目录
项目整体介绍
有需要本项目的代码、文档、完整资源,或者需要部署调试的朋友,可以私信博主。
这个项目围绕二手房交易数据展开,目标是把原始房源数据变成一个可以查询、可以分析、可以可视化、也可以做价格预测的完整平台。前期主要处理房源字段比较杂、数据来源分散、展示维度不统一的问题,后期把清洗后的数据接入到 Web 系统中,用图表、大屏和预测模型把结果展示出来。整体上,它不是单纯写几个统计图,也不是只训练一个模型,而是把数据采集、数据治理、数据库存储、后台管理、可视化分析和智能预测串成了一条完整链路。
我在整理项目时,把重点放在"能不能跑起来、能不能看得懂、能不能展示出效果"这几个方面。数据层面保留了房源名称、成交价格、建筑面积、楼层、户型结构、建筑类型、装修情况、是否配备电梯、地区、抵押信息等核心字段;系统层面则围绕用户登录、数据管理、统计分析、大屏展示和房价预测几个模块展开。项目最终形成的是一个偏工程化的数据应用平台,既可以作为大数据课程设计、毕业设计或实训项目展示,也适合继续扩展成更完整的房产数据分析系统。

图 1 项目封面与主题展示
项目背景与建设思路
二手房市场的数据维度比较丰富,同一套房源往往同时包含价格、面积、户型、楼层、朝向、装修、产权、抵押、区域等信息。直接看表格时,很难判断不同区域的价格差异,也不容易发现房屋属性对成交价格的影响。这个项目首先解决的是数据组织问题:把分散的 CSV、Excel 和数据库表整理成统一的数据源,再通过清洗、字段转换和聚合统计,为后面的可视化和预测建模做准备。
从项目实现过程看,数据先经过爬取与汇总,再进行去重、异常值处理和字段规范化。清洗后的数据既可以进入 MySQL 作为业务系统的数据基础,也可以在分析脚本中继续完成聚合统计和模型训练。可视化部分使用 ECharts、Pyecharts 生成柱状图、折线图、饼图、大屏组合图等页面,预测部分则使用 CatBoost 等回归模型完成房价估计。这样设计的好处是,展示页面不是孤立的静态截图,而是来自真实数据处理链路的结果。
项目资料中还包含 Flume、Hive、Hadoop 相关脚本,说明整个系统不仅停留在本地数据分析层面,也预留了大数据处理环境的部署思路。对于课程或项目展示来说,这一点比较关键,因为它能体现从数据接入、数据计算到可视化应用的完整路径,而不是只做前端页面包装。
