MLOps 与 AIOps:AI 基础设施的两大支柱
本文系统梳理 MLOps 与 AIOps 的核心概念、技术栈、架构设计与生命周期管理,并结合 AI Infra 实践经验给出落地建议。适合 ML 工程师、平台工程师和技术架构师阅读。
目录
- 背景与简介
- [核心概念辨析:MLOps vs AIOps](#核心概念辨析:MLOps vs AIOps)
- 技术栈全景
- 体系架构设计
- 生命周期管理
- 对比分析
- [在 AI Infra 中的实践](#在 AI Infra 中的实践)
- 未来趋势
- 总结
1. 背景与简介
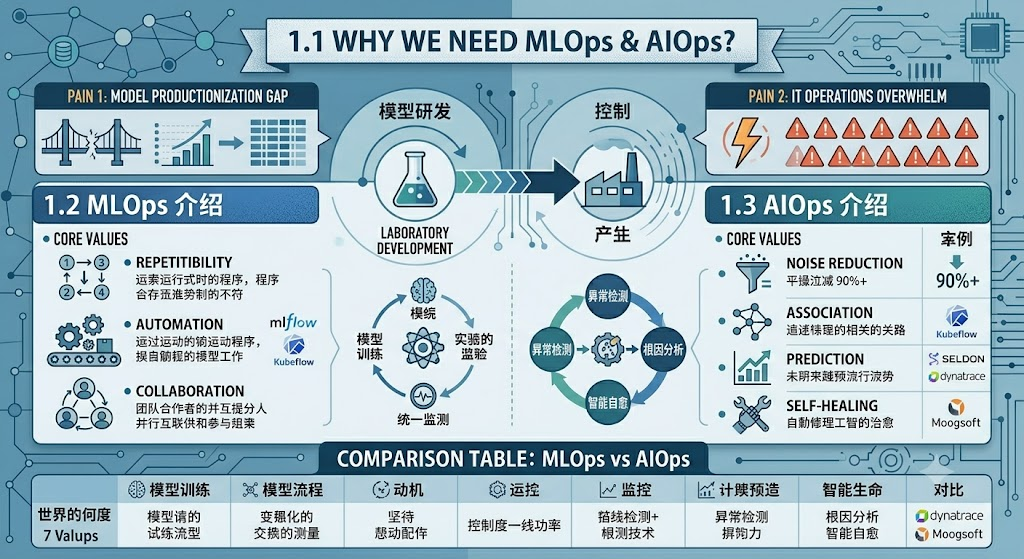
1.1 为什么需要 MLOps 和 AIOps?
随着企业 AI 化程度的加深,机器学习模型从实验室走向生产、IT 运维系统引入智能决策,两大痛点随之浮现:
痛点一:模型生产化难
据 Gartner 调研,超过 85% 的机器学习项目无法顺利进入生产环境。数据科学家写出的模型往往停留在 Jupyter Notebook,难以被工程化、版本化、持续交付。
痛点二:运维规模化失控
现代 IT 系统每天产生数以亿计的日志、指标和告警。传统基于规则的运维体系已无法应对:告警风暴、根因难定位、故障恢复慢,这些问题在云原生时代被进一步放大。
MLOps 和 AIOps 分别从"让 AI 更好地服务业务"和"让 AI 更好地运维系统"两个维度给出了解答。
1.2 MLOps 简介
MLOps(Machine Learning Operations) 是将 DevOps 理念延伸到机器学习领域的工程实践体系。它关注的核心问题是:如何将 ML 模型从研发阶段可靠、高效、可重复地部署到生产,并持续监控和迭代。
MLOps 的核心价值:
- 可重复性:数据、代码、环境全链路版本化,实验结果可复现
- 自动化:从数据准备到模型上线的 CI/CD 流水线
- 可观测性:模型性能、数据漂移、基础设施指标的统一监控
- 协作性:数据科学家、ML 工程师、DevOps 团队的协同工作流
1.3 AIOps 简介
AIOps(Artificial Intelligence for IT Operations) 是将 AI/ML 技术应用于 IT 运维的平台和方法论。它关注的核心问题是:如何用机器智能处理海量运维数据,实现异常检测、根因分析和智能自愈。
AIOps 的核心价值:
