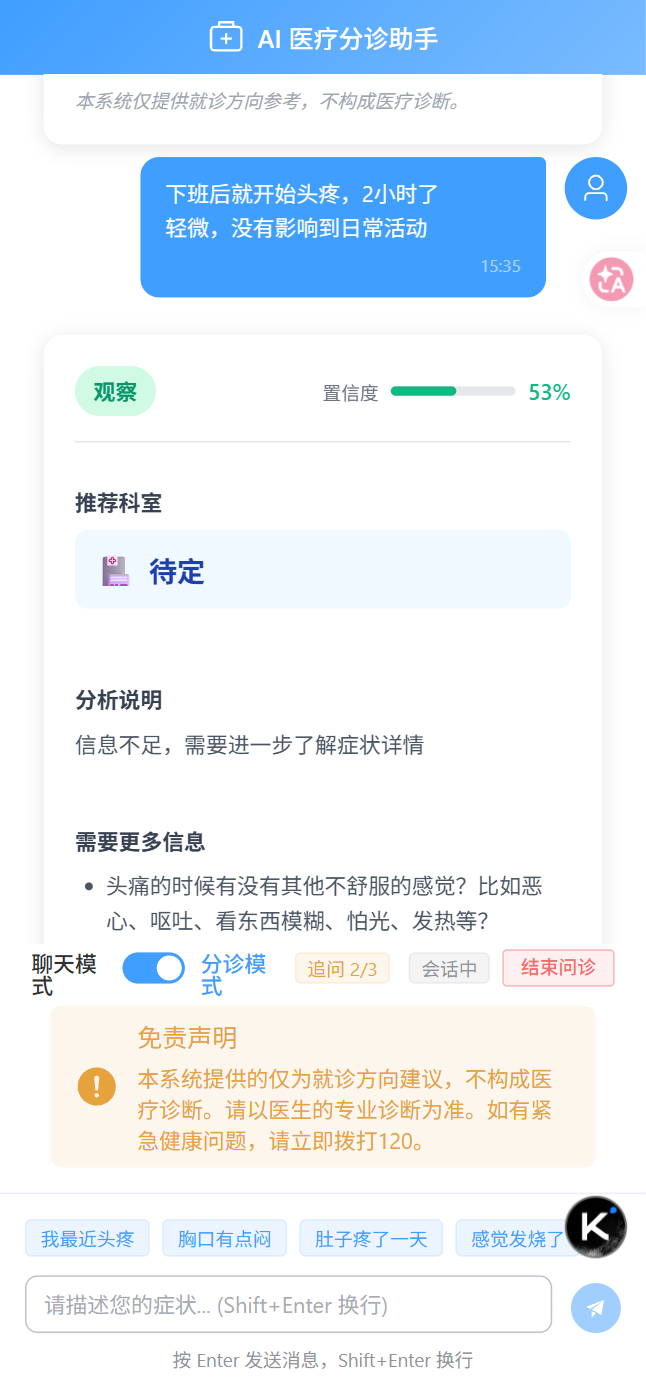
(2)第二轮:
-
输入:
{
"sessionId": "ff5fd677-65b1-4723-a323-6c3515d2a127",
"message": "下班后就开始头疼,2小时了\n轻微,没有影响到日常活动"
} -
流程:用户输入 → EmergencyRuleService.check() → 未命中 → AI分析 → 信息完整度0.53 < 0.6 → 追问
-
返回:
typescript
{
"needEmergency": false,
"urgencyLevel": "OBSERVATION",
"primaryDepartment": "待定",
"alternativeDepartments": [],
"confidenceScore": 0.525,
"needClarification": true,
"clarificationQuestions": [
"头痛的时候有没有其他不舒服的感觉?比如恶心、呕吐、看东西模糊、怕光、发热等?",
"请问您的年龄和性别是?"
