视觉Transformer实战 | Twins空间注意力机制详解与实现
-
- [0. 前言](#0. 前言)
- [1. 空间注意力的重新思考](#1. 空间注意力的重新思考)
-
- [1.1 研究背景](#1.1 研究背景)
- [1.2 视觉注意力模型设计的挑战](#1.2 视觉注意力模型设计的挑战)
- [2. Twins 架构概述](#2. Twins 架构概述)
-
- [2.1 条件位置编码](#2.1 条件位置编码)
- [2.2 Twins-SVT](#2.2 Twins-SVT)
- [2.3 局部分组注意力](#2.3 局部分组注意力)
- [2.4 全局下采样注意力](#2.4 全局下采样注意力)
- [2.5 空间可分离注意力机制](#2.5 空间可分离注意力机制)
- [3. 使用 PyTorch 实现 Twins](#3. 使用 PyTorch 实现 Twins)
-
- [3.1 模型构建](#3.1 模型构建)
- [3.2 数据集加载](#3.2 数据集加载)
- [3.3 模型训练](#3.3 模型训练)
- 相关链接
0. 前言
视觉任务里,标准全局自注意力在高分辨率输入上代价太高;纯局部窗口注意力虽然更省算力,但跨窗口信息不足,对检测、分割这类密集预测任务并不友好。Twins 因此提出了两条路线:Twins-PCPVT 和 Twins-SVT,前者重点改位置编码,后者重点改空间注意力设计。本文将详细介绍 Twins 网络的技术原理,并提供完整的 PyTorch 实现。
1. 空间注意力的重新思考
1.1 研究背景
最早把 Transformer 引入计算机视觉的 ViT,证明了纯注意力架构在分类任务上的潜力,但它们本质上仍然依赖全局逐词元 (token-to-token) 交互;一旦输入分辨率升高,尤其是进入检测、分割这类需要特征金字塔和高分辨率输入的任务时,标准自注意力的复杂度就会迅速变得不可接受。若输入分辨率为 H × W H×W H×W,标准自注意力的复杂度大约是 O ( H 2 W 2 d ) O(H^2W^2d) O(H2W2d)。
为了缓解这个问题,已有工作主要从两个方向进行改进。第一个是局部窗口化注意力,例如把特征图切成不重叠的小窗口,只在窗口内部做注意力;这样复杂度明显下降,但窗口之间不通信,跨区域建模能力会不足。Swin Transformer通过移位窗口 (shifted window) 让相邻层的窗口边界发生偏移,从而实现跨窗口信息流动,但这种不规则窗口在 ONNX 或 TensorRT 等部署框架下并不友好。第二个是PVT这类带空间降采样的全局注意力,它让查询只和降采样后的键/值交互,实践中能把计算降下来,但并没有从根本上解决视觉任务中的空间注意力设计问题。
Twins 的核心思想就是:与其把 Transformer 当成自然语言结构直接搬进视觉,不如重新审视"空间注意力"本身,设计一种更适合图像结构的方案。最终提出了两个版本:Twins-PCPVT 和 Twins-SVT。前者是在PVT框架上修改位置编码,后者则进一步提出新的空间可分离注意力机制 (spatially separable self-attention, SSSA)。
1.2 视觉注意力模型设计的挑战
总结而言,Twins 主要是为了解决视觉注意力模型设计中的以下问题:
- 高效率计算:缩小与卷积神经网络在运算效率上的差距,推动实际业务应用
- 灵活的注意力机制:融合卷积的局部感受野与自注意力的全局感受野,兼取两者优势
- 利于下游任务:支持检测、分割等任务,尤其是输入尺度变化的场景
2. Twins 架构概述
2.1 条件位置编码
PVT 的表现之所以不如Swin,一个重要原因不是全局注意力不行,而是 PVT 使用了绝对位置编码。绝对位置编码有两个明显缺点:第一,它对可变输入尺寸不够友好;第二,它会破坏平移不变性,而视觉任务恰恰特别依赖这种性质。CPVT 提出的条件位置编码 (conditional positional encoding, CPE) 则是输入条件化的,能够更自然地适配不同尺寸的特征图。Twins-PCPVT 直接沿用了这个思路,用位置编码器 (Positional Encoding Generator, PEG) 替换掉绝对位置编码。PEG 的实现非常简单,本质上就是一个二维深度可分离卷积,而且它被放在每个阶段的第 1 个 Transformer 编码器之后,如下图所示。
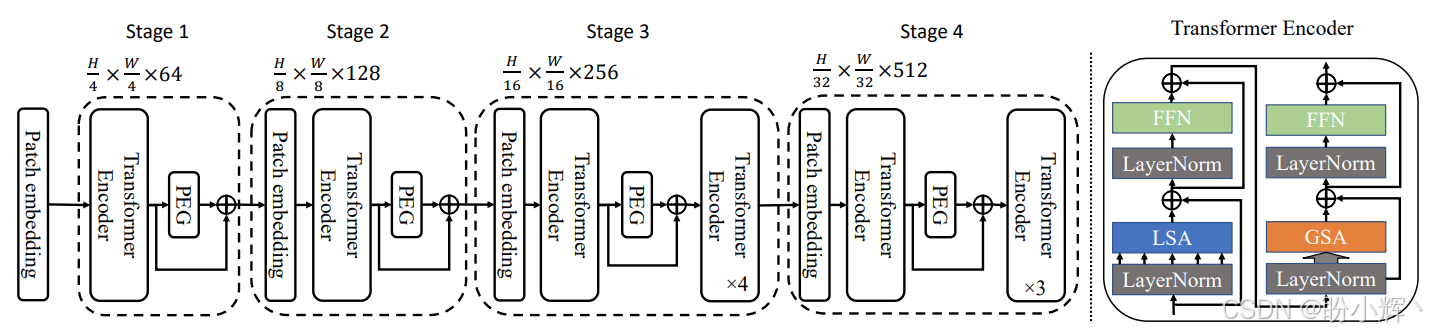
2.2 Twins-SVT
Twins-SVT 是 Twins 论文里真正的重点。它提出的空间可分离注意力机制 (spatially separable self-attention, SSSA) 借鉴了深度可分离卷积的思想:先做局部建模,再做全局融合。论文明确把它拆成两类注意力:局部分组注意力 (locally-grouped self-attention, LSA) 和全局下采样注意力 (global sub-sampled attention, GSA)。LSA 负责局部窗口内部的信息交互,GSA 负责在子采样后的全局范围内完成跨窗口通信,这一结构在实现层面非常简单,本质上就是少量矩阵乘法的组合。从直觉上看,SSSA 很像卷积神经网络里的"先局部、后融合":
