作者:念风 | 蚂蚁集团-工业化数据体系部

核心观点
- ChatBI 的价值不只是"自然语言生成 SQL",而是把分析从工具操作推进到问题协作、流程编排和经验沉淀。
- SQL 不准只是结果,更深层的问题是业务问题被编译成可执行分析表达的链路还不稳定。
- 语义层提供组织级稳定口径,业务记忆记录分析现场里的动态上下文,两者共同支撑可信 ChatBI。
- 未来 BI 会从"看数系统"走向"业务问题求解系统"。数据系统的竞争力,会从数据供给能力升级为上下文供给能力。
- AI 时代的生产力瓶颈正在上移:从亲手执行,转向定义目标、上下文、约束、流程和验收。
1. 从一个 ChatBI 问题开始:一句话背后的上下文
先从一个再普通不过的问题说起:
帮我看看最近 GMV 为什么跌了?

这句话很像 ChatBI 最该擅长的场景。用户不用写 SQL,不用写 DAX,不用打开 Python/R notebook,也不用在看板里一层层拖维度、切时间、找异常。只要问一句,AI 就应该把答案端上来。
但真正做过 BI 的人都知道,这句话一点也不简单。
"GMV"到底是什么口径?含退款吗?含取消订单吗?看支付 GMV 还是成交 GMV?"最近"是最近 7 天、自然周,还是某个活动周期?"跌了"是同比跌、环比跌,还是低于预期?看全站,还是某个业务线、渠道、地区、类目?用户有没有权限看到拆分明细?历史上有没有类似波动,当时怎么归因的?团队是不是已经确认过某个口径不能这么用?
这些东西如果不说清楚,ChatBI 当然也能答。问题是,它很可能是在猜。
这是我现在看 ChatBI 最大的感受:自然语言入口只是第一步。它降低了提问门槛,但没有自动解决业务语义、指标口径、历史上下文和分析可信度的问题。
所以本文聊的,不是"ChatBI 会不会替我们写 SQL",而是一个更底层的问题:AI 时代,BI 的生产力到底发生了什么变化?
2. BI 的抽象阶梯:分析能力如何一步步下放
BI 这件事,一直在沿着抽象阶梯往上爬。
每往上一级,工具都会接管一层底层复杂度,让更多人、更靠近业务现场的人,获得数据分析能力。
很多组织里,最早的大众化 BI 雏形其实是 Excel。它把计算、透视、图表和简单建模放进一个人人都能打开的工具里。财务、运营、销售、产品都可以拿到一份明细,自己筛选、排序、透视、画图。Excel 的价值不只是"能算",而是让数据第一次比较大规模地进入个人和小团队的日常工作流。
但 Excel 也有明显边界:数据从哪来,口径是否一致,版本是不是最新,公式有没有被改坏,这些都很难治理。
于是,当数据规模变大、系统变多、口径变复杂后,复杂分析又回到了能直接取数和写查询的人手里。你得知道数据在哪张表、字段叫什么、怎么 join、怎么过滤、怎么聚合。能回答复杂业务问题的人,往往是数据开发、数仓工程师,或者足够懂数据模型的分析师。
后来报表和 Dashboard 出现,一批固定问题被产品化。业务运营、产品经理、管理者不再需要每次都找人临时取数,而是可以打开看板看核心指标:今天 GMV 怎么样、转化率有没有掉、哪个渠道波动最大。数据开始从服务"会取数的人",走向服务"要监控业务的人"。
再往后,自助 BI 和语义层把门槛又往下降了一截。指标、维度、数据集、权限被提前建模,业务同学可以拖拽维度、切时间、加筛选,自己探索问题。这个阶段,数据开始服务"会用 BI 工具的人"。运营、产品、销售、财务这些更靠近业务现场的人,也能做一部分自助分析。
到了 ChatBI,自然语言成为入口。它的变化不只是让同一批 BI 用户少点几下鼠标,而是把数据服务对象继续往前推:从服务会用工具的人,走向服务业务现场里的每一个决策动作。
但这里要说得准确一点:一线运营发现某个活动转化不对,自助 BI 当然也能分析。会用工具的人可以打开看板,切渠道、切人群、切时间,逐层下钻,最后定位问题。ChatBI 并不是凭空发明了一种自助 BI 完全做不到的分析能力。
所以在抽象的阶梯里,ChatBI 不应该被理解成"又一个查询入口",而是更高一层的分析表达方式。
自助 BI 阶段,人主要表达的是"我要按什么维度分析";ChatBI 阶段,人开始表达的是"我要解决什么业务问题"。
这条阶梯并非仅限于"SQL 到自然语言"。SQL、DAX、MDX、Python、R、Excel 公式、报表配置、拖拽建模,本质上都是不同形态的分析表达层。它们解决的是同一个核心问题:人如何把业务问题翻译成系统能执行的分析过程。
这一演进过程可以概括如下:

| 阶段 | 数据主要服务谁 | 人主要表达什么 | 典型工具/能力 | 被屏蔽的复杂度 |
|---|---|---|---|---|
| Excel / 个人分析 | 个人和小团队 | 我要怎么算、怎么看 | Excel 公式、透视表、图表 | 部分计算和可视化细节 |
| 数据访问 | 数据开发、数仓工程师、专业分析师 | 我要取哪些数据 | SQL、脚本、数据集、接口 | 存储位置、表结构、取数过程 |
| 固定报表 / Dashboard | 业务运营、产品经理、管理者 | 我要监控什么 | 报表、Dashboard、固定看板 | 查询细节、图表配置、指标展示 |
| 自助 BI / 语义层 | 会用 BI 工具的业务人员 | 我要按什么维度分析 | 语义层、指标平台、自助 BI、拖拽式分析 | 部分建模、关联路径、指标复用 |
| ChatBI / Agentic BI | 业务现场里的问题提出者和决策参与者 | 我要解决什么业务问题 | 自然语言、工具调用、分析流程编排 | 大量低层分析表达和执行链路 |
每升一级,人的操作门槛都会降低。但同时,系统对"语义是否清楚"的要求也会提高。
3. ChatBI 的价值:从工具操作走向问题协作
3.1 自助 BI 已经降低了工具门槛
如果说上一节的抽象阶梯回答的是"ChatBI 站在 BI 演进的哪一级",这一节要回答的是:站上这一级之后,分析到底变了什么。
不能把 ChatBI 的价值说成"让不会写 SQL 的人也能分析"。这句话太窄,也不公平。自助 BI 早就把很多链路压短了。业务同学可以自己打开看板,拖拽、筛选、下钻,很多问题不用再排队找分析师。
但自助 BI 仍然有一个隐含前提:用户要把业务问题拆成一串工具操作。你要知道打开哪个看板,选哪个指标,拖哪个维度,切哪个时间范围,看到图表以后再自己解释。

3.2 ChatBI 降低的是协作摩擦
ChatBI 改变的不是"能不能分析",而是分析发生的摩擦和形态。

摩擦降低,指的是业务问题可以更早进入数据系统。用户不一定要先把问题整理成取数需求,也不一定要先找到正确看板,而是可以从一句业务问题开始,让系统反过来帮助他澄清口径、补齐上下文、生成分析计划。
形态变化,指的是分析从一次性交付变成连续协作。用户可以围绕同一个问题追问:为什么跌、跌在哪、和哪些人群有关、有没有历史相似案例、下一步该看什么。系统不只是返回图表,还要能解释为什么这么查、还缺什么信息、当前结论可信度如何。
还有一层变化:分析过程本身开始变成资产。过去一次分析结束,很多东西留在人脑里:这次用了什么口径,排除了哪些假设,哪条路径走不通,哪个结论被业务确认。ChatBI 如果能把这些过程沉淀下来,下一次就不必从零开始。
所以,ChatBI 的价值不在于和自助 BI 抢"谁能做分析"这件事,而是把分析从"工具操作"推进到"问题协作",再推进到"经验沉淀"。
但链路越短,风险也越直接。过去错误可能在分析师对数、报表评审、业务确认中被拦住;现在如果 ChatBI 在口径、权限、粒度或因果判断上犯错,错误结论可能更快进入业务决策。
3.3 自然语言入口背后,仍要生成可执行查询
这里要把逻辑说清楚。ChatBI 的前台入口变成了自然语言,但后台并不会直接"理解业务"然后凭空变出答案。绝大多数数据分析,最终还是要落到一段可执行的分析表达上。
这个最终产物可能是 SQL,也可能是 DAX、Python/R 脚本、指标平台查询,或者内部查询 DSL。为了行文方便,下面用 SQL 代表这一类"可执行分析表达"。

更值得研究的,不是"SQL 为什么写错了",而是它是怎么被产生出来的。
从用户的一句话,到最终可执行的 SQL,中间至少要经过一条链路:
业务问题 → 分析意图 → 指标/维度/时间语义 → 数据模型和表字段 → 查询计划 → SQL/DAX/Python/R/DSL → 结果校验
ChatBI 把用户从工具操作里解放出来,但系统内部仍然要完成这次"业务问题编译"。如果编译链路里的任何一层错了,最后生成的 SQL 看起来能跑,业务上也可能是错的。
4. 从业务问题到 SQL:这条"编译链"为什么会出错
现在很多 ChatBI 产品都会遇到一个现实问题:最终生成的 SQL 准确率还不够高。但 SQL 不准只是结果。更准确地说,是"业务问题被编译成 SQL 的过程"不够稳定。
很多时候,模型生成的 SQL 在语法上没问题,甚至执行也能跑通,但业务上是错的。错不一定发生在最后一行 SQL,也可能发生在前面的任意一层。

