写在前面
如果你最近也在用 LLM 做内容流水线,大概率踩过这几个坑:
- prompt 链一长就脆,任何一步出错整条链报废
- 画面和字幕对不上,差 1-2 秒字幕就飘
- 改一个细节得重跑全流程,中间产物没落库
- 平台数据回写不知道怎么用
我业余时间做了一个开源项目 Auteur,把这些问题逐个解决了。这篇文章把我踩过的坑和解决思路一次性写出来,代码 + 配置都是真实可跑的。
仓库地址:https://github.com/nxin-github/Auteur
在线 demo:https://nxin-github.github.io/Auteur/
技术栈:Spring Boot 3.3 + JPA + Flyway + MySQL 8.0 + Java 21 + Vue 3 + ffmpeg / Remotion
一、为什么不能用 prompt chain
最早做的就是 LangChain 风格的 chain:
brainstorm → script → storyboard → image → voice → video跑了一周发现几个事:
- LLM API 本来就不稳定,链越长越脆
- 中间产物只在内存里,UI 看不到也没法人工介入
- 改一处要全跑,5 分钟起步
- 加自审到 chain 里要么改框架要么塞 if,丑
根本问题是 chain 把"流程"和"状态"耦合在一起。
后来推翻重做,每个 AI 角色一个独立 Spring Service,角色之间不直接互相调用,全部通过 DB 表解耦。读上游表,写下游表。
topic(选题)
↓
script(脚本)
↓
storyboard_shot(分镜,每镜一行)
↓
image_asset(图片资产)
↓
voice_asset(配音资产)
↓
video_asset(合成视频)
↓
published_video(平台回写的真实数据)
↓
weekly_review(周复盘)每张表对应一个产物,任何一段失败可以单独重跑,不影响别的。中间产物全部落库,UI 上能看能改。
java
@Service
public class ScriptWriterService {
// 读上游:topic 表
// 写下游:script 表
public ScriptResult write(Long topicId) { ... }
}
@Service
public class ScriptCriticService {
// 读:script 表
// 写:script_review 表 + 触发 ScriptWriterService 重写一稿
public CriticResult review(Long scriptId) { ... }
}加新角色 = 加新 Service + 新表,对其它角色零侵入。
⚠️ 踩坑:第二版我还试过用 Spring Events 解耦------不行,事件链一长跟 chain 没本质区别,异步事件链调试起来更难。回到"产物落库 + 显式触发",基于 DB 状态机才是正解。
二、自审反馈环:让 LLM 给自己批稿子
LLM 输出会漂移这是事实。常见处理方式:
- 换更大的模型 → 贵
- 写更细的 prompt → 反噬,prompt 越复杂 LLM 越抓不住重点
- 加 retry → 不知道为什么错
Auteur 的方案:给关键角色配一个自审角色。
java
public ScriptResult writeWithCritic(Long topicId, int threshold) {
ScriptResult draft = scriptWriter.write(topicId);
CriticResult review = scriptCritic.review(draft);
