1. 作者介绍
张嘉怡,西安工程大学电子信息学院研究生,
研究方向为移动目标检测与跟踪。
电子邮件:1462087576@qq.com
董柯帆,男,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:867068473@qq.com
本项目是一次基于云端人工智能 API 的课程实践,题目为 Python 调用百度智能云 API 实现地址识别。项目围绕真实生活中常见的收货地址整理场景展开,目标是使用 Python 将混合在一起的姓名、电话和地址信息拆分成结构化字段。
与本地训练机器学习模型不同,本项目的核心识别能力由百度智能云 NLP 地址识别服务提供。本地程序重点完成 API 鉴权、文本输入、HTTPS 请求、JSON 解析、批量处理和结果保存。
2. 项目背景与研究意义
在电商、物流、表单整理和课程项目演示中,经常会遇到一整段混合文本,例如"张三,联系电话 13800138000,收货地址北京市海淀区上地十街10号"。人工整理这些文本时,需要逐个判断姓名、电话、省市区和详细地址,效率低且容易出错。
随着云端 AI 服务的发展,开发者可以通过 API 快速调用成熟的自然语言处理能力,不必从零开始训练模型。本项目正是利用这一特点,把百度智能云地址识别能力接入到 Python 程序中,形成一个轻量、可复现、可扩展的地址结构化小工具。
- 提升地址录入和整理效率,把非结构化文本转换为可查询、可统计的字段。
- 练习云 API 项目的完整接入流程,包括账号开通、密钥配置、鉴权、接口调用和异常处理。
- 通过 JSON 与 CSV 文件保存结果,便于后续截图、汇报、二次处理和上传 CSDN。
- 通过批量识别功能,让项目从单条演示脚本扩展为可以处理多条样本的实用工具。
3. 理论知识介绍
3.1 API 技术概述
API 是 Application Programming Interface 的缩写,中文通常称为应用程序编程接口。简单来说,API 是不同软件系统之间约定好的调用入口。调用方按照接口文档准备参数并发送请求,服务方返回规定格式的数据。
在本项目中,百度智能云提供地址识别 API,本地 Python 程序只需要把待识别文本封装为 JSON,通过 HTTP POST 请求发送到接口地址,就可以获得姓名、电话号码、省、市、区县、街道、详细地址和经纬度等字段。
- 注册并登录百度智能云或百度 AI 开放平台账号。
- 开通 NLP 地址识别服务并创建应用。
- 获取 API Key 和 Secret Key。
- 使用密钥向 OAuth 接口申请 access_token。
- 携带 access_token 调用地址识别接口。
- 解析接口返回的 JSON 结果并进行展示或保存。
3.2 地址识别技术概述
地址识别属于自然语言处理中的信息抽取任务。输入文本往往并不规范,姓名、电话、行政区划和门牌号可能顺序混乱,甚至包含"收件人""联系电话""手机"等提示词。地址识别模型需要理解文本中的实体边界和地址层级。
百度智能云地址识别 API 会从文本中提取常见字段,例如 person 表示姓名,phonenum 表示电话号码,province、city、county 分别表示省、市、区县,town 表示街道,detail 表示详细地址,lat 与 lng 表示参考坐标。
3.3 Python 终端程序设计思路
本项目没有设计 Web 前端,而是采用终端程序形式运行。这样更适合课程作业、快速演示和本地调试:用户可以通过命令行输入单条文本,也可以指定批量文件路径。程序输出既显示在终端,也保存到本地文件。
- 单条识别:通过交互输入或 `--text` 参数传入待识别文本。
- 演示模式:通过 `--demo` 使用本地预设结果,不调用真实百度 API。
- 真实模式:读取 `.env` 中的密钥,获取 access_token 后调用接口。
- 批量模式:通过 `--batch` 读取 JSON、CSV 或 TXT 文件,逐条识别并导出 CSV。
3.4 系统整体技术架构
系统可以分为输入层、本地处理层、云端服务层和结果输出层。输入层负责接收单条文本或批量文件;本地处理层负责读取配置、构造请求、调用 API、解析 JSON;云端服务层由百度智能云地址识别模型完成实体抽取;结果输出层负责终端展示、JSON 保存、CSV 汇总和运行报告记录。
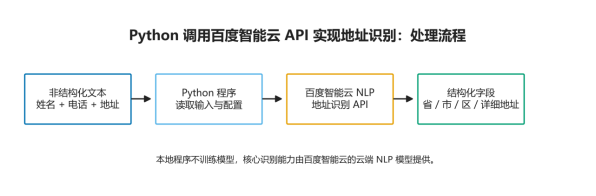
图 1 Python 调用百度智能云 API 实现地址识别的处理流程
4. 系统需求分析
4.1 功能需求
本项目主要实现以下功能:
- 文本输入功能:支持终端交互输入,也支持通过 `--text` 参数直接传入字符串。
- API 鉴权功能:读取 API Key 和 Secret Key,并向百度 OAuth 接口申请 access_token。
- 地址识别功能:调用百度智能云 NLP 地址识别接口,解析返回字段。
- 演示模式功能:在没有真实凭证时,通过本地样例验证程序流程。
- 批量识别功能:支持 JSON、CSV、TXT 三类输入文件,逐条调用接口。
- 结果保存功能:保存原始 JSON、批量 CSV、运行历史和 Markdown 报告。
- 错误处理功能:对密钥缺失、网络失败、接口错误和文本超长进行提示。
4.2 非功能需求
- 安全性:真实密钥只写入 `.env`,不写入源代码、截图或公开文章。
- 易用性:通过命令行参数即可切换演示、真实调用和批量识别。
- 可复现性:项目依赖较少,主要依赖 `requests` 和 `matplotlib`。
- 兼容性:CSV 使用 `utf-8-sig` 编码,方便 Windows Excel 正确显示中文。
- 稳定性:对接口文本长度进行 1000 字节限制检查,避免无效请求。
5. 实验环境与准备工作
5.1 开发环境
