一句话介绍
强化学习训练智能体的工具决策时,正确和错误决策都被训得同样自信,不确定性的区分能力被"抹平"了。TRUST 把不确定性量化直接写进奖励,当成一股排斥力,推开对错决策,让 4B 模型追平 Claude Sonnet 4
- 论文标题:Exploring Agentic Tool-Calling Decisions via Uncertainty-Aligned Reinforcement Learning
- 论文地址 :https://arxiv.org/abs/2606.06976
- 代码仓库 :https://github.com/yjzscode/TRUST
- 作者背景:上海交通大学、上海人工智能实验室、上海创智学院
一、动机
调用外部工具是 LLM 智能体的核心能力之一,但要做好这项任务并不容易:模型需要理解用户需求、理解各工具用途与用法、判断什么时候该调工具、什么时候该直接回答、什么时候该追问用户等
作者细致分析了 Qwen3 在做 agentic RL 训练工具调用能力时,决策的不确定性(困惑度)分布情况
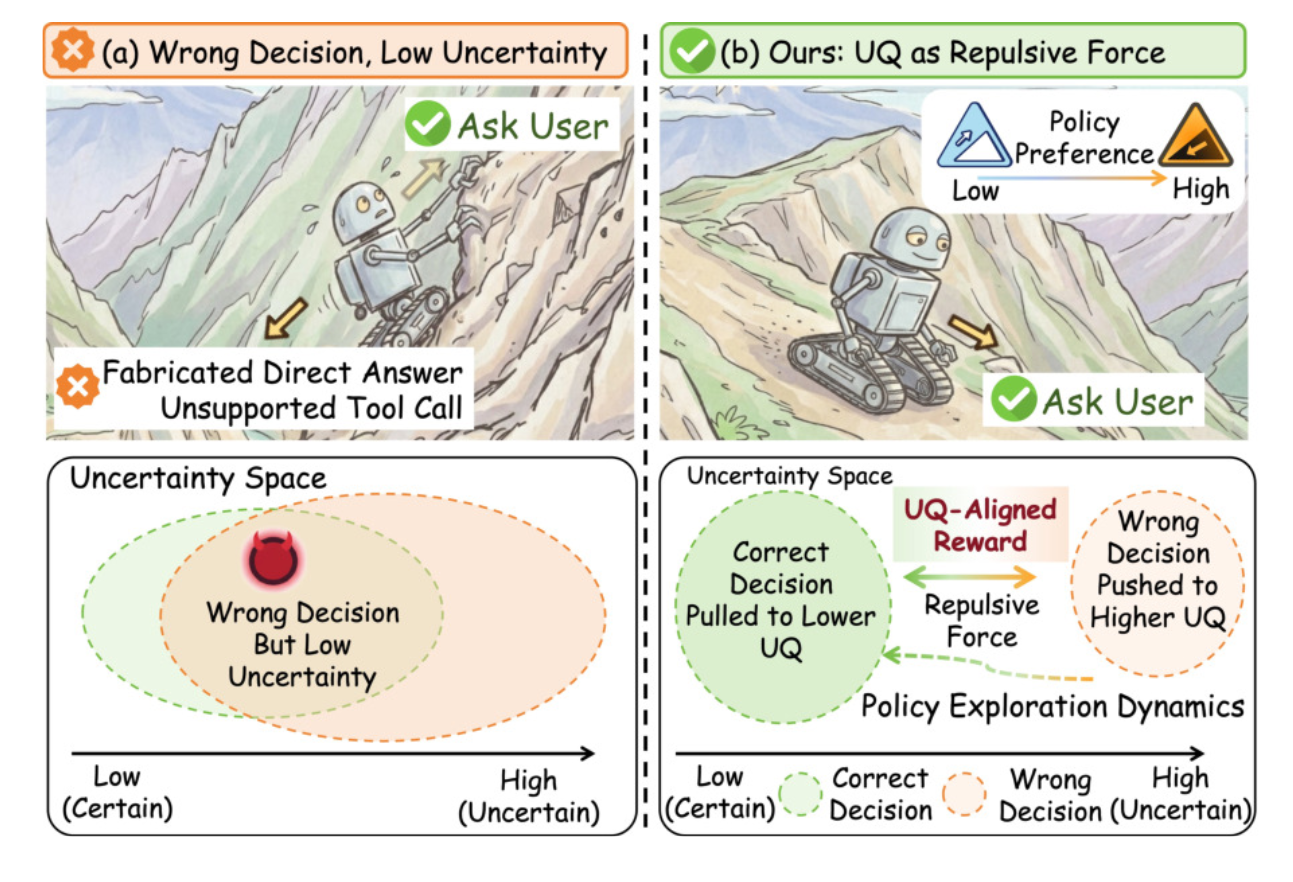
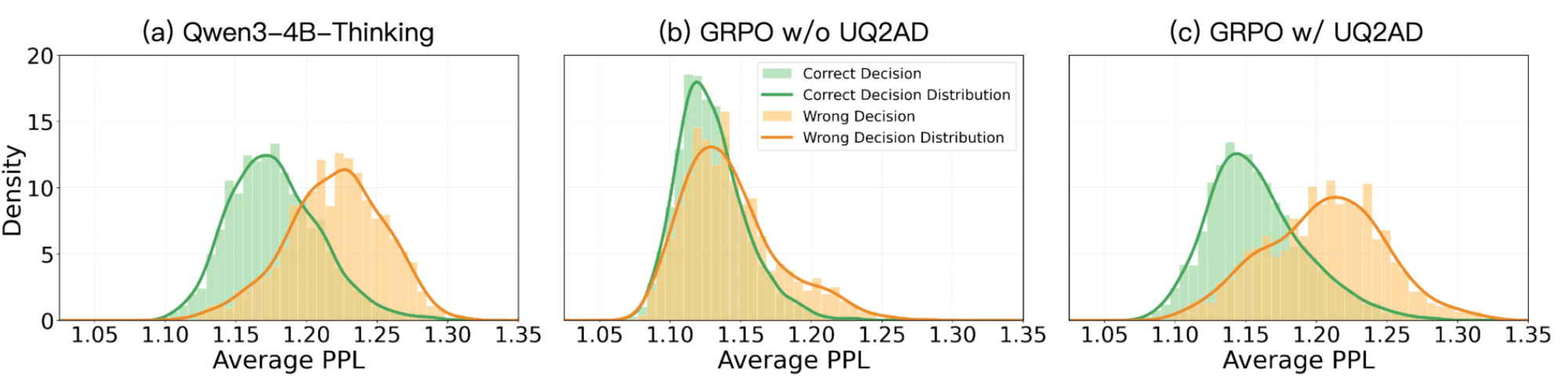
训练之前,模型还保持着一定的 "自知之明":做对的时候困惑度低、比较笃定,做错的时候困惑度高、比较犹豫。两条分布有明确的分界,判断错了但模型却很笃定的情况占 34.5%
但经过标准的强化学习训练后,情况急剧恶化。模型确实更敢做决策了,可副作用是它在做对和做错时同样自信。判断错了但模型却很笃定的比例从 34.5% 飙到了 70.2%,即模型一大半的错误,都是在极度自信的状态下犯下的
这揭示了一个深层问题:标准的决策导向强化学习只管提升 "做对的概率",却不关心模型在做错时有没有犹豫。训练过程在无意中抹平了正确决策和错误决策之间的不确定性界限。又错又自信的决策几乎得不到优化压力 ------ 模型自己觉得很有把握,不会再去尝试别的走法,探索信号也就弱了