LSA像深度卷积(看局部邻域):;将特征图划分为子窗口,在子窗口内计算自注意力GSA像逐点融合(把局部结果汇总起来):对键和值进行空间下采样,降低计算复杂度
这也是为什么说它与可分离卷积有相似性,它不是简单地把注意力缩小,而是把它拆成两个更符合视觉数据结构的阶段。
2.3 局部分组注意力
Twins 的第一步是把二维特征图划分成 m × n m×n m×n 个子窗口。假设高度和宽度都能被整除,那么每个窗口大小就是:
k 1 = H m , k 2 = W n k_1=\frac H m,\ \ \ k_2=\frac W n k1=mH, k2=nW
每个窗口里只有 k 1 k 2 k_1k_2 k1k2 个词元,因此单个窗口内部做自注意力的代价是:
O ( ( k 1 k 2 ) 2 d ) O((k_1k_2)^2d) O((k1k2)2d)
一共有 m n mn mn 个窗口,所以总复杂度为:
O ( m n ⋅ ( k 1 k 2 ) 2 d ) O(mn⋅(k_1k_2)^2d) O(mn⋅(k1k2)2d)
化简可得:
O ( k 1 k 2 H W d ) O(k_1k_2HWd) O(k1k2HWd)
这意味着:如果窗口大小固定,那么复杂度就会随着输入分辨率近似线性增长,而不是平方爆炸。我们可以这样理解 LSA:
shell
整张图 → 切成多个子窗口 → 每个窗口内部单独做注意力它的优点是高效,缺点也很明显:不同窗口之间没有直接通信。这也是为什么论文接下来要引入 GSA。
2.4 全局下采样注意力
如果只用 LSA,模型只会在局部范围里"徘徊",所以 Twins 又加入了 GSA。GSA 的做法不是让所有词元继续和所有词元交互,而是先为每个子窗口生成一个"代表词元"或子采样后的键/值,再让全局查询去和这些代表信息做注意力计算。这样就把跨窗口通信的复杂度从标准全局注意力的:
O ( H 2 W 2 d ) O(H^2W^2d) O(H2W2d)
降低到:
O ( m n H W d ) = O ( H 2 W 2 d k 1 k 2 ) O(mnHWd)=O(\frac {H^2W^2d}{k_1k_2}) O(mnHWd)=O(k1k2H2W2d)
GSA 的核心思想可以概括成一句话:不是让每个位置看全图,而是让全图的"代表点"来参与注意力。这非常符合工程优化的逻辑:保留全局关系,但压缩全局词元数量。
2.5 空间可分离注意力机制
SSSA 可以写成一个交替堆叠的结构。用更清晰的写法可以表示为:
z ^ i j l = L S A ( L N ( z i j l − 1 ) ) + z i j l − 1 z i j l = F F N ( L N ( z ^ i j l ) ) + z ^ i j l z ^ l + 1 = G S A ( L N ( z i j l ) ) + z i j l z l + 1 = F F N ( L N ( z ^ l + 1 ) ) + z ^ l + 1 \hat z_{ij}^l=LSA(LN(z_{ij}^{l−1}))+z_{ij}^{l−1}\\ z_{ij}^l=FFN(LN(\hat z_ij^l))+\hat z_{ij}^l\\ \hat z^{l+1}=GSA(LN(z_ij^l))+z_{ij}^l\\ z^{l+1}=FFN(LN(\hat z^{l+1}))+\hat z^{l+1} z^ijl=LSA(LN(zijl−1))+zijl−1zijl=FFN(LN(z^ijl))+z^ijlz^l+1=GSA(LN(zijl))+zijlzl+1=FFN(LN(z^l+1))+z^l+1
这组公式表达的就是一个标准的 Transformer 块变体:先局部注意力,再前馈网络;然后全局注意力,再前馈网络。每一步都带残差连接和层归一化。LSA 是在子窗口内部做注意力,而 GSA 则是通过子采样后的代表键 (K) 和各个窗口交互。
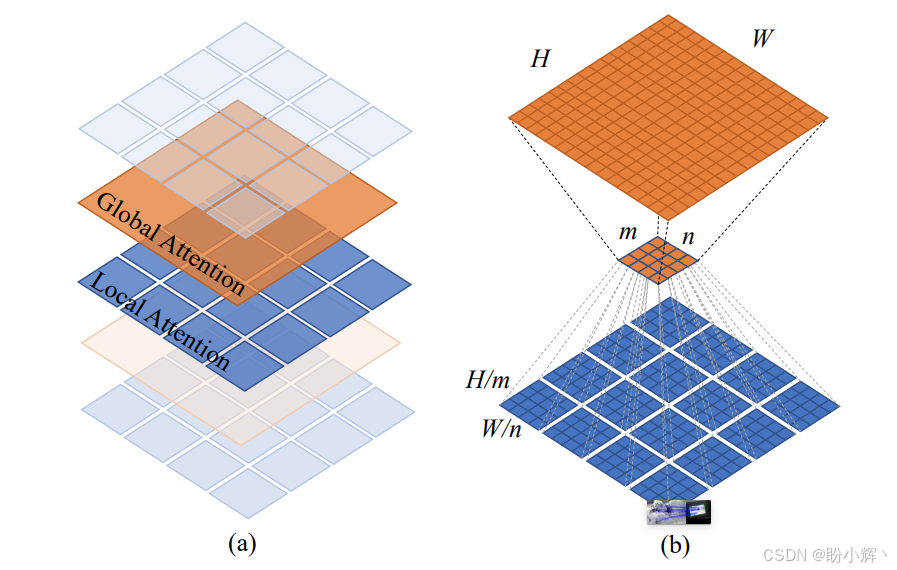
上图 (a) 的意思是:Twins-SVT 不是只做局部注意力,而是把 LSA 和 GSA 交替使用。(b) 则更具体地说明了两个模块的分工:LSA 将特征图切成多个子窗口,只在窗口内部做注意力;GSA 则通过子采样后的代表词元,把一个窗口的信息传播到其他窗口。这就是 Twins "先局部,后全局"的空间注意力路线。它既避免了标准全局注意力的高成本,也弥补了纯局部窗口缺少跨区域联系的问题。
3. 使用 PyTorch 实现 Twins
3.1 模型构建
(1) 首先,加载所需库:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import DropPath, trunc_normal_
from sklearn.model_selection import train_test_split
import torch.optim as optim
