Xiaothink-T17-Tiny 模型卡片
模型概览
| 属性 | 值 |
|---|---|
| 模型名称 | Xiaothink-T17-Tiny |
| 架构 | GRU3 + 历史检索 Transformer |
| 参数量 | 0.15B(96,924,408) |
| 训练数据 | 1.5GB 预训练 + 1.5GB 指令微调 |
| 词表大小 | 52,894 |
| 最大序列长度 | 512 |
| 深度学习框架 | PyTorch(≥2.0) |
| 最低库版本 | xiaothink ≥ 1.4.2 |
| 语言 | 中文(截止 Xiaothink-T17 系列发布,所有模型只支持中文处理) |
⚠️ 由于模型架构特殊(GRU3 历史检索机制),目前不支持 ModelScope 调用,请使用 xiaothink ≥ 1.4.2 库加载。
核心创新
T17 历史检索架构(History Retrieval Architecture)
Xiaothink-T17-Tiny 基于创新的 GRU3 + 历史检索 架构,在保证 RNN 空间复杂度接近线性的同时,大幅增强了模型的长距离依赖建模能力。
1. GRU3 历史感知序列建模
使用 GRU(门控循环单元)作为序列建模骨干,每 save_every 步保存隐藏状态到历史缓存。在每一步,通过 top-k 历史注意力 检索最相关的历史状态,并通过 标量门控融合 将历史信息注入当前表示:
h_gru = GRU(x, h_prev) # GRU 序列建模
