一.Buffer Pool调优
磁盘 I/O 是数据库最大的性能瓶颈。Buffer Pool 是 InnoDB 在内存中开辟的一片区域,核心作用:
1.缓存数据页:将频繁访问的数据/索引页保留在内存,避免重复磁盘读取
2.延迟写(Write-back):修改先写内存页,再异步刷盘,将随机写变为顺序写
3.预读(Read-ahead):基于局部性原理,提前加载相邻数据页
内存结构

LRU算法的改进 ------以防扫描污染
在传统的LRU问题里面,我们的全表扫描会将大量的冷数据push入链表头部,挤出真正的热数据。
而我们的InnoDB存储引擎对此有解决方法:
1.将LRU分为New区和Old区
2.行读取的页会先放到Old区头部
3.只有在Old区停留超过nnodb_old_blocks_time(默认 1000ms)且再次被访问,才会晋升到 New 区
这样一来,在短暂扫描的数据不会污染热数据区
脏页刷盘机制
1.nnodb_max_dirty_pages_pct:脏页占比阈值(默认 75%),超过则加速刷盘
2.nnodb_io_capacity:InnoDB 后台任务的 IOPS 上限
3.nnodb_flush_neighbors:刷脏页时是否连带刷相邻页(SSD 建议关闭)
关键参数
innodb_buffer_pool_size:缓冲池大小(通常设为物理内存的 50%-75%)
innodb_buffer_pool_instances:缓冲池实例数(减少锁竞争)
innodb_old_blocks_pct / innodb_old_blocks_time:LRU 列表老生代比例和停留时间