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import os
import re
from PIL import Image(2) 实现条件位置编码模块:
python
class CPE(nn.Module):
def __init__(self, dim):
super().__init__()
# 使用深度可分离卷积生成位置编码
self.pos_embed = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim)
def forward(self, x):
# 输入形状: [B, N, C]
B, N, C = x.shape
H = W = int(N**0.5)
# 转换为2D特征图 [B, C, H, W]
x = x.transpose(1, 2).view(B, C, H, W)
# 应用深度卷积生成位置编码
x = self.pos_embed(x) + x
# 恢复原始形状 [B, N, C]
x = x.flatten(2).transpose(1, 2)
return x(2) 实现多头自注意力模块:
python
class MSA(nn.Module):
def __init__(self, dim, num_heads=8):
super().__init__()
self.num_heads = num_heads
self.scale = (dim // num_heads) ** -0.5
self.qkv = nn.Linear(dim, dim * 3)
self.proj = nn.Linear(dim, dim)
def forward(self, x):
B, N, C = x.shape
# 生成Q,K,V [3, B, num_heads, N, C//num_heads]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
# 注意力计算
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# 输出投影
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x(3) 实现局部分组注意力 (locally-grouped self-attention, LSA),LSA 只在窗口内部做注意力,适合提取局部细节:
python
class LSA(MSA):
def __init__(self, dim, num_heads=8, window_size=7):
super().__init__(dim, num_heads)
self.window_size = window_size
# 相对位置偏置表
self.rel_pos_bias = nn.Parameter(torch.zeros(
(2 * window_size - 1) * (2 * window_size - 1),
num_heads
))
self._init_rel_pos()
def _init_rel_pos(self):
# 初始化相对位置索引
coords = torch.arange(self.window_size)
coords = torch.stack(torch.meshgrid(coords, coords, indexing='ij'))
coords_flatten = torch.flatten(coords, 1)
# 计算相对位置坐标
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
# 转换为非负索引
relative_coords[:, :, 0] += self.window_size - 1
relative_coords[:, :, 1] += self.window_size - 1
relative_coords[:, :, 0] *= 2 * self.window_size - 1
relative_position_index = relative_coords.sum(-1)
# 注册为缓冲区
self.register_buffer("relative_position_index", relative_position_index)
def forward(self, x):
B, N, C = x.shape
H = W = int(N**0.5)
x = x.view(B, H, W, C)
# 填充到窗口大小的整数倍
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# 将特征图划分为窗口
num_wh = Hp // self.window_size
num_ww = Wp // self.window_size
x = x.view(B, num_wh, self.window_size, num_ww, self.window_size, C)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, self.window_size * self.window_size, C)