H_cache = {h_t | t mod save_every == 0} # 历史缓存
attn = softmax(Q(h_gru) · K(H_cache) / √d) # top-k 注意力检索
h_hist = V(H_cache) · attn # 历史检索输出
gate = σ(W_g · [h_gru; h_hist]) # 标量门控
output = gate · h_gru + (1 - gate) · h_hist # 门控融合2. 固定张量历史缓存(推理时)
推理时预分配 GPU 张量作为历史缓存,通过循环指针实现 O(1) 写入更新,避免每次 stack 操作带来的显存分配开销。
3. 平方 ReLU 前馈网络
采用 relu(W_k · x)² 激活函数配合接收门控(receptance gate),替代传统 Transformer 的 FFN:
v_ffn = W_v · relu(W_k · x)² # 平方 ReLU 激活
output = x + r_ffn · v_ffn # 接收门控残差4. 训练与推理双模式历史检索
训练和推理均激活历史检索机制,但使用不同的缓存策略:
- 训练模式:per-batch Python list 缓存 + 因果掩码的 intra-sequence 检索
- 推理 Prefill:持久化固定 tensor 缓存 + 批量历史检索
- 推理 Decode:持久化固定 tensor 缓存 + 单步交叉检索
5. 梯度检查点兼容
所有自定义层(GRU、history_transform MLP)支持 PyTorch 激活检查点,在低显存环境下可用时间换空间。
模型参数
| 参数 | 值 | 说明 |
|---|---|---|
d_model |
450 | 嵌入维度 |
hidden_dim |
450 | GRU 隐藏层维度 |
num_heads |
8 | 多头注意力头数 |
num_layers |
14 | GRU3 Block 层数 |
max_seq_len |
512 | 最大序列长度 |
history_top_k |
6 | 历史检索 top-k 值 |
save_every |
6 | 历史缓存保存间隔 |
n_maxgate |
0 | 门控上限层数(0=不限制) |
v_maxgate |
1.0 | 门控最大值 |
dropout |
0.0 | Dropout 率 |
use_h |
True | 启用历史检索 |
freeze_gate |
False | 是否冻结门控权重 |
性能评测
与同规模 Transformer 对比
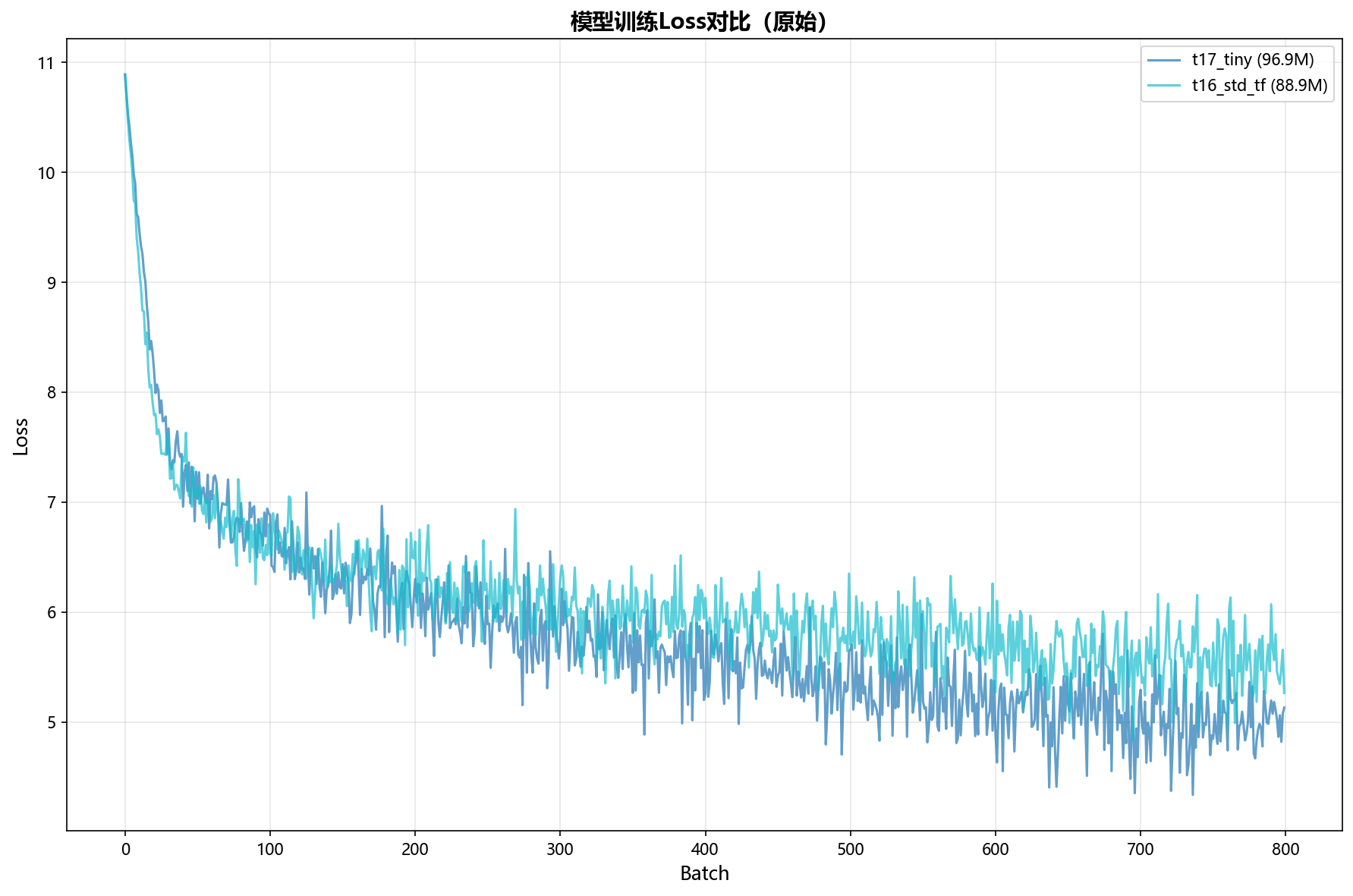
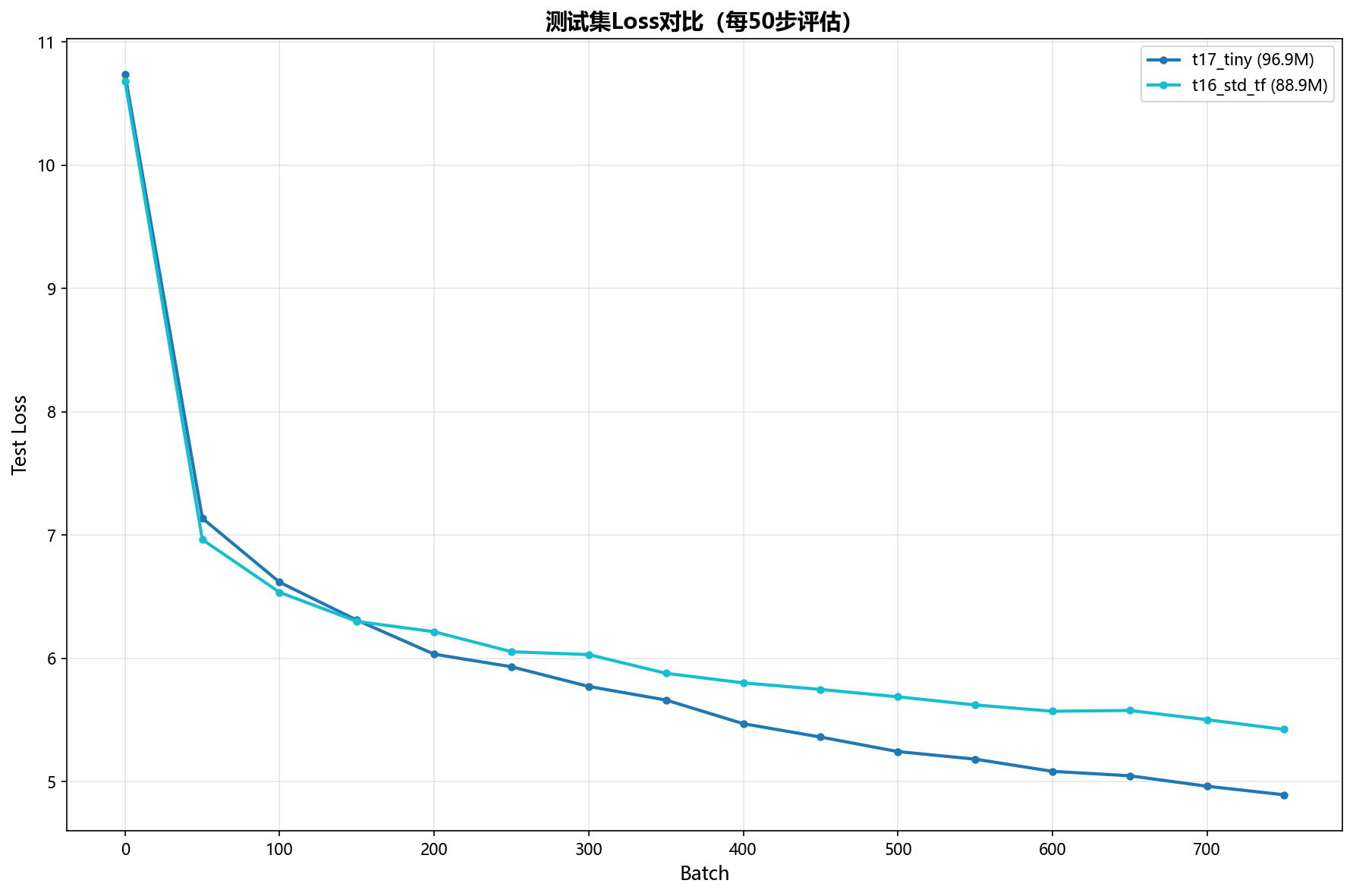
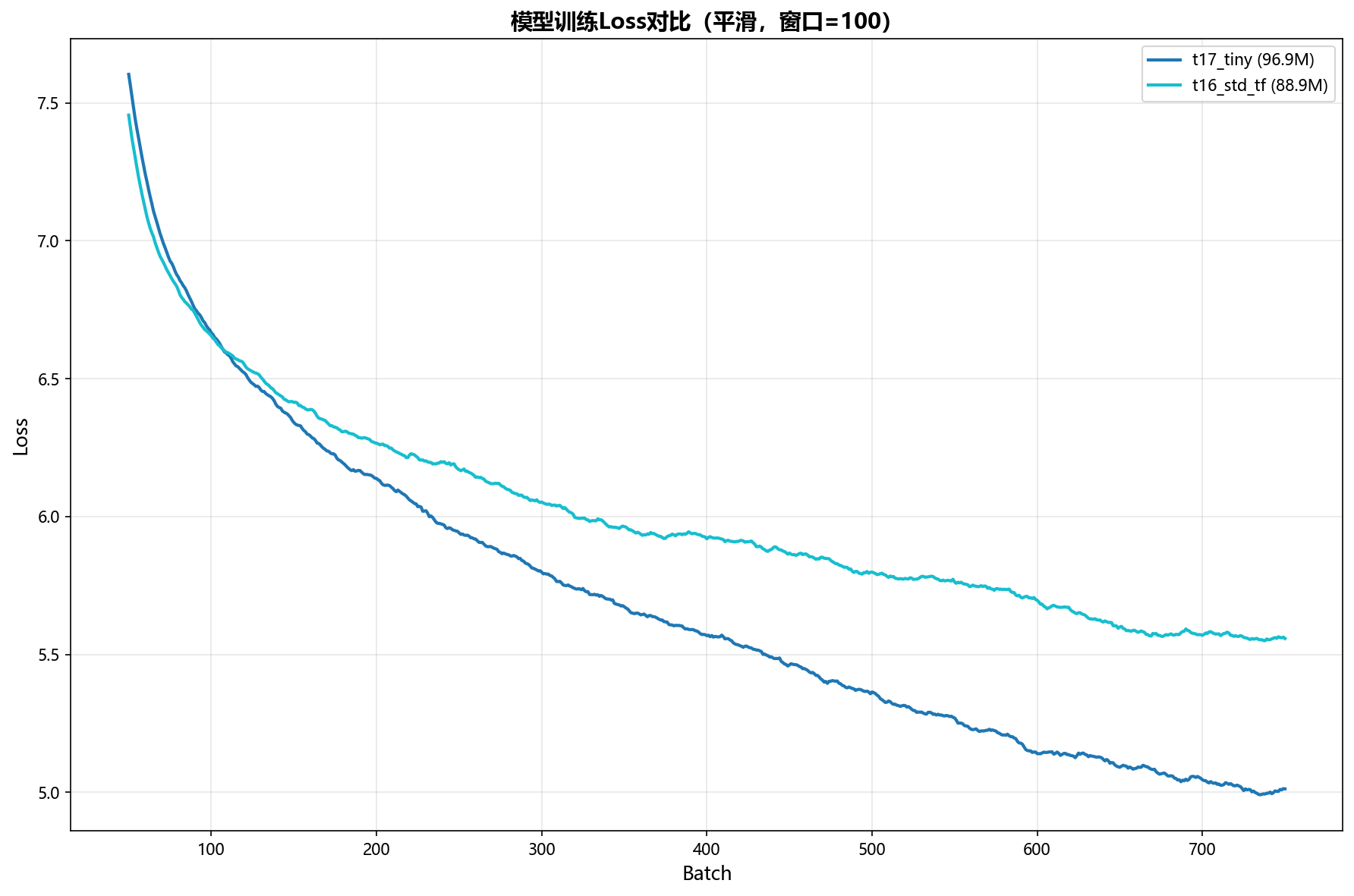
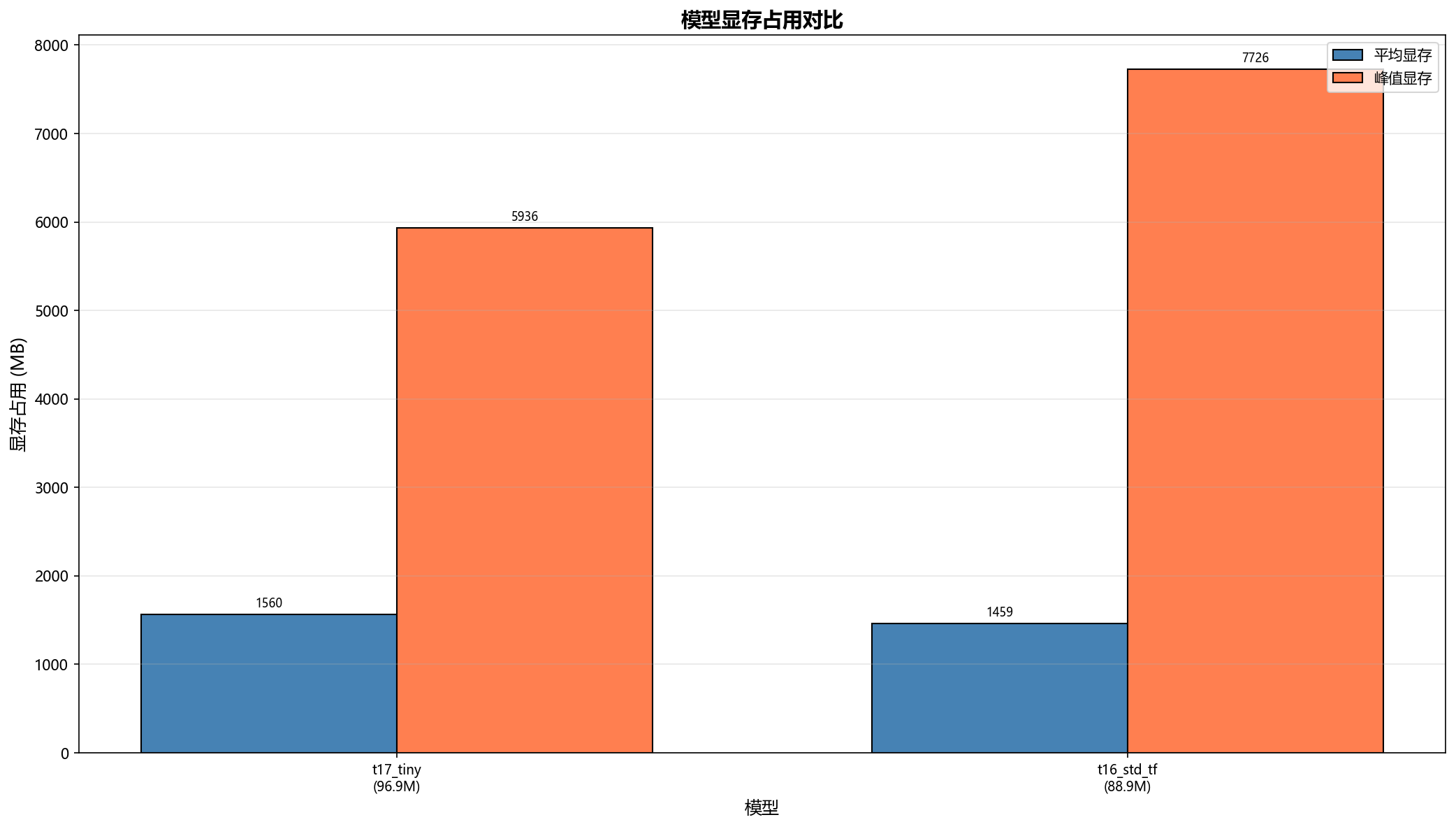
