Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第六章 Comprehensions and Generators(推导式和生成器)
许多程序都是围绕处理列表 、字典键值 对和集合而构建的。Python 提供了一种特殊的语法结构,称为 "推导式",用于简洁地遍历这些类型并创建衍生数据结构。推导式能够显著提升执行这些常见任务的代码的可读性,并带来诸多其他益处。
这种处理方式也适用于具备生成器功能的函数,这种功能使得函数能够逐次返回一系列值。调用生成器函数的结果可在任何适合使用迭代器的地方加以利用(例如 for 循环、带星号的解包表达式等)。生成器能够提升性能、减少内存使用量、提高可读性并简化实现过程。
Item 40:使用 comprehension 而非 map 和 filter
Python 提供了简洁的语法,用于从另一序列或可迭代对象中生成新列表。这些表达式被称为列表推导式。例如,假设我想要计算列表中每个数字的平方。在此情况下,我通过使用简单的 for 循环来实现这一目标:
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
squares = []
for x in a:
squares.append(x**2)
print(squares)
>>>
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
借助列表推导式,我可以通过在一行代码中指定用于计算的表达式以及用于循环的输入序列变量来实现相同的结果:
squares = [x**2 for x in a] # List comprehension
print(squares)
>>>
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
除非你是在应用一个单参数函数,否则对于简单情况而言,列表推导式比内置的 map 函数更加清晰易懂。map 函数需要为计算过程创建一个 lambda 函数(参见 Item 39:"建议使用 functools.partial 而非 lambda 表达式来编写 Gule 函数")。相比之下,map 函数的实现方式在视觉上显得较为杂乱。
alt = map(lambda x: x**2, a)
assert list(alt) == squares, f"{alt} {squares}"
与 map 不同,列表推导式能让你轻松从输入列表中筛选出相应项,从而从结果中移除对应的输出。例如,假设我想要计算那些能被 2 整除的数字的平方。在此情况下,我通过在循环后对列表推导式添加一个条件语句来实现这一目标:
even_squares = [x**2 for x in a if x % 2== 0]
print(even_squares)
>>>
[4, 16, 36, 64, 100]
内置的 filter 函数可与 map 结合使用以达到相同的效果,但是由于嵌套和样板代码的存在,其可读性要低得多:
alt = map(lambda x: x**2, filter(lambda x: x % 2 == 0, a))
assert even_squares == list(alt)
字典和集合有其各自对应的列表推导式(分别称为字典推导式 和集合推导式)。这些功能使得在编写算法时能够轻松创建其他类型的衍生数据结构:
even_squares_dict = {x: x**2 for x in a if x % 2 == 0}
threes_cubed_set = {x**3 for x in a if x % 3 == 0}
print(even_squares_dict)
print(threes_cubed_set)
>>>
{2: 4, 4: 16, 6: 36, 8: 64, 10: 100}
{216, 729, 27}
通过使用 map 和 filter 方法,并配合相应的构造函数对每个调用进行封装,同样可以达到相同的效果。但这些语句会变得异常冗长,以至于不得不将其分散到多行中,这反而会显得更加杂乱,应尽量避免这种做法:
alt_dict = dict(
map(
lambda x: (x, x**2),
filter(lambda x: x % 2 == 0, a),
)
)
alt_set = set(
map(
lambda x: x**3,
filter(lambda x: x % 3 == 0, a),
)
)
assert even_squares_dict == alt_dict
assert threes_cubed_set == alt_set
然而,map 和 filter 内置函数的一个好处在于,它们返回的迭代器会逐次生成一个结果。这使得这些函数能够高效地组合在一起,且内存使用量极小(有关信息,请参阅 Item 43:"考虑使用生成器而非返回列表"和 Item 24:"考虑使用 itertools 来处理迭代器和生成器")。
相比之下,列表推导式则在进行求值时即会生成完整的结果,这会导致内存消耗显著增加。所幸 Python 还提供了一种与列表推导式非常相似的语法结构,它能够创建无限长且内存效率高的值流(参见 Item 44:"考虑使用生成器表达式处理大型列表推导式")。
注意:
- 列表推导式比内置的 map 和 filter 函数更加清晰易懂,因为它们无需使用 lambda 表达式。
- 列表推导式使您能够通过使用条件语句轻松跳过输入列表中的项。这种操作方式在 map 中无法独立实现,需借助过滤功能方可实现。
- 字典和集合也可通过使用推导式来创建。
- 列表推导式在评估时会具体化完整结果,与逐次生成每个输出的迭代器相比,它会使用大量内存。
Item 41:避免在推导式中使用两个以上的控制子表达式
除了基本用法(参见 Item 40)之外,推导式还支持多级循环。例如,假设我想将矩阵(包含其他列表实例的列表)简化为所有项目的一个平面列表。在这里,我通过包含两个 for 子表达式来使用列表推导来完成此操作。这些子表达式按照提供的顺序从左到右运行:
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
flat = [x for row in matrix for x in row]
print(flat)
>>>
[1, 2, 3, 4, 5, 6, 7, 8, 9]
上面的例子简单、可读,并且在理解中合理地使用了多个循环。多个循环的另一个合理用法涉及复制输入列表的两级深度布局。例如,假设我想要对二维矩阵的每个单元格中的值进行平方。由于额外的 \[\] 字符,这种理解更加嘈杂,但它仍然相对容易阅读:
squared = [[x**2 for x in row] for row in matrix]
print(squared)
>>>
[[1, 4, 9], [16, 25, 36], [49, 64, 81]]
如果这个推导式包含另一个循环,它会变得很长,我必须将它分成多行:
my_lists = [
[[1, 2, 3], [4, 5, 6]],
...
]
flat = [x for sublist1 in my_lists
for sublist2 in sublist1
for x in sublist2]此时,多行推导式并不比替代方案短多少。在这里,我使用普通循环语句产生相同的结果。这个版本的缩进使循环比上面的三级列表推导式更清晰:
flat = []
for sublist1 in my_lists:
for sublist2 in sublist1:
flat.extend(sublist2)推导式支持多个 if 条件。同一循环级别的多个条件具有隐式的 and 表达式。例如,假设我想将数字列表过滤为仅大于 4 的偶数值。那么这两个列表推导式是等效的:
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
b = [x for x in a if x >4 if x % 2 == 0]
c = [x for x in a if x >4 and x % 2 == 0]可以在 for 子表达式之后的每个循环级别指定条件。例如,假设我想要过滤一个矩阵,那么剩下的唯一单元格就是那些总和为 10 或更高的行中可被 4 整除的单元格。用列表推导式来表达这一点不需要大量代码,但阅读起来非常困难:
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
filtered = [[x for x in row if x % 4 == 0]
for row in matrix if sum(row) >= 10]
print(filtered)
>>>
[[4], [8]]
尽管这个例子有点复杂,但在实际中你会看到这种推导式似乎很合适的情况。我强烈建议您避免使用像这样的列表、字典或集合推导式。对于新读者来说,生成的代码非常难以理解。字典推导式产生混淆的可能性尤其大,因为它已经需要一个额外的参数来表示每个项目的键和值。
总之,经验告诉我们避免在推导式中使用两个以上的控制子表达式。这可以是两个条件、两个循环,或者一个条件和一个循环。一旦它变得比这更复杂,你应该使用普通的 if 和 for 语句并编写一个辅助函数(参见 Item 43:"考虑生成器而不是返回列表")。
注意:
- 推导式支持多个循环级别以及每个循环级别的多个条件。
- 具有两个以上控制子表达式的推导式非常难以阅读,应避免。
Item 42:使用赋值表达式减少推导式中的重复
推导式(包括列表、字典和集合变体)的常见模式是需要在多个位置引用相同的计算。例如,假设我正在编写一个程序来管理一家紧固件公司的订单。当客户收到新订单时,我需要能够告诉他们我是否可以履行他们的订单。具体来说,假设我需要验证请求是否有足够的库存并且高于运输的最低阈值(例如,以 8 为一批),如下所示:
stock = {
"nails": 125,
"screws": 35,
"wingnuts": 8,
"washers": 24,
}
order = ["screws", "wingnuts", "clips"]
def get_batches(count, size):
return count // size
result = {}
for name in order:
count = stock.get(name, 0)
batches = get_batches(count, 8)
if batches:
result[name] = batches
print(result)
>>>