- 降噪:从海量告警中识别真正需要关注的事件,告警压缩率通常可达 90%+
- 关联:跨系统、跨维度关联分析,自动发现事件之间的因果关系
- 预测:基于历史数据预测系统瓶颈、容量不足、故障风险
- 自愈:结合自动化平台实现故障的自动处置和恢复
2. 核心概念辨析:MLOps vs AIOps
很多人将这两个概念混淆,下面用一张表格做清晰区分:
| 维度 | MLOps | AIOps |
|---|---|---|
| 本质 | 把 AI/ML 模型做好 | 用 AI/ML 做好运维 |
| 服务对象 | 机器学习工程团队 | IT 运维/SRE 团队 |
| 核心输入 | 训练数据、特征、模型代码 | 日志、指标、事件、链路数据 |
| 核心输出 | 可用的模型服务、推理 API | 告警聚合、根因报告、自愈动作 |
| 关键挑战 | 数据漂移、模型腐化、实验管理 | 数据孤岛、告警风暴、关联分析 |
| 典型工具 | MLflow、Kubeflow、Seldon | Dynatrace、Moogsoft、自研平台 |
| 与 DevOps 关系 | 是 DevOps 在 ML 领域的延伸 | 是 DevOps 工具链的智能化升级 |
一句话区分:MLOps 是"运维 AI 模型",AIOps 是"AI 辅助运维"。
2.1 两者的交汇地带
在现代 AI Infra 中,MLOps 和 AIOps 并非孤立存在:
- MLOps 平台本身需要 AIOps 能力:训练集群、模型服务的稳定性需要智能运维保障
- AIOps 依赖 MLOps 工程实践:AIOps 平台内部的异常检测模型需要 MLOps 流水线来训练、更新和部署
- 统一的 AI Infra 层:GPU 调度、向量数据库、特征平台等基础设施同时服务两者
3. 技术栈全景
3.1 MLOps 技术栈
MLOps 技术栈横跨数据、训练、评估、部署、监控五大环节:
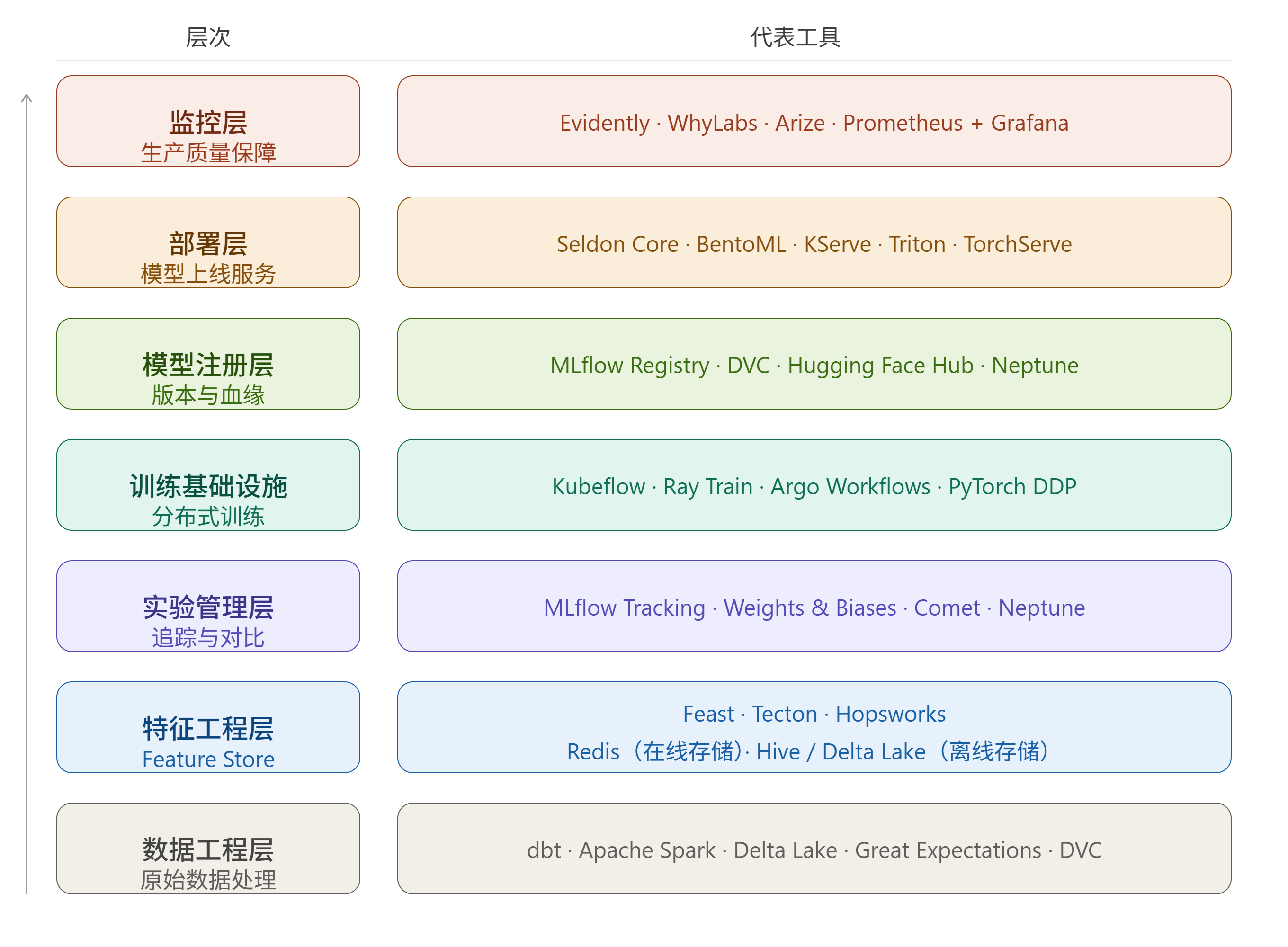
数据与特征层
特征平台(Feature Store)是 MLOps 中常被忽视但极其重要的组件:
- 离线特征存储:通常基于 Hive/Delta Lake,支持历史特征回溯,保证训练数据的时序一致性
- 在线特征存储:通常基于 Redis/Cassandra,支持低延迟特征查询(P99 < 10ms)
- 特征血缘追踪:记录特征从原始数据到模型的完整血缘关系
训练基础设施层
大规模模型训练需要解决以下工程问题:
- 资源调度:Kubernetes + GPU Operator,支持抢占式调度和 Gang Scheduling
- 分布式训练:数据并行(DDP)、模型并行(Tensor/Pipeline Parallelism)
- 实验追踪:参数、指标、artifact 的统一记录,支持实验对比
模型部署层
模型服务化的关键技术点:
- 在线推理:REST/gRPC API,支持 A/B 测试、金丝雀发布
- 批量推理:面向离线场景的批处理推理,通常结合 Spark 或 Ray
- 推理优化:TensorRT/ONNX 量化、模型剪枝、动态批处理
3.2 AIOps 技术栈
AIOps 的数据来源和处理链路相对更复杂:
AIOps 技术栈全景
| 层次 | 核心功能 | 代表工具 |
|---|---|---|
| 数据采集层 | 多源数据接入/标准化 | Prometheus, OpenTelemetry |
| 数据传输层 | 流式/批量数据传输 | Kafka, Flink, Logstash |
| 数据存储层 | 时序/日志/拓扑存储 | InfluxDB, Elasticsearch, CMDB |
| AI 分析层 | 异常检测/关联分析 | 自研算法, Prophet, Isolation Forest, LSTM |
| 智能决策层 | 告警压缩/根因定位 | Moogsoft, BigPanda, 自研 |
| 自动化执行层 | 自愈/变更/通知 | Ansible, PagerDuty, Runbook |
| 可视化层 | 大盘/拓扑/报告 | Grafana, Kibana, 定制大盘 |
可观测性三支柱
AIOps 的数据基础是可观测性(Observability),包含三个核心维度:
| 信号类型 | 描述 | 典型工具 |
|---|---|---|
| Metrics(指标) | 时序数值数据,如 CPU、QPS、延迟 | Prometheus + VictoriaMetrics |
| Logs(日志) | 结构化/非结构化事件记录 | ELK Stack、Loki |
| Traces(链路) | 分布式请求的完整调用链 | Jaeger、Tempo、SkyWalking |
核心 AI 算法
AIOps 平台中常用的算法类型:
- 时序异常检测:Prophet(Facebook 开源)、LSTM 自编码器、Isolation Forest