],
"reasoningSummary": "信息不足,需要进一步了解症状详情",
"preparationAdvice": [],
"warningSigns": [],
"disclaimer": "本系统仅提供就诊方向参考,不构成医疗诊断。",
"emergencyMessage": null,
"errorMessage": null,
"status": "success",
"sessionId": "ff5fd677-65b1-4723-a323-6c3515d2a127",
"stage": "CLARIFICATION",
"clarificationRound": 2,
"agentTrace": [
{
"agentName": "IntakeAgent",
"inputSummary": "用户消息: 下班后就开始头疼,2小时了\n轻微,没有影响到日常活动",
"outputSummary": "完整度:0.53, 追问:true",
"durationMs": 19244,
"modelName": null,
"success": true,
"errorMessage": null
}
]
}
(3)第三轮:
- 输入:
json
{
"sessionId": "ff5fd677-65b1-4723-a323-6c3515d2a127",
"message": "看东西模糊、26、男"
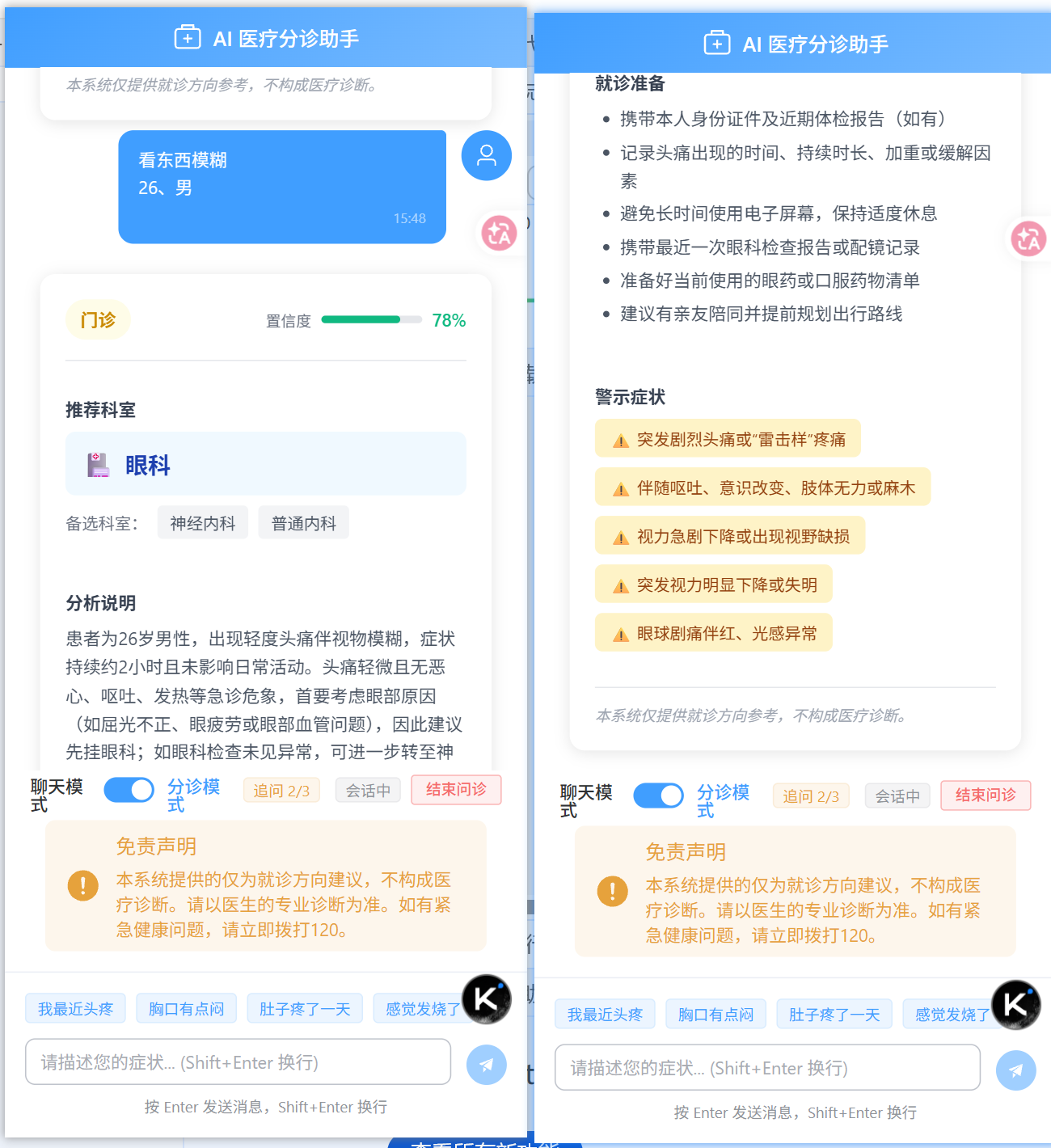
}-
流程:用户输入 → EmergencyRuleService.check() → 未命中 → AI分析 → 信息完整度0.78 > 0.6 → 分诊并返回报告
-
返回:
json
{
"needEmergency": false,
"urgencyLevel": "OUTPATIENT",
"primaryDepartment": "眼科",
"alternativeDepartments": [
"神经内科",
"普通内科"
],
"confidenceScore": 0.78,
"needClarification": false,
"clarificationQuestions": [],
"reasoningSummary": "患者为26岁男性,出现轻度头痛伴视物模糊,症状持续约2小时且未影响日常活动。头痛轻微且无恶心、呕吐、发热等急诊危象,首要考虑眼部原因(如屈光不正、眼疲劳或眼部血管问题),因此建议先挂眼科;如眼科检查未见异常,可进一步转至神经内科或普通内科评估。",
"preparationAdvice": [
"携带本人身份证件及近期体检报告(如有)",
"记录头痛出现的时间、持续时长、加重或缓解因素",
"避免长时间使用电子屏幕,保持适度休息",
"携带最近一次眼科检查报告或配镜记录",
"准备好当前使用的眼药或口服药物清单",
"建议有亲友陪同并提前规划出行路线"
],
"warningSigns": [
"突发剧烈头痛或"雷击样"疼痛",
"伴随呕吐、意识改变、肢体无力或麻木",
