摘要
机器人食物舀取是食品制备和服务机器人中的关键操作技能。然而,现有的机器人学习算法,尤其是模仿学习方法,仍然难以处理多样化和动态的食物状态,这常常导致食物溢出和可靠性下降。
本文提出 GRITS:一个面向机器人食物舀取任务的 spillage-aware 引导扩散策略框架。该框架利用引导扩散策略,在舀取过程中最小化食物溢出,并确保食物从初始位置到目标位置的可靠转移。具体而言:
- 设计了一个 spillage 预测器,根据当前观测和动作 rollout 估计溢出概率
- 在仿真环境中构建数据集,使用四种基本形状(球体、立方体、圆锥体、圆柱体)并赋予不同的物理属性
- 推理时,预测器作为可微分的引导信号,将扩散采样过程导向更安全的轨迹
真实世界实验验证:GRITS 在 6 种食物类别上训练,在 10 种未见类别上测试,实现了 82% 的任务成功率和 4% 的溢出率,相比无引导的基线方法减少了 40% 以上的溢出。
1. 研究背景与动机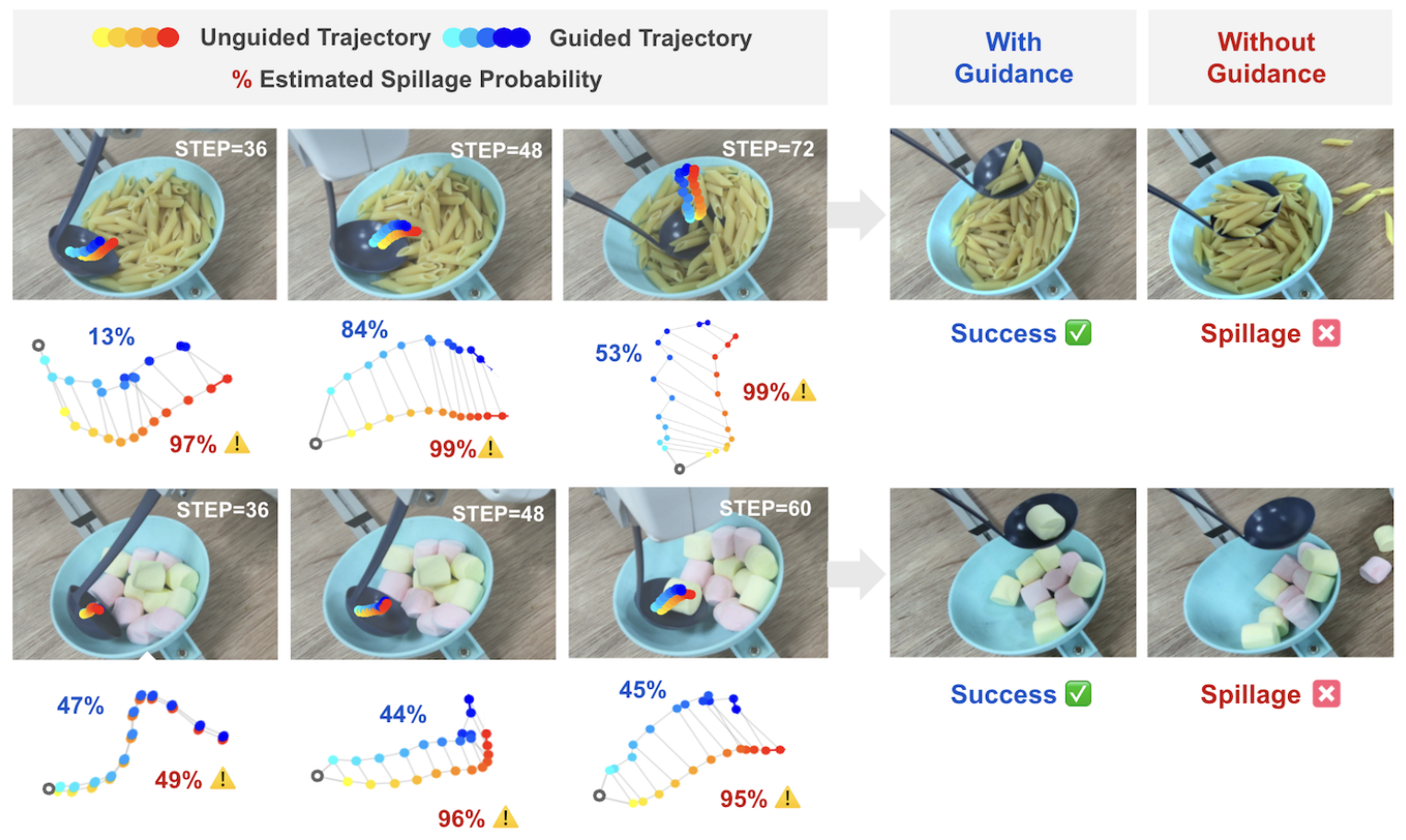
1.1 机器人食物舀取的挑战
食物舀取在以下场景中具有重要应用:
- 食品制备(自动烹饪)
- 辅助喂食(帮助行动不便者)
然而,这一任务面临独特挑战:
| 挑战 | 说明 |
|---|---|
| 食物多样性 | 形状、大小、质地、粘性、颗粒度各异 |
| 动态状态 | 食物在舀取过程中会移动、滚动、粘连 |
| 溢出风险 | 微小偏差就可能导致食物洒出容器外 |
| 数据采集困难 | 为每种食物收集演示数据成本高昂 |
1.2 现有方法的局限
| 方法 | 优点 | 局限 |
|---|---|---|
| 规则方法 | 简单可控 | 无法适应不同食物 |
| 行为克隆 | 学习演示 | 泛化能力有限 |
| 扩散策略 | 强泛化性 | 不考虑溢出风险 |
| SCONE | 主动感知 | 未明确处理安全性 |
1.3 核心研究问题
能否利用引导扩散策略,在测试时动态调整轨迹,既保证舀取成功,又避免食物溢出?
2. 方法:GRITS
2.1 问题形式化
任务定义:机器人从固定容器中舀取食物,转移到随机放置的目标容器。
三阶段分解:
- 舀取(Scooping)→ 核心挑战,本文重点
- 转移(Transferring)→ 运动规划
- 倾倒(Pouring)→ 预定义轨迹
策略输入输出:
- 输入:过去和当前 m 步 RGB-D 观测序列 OtO_tOt
- 输出:未来 n 步末端执行器位姿序列 AtA_tAt
成功标准:
- 大颗粒食物:至少舀起一个
- 小颗粒食物:覆盖勺子的三分之一
2.2 引导扩散策略基础
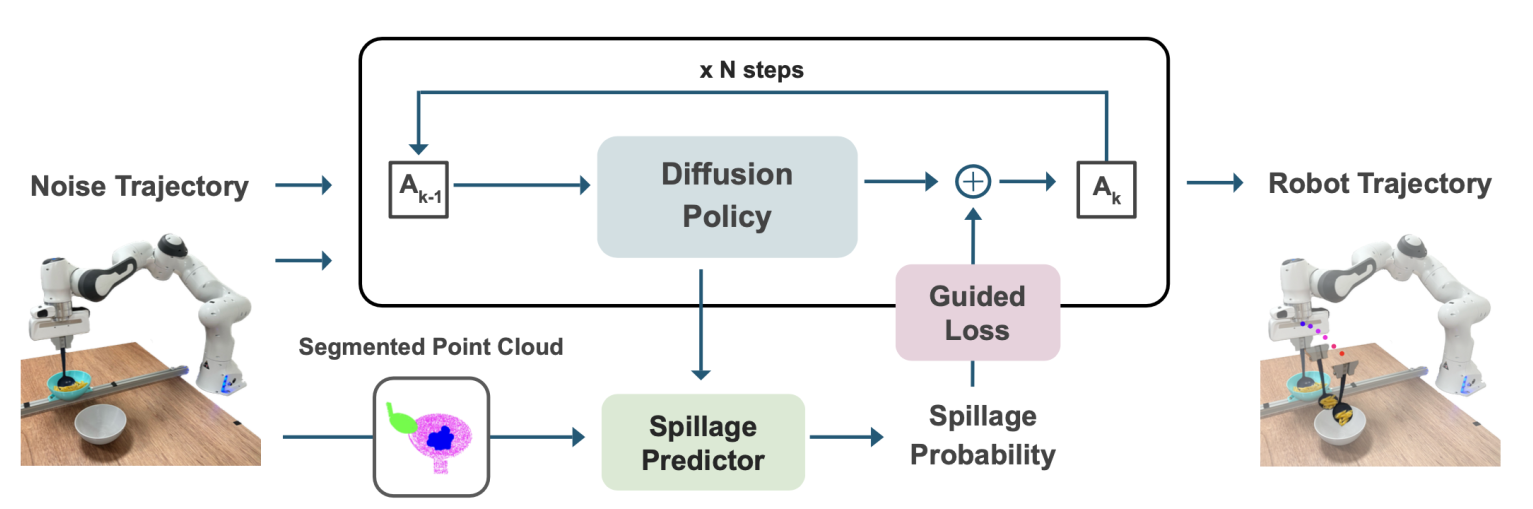