- 日志模式识别:Drain(日志模板提取)、基于 BERT 的日志语义聚类
- 根因分析:因果图(Causal Graph)、Pagerank 变种算法、拓扑传播模型
- 告警关联:基于时间窗口的关联规则挖掘、图神经网络
4. 体系架构设计
4.1 MLOps 参考架构
标准的 MLOps 平台架构分为四个平面:
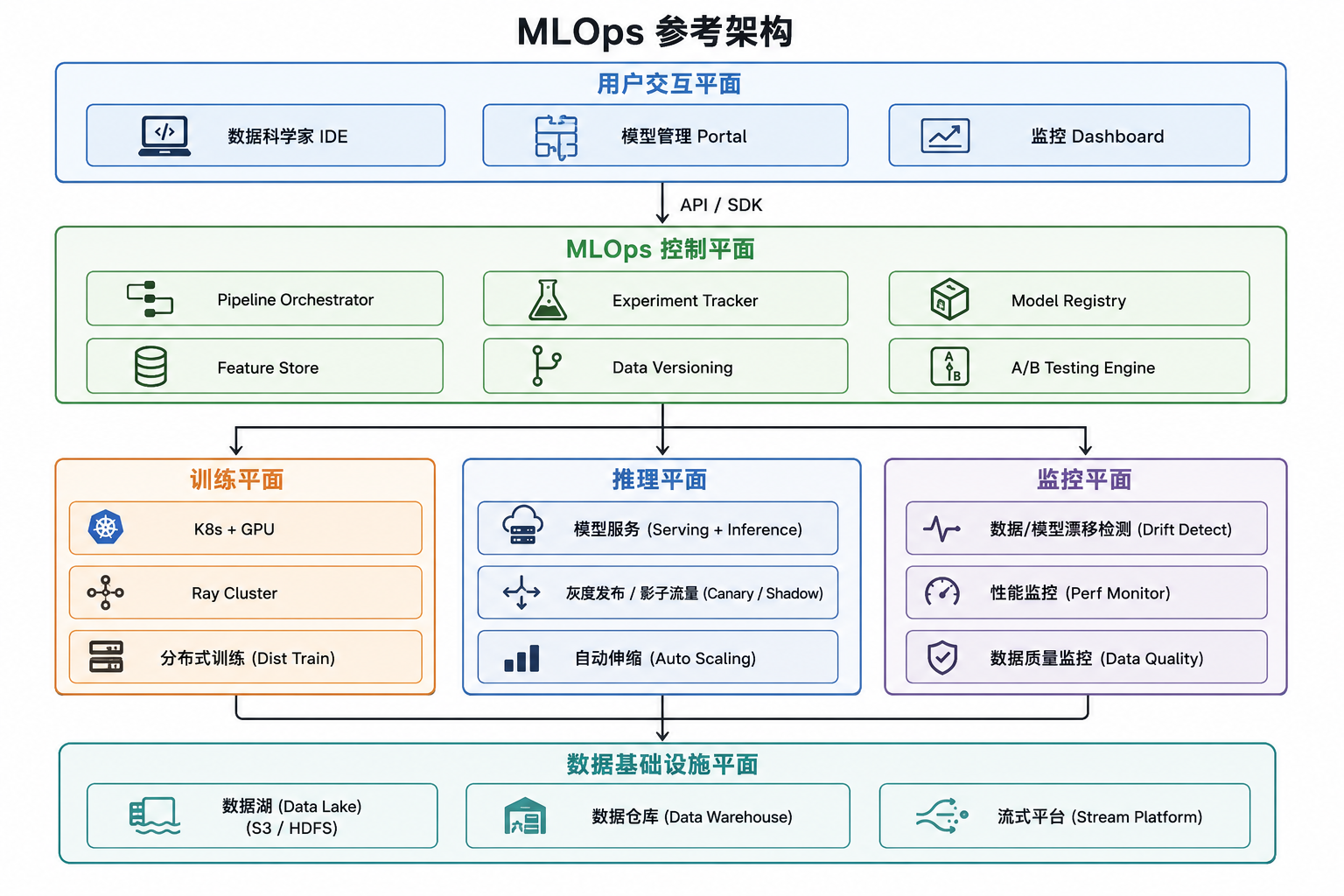
关键设计原则:
- 数据版本化与血缘追踪:每次模型训练必须记录使用的数据集版本、特征版本和代码版本,形成完整的可复现链路
- 不可变部署(Immutable Deployment):模型镜像一旦构建不可修改,通过版本切换而非就地更新来实现升级
- 影子部署(Shadow Deployment):新模型先以影子模式运行,消费真实流量但不返回结果,用于离线评估
- 模型治理:包括模型审计、公平性检测、合规检查,是大型企业 MLOps 平台的必备能力
4.2 AIOps 参考架构
AIOps 架构以数据流为核心,分为实时流处理和离线批处理两条链路:
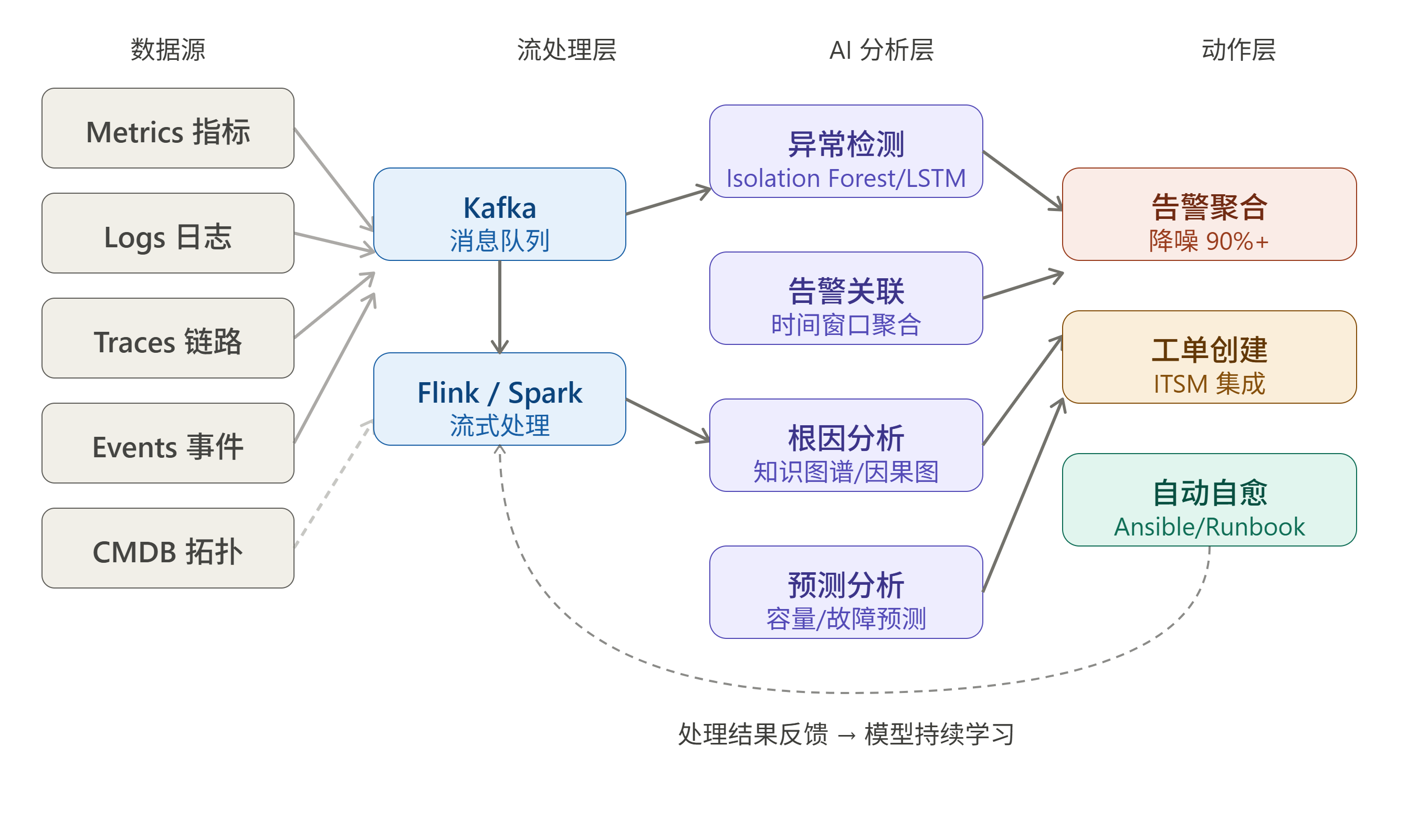
关键设计原则:
- 实时 + 批处理双轨:告警关联需要实时响应(秒级),而模型训练和趋势分析需要批处理(小时级)
- 知识图谱驱动:将 CMDB 中的拓扑关系、服务依赖、变更历史构建成知识图谱,是根因分析的基础
- 人机协同:AIOps 的目标是辅助决策,而非完全替代人类判断。高置信度问题自动处理,低置信度问题推送给人工
- 闭环反馈:运维人员对 AI 决策的确认/否定需要反哺训练数据,持续改进模型
4.3 统一 AI Infra 架构(融合视角)
在成熟的大厂 AI 基础设施中,MLOps 和 AIOps 共享底层基础设施:
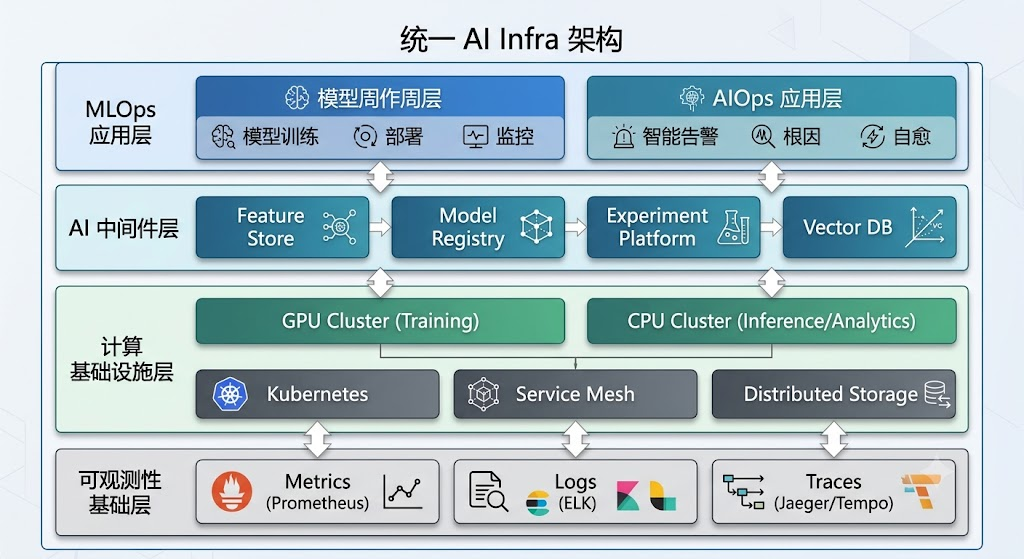
5. 生命周期管理
5.1 MLOps 生命周期
MLOps 生命周期是一个迭代循环,通常分为以下阶段:
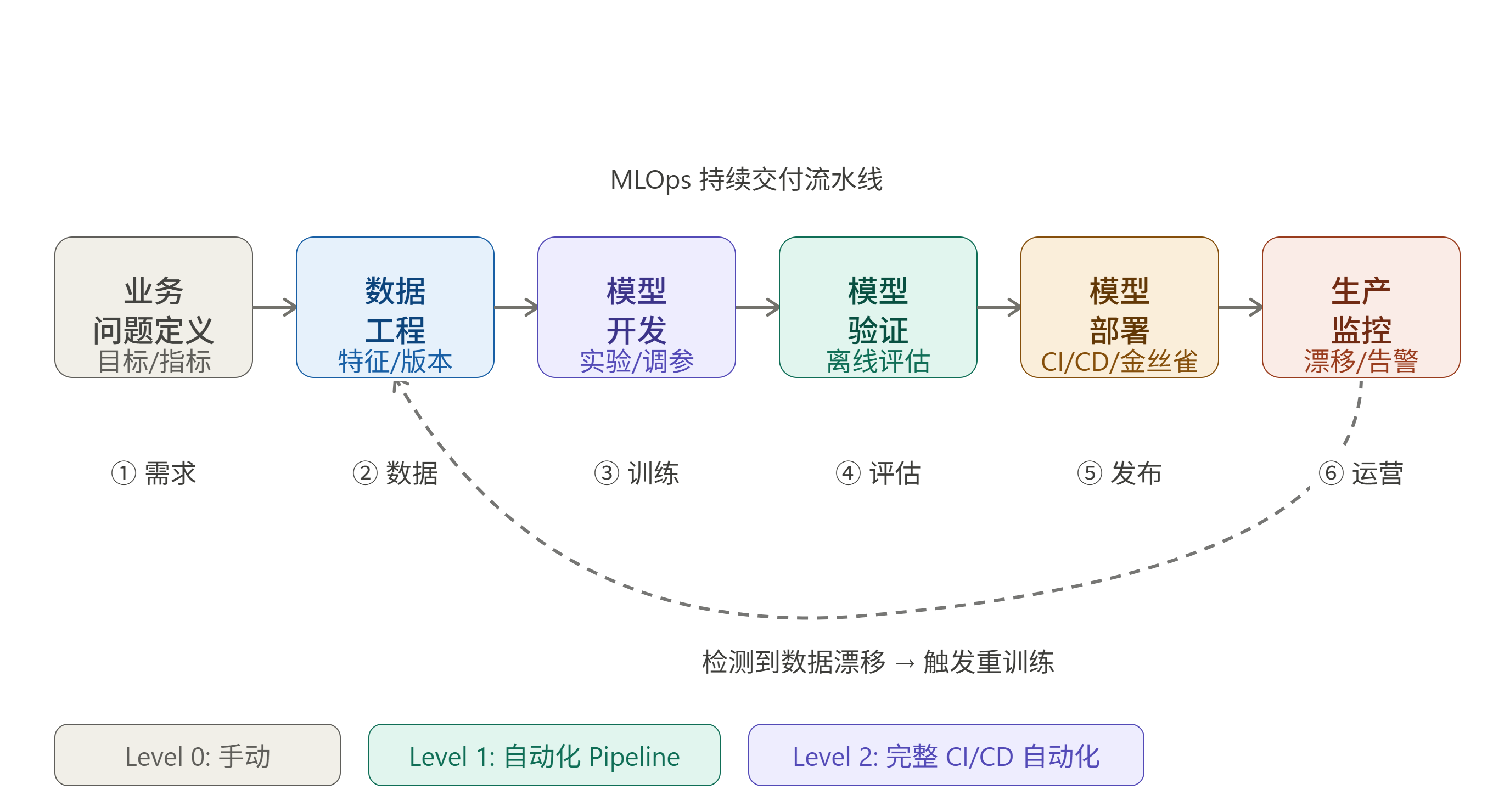
各阶段关键实践:
阶段②:数据工程
- 使用 DVC(Data Version Control)对训练数据集进行版本控制
- 特征工程结果写入 Feature Store,避免训练-服务特征不一致(Training-Serving Skew)