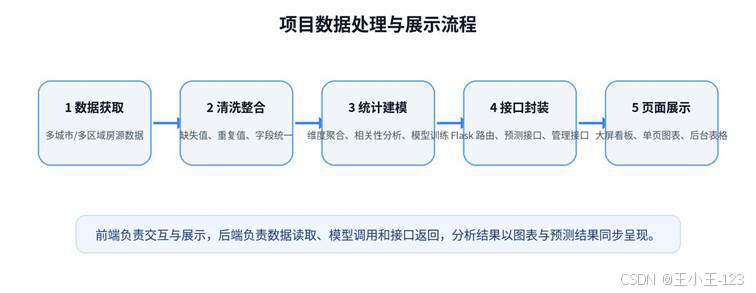
图 2 数据处理与展示流程
技术架构与功能模块
平台采用"数据层---处理层---存储层---服务层---展示层---模型层"的结构。数据层主要负责房源信息采集与原始数据保存;处理层负责数据清洗、字段拆分、缺失处理、异常过滤和格式统一;大数据层使用 Flume、Hadoop、Hive 等组件完成数据接入与计算支撑;存储层使用 MySQL 管理用户信息、房源数据和统计结果;服务层使用 Flask 提供页面路由和接口;展示层使用 Layui、ECharts、Pyecharts 完成后台页面和可视化图表;模型层则负责加载训练好的房价预测模型,并根据用户输入返回预测结果。
前端页面的设计以管理后台为主,左侧菜单按功能分组,包括大屏展示、价格分析、属性分布统计、房屋状态分析、小区专项分析、区域特征分析、时间维度分析和智能预测模型。后台部分提供房源数据表格、检索条件、新增、编辑和删除等常见管理能力。预测页面则把建筑面积、房间数、户型结构、地区、建筑类型、房屋用途、楼总高、房屋朝向、是否配备电梯、产权所属、建筑结构、装修情况、抵押信息、小区名称和房屋年限等字段组织成表单,用户填写或选择后即可得到房价预测结果。
为了方便项目运行和维护,资料中同时保留了数据清洗脚本、可视化生成脚本、SQL 文件、Flask 主程序、模型文件、前端页面和静态资源。整体目录结构比较清晰,后续如果要二次开发,可以从数据源、图表页面、预测模型或后台接口中的任意一部分入手。
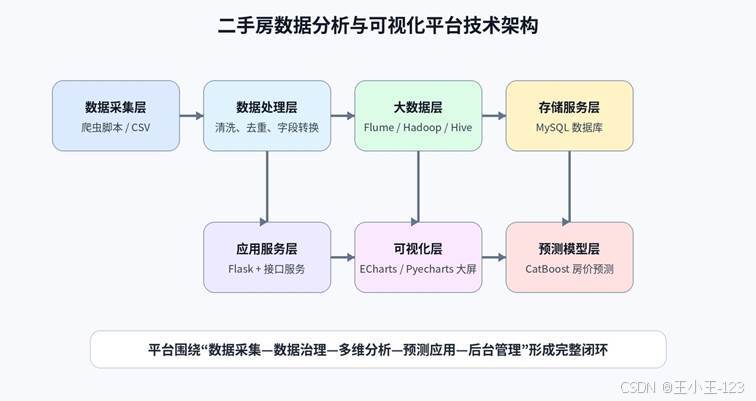
图 3 平台技术架构设计

图 4 项目目录结构脱敏展示
数据处理与分析设计
数据处理是这个项目比较核心的一步。原始房源数据并不是直接拿来展示,而是先经过合并、去重、字段检查、异常范围筛选和格式转换。比如成交价格、建筑面积、楼总高、总房间数、抵押金额等字段适合用于数值统计;户型结构、建筑类型、房屋朝向、装修情况、配备电梯、产权所属、房屋年限等字段更适合做分类维度统计。经过这些处理后,平台可以从不同角度展示价格差异和属性分布。