好的我们使用sql,查看当前 Buffer Log 的状态
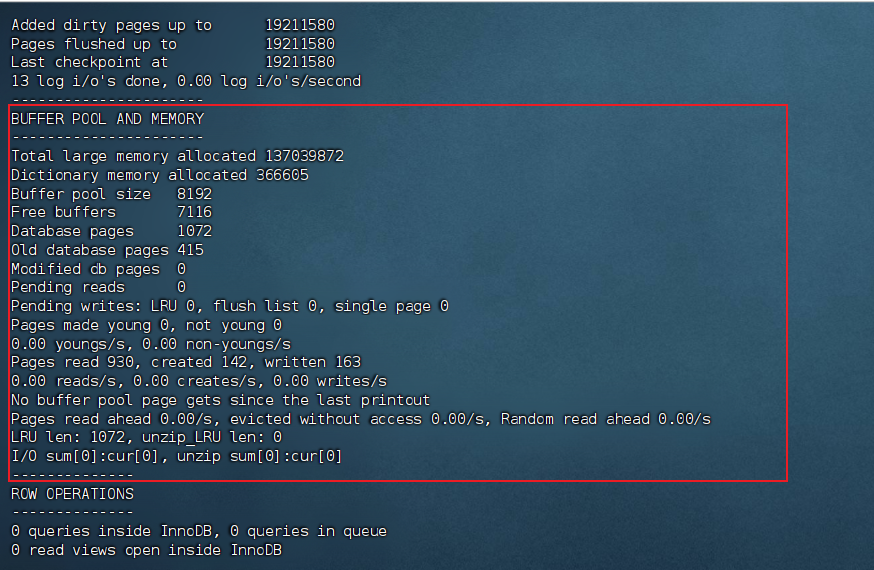
接下来我们看看Buffer Iog Pool配置
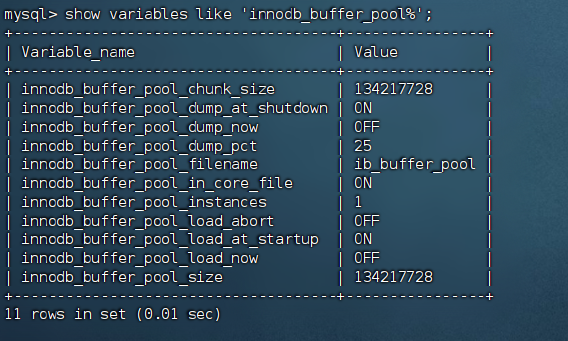
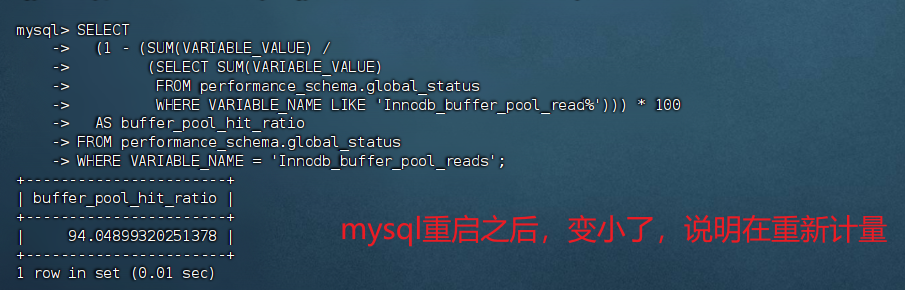
查看 Buffer Pool 命中率(应保持在 95% 以上)
我的有点低了,我就增加一下分配的值

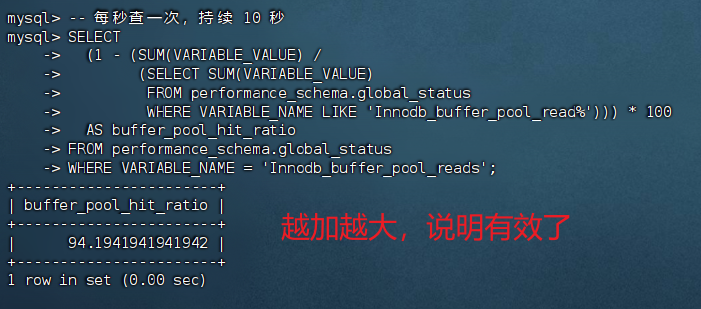
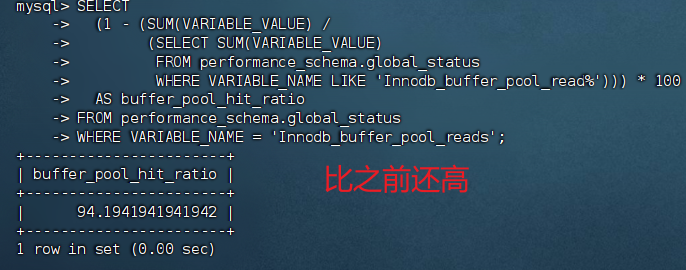
不错,好了
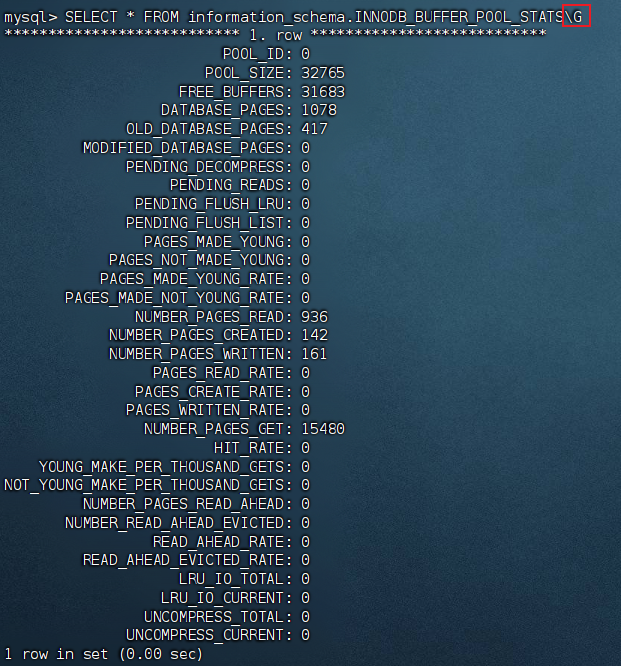
接下来查看各实例状态
我们这样子不好看,在后面加上一个后缀/G
sql
-- 查看当前 buffer pool 状态
show engine innodb status;
-- 查看 buffer pool 配置
show variables like 'innodb_buffer_pool%';
-- 查看 buffer pool 命中率(应保持在 95% 以上)
select
(1 - (sum(variable_value) /
(select sum(variable_value)
from performance_schema.global_status
where variable_name like 'innodb_buffer_pool_read%'))) * 100
as buffer_pool_hit_ratio