- 数据质量检查:使用 Great Expectations 定义数据契约
阶段③:模型开发
- 实验追踪:所有实验参数、指标、artifact 记录到 MLflow/W&B
- Hyperparameter Tuning:Optuna/Ray Tune 自动化调参,替代手工网格搜索
- 代码评审:模型代码与应用代码同等标准进行 Code Review
阶段⑤:模型部署
- 模型打包:将模型、前后处理逻辑、依赖打包为 OCI 容器镜像
- 发布策略 :
- 蓝绿部署:维护两个生产环境,零停机切换
- 金丝雀发布:逐步将流量从 1% → 10% → 100% 迁移到新模型
- A/B 测试:同时运行多个模型版本,统计显著性验证后全量推送
阶段⑥:生产监控
| 监控维度 | 检测方法 | 告警阈值示例 |
|---|---|---|
| 数据漂移 | PSI(Population Stability Index)、KS 检验 | PSI > 0.2 触发告警 |
| 概念漂移 | 预测分布变化、标签对齐率下降 | 预测均值偏移 > 3σ |
| 模型性能 | AUC/F1/NDCG 指标周期性计算 | 较基线下降 > 5% |
| 服务健康 | 推理延迟、错误率、吞吐量 | P99 延迟 > SLA |
5.2 AIOps 生命周期
AIOps 平台的生命周期围绕数据积累和模型持续优化展开:
① 数据接入 ──→ ② 数据治理 ──→ ③ 模型训练 ──→ ④ 规则/模型部署
│ │
└───────── ⑥ 反馈学习 ←── ⑤ 线上运行 ←────────┘AIOps 的冷启动问题
新建 AIOps 平台面临的最大挑战是"冷启动":历史数据不足、告警标注稀少、业务拓扑不完整。通常的应对策略:
- 第一阶段(0-3个月):以规则引擎为主,积累标注数据
- 第二阶段(3-6个月):引入无监督异常检测(不依赖标签),实现告警压缩
- 第三阶段(6个月+):基于积累的数据训练有监督模型,开启根因分析和预测功能
持续学习机制
AIOps 模型需要适应不断变化的系统环境:
- 在线学习:时序异常检测模型随新数据流式更新基线
- 主动学习:对不确定案例主动请求人工标注,用最少标注获取最大收益
- 定期重训:业务高峰/低谷特征变化显著,模型需定期(周/月)重训
6. 对比分析
6.1 技术深度对比
| 对比维度 | MLOps | AIOps |
|---|---|---|
| 核心数据 | 结构化特征数据、训练集 | 日志、指标、拓扑、事件 |