扩散策略训练 :学习条件分布 P(At∣Ot)P(A_t|O_t)P(At∣Ot)
逆向去噪过程:
Ak−1=μk+σkz,z∼N(0,I)A_{k-1} = \mu_k + \sigma_k z, \quad z \sim \mathcal{N}(0, I)Ak−1=μk+σkz,z∼N(0,I)
μk=α(Ak−γϵθ(Ot,At,k))\mu_k = \alpha (A_k - \gamma \epsilon_\theta(O_t, A_t, k))μk=α(Ak−γϵθ(Ot,At,k))
引导采样 :在推理时加入目标函数 JJJ 的梯度引导:
A0∣k=Ak−1−αˉkϵθ(Ak)αˉkA_{0|k} = \frac{A_k - \sqrt{1-\bar{\alpha}k}\epsilon\theta(A_k)}{\sqrt{\bar{\alpha}_k}}A0∣k=αˉk Ak−1−αˉk ϵθ(Ak)
Ak−1=μk−ρ∇J+σkzA_{k-1} = \mu_k - \rho \nabla J + \sigma_k zAk−1=μk−ρ∇J+σkz
其中 ρ\rhoρ 是引导权重,控制目标函数的影响强度。
2.3 GRITS 的核心组件
组件 1:仿真数据采集
为什么用仿真?
- 真实世界采集 spillage 数据需要大量清理工作
- 可能损坏食物,成本高
仿真环境:Isaac Lab,硬件设置与真实平台一致
数据规模:4,000 次舀取轨迹
- 2,000 次 spillage
- 2,000 次 non-spillage
轨迹多样性:
- 对真实演示的均值轨迹施加随机偏移
- X 轴:±7 cm,Y/Z 轴:±5 cm
物体多样性:
| 形状 | 数量 |
|---|---|
| 球体 | 1,000 |
| 立方体 | 1,000 |
| 圆锥体 | 1,000 |
| 圆柱体 | 1,000 |
变化的物理属性:质量、摩擦系数、颗粒大小、数量
组件 2:Spillage 预测器
输入:
- 生成的轨迹 AtA_tAt
- 分割后的物体点云 PtP_tPt
点云构建(图 9 消融实验验证):
| 物体 | 来源 |
|---|---|
| 食物 | 深度图重建 + SAM2 分割 |
| 勺子 | CAD 模型 + 正向运动学 |
| 碗 | CAD 模型 + 预定义标定位姿 |
点云编码:DP3 编码器(PointNet++ 变体,去除 T-Net 和 BatchNorm)
轨迹编码:全连接 MLP
输出 :通过 softmax 输出 spillage 概率 PspillageP_{\text{spillage}}Pspillage
训练损失:交叉熵损失
组件 3:引导扩散策略集成