from performance_schema.global_status
where variable_name = 'innodb_buffer_pool_reads';
-- 查看各实例状态
select * from information_schema.innodb_buffer_pool_stats;二.Redo/Undo Log机制
事务的ACID与日志的关系

Redo Log ------物理日志的极致优化
在事务提交的时候,如果直接刷数据页到磁盘,随机I/O性能极差
解决方法:
1.我们可以采用WAL:先写日志,之后再刷脏页就没有非常大的后顾之忧了
2.Redo Log 是顺序写(可以追加到日志文件末尾),它的性能远远高于随机写
3.日志文件大小固定,循环覆盖(有点类似于Ring Buffer)
LSN的三元组:
1.Log sequence number:当前写入位置
2.Log flushed up to:已刷盘位置
3.Pages flushed up to:数据页已刷盘位置
三者关系:LSN(write) >= LSN(flush) >= LSN(page_flush)
Undo Log ------逻辑日志与MVCC
它的存储内容不是物理镜像,而是逻辑反向操作,就相当于我们在windows里面的撤回操作大体是一样的

Undo Log 与 MVCC 的关系
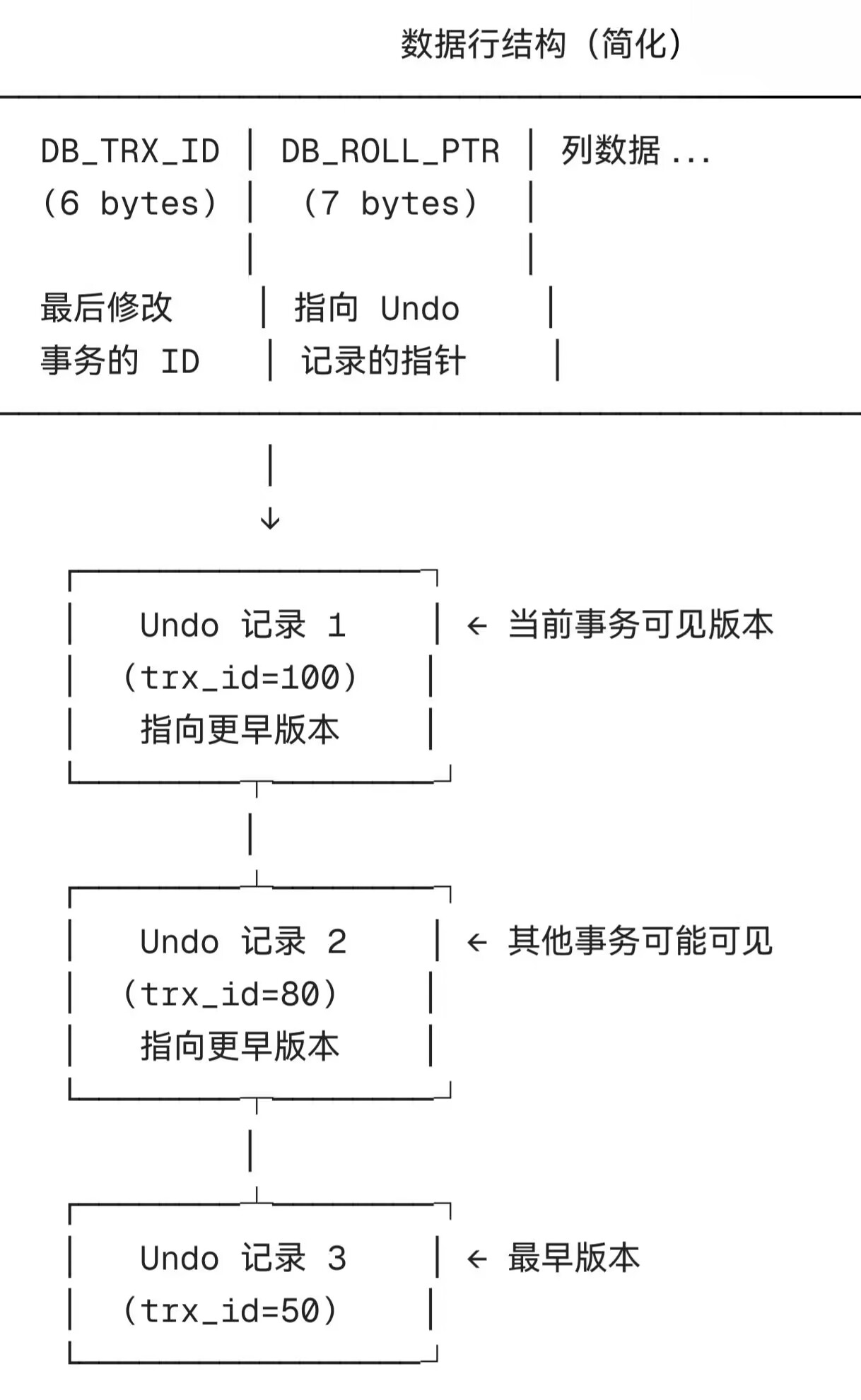
我们来看看一致性视图的机制(Read View):
1.m_ids:生成 Read View 时活跃的事务 ID 列表
2.min_trx_id:活跃事务里面最小的 ID