{'screws': 4, 'wingnuts': 1}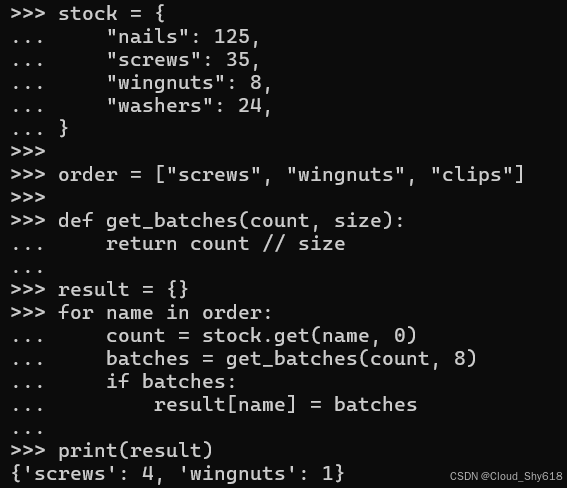
在这里,我通过使用字典推导式来更简洁地实现此循环逻辑(有关最佳实践,请参阅 Item 40):
found = {name: get_batches(stock.get(name, 0), 8)
for name in order
if get_batches(stock.get(name, 0), 8)}
print(found)
>>>
{'screws': 4, 'wingnuts': 1}
虽然这段代码更紧凑,但问题是 get_batches(stock.get(name, 0), 8) 表达式是重复的。这会增加视觉噪音,从而损害可读性,并且在技术上是不必要的。如果两个表达式不保持同步,重复还会增加引入错误的可能性。例如,这里我将第一个 get_batches 调用更改为 4 作为其第二个参数,而不是 8,这会导致结果不同:
has_bug = {name: get_batches(stock.get(name, 0), 4) # Wrong
for name in order
if get_batches(stock.get(name, 0), 8)}
print("Expected:", found)
print("Found: ", has_bug)
>>>
Expected: {'screws': 4, 'wingnuts': 1}
Found: {'screws': 8, 'wingnuts': 2}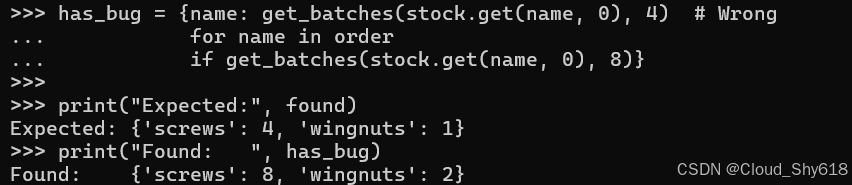
解决这些问题的一个简单方法是使用赋值表达式(通常称为海象运算符)作为推导式的一部分(有关信息,请参阅 Item 8:"使用赋值表达式防止重复"):
found = {name: batches for name in order
if (batches := get_batches(stock.get(name, 0), 8))}赋值表达式 (batches := get_batches(...)) 允许我在 stock 字典中查找每个 order 键的值,调用 get_batches 一次,然后将其相应的值存储在 batches 变量中。然后,我可以在推导式的其他地方引用该变量来构造字典的内容,而不必再次调用 get_batches。消除对 get 和 get_batches 的冗余调用还可以通过避免按顺序对每个项目进行不必要的计算来提高性能。
在值表达式中定义赋值表达式以进行推导是有效的语法。但是,如果您尝试在推导式的其他部分引用它定义的变量(第十个),则由于推导式的求值顺序,您可能会在运行时遇到异常:
result = {name: (tenth := count // 10)
for name, count in stock.items() if tenth > 0}
>>>
Traceback ...
NameError: name 'tenth' is not defined
您可以通过将赋值表达式移动到条件中,然后在推导式的值表达式中引用它定义的变量名称(第十个)来修复此示例:
result = {name: tenth for name, count in stock.items()
if(tenth := count // 10) > 0}
print(result)
>>>
{'nails': 12, 'screws': 3, 'washers': 2}
当推导式使用海象运算符时,任何相应的变量名称都将泄漏到包含范围中(有关信息,请参阅 Item 33:"了解闭包如何与变量范围和 nolocal 交互"):
half = [(squared := last**2)
for count in stock.values()
if (last := count // 2) > 10]
print(f"Last item of {half} is {last} ** 2 = {squared}")
>>>
Last item of [3844, 289, 144] is 12 ** 2 = 144
这些变量名的泄漏与普通 for 循环中发生的情况类似:
for count in stock.values():
last = count // 2
squared = last**2
print(f"{count} // 2 = {last}; {last} ** 2 = {squared}")
>>>
24 // 2 = 12; 12 ** 2 = 144
然而,这种泄漏行为可能令人意外,因为当推导式不使用赋值表达式时,循环变量名称不会像这样泄漏(有关信息,请参阅 Item 20:"永远不要在循环结束后使用循环变量"和 Item 84:"谨防异常变量消失"):
try:
del count
half = [count // 2 for count in stock.values()]
print(half) # Works
print(count) # Exception because loop variable didn't leak
except:
logging.exception('Expected')
else:
assert False
>>>
[62, 17, 4, 12]
Traceback ...