| 数据规模 | GB ~ TB 级训练集 | PB 级日志/指标流 |
| 实时性要求 | 训练离线为主,推理毫秒级 | 实时检测秒级响应 |
| 算法复杂度 | 深度学习、大模型、强化学习 | 时序分析、图算法、NLP |
| 业务反馈周期 | 天 ~ 周(离线评估) | 分钟 ~ 小时(线上反馈) |
| 可解释性要求 | 中等(部分场景高) | 高(根因必须可解释) |
| 自动化程度 | 较高(CI/CD 成熟) | 中等(自愈还需人工确认) |
| 开源生态 | 极其丰富 | 相对有限,多为商业工具 |
6.2 成熟度对比
MLOps 成熟度分级(Google 定义):
| 级别 | 描述 |
|---|---|
| Level 0 | 手动训练和部署,脚本化流程 |
| Level 1 | 自动化 ML Pipeline,持续训练 |
| Level 2 | 完整 CI/CD,自动化训练、评估、部署 |
AIOps 成熟度分级(Gartner 定义):
| 级别 | 描述 |
|---|---|
| Level 1 | 数据汇聚,统一告警视图 |
| Level 2 | 基于规则的告警关联 |
| Level 3 | ML 驱动的异常检测和根因分析 |
| Level 4 | 预测式运维和自动化自愈 |
6.3 组织能力要求对比
| 能力领域 | MLOps 侧重 | AIOps 侧重 |
|---|---|---|
| 数据工程 | 特征工程、数据版本化 | 数据清洗、拓扑建模 |
| 平台工程 | K8s、GPU 调度、推理优化 | 流处理、时序存储、CMDB |
| 算法能力 | 模型算法研究与优化 | 异常检测、因果推断 |
| 运维能力 | SRE 保障 ML 平台稳定性 | SRE 自身能力的 AI 化 |
| 产品能力 | ML 平台易用性设计 | 告警管理、值班流程设计 |
7. 在 AI Infra 中的实践
7.1 构建 MLOps 平台的最佳实践
实践一:Feature Store 的统一管理
训练-服务特征不一致(Training-Serving Skew)是 MLOps 中最常见也最隐蔽的问题。解决方案:
python
# 使用 Feast 统一管理特征,训练和推理使用同一套特征定义
from feast import FeatureStore
store = FeatureStore(repo_path=".")
