一、研究背景与基础框架
1. 自动驾驶感知核心任务
3D检测和多目标跟踪(MOT)是自动驾驶感知系统的两个基础任务,前者输出当前帧物体3D bounding box,后者输出跨帧物体的关联ID与运动轨迹。
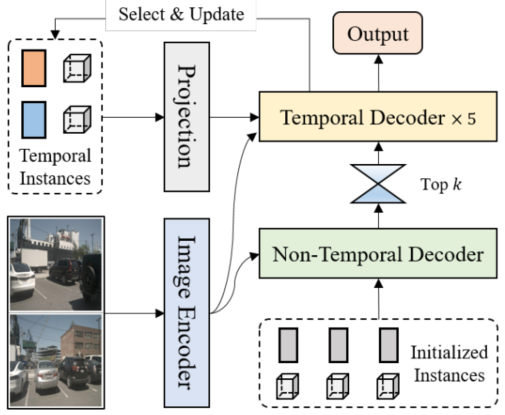
图1:稀疏4D框架概览,该框架输入多视角视频,并输出所有帧的感知结果。
2. 主流3D感知算法范式对比
| 范式 | 核心特征 | 典型代表 |
|---|---|---|
| 稠密BEV-based算法 | 需要先将多视角图像特征通过视图转换投影到鸟瞰视角空间,再进行检测 | BEVFormer、BEVDepth |
| 稀疏query-based算法 | 以实例query为媒介,无需显式视图转换,检测头计算量与感知距离、图像分辨率无关,易端到端集成下游任务 | DETR3D、Sparse4D系列 |
3. 基线模型Sparse4Dv2的结构
- 整体为端到端稀疏时序感知框架:图像编码器提取多视角图像的多尺度特征,解码器以稀疏实例query为输入,迭代优化实例特征与显式anchor,输出检测结果。
- 时序建模采用循环结构:将上一帧的实例经过自车姿态与速度补偿后,投影到当前帧作为部分输入,实现时序信息融合。
- 存在的问题:稀疏算法采用一对一正样本匹配,训练初期匹配不稳定、正样本数量少,解码器收敛难度大;原始注意力机制存在特征干扰,导致注意力权重异常。
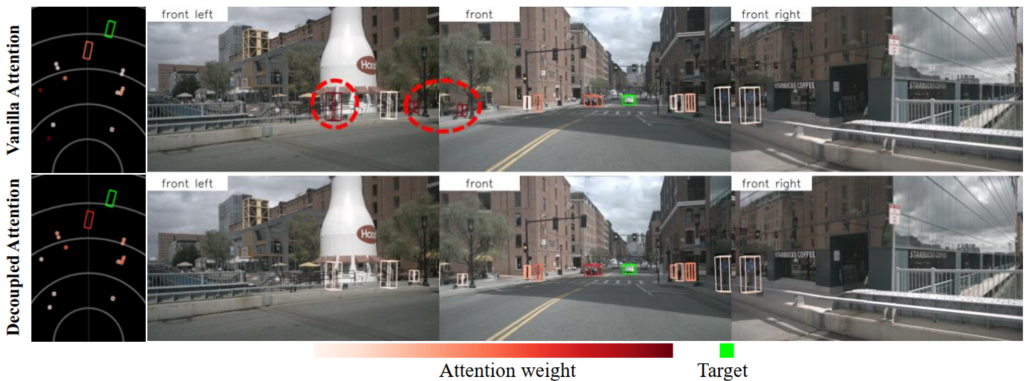
图3:实例自注意力中注意力权重的可视化:1)第一行展示了常规自注意力中的注意力权重,其中红色圆圈内的行人与目标车辆(绿色方框)存在非预期的相关性。2)第二行显示了解耦注意力中的注意力权重,有效解决了该问题。
二、Sparse4D v3的核心改进
1. 时序实例去噪(Temporal Instance Denoising)
- 设计动机:解决稀疏query-based算法训练收敛不稳定、正样本少的问题,将2D检测的去噪思想拓展到3D时序场景。
- 实现逻辑:
- 训练阶段在learnable query之外,额外生成多组带噪声的query:对3D真实框(GT)的位置、尺寸、航向角、速度添加不同幅度的随机噪声,生成带噪anchor。
- 采用二分图匹配为每组带噪query分配正负样本,避免噪声样本的匹配歧义。
- 拓展到时序场景:随机选择部分带噪实例,和正常实例采用相同的时序投影策略传播到下一帧,适配循环训练流程。
- 引入注意力掩码隔离不同组的实例,避免组间特征干扰,保证匹配无歧义。
- 效果:提升训练稳定性,丰富正样本数量,单帧去噪+时序去噪分别可带来0.8%、0.4%的mAP提升。
2. 质量估计(Quality Estimation)
- 设计动机:传统分类置信度无法反映预测框和GT的匹配质量,导致检测结果排序不合理,影响最终指标。
- 核心设计:
- 定义两个3D检测质量指标:
- 中心度(Centerness):C=exp(−∥x,y,zpred−x,y,zgt∥2),衡量预测框和GT的中心距离。
- 航向角相似度(Yawness):Y=sinyaw,cosyawpred⋅sinyaw,cosyawgt,衡量航向角的匹配程度。
- 网络在输出分类置信度的同时,额外预测这两个质量指标,分别用交叉熵损失和Focal Loss监督,最终将分类置信度与质量预测结果相乘作为最终检测排序依据。
- 定义两个3D检测质量指标:
- 效果:让检测结果的置信度更贴合实际定位精度,显著降低定位误差(mATE下降2.8%),提升检测指标。
