第一章 绪论
1.1 研究背景及意义
1.1.1 抑郁症检测背景
抑郁症是一种常见的精神障碍,以持续的情绪低落、兴趣丧失、精力减退为主要特征,严重时可能导致自残、自杀等极端行为。据世界卫生组织统计,全球有超过3亿人受抑郁症困扰,占全球人口的4%以上,预计到2030年,抑郁症将成为全球疾病负担的首要原因。在中国,抑郁症的终身患病率约为6.8%,但就诊率却不足10%,大量患者未能得到及时有效的诊断和治疗。
抑郁症的诊断目前主要依靠精神科医生的临床访谈和量表评估,如患者健康问卷(PHQ-9)、贝克抑郁量表(BDI)等。这些方法存在以下局限性:首先,诊断过程高度依赖医生的临床经验,具有一定的主观性;其次,面对面访谈需要投入大量时间,难以满足大规模筛查的需求;第三,由于社会 stigma(病耻感)的存在,许多患者不愿意主动寻求专业帮助,导致病情延误。研究表明,如果患者未能在症状出现后的最初几个月内开始治疗,康复率会显著下降,病情持续的风险增加。
随着互联网的普及,越来越多的人倾向于在网络平台上表达自己的情绪和困扰,心理咨询平台、社交媒体等渠道积累了大量的文本数据。这些文本中隐含着丰富的心理状态信息,为基于自然语言处理的抑郁症自动检测提供了数据基础1。同时,机器学习技术的快速发展,使得从文本中自动识别抑郁倾向成为可能。
1.1.2 研究意义
基于上述背景,开发一个基于机器学习的抑郁症文本检测系统具有重要的理论意义和现实价值
1.2 国内外研究现状
近年来,基于机器学习的抑郁症自动检测已成为计算精神病学领域的研究热点。
在中文文本处理方面,由于中文的语言特性,分词、词性标注等预处理步骤尤为重要。同时,中文心理咨询语料具有口语化强、隐含信息丰富等特点,需要针对性地设计特征提取方法6。
1.3 论文研究目标和内容
本论文旨在设计并实现一个基于机器学习的抑郁症文本检测系统,主要研究内容包括:
系统需求分析:从功能需求和非功能需求两个维度,分析系统应具备的核心功能,包括用户管理、文本预测、批量处理、数据可视化等。
系统架构设计:设计系统的整体架构,包括前端展示层、业务逻辑层、数据访问层,以及各功能模块的划分与交互关系。
数据库设计:设计用户表、咨询数据表、预测记录表的结构,满足用户管理和预测数据存储的需求。
文本预处理与特征工程:实现中文文本清洗、分词、停用词过滤等预处理流程;设计多维特征提取方法,包括情感特征、LIWC特征、词性特征、句子结构特征、TF-IDF特征等。
机器学习模型构建:实现并比较Logistic回归、随机森林、XGBoost、LightGBM等多种分类模型;采用SMOTE过采样技术处理类别不平衡问题;通过交叉验证评估模型性能。
Web应用开发:基于Flask框架开发完整的Web应用,实现用户认证、单条预测、批量上传、结果可视化、管理员后台等功能。
第二章 系统需求分析
- 1 系统功能需求分析
2.1.1 用户管理需求分析
系统需要支持多用户使用,包括普通用户和管理员两种角色。普通用户可以访问预测功能和查看个人历史记录;管理员除普通用户权限外,还需要管理用户账号和查看所有预测记录。
2.1.2 数据预处理需求分析
系统需要处理用户输入的各种文本数据,包括单条输入和批量上传的文件。预处理模块应满足以下需求:
文本清洗:去除无关字符、特殊符号、多余空格,对手机号、邮箱等个人信息进行脱敏处理。
文本长度限制:系统应限制输入文本的最小和最大长度,确保预测的可靠性。
文件格式支持:批量预测应支持TXT、CSV、XLSX等常见文件格式,并能够自动识别文件中的文本列。
异常处理:对于空文本或格式错误的文件,系统应给出明确的错误提示。
2.1.3 抑郁症预测需求分析
预测功能是系统的核心业务需求,应满足:
单条文本预测:用户输入一段文本后,系统应返回预测的风险等级(正常/疑似/明确)、置信度、各等级概率分布,以及支持预测结果的关键证据片段。
批量文本预测:用户上传包含多条文本的文件后,系统应逐条处理并展示所有预测结果,包括每条记录的文本预览、风险等级、置信度等信息。
预测记录保存:系统应自动保存用户的预测历史,包括输入文本、预测结果、置信度、时间戳等,供用户后续查看。
模型可解释性:系统应提供证据片段提取功能,向用户解释模型做出判断的依据,增强结果的可信度。
第三章 系统设计
- 1 系统总体设计
3.1.1 系统架构设计
系统采用经典的B/S架构,分为前端展示层、业务逻辑层和数据访问层三层架构。前端负责用户交互和数据可视化;业务逻辑层处理核心业务,包括用户认证、文本预测、模型调用等;数据访问层封装数据库操作,提供数据持久化支持。如图3-1所示
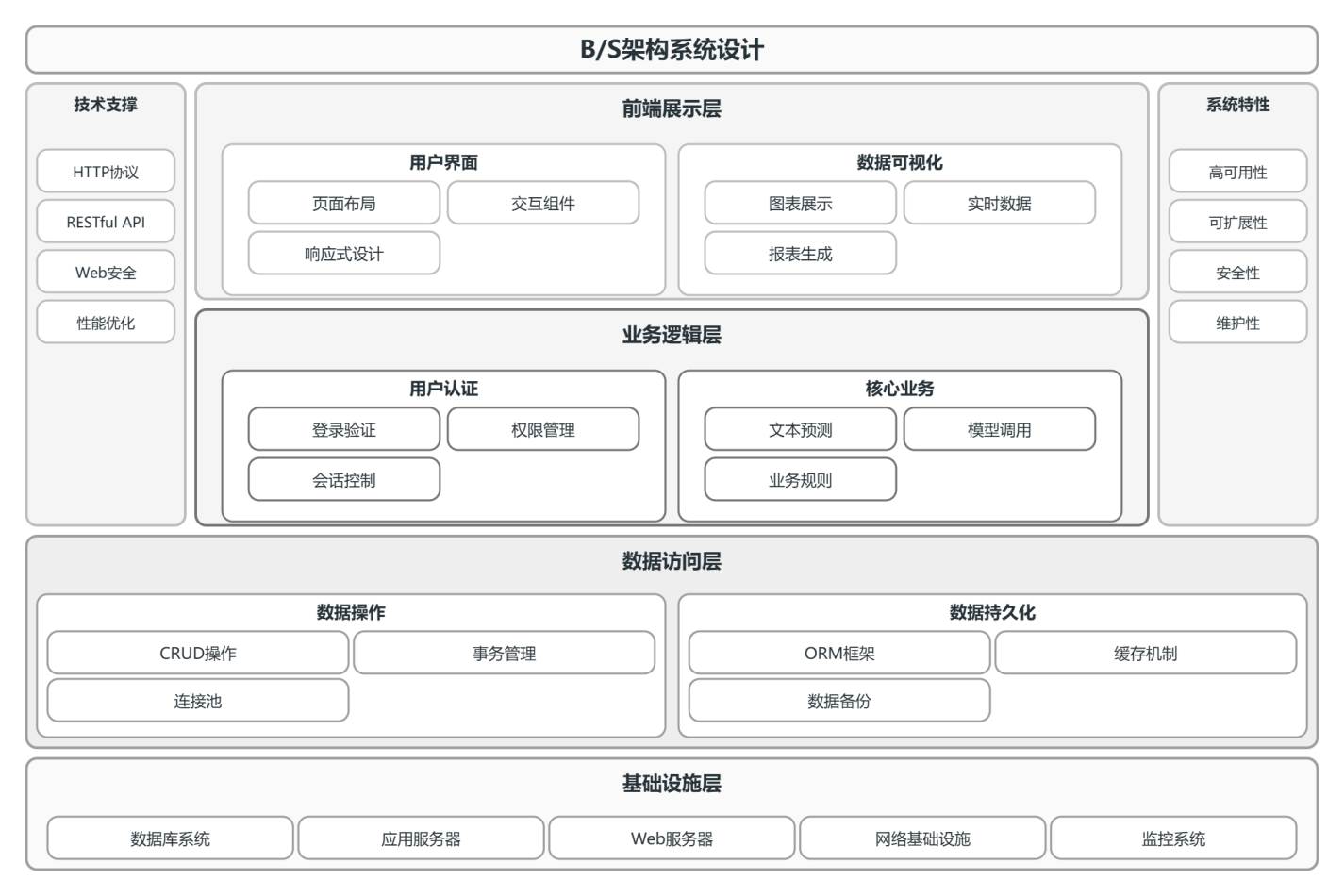
图 3-1 系统架构图
3.1.2 系统功能设计
系统整体功能模块划分如图3-2所示,主要包括:
用户模块:负责用户的注册、登录、登出和权限管理
预测模块:提供单条和批量文本预测功能
模型服务模块:封装模型加载、特征提取、预测推理等核心算法
数据管理模块:负责预测记录、用户信息、系统数据的存储与查询
可视化模块:以图表形式展示数据统计和预测结果
管理员模块:提供用户管理和系统监控功能。

图 3-2 系统功能图
- 2 系统功能模块设计
3.2.1 用户管理模块
用户管理模块的核心功能包括用户注册、登录认证、会话管理和权限控制。用户登录后,系统通过Flask-Login维护用户会话状态。权限控制通过检查当前用户的角色属性实现,管理员可以访问/admin开头的路由,普通用户则被重定向。
3.2.2 数据预处理模块
数据预处理模块负责对原始文本进行清洗和标准化。主要功能包括:移除特殊符号和多余空格;对手机号、邮箱等个人信息进行脱敏替换;对文本进行分句和分词;过滤停用词。
3.2.3 特征工程模块
特征工程模块是系统的核心算法组件,负责从清洗后的文本中提取可用于模型训练的特征。具体包括:
手工特征提取:提取情感词频、LIWC心理语言学特征、词性分布特征、句子结构特征等
TF-IDF特征提取:将文本转换为TF-IDF向量,捕捉关键词重要性
特征融合与标准化:将多类特征进行拼接,并对数值特征进行标准化处理
3.2.4 模型训练与预测模块
该模块负责机器学习模型的训练、保存和加载,并提供预测接口。系统支持多种分类模型,包括Logistic回归、随机森林、XGBoost和LightGBM。训练完成后,系统选择验证集上性能最优的模型用于线上预测。
- 3 数据库设计
3.3.1 数据库E-R模型设计