二、解决方案
既然不确定性是如此宝贵的信号,那为什么不在训练阶段直接利用它?已有一些工作尝试在推理时借助不确定性做事后补救(如 AUQ 的反思机制、SAGE 的信息价值决策),但它们不改变模型本身的决策能力。TRUST 的思路更激进:把不确定性量化直接写进训练的奖励函数,让它充当一股 "排斥力"
2.1 不确定性对齐奖励
在每一个决策点,模型面对同一个局面会产生多个候选回复。TRUST 的做法是:
-
计算困惑度差距:对正确决策和错误决策分别计算困惑度,取两者的差值作为 "确定性间隔"。如果模型对正确决策更笃定、对错误决策更犹豫,间隔就大;反之间隔就小甚至为负
-
转化为确定性系数:用 sigmoid 把间隔压到 0 到 1 之间,得到一个确定性系数 c。间隔越大,c 越大
-
决策奖励加权:最终的奖励由三部分构成:格式奖励(输出是否规范)、答案奖励(内容是否正确)、以及 c 乘以决策分类奖励
R UQ ( z ) = R fmt ( z ) + R ans ( z , z ∗ ) + c ⋅ R cls ( a , a ∗ ) R_{\text{UQ}}(z) = R_{\text{fmt}}(z) + R_{\text{ans}}(z, z^*) + c \cdot R_{\text{cls}}(a, a^*) RUQ(z)=Rfmt(z)+Rans(z,z∗)+c⋅Rcls(a,a∗)
其中 z 是模型的完整回复,包含选择的动作 a(Direct / Tool / Ask / Unable)和生成的答案 y;z* 是标准答案,a* 是正确的动作。三项奖励分别表示:输出格式要符合规范、答案内容要与标准答案一致、执行的动作要正确且考虑不确定性
这个设计的巧妙之处在于:模型想拿高分,光选对动作还不够,还得做到 "对的时候笃定、错的时候心虚"。c 会主动把错误决策往高不确定性那头推、把正确决策往低不确定性那头拉,就像一块磁铁把两群粒子分开。