目标函数 :
J(A0∣k,Pt)=fspillage(A0∣k,Pt)J(A_{0|k}, P_t) = f_{\text{spillage}}(A_{0|k}, P_t)J(A0∣k,Pt)=fspillage(A0∣k,Pt)
引导过程:
- 最小化 spillage 概率(等价于最小化到安全状态的距离)
- 梯度 ∇J\nabla J∇J 用于修正轨迹
延迟激活策略 (阈值 s=30s=30s=30):
- 前 sss 步:无引导,形成粗轨迹
- 后 sss 步:激活引导,精细调整
设计理由:
- 早期步骤的轨迹非常粗糙,引导可能过度修正
- 先形成合理骨架,再优化细节
3. 实验设计
3.1 硬件平台
| 组件 | 规格 |
|---|---|
| 机械臂 | 7-DoF Franka Emika Panda |
| 末端执行器 | 勺子附件 |
| 相机 | 2 × Orbtec Femto Bolt RGB-D |
| 工作空间 | 35 × 30 cm |
| 控制频率 | 10 Hz |
3.2 数据集
训练集(6 种食物):
| 食物 | 类型 |
|---|---|
| 糙米 | 小颗粒 |
| 大豆 | 小颗粒 |
| 绿豆 | 小颗粒 |
| 巧克力球 | 球状 |
| 干枣 | 大颗粒 |
| 橙子 | 大颗粒 |
训练数据量:
- 3 种数量级别
- 5 种碗配置
- 共 80 条演示
测试集(10 种未见食物):
| 食物 | 形状特征 |
|---|---|
| 西米 | 小球状 |
| 红豆 | 小球状 |
| 曼妥思 | 椭球状 |
| 棉花糖 | 软质、可变形 |
| 软糖 | 粘性 |
| 通心粉 | 管状 |
| 西梅干 | 不规则、粘性 |
| 拉面零食 | 波浪形 |
| 混合坚果 | 混合物 |
| 奶茶 | 液体 + 珍珠 |
3.3 基线方法
| 基线 | 说明 |
|---|---|
| Rule-based | 固定策略:移动到中心 → 测高 → 固定深度舀取 |
| Behavior Cloning (BC) | CNN + MLP 直接回归动作 |
| SCONE | 主动感知框架,无显式 spillage 处理 |
| Diffusion Policy (DP) | 标准扩散策略,无引导 |
| Diffusion Policy (Post.) | 后处理:去噪后评估并调整高风险轨迹 |
3.4 评估指标
| 指标 | 定义 |
|---|---|
| Task Success Rate | 成功舀取并转移,无溢出 |
| Spillage Rate | 舀取过程中发生溢出的比例 |
| Scoop Failure Rate | 未能舀起食物的比例 |