系统涉及的核心实体包括用户(User)、咨询数据(Counseling Data)和预测记录(Prediction)。它们之间的关系如下:
一个用户可以有多条预测记录,用户与预测记录是一对多关系
咨询数据是预置的训练数据,与用户无直接关联。
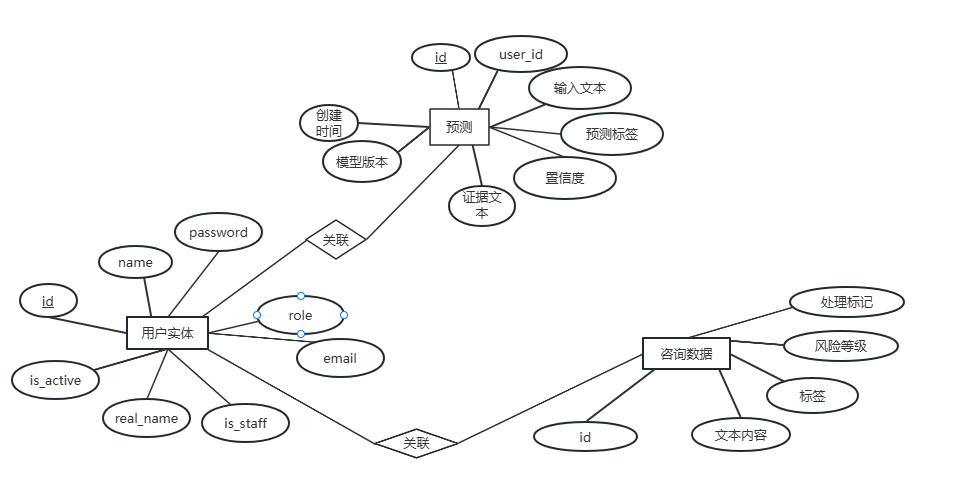
图 3-1 E-R图
3.3.2 实体属性设计
用户实体(User):包含用户ID、用户名、密码哈希、邮箱、角色、创建时间、最后登录时间等属性。
预测记录实体(Prediction):包含记录ID、用户ID(外键)、输入文本、预测标签、置信度、证据文本、模型版本、创建时间等属性。
咨询数据实体(Counseling Data):包含数据ID、MD5哈希、文本内容、多级分类标签、风险等级、处理标记等属性。
3.3.3 数据库详细表设计
系统采用SQLite作为数据库,共包含三张核心数据表,详细结构如下:
表 3-1 用户表(users)
|------------|-----------|---------------------------|----------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 用户ID |
| username | TEXT | UNIQUE NOT NULL | 用户名 |
| password | TEXT | NOT NULL | 密码哈希 |
| email | TEXT | | 邮箱 |
| role | TEXT | NOT NULL | 角色(admin/user) |
| created_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | 创建时间 |
| last_login | TIMESTAMP | | 最后登录时间 |
表 3-2 咨询数据表
|---------------|-----------|---------------------------|----------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 数据ID |
| md5 | TEXT | UNIQUE | 文本MD5 |
| owner | TEXT | | 数据来源 |
| title | TEXT | | 标题 |
| combined_text | TEXT | NOT NULL | 合并后的文本内容 |
| s1_name | TEXT | | 一级分类名称 |
| s1_id | REAL | | 一级分类ID |
| s1_score | REAL | | 一级分类得分 |
| s2_name | TEXT | | 二级分类名称 |
| s2_id | REAL | | 二级分类ID |
| s2_score | REAL | | 二级分类得分 |
| s3_name | TEXT | | 三级分类名称 |
| s3_id | REAL | | 三级分类ID |
| s3_score | REAL | | 三级分类得分 |
