从"检测到一个人"到"确认他正在奔跑":双模型、Homography 与速度校验实战
最近我在做一个地铁站人员奔跑检测的小型验证项目。
一开始,我的想法很直接:检测出画面中的人,跟踪他的运动轨迹,再根据移动速度判断是否奔跑。但真正开始测试以后,很快就发现这个问题没有看起来那么简单。
摄像头的安装高度、俯视角度和焦距各不相同。同一个人在画面近处移动十几个像素,和在画面远处移动十几个像素,代表的真实距离完全不同。如果直接使用像素速度,算法几乎无法跨摄像头复用。
另一方面,如果对画面中的每个人都持续计算轨迹、距离、速度、步频等指标,计算量和误报率都会增加。
经过几轮测试,我最终将 demo 调整为一套"双模型级联 + 地面坐标校验"的方案:
text
人头人身检测模型
-> 获得人员 bbox,并维护跟踪对象
奔跑现象检测模型
-> 提出疑似奔跑候选框
候选框与人员框关联
-> 为对应跟踪对象设置 running 状态
只有 running 状态的对象
-> 执行 Homography、距离、速度、步频等后续逻辑校验这篇文章记录当前 demo 的开发思路、核心算法、踩过的坑,以及后续准备如何把它改造成可部署的框架模块。
一、为什么不直接依赖奔跑检测模型
训练一个单类别的"奔跑"检测模型,确实可以直接在画面中框出正在奔跑的人。
但只依赖单帧检测模型,会遇到几个问题:
- 快走、身体前倾、追逐动作可能被误判成奔跑。
- 遮挡或姿态变化可能导致奔跑框间歇性消失。
- 单帧检测结果没有稳定的人员身份,无法持续计算某个人的运动轨迹。
- 无法回答"这个人实际移动了多远、速度是否持续、是否只是原地动作"等问题。
因此,我把奔跑模型定位为一个候选状态触发器,而不是最终判断器。
人头人身检测和跟踪模型负责回答:
画面里有哪些人?这个 bbox 在前后帧中属于哪个人?
奔跑检测模型负责回答:
当前帧中,哪些人体外观表现出了奔跑特征?
最后再使用轨迹和速度逻辑回答:
这个人是否真的在一段时间内快速移动?
这种级联方式既保留了深度学习模型对姿态和动作的识别能力,也增加了基于运动几何的可解释校验。
二、当前 demo 的整体结构
当前目录中的主要文件如下:
text
homography_speed_demo.py 主程序
PERSON_MODEL.onnx 行人检测模型
RUN_MODEL.onnx 奔跑现象单类别检测模型
README.md 参数、标定与部署注意事项两个 ONNX 模型的作用不同:
| 模型 | 输入尺寸 | 作用 |
|---|---|---|
PERSON_MODEL.onnx |
960 x 544 |
检测行人,为跟踪与脚底点计算提供 bbox |
RUN_MODEL.onnx |
640 x 384 |
检测疑似奔跑现象,触发 running 候选状态 |
主流程可以概括为:
text
读取视频帧
|
+-- 人体检测 / 跟踪
|
+-- 奔跑候选检测
|
+-- 奔跑框与人体框关联
|
+-- 更新 running 状态机
|
+-- 计算脚底点与地面坐标轨迹
|
+-- running 状态开启时,累计有效速度与距离
|
+-- 输出可视化视频正常走路与奔跑状态示例
下面两张图来自当前 demo 的实际运行结果。
正常走路时,人体跟踪框保持绿色,状态显示为 normal,后续奔跑逻辑处于 standby:

当奔跑现象检测框与人体框成功关联,并满足状态机条件后,人体状态切换为 RUNNING,Logic Check 变为 ENABLED,系统才开始重点校验该对象的距离、速度等运动指标:

图中的黄色四边形是用于建立 Homography 的地面标定区域,蓝色曲线是脚底点形成的运动轨迹。示例图中的四边形只是为了快速验证流程,按照宽高 1:1 随手绘制,并没有严格对应真实物理世界的比例,因此映射后的距离和速度存在偏差。
正式使用时,画面中最好存在可测量的参照物,例如:
- 已知尺寸和排列数量的地砖。
- 车位线、通道线、闸机间距等已知尺寸结构。
- 现场测量得到的地面矩形或规则区域。
标定四边形映射到目标平面时,必须尽量按照参照物的真实宽高比例设置 world_width/world_height。例如标定区域横向覆盖 8 块正方形地砖、纵向覆盖 4 块,则应设置为 8:4,而不是为了方便直接映射为 1:1。
三、统一 ONNX 检测器
两个模型虽然类别数量和输入尺寸不同,但都属于 YOLO 风格的 ONNX 输出,因此 demo 中复用了同一个检测器。
检测器初始化时读取模型的固定输入尺寸:
python
class YoloOnnxDetector:
def __init__(self, model_path, conf_thresh, iou_thresh):
self.session = ort.InferenceSession(
model_path,
providers=["CPUExecutionProvider"],
)
self.input = self.session.get_inputs()[0]
self.input_name = self.input.name
self.input_h = int(self.input.shape[2])
self.input_w = int(self.input.shape[3])
self.conf_thresh = conf_thresh
self.iou_thresh = iou_thresh推理时完成 resize、RGB 转换、归一化和 NCHW 排列:
python
resized = cv2.resize(frame, (self.input_w, self.input_h))