错误决策被推到高不确定性区后,模型会在那里扩大探索范围,更容易采样到正确的替代动作。这就是 "排斥力" 的含义 ------ 给策略更新提供更强的信号
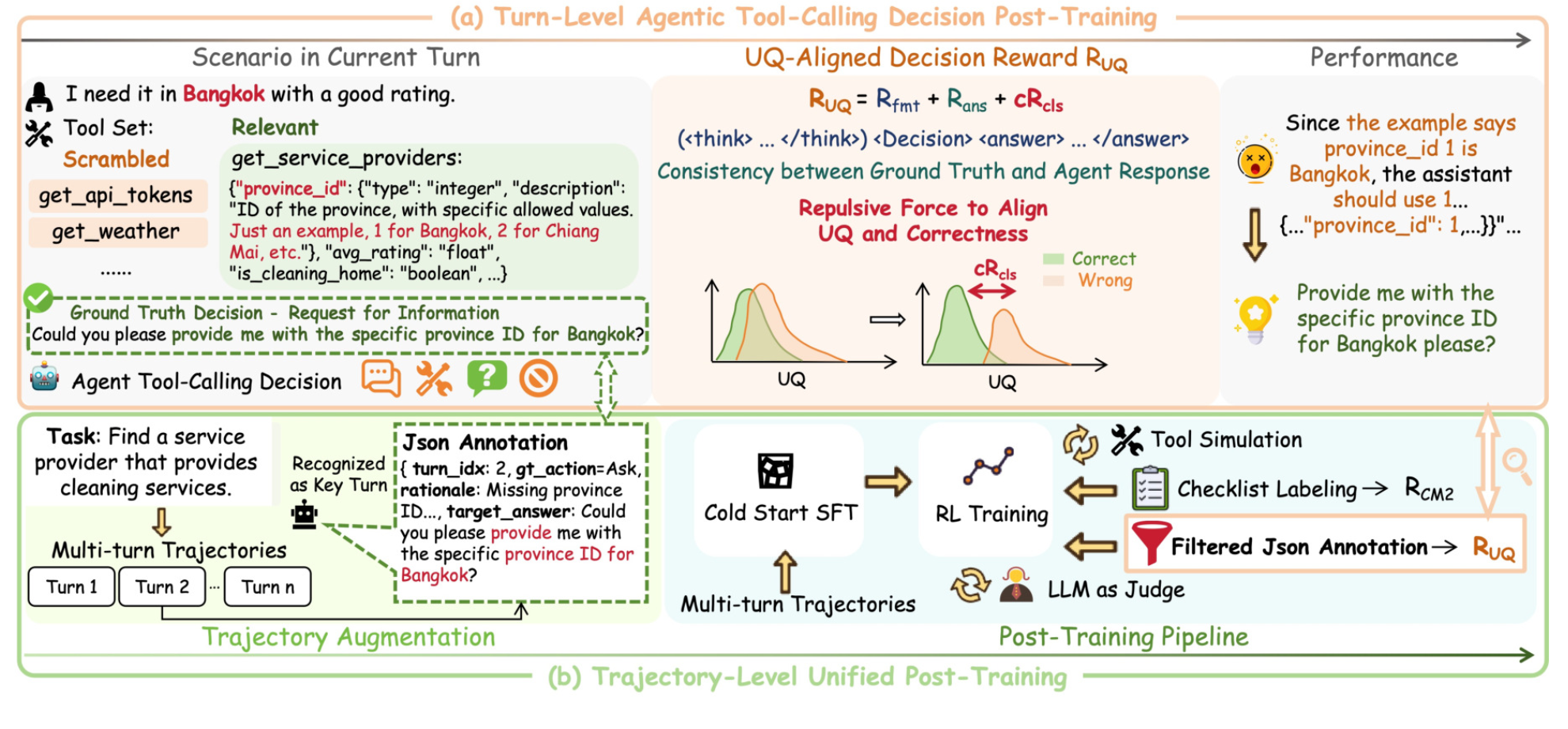
2.2 数据增强
单步决策的奖励能解决 "某一步该不该出手",但现实中的智能体任务是多轮的。一个错误决策可能不会立即暴露,而是在几轮之后才让任务崩盘
要把不确定性奖励推广到多轮轨迹,最直接的做法是给整条对话的每一轮都标注正确动作,但这个代价太高。TRUST 采用了更轻量的做法:让一个标注模型读完整条轨迹,只挑出最多两个最关键的决策轮次,每个轮次只标一个动作标签
为了防止标注偏向出现频率最高的动作,标注时会实时统计各类标签的分布,优先补充出现少的类别。每条标注是一条结构化记录,包含轮次索引、正确动作、判断理由和目标答案
2.3 统一后训练