# 计算相对位置偏置
relative_position_bias = self.rel_pos_bias[self.relative_position_index.view(-1)].view(
self.window_size * self.window_size,
self.window_size * self.window_size,
-1 # num_heads维度
)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
# 执行窗口内注意力
qkv = self.qkv(x).view(x.size(0), x.size(1), 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
# 注意力计算(添加相对位置偏置)
attn = (q @ k.transpose(-2, -1)) * self.scale + relative_position_bias.unsqueeze(0)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(x.size(0), x.size(1), C)
x = self.proj(x)
# 恢复特征图
x = x.view(B, num_wh, num_ww, self.window_size, self.window_size, C)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, C)
# 移除填充
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
return x(4) 实现全局下采样注意力 (global sub-sampled attention, GSA),GSA 则先对子采样后的特征图计算键/值,再让全局查询去和这些代表词元交互,用更低成本把跨窗口信息补回来:
python
class GSA(nn.Module):
def __init__(self, dim, num_heads=8, sr_ratio=4):
super().__init__()
self.num_heads = num_heads
self.scale = (dim // num_heads) ** -0.5
self.q = nn.Linear(dim, dim)
self.kv = nn.Linear(dim, dim * 2)
self.proj = nn.Linear(dim, dim)
# 空间缩减模块
self.sr = nn.Conv2d(dim, dim, sr_ratio, sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x):
B, N, C = x.shape
H = W = int(N**0.5)
# 生成查询向量
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
# 空间缩减
x_ = x.permute(0, 2, 1).view(B, C, H, W)
x_ = self.sr(x_).view(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
# 生成键值对
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
# 注意力计算
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x(5) 实现 Twins 基本块:
python
class Block(nn.Module):
def __init__(self, dim, num_heads, window_size=7, sr_ratio=4, mlp_ratio=4., drop_path=0.):
super().__init__()
# 第一个子块:局部注意力
self.norm1 = nn.LayerNorm(dim)
self.cpe1 = CPE(dim)
self.attn1 = LSA(dim, num_heads, window_size)
# 第二个子块:全局注意力
self.norm2 = nn.LayerNorm(dim)
self.cpe2 = CPE(dim)
self.attn2 = GSA(dim, num_heads, sr_ratio)
# MLP
self.norm3 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, int(dim * mlp_ratio)),
nn.GELU(),
nn.Linear(int(dim * mlp_ratio), dim)
)
# 随机深度衰减
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