可视化分析主要分为几个方向。第一类是价格分析,例如不同建筑类型、户型结构、装修情况、楼层、电梯配置对应的平均成交价格;第二类是属性分布,例如不同楼层、建筑类型、产权状态、抵押状态的出现次数;第三类是区域分析,例如不同地区平均成交价格对比;第四类是小区专项分析,例如高价小区、低价小区、建筑面积靠前的小区、抵押金额较高的小区等。通过这些图表,系统可以把大量房源数据压缩成直观的结果。
在页面呈现上,我没有把每一个字段都堆到一张图里,而是拆成单页图表和大屏图表两类。单页图表适合做专项分析,方便聚焦某一个维度;大屏图表适合做汇总展示,适合项目汇报、演示和发布页面展示。
系统界面与交互效果
系统入口采用登录页,用户和管理员可以进入不同的操作场景。登录后进入后台主界面,左侧是功能菜单,右侧是主内容区。这样的布局比较适合数据平台,因为后续扩展新的图表、数据表、预测模型或管理页面时,只需要在菜单中新增入口即可。
数据管理页面提供了房屋朝向、小区名称、地区等检索条件,表格中可以查看小区名称、成交价格、所在楼层、建筑面积、户型结构、建筑类型、朝向、装修情况、电梯配置和地区等字段。这个模块主要解决数据可查、可改、可维护的问题。对项目演示来说,它能够说明后台不是纯静态展示,而是具备基本业务管理能力。
预测页面的交互逻辑比较直接:用户输入或选择房源属性,点击预测后,系统调用后端接口和模型文件,返回一个估算价格。为了让页面更贴近真实使用场景,表单中保留了多个分类字段,并通过下拉选择减少输入错误。后续如果继续优化,可以增加输入校验、历史预测记录、推荐相似房源、预测解释等功能。
图 5 系统登录页面展示
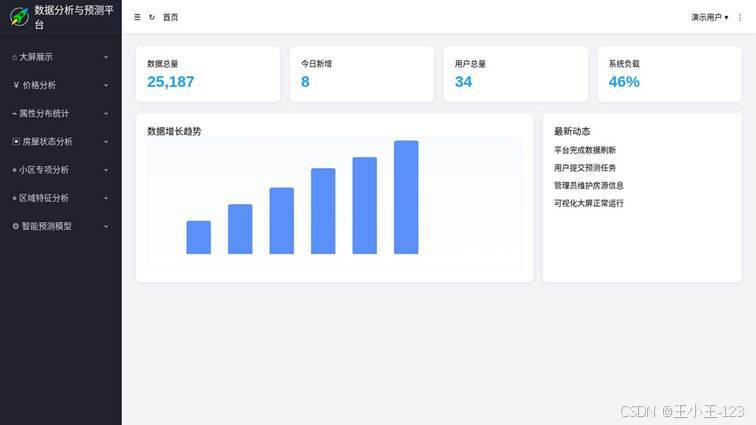
图 6 平台主界面与功能菜单展示
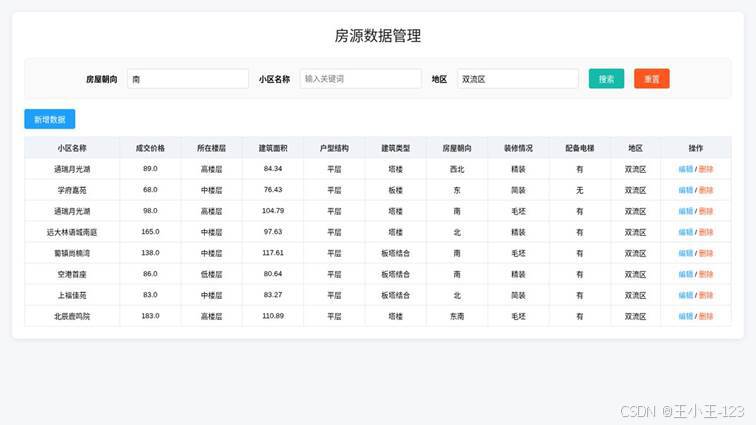
图 7 房源数据管理页面展示

图 8 房价预测页面展示
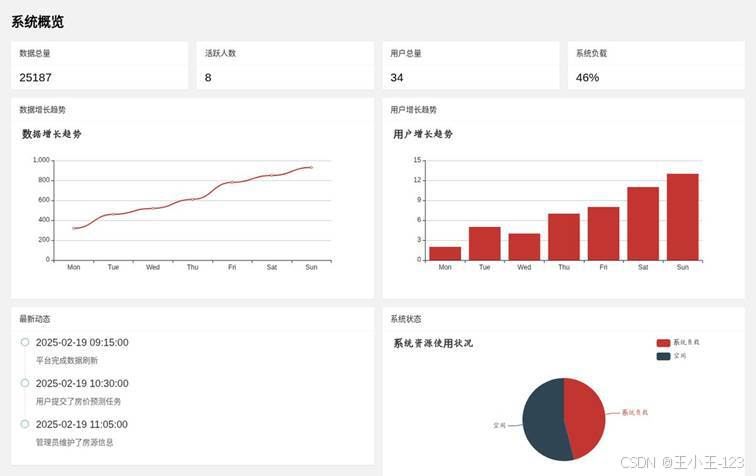
图 9 系统概览与运行状态展示
可视化大屏与图表展示
可视化模块是这个项目最适合展示的部分。项目中生成了多张单页图表,也配置了多个大屏页面。大屏页面可以把多个维度的统计结果组合在一起,例如楼层价格、楼层分布、装修情况、建筑类型、房屋用途、区域价格等。相比单个图表,大屏更适合在项目演示时呈现整体效果。