Xiaothink-T17-Tiny的架构(96.9M参数) 与同参数量级的标准 Transformer(T16-Std-TF,88.9M 参数)在相同数据(中文,Minimind-hqpretrain数据集部分数据,length=1024,batch_size=8)上的对比结果:
| 指标 | T17-Tiny(96.9M) | T16-Std-TF(88.9M) |
|---|---|---|
| 最终训练损失 | 5.130 | 5.263 |
| 最终测试损失 | 4.895 | 5.424 |
| 最低训练损失 | 4.337 | 4.833 |
| 峰值显存 | 5936 MB | 7726 MB |
| 平均显存 | 1560 MB | 1459 MB |
T17-Tiny 在测试损失上显著优于同规模 Transformer(4.895 vs 5.424),且峰值显存更低(5936 MB vs 7726 MB)。
训练曲线对比
资源消耗对比
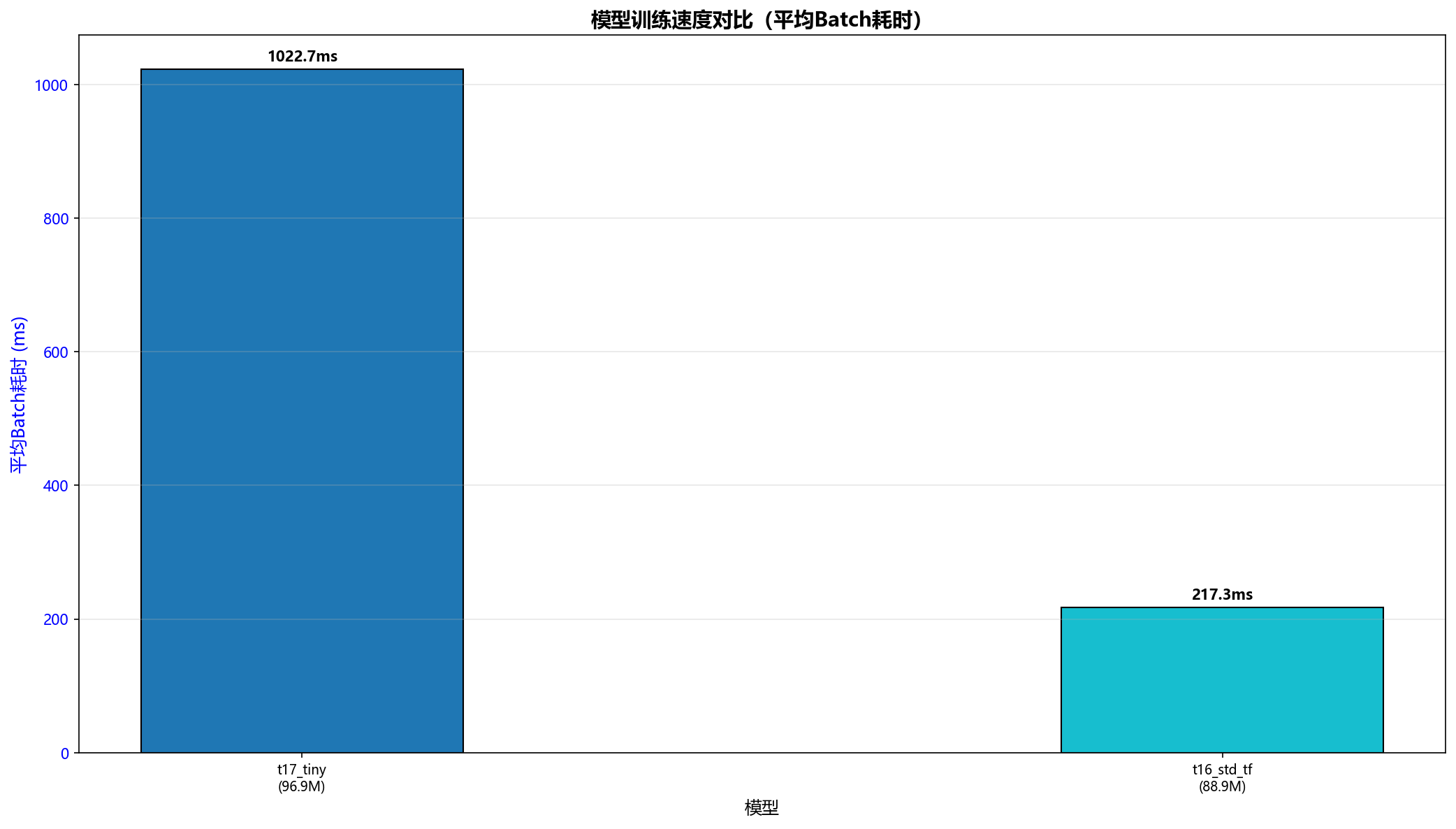
RNN 的低资源拟合优势
由于 GRU3 架构的 RNN 特性,T17-Tiny 在低资源(少量训练数据、低显存)条件下的拟合效果优于同规模 Transformer:
- 空间复杂度接近线性:GRU 的序列建模复杂度接近 O(T),而非 Transformer 的 O(T²)
- 更低的峰值显存:5936 MB vs 7726 MB(节省 23%)
- 更快的收敛速度:在相同训练步数下达到更低的训练和测试损失