4.1 业务问题没有被规格化
自然语言问题里有大量隐含语义。用户说"最近 GMV",并不会主动说明口径、时间范围、业务线、退款处理方式、权限边界。如果系统不追问,就只能替用户补空白。
它可能默认"最近"是近 7 天,也可能默认是自然周;它可能用支付 GMV,也可能用成交 GMV。最后 SQL 生成出来了,但从第一步开始就已经偏了。

4.2 业务语义缺少稳定锚点
数据库表结构不等于业务语义。表名、字段名、分区字段、状态枚举、宽表和明细表之间的关系,往往是数据开发和历史系统演进的产物,不是为自然语言理解设计的。
模型看到 pay_amt、actual_pay_amt、gmv_amt,未必知道哪个才是当前业务默认口径;看到 dt、biz_date、pay_time,也未必知道分析时应该按哪个时间字段归因。

4.3 查询计划可能选错路径
即使指标和字段选对了,查询计划仍然可能出错。
BI 分析经常涉及事实表、维表、汇总表、多对多关系、时间粒度和去重逻辑。一个 join 路径选错,或者把订单粒度和用户粒度混在一起,SQL 也能跑,结果却会偏。
还有一些错误更隐蔽:过滤条件放在 join 前还是 join 后,去重发生在明细层还是聚合层,窗口函数边界是否包含当天,节假日同比是否要对齐业务周期。这些都不是"会不会写 SQL 语法"的问题,而是分析计划是否正确的问题。

4.4 上下文全了,也不等于一定对
这里也要说得更严谨一点:业务语义上下文是生成正确 SQL 的必要条件,不是充分条件。
就算指标口径、表结构、字段解释、历史规则都给全了,SQL 也不一定必然正确。模型仍然可能选错事实表、绕错 join 路径、把过滤条件放错层级。
它也可能在生成层面写错 group by 粒度、窗口函数边界、去重逻辑;还可能在执行后解释上出错,比如数字能跑通,但和权威报表对不上。
所以,可靠 ChatBI 不能把"补上下文"当成唯一解法。上下文解决的是"按什么业务含义去生成",查询规划解决的是"怎么生成",执行校验解决的是"生成出来以后是否真的可信"。

4.5 可靠性来自语义、生成和校验闭环
ChatBI 生成 SQL 的准确性至少需要三类能力叠在一起:
| 能力 | 解决什么问题 |
|---|---|
| 语义对齐 | 用户问题里的指标、维度、时间、权限和业务默认口径是什么 |
| 查询构造 | 如何选择表、join 路径、过滤条件、聚合粒度和计算逻辑 |
| 执行校验 | 结果是否跑通,分布是否异常,是否能和历史结果/权威报表对上 |
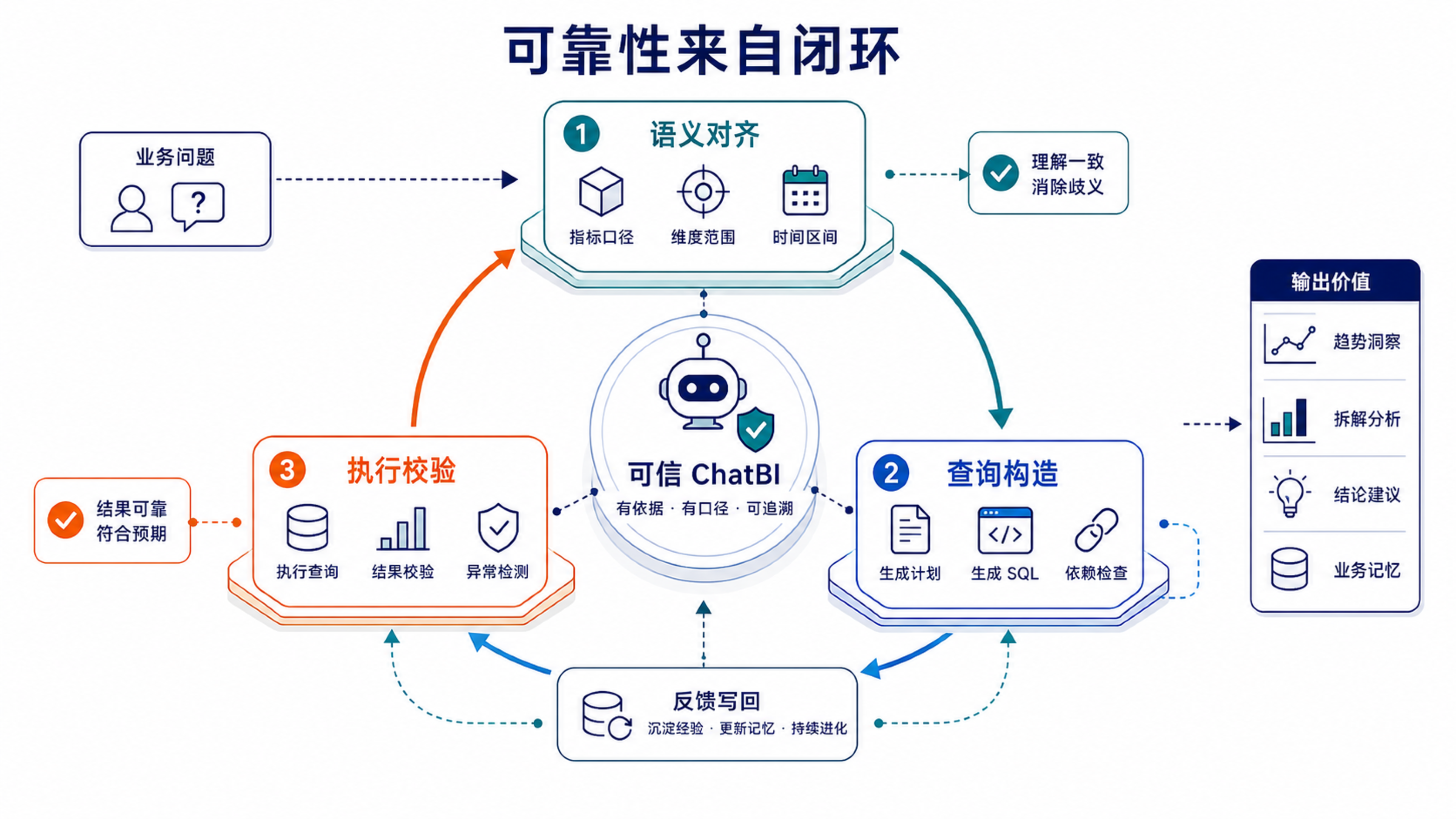
语义上下文解决的是"按什么业务含义生成"的问题;查询规划和执行校验解决的是"生成过程是否正确、结果是否可信"的问题。前者不充分,但没有前者,后面两层也很难稳定。
到这里,前面那个"ChatBI 改变分析形态"的判断,落到了一个更硬的问题上:如果底层仍然只有"自然语言 → SQL → 答案",所有不确定性都会被压到一次生成里。
于是问题从"模型会不会写 SQL",变成了"系统有没有给 AI 一个稳定的业务世界"。这个业务世界至少需要两层。
第一层是语义层。它告诉系统,组织里的指标、维度、权限、血缘和默认口径是什么。
第二层是业务记忆。它告诉系统,在一次具体分析里,用户刚刚确认了什么、修正了什么、哪些历史经验可以参考、哪些结论曾经被证明是错的。
没有语义层,AI 不知道站在哪张地图上;没有业务记忆,AI 每次都会像第一次见到这个业务一样重新开始。
5. 语义层之后,为什么还需要业务记忆
5.1 语义层提供稳定的数据地图
要让 ChatBI 靠谱,语义层是绕不过去的。
语义层解决的是物理数据和业务语言之间的翻译问题。业务同学关心的是"GMV""活跃用户""转化率""新客""复购",但数据库里通常是表、字段、状态码、分区、明细粒度和一堆历史包袱。
语义层要做的,就是把这些底层数据结构封装成业务可理解、可复用、可治理的对象。
它通常会沉淀几类东西:
| 内容 | 例子 |
|---|---|
| 指标定义 | GMV、UV、留存、转化率怎么算,分子分母是什么 |
| 维度模型 | 用户、商品、门店、渠道、区域、时间如何关联事实数据 |
| 口径和计算规则 | 去重逻辑、时间窗口、同比环比、节假日对齐 |
| 权限和治理规则 | 谁能看什么数据,哪些指标是官方口径 |
| 数据血缘 | 一个指标从哪些表来,中间经过哪些加工 |
为什么需要语义层?因为如果每个人都直接面对物理表,同一个"GMV"很容易被算出十个版本。语义层把专家对数据的理解沉淀下来,降低使用门槛,也保证不同的人看同一个指标时尽量站在同一个口径上。

5.2 业务记忆不是普通记忆
但 ChatBI 只靠传统语义层还不够。传统语义层更多沉淀的是相对静态、预先建模的知识。它回答的是:"这个组织里的数据应该如何被理解和使用?"
这里说的业务记忆,不是聊天历史,也不是 FAQ 知识库,而是把分析过程中产生的事实、口径、偏好、证据、版本、有效时间和适用范围,沉淀成 AI 可以检索、判断和执行的上下文结构。
它要持续回答几个问题:
- 这条记忆是什么?
- 它从哪来?
- 现在是否仍然有效?
- 适用于谁、哪个团队、哪个场景?
- 能否被检索、解释和复用?
- 如果后来被推翻,系统怎么知道它不该再被当成事实?
这和"记住用户说过什么"完全不是一个层级。
概念上,一个业务记忆系统至少需要三层结构:
| 层次 | 记录什么 | 解决什么问题 |
|---|---|---|
| 证据层 | 原始对话/文档片段、来源、时间、用户、session、引用片段 | 这个结论从哪来 |
| 领域层 | 允许出现的实体类型、关系类型、属性规则、版本规则、失效规则 | 什么可以被记、怎么记才稳定 |
| 事实层 | 指标口径、偏好、血缘、分析结论、有效时间、作用域、置信度 | 当前可用的业务事实是什么 |
落到工程实现里,这三层还会继续展开成多层 schema contract。
证据怎么挂,实体和关系有哪些闭集类型,哪些 attributes 是稳定字段,哪些关系属于 preference / governance,哪些事实需要版本链,搜索时如何按 activeOnly 和 asOfTime 过滤,都要进入 contract。
也就是说,schema 不是数据库表结构,而是一套约束 AI 如何写入、更新、失效、检索记忆的规则系统。