if (review.score() < threshold) {
return scriptWriter.rewriteWithFeedback(draft, review.feedback());
}
return draft;
}调试这个 loop 时踩了三个坑,每个都让我返工过:
坑 1:自审 prompt 必须"找问题"导向不能"打分"导向。 让 LLM 列出 3 个最大的问题,比让它给个 80 分有用得多。打分版本会出现"凑分数"------看见草稿写得不错就给个高分混过去。
坑 2:重写最多 1 次,再不行放过。 我见过 LLM 把一个本来还行的剧本越改越奇怪,钻牛角尖比放过去还糟。
坑 3:自审反馈环必须是闭合的小循环,不能让自审失败传染下游。 如果自审本身挂了(LLM 返回格式不对),跳过自审走原稿,不要让整个流水线挂在自审上。
目前编剧、摄影、美术三个角色都接了自审。生产跑下来编剧自审能把"逻辑断层"和"信息密度过低"两类问题捕住八成以上。
三、镜头时长锚定:画面与字幕一帧不差
这是我自己最得意的一个设计。
问题: 普通流水线让 LLM 给每个镜头估时长(比如 3.5s),后端按这个时长拼图。但 LLM 估的时长跟真实 TTS 音频对不上,剪出来字幕飘 1-2 秒。我试过加更详细的 prompt 让 LLM 估准。没用,它压根不知道你的 TTS 模型每秒念几个字。
解法: 让摄影指导给每个镜头一段 anchor_text(必须是脚本里的连续子串),后端 SRT 解析后在音频时间轴上反查这段文本的真实秒数:
java
public Duration resolveShotDuration(Shot shot, List<SrtCue> srtCues) {
String anchor = normalize(shot.anchorText());
SrtRange range = srtCues.stream()
.filter(cue -> normalize(cue.text()).contains(anchor))
.findFirst()
.orElseThrow();
return Duration.between(range.start(), range.end());
}LLM 不再负责估算,只负责"指认"。LLM 擅长的是语义匹配,不是数值估算------把它放在它擅长的位置上。
校验链写得比较狠:
- ✅ anchor 必须真的是脚本子串(normalize 之后比对,去标点 / 全半角 / 大小写)
- ✅ 相邻 shot 的 anchor 在脚本里位置必须单调递增(防 LLM 把镜头顺序搞乱)
- ⚠️ 没命中的镜头标
anchor_match=false,视频还能渲,但日志和 UI 都会提示
踩坑:normalize 一定要包括去全半角和繁简体,不然 LLM 输出的 anchor 跟脚本对不上。我一开始只去了标点,匹配率惨不忍睹。
四、Agent 工具系统:自然语言驱动整条流水线
光有流水线还不够,用户得点 N 个按钮才能把活干完。所以又加了一个 Agent 聊天工作台。
底层是带工具调用 + 审批门槛 + Skill 上下文加载的对话循环。几个工程关键点:
1. 工具自动注册
java
@Component
public class StoryboardTools {
@Tool(name = "regenerate_image_for_shot",
description = "重新为指定 shot 生成图片")
public RunRef regenerateImageForShot(Long shotId, String stylePatch) { ... }