注:低 spillage rate 不一定好------如果什么都没舀起来,当然不会溢出。需要结合 success rate 一起看。
4. 实验结果
4.1 整体性能对比(图 6)
| 方法 | 成功率 ↑ | 溢出率 ↓ | 舀取失败率 |
|---|---|---|---|
| Rule-based | 20% | 65% | 15% |
| BC | 45% | 45% | 10% |
| SCONE | 65% | 20% | 15% |
| Diffusion Policy | 70% | 15% | 15% |
| Diffusion Policy (Post.) | 52% | 8% | 40% |
| GRITS (Ours) | 82% | 4% | 14% |
关键发现:
- GRITS 成功率最高(82%),溢出率最低(4%)
- 相比标准 DP,溢出减少 40% 以上
- 后处理方法虽然溢出率低(8%),但舀取失败率高(40%),因为后处理可能牺牲任务目标
4.2 各食物类别性能(图 7)
球状食物(西米、红豆、曼妥思):
- 标准 DP:常有溢出
- GRITS:几乎消除溢出,接近完美
规则形状(棉花糖、软糖、通心粉):
- 棉花糖:软质可变形,仍具挑战
- 软糖:粘性 + 密集堆积
- 通心粉:相对稳定,成功率较高
不规则物品:
- 西梅干:粘性会拖拽邻居,仍困难
- 拉面零食:波纹形状,GRITS 通过稳定插入和旋转获得高成功率
混合/液体(坚果、奶茶):
- GRITS 始终优于标准 DP
4.3 Spillage 预测器消融(图 9)
| 配置 | 成功率 | 溢出率 |
|---|---|---|
| 原始点云(无组合) | 55% | 25% |
| PointNet++ 编码器 | 62% | 18% |
| GRITS(组合点云 + DP3) | 82% | 4% |
结论:
- 原始点云噪声大、几何缺失 → 预警不及时
- PointNet++ 难以捕捉 spillage 相关的物体和运动模式
- 组合点云(已知 CAD + 深度重建)+ DP3 编码器效果最佳
5. 算法流程
Algorithm 1: Spillage-Aware Guided Diffusion Policy
| 步骤 | 操作 |
|---|---|
| 1 | 从高斯分布采样初始噪声轨迹 ATA_TAT |
| 2 | for k=Tk = Tk=T down to 1: |
| 3 | \quad 计算 μk\mu_kμk,采样 Ak−1∼N(μk,σk2I)A_{k-1} \sim \mathcal{N}(\mu_k, \sigma_k^2 I)Ak−1∼N(μk,σk2I) |