|-----------|---------|
| 环境项 | 配置 |
| 操作系统 | Windows |
| 开发工具 | VS Code |
| Python 版本 | 3.10 |
5.2 安装依赖
第一次运行项目时,需要进入项目目录并安装依赖。项目依赖写在 requirements.txt 中,当前主要包括 requests>=2.31.0 和 matplotlib>=3.7.0。
powershell
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
5.3 百度智能云 API 凭证配置
真实调用前,需要在百度智能云控制台开通 NLP 地址识别服务,创建应用并获取 API Key、Secret Key。随后在项目根目录创建 .env 文件,写入以下内容:
text
BAIDU_API_KEY=你的API Key
BAIDU_SECRET_KEY=你的Secret Key
注意:.env 文件保存的是敏感凭证,不应上传到 GitHub、CSDN 或发送给他人。项目提供 scripts/check_credentials.py 用于脱敏检查凭证是否已读取。
powershell
python scripts/check_credentials.py
6. 系统代码实现
6.1 项目结构
|------------------------------|-----------------------------------------------------|
| 文件或目录 | 作用说明 |
| main.py | 命令行主程序,负责参数解析、单条识别、批量识别、结果展示和文件保存。 |
| baidu_address_api.py | 百度地址识别 API 客户端,负责获取 access_token、发送 POST 请求和处理接口异常。 |
| data/sample_addresses.json | 演示模式样例数据,包含 5 条地址文本及对应预设结果。 |
| data/batch_test.txt | 真实批量识别测试文件,每行一条待识别地址文本。 |
| scripts/check_credentials.py | 检查 `.env` 是否存在并脱敏显示密钥读取状态。 |
| scripts/diagnose_network.py | 使用假凭证诊断百度 HTTPS 接口连通性,避免泄露真实密钥。 |
| artifacts/responses | 保存单条或批量调用的原始 JSON 响应。 |
| artifacts/batch_results | 保存批量识别后的 CSV 表格结果。 |
| artifacts/reports | 保存每次运行的 Markdown 记录。 |
6.2 导入依赖与常量设计
主程序使用标准库完成参数解析、CSV/JSON 文件读写、路径处理、计时和运行记录,并导入自定义的 BaiduAddressClient 完成真实 API 调用。
python
import argparse
import csv
import json
import os
import platform
import sys
import time
from datetime import datetime
from pathlib import Path
from typing import Any
from baidu_address_api import (
ADDRESS_RECOGNITION_URL,
BaiduAddressAPIError,
BaiduAddressClient,
)
PROJECT_ROOT = Path(__file__).resolve().parent
ARTIFACTS_DIR = PROJECT_ROOT / "artifacts"
RESPONSES_DIR = ARTIFACTS_DIR / "responses"
REPORTS_DIR = ARTIFACTS_DIR / "reports"
BATCH_RESULTS_DIR = ARTIFACTS_DIR / "batch_results"6.3 命令行参数设计
项目通过 argparse 提供多个运行入口:--text 用于直接传入文本,--batch 用于批量识别,--output 用于指定 CSV 输出路径,--demo 用于本地演示模式。
python
parser.add_argument("--text", help="直接指定待识别文本,适合非交互运行")
parser.add_argument(
"--batch",
nargs="?",
const=str(SAMPLE_DATA_PATH),
help="批量识别输入文件,支持 JSON/CSV/TXT",
)
parser.add_argument("--output", help="批量识别 CSV 输出路径")
parser.add_argument(
"--demo",
action="store_true",
help="使用本地演示响应,不调用真实百度 API",
)6.4 `.env` 配置读取
为了减少额外依赖,项目没有强制使用 python-dotenv,而是使用标准库读取简单的 KEY=VALUE 配置。这样可以降低环境安装失败概率,也能避免把密钥写死在代码中。
python
def load_env_file(path: Path) -> None:
if not path.exists():
return
for raw_line in path.read_text(encoding="utf-8").splitlines():
line = raw_line.strip()
if not line or line.startswith("#") or "=" not in line:
continue
key, value = line.split("=", 1)
key = key.strip()
value = value.strip().strip('"').strip("'")
if key and key not in os.environ:
os.environ[key] = value6.5 百度 API 客户端封装
baidu_address_api.py 将网络调用逻辑封装为 BaiduAddressClient 类。这样主程序不需要关心 token 如何获取、请求如何发送、接口错误如何判断,代码结构更加清晰。
python
TOKEN_URL = "https://aip.baidubce.com/oauth/2.0/token"
ADDRESS_RECOGNITION_URL = "https://aip.baidubce.com/rpc/2.0/nlp/v1/address"
MAX_TEXT_BYTES = 1000
@dataclass
class BaiduAddressClient:
api_key: str
secret_key: str
timeout: float = 20.0
_access_token: str | None = field(default=None, init=False, repr=False)6.6 获取 access_token
百度接口需要先用 API Key 和 Secret Key 换取临时 access_token。程序将密钥放入请求参数中,向百度 OAuth 接口发送 POST 请求;若返回结果中没有 access_token,则抛出自定义异常。
python
def get_access_token(self) -> str:
params = {
"grant_type": "client_credentials",
"client_id": self.api_key,
"client_secret": self.secret_key,
}
try:
response = requests.post(TOKEN_URL, params=params, timeout=self.timeout)
response.raise_for_status()
payload = response.json()
except requests.RequestException as exc:
raise safe_request_error("获取 access_token 时网络请求失败", exc) from exc
token = payload.get("access_token")
if not token:
description = payload.get("error_description") or payload.get("error") or payload
raise BaiduAddressAPIError(f"获取 access_token 失败:{description}")
return str(token)6.7 调用地址识别接口
真正的地址识别发生在 recognize 方法中。程序先清理输入文本,检查 UTF-8 字节长度是否超过 1000 字节,然后携带 access_token 调用百度地址识别接口。
python
def recognize(self, text: str) -> dict[str, Any]:
cleaned_text = text.strip()
if not cleaned_text:
raise ValueError("待识别文本不能为空。")
byte_length = len(cleaned_text.encode("utf-8"))
if byte_length > MAX_TEXT_BYTES:
raise ValueError(
f"待识别文本为 {byte_length} 字节,超过接口允许的 {MAX_TEXT_BYTES} 字节。"
)
if self._access_token is None:
self._access_token = self.get_access_token()
response = requests.post(
ADDRESS_RECOGNITION_URL,
params={"access_token": self._access_token},
headers={"Content-Type": "application/json; charset=UTF-8"},
json={"text": cleaned_text},
timeout=self.timeout,
)
payload = response.json()
if "error_code" in payload:
raise BaiduAddressAPIError(f"地址识别失败:{payload}")
return payload6.8 结果展示与保存
接口返回后,主程序会提取常用字段并在终端打印,同时保存完整 JSON。批量模式下,还会将每条记录整理为 CSV 行。
python
DISPLAY_FIELDS = [
("person", "姓名"),
("phonenum", "电话号码"),
("province", "省级行政区"),
("city", "城市"),
("county", "区县"),
("town", "乡镇街道"),
("detail", "详细地址"),
("lat", "纬度"),
("lng", "经度"),
]7. 批量识别流程设计
7.1 批量输入文件支持
为了让项目更接近真实应用,本项目在单条识别基础上增加 --batch 参数。批量模式支持三种输入格式:
- JSON:列表格式,每条记录可以是字符串,也可以是包含 `text` 字段的对象。