}ToolRegistry 启动时扫描所有 @Tool 注解,自动注册到 Agent 上下文,不用改 Agent 主循环代码。这是 Spring 注解扫描在 LLM 工程里的一个绝佳应用场景。
2. 写操作必须实现审批接口
java
public interface PreviewableHandler<T> {
PreviewCard preview(T args); // 给前端的审批卡
Object execute(T args); // 用户点确认后才跑
}前端弹一张"即将做这件事,确认吗"的卡片,用户按一下才执行。这是把 LLM 不可控性挡在副作用之外的最后一道闸。
踩坑:我一开始没加这个,调试时 Agent 自作主张把一个预设的 prompt 改了,改回去花了我半小时。从那以后所有写操作必须走审批门槛。
3. Skill 按需加载,不是 system prompt 塞所有上下文
把"调整内容""触发流水线""创建选题""改预设""编辑文本" 5 类剧本写成 markdown 放在 agent/skills/,Agent 自己根据当前对话决定加载哪份。
避免 system prompt 越写越长占满 context window。
4. 长任务异步 + runId 轮询
生图、合成视频这类任务要几十秒。Agent 工具返回 runId,前端轮询 GET /api/runs/{id} 看进度。Agent 不阻塞在长任务上。
五、模型 ID 不在代码里写死
这是后期重构的一个关键决策。早期我把 LLM 模型 ID 散落在各 Service 里:
java
// ❌ 散落各处的字面量
private static final String SCRIPT_MODEL = "deepseek-chat";
LlmCallSpec.builder().model("gpt-4o-mini").build();后来改型号、做 A/B、降级模型时全是 grep 改代码。改成 ModelRegistry:
java
@Service
public class ModelRegistry {
public String modelFor(String step) { ... }
public String modelOrDefault(String presetValue, String step) { ... }
}所有 LLM / 图像 / Agent 模型走 ModelRegistry.modelFor("<step>") 读 app_config 表(category='model',key 形如 auteur.model.<step>),前端"配置 → AI 模型"页面统一编辑。预设可覆盖的步骤(脚本/分镜/批评/脑暴/图像主模型)用 modelOrDefault(presetValue, step),preset 优先,本页兜底。
加新流水线步骤的标准动作:
- 写下一个
V*__model_<step>.sql迁移,INSERT IGNORE注册 +UPDATE COALESCE灌默认值 - 在
ModelRegistry.KNOWN_STEPS列表里加上新 step,启动自检会校验 - Service 注入
ModelRegistry,调modelFor(step)或modelOrDefault(presetValue, step) - 前端
ModelConfig.vue的GROUPS数组里把新 step 加进合适分组
六、本地优先 + 可降级
任何外部依赖缺失,后端不能挂。这条对开源项目特别重要------你不知道用户机器上装了啥。
| 依赖 | 没配会怎样 |
|---|---|
| 火山 TOS | 走本地路径 + /api/files/... 静态服务 |
| 火山 TTS | 配音 disabled,前端提示 |
| Jamendo BGM | BGM 不推荐,制片照常合成 |