# 训练时:从离线存储拉取历史特征
training_df = store.get_historical_features(
entity_df=entity_df,
features=["user_stats:total_purchases", "user_stats:avg_order_value"]
).to_df()
# 推理时:从在线存储实时获取特征(同一套定义,零偏差)
online_features = store.get_online_features(
features=["user_stats:total_purchases", "user_stats:avg_order_value"],
entity_rows=[{"user_id": 1001}]
).to_dict()实践二:模型发布的渐进式策略
yaml
# Kubernetes 金丝雀发布配置示例(使用 Argo Rollouts)
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: model-serving-rollout
spec:
strategy:
canary:
steps:
- setWeight: 5 # 第1步:5% 流量到新版本
- pause: {duration: 10m}
- setWeight: 20 # 第2步:扩大到 20%
- pause: {duration: 20m}
- setWeight: 50 # 第3步:扩大到 50%
- pause: {duration: 30m}
# 若各步骤业务指标正常,全量发布
analysis:
templates:
- templateName: model-accuracy-check
args:
- name: service-name
value: model-serving实践三:多维度模型监控体系
生产中的模型监控要覆盖三个层次:
- 基础设施层监控:Prometheus + Grafana 监控推理服务的 QPS、延迟、GPU 利用率
- 数据质量监控:Evidently 对输入特征分布进行实时检测,发现数据管道异常
- 模型质量监控:定期(每日/每周)在带标签的数据窗口上计算离线指标
python
# Evidently 数据漂移检测示例
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
report = Report(metrics=[DataDriftPreset()])
report.run(
reference_data=reference_df, # 训练时的数据分布
current_data=production_df, # 生产环境近期数据
)
# 若检测到漂移,触发重训练 Pipeline
if report.as_dict()["metrics"][0]["result"]["dataset_drift"]:
trigger_retraining_pipeline()实践四:LLM 时代的 MLOps 新挑战
大语言模型(LLM)的兴起给 MLOps 带来了新挑战:
| 传统 ML 场景 | LLM 场景 |
|---|---|
| 完整重训 | Prompt 工程 + Fine-tuning |
| 数值指标评估(AUC、F1) | LLM-as-Judge、人工评测 |
| 特征漂移检测 | 输出质量退化检测 |
| 模型版本切换 | Prompt 版本管理 |
| 推理延迟 ms 级 | 延迟秒级,需流式输出 |
应对策略:
- 引入 Prompt Management 平台(如 LangSmith、PromptLayer),将 Prompt 版本化管理
- 建立 LLM Evaluation Pipeline,定期运行 benchmark 评测集
- 部署 RAG(Retrieval-Augmented Generation) 时,需要管理 Embedding 模型和向量数据库的版本一致性
7.2 构建 AIOps 平台的最佳实践
实践一:告警治理先行
AIOps 平台上线前,必须先解决告警质量问题。告警噪声过多会导致 AI 模型被"投毒":
告警治理步骤:
- 告警审计:统计过去 30 天各告警的触发频率、处理率、有效率
- 定义黄金指标:每个服务只保留 3-5 个核心 SLI 告警
- 清理僵尸告警:90 天内从未触发的告警规则直接下线
- 告警分级:P0(影响核心业务)、P1(降级)、P2(体验受损)、P3(信息通知)
实践二:可观测性数据标准化
AIOps 的分析质量高度依赖数据质量。建议:
yaml
# OpenTelemetry 资源属性标准(统一打标,便于关联分析)
resource:
attributes:
service.name: "order-service"
service.version: "v2.3.1"
service.namespace: "production"
deployment.environment: "prod"
host.name: "node-0023"
k8s.pod.name: "order-service-7d9b-xxxx"
k8s.namespace.name: "prod-backend"统一的标签体系使得:
- 日志、指标、链路数据可以被准确关联(同一 pod 的三类数据自动聚合)
- 告警自动附带服务归属、版本信息,加速定位
实践三:根因分析的工程化落地
根因分析(RCA)是 AIOps 中技术难度最高的模块,工程化落地要注意:
故障发生
│
▼