| risk_level | TEXT | | 风险等级 |
| is_processed | INTEGER | DEFAULT 0 | 是否已处理 |
| created_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | 创建时间 |
| updated_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | 更新时间 |
表 3-3 预测记录表
|-----------------|---------|---------------------------|----------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 记录ID |
| user_id | INTEGER | NOT NULL | 用户ID(外键) |
| input_text | TEXT | NOT NULL | 输入文本 |
| predicted_label | TEXT | | 预测标签 |
| confidence | REAL | | 置信度 |
| evidence_text | TEXT | | 证据文本 |
| model_version | TEXT | | 模型版本 |
第四章 算法设计与实现
4.1 数据预处理
4.1.1 文本清洗与脱敏
原始心理咨询文本包含大量噪声,如特殊符号、多余空格,以及手机号、邮箱等个人隐私信息。文本清洗模块需要去除这些噪声,同时保护用户隐私。
文本清洗的流程如下:
移除特殊符号和表情:使用正则表达式\^\\w\\s\\u4e00-\\u9fff匹配并替换非中文字符、非数字、非字母、非空格的字符
移除数字:使用\d+匹配连续数字并替换为空
移除多余空格:将多个连续空格替换为单个空格
脱敏处理:分别匹配手机号、身份证号、邮箱、微信号、QQ号等敏感信息,替换为手机号等占位符。如表4-1所示脱敏规则示例结果
表 4-1 脱敏规则示例
|--------|-------------------------------|----------|
| 敏感信息类型 | 正则表达式 | 替换格式 |
| 手机号 | 13-9\d{9} | 手机号 |
| 身份证号 | \d{17}\\dXx | 身份证号 |
| 邮箱 | \\w.-+@\\w.-+.\w+ | 邮箱 |
| 微信号 | wxid_\w+|微信号::\s*\w+ | 微信号 |
| QQ号 | QQ::\s*\d{5,} | QQ号 |
4.1.2 中文分词与停用词过滤
中文文本处理需要先进行分词。系统采用jieba分词库进行分词,并加载停用词表过滤无意义的词语。停用词包括常见的虚词、标点符号和低频无意义词。代码如下所示:
def tokenize(self, text: str) -> Liststr:
"""中文分词并过滤停用词"""
words = jieba.lcut(text)
words = [word for word in words
if word not in self.stop_words and word.strip()]
return words,