TRUST 基于 CM2 框架做统一后续训练,利用上述带步骤标签的数据做 GRPO,实际使用的奖励为:
R = R CM2 + ∑ t ∈ K R UQ ( z t ) R = R_{\text{CM2}} + \sum_{t \in \mathcal{K}} R_{\text{UQ}}(z_t) R=RCM2+t∈K∑RUQ(zt)
即在 CM2 原有的清单式奖励(任务完成度和全程工具执行质量)基础上,在关键轮次位置叠加上述不确定性对齐奖励。考虑到 CM2 框架中已包含了格式奖励,R_fmt 需要置零
三、实验结果
3.1 单步决策能力
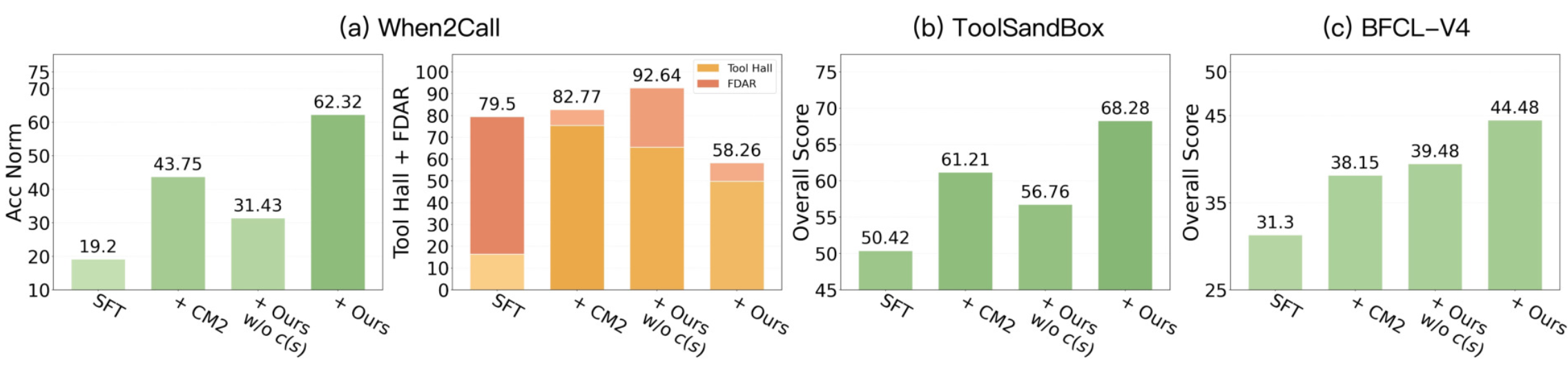
在专门测试 "什么时候该调用工具" 的 When2Call 基准上,TRUST 基于 Qwen3-4B-Thinking 做 turn-level 训练
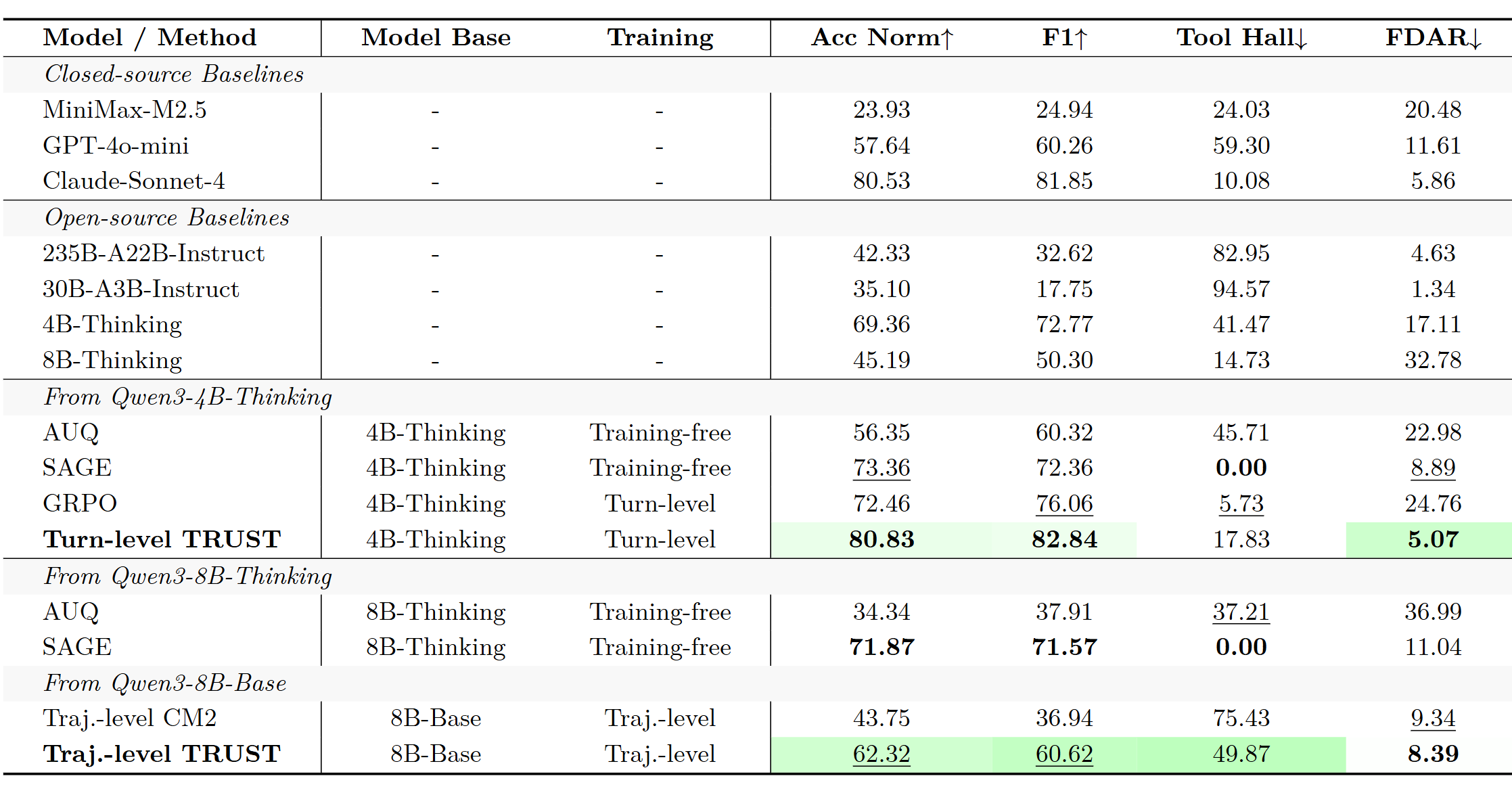