| Remotion | 走纯 ffmpeg 路径 |
| LLM 网关 | OpenAI 兼容协议,vLLM / DeepSeek / 智谱 / Anthropic 都行 |
写起来到处都是兜底,但这事不能省。
七、几个让我返工过的踩坑
1. .gitignore 必须用前导 / 锚定
storage/ 会递归忽略所有层级 ------不光忽略 backend/storage/ 产物目录,还会一并忽略 backend/src/main/java/com/auteur/storage/ 业务包。CI 编译失败你都不知道为啥。
正确写法:/storage/,只匹配 git 根下的同名目录。
.dockerignore 语义不同(用 Go filepath.Match 不递归),所以同样写法在 dockerignore 里没问题------这种语义差异让我本地 docker build 通过、CI 编译挂。
改完 .gitignore 用 git check-ignore -v <file> 抽查关键源码目录验证。
2. Spring Boot ddl-auto: validate 严格校验
加字段忘 Flyway migration → 启动失败。强制走 Flyway,不要直接改 entity 让 JPA 自动建表。
正确做法:
- 在
backend/src/main/resources/db/migration/加V<下一个数字>__<描述>.sql - 数字递增不能跳号,描述用下划线分隔
- 同时改 entity 类
- Flyway 启动时自动执行
3. alpine 容器里 localhost 优先解析 IPv6
但 nginx 默认只监听 IPv4 → healthcheck 永远失败。改成 127.0.0.1 立刻好。
4. Remotion 不支持 file:// 协议
本地静态文件得走 HTTP URL,配 auteur.video.remotion.public-base-url 拼成 http://host:port/api/files/...。
数据回写驱动复盘
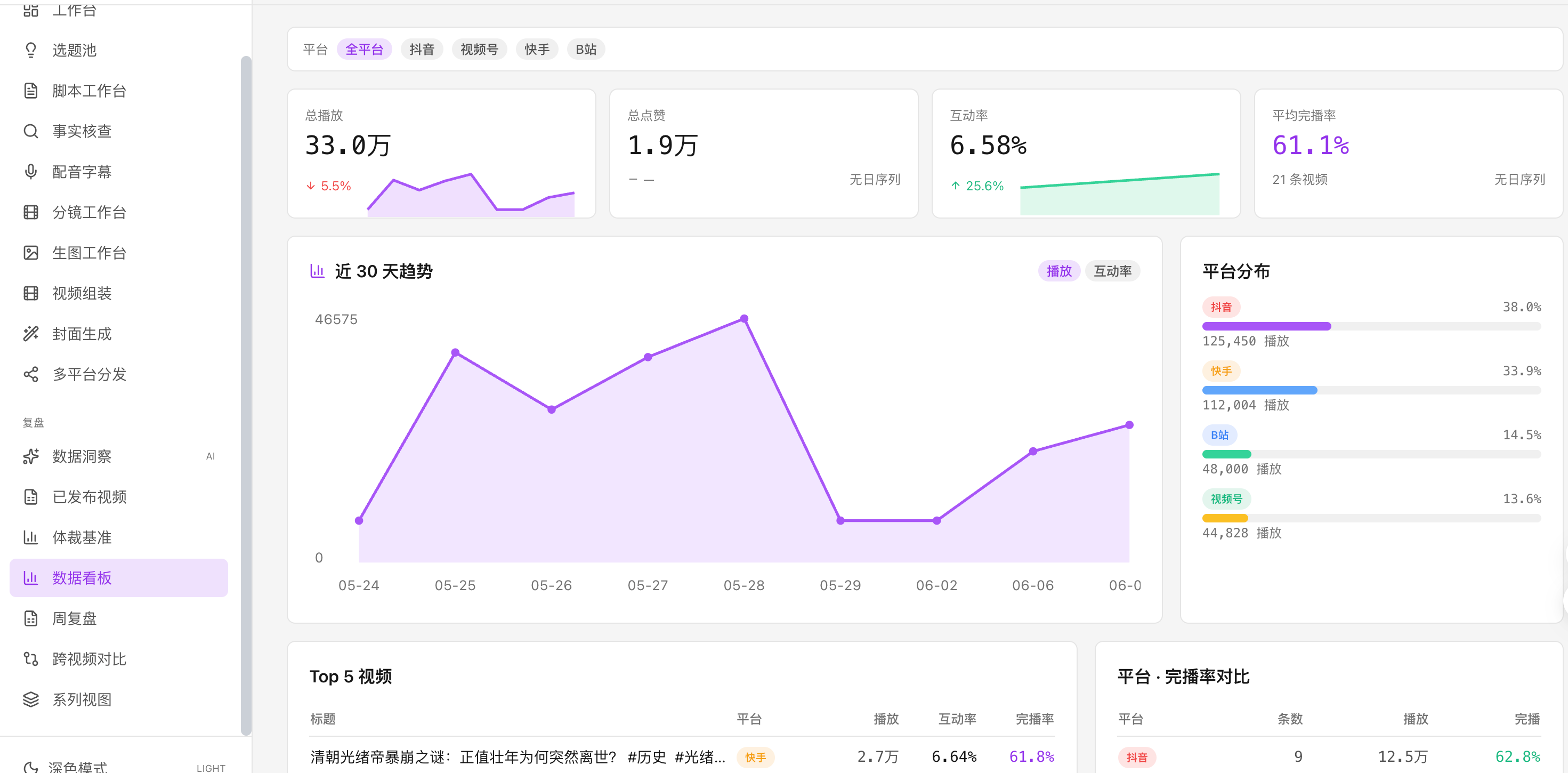
extension/ 目录是个 Chrome 扩展,插到抖音 / B 站 / 视频号 / 快手 的创作者后台,自动抓播放数和完播率 POST 回 Auteur,落 published_video 表。
WeeklyReviewService 每周根据这些数据算哪些题材和钩子组合表现好,给下周的选题脑暴一份权重表。下一次选题策划就读这份周报。流水线越跑越懂受众。
怎么跑起来
bash
git clone https://github.com/nxin-github/Auteur && cd Auteur
cp .env.example .env
docker compose up -d --build3-5 分钟,打开 http://localhost:5174,右上角切到 admin → 系统设置 → 填 LLM key(OpenAI 兼容协议都行),其它依赖留空就降级。
最后
完全开源 MIT 协议,随便用、随便改、随便商用。
- 仓库:https://github.com/nxin-github/Auteur
- 在线 demo:https://nxin-github.github.io/Auteur/
- 给 AI 编程助手的 onboarding cheat sheet:
CLAUDE.md(项目根目录)
LLM 工程化是个大坑,这个项目把我四个月里踩过的坑基本全暴露了。希望对你有用。
如果觉得思路有意思,star 是对独立开发者最直接的鼓励。有问题欢迎评论或者 GitHub issue。