单页图表部分更适合做细分分析。比如建筑类型维度可以看到板楼、塔楼、板塔结合等类型的平均成交价格差异;户型结构维度可以对比平层、复式、跃层等房源的价格水平;装修情况维度可以展示精装、简装、毛坯等状态与成交价格之间的关系。通过这些图表,项目可以从"房源属性---成交价格"之间建立直观联系。
为了避免页面过于拥挤,项目把大屏图表和单页图表分开管理。大屏负责综合展示,单页负责专项分析,后台菜单负责组织入口。这种结构对于后续扩展非常友好,例如可以继续新增区域热力图、价格区间分布、挂牌时间趋势、成交周期分析等内容。
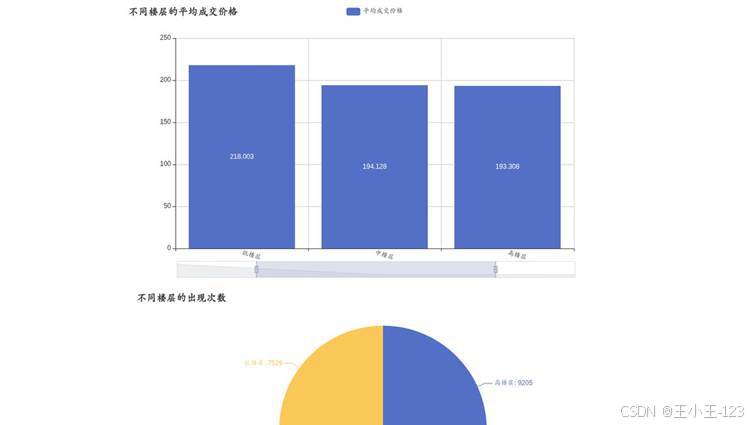
图 10 可视化大屏组合展示
|-------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| 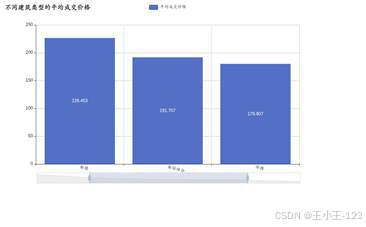 图 11 不同建筑类型平均成交价格展示 |
图 11 不同建筑类型平均成交价格展示 | 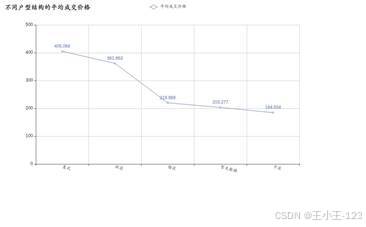 图 12 不同户型结构平均成交价格展示 |
图 12 不同户型结构平均成交价格展示 |
| 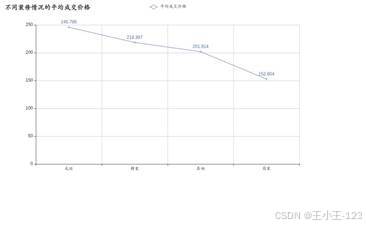 图 13 不同装修情况平均成交价格展示 | |
图 13 不同装修情况平均成交价格展示 | |
智能房价预测模块
预测模块使用清洗后的房源数据训练回归模型,核心目标是根据房源属性估计成交价格。模型输入保留了建筑面积、总房间数、户型结构、地区、建筑类型、房屋用途、楼总高、朝向、电梯配置、产权所属、建筑结构、装修情况、抵押信息、小区名称和房屋年限等字段。项目中尝试了多种回归算法,最终将表现较好的模型保存为文件,并在 Flask 服务中加载调用。
模型训练阶段不仅关注误差指标,也做了特征重要性分析和预测效果对比。从结果看,建筑面积、地区、小区名称、总房间数等字段对价格预测影响更明显,这和二手房定价逻辑基本一致。预测效果图中,真实价格与预测价格整体呈现较高一致性,说明模型能够捕捉主要价格规律。
前端预测页面把模型能力封装成一个简单表单,用户不需要理解训练过程,也不需要运行代码,只需要输入房源条件即可得到预测结果。这个设计让模型从 Notebook 中走出来,真正接入到 Web 系统中,形成了"数据分析 + 机器学习 + 系统应用"的闭环。