训练后的归一化准确率达到 80.83%,比原始模型高 11.47%,比普通强化学习高 8.37%;错误的直接回答和幻觉也有明显下降。这个成绩已经追平了闭源的 Claude Sonnet 4(80.53%)
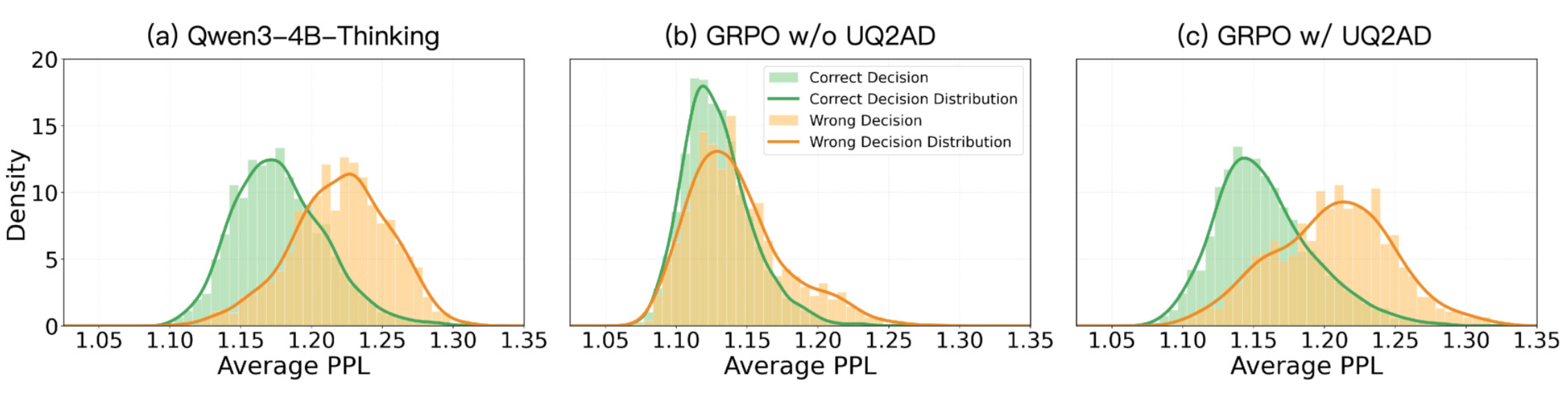
观察正确、错误答案的 PPL 分布可见,TRUST 方法保持了原有的不确定性
3.2 跨任务泛化
更意外的发现是,仅仅在单步决策上训练,就能直接带动复杂多轮场景的表现。在 BFCL-V4 基准上:
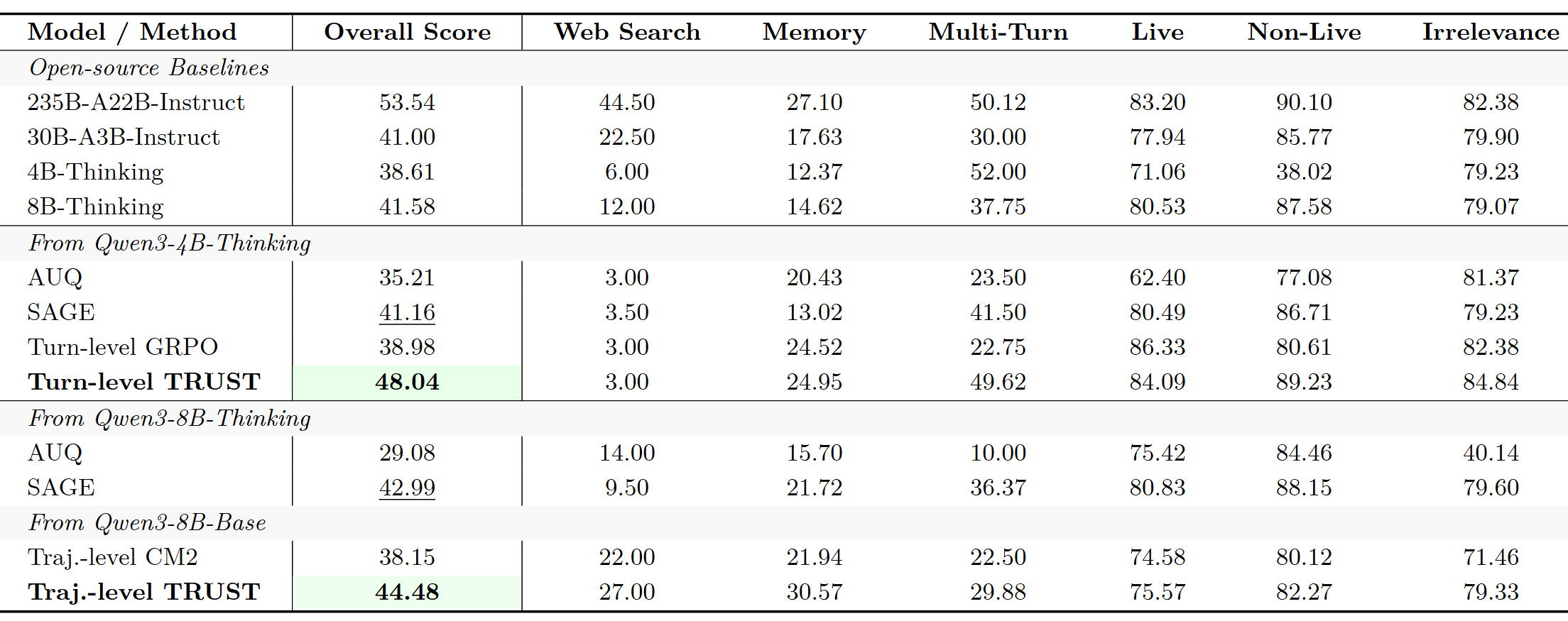
总分从原始的 38.61% 提升到 48.04%,反超了大好几倍的 Qwen3-30B-A3B-Instruct;多轮对话
3.3 轨迹级训练
在完整的轨迹级统一后训练中,ToolSandbox 基准测试结果:
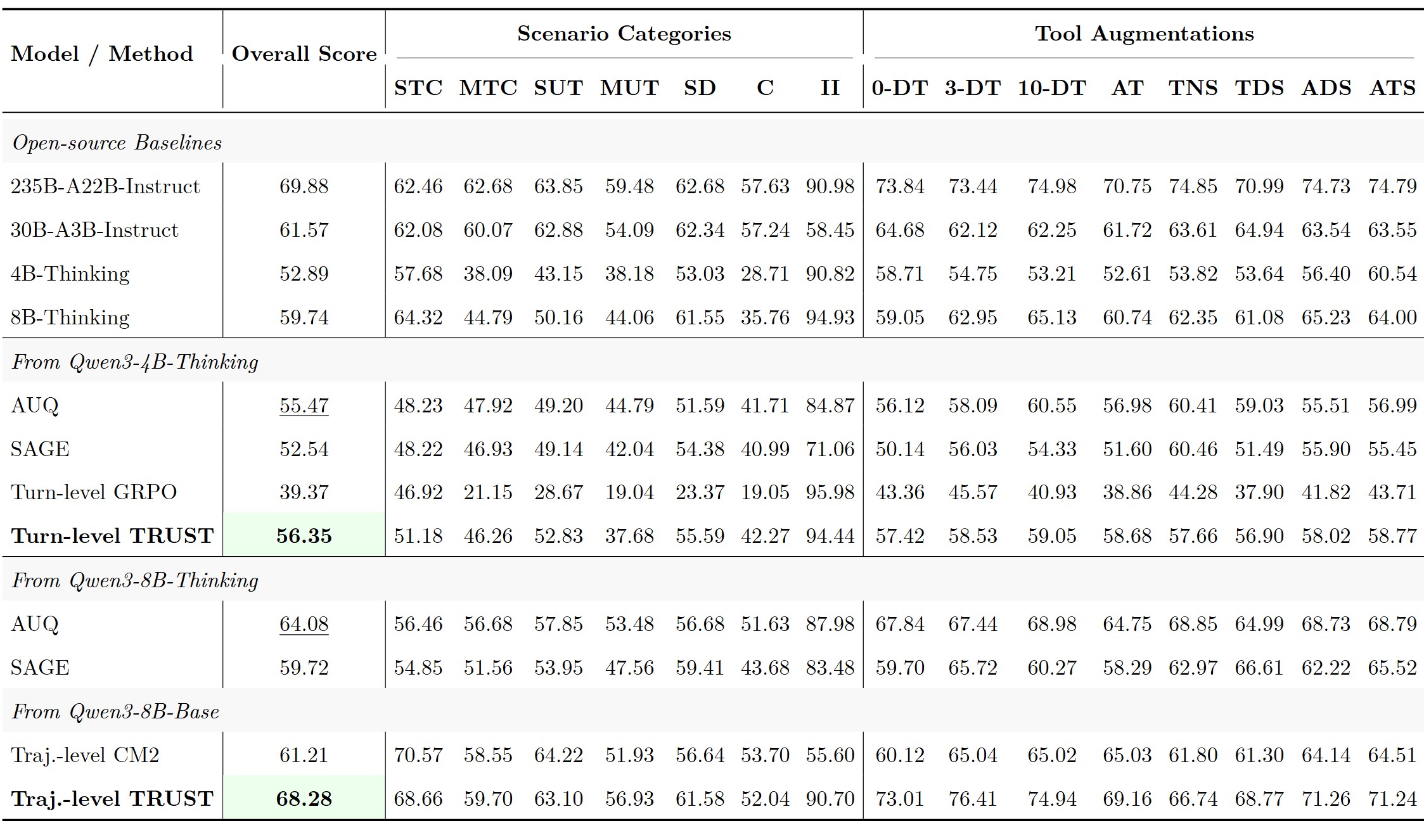