两者不是替代关系,而是上下层关系。
语义层像地图 ,告诉系统这个数据世界有哪些道路、路名是什么、哪些路能走、哪些路不能走。记忆系统像行程记录,告诉系统这次和这个用户已经走到哪里、刚刚确认过哪些路、哪些判断已经被接受、哪些假设还没有验证。
举个具体例子。用户在一次活动复盘里说"这次 GMV 不看退款后口径",这可能只是本次分析的临时约束,不代表整个组织的 GMV 官方口径变了。语义层负责告诉系统:官方 GMV 口径是什么、有哪些可选口径、哪个口径是默认口径;记忆系统负责记录:这个用户在这次分析里临时采用了哪个口径,以及这个选择为什么成立。
没有语义层,记忆系统可能会把一次对话里的临时说法误当成全局规则。没有记忆系统,ChatBI 又会每轮都从官方语义层重新开始,无法延续某次分析中已经确认过的上下文。
5.3 Memstream:一次业务记忆系统探索
Memstream 正是在这个问题上做的一次原型探索。
项目背景:Memstream 是 DeepInsight 的知识图谱记忆中间件,面向 ChatBI 场景,目标是把用户和 AI 的对话、业务知识库中的文档和指标知识,转化为可复用的业务记忆。它的核心是一条 AddEpisode Pipeline,以及一套 Wiki / Knowledge Base import-export 能力:前者处理动态对话,后者接入相对稳定的业务知识、指标说明、数据集说明和分析经验文档。
它不是把聊天记录原样存起来,也不是做一个 FAQ 知识库,而是把对话和业务知识库中真正对后续分析有价值的业务知识、指标口径、实体关系和分析经验结构化下来。
换句话说,Memstream 想给 ChatBI 补的不是"聊天记忆",而是一层"业务世界的长期上下文"。
这里的"记忆"不只是对话内容本身,还包括业务知识库里已有的指标定义、数据集说明、分析文档,以及对话里新沉淀出的业务知识、分析经验和分析思路。
比如,一个问题最后确认了某个指标口径,这是知识;一次波动分析发现"先看渠道,再看新老客,再看活动补贴"更有效,这是经验;某个团队习惯先排除节假日和大促影响,再做归因,这是分析思路。这些东西如果不被沉淀下来,ChatBI 下一次还是会像第一次一样,从一段 prompt 和几张表开始猜。

6. Memstream:业务记忆的整体架构与核心设计
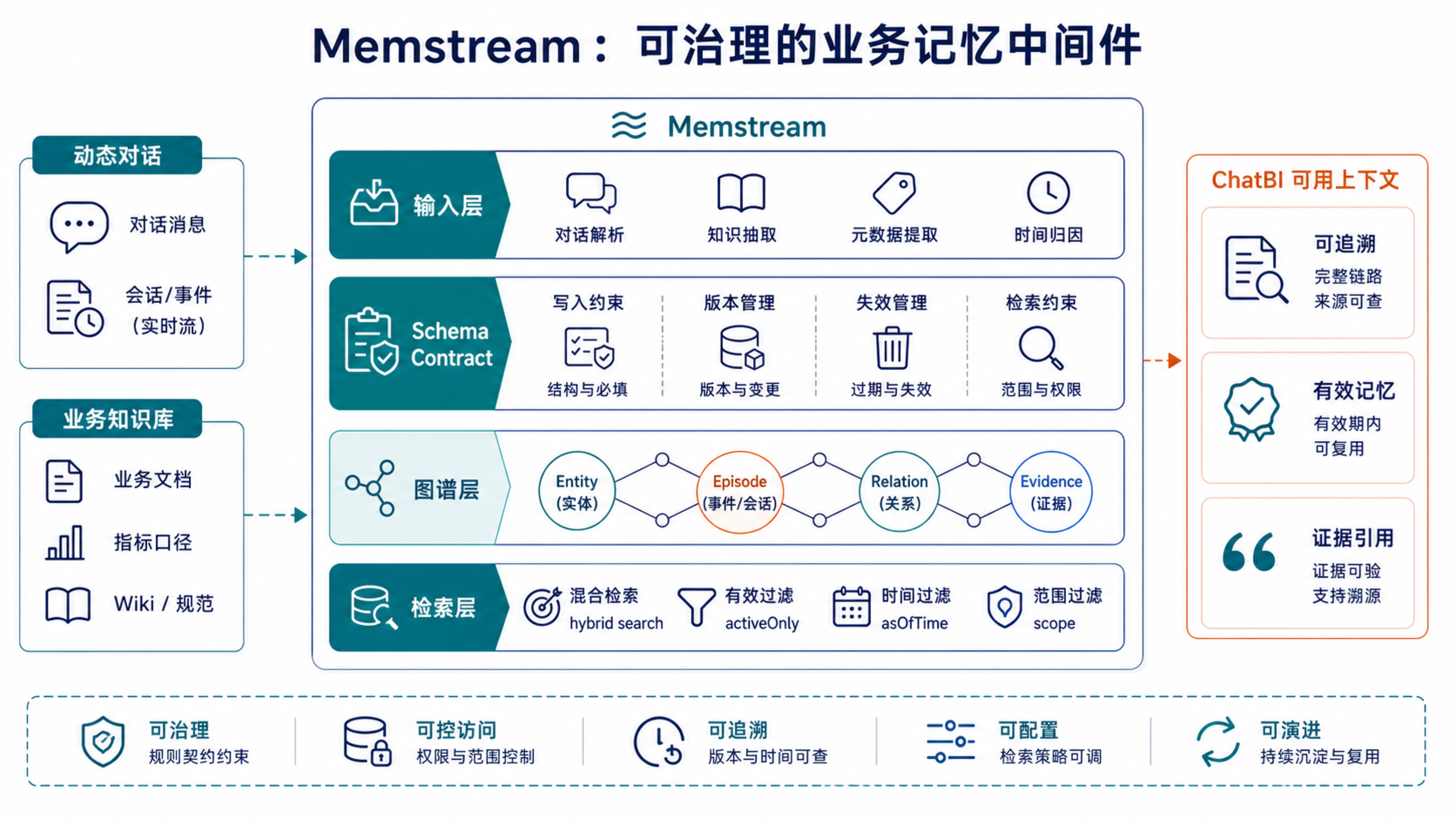
这一节先给结论:Memstream 不是一个"聊天记录存储器",而是一套面向 ChatBI 的业务记忆中间件。它把两类输入合并到同一个可治理的知识图谱里:
- 动态分析现场:用户和 AI 的对话、口径确认、用户纠正、分析结论、下一步计划。
- 静态业务知识库:指标说明、数据集文档、维度定义、业务术语、历史分析文档、LLM-Wiki / markdown 知识库。
前者解决"这次分析过程中发生了什么",后者解决"组织里原本就有哪些业务知识"。两者合在一起,ChatBI 才不只是记得用户刚刚说了什么,也能接上已有的业务知识体系。
可以把 Memstream 的整体架构看成四层:
| 层次 | 作用 | 典型能力 |
|---|---|---|
| 输入层 | 接收对话和业务知识库 | AddEpisode、Wiki import、文档解析 |
| Schema contract 层 | 定义什么可以被记、怎么被治理 | Evidence schema、Domain schema、Fact schema、Governance schema、Retrieval schema |
| 图谱层 | 存储结构化业务记忆 | Entity、Episode、Relation、Saga、Community、Evidence |
| 检索层 | 为 ChatBI 取回可用上下文 | hybrid search、schema-aware filter、asOfTime、activeOnly |
后面再展开几个核心设计。
下面会稍微工程化一点。因为业务记忆如果只停在概念层,很容易说得漂亮,却落不成可靠系统。
6.1 输入层:对话和业务知识库都要进记忆系统
Memstream 有两条主要写入路径。
第一条是对话路径。用户和 AI 的一次对话,会先被保存为 Episode。Episode 不是最终记忆,而是证据来源。后续生成出来的实体、关系、口径、偏好和结论,都应该能够追溯到这段原始对话。
第二条是业务知识库路径。组织里已经存在大量业务知识:指标文档、数据集说明、维度定义、分析方法、历史复盘、术语解释。这些内容不应该只躺在文档里,等用户问到时再让模型临时搜索。
Memstream 通过 Wiki / Knowledge Base import 能力接入这类内容。它会把 LLM-Wiki 风格的 markdown、wikilink、frontmatter、指标表格、数据集说明,解析成图谱里的 Entity 和 Relation。
这两条路径的价值不同。对话路径负责捕捉动态上下文,业务知识库路径负责接入稳定知识底座。可靠的 ChatBI 两者都需要:没有对话记忆,就无法延续分析现场;没有业务知识库,就缺少组织已经沉淀好的语义基础。