tensor = resized[:, :, ::-1].transpose(2, 0, 1)
tensor = np.ascontiguousarray(tensor[None], dtype=np.float32) / 255.0
output = self.session.run(None, {self.input_name: tensor})[0]这里有一个实际踩过的坑。
人头人身模型是两类别输出,单条预测为:
text
[cx, cy, width, height, head_score, body_score]奔跑模型是单类别输出,单条预测为:
text
[cx, cy, width, height, running_score]因此通用后处理不能假设输出至少有 6 列,而要兼容至少 5 列:
python
if arr.shape[1] < 5:
raise RuntimeError(f"Expected at least 5 output columns, got {arr.shape}")这个小细节很容易在接入第二个模型时被忽略。
四、为什么使用脚底中心点
人员 bbox 中心并不位于地面平面上。
如果直接把 bbox 中心投影到地面坐标,会因为人物身高和摄像机视角产生明显偏差。相比之下,人脚与地面接触,因此 bbox 底边中心更适合作为人员在地面上的位置近似。
核心代码非常简单:
python
def bbox_bottom_center_xyxy(bbox):
x1, _y1, x2, y2 = bbox
return (x1 + x2) * 0.5, y2但这个点是否可靠,依赖于人体检测框质量:
- 人体下半身被闸机或其他人遮挡时,bbox 底部不是真实脚底。
- 模型框上下抖动时,脚底轨迹也会抖动。
- 检测到半身时,脚底点几乎不可用。
因此正式框架中,脚底点应该附带置信度,而不是默认永远可信。
五、使用 Homography 建立地面坐标系
像素坐标不能直接比较不同位置的运动距离。解决这个问题的核心,是使用 Homography 将画面中的地面平面映射到一个统一坐标平面。
Homography 的基本原理
Homography,也称单应性变换,用于描述同一个平面在两个不同视角或两个平面坐标系之间的投影关系。
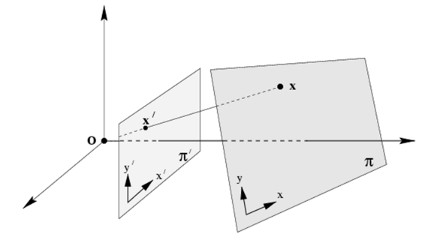
图中可以把摄像机成像平面理解为一个平面,把地面理解为另一个平面。只要目标点都位于同一个真实地面平面上,就可以通过一个 3 x 3 矩阵,将画面中的地面像素点映射到目标地面坐标系。
使用齐次坐标表示时,映射关系为:
text
[h11 h12 h13] [u]
s [X Y 1]^T = [h21 h22 h23] [v]
[h31 h32 h33] [1]其中:
(u, v)是摄像机画面中的像素坐标。(X, Y)是映射后的地面平面坐标。H是3 x 3Homography 矩阵。s是齐次坐标中的比例因子。
展开并完成归一化后:
text
X = (h11*u + h12*v + h13) / (h31*u + h32*v + h33)
Y = (h21*u + h22*v + h23) / (h31*u + h32*v + h33)Homography 矩阵整体乘以任意非零常数都表示同一个映射,因此它实际上有 8 个独立自由度。一个点对可以提供两个独立方程,所以至少需要 4 组不共线的地面点对应关系,才能求出这个映射。
在当前 demo 中,画面四点与目标地面四点一一对应:
text
image top-left -> world (0, 0)
image top-right -> world (world_width, 0)
image bottom-right -> world (world_width, world_height)
image bottom-left -> world (0, world_height)在画面中选择四个同属于地面的点,并为它们指定目标平面坐标:
python
world_pts = np.array(
[
[0, 0],
[world_width, 0],
[world_width, world_height],
[0, world_height],
],
dtype=np.float32,
)
H, _ = cv2.findHomography(img_pts, world_pts)之后,任何脚底像素点都可以通过矩阵 H 映射到地面坐标:
python
def pixel_to_world(point, H):
p = np.array([point[0], point[1], 1.0], dtype=np.float32)
q = H @ p
q = q / q[2]
return float(q[0]), float(q[1])这里需要特别理解一点:Homography 能把透视四边形"拉正"为矩形,但它并不知道真实世界中的矩形究竟有多宽、多高。真实尺度和比例完全来自我们提供的 world_width/world_height。
如果真实区域宽高比是 2:1,却错误地映射为 1:1,则目标坐标中的一个方向会被压缩或拉伸。即使四边形看起来被成功拉正,后续计算出的运动方向、距离和速度仍然会产生系统性偏差。
因此,图片中存在可计量参照物时,应优先按真实比例进行绘制和映射:
text
真实区域:横向 8 块砖,纵向 4 块砖
推荐设置:world_width=8, world_height=4
真实区域:宽 6 米,深 9 米
