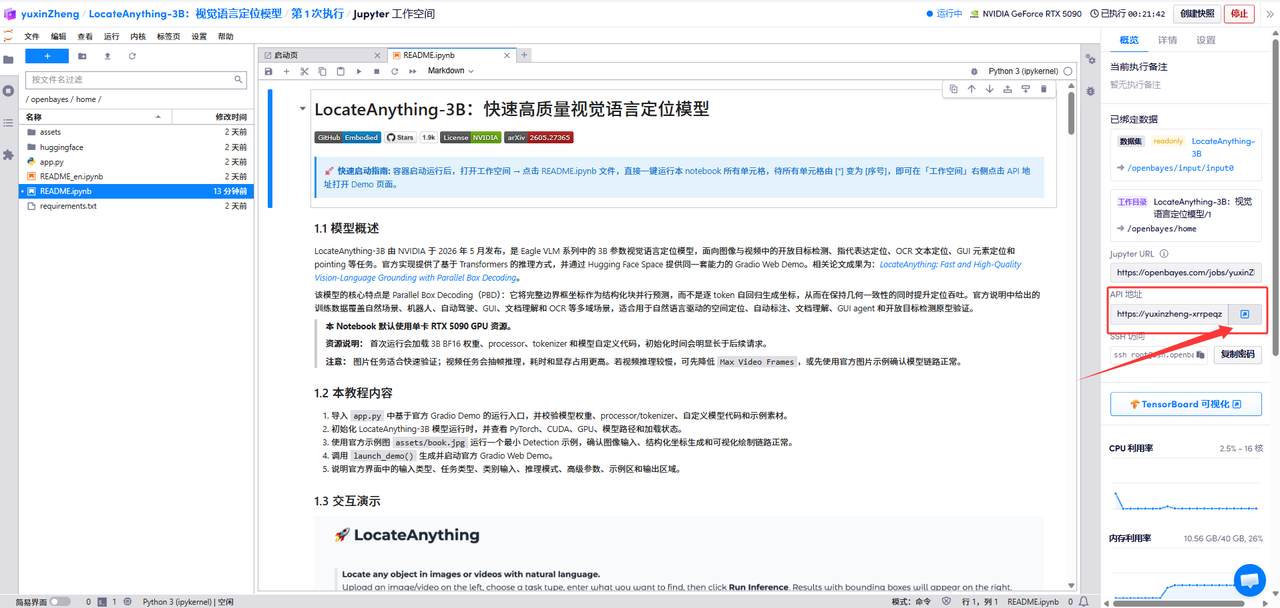
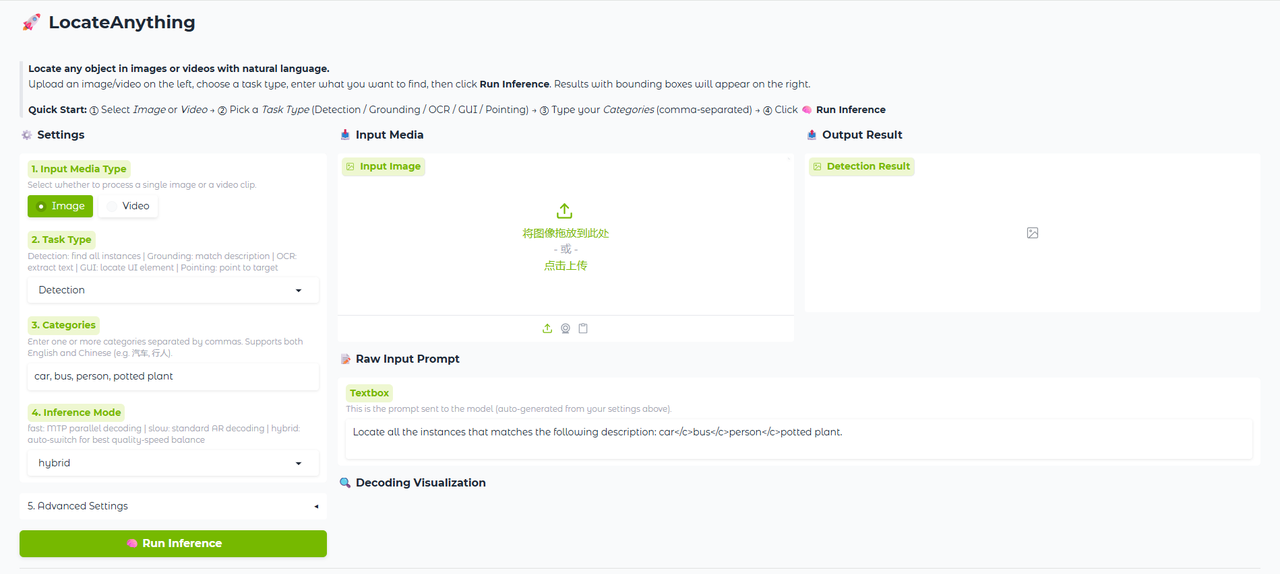
来自 NVIDIA 的新作,LocateAnything-3B,主打视觉语言定位。说实话,看到「3B」这数字我第一反应:能有多能打?结果一看介绍,直接破防了。
它搞了个叫 Parallel Box Decoding 的东西,说白了就是:不再一个 token 一个 token 地憋坐标,而是整框并行预测。就像从「手写快递单」进化到「一键批量打印」------ 吞吐量上去了,几何一致性还不崩。不管是开放目标检测、OCR 文字定位,还是 GUI 元素捡取、自动驾驶场景,都能稳定输出。
Hybrid 模式可以达到 12.7 框每秒,比传统自回归方法快了整整一个数量级。而且它支持从图像到视频的全域定位,甚至能处理指代表达式------你直接说「那个红色的按钮」,它就给你框出来。
如果你也被「定位慢」「坐标不准」「每次调参像开盲盒」折磨过,不妨试试 LocateAnything-3B。终于不用再对着漫天乱飞的框线怀疑人生了。
教程链接: https://go.openbayes.com/eptce
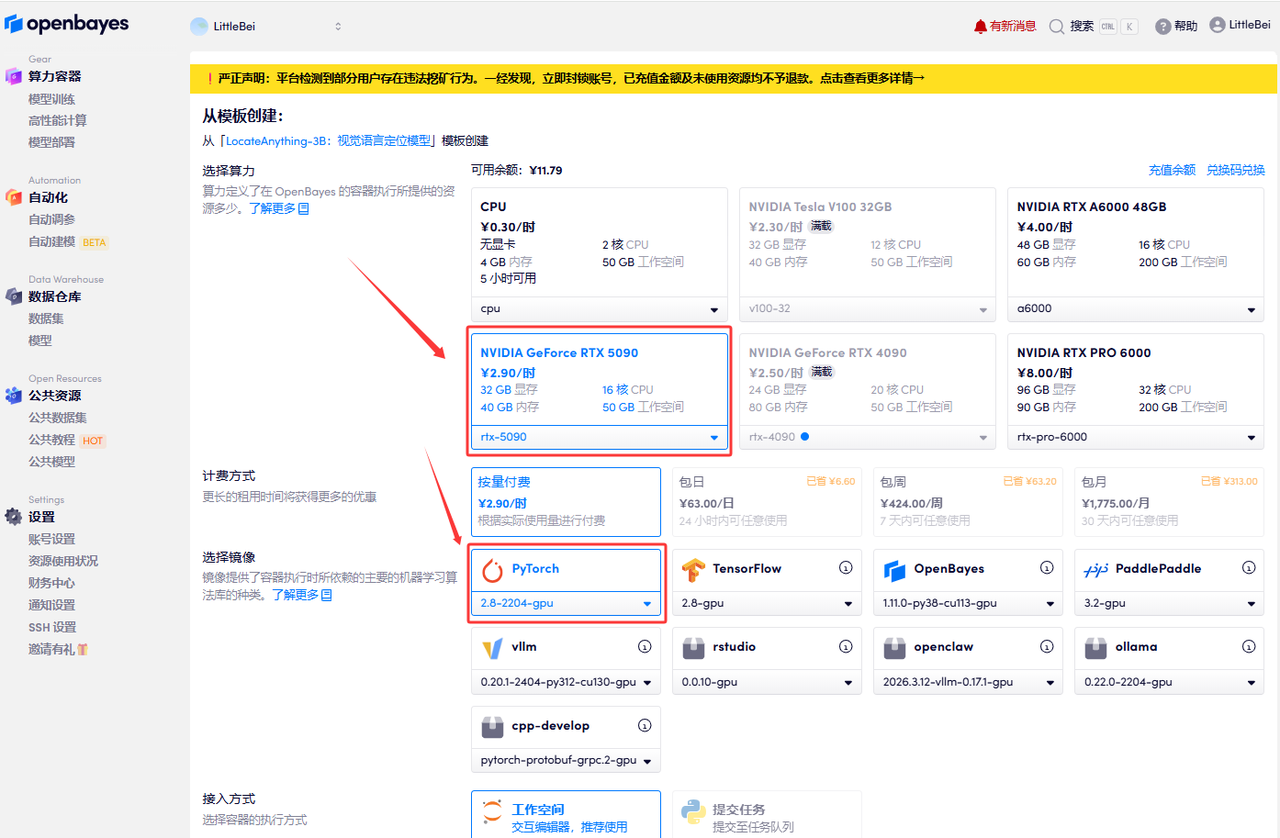
使用云平台: OpenBayes http://openbayes.com/console/signup?r=sony_0m6v 首先点击「公共教程」,找到「LocateAnything-3B:视觉语言定位模型」,单击打开。
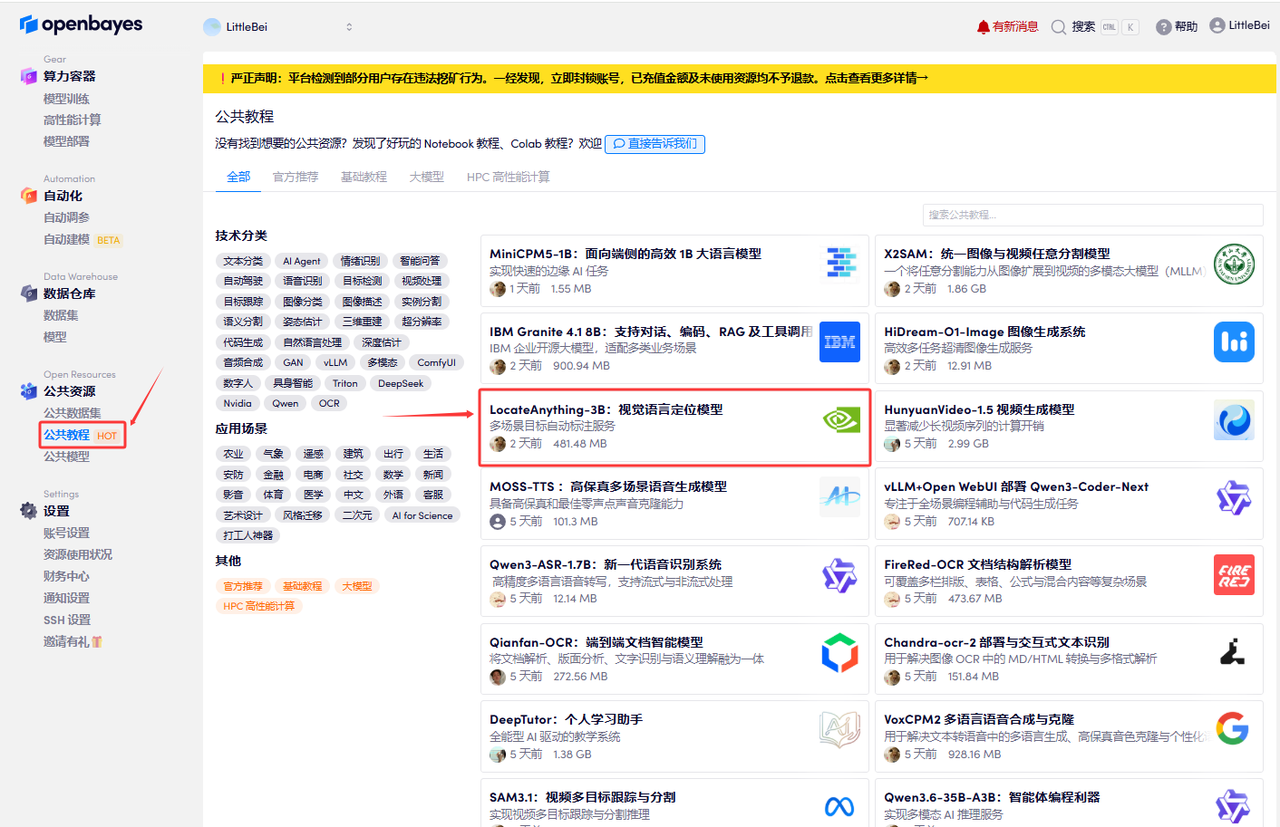
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
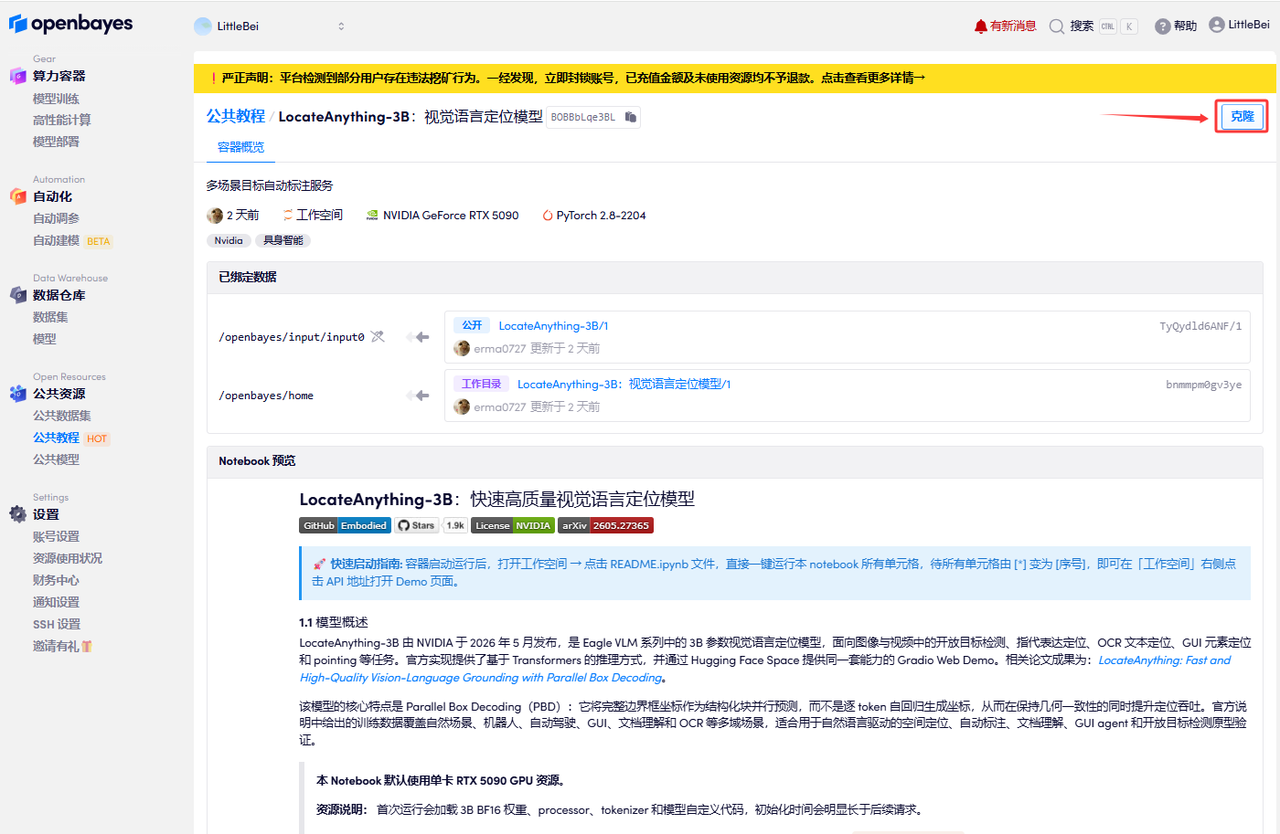
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
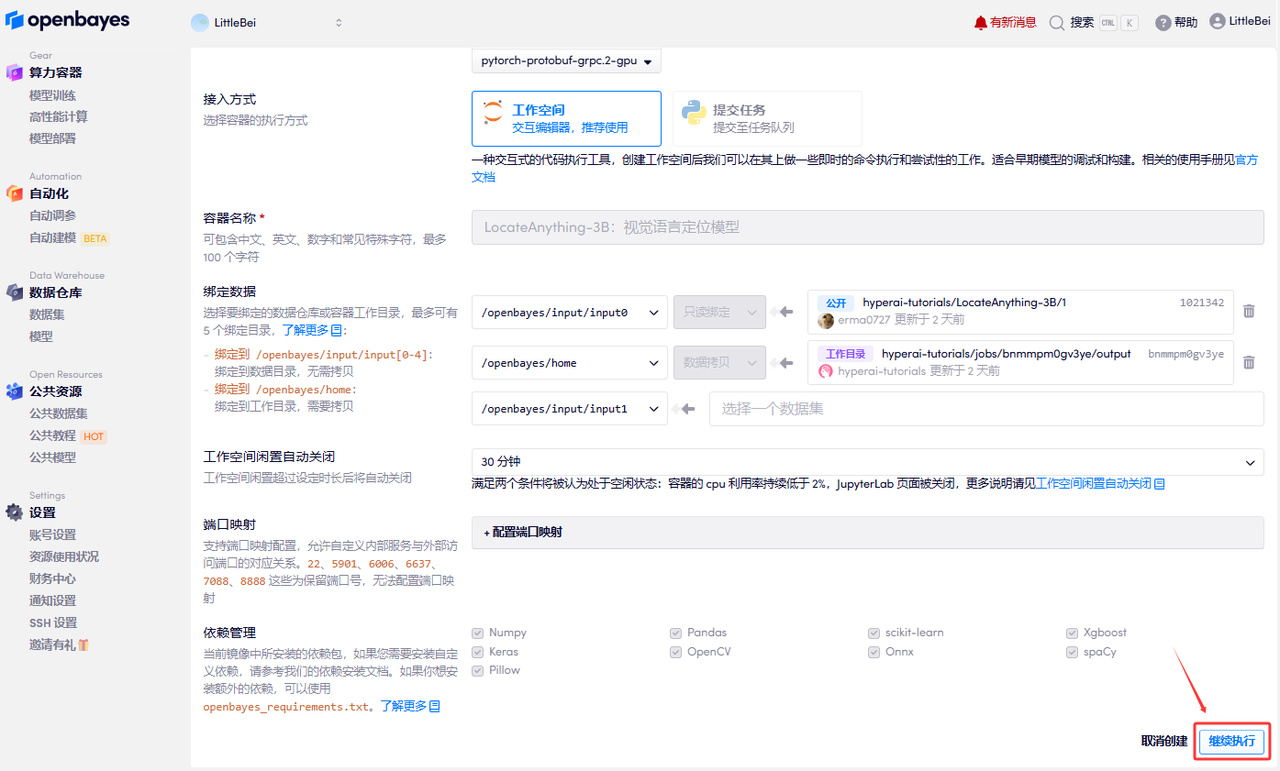
若显示「Bad Gateway」,这表示模型正在加载中,请等待约 2-3 分钟后刷新页面即可;若显示「运行中」,点击「打开工作空间」。
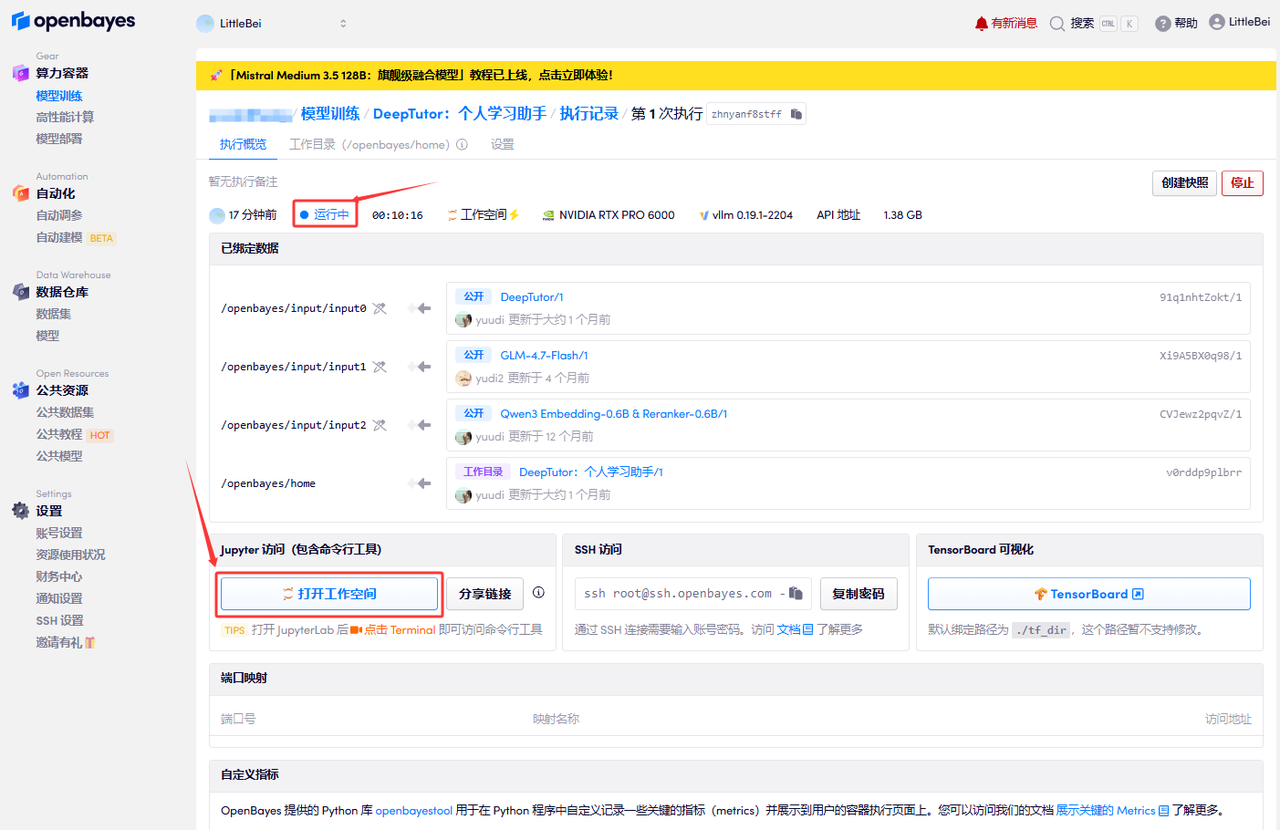
使用步骤如下:
1.页面跳转后,点击左侧 README.ipynb 文件,依据指示输入 API 网址,点击上方「运行」。
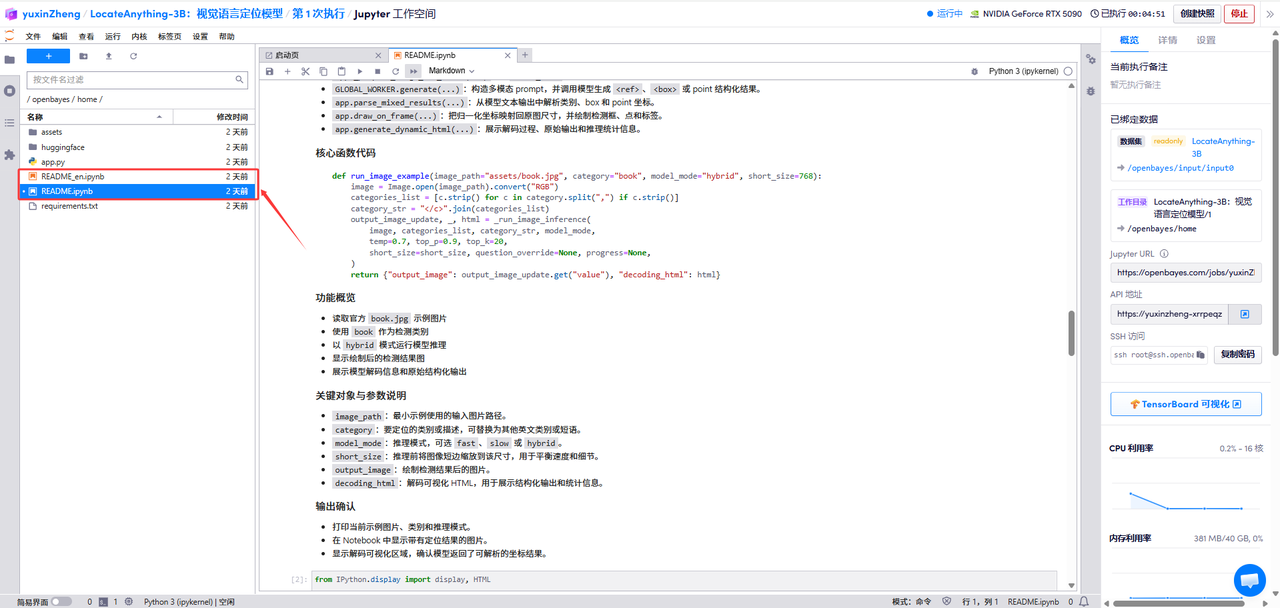
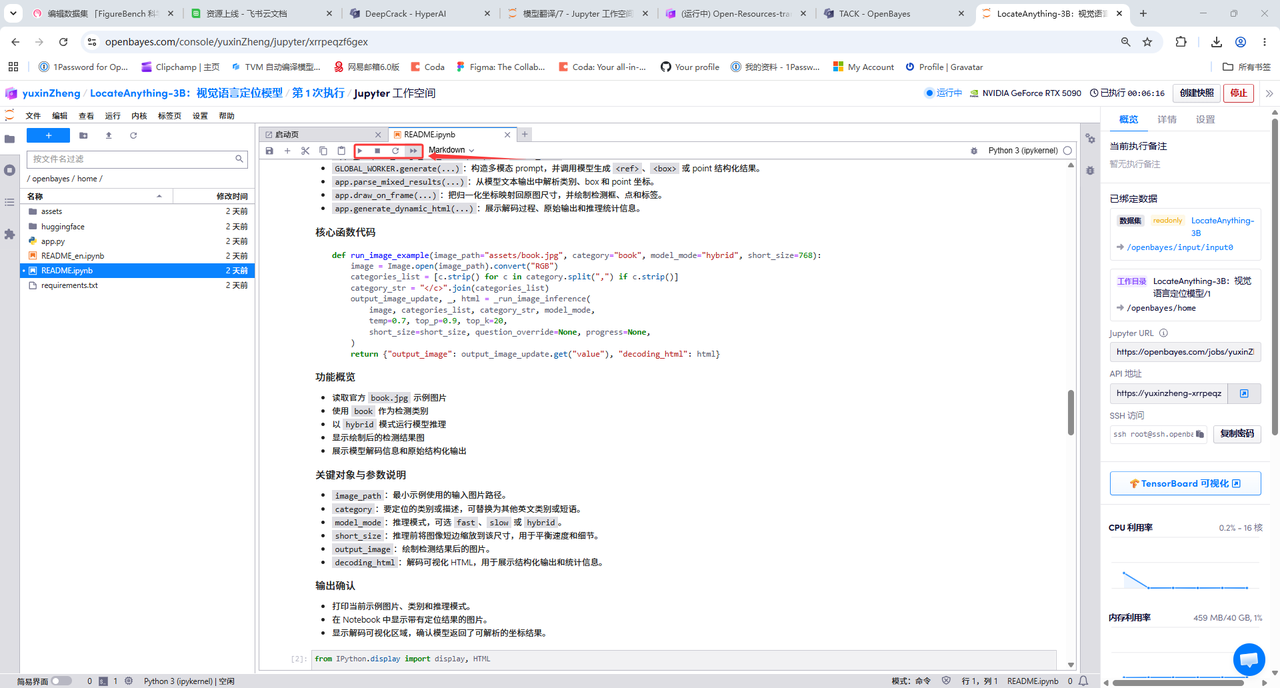
2.运行完成,即可点击右侧 API 地址跳转至 demo 页面。