# 第一个子块
x = x + self.drop_path(self.attn1(self.cpe1(self.norm1(x))))
# 第二个子块
x = x + self.drop_path(self.attn2(self.cpe2(self.norm2(x))))
# MLP
x = x + self.drop_path(self.mlp(self.norm3(x)))
return x(6) 实现图像分块嵌入:
python
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=64):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = img_size // patch_size
self.num_patches = self.grid_size ** 2
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# 分块投影
x = self.proj(x).flatten(2).transpose(1, 2)
return x(7) 实现 Twins-SVT 模型:
python
class TwinsSVT(nn.Module):
"""Twins-SVT模型"""
def __init__(self, img_size=224, in_chans=3, num_classes=1000,
depths=[2, 2, 10, 4], embed_dims=[64, 128, 256, 512],
num_heads=[2, 4, 8, 16], window_sizes=[7, 7, 7, 7],
sr_ratios=[8, 4, 2, 1], mlp_ratios=[4, 4, 4, 4], drop_path_rate=0.1):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.embed_dims = embed_dims
# 分块嵌入
self.patch_embed = PatchEmbed(img_size, 4, in_chans, embed_dims[0])
# 位置编码
self.pos_embed = nn.Parameter(torch.zeros(1, self.patch_embed.num_patches, embed_dims[0]))
# 随机深度衰减规则
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
# 构建四个阶段
self.stages = nn.ModuleList()
cur = 0
for i in range(4):
# 每个阶段开始的下采样
if i > 0:
patch_merge = nn.Conv2d(embed_dims[i-1], embed_dims[i], 2, 2)
self.stages.append(patch_merge)
# 当前阶段的块
stage_blocks = nn.ModuleList([
Block(
dim=embed_dims[i],
num_heads=num_heads[i],
window_size=window_sizes[i],
sr_ratio=sr_ratios[i],
mlp_ratio=mlp_ratios[i],
drop_path=dpr[cur + j]
) for j in range(depths[i])
])
self.stages.append(stage_blocks)
cur += depths[i]
# 分类头
self.norm = nn.LayerNorm(embed_dims[-1])
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
# 初始化权重
trunc_normal_(self.pos_embed, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
# 初始分块嵌入
x = self.patch_embed(x)
x = x + self.pos_embed
# 转换特征图形状 [B, N, C] -> [B, C, H, W]
B, N, C = x.shape
H = W = int(N**0.5)
x = x.permute(0, 2, 1).view(B, C, H, W)
# 四个处理阶段
for stage in self.stages:
if isinstance(stage, nn.ModuleList):
# 处理块序列
for blk in stage:
# 转换回序列形式 [B, C, H, W] -> [B, N, C]
_, C, H, W = x.shape
x = x.flatten(2).permute(0, 2, 1)
x = blk(x)
# 转换回特征图形式
x = x.permute(0, 2, 1).view(B, C, H, W)