推荐设置:world_width=6, world_height=9, unit=m如果完全无法获得真实尺寸,也应尽量保证宽高比例正确。绝对尺度未知时可以继续使用 body/s 做相对判断,但宽高比例错误依然会破坏地面运动几何。
标定区域是整个算法最敏感的部分
测试中最明显的经验是:
Homography 数学公式并不复杂,真正决定结果的是四个标定点是否可靠。
标定时需要特别注意:
- 四点必须位于同一地面平面。
- 标定四边形应尽量覆盖人员实际运动区域。
- 不要只选择一小块地砖,再对很远区域进行外推。
world_width/world_height的比例应接近真实地面比例。- 广角镜头畸变明显时,应先做畸变校正。
- 四个对应点不应接近共线,否则 Homography 求解会非常不稳定。
- 四点点击误差越大,映射后的距离和速度误差越大。
demo 会检查脚底点是否位于标定区域内:
python
inside_plane = (
cv2.pointPolygonTest(img_pts.astype(np.float32), foot, False) >= 0
)如果画面中持续出现:
text
Inside Plane: NO说明当前速度主要来自 Homography 外推区域,可靠性会明显下降。
六、为什么速度使用 body/s
在大规模部署中,很难要求每个摄像头都精确测量地面区域的真实米制尺寸。
因此当前推荐模式不是直接输出严格的 m/s,而是输出:
text
body/s它表示:
一个人每秒在地面坐标中移动了多少个"自身高度尺度"。
算法形式为:
text
Speed(body/s)
= 地面坐标中的脚底位移
/ 当前人物高度对应的局部地面尺度
/ 时间当前默认使用 Homography 在脚底点附近的局部尺度,也就是局部 Jacobian 近似:
python
def estimate_body_height_ground(foot, body_height_px, H, mode):
foot_w = pixel_to_world(foot, H)
x_w = pixel_to_world((foot[0] + 1.0, foot[1]), H)
y_w = pixel_to_world((foot[0], foot[1] + 1.0), H)
sx = math.hypot(x_w[0] - foot_w[0], x_w[1] - foot_w[1])
sy = math.hypot(y_w[0] - foot_w[0], y_w[1] - foot_w[1])
return body_height_px * math.sqrt(sx * sy)计算帧间速度时,再除以该尺度:
python
dx = smooth_x - prev_metric[0]
dy = smooth_y - prev_metric[1]
ref_height = (body_height_metric + prev_body_height_metric) * 0.5
dx /= ref_height
dy /= ref_height
speed = math.hypot(dx, dy) / dt为了便于理解,也可以按平均身高近似换算:
text
Approx Speed(m/s) = Speed(body/s) * person_height_m例如使用 person_height_m=1.7:
text
1.8 body/s ≈ 3.06 m/s需要强调的是,这仍然是近似值。body/s 更适合作为跨摄像头奔跑判断指标,而不是严格的物理测速结果。
七、轨迹为什么需要平滑
即使人员实际静止,检测 bbox 也会在相邻帧中轻微变化。速度又是位置差分,任何小抖动都会被放大。
当前 demo 支持:
text
EMA
Kalman
NoneEMA 的实现形式为:
python
self.ema = (
alpha * measurement
+ (1.0 - alpha) * self.ema
)当前默认:
text
--smooth ema
--ema_alpha 0.35alpha 越大,响应越快,但速度曲线更容易抖动;alpha 越小,曲线更稳定,但会延迟速度峰值。
实际告警不应依赖单帧峰值,应该使用时间窗口中的中位速度、平均速度、净位移等指标。
八、奔跑框如何关联到人体对象
奔跑模型输出的是"疑似奔跑框",人体模型输出的是"人体框"。要给正确的跟踪对象设置 running 状态,必须先完成两类框的关联。
当前 demo 同时参考标准 IoU 和较小框覆盖率:
python
def bbox_overlap_min_area(a, b):
inter = intersection_area(a, b)
smaller = min(bbox_area(a), bbox_area(b))
return inter / smaller关联逻辑为:
python
if best_iou >= iou_thresh or best_overlap >= overlap_thresh:
return matched_detection这样做是因为两个模型对同一个人的框可能松紧不同。奔跑模型可能框得更大,而人体模型框得更紧,此时标准 IoU 可能不高,但两者明显属于同一个人。
正式框架更推荐"奔跑框对人体框的覆盖率"
当前 demo 使用的是"交集除以较小框面积"。在正式多目标框架中,我更推荐直接计算:
text
body_coverage
= intersection(run_bbox, body_bbox)
/ area(body_bbox)原因是我们真正关心的问题是:
这个人体框是否被奔跑候选框充分覆盖?
同时还需要增加面积比例限制,避免一个很大的奔跑框同时覆盖多个人:
text
body_coverage >= 0.7
AND run_area / body_area <= 2.5如果多个跟踪对象满足条件,则选择覆盖率最高的对象。
九、当前 running 状态机
当前 demo 使用一个简单的进入/退出滞回状态机。
核心代码如下:
python
class RunningState:
def __init__(self, enter_frames, exit_frames):
self.enter_frames = enter_frames
self.exit_frames = exit_frames
self.hit_count = 0
self.miss_count = 0
self.is_running = False
def update(self, matched):
if matched:
self.hit_count += 1
self.miss_count = 0
if self.hit_count >= self.enter_frames:
self.is_running = True
else:
self.hit_count = 0
self.miss_count += 1
if self.miss_count >= self.exit_frames:
self.is_running = False默认逻辑为:
text
连续命中 3 次 -> 进入 RUNNING
连续丢失 8 次 -> 退出 RUNNING只有进入 RUNNING 状态后,才累计后续逻辑校验结果:
python
if running_state.is_running:
validated_distance += frame_distance
validated_peak_speed = max(validated_peak_speed, speed)
validated_frames += 1这种方式简单直观,但存在一个明显不足:
从第一次奔跑命中到正式进入 RUNNING 之前的位移没有被计入有效统计。
因此它适合 demo 验证,但不是最终推荐方案。
十、下一步推荐:候选时间窗口
更合理的设计,是从第一次奔跑模型成功关联到人体对象时,就保存一个候选窗口锚点。
推荐状态流程:
text
NORMAL
|
| 第一次 running 成功关联
v
CANDIDATE
|
| 开启固定推理周期窗口
| 记录初始位置、时间和后续轨迹
v
窗口结束
|
+-- 命中次数达到阈值 -> RUNNING
|
+-- 命中不足 -> NORMAL,丢弃候选窗口例如每 3 个视频帧运行一次奔跑模型:
text
窗口长度:8 个奔跑模型推理周期
确认条件:8 次中至少命中 4 次在 25 FPS 视频中:
text
8 个推理周期 x 3 帧 ≈ 24 帧 ≈ 0.96 秒窗口确认后,应使用第一次命中的锚点回算整个窗口中的运动指标,而不是从确认帧才开始计算。
推荐同时计算:
text
净位移速度 = 起点到终点距离 / 窗口时间
路径速度 = 窗口累计移动距离 / 窗口时间
中位速度 = 窗口内各段速度的中位数
命中比例 = running 命中次数 / 推理次数最终判定可以写成:
text
命中次数 >= 4
AND 净位移速度 > threshold_net_speed
AND 路径速度 > threshold_path_speed
AND 净位移 > threshold_displacement
AND 速度置信度足够这个方案可以过滤以下误报:
- 原地做出类似奔跑的动作。
- 单帧身体前倾。
- 检测框突然跳动造成的速度尖峰。
- 奔跑模型偶发单帧误检。
十一、单目标 demo 与正式多目标框架的差异
当前 demo 仍然是轻量单目标逻辑,只维护一个 last_bbox。
当画面中存在多人时,单目标选择器可能跟到另一个静止人员。测试中就遇到过这种情况:奔跑模型准确框住了横穿画面的人,但单目标逻辑仍然维护着画面顶部的另一个人,导致两个框完全没有重叠。
为缓解这个问题,demo 在出现奔跑候选时,会优先选择与候选框重叠的人体:
python
body_det = pick_body_detection(
detections,
body_class,
last_bbox,
run_detections,
run_match_iou,
run_match_overlap,
)但正式框架不应该继续使用单个 last_bbox,而应该为每个 tracker ID 保存独立状态:
text
track_id
body_bbox
foot_trajectory
world_trajectory
running_window
running_state
speed_history
distance_history
confidence