"视力急剧下降或出现视野缺损",
"突发视力明显下降或失明",
"眼球剧痛伴红、光感异常"
],
"disclaimer": "本系统仅提供就诊方向参考,不构成医疗诊断。",
"emergencyMessage": null,
"errorMessage": null,
"status": "success",
"sessionId": "ff5fd677-65b1-4723-a323-6c3515d2a127",
"stage": "TRIAGE",
"clarificationRound": 2,
"agentTrace": [
{
"agentName": "IntakeAgent",
"inputSummary": "用户消息: 看东西模糊\n26、男",
"outputSummary": "完整度:0.90, 追问:false",
"durationMs": 17560,
"modelName": null,
"success": true,
"errorMessage": null
},
{
"agentName": "TriageAgent",
"inputSummary": "症状摘要: 26岁男性,下班后出现头痛,持续约2小时,程度轻微,不影响日常活动,伴有视物模糊。",
"outputSummary": "科室:眼科, 紧急:OUTPATIENT, 置信度:0.78",
"durationMs": 5531,
"modelName": null,
"success": true,
"errorMessage": null
},
{
"agentName": "ReportAgent",
"inputSummary": "分诊报告, 科室: 眼科",
"outputSummary": "报告生成完成",
"durationMs": 6937,
"modelName": null,
"success": true,
"errorMessage": null
}
]
}
小结
这一篇解决了三个核心问题:
- AI输出不可控 → 结构化JSON + 容错解析器,AI再怎么折腾都能兜住
- 急症响应慢 → 规则引擎前置,命中急症关键词直接返回,不走AI
- AI乱说话 → 安全过滤 + Prompt约束 + 免责声明,三重保险
- 信息不足硬分诊 → 多轮追问 + 完整度阈值,信息不够就问,问够了再分诊
踩的坑也不少:AI返回的JSON格式千奇百怪、AI总说信息不够、追问计数忘了重置、AI会绕过禁词......这些都是真实开发中会遇到的问题,不是写个Demo就能发现的。
ps:因为我的代码已经拆分到3agent了,本篇就不写单agent的具体代码了,了解大致业务即可,后续多agent与分诊等详细代码请看下一篇
下一篇要把现在挤在一起的逻辑拆成三个Agent------IntakeAgent负责采集症状、TriageAgent负责分诊、ReportAgent负责生成报告------然后用一个编排器来协调它们。这就是三Agent编排,也是整个项目从"能跑"到"能维护"的关键一步。