4.2 特征提取
特征提取是系统的核心算法环节。系统从多个维度提取文本特征,形成多维特征向量供模型训练。
4.2.1 手工特征设计
手工特征的设计基于心理学和语言学的理论基础,主要包括以下几类:
情感词频特征:基于正面情感词词典和负面情感词词典,统计文本中包含的情感词数量,并计算情感得分9。
LIWC特征:LIWC(Linguistic Inquiry and Word Count)是心理语言学研究中广泛使用的文本分析工具。系统实现了简化的LIWC特征,包括人称代词、情感词、社交词、认知词等类别。
词性分布特征:使用jieba的词性标注功能,统计文本中名词、动词、形容词、副词、代词的比例。
句子结构特征:通过分析文本的句子数量、平均句长、问句数量、感叹句数量等,捕捉文本的表达风格。
程度词与否定词特征:统计程度副词和否定词的出现频率,这些词可以反映情绪的强度。
表 4-2 手工特征维度统计
|--------|-------|--------------------|
| 特征类别 | 特征维度数 | 说明 |
| 句子特征 | 8 | 句子数、平均句长、问号/感叹号数量等 |
| 词性特征 | 6 | 名词、动词、形容词、副词、代词比例 |
| 情感特征 | 6 | 积极/消极词频、情感多样性、情感强度 |
| LIWC特征 | 24 | 人称代词、社交词、认知词等24类 |
| 程度词特征 | 4 | 程度词/否定词数量及比例 |
| 词汇特征 | 3 | 词汇多样性、平均词长等 |
| 对话特征 | 3 | 对话轮次、问答比例等 |
4.2.2 TF-IDF与N-gram特征
TF-IDF(Term Frequency-Inverse Document Frequency)是文本分类中常用的统计特征,用于衡量词语在文档中的重要程度。系统采用sklearn.feature_extraction.text.TfidfVectorizer提取TF-IDF特征,并支持N-gram扩展以捕捉短语信息10。
4.2.3 特征标准化与融合
手工特征和TF-IDF特征的数值范围差异较大,需要进行标准化处理。系统采用StandardScaler对特征矩阵进行标准化,使其均值为0、标准差为1。
4.3 机器学习模型选择
系统实现了多种主流机器学习分类模型,并在验证集上比较其性能,选择最优模型用于线上预测。
4.3.1 Logistic回归
Logistic回归是一种线性分类模型,通过Sigmoid函数将线性组合映射为概率值。对于多分类问题,采用softmax回归(多项Logistic回归)。系统配置的Logistic回归参数包括:class_weight='balanced'(处理类别不平衡)、solver='saga'(支持L1正则化)、max_iter=1000。
4.3.2 随机森林
随机森林是基于决策树的集成学习方法,通过Bagging和随机特征选择提高模型的泛化能力。系统配置的随机森林参数包括:n_estimators=200(200棵决策树)、max_depth=20(树的最大深度)、class_weight='balanced'。
4.3.3 XGBoost