① 告警聚合(时间窗口内相关告警合并为一个故障事件)
│
▼
② 拓扑遍历(沿服务依赖图向上游和下游传播,找出影响范围)
│
▼
③ 变更关联(比对 CMDB 变更记录,发现故障前 1 小时内的变更)
│
▼
④ 指标下钻(对疑似根因节点,展开 CPU/内存/网络/DB 等细粒度指标)
│
▼
⑤ 置信度评分(综合多个信号给出 Top-N 根因候选及置信度)
│
▼
⑥ 推送给 On-call 工程师(附带完整证据链和建议修复步骤)实践四:AIOps 与 ITSM 的集成
AIOps 平台必须与 ITSM(IT 服务管理,如 ServiceNow、Jira Service Desk)集成,形成闭环:
- 单向推送:AIOps 检测到故障 → 自动创建工单 → 分配给对应团队
- 上下文传递:工单附带告警详情、根因分析结果、相似历史故障链接
- 处理结果回流:工单处理结果(解决方案、根本原因标注)反哺 AIOps 模型
- SLA 监控:AIOps 平台自动追踪工单处理时效,P0 故障超时自动升级
7.3 典型落地路径
中小规模团队(< 50 人工程团队)
建议技术选型:
- MLOps:MLflow(实验追踪) + Seldon Core(模型部署) + GitHub Actions(CI/CD)
- AIOps:Prometheus + Grafana(监控基础) + 简单规则引擎告警聚合
- 基础设施:单 K8s 集群,按需申请 GPU 节点中大规模团队(50-500 人工程团队)
建议技术选型:
- MLOps:Kubeflow Pipelines + Feast + MLflow Registry + Seldon
- AIOps:ELK Stack + Prometheus/Victoria + Kafka + 自研异常检测服务
- 基础设施:多集群 K8s,GPU 资源池化管理,Object Storage 统一数据湖大规模平台(500+ 人,多业务线)
建议技术选型或自研:
- MLOps:自研 ML Platform(参考 Uber Michelangelo、Meta FBLearner 架构)
- AIOps:自研 + 商业工具(Dynatrace/Datadog 结合内部算法平台)
- 基础设施:混合云,专用 GPU 集群,多租户隔离
- 关键能力:统一 Feature Store、模型治理、成本管控8. 未来趋势
8.1 MLOps 的演进方向
1. LLMOps 的崛起
LLM 时代,MLOps 正在演化为 LLMOps,新增核心关注点:
- Prompt 版本管理与测试:Prompt 的变更如同代码变更,需要版本控制和回归测试
- RAG Pipeline 管理:向量数据库、Embedding 模型、检索策略的协同版本化
- 推理成本控制:LLM 推理成本是传统模型的数十到数百倍,精细化成本监控成为刚需
- 输出安全检测:幻觉检测、毒性过滤、PII 保护需要嵌入生产 Pipeline
2. AutoML 与 MLOps 的融合
未来的 MLOps 平台将内置更多自动化能力:
- 自动化特征选择和特征工程
- 自动触发重训练(基于数据漂移检测结果)
- 自动模型选型(针对新任务类型)
3. 隐私计算与 MLOps
联邦学习、差分隐私的工程化需要 MLOps 平台提供专门支持:多方数据协作训练、模型聚合、隐私预算追踪。
8.2 AIOps 的演进方向
1. 因果 AI 替代相关性分析
当前 AIOps 工具大多依赖相关性分析,误报率高。未来趋势是引入因果推断(Causal Inference):不仅找出"告警 A 和告警 B 同时出现",而是明确判断"A 导致了 B",大幅提升根因分析精度。
2. 生成式 AI 加速 AIOps
LLM 在 AIOps 中的应用场景:
- 自然语言查询:"最近 1 小时订单服务的 P99 延迟为何升高?" → LLM 自动生成查询语句并分析结果
- 告警解读:将技术告警翻译为业务影响描述,降低值班门槛
- 自动生成 Runbook:基于历史处理经验,自动生成故障处理步骤建议
3. AIOps 平台原生化
主流云厂商(AWS、Azure、GCP)和 APM 厂商(Datadog、Dynatrace)正在将 AIOps 能力内置到基础设施平台,推动 AIOps 从独立系统向平台原生能力演进。
9. 总结
MLOps 和 AIOps 代表了 AI 工程化的两个核心方向:
-
MLOps 解决的是"如何让 AI 模型可靠地跑在生产上"。它的核心价值是工程化------将数据科学实验转化为可维护、可迭代的生产系统。
-
AIOps 解决的是"如何用 AI 让系统运维更智能"。它的核心价值是智能化------用机器智能处理人类已无力独立应对的运维数据规模。
两者的共同点是:都需要扎实的数据工程基础、成熟的 ML 工程能力,以及强大的组织协同。
在 AI Infra 实践中,建议遵循以下原则:
- 从问题出发,而非从工具出发:先明确要解决什么问题,再选择合适的工具,避免"为了 MLOps 而 MLOps"
- 循序渐进,避免大跃进:从最小可行平台开始,随业务规模逐步增加能力
- 数据质量优先:无论 MLOps 还是AIOps,数据质量都是第一优先级,垃圾进,垃圾出
- 工具链标准化:统一技术选型,降低认知负担,提升团队协作效率
- 反馈闭环:建立从生产反馈到模型改进的完整闭环,持续提升系统智能化水平
随着 LLM 和生成式 AI 的普及,MLOps 和 AIOps 都在快速演进。把握这一趋势,构建具有前瞻性的 AI Infra 能力,是技术团队在 AI 时代保持竞争力的关键。