3.max_trx_id:下一个需要分配的事务 ID
4.creator_trx_id:创建 Read View 的事务 ID
可间断性规则:
1.trx_id == creator_trx_id → 可见(自己改的)
2.trx_id < min_trx_id → 可见(已提交)
3.trx_id >= max_trx_id → 不可见(未来事务)
4.min_trx_id <= trx_id < max_trx_id → 检查是否在 m_ids 中(在则不可见)
Purge线程 ------清理过期Undo
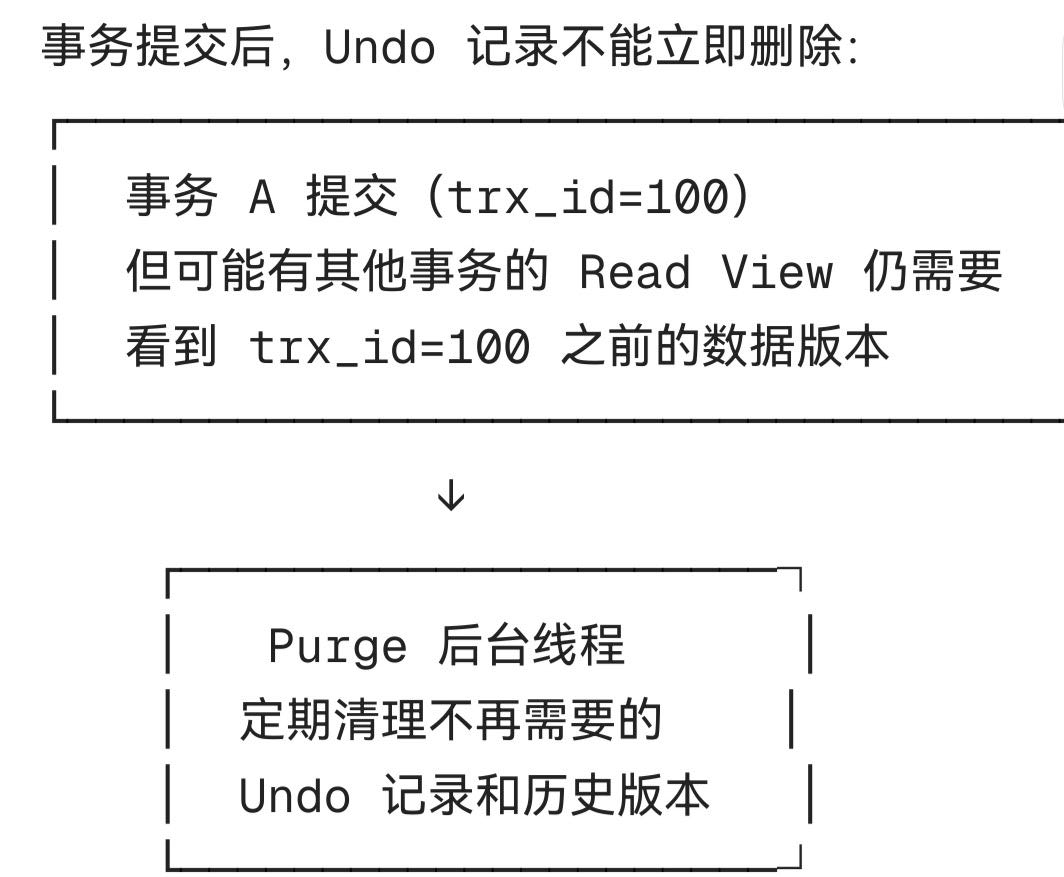
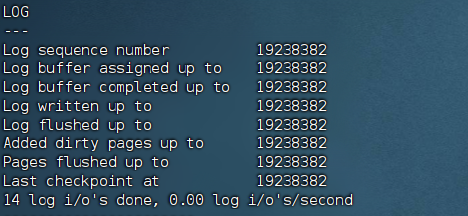
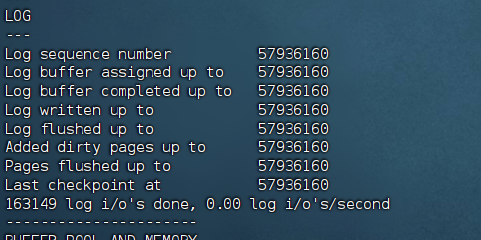
1.Log sequence number(19238382):这是 Redo Log 的逻辑写入位置。它一直在增加,代表系统正在不断地把新的修改记录写进日志。
2.Log flushed up to(19238382):这是 Redo Log 的物理刷盘位置。
关键点:这里和上一项数字完全一致,说明日志产生后,立刻就被刷到了磁盘上(或者刚好同步)。这说明你的 innodb_flush_log_at_trx_commit参数设置得很激进(通常是 1),安全性高,性能消耗也大。
3.Last checkpoint at(19238382):这是检查点位置。
关键点:它也和上面一样。这意味着目前内存里的脏页(修改过的数据页)非常少,或者刚刚做过清理。数据库处于一个很轻松的状态,没有积压太多未刷盘的脏数据。