XGBoost是一种基于梯度提升框架的优化算法,通过迭代训练弱分类器并加权组合形成强分类器。XGBoost支持自定义损失函数、正则化、并行计算等特性。系统配置的XGBoost参数包括:n_estimators=200、max_depth=6、learning_rate=0.1、objective='multi:softprob'。
4.3.4 LightGBM
LightGBM是微软开源的梯度提升框架,采用基于直方图的决策树算法和单边梯度采样技术,训练速度快、内存占用小。系统配置的LightGBM参数包括:n_estimators=200、max_depth=6、num_leaves=63、objective='multiclass'。
4.3.5 集成学习
除单一模型外,系统还支持投票集成(Voting Ensemble)和堆叠集成(Stacking Ensemble),通过组合多个基础模型的预测结果,进一步提高分类性能。
表 4-3 各模型在验证集上的性能对比
|------------|--------|---------|---------|----------|
| 模型 | 准确率 | 精确率(加权) | 召回率(加权) | F1分数(加权) |
| Logistic回归 | 38.75% | 38.02% | 38.75% | 38.38% |
| 随机森林 | 91.25% | 91.56% | 91.25% | 91.40% |
| XGBoost | 91.38% | 91.69% | 91.38% | 91.53% |
| LightGBM | 91.25% | 91.56% | 91.25% | 91.40% |
4.4 模型训练与优化
4.4.1 类别不平衡处理
心理咨询语料中,正常样本数量远多于疑似和明确样本,存在类别不平衡问题。系统采用SMOTE(Synthetic Minority Over-sampling Technique)过采样技术生成少数类样本的合成数据,平衡各类别的样本数量。
SMOTE算法原理:对于少数类中的每个样本,随机选择k个近邻,在两个样本之间的连线上随机生成新样本。系统配置的SMOTE参数为random_state=42。
处理前后各类别样本数量的变化:
处理前:正常类约70%,疑似类约20%,明确类约10%
处理后:三类样本数量相等,各占33.3%
4.4.2 交叉验证
为更稳健地评估模型性能,系统采用分层K折交叉验证(Stratified K-Fold Cross Validation)。分层确保每一折中各类别的比例与原始数据保持一致。系统默认采用5折交叉验证,评估指标包括准确率、精确率、召回率和F1分数。
4.4.3 超参数优化
系统支持网格搜索(Grid Search)和随机搜索(Random Search)两种超参数优化方法。网格搜索遍历所有参数组合,确保找到最优解,但计算开销较大;随机搜索在参数空间中随机采样,可以在较短时间内找到近似最优解。
4.5 模型评估方法
4.5.1 分类评估指标
系统采用以下指标评估分类性能:
准确率(Accuracy):预测正确的样本数占总样本数的比例
精确率(Precision):预测为正类的样本中实际为正类的比例