- CSV:表格中包含 `text`、`address` 或 `input_text` 列即可。
- TXT:每行一条地址文本。
7.2 批量识别核心逻辑
批量识别时,程序先读取输入文件,再逐条识别。每条记录都会记录状态、耗时、错误信息和识别字段。即使某一条失败,也可以在结果中保留失败原因。
python
for index, record in enumerate(records, start=1):
record_id = record["id"]
input_text = record["text"]
item_started = time.perf_counter()
try:
response = demo_response(input_text) if mode == "demo" else client.recognize(input_text)
item_duration = time.perf_counter() - item_started
csv_rows.append(build_csv_row(
record_id=record_id,
input_text=input_text,
status="success",
duration_seconds=item_duration,
response=response,
))
success_count += 1
except (ValueError, RuntimeError, BaiduAddressAPIError) as exc:
item_duration = time.perf_counter() - item_started
csv_rows.append(build_csv_row(
record_id=record_id,
input_text=input_text,
status="failed",
duration_seconds=item_duration,
error=str(exc),
))
failed_count += 17.3 演示模式与真实模式区分
演示模式只使用 data/sample_addresses.json 中的本地预设数据,不调用真实百度 API。这样在没有凭证或网络不稳定时也可以演示程序流程。真实模式则必须读取有效密钥,并将文本发送到百度智能云。
项目中特别强调:演示模式不能作为真实 API 效果,文档、PPT 和 CSDN 文章中应明确标注这一点。
8. 示例测试数据说明
data/sample_addresses.json 包含 5 条样例地址,用于验证输入输出流程。每条样例都包含 id、text、expected_fields 和 demo_result。这些数据不是训练集,而是用于演示字段覆盖情况的小型测试集。
|-----------|--------------------------------------|--------------------------------|
| 编号 | 输入文本 | 演示识别结果 |
| sample_01 | 张三,联系电话13800138000,收货地址北京市海淀区上地十街10号 | 张三 / 13800138000 / 北京市北京市海淀区 |
| sample_02 | 李女士 13912345678 上海市浦东新区世纪大道100号 | 李女士 / 13912345678 / 上海市上海市浦东新区 |
| sample_03 | 王强,广东省深圳市南山区科技园南区,电话13600001111 | 王强 / 13600001111 / 广东省深圳市南山区 |
| sample_04 | 收件人赵敏,浙江省杭州市西湖区文三路,手机13588889999 | 赵敏 / 13588889999 / 浙江省杭州市西湖区 |
| sample_05 | 刘先生 15800002222 四川省成都市武侯区人民南路四段 | 刘先生 / 15800002222 / 四川省成都市武侯区 |
图 2 示例测试数据中的字段覆盖情况
9. 命令行运行流程
9.1 第一次运行
powershell
conda activate zzz
cd C:\Users\Lenovo\Desktop\fix\baidu_address_recognition
python main.py --demo
--demo 只用于验证程序流程,不会调用真实百度 API。
9.2 真实 API 单条识别
powershell
python scripts/check_credentials.py
python main.py --text "张三,联系电话13800138000,收货地址北京市海淀区上地十街10号"
9.3 真实 API 批量识别
powershell
python main.py --batch data/batch_test.txt
批量识别成功后,程序会在 artifacts/batch_results/ 中保存 CSV 表格,在 artifacts/responses/ 中保存完整 JSON 响应,并在 artifacts/reports/ 中保存运行报告。
10. 实验测试与结果分析
10.1 测试方法
本项目测试分为离线单元测试和真实 API 批量运行两部分。离线单元测试通过 mock 请求验证客户端是否按预期发送 token 请求和地址识别请求,同时检查 1000 字节限制和密钥脱敏逻辑。真实 API 测试使用 data/batch_test.txt 中的 5 条地址文本。
powershell
python -m unittest discover -s tests
在项目原 Conda 环境 zzz 中,离线单元测试结果为:Ran 3 tests in 0.003s - OK。
10.2 真实批量运行结果