| 4 | \quad if k≤sk \leq sk≤s(阈值=30): |
| 5 | \quad\quad 估计干净轨迹 $A_{0 |
| 6 | \quad\quad 用 spillage 预测器梯度修正:Ak−1←Ak−1−ρ∇JA_{k-1} \leftarrow A_{k-1} - \rho \nabla JAk−1←Ak−1−ρ∇J |
| 7 | \quad end if |
| 8 | end for |
| 9 | 返回 A0A_0A0 |
设计要点:
- 延迟激活(k≤sk \leq sk≤s):让扩散策略先形成粗轨迹
- DDIM 采样:训练 100 步,推理 16 步,提高效率
- 引导权重 ρ=2.5\rho = 2.5ρ=2.5
6. 核心创新总结
| 创新点 | 说明 |
|---|---|
| 首个 spillage-aware 引导扩散策略 | 将溢出风险作为可微分目标函数,测试时动态调整轨迹 |
| 仿真数据采集管线 | 4 种基本形状 + 多样化物理属性,避免真实数据采集难题 |
| 组合点云表示 | CAD 模型 + 深度重建 + SAM2 分割,减少 sim-to-real 差距 |
| 延迟引导机制 | 前 30 步不引导,先形成粗轨迹再优化,避免过度修正 |
| 真实世界验证 | 6 种训练 + 10 种未见食物类别,显著优于基线 |
7. 局限性与未来方向
| 局限性 | 未来方向 |
|---|---|
| 仅依赖视觉信息 | 融入力-扭矩和触觉传感,构建更全面的食物表征 |
| 需要已知勺子/碗模型 | 扩展到未知或变化的容器 |
| 仅针对舀取任务 | 扩展到切割、倾倒等其他食物操作任务 |
| 仿真-真实仍有差距 | 更逼真的仿真或域随机化 |
8. 结论
本文提出的 GRITS 是一个面向机器人食物舀取的 spillage-aware 引导扩散策略框架。核心贡献包括:
- 引导机制:将 spillage 预测器集成到扩散策略的采样过程中,测试时动态调整轨迹
- 仿真数据:构建了涵盖多种形状和物理属性的仿真数据集,用于训练 spillage 预测器
- 真实验证:在 6 种训练食物和 10 种未见食物上验证,实现 82% 成功率和 4% 溢出率
GRITS 展示了引导扩散策略在处理需要精细控制和安全性考量的机器人操作任务中的潜力,为食物操作乃至更广泛的接触丰富任务提供了新思路。
9. 资源
- 🌐 项目主页:https://hcis-lab.github.io/GRITS/
- 📄 论文标题:GRITS: A Spillage-Aware Guided Diffusion Policy for Robotic Food Scooping