else:
# 下采样操作
x = stage(x)
# 最终全局平均池化
x = x.mean(dim=[2, 3]) # [B, C]
return x
def forward(self, x):
x = self.forward_features(x)
x = self.norm(x)
x = self.head(x)
return x3.2 数据集加载
构建了 Twins 模型后,我们将使用与CrossViT 详解与实现一节中相同的数据集训练模型。
(1) 定义数据集类:
python
class CustomDataset(Dataset):
def __init__(self, root_dir, transform=None, train=True, test_size=0.1):
self.root_dir = root_dir
self.transform = transform
self.train = train
# 获取所有图像和对应的标签
self.image_paths = []
self.labels = []
# 从文件名中提取类别
all_files = os.listdir(root_dir)
pattern = re.compile(r'^(.+?)_\d+\.(jpg|jpeg|png)$', re.IGNORECASE)
# 收集所有类别
classes = set()
for filename in all_files:
match = pattern.match(filename)
if match:
classes.add(match.group(1))
self.classes = sorted(classes)
self.class_to_idx = {cls: idx for idx, cls in enumerate(self.classes)}
# 收集所有有效图像
for filename in all_files:
match = pattern.match(filename)
if match:
cls = match.group(1)
self.image_paths.append(os.path.join(root_dir, filename))
self.labels.append(self.class_to_idx[cls])
# 划分训练集和验证集
train_paths, test_paths, train_labels, test_labels = train_test_split(
self.image_paths, self.labels, test_size=test_size, stratify=self.labels
)
if train:
self.image_paths = train_paths
self.labels = train_labels
else:
self.image_paths = test_paths
self.labels = test_labels
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path).convert('RGB')
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label(2) 定义数据集变换器:
python
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomApply([
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.RandomApply([
transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 0.2))
], p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])(3) 创建数据集和数据加载器:
python
train_dataset = CustomDataset(root_dir='data/images', transform=train_transform, train=True)
val_dataset = CustomDataset(root_dir='data/images', transform=val_transform, train=False)
batch_size = 8
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4, pin_memory=True)
num_classes = len(train_dataset.classes)3.3 模型训练
(1) 定义模型训练和测试函数:
python
def train_model(model, train_loader, val_loader, num_epochs=50, lr=1e-4):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