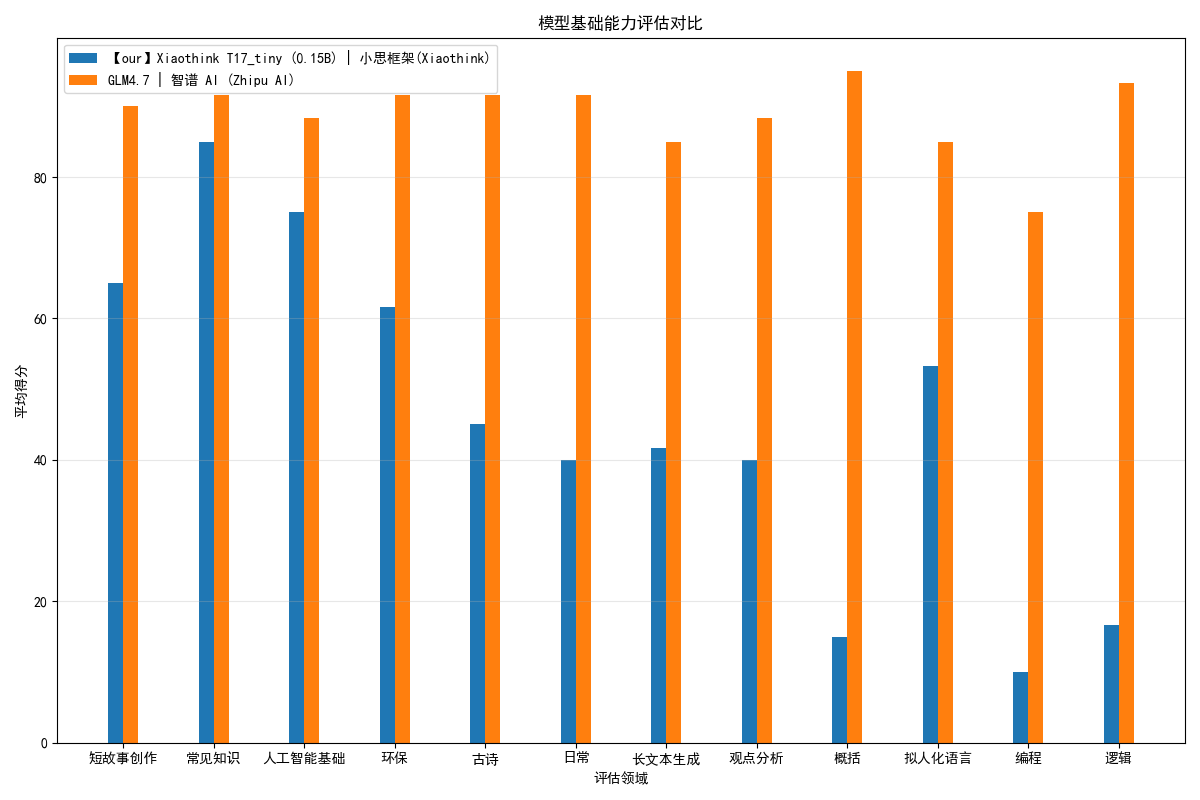
盲测测评
以 GLM-4.7 作为裁判,对 Xiaothink-T17-Tiny 与 GLM-4.7 进行盲测测评:
端侧任务表现
Xiaothink-T17-Tiny 在仅 0.15B 参数的体量下,凭借独特的 GRU3 历史检索架构,在古诗生成、观点分析、文本分类、文本生成、内容概括、绝句创作、短信分类、情感分析等端侧任务上达到了该参数规模下的领先水平。其线性复杂度的空间效率和低峰值显存特性使其特别适合:
- 移动端与嵌入式设备部署:峰值显存仅 5.9GB(且可通过梯度检查点进一步降低),可在消费级显卡甚至 CPU 上运行
- 低资源场景下的快速拟合:RNN 架构在少量数据下收敛速度快于同规模 Transformer
- 实时文本处理:TinySkill 工具箱提供了即用型的分类与生成接口,无需编写复杂流程
- 边缘计算与隐私保护:模型完全本地运行,数据无需上传至云端
TinySkill 工具箱
Xiaothink-T17-Tiny 内置了 TinySkill 工具箱,这是一种轻量级技能注册与执行机制。通过预定义的 prompt 模板和执行类型,用户可以直接调用以下 8 个内置技能,无需编写任何 prompt。
内置技能一览
| ID | 名称 | 类型 | 说明 |
|---|---|---|---|
summarize_word |
词语概括 | generate | 用一个词语概括输入内容 |
summarize_short |