查看Redo Log的配置
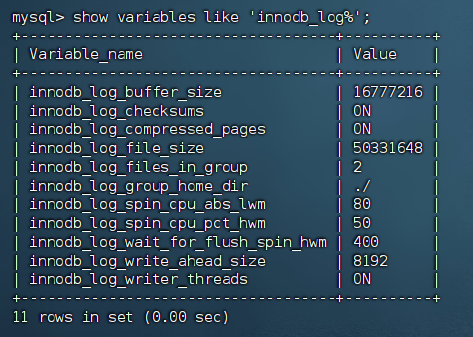
查看它的写入状态
查看Undo信息
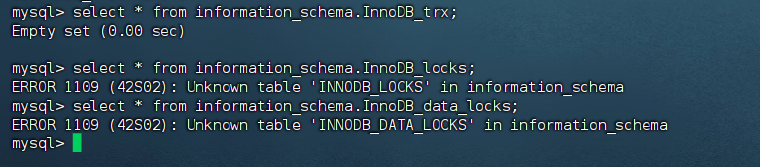
没招了,没想到mysql版本太高了

现在可以了,一个没有锁就没有回显,一个有此表存在
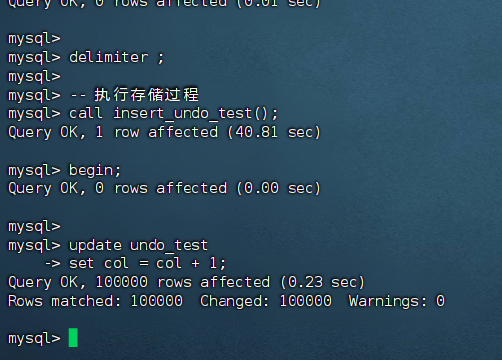
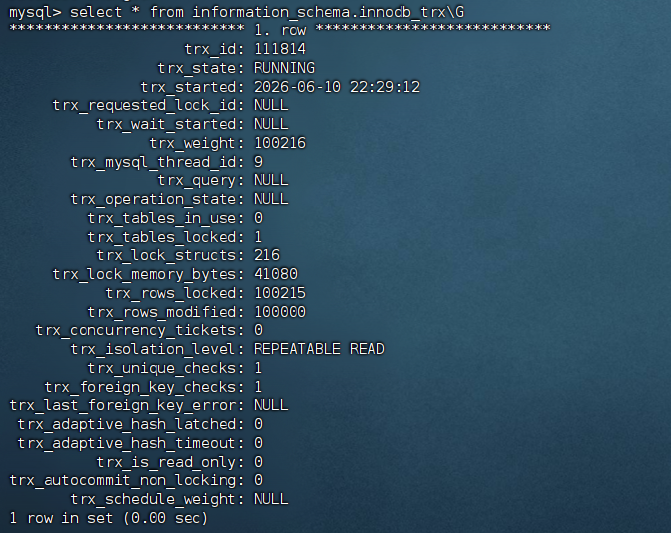
查看活跃事务
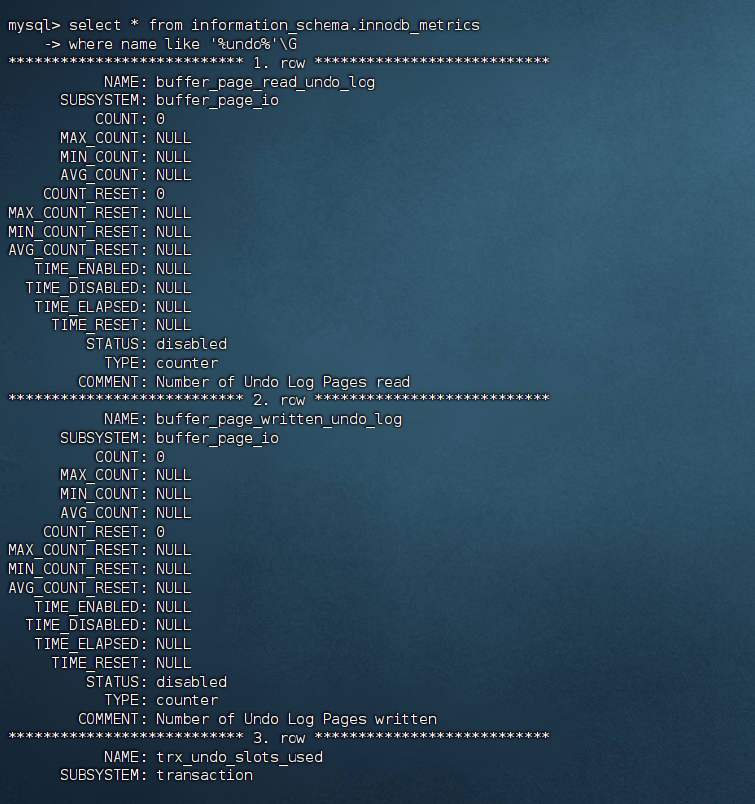
查看 Undo 使用情况
查看 Redo / Undo 压力
sql
-- 创建专用测试库(避免搞乱你的业务库)
create database if not exists test_undo;
use test_undo;
-- 创建测试表
create table if not exists undo_test (
id int primary key auto_increment,
col int default 0,
create_time datetime default current_timestamp
) engine=innodb;
--插入
delimiter $$
create procedure insert_undo_test()
begin
declare i int default 0;
while i < 100000 do
insert into undo_test (col) values (i);
set i = i + 1;
end while;
end
$$
delimiter ;
-- 执行存储过程
call insert_undo_test();
sql
-- 查看 Redo Log 配置
show variables like 'innodb_log%';
-- 查看 Redo Log 写入状态
show engine InnoDB status\G
-- 关注 Log sequence number、Log flushed up to 的差值
-- 查看 Undo 信息
select * from information_schema.InnoDB_TRX; -- 当前活跃事务
select * from information_schema.InnoDB_LOCK_WAITS; -- 当前锁信息(MySQL 8.0 已移除,改用 data_locks)
select * from performance_schema.data_locks; -- MySQL 8.0+
-- 模拟长事务,观察 Undo Log 增长
--开启事务(不提交)
begin;
update undo_test
set col = col + 1;
--查看活跃事务
select * from information_schema.innodb_trx\G
--查看 Undo 使用情况(MySQL 8.0)
select * from information_schema.innodb_metrics
where name like '%undo%'\G
--查看 Redo / Undo 压力
show engine innodb status\G