NameError: name 'count' is not defined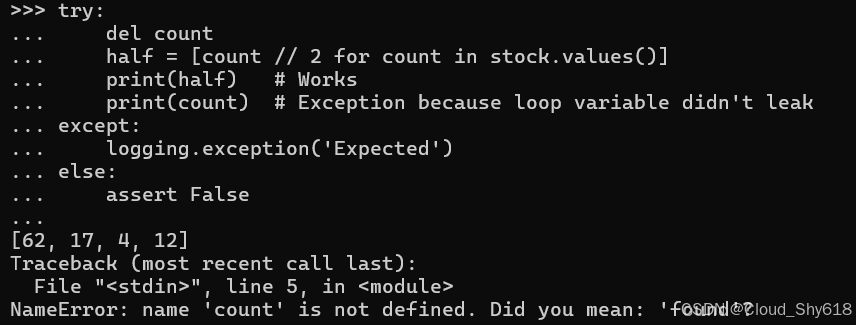
在生成器表达式中使用赋值表达式的方式也相同(请参阅 Item 44:"考虑大型列表推导式的生成器表达式")。 在这里,我创建了一个包含商品名称和当前库存数量的迭代器,而不是字典实例:
found = ((name, batches) for name in order
if(batches := get_batches(stock.get(name, 0), 8)))
print(next(found))
print(next(found))
>>>
('screws', 4)
('wingnuts', 1)
注意:
- 赋值表达式使推导式和生成器表达式可以在同一推导式中的其他位置重用某个条件的值,从而提高可读性和性能。
- 尽管可以在推导式或生成器表达式的条件之外使用赋值表达式,但您应该避免这样做,因为它不能可靠地工作。
- 在推导式中,赋值表达式中的变量将泄漏到封闭范围中;相反,推导式中的循环变量不会泄漏。
Item 43:考虑生成器而不是返回列表
对于生成结果序列的函数,最简单的选择是返回项目列表。例如,假设我想找到字符串中每个单词的索引。在这里,我使用 append 方法将结果累积在列表中,并在函数末尾返回它:
def index_words(text):
result = []
if text:
result.append(0)
for index, letter in enumerate(text):
if letter == " ":
result.append(index + 1)
return result对于某些示例输入,这将按预期工作:
address = "Four score and seven years ago..."
result = index_words(address)
print(result[:10])
>>>
[0, 5, 11, 15, 21, 27, 31, 35, 43, 51]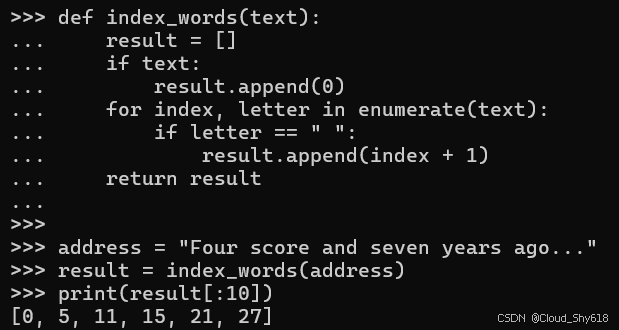
上面的 index_words 函数有两个问题。
第一个问题是代码有点密集且有噪音。每次找到新结果时,我都会调用追加方法。方法调用的批量 (result.append) 不强调添加到列表 (index + 1) 中的值。其中一行用于创建结果列表,另一行用于返回结果列表。 虽然函数体包含大约 130 个字符(没有空格),但只有大约 75 个字符是重要的。
编写此函数的更好方法是使用生成器,它是一个使用 yield 表达式逐次生成输出的函数。在这里,我定义了该函数的生成器版本,它实现了与之前相同的结果:
def index_words_iter(text):
if text:
yield 0
for index, letter in enumerate(text):
if letter == " ":
yield index + 1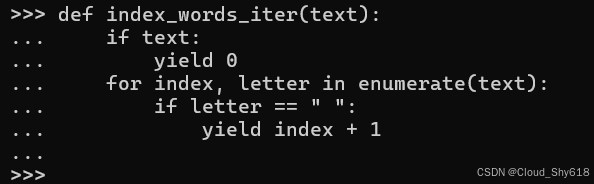
调用时,生成器函数实际上并不运行,而是立即返回一个迭代器。每次调用下一个内置函数时,迭代器都会将生成器前进到下一个 yield 表达式。传递给生成器的每个值都会由迭代器返回给 next 的调用者:
it = index_words_iter(address)
print(next(it))
print(next(it))
>>>
0