6.2 写入链路:从文本到图谱,不是从文本到文本
对话进入 Memstream 后,会经过 AddEpisode Pipeline。它不是把聊天记录原样存起来,而是把文本编译成一组可治理的业务事实:
Episode 创建 → 历史上下文读取 → Entity resolution / dedup → Relation resolution → Graph persistence / contradiction handling → Summary、MENTIONS、Saga / Community 更新
这条链路里有几个关键边界。
第一,历史 Episode 只能辅助理解当前文本,不能变成本轮 entity extraction 的自由来源。比如历史里出现过"复购率",当前用户只是在说"渠道归因",系统不能因为历史里有"复购率"就把它重新抽出来,否则很容易制造孤儿节点。
第二,Entity resolution 不能只靠 name。比如"AI"和"AI Agent"可能相关但不是同一个东西;"复购率"这类 metric 又需要比普通 entity 更强的身份约束。
Memstream 里采用的是 name matching、embedding similarity、LLM-based dedup 和 schema rules 结合的方式,避免同名误合并,也避免同一指标被反复创建。
第三,Relation 不是抽出来就写。Relation 要做 pointer resolution、dedup、contradiction detection 和 temporal validity 处理。一个新事实可能只是补充旧事实,也可能意味着旧事实失效。系统要尽量区分这两种情况。
这样,一句话不是被存成一段文本,而是被编译成一组带来源、时间、作用域和治理规则的业务事实。

6.3 多层 Schema:先把"业务世界"变成 contract
业务记忆要可靠,不能只靠 prompt 约定。Prompt 可以告诉模型"请抽取指标、维度、偏好",但真正让系统稳定的是 schema contract:什么类型允许出现,哪些字段必须保存,什么关系会让旧关系失效,查询时默认应该拿当前事实还是历史事实。
Memstream 里的 schema 不是单层的。它至少分成五个层面:
| Schema 层次 | 约束什么 | Memstream 里的对应设计 |
|---|---|---|
| Evidence schema | 事实从哪来 | episode_uuid、quote、confidence、extractor、created_at |
| Domain schema | 业务世界有哪些对象和关系 | ChatBIEntityType、RelationTypeEnum、entity / relation type registry |
| Fact schema | 事实如何结构化 | metric version、preference fact、lineage、valid_at、invalid_at、active |
| Governance schema | 事实如何被替代、失效和审计 | SUPERSEDES、MENTIONS、relation family、lifecycle role、invalidation rule |
| Retrieval schema | 记忆如何被取回 | entityTypes、relationTypes、asOfTime、activeOnly、preferenceScope、includeEvidence |
这几层合在一起,才让业务记忆从"模型抽出来的一堆文本"变成"系统可以治理的上下文资产"。
Domain schema 面向 ChatBI 定义了一组更贴近分析场景的 entity types:metric、dimension、data table、report、data source、person、org、place、concept、preference target。
这些类型不是为了让图谱好看,而是为了让 AI 后续能知道"什么是什么"。例如:
- "GMV"更可能是 metric,不是普通 concept;
- "渠道"可能是 dimension;
- "dwd_trade_order_di"可能是 data table;
- "经营日报"可能是 report;
- "以后给我柱状图"里的"柱状图"可能是 preference target。
Relation types 也不只是"相关"。Memstream 会区分 semantic relation、preference relation 和 governance relation。例如 PREFERS_CHART 表示图表偏好,LINEAGE 表示数据血缘,SUPERSEDES 表示一个版本替代另一个版本,MENTIONS 表示某个 Episode 提及了某个 entity。
关系还可以带 lifecycle role:有些是 state relation,有些是 event relation,有些是 governance relation。这样系统才能知道一个新事件是补充旧事实,还是让旧事实失效。
这一步的本质是把业务世界变成 schema contract。Prompt 可以帮助模型理解,但最终什么类型能写、怎么写、怎么检索、怎么失效,必须由代码里的 schema 规则兜底。否则记忆系统会退化成"LLM 说了算"的文本仓库。

6.4 核心设计一:指标口径不是覆盖,而是版本事实
指标口径是 ChatBI 里最容易出错、也最值得治理的一类记忆。
假设用户说:"活跃会员口径从 90 天改成 60 天。"
最简单的做法,是直接把"活跃会员"的定义覆盖掉。但这会带来一个问题:历史分析怎么办?如果上个月的复盘用的是 90 天口径,今天把定义覆盖成 60 天,系统以后就很难解释"当时为什么这么算"。
所以更合理的方式是把口径变化建成 versioned fact:
- "活跃会员"这个业务名保持稳定;
- v1 表示"90 天内有消费记录的会员";
- v2 表示"60 天内有消费记录的会员";
- v2 通过
SUPERSEDES指向 v1; - v1 被标记为 inactive,并写入 invalid_at;
- 默认查询返回当前 active version;
- 如果用户问历史分析,可以通过 asOfTime 找回当时有效的版本。
这件事看起来很工程,但它背后是一个产品判断:业务记忆不能只回答"现在是什么",还要能回答"之前是什么、什么时候变的、为什么变的"。

6.5 核心设计二:偏好事实不是闲聊,而是可执行约束
另一类很容易被忽视的记忆,是用户偏好。
用户说"以后给我柱状图""别用饼图""城西银泰的数据先看渠道",这些话如果只存在聊天记录里,下次分析仍然要重新解释。
Memstream 会把这类信息结构化成 preference fact:
| 字段 | 含义 |
|---|---|
| scope | 适用于个人、团队、部门还是组织 |
| polarity | positive 还是 negative |
| target | 偏好的目标,如 bar、line、pie、渠道 |
| applies_to | 适用场景,如城西银泰、会员分析 |
| condition | 可选条件 |
| evidence_refs | 这条偏好来自哪次对话或哪份知识文档 |
这样,"别用饼图"不只是被记住,而是能在后续图表生成时被执行;"城西银泰先看渠道"也不只是经验描述,而是能影响下一次 Plan 的分析顺序。

6.6 核心设计三:普通实体变化不要滥用版本
版本化很重要,但不能什么都版本化。
指标口径变化适合版本化,因为不同版本代表不同定义,历史上都可能需要追溯。但普通实体状态变化不适合生成 v2/v3。
例如"刘芳从西湖银泰调到城西银泰",不应该创建"刘芳 v2"。刘芳这个 entity identity 应该保持不变,变化应该落在 relation 上:旧的 WORKS_AT relation 失效,新的 WORKS_AT relation 生效,或者新增一条调动 event relation。
这类 temporal relation 也需要治理。比如 RESIGNED_FROM 可能使旧的 WORKS_AT 失效,DIVORCED_FROM 可能使旧的 MARRIED_TO 失效。系统不能只靠模型自己判断,而要把 relation type、alias、lifecycle role 和 invalidation rule 写进 schema contract。
这说明业务记忆不是"把事实存下来"这么简单。它还要知道事实属于哪类对象、是否会随时间变化、变化应该落在 node 上还是 edge 上、旧事实是否仍然有效。

6.7 检索层:不只是 vector search
业务记忆写进去以后,关键还在于怎么取出来。
普通 vector search 只能回答"哪些内容语义相似"。但 ChatBI 需要的不只是相似,它还要知道:
- 我只想找 metric,不想找普通 concept;
- 我只想找某类 relation,比如 lineage 或 preference;
- 我只想看当前有效事实;
- 我想回到某个历史时间点,看当时有效的口径;
- 我想只使用 user-level preference,不要混入 team-level 规则;
- 我需要 evidence refs,方便解释为什么系统这么判断。
所以 Memstream 的搜索层引入了 schema-aware filter:entityTypes、relationTypes、asOfTime、activeOnly、preferenceScope、includeEvidence。
这一步把 memory retrieval 从找相似文本,推进到按业务结构取上下文。

7. 用 AI 开发 Memstream:一次生产力跃迁的真实实验
Memstream 的开发过程,提供了一个反向验证样本。
Memstream 要解决 ChatBI 的业务记忆问题,开发工具则是 Claude Code。换句话说,这是一个 AI 系统在帮助构建另一个 AI 系统所需要的记忆能力。
这个过程很快暴露出一个共同问题:无论是 AI Coding,还是 ChatBI,系统都依赖上下文。上下文缺失时,模型会猜;上下文过载时,模型会忘;规格模糊时,模型会把临时判断当成事实。

7.1 AI 开发暴露的问题
在简单任务里,AI 协作确实很顺。需求清楚,AI 写代码、跑测试、修 bug,效率会高得出乎意料。问题通常出现在系统复杂度上来之后。

第一个问题是关键知识会丢。GraphFuse SDK 的 upsertVectors 会覆盖整个节点数据,这是一个已经确认过的架构约束。但只要它没有进入稳定上下文,新的会话里仍然可能重新踩坑。
对人来说,这是一个已经确认过的架构约束;对没有稳定记忆的 AI 来说,它只是上一轮对话里的信息。
第二个问题是上下文会越补越重。越怕 AI 忘,就越不敢开新会话;越不敢开新会话,上下文越快溢出;溢出后又要重新补课。这个循环非常真实:为了防止 AI 忘,补充的信息越来越多;信息越多,窗口越快满;窗口越快满,AI 越容易忘。
第三个问题是规格不清时,AI 会猜。一次 Skill 文件实现里,AI 没有先查规范,而是直接猜了一个目录结构,创建成 .claude/skills/build.md。但 Claude Code 需要的是 .claude/skills/build/SKILL.md。文件虽然存在,系统却完全识别不到。
另一个例子是 attributes 字段:数据库里是 STRING,本意是存序列化 JSON;Java 模型里却是 Map<String, Object>。如果没有明确的序列化契约,AI 很容易在某个转换路径里直接把 String 当 Map 用。
这些问题放在 Coding 里,是代码 bug、构建失败、运行异常。放到 BI 里,就是另一种形式的分析错误。
Claude Code 会忘项目上下文,ChatBI 也会忘业务上下文。Claude Code 在规格不清时会猜实现,ChatBI 在指标口径不清时会猜查询。Claude Code 写错了,可能是系统 bug;ChatBI 分析错了,可能就会进入业务决策。
7.2 重新设计人和 AI 的协作方式
解决这些问题的方向,不是让 AI 少做,而是重新设计人和 AI 的协作方式。

第一层,是给 AI 一块"硬盘"。最核心的项目背景、架构决策、已知坑、构建命令和工作流规则,都需要写进 CLAUDE.md。关键决策后面必须写 WHY。
比如,为什么不能调用 upsertVectors,为什么 entity dedup 要用 name matching + embedding similarity 双重判断。没有 WHY 的规则,AI 很容易在后续会话里重新推翻。
第二层,是让 AI 按信息生命周期分工。Planner 负责读代码、探索影响、写 spec;Implementer 只读 approved spec,负责实现和测试;Reviewer 再独立检查实现是否偏离方案。探索阶段产生的大量上下文噪声,不应该污染实现阶段。
第三层,是把高频重复动作封装成 Skill。编译、测试、提交、创建 spec、扫描进度,这些稳定动作从上下文里拿出去,该调用时再加载,平时不占窗口。
第四层,是给 AI 的自由度画边界。复杂任务必须先有 approved spec;架构决策必须带 WHY;新方案如果要推翻旧决策,必须说明理由;commit 要关联 spec,方便追溯。CLAUDE.md 在这里不像文档,更像一段"跑在 AI 上的程序",定义 AI 可以怎么工作、不能越过哪些线。
7.3 RedisGraphAdapter:先规划,再实现
RedisGraphAdapter 的开发最能说明这种变化。需求很简单:开发阶段用 InMemoryGraphAdapter,每次重启数据全丢,调试 AddEpisode 管线要重复消耗 LLM token,所以需要一个 Redis 后端适配器,把开发环境数据持久化下来。

这个需求如果直接交给 AI 写,很可能快速铺开大量代码。更稳的方式,是先启动 Planner。Planner 读了 BaseGraphAdapter、InMemoryGraphAdapter、GraphFuseProperties、GraphFuseClientFactory,整理出 14 个必须实现的方法,设计 Redis Key 模式,然后输出 spec。
spec 审阅时,一个关键问题被暴露出来:选择 Jedis 同步 API 是合理的,因为底层抽象本来就是阻塞模型;但 Redis Hash 只能存 String,嵌套类型怎么序列化还没说清楚。于是审阅意见要求补充类型转换策略。Planner 随后把 JSON 前缀方案写进 spec,再标记 approved。
接下来 Implementer 才开始动手。它只读 spec,不读 Planner 前面探索时产生的大量过程信息。最后新增 RedisGraphAdapter、类型转换、配置项和测试,包括持久化跨重启验证。
整个过程里,人的主要输入不再是 Java 代码,而是一句需求、一次 spec 审阅和一条批注。
7.4 回到 ChatBI:高层表达更重要
这段经历和 ChatBI 的关系非常直接。可靠的 ChatBI 也不应该从一个模糊业务问题直接跳到最终 SQL。它也需要先澄清问题、读取上下文、生成计划、让关键口径被确认,再调用工具执行,最后把结论和经验写回记忆。

换句话说,AI 时代真正改变的不是"代码可以自动生成"这件事,而是生产力的瓶颈上移了。
以前生产力来自人能更快地执行:写代码、写查询、写公式、搭报表、调接口。现在 AI 可以承担越来越多低层表达和执行动作,于是人的价值变成:能不能把目标、上下文、约束和验收组织清楚。
AI 没有消灭表达。它只是把低层表达自动化了,于是高层表达变得更重要。
8. Context Engineering:数据智能的新基础设施
上一节写的是 AI 编程实践,但它落回 BI 其实非常自然。
不管是写代码,还是做分析,AI 都需要在有限上下文里做复杂决策。上下文没组织好,它就会忘、会猜、会把临时判断当成事实。
Context Engineering 可以翻译成"上下文工程"。它听起来像一个新词,但做的事情很朴素:让正确的信息,在正确的时间,以正确的结构,出现在 AI 面前。
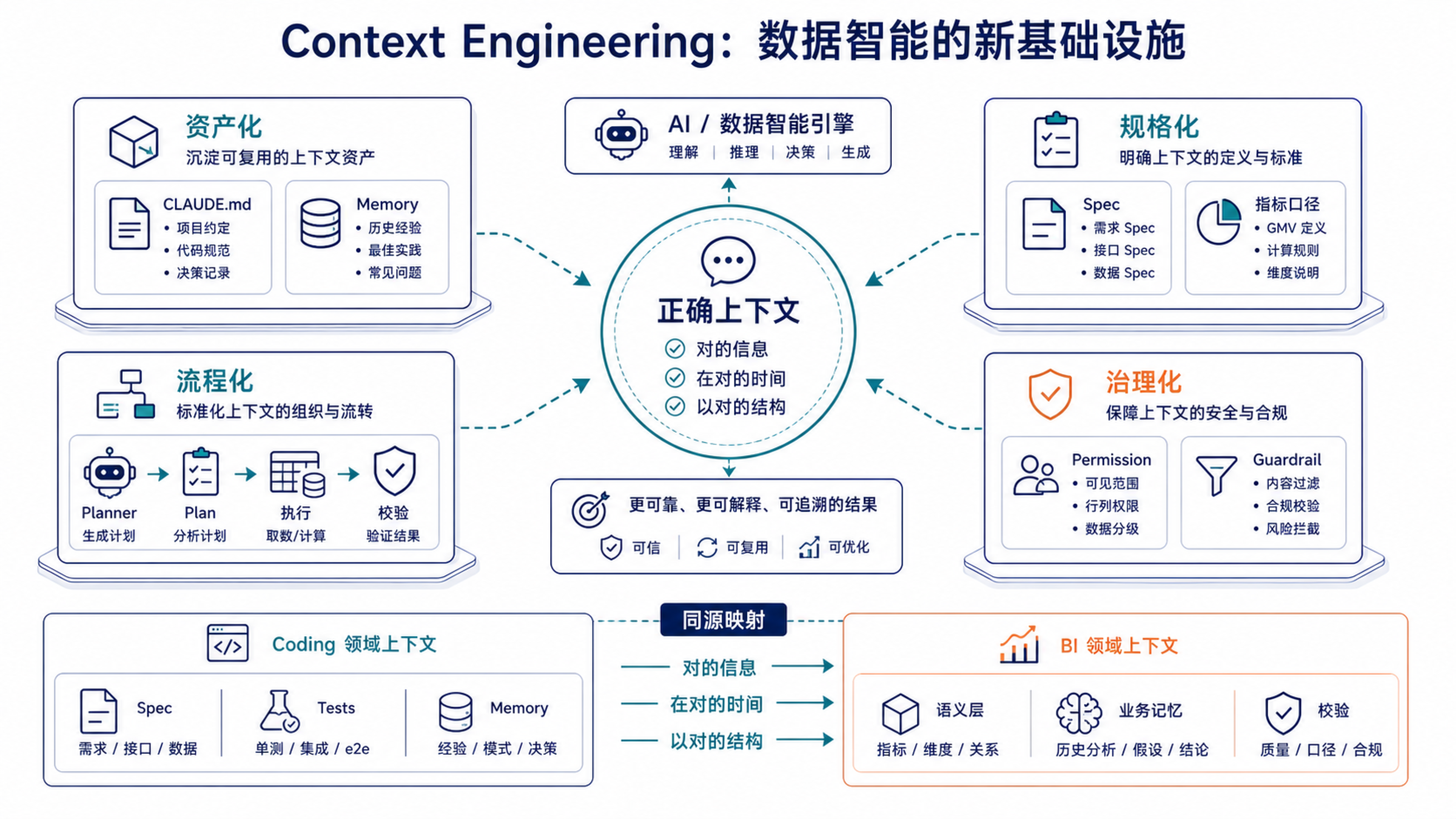
在 Memstream 的开发过程中,我最后沉淀出四层做法。它们原本是为 Claude Code 协作服务的,但换到 BI 场景里,同样成立。
| Context Engineering 方法 | Coding 场景 | BI / Memstream 场景 |
|---|---|---|
| 上下文资产化 | CLAUDE.md、spec、memory、踩坑记录 | Episode、Entity、Relation、Evidence refs |
| 模糊问题规格化 | 复杂需求先写 spec,再实现 | 指标口径、分析范围、偏好事实、版本规则 |
| 复杂任务流程化 | Planner、Implementer、Reviewer | 问题澄清、口径确认、取数、归因、校验、报告 |
| AI 自由度治理化 | 架构约束、危险 API、测试门禁 | 权限、口径、时间粒度、因果边界、记忆复用边界 |
8.1 把上下文资产化
不要让关键知识只留在聊天记录里。Coding 里,我把架构决策、踩坑记录、构建命令、否定性约束写进 CLAUDE.md、spec 和 memory 文件。
BI 里,对应的是 metric definition、entity definition、业务规则、data lineage、历史分析结论、用户纠正记录、成功和失败的分析路径。
这些东西要变成可持久化、可检索、可治理的上下文资产。Memstream 要做的第一件事,就是从 conversation 和 Knowledge Base 里抽取结构化事实,写成 graph 里的 node、edge 和 attributes。

8.2 把模糊问题规格化
AI 最危险的时候,不是它不会,而是它在不确定时替你补空白。
Coding 里,复杂需求要先写 spec,再让 AI 实现。BI 里,复杂分析也应该先明确口径、时间范围、维度边界、归因假设和验收标准,再让 AI 取数、分析和解释。
Memstream 记录这些澄清过程,不只是为了回放对话,而是为了让后续类似问题可以复用已经确认过的规格。

8.3 把复杂任务流程化
不要指望 AI 一步到位完成所有事情。
Coding 里,我把任务拆成 Planner、Implementer、Reviewer:先探索和规划,再实现,最后审查。BI 里也可以有类似流程:问题澄清、口径确认、数据获取、异常检测、归因分析、结论校验、报告生成。
流程越清楚,AI 自由发挥的空间越可控。Memstream 如果能把一次分析经过了哪些步骤、哪些步骤有效、哪些步骤走错记录下来,就有机会让下一次分析从"凭空生成答案"变成"沿着历史有效路径规划"。

8.4 把 AI 自由度治理化
AI 的能力越强,越需要边界。
Coding 里,不能随便推翻架构决策,不能调用已知危险 API,不能跳过测试。BI 里,不能随便改指标口径,不能绕过权限边界,不能混用时间粒度,不能编造不存在的维度,不能把相关性直接写成因果结论。
Memstream 里的记忆也要遵守这些边界:不是所有对话都能变成全局知识,不是所有结论都能跨团队复用,也不是所有历史经验都永远有效。

8.5 从上下文工程走向 Plan 模式
这四层合起来,就是我理解的 AI 时代数据智能基础设施:
AI 时代的数据智能基础设施,本质上是一套 AI 可消费、可执行、可治理的业务上下文体系。
一旦这样看,ChatBI 的产品形态也会跟着变化。
如果可靠 ChatBI 需要先澄清问题,再取回语义层和业务记忆,再规划分析路径,再调用工具执行,再校验结果,最后把确认过的结论写回记忆,那么它就不再是一个"问一句、答一句"的系统。
这些动作之间有顺序,也有依赖。口径没确认,查询不该贸然生成;历史上下文没取回,分析路径可能会重复走弯路;结果没校验,解释就不能直接进入决策;结论没写回,下次还会从零开始。
所以,Plan 模式不是一个交互噱头。它是可靠性要求推出来的产品形态:把原本藏在模型内部的一次性生成,拆成用户和系统都能看见、能确认、能修正的分析流程。

9. Plan 模式:让分析在执行前被看见和修正
Plan 模式不是给 ChatBI 多加一个按钮。它要把上面那些可靠性动作产品化。
如果把 ChatBI 理解成"用户问一句,模型生成一段 SQL,再返回一个答案",它很容易停留在 Vibe BI 阶段:体验很顺,但稳定性不够。

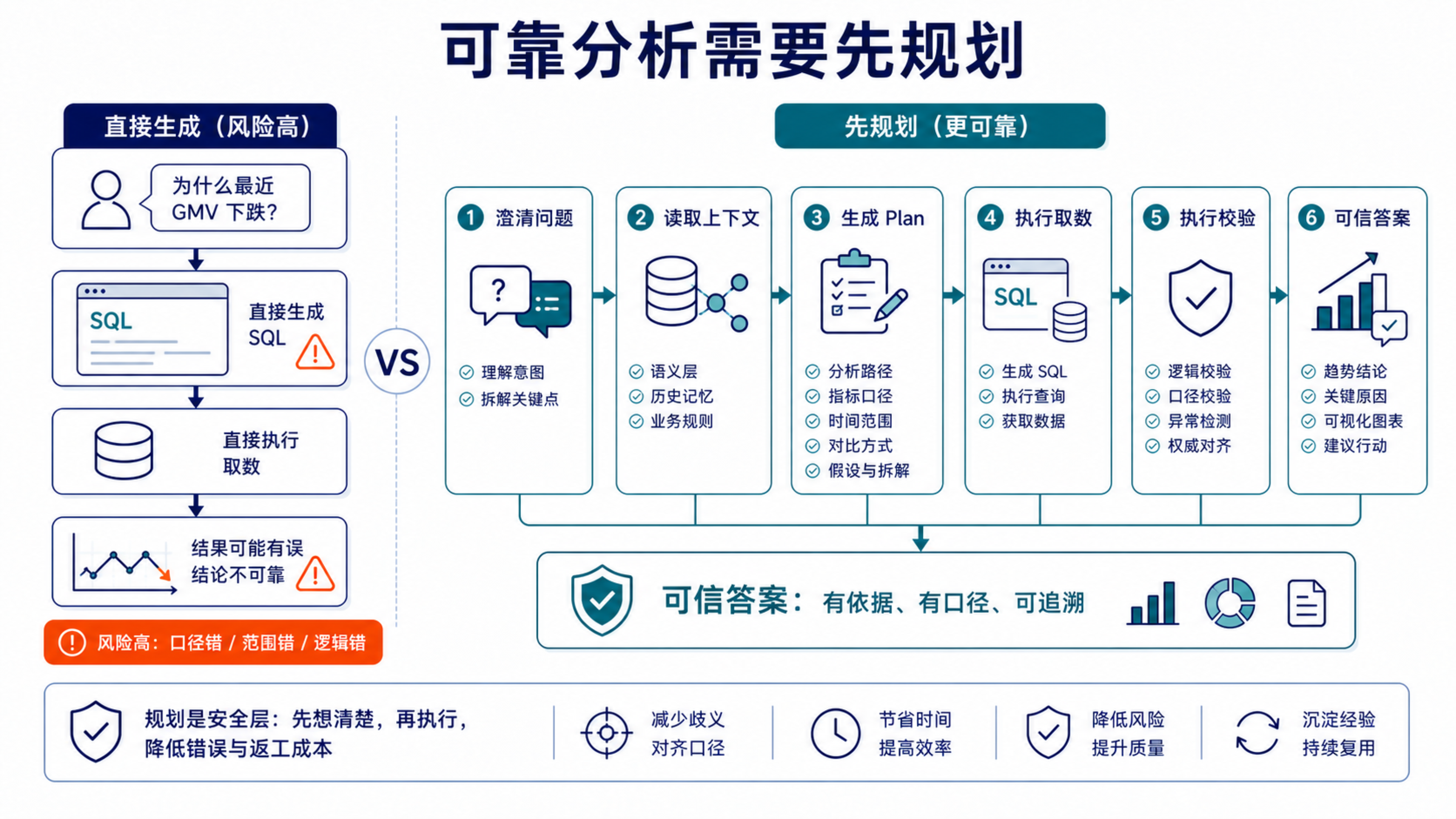
9.1 可靠分析需要先规划
以"帮我看看最近 GMV 为什么跌了"为例,一个更可靠的 ChatBI 不应该立刻生成 SQL,而应该先进入一种 Plan 模式:
- 澄清问题:确认 GMV 口径、时间范围、业务范围、同比/环比方式;
- 读取上下文:从语义层拿指标定义、维度模型、权限规则,从记忆系统拿历史结论和类似案例;
- 生成分析计划:先看整体趋势,再拆业务线/渠道/新老客,再检查活动、价格、流量等可能因素;
- 执行取数和校验:生成查询,运行结果,和权威报表或历史分布对数;
- 解释和追问:给出阶段性结论,说明置信度和未验证假设,引导用户继续追问;
- 写回记忆:把确认过的口径、结论、分析路径和经验规则沉淀下来。
9.2 用户修正 Plan,就是显性化业务判断
这里有一个很关键的点:Plan 不是系统生成完,用户只能点"执行"。有价值的 Plan 模式,应该允许用户在执行前修正它。因为很多业务判断,只有用户知道。
比如系统先生成了一个计划:
- 使用默认 GMV 口径;
- 比较最近 7 天和前 7 天;
- 先按区域拆分,再按渠道拆分;
- 对下降最明显的区域继续下钻到商品类目和用户人群。
用户可能会直接改:
- "最近"不是近 7 天,是这次活动周期;
- GMV 用支付 GMV,不看退款后口径;
- 先别按区域拆,先看渠道,因为上周投放策略刚调整;
- 华东大客户不要下钻到用户明细,权限和业务敏感度都不合适;
- 节假日影响上次已经排除过,这次不用重复查。
这一轮修正非常重要。它不是简单的交互体验,而是在把人的业务判断显性化。用户改过的口径、范围、优先级、排除项和权限边界,都可以进入业务记忆,成为后续类似分析的上下文。
也就是说,Plan 模式真正改变的是"人怎么参与 AI 的分析过程"。过去人是在看到结果后纠错;现在人可以在 AI 执行前修正分析路径,把错误拦在 SQL、图表和结论生成之前。

9.3 SQL 只是计划中的一个工具动作
这和"生成 SQL"不是一个层级的问题。SQL 只是计划执行中的一个动作,关键是围绕业务问题组织一条可检查、可修正、可复用的分析流程。
我在用 Claude Code 做 Memstream 的过程中,也经历了类似转变。
最开始我会直接让 AI 改代码。小任务没问题,复杂任务就开始失控:它会忘上下文,会猜规格,会在不该自由发挥的地方自由发挥。后来我慢慢把流程改成:先规划、写 spec、审方案、再实现、再验收。
这个经验放回 ChatBI 里,其实就是同一个道理:不要让 AI 从模糊业务问题直接跳到最终答案,而是让它先把问题、上下文、假设、计划和验收标准显性化。
所以,这里讲 Vibe Coding 不是为了炫"AI 写了多少代码",而是为了说明一种生产力范式:AI 越强,越不能只靠一句话驱动它直接执行;越复杂的任务,越需要 Plan、约束、校验和记忆。
沿着这个方向看,ChatBI 往后走,很可能会从"自然语言生成 SQL"升级成"自然语言驱动分析流程"。
用户提出的是业务目标,系统生成的是分析计划;SQL、Python、指标查询、图表生成、文本解释,都只是计划中的工具调用。分析过程中产生的新知识、新经验、新路径,又会写回业务记忆系统,成为下一次分析的上下文。
这也是 Memstream 这类系统的意义:它不只是帮 ChatBI 记住"聊过什么",而是帮 Agentic BI 记住"这个业务世界是什么、我们曾经怎么分析过、哪些结论已经被确认、哪些路径更有效"。

10. 未来 BI 会走向何处:从看数系统到业务问题求解系统
如果把前面的判断合起来,我对未来 BI 的判断是:
未来 BI 会从"看数系统"走向"业务问题求解系统";数据系统在 AI 时代的竞争力,不再只是存得多、算得快、图表好看,而是谁能把业务上下文组织成 AI 可以正确理解、执行、校验和复用的结构。
这件事会带来几层变化。

10.1 入口会走向自然语言,但终点不是 Chat
ChatBI 很重要,但 ChatBI 不是终点。
如果只是把自然语言接到数据库上,让模型生成一段 SQL,再返回一个图表,那它只是换了一个入口。它降低了提问门槛,但没有真正改变 BI 的工作方式。
接下来的方向不是"问一句,答一句",而是用户提出业务目标,系统生成分析计划,调用指标、SQL、Python、报表、监控、知识库等工具,给出可追溯结论,并把确认过的经验写回系统。
也就是说,未来 BI 的核心体验可能不再是一个聊天框,也不再是一组固定看板,而是一套围绕业务问题展开的分析工作流。

10.2 BI 的核心对象会从图表变成 Plan
过去 BI 的核心对象是报表、指标、图表。
未来 BI 的核心对象会越来越像 Plan:问题如何澄清、口径如何确认、先查什么、后查什么、哪些假设被排除、结论可信度如何、下一步建议是什么。
图表仍然重要,但图表只是 Plan 的一个输出。SQL 仍然重要,但 SQL 只是 Plan 的一个工具动作。有价值的是一条可检查、可修正、可复用的分析流程。
这会改变 BI 产品的设计重心。过去产品关注"如何让用户更快找到数据、配置图表、下钻维度"。未来产品还要关注"如何让用户在 AI 执行前看见计划、修正假设、确认口径、控制风险"。

10.3 BI 会从一次性分析走向持续记忆
过去很多分析都是一次性的。
一次波动分析结束后,结论可能写在 PPT 里,过程散在群聊里,口径确认留在分析师脑子里。下一次类似问题再来,大家又重新找人、重新取数、重新解释。
未来有价值的 BI 系统要记住:某个指标口径为什么这么定,某次波动怎么归因,哪个分析路径曾经有效,哪个结论后来被推翻,某个团队偏好怎么看数。
这不是为了让系统"懂你"这种泛泛的个性化,而是为了让组织的分析经验不再每次从零开始。
10.4 数据系统的竞争力会从数据供给升级为上下文供给
过去评价一个数据系统,常常看几件事:数据是否齐全、链路是否稳定、查询是否够快、指标是否一致、报表是否好用。
这些能力仍然重要。但在 AI 时代,只做到这些还不够。
因为 AI 面对的不是一张表,也不是一个指标,而是一个业务问题。它需要知道:
- 什么指标能用;
- 什么口径是默认的;
- 哪些维度能拆;
- 哪些数据有权限;
- 哪些历史结论已经被确认;
- 哪些经验只适用于某个团队;
- 哪些结果必须先校验再进入决策。
所以,数据系统新的竞争力会体现在六类能力上:
| 能力 | 说明 |
|---|---|
| 语义能力 | 指标、维度、口径、血缘、权限、质量规则是否足够清楚 |
| 上下文能力 | 能否提供与当前问题相关的历史分析、业务事件、用户修正、团队经验 |
| 可执行能力 | 能否把业务问题稳定编译成查询计划、SQL、工具调用和分析步骤 |
| 校验能力 | 能否和权威报表、历史分布、数据质量规则对齐 |
| 治理能力 | 记忆、口径、偏好、结论是否有作用域、版本、有效时间和权限边界 |
| 学习能力 | 用户修正 Plan、确认口径、否定结论之后,系统能否沉淀反馈 |
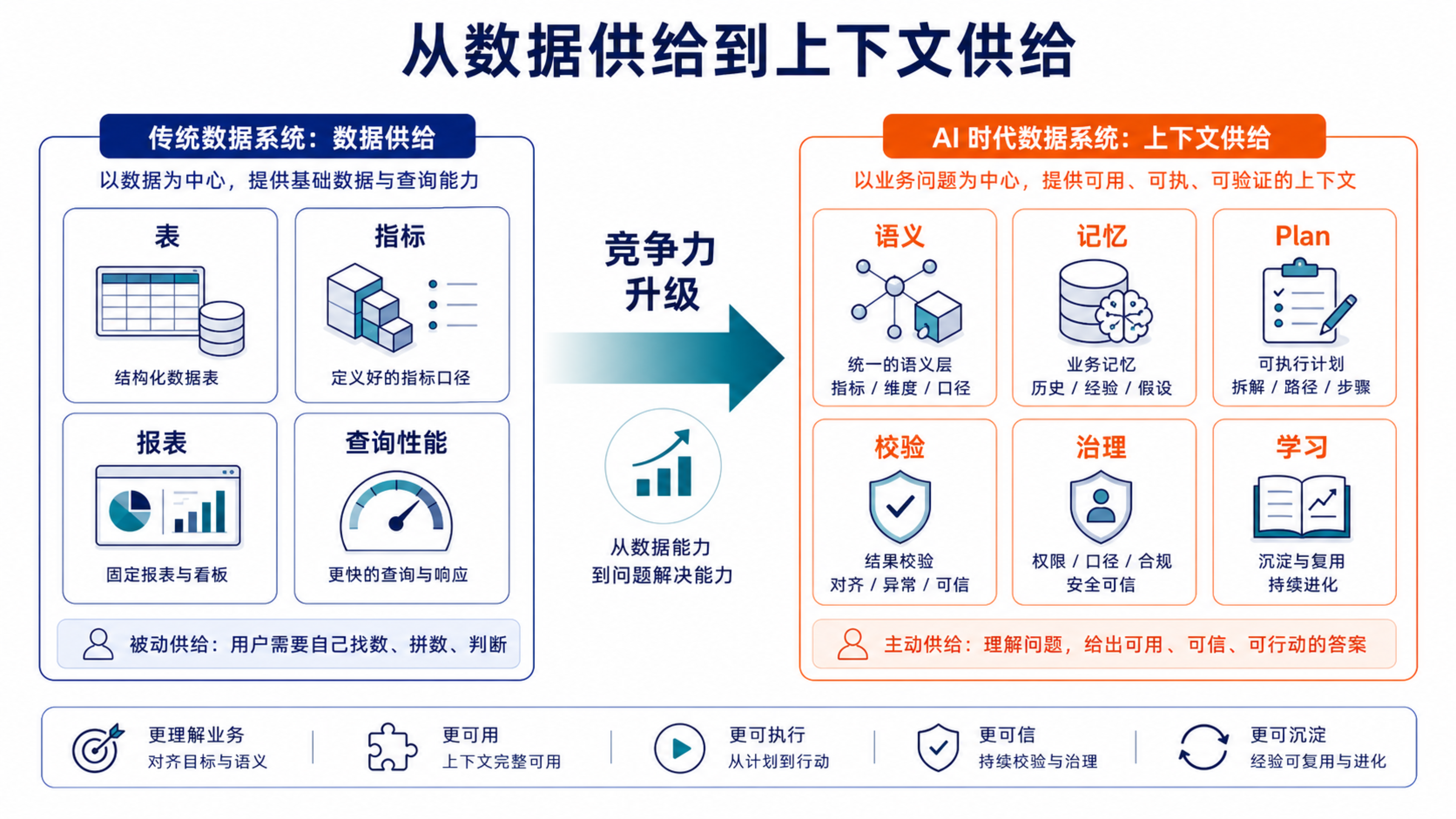
未来 BI 的分水岭,不在于谁先把聊天框接到数据库上,而在于谁能把业务语义、分析流程和历史经验组织成 AI 可消费的上下文。
AI 会越来越擅长写 SQL、画图、生成报告,但它仍然需要知道:什么指标能用,什么口径是默认的,哪些历史结论已经被确认,哪些经验只适用于特定团队,哪些结果必须先校验再进入决策。
因此,AI 时代数据系统的核心竞争力,会从"数据供给能力"升级为"上下文供给能力"。谁能让 AI 更正确地理解业务世界、更可靠地执行分析流程、更持续地积累组织经验,谁就更有机会在下一代 BI 中占据核心位置。
11. 业务记忆的机会与挑战
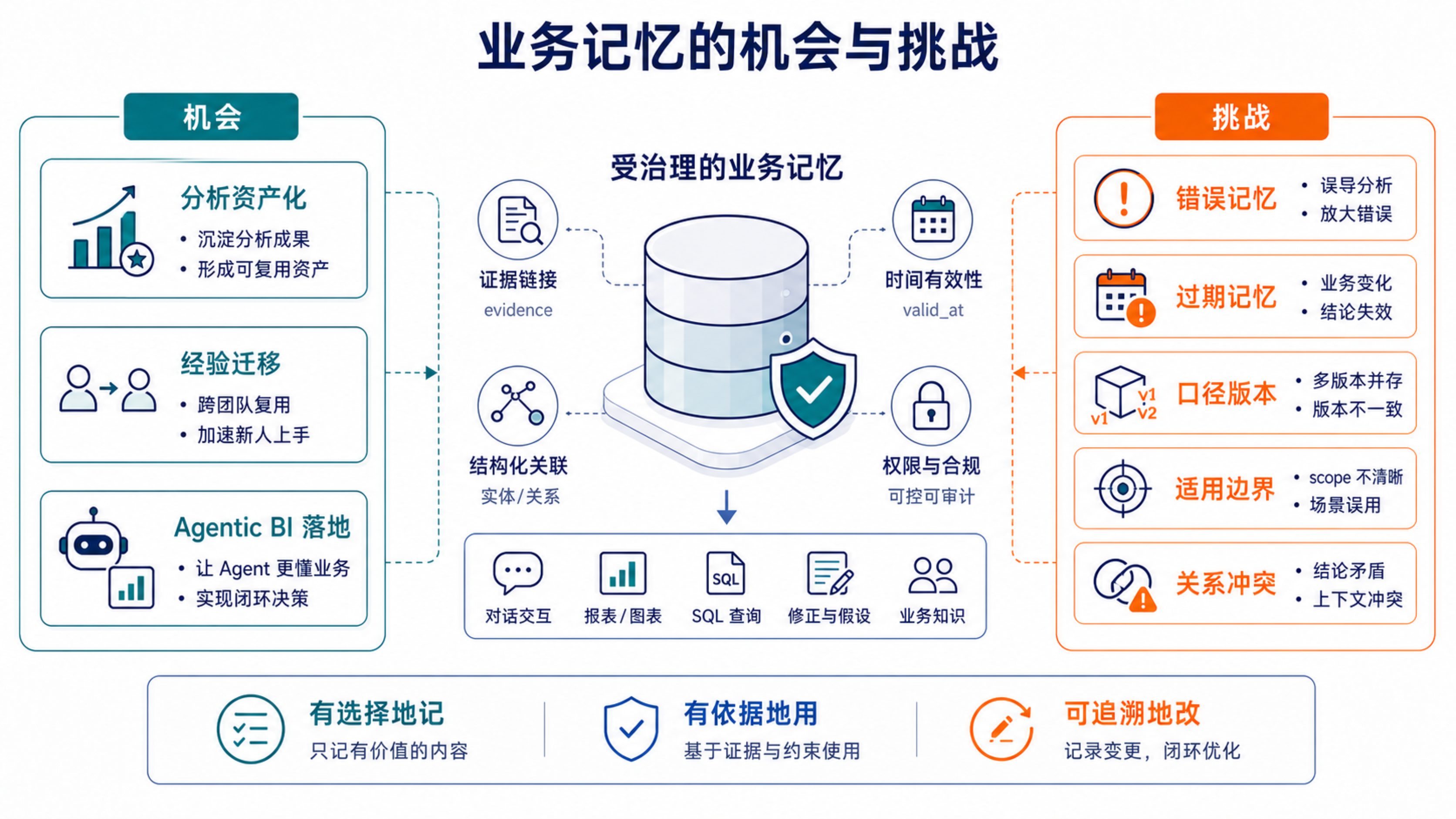
11.1 机会:让分析过程成为组织资产
如果 ChatBI 真的走到业务记忆这一步,机会会很大。
第一,分析过程可以资产化。过去一次分析结束,很多过程性知识会散在人脑、群聊和文档里。记忆系统如果能沉淀"当时怎么查、哪些假设被排除、哪个结论被确认、最后怎么决策",后续类似问题就能站在已有经验上继续往前走。
第二,组织经验可以被迁移。一个资深分析师知道某类活动波动应该先看渠道,再看新老客,再看补贴策略;一个老运营知道某个业务线早上的数据经常延迟,不要过早归因。
这些经验过去很难产品化,但在 AI 时代,它们有机会变成可检索、可复用、可治理的业务上下文。
第三,Agentic BI 会更容易进入真实业务流程。只会回答问题的 ChatBI,价值主要停留在交互体验;能记住业务世界、分析路径和历史反馈的 BI Agent,才有机会参与更长链路的诊断、复盘、监控和决策支持。