根据项目中保存的真实运行报告,2026-06-05 16:35:38 进行了一次真实 API 批量识别,输入文件为 data\batch_test.txt,总条数 5,成功 5 条,失败 0 条,总耗时 1.970 秒。
|---------|---------|----------|--------|-------------|-------|-------|--------|--------|
| 编号 | 状态 | 耗时/s | 姓名 | 电话 | 省 | 市 | 区县 | 街道 |
| row_001 | success | 0.607 | 李明 | 13800000001 | 北京市 | 北京市 | 海淀区 | 海淀街道 |
| row_002 | success | 0.341 | 王芳 | 13900000002 | 广东省 | 深圳市 | 福田区 | 莲花街道 |
| row_003 | success | 0.360 | 赵强 | 13700000003 | 浙江省 | 杭州市 | 西湖区 | 西溪街道 |
| row_004 | success | 0.308 | 刘女士 | 13600000004 | 四川省 | 成都市 | 武侯区 | 浆洗街街道 |
| row_005 | success | 0.352 | 陈晨 | 13500000005 | 上海市 | 上海市 | 浦东新区 | 陆家嘴街道 |
10.3 结果分析
从测试结果可以看出,程序能够将混合顺序的地址文本拆分为姓名、手机号、行政区划、街道和坐标等字段。批量识别的 5 条记录均成功返回,说明 API 调用链路、文件读取、结果解析和 CSV 导出流程已经跑通。
同时也可以看到,云端模型对部分详细地址字段的返回并不总是完全符合人工预期,例如某些样例中 detail 为空或拼接了城市信息。这说明 API 结果在实际业务中仍需要结合人工校对或后处理规则。
11. 开发过程中遇到的问题与解决方法
11.1 API 凭证与安全问题
真实地址识别必须使用 API Key 和 Secret Key 获取 access_token。项目通过 .env 保存密钥,并提供 check_credentials.py 进行脱敏检查。这样既能保证程序读取配置,又避免在代码、截图和文章中暴露密钥。
11.2 Conda 环境路径问题
开发过程中发现 Anaconda 主程序安装目录与具体 Conda 环境目录并不一致。解决方法是使用 conda env list 查询环境真实路径,并在 VS Code 中选择 C:\Users\Lenovo\.conda\envs\zzz\python.exe。
11.3 第三方依赖问题
初版曾考虑使用 python-dotenv 读取 .env,但该功能只需要解析简单的 KEY=VALUE 文本,因此最终改用标准库实现,减少依赖数量,提高项目可复现性。
11.4 HTTPS 与接口限流问题
真实调用过程中曾出现 SSL 连接中断和 QPS 限制错误。项目通过 diagnose_network.py 使用假凭证检测百度 HTTPS 连通性,并在错误信息中隐藏 client_id 和 client_secret,避免敏感信息泄露。
12. 项目创新点
- 从单条地址识别扩展到批量识别,支持 JSON、CSV、TXT 三类输入文件。
- 严格区分演示模式和真实 API 模式,避免把模拟结果误认为真实接口效果。
- 将 API 鉴权、地址识别、命令行入口、批量保存分层实现,代码职责清晰。
- 增加运行历史、Markdown 报告、JSON 原始响应和 CSV 表格结果,便于课程汇报和 CSDN 展示。
- 重视密钥安全和错误脱敏,不在异常信息中泄露 API Key、Secret Key 或 access token。
13. 项目不足与改进方向
虽然本项目已经实现了基本的地址识别、批量处理和结果保存,但仍存在一些不足:
- 目前主要是命令行工具,没有图形界面或 Web 页面,普通用户使用门槛略高。
- 对 API 返回结果的后处理还比较简单,部分 detail 字段需要进一步清洗。
- 批量识别目前是逐条串行调用,如果数据量较大,可以考虑加入限速、重试和异步队列。
- 结果主要保存为 JSON 和 CSV,后续可以增加 Excel、Word 或数据库存储。
- 当前没有对识别准确率进行系统统计,后续可构造带标准答案的数据集进行评估。
未来可以在本项目基础上继续扩展 Web 上传页面、Excel 导出、地址规范化校验、地图坐标展示和历史记录查询等功能。
14. 总结
本文整理了一个使用 Python 调用百度智能云 API 实现地址识别的项目。项目以非结构化收货信息为输入,通过百度智能云 NLP 地址识别接口提取姓名、电话、省、市、区县、街道、详细地址和经纬度等字段,并将结果展示在终端、保存为 JSON 与 CSV 文件。
从课程实践角度看,本项目的重点不在于本地训练模型,而在于完整掌握云 API 项目的接入流程:申请服务、配置密钥、获取 token、发送请求、解析结果、处理异常和保存输出。通过批量识别增强,项目从一个单条演示脚本扩展成了可以处理多条地址样本的小工具,具有一定实用价值。
总体来说,本项目体现了"把成熟云端 AI 能力嵌入本地程序"的开发思路。对于初学者而言,它既能练习 Python 工程组织和文件读写,也能理解真实 API 调用中的安全、网络、异常和结果落地问题。
15. 参考链接
- 百度智能云 NLP 地址识别 API:https://cloud.baidu.com/doc/NLP/s/vk6z52h5n
- 百度 AI 开放平台地址识别产品页:https://ai.baidu.com/tech/nlp_apply/address
- 百度智能云 Access Token 获取说明:https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu