Karmada 是开放的多云多集群容器编排引擎,旨在帮助用户在多云环境下部署和运维业务应用。凭借兼容 Kubernetes 原生 API 的能力,Karmada 可以平滑迁移单集群工作负载,并且仍可保持与 Kubernetes 周边生态工具链协同。

Karmada v1.181 版本现已发布,本版本包含下列新增特性:
-
支持混合云场景下的溢出式集群亲和调度
-
引入调度超分保护机制
这些更新进一步增强了 Karmada 在混合云和大规模调度场景中的可用性与灵活性。我们鼓励您升级2 到 v1.18.0,体验这些新能力带来的价值。
新特性概览
支持混合云场景下的溢出式集群亲和调度
在混合云环境中,企业通常会将本地数据中心作为主要资源池,把公有云作为峰值流量到来时的弹性补充资源。此前,Karmada 的 ClusterAffinities 已经支持声明多个候选集群组,但这些集群组在一次调度过程中是互斥的:调度器最终只会选择其中一个集群组,无法在首选资源池容量不足时,将剩余副本继续扩展到补充资源池。
Karmada v1.18 引入了引入了Overflow Cluster Affinities 能力,在 ClusterAffinityTerm 中新增 overflowAffinities 字段,用于声明按优先级排列的补充集群组。调度器会优先填满主集群组;当主集群组资源耗尽后,再按声明顺序逐级向补充集群组溢出副本,从而实现"优先使用 IDC,容量不足时再溢出到云"的混合云调度模式。
这项能力主要带来以下价值:
-
渐进式溢出 :用户可以在同一个
ClusterAffinityTerm中声明多个补充集群组,调度器会按照顺序逐级扩展调度范围。 -
反向收缩:在缩容场景下,副本会优先从补充集群组回收,从而尽量保留主资源池中的稳定负载。
-
成本优化:让基线工作负载稳定运行在成本更优的本地集群上,只在确有需要时才使用公有云资源承接突发流量。
这一能力特别适用于如下场景:
-
弹性 GPU 调度:本地 IDC GPU 集群承载日常推理流量,云上 GPU 集群仅用于承接峰值负载。
-
成本控制:将常态业务留在本地基础设施,借助公有云弹性处理流量波峰。
-
容量规划:用清晰的优先级关系定义资源池使用顺序,减少人工干预。
效果图如下:
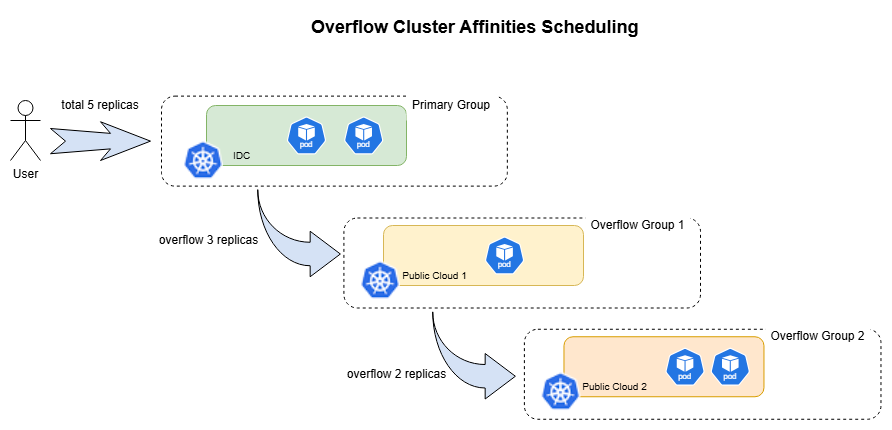
下面是一个精简示例,优先将工作负载调度到 IDC GPU 集群,不足时再溢出到云上 GPU 集群:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: gpu-inference-overflow
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinities:
- affinityName: idc-gpu
clusterNames:
- idc-gpu-cluster1
overflowAffinities:
- affinityName: cloud-gpu
clusterNames:
- cloud-gpu-cluster1
- cloud-gpu-cluster2
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
dynamicWeight: AvailableReplicas更多有关此功能的资料请参考:官方特性文档3 和 特性提案4。
引入调度超分保护机制
在大规模多集群环境中,调度器虽然按顺序处理调度请求,但在决定某个集群是否还有可用容量时,需要依赖 karmada-scheduler-estimator 提供的集群容量估算结果。问题在于:调度器刚刚完成一次副本分配后,新的工作负载真正下发到成员集群、创建 Pod 并绑定到节点之间,存在天然的时间窗口。
如果在这个窗口内又到来新的调度请求,scheduler-estimator 看到的仍然可能是"旧的容量快照",从而导致多个连续调度决策重复使用同一份尚未更新的空闲资源,造成资源超卖。最终结果就是:调度阶段看起来成功,但工作负载落地后可能因为资源不足长期 Pending。
为了解决这一问题,Karmada v1.18 引入了 Scheduling Overcommit Protection(调度超分保护)。该特性在调度器和估算器之间引入"assume and deduct(先假定、再扣减)"机制:
-
调度器在完成一次调度决策后,会先假定这部分资源已经被占用
-
估算器在后续容量计算时,会把这部分"假定占用"的资源一起考虑进去
-
从而避免后续调度在真实状态尚未更新前重复消耗同一批资源
这一特性尤其适用于高吞吐量调度场景,可以显著降低由于状态延迟带来的资源超卖问题,让副本分配结果更贴近成员集群的真实承载能力。
当前该特性是 Alpha 特性,默认关闭,并且需要同时在 karmada-scheduler 和 karmada-scheduler-estimator 上启用:
--feature-gates=SchedulingOvercommitProtection=true需要注意的是,该特性只对 ReplicaSchedulingType: Divided 且采用容量感知分配策略的场景生效,例如 Aggregated 或 DynamicWeight。对于 Duplicated 模式以及完全静态权重分配的场景,不会产生影响。
更多有关此功能的资料请参考:官方特性文档5和 调度超分保护6。
致谢贡献者
Karmada v1.18 版本包含了来自 31 位贡献者的 144 次代码提交,在此对各位贡献者表示由衷的感谢:
参考资料
1 Karmada v1.18 release: https://github.com/karmada-io/karmada/releases/tag/v1.18.0
2 Karmada v1.18 发行说明: https://github.com/karmada-io/karmada/blob/master/docs/CHANGELOG/CHANGELOG-1.18.md
3 溢出式集群亲和调度特性官方文档: https://karmada.io/docs/userguide/scheduling/propagation-policy#how-overflowaffinities-works
4 溢出式集群亲和调度提案: https://github.com/karmada-io/karmada/blob/master/docs/proposals/scheduling/multi-scheduling-group/overflow-affinities/README.md
5 调度超分保护特性官方文档: https://karmada.io/zh/docs/userguide/scheduling/scheduling-overcommit-protection