短词概括 | generate | 用简短的词语概括内容 |
generate_title |
题目生成 | generate | 为输入文本生成一个题目 |
generate_poem |
古诗生成 | generate | 根据内容生成一段优美的古诗 |
generate_philosophy |
哲理文本 | generate | 生成一段富有哲理的文本 |
generate_jueju |
绝句生成 | generate | 根据主题生成一首绝句 |
sms_classify |
短信分类 | classify | 判断短信是广告推销还是生活通知,给出推理过程 |
emotion_analysis |
情感分析 | classify | 分析文本的正面/反面/中性情感倾向 |
技能类型说明
- generate 类型 (6 个):文本生成任务,默认
temperature=0.5, max_length=64, repetition_penalty=1.1。模型根据 prompt 模板生成对应文本。 - classify 类型 (2 个):文本分类任务,默认
temperature=0.001, repetition_penalty=1.0。基于模型输出中的关键词命中概率计算分类概率,无需额外训练。
分类原理
classify 类型的技能通过统计输出文本中各类别关键词的出现次数来计算概率:
- 极低温度(0.001)调用模型,得到确定性输出
- 统计每个类别关键词在输出中的出现次数
- 概率 = 该类命中次数 / 总命中次数
- 若总命中数为 0,归为 other 类别(概率 = 1.0)
示例 :短信分类技能(sms_classify)中:
- 类别
"0"(广告推销)关键词:["广告", "营销", "推销", "销", "宣传"] - 类别
"1"(生活通知)作为 other 类别
若模型输出含有"广告"×1 + "营销"×1,则概率为 {"0": 1.0, "1": 0.0}。
自定义注册
除内置技能外,用户可通过 TinySkill 类注册自定义技能,支持设置独立的 temperature、max_length、repetition_penalty 参数。详见 xiaothink 库文档 - TinySkill 自定义注册。
快速开始
安装
bash
pip install xiaothink # 基础安装(无深度学习后端)
pip install xiaothink[torch] # 包含 PyTorch(T17 推荐)
pip install xiaothink[all] # 包含所有后端使用
TinySkill 工具箱 (完整代码见 xiaothink库文档 README_zh.md#tinyskill-工具箱v142-新增):
python
from xiaothink.llm.inference_torch.torch_formal import TorchModel
from xiaothink.llm.tools.tiny_skill import TinyToolbox, register_default_skills
# 1. 加载模型
model = TorchModel(ckpt_dir="模型权重目录", MT="t17_tiny")
model.set_form("ua_chat")
# 2. 创建工具箱并注册内置技能
toolbox = TinyToolbox(model)
register_default_skills(toolbox)
# 3. 按技能名称或 id 执行
result = toolbox.run("题目生成", "春天来了,万物复苏。")
print(result["text"])更详细的使用说明(多轮对话、文本生成、TinySkill 自定义注册等)请参阅 xiaothink 库文档。
环境变量
bash
# 仅导入 PyTorch 后端(跳过 TensorFlow/PaddlePaddle)
export XIAOTHINK_BACKEND=torch局限性
- 仅支持中文:截止 Xiaothink-T17 系列发布,所有模型只支持中文处理
- 不支持 ModelScope:由于 GRU3 历史检索架构的特殊性,目前不支持 ModelScope 调用
- 推理速度:GRU3 的逐步解码速度低于纯 Transformer 架构,但空间复杂度更优
- 序列长度限制:理论支持无限上下文,训练时使用了 256 token 的序列长度
许可证
本项目采用 Apache License 2.0 许可证。
Copyright © 2026 Xiaothink Team