3. 解耦注意力(Decoupled Attention)
- 设计动机:原始自注意力将实例特征和anchor embedding直接相加作为输入,会引入特征干扰,导致注意力权重异常(比如车辆query错误和行人产生高相关性)。
- 实现逻辑:
- 改进anchor编码:对anchor的位置、尺寸、航向角、速度等不同分量独立编码后拼接,降低参数量和计算量。
- 改进注意力计算:将实例特征和anchor embedding拼接后再计算注意力权重,替代直接相加的方式,在多头注意力层维度实现特征解耦。
- 与Conditional DETR的区别:Conditional DETR优化的是query和图像特征的交叉注意力,而该改进针对query之间的自注意力与时序交叉注意力,适配稀疏实例间的关系建模。
- 效果:消除异常注意力权重,提升mAP 1.1%,同时速度几乎无损失。
三、端到端3D多目标跟踪拓展
1. 现有跟踪方法的局限
- 跟踪-by-detection方法:依赖检测结果做后处理数据关联,流程复杂、超参数多,无法端到端优化。
- 现有端到端跟踪方法:需要修改训练流程,引入跟踪ID的匹配监督,依赖GT ID,还需要额外微调。
2. Sparse4D v3的轻量跟踪实现
无需修改检测器的训练流程、损失函数,也不需要GT ID监督,仅在推理阶段增加ID分配逻辑即可实现跟踪:
- 实例的生命周期由Sparse4D原有的top-k时序传播策略天然管理,实例会在帧间持续传播优化。
- 当某实例的检测置信度超过设定阈值时,为其分配唯一ID,该ID在后续时序传播中保持不变。
- 低置信度实例不分配ID,继续参与帧间传播,直到置信度达标或被top-k策略淘汰。
四、实验验证
1. 评测基准与指标
采用自动驾驶主流的nuScenes数据集验证效果:
- 检测指标:mAP(平均精度均值)、NDS(nuScenes检测综合得分)、以及定位、尺寸、航向角、速度、属性等细分误差指标。
- 跟踪指标:AMOTA(平均多目标跟踪精度)、AMOTP(平均多目标跟踪位置误差)、IDS(ID切换次数)、Recall(召回率)等。
2. 核心实验结果
| 配置 | 检测效果(对比v2基线) | 跟踪效果(对比v2基线) | 速度表现 |
|---|---|---|---|
| ResNet50+256×704输入 | mAP+3.0%、NDS+2.2%,达到46.9%、56.1% | AMOTA+7.6%,达到49.0% | 19.8FPS,接近v2的20.3FPS |
| 大模型+未来帧融合 | 最优版本在nuScenes测试集达到71.9% NDS、67.7% AMOTA | - | 部分指标超过激光雷达检测方案(如TransFusion) |
3. 消融实验结论
三个改进点均能带来稳定的性能提升:时序去噪提升收敛稳定性,解耦注意力优化实例关系建模,质量估计优化检测排序合理性,三者叠加实现了最终的性能突破。
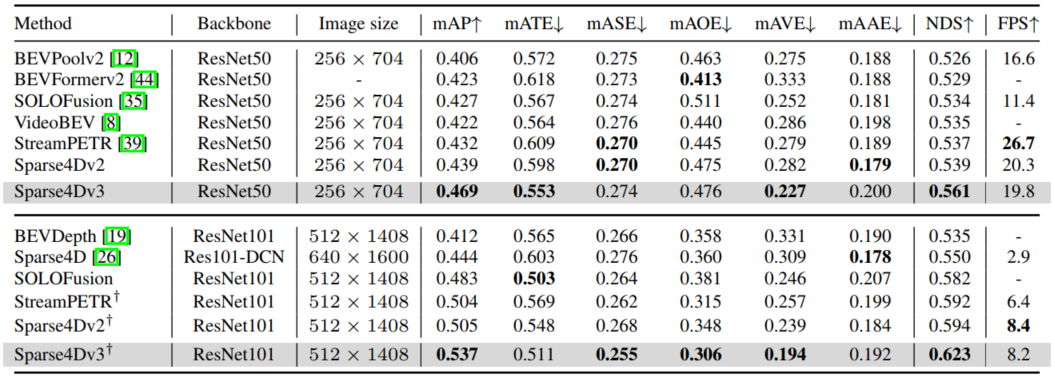
表1:在nuScenes验证数据集上进行3D检测的结果。†† 表示使用来自nuImage数据集的预训练权重。
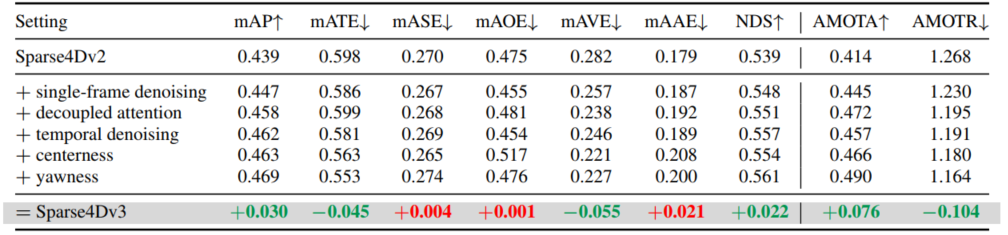
表5:消融实验。最后一行中,绿色字体表示指标有所提升,红色字体则表示相反情况。
五、研究展望
Sparse4D框架未来可拓展方向包括:
- 进一步优化跟踪性能,降低ID切换率;
- 拓展为纯激光雷达或多模态感知模型;
- 基于端到端跟踪能力,集成预测、规划等更下游的自动驾驶任务;
- 扩展支持在线建图、交通标志/信号灯检测等其他感知任务。