5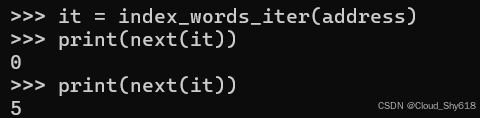
index_words_iter 函数明显更容易阅读,因为与结果列表的所有交互都已被消除。结果被传递给 yield 表达式。 如有必要,我可以通过将生成器返回的迭代器传递给列表内置函数,轻松地将其转换为列表(有关其工作原理,请参阅 Item 44:"考虑大型列表推导式的生成器表达式"):
address = "Four score and seven years ago our fathers brought forth on this continent a new nation, conceived in liberty, and dedicated to the proposition that all men are created equal."
result = list(index_words_iter(address))
print(result[:10])
>>>
[0, 5, 11, 15, 21, 27, 31, 35, 43, 51]
index_word 的第二个问题是它要求所有结果在返回之前都存储在列表中。对于巨大的输入,这可能会导致程序内存不足并崩溃。相比之下,由于其有限的内存要求,该函数的生成器版本可以轻松地适应任意长度的输入。例如,在这里我定义了一个生成器,它一次一行地从文件中传输输入,并一次生成一个单词的输出:
def index_file(handle):
offset = 0
for line in handle:
if line:
yield offset
for letter in line:
offset += 1
if letter == " ":
yield offset该函数的工作内存仅限于一行输入的最大长度,而不是整个输入文件的内容。在这里,我展示了在文件输入上运行生成器会产生相同的结果(有关 islice 函数的更多信息,请参阅 Item 24:"考虑使用 itertools 来使用迭代器和生成器"):
address_lines = """Four score and seven years ago our fathers brought forth on this
continent a new nation, conceived in liberty, and dedicated to the proposition that all men are created equal."""
with open("address.txt", "w") as f:
f.write(address_lines)
import itertools
with open("address.txt", "r") as f:
it = index_file(f)
results = itertools.islice(it, 0, 10)
print(list(results))
>>>
[0, 5, 11, 15, 21, 27, 31, 35, 43, 51]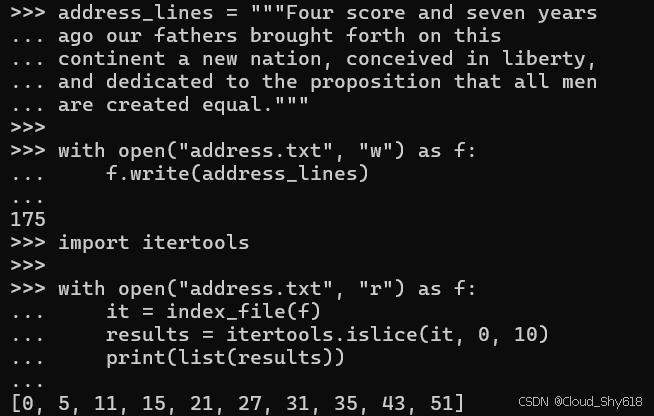
像这样定义生成器的唯一问题是调用者必须知道返回的迭代器是有状态的并且不能重用(请参阅 Item 21:"迭代参数时保持防御性")。
注意:
- 使用生成器比让函数返回累积结果列表更清晰。
- 生成器返回的迭代器生成传递给生成器函数体内的 yield 表达式的值的集合。
- 生成器可以为任意大的输入生成一系列输出,因为它的工作内存不包括所有先前输入和输出的具体化。