11.2 挑战:记忆需要被治理
当然,机会越大,挑战也越真实。
第一个问题是错误记忆怎么处理。一次分析里的结论可能后来被推翻,模型假设也不能变成组织事实。记忆必须有 evidence、confidence、extractor 和 created_at,至少要能回答"这条记忆从哪来、当时依据是什么"。
第二个问题是过期记忆怎么处理。业务事实会变化,指标口径会变化,组织结构会变化,用户偏好也会变化。记忆需要 valid_at、invalid_at、activeOnly、asOfTime 这类机制,否则旧事实会长期污染新分析。
第三个问题是口径变化怎么处理。指标口径不能简单覆盖,否则历史分析无法解释。更合理的做法是 version、lineage_id、SUPERSEDES 和当前 active 版本共同维护。
第四个问题是适用边界怎么处理。个人偏好、团队偏好、组织规则不能混用;某次活动复盘的临时约束,也不能自动升级成全局规则。
第五个问题是关系冲突怎么处理。一个新事件可能会让旧状态关系失效,比如离职会使任职关系失效,口径变更会使旧口径失效。这些不能只靠 LLM 自己判断,而要进入 schema 和治理规则。
所以,Memstream 要探索的不是"让 ChatBI 记住一切",而是让它学会有选择地记、有依据地用、可追溯地改。

12. 从 Claude Dreaming、Hermes 看长期记忆
最近看到两个很有意思的方向,一个是 Claude Managed Agents 里的 Dreaming,一个是 Nous Research 开源的 Hermes Agent。(https://github.com/nousresearch/hermes-agent)
Claude Dreaming 是一个定期运行的过程,会回看 agent 过去的 sessions 和 memory stores,提炼模式、整理记忆,让 agent 随着时间自我改进。
Hermes Agent 则更像一个开源的、可长期运行的个人 agent 系统:有持久记忆,会从经验中创建 skills,会搜索自己的历史会话,也支持 subagents、定时任务和多平台入口。它强调的是一个 agent 如何"越用越懂你、越用越会做事"。
这两个方向和 Memstream 有联系,也有区别。

Claude Dreaming 和 Hermes 更关注的是:Agent 如何记住自己怎么工作。比如它上次怎么解决问题,踩过什么坑,用户偏好什么风格,哪些工作流更有效。
Memstream 更关注的是:BI Agent 如何记住业务世界是什么,以及围绕这个业务世界发生过哪些分析。
比如某个指标到底怎么定义,某个业务实体和另一个实体有什么关系,用户上次确认过哪个结论,某次波动的历史归因是什么,哪些分析路径曾经有效,哪些分析假设后来被推翻。
一个更偏 Agent 的工作记忆,一个更偏业务世界的语义记忆和分析经验记忆。
但它们背后回答的是同一个问题:AI 要长期创造价值,不能只靠单轮 prompt。它需要可积累、可检索、可治理的上下文。
如果说 Claude Dreaming 和 Hermes 代表的是 Agent 自身记忆系统的演进,那么 Memstream 想探索的是 Agentic BI 所需要的业务记忆系统。
未来这两件事大概率会汇合:Agent 既要记住自己怎么工作,也要记住它正在服务的业务世界,以及自己曾经如何分析这个业务世界。
13. 结语:数据智能角色正在从执行走向定义
回到最开始那个问题:
帮我看看最近 GMV 为什么跌了?
AI 当然会越来越擅长回答这类问题。模型会更强,工具调用会更稳,分析链路会更自动化。但越往后走,我越觉得真正的分水岭不在"谁的聊天框更聪明",而在"谁能把业务上下文组织得更好"。
过去,BI 能力强,可能体现为会写 SQL、DAX、Python、R,会搭指标体系,会做报表,会建模型。未来,这些能力仍然重要,但它们会越来越多地被 AI 部分接管或辅助完成。
这里说的不是某一个固定岗位,而是一组围绕数据智能协作的角色:业务用户、数据分析师、数据产品经理、数仓和数据工程同学,以及研发 ChatBI 的工程团队。AI 抽象上移之后,他们的职责会一起变化,但变化方向并不相同。

业务用户更需要说清业务问题和决策语境:为什么问这个问题,当前有哪些已知事实,哪些结论能接受,哪些假设不成立。
数据分析师和数据产品经理更需要把分析经验产品化:哪些问题应该先看什么,哪些指标口径容易混淆,哪些归因路径曾经有效,哪些经验只能在特定场景下复用。
数仓和数据工程同学更需要把数据语义治理好:指标、维度、权限、血缘、质量校验和数据粒度,不能只存在于人脑和文档里,而要变成 AI 可读取、可执行、可约束的上下文。
ChatBI 研发团队则要负责把这些能力编排成系统:语义层怎么接入,记忆怎么检索,工具怎么调用,结果怎么校验,错误经验怎么被修正,权限边界怎么被遵守。
所以,AI 不是让这些角色消失,而是把他们从亲手完成低层分析表达,推向更高一层的系统定义。
- 从亲手写查询和公式,到定义指标、语义和约束;
- 从交付报表和分析结论,到沉淀可复用的分析流程;
- 从一次次回答问题,到建设一个能持续学习、校验和复用经验的数据智能系统。
这也是我做 Memstream 最大的收获。表面上,我是在给 ChatBI 做记忆系统;实际上,我是在理解 AI 时代生产力的底层变化。
当 AI 接管越来越多低层分析表达,数据智能的真正生产力差距,会来自谁能把业务、数据和系统约束组织成 AI 可以正确执行的上下文。
换句话说,未来的数据智能竞争,不会只发生在模型参数、查询引擎或图表组件之间。它会发生在更深的地方:谁能更好地定义业务世界,谁能更可靠地组织上下文,谁能让 AI 把组织经验变成持续复用的生产力。