last_seen_time推荐结合 BYTETrack、OC-SORT、DeepSORT 或现有业务框架中的多目标 tracker。
双模型级联应当作用于所有活跃 track:
text
for each run_detection:
找到覆盖率最高的 body track
更新该 track 的 running 窗口
for each body track:
根据自己的状态和轨迹完成后续校验十二、速度结果也应该有置信度
在工程系统中,输出一个 Speed=1.8 body/s 还不够。
同样的速度数值,在不同情况下可信程度完全不同:
- 脚底点位于 Homography 标定区域内,可信度高。
- 脚底点在标定区域很远之外,可信度低。
- bbox 高度稳定,可信度高。
- 人体被严重遮挡,可信度低。
- 轨迹连续几十帧,可信度高。
- 只有两帧位置,可信度低。
建议最终输出:
text
running_score
speed_body_s
approx_speed_mps
speed_confidence
inside_plane
track_age
running_hit_ratio
net_displacement
path_distance速度置信度可以综合:
text
检测置信度
奔跑模型置信度
人体覆盖率
脚底是否位于标定区域内
Homography 外推距离
bbox 高度稳定性
轨迹连续长度
遮挡状态这样后续业务规则就不必把一个不稳定的速度值当作绝对事实。
十三、当前 demo 的运行方式
交互选择 Homography 四点并运行双模型:
powershell
& 'C:\Users\zhang\.conda\envs\yolov8\python.exe' `
.\homography_speed_demo.py `
--video .\test2.mp4 `
--model .\PERSON_MODEL.onnx `
--run_model .\RUN_MODEL.onnx使用已知四点直接运行:
powershell
& 'C:\Users\zhang\.conda\envs\yolov8\python.exe' `
.\homography_speed_demo.py `
--video .\test2.mp4 `
--model .\PERSON_MODEL.onnx `
--run_model .\RUN_MODEL.onnx `
--homography_points "566,460;981,458;661,821;218,706" `
--world_width 4 `
--world_height 4奔跑模型抽帧推理:
powershell
--run_detect_every 3当前连续命中状态机参数:
powershell
--run_enter_frames 3 --run_exit_frames 8不显示窗口,只输出视频:
powershell
--no_show双模型在 CPU 上逐帧推理会比较慢。正式部署时需要考虑:
- 奔跑模型抽帧推理。
- 多路视频批处理。
- GPU/NPU 推理。
- 只对有效 ROI 运行模型。
- 对 normal 对象降低后续逻辑计算频率。
十四、这套方案目前最值得保留的经验
回头看这个 demo,真正有价值的并不是某一个速度阈值,而是下面几条设计经验。
1. 奔跑检测模型适合做候选触发器
让模型负责发现动作外观,让轨迹和速度负责验证真实运动,两者结合比单独使用任何一种方式都更稳。
2. 后续重逻辑只对候选对象执行
只有进入候选或 running 状态的人员,才需要计算详细距离、速度、步频和持续时间。这种级联方式更适合多摄像头部署。
3. Homography 标定质量决定速度上限
标定区域太小、点位不准、宽高比例错误、人员长期处于外推区域,都会让速度结果失真。算法框架必须把标定质量和 Inside Plane 纳入置信度。
4. 不要用单帧峰值定义奔跑
奔跑是一个时序事件。命中比例、净位移、路径速度、持续时间和轨迹稳定性,比某一帧的速度峰值更重要。
5. 正式系统必须以 tracker ID 为中心
每个人都应该拥有独立状态机和独立轨迹。双模型框关联、速度计算和告警窗口,都应绑定到 tracker ID,而不是绑定到某个临时 bbox。
结语
人员奔跑检测看起来像一个简单的动作识别问题,但真正落到监控场景后,它同时涉及目标检测、多目标跟踪、地面几何映射、时序状态机、速度估计和业务规则。
当前 demo 已经验证了一个可行方向:
text
奔跑模型负责提出候选
人体跟踪负责稳定身份
Homography 负责统一地面坐标
速度与位移负责完成逻辑校验下一步最值得做的工作,是将当前连续命中状态机升级为"首次命中锚点 + 固定推理周期窗口",并将整套逻辑迁移到真正的多目标 tracker ID 上。
当系统能够回答"谁在跑、持续多久、移动多远、结果有多可信"时,它才真正从一个检测 demo 变成可用于业务框架的奔跑事件算法。