train_losses = []
val_losses = []
train_accs = []
val_accs = []
# 优化器
optimizer = optim.AdamW(model.parameters(), lr=lr, weight_decay=0.01)
criterion = nn.CrossEntropyLoss()
# 混合精度训练
scaler = torch.amp.GradScaler()
# 学习率调度
scheduler = optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=1e-4,
steps_per_epoch=len(train_loader),
epochs=num_epochs,
pct_start=0.1
)
for epoch in range(num_epochs):
# 训练阶段
model.train()
train_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
with torch.amp.autocast(device_type='cuda', dtype=torch.float16):
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
train_acc = 100. * correct / total
avg_train_loss = train_loss / len(train_loader)
train_losses.append(avg_train_loss)
train_accs.append(train_acc)
# 验证阶段
val_loss, val_acc = validate(model, val_loader, criterion, device)
val_losses.append(val_loss)
val_accs.append(val_acc)
# 更新学习率
scheduler.step()
print(f'Epoch {epoch+1}/{num_epochs}: '
f'Train Loss: {avg_train_loss:.4f}, Train Acc: {train_acc:.2f}%, '
f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Val Loss')
plt.legend()
plt.title('Loss')
plt.subplot(1, 2, 2)
plt.plot(train_accs, label='Train Acc')
plt.plot(val_accs, label='Val Acc')
plt.legend()
plt.title('Accuracy')
plt.savefig('training_curve.png')
plt.show()
def validate(model, val_loader, criterion, device):
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
avg_val_loss = val_loss / len(val_loader)
val_acc = 100. * correct / total
return avg_val_loss, val_acc(2) 初始化模型:
python
model = TwinsSVT(
img_size=224,
num_classes=len(train_dataset.classes),
depths=[2, 2, 10, 4],
embed_dims=[64, 128, 256, 512],
num_heads=[2, 4, 8, 16],
window_sizes=[7, 7, 7, 7],
sr_ratios=[8, 4, 2, 1]
)(3) 开始训练:
python
train_model(model, train_loader, val_loader, num_epochs=200, lr=2e-4)模型训练过程,损失和模型性能变化情况如下所示:
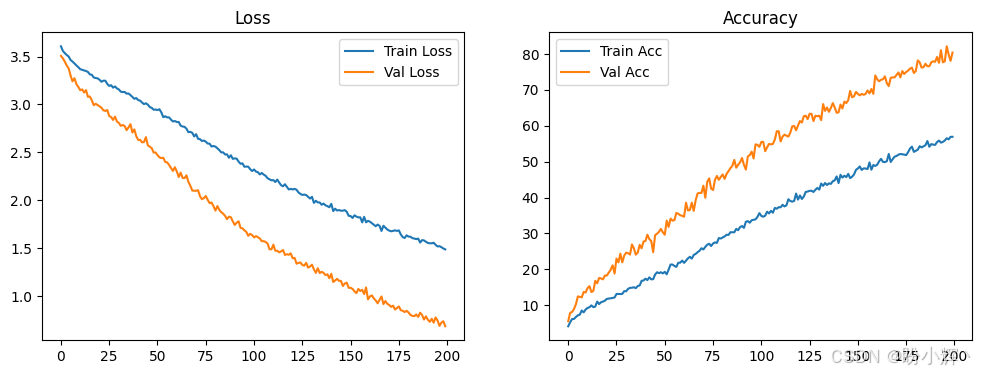
相关链接
视觉Transformer实战 | Transformer详解与实现
视觉Transformer实战 | Vision Transformer(ViT)详解与实现
视觉Transformer实战 | Token-to-Token Vision Transformer(T2T-ViT)详解与实现
视觉Transformer实战 | Pooling-based Vision Transformer(PiT)详解与实现
视觉Transformer实战 | Data-efficient image Transformer(DeiT)详解与实现
视觉Transformer实战 | Cross-Attention Multi-Scale Vision Transformer(CrossViT)详解与实现