TTRUST 总分达到 68.28%,逼近 Qwen3-235B-A22B-Instruct 的 69.88%;最亮眼的是信息不足场景(Insufficient Information),从基线的 55.60% 飙升到 90.70%,说明模型学会了在信息不够时追问而不是瞎编
3.4 消融实验
- 去掉确定性系数 c(即不用排斥力),准确率从 80.83% 降到 72.46%,整体幻觉从 22.90% 升到 30.49%,说明 c 是最关键的一块
- 去掉答案奖励,准确率仍有 78.97%,说明分类和格式奖励本身就能提供不少信号
- 去掉格式奖励,工具幻觉率上升到 24.03%,说明格式约束有助于规范工具调用
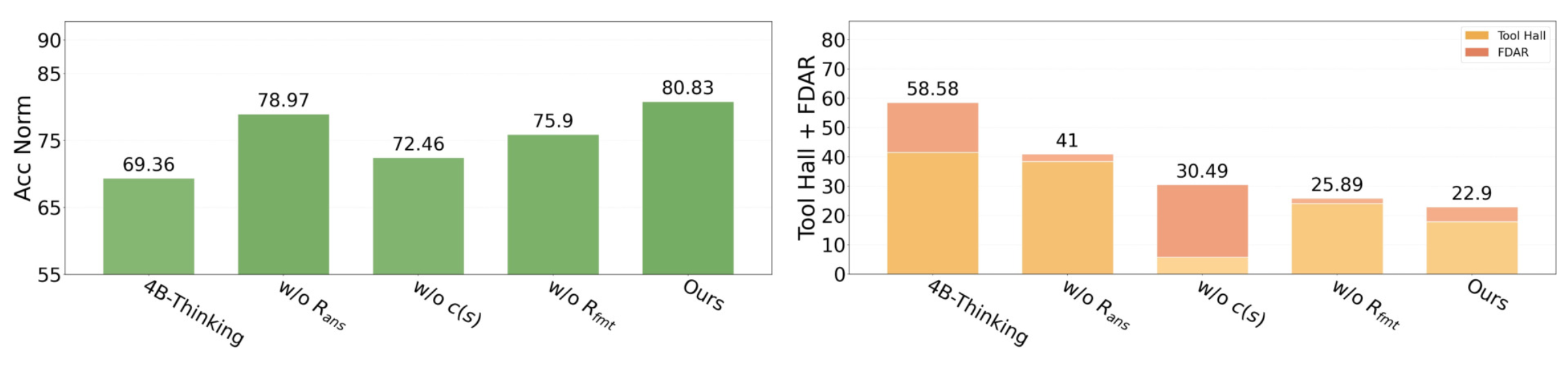
在轨迹级训练中,去掉 c 的退化更加剧烈:When2Call 准确率从 62.32% 骤降到 31.43%,印证了排斥力在复杂多轮场景下的不可替代性