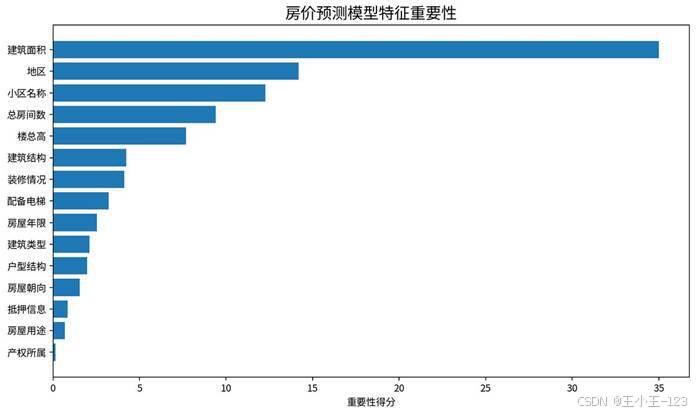
图 14 模型特征重要性展示
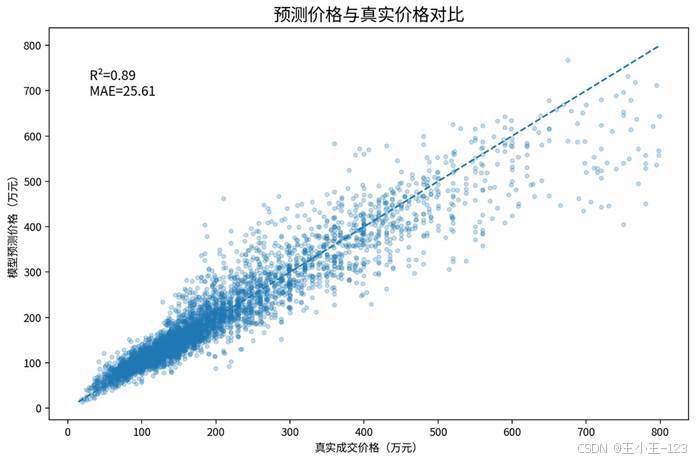
图 15 预测价格与真实价格对比展示
项目完整性与可扩展方向
这个项目的完整性主要体现在三个层面。第一,数据链路完整,从原始数据、清洗数据、数据库脚本到可视化页面都有对应材料;第二,系统功能完整,包含登录、后台主界面、数据管理、图表展示、预测模型和接口调用;第三,展示效果完整,既有单页统计图,也有综合大屏,还有模型预测结果。
后续如果继续升级,可以从几个方向推进。数据层可以增加定时更新和更多城市数据源;分析层可以加入价格区间、成交周期、地铁距离、学区因素等扩展字段;模型层可以增加模型解释、误差分布和多模型对比;系统层可以增加权限管理、日志记录、预测历史、导出报告等功能。对于实际部署,还可以把 Hadoop/Hive 数据处理链路与 Web 系统进一步打通,形成更稳定的数据同步流程。
项目目前已经具备比较完整的展示价值:有数据、有系统、有图表、有模型、有后台,也有可继续扩展的空间。对于想做大数据可视化、房价预测、Flask 后台系统、ECharts 大屏或机器学习落地项目的同学来说,这套资料可以作为一个比较完整的参考样例。
从展示效果来看,我更希望把它做成一个"打开就能讲清楚"的项目:先用数据管理页面说明数据从哪里来、清洗后保留了哪些关键信息,再用图表页面展示价格分布和结构差异,最后通过预测页面把模型能力落到一个具体房源上。这样无论是课程答辩、项目汇报还是作品展示,都能顺着一条清晰的业务线展开,而不是停留在单个脚本或单张图表上。
同时,系统保留了继续扩展的空间。比如后续可以接入更多城市或更细粒度的板块数据,也可以增加地图分布、成交周期、学区距离、地铁距离等分析维度;在模型侧,可以继续补充误差解释、预测区间和历史预测记录;在管理侧,可以加入权限分级、操作日志和报表导出。当前版本已经把数据、图表、模型和后台串联起来,后面再做功能增强会更加顺手。
每文一语
把数据跑通只是第一步,真正有价值的是把结果做成别人看得懂、用得上、愿意继续追问的作品。