召回率(Recall):实际为正类的样本中被正确预测的比例
F1分数:精确率和召回率的调和平均数
加权平均:根据各类别样本数量加权计算的平均指标
对于多分类问题,系统同时计算宏平均(各类别指标算术平均)和加权平均。
4.5.2 可解释性分析
为增强模型的可信度,系统设计了两种可解释性方法:
证据片段提取:根据预测的风险等级,从原文中提取与相应关键词匹配的句子作为证据。例如,当预测为"明确"风险时,系统会提取包含"自杀"、"想死"等关键词的句子。
特征重要性分析:通过模型的feature_importances_属性(树模型)或系数(线性模型),分析哪些特征对预测结果影响最大。
表 4-4 风险等级与证据关键词映射
|------|---------------|--------------|
| 风险等级 | 关键词 | 证据提取策略 |
| 正常 | 开心、快乐、幸福、满意 | 提取包含正面词的句子 |
| 疑似 | 痛苦、难过、绝望、孤独 | 提取包含负面情绪词的句子 |
| 明确 | 自杀、想死、结束、活不下去 | 提取包含极端危险词的句子 |
第五章 系统开发与实现
5.1 系统技术选型
系统采用的技术栈如下:
后端框架:Flask 2.0+,轻量级Python Web框架
前端框架:Bootstrap 5 + ECharts,实现响应式界面和数据可视化
数据库:SQLite,轻量级嵌入式数据库
机器学习:scikit-learn、XGBoost、LightGBM、imbalanced-learn
中文NLP:jieba分词、正则表达式
用户认证:Flask-Login、Werkzeug安全模块。
5.2 主要模块的实现
5.2.1 用户登录与注册实现
用户认证采用Flask-Login扩展实现。密码使用werkzeug.security.generate_password_hash进行哈希加密,存储到数据库;登录验证时使用check_password_hash比对密码。
图 5-1 登录页面
5.2.2 单条文本预测实现
单条预测功能接收用户输入的文本,调用预测核心函数,返回分析结果并保存记录。
预测核心函数predict_text的实现流程:检查模型和特征工程器是否已加载,调用特征工程器提取文本特征,调用模型预测风险等级和概率,根据预测结果提取证据片段,封装结果字典返回。
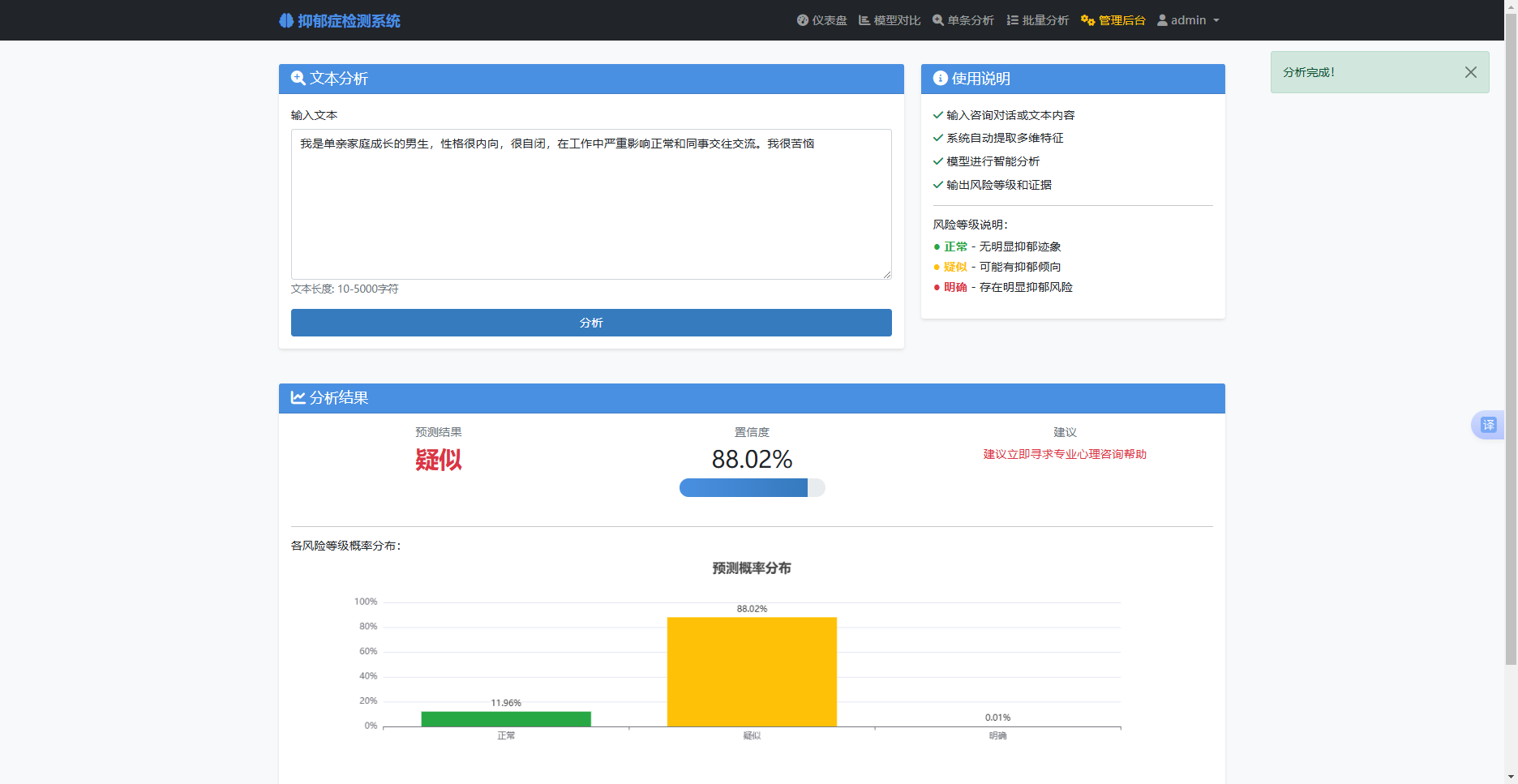
图 5-2 单条文本预测实现
5.2.3 批量文本预测实现
批量预测功能支持用户上传文件,系统解析文件后逐条处理。文件上传通过Flask的request.files获取,使用secure_filename确保文件名安全。
文件解析逻辑:TXT文件:按行读取,每行作为一条文本,CSV/XLSX文件:用pandas读取,自动识别文本列(列名包含"text"、"content"或"文本")
每行处理完后,将结果添加到列表,最终在页面展示。
图 5-4 批量预测页面
5.2.4 模型训练与评估实现
模型训练模块model_trainer.py封装了完整的训练流程,包括数据加载、特征提取、模型训练、评估和保存。训练时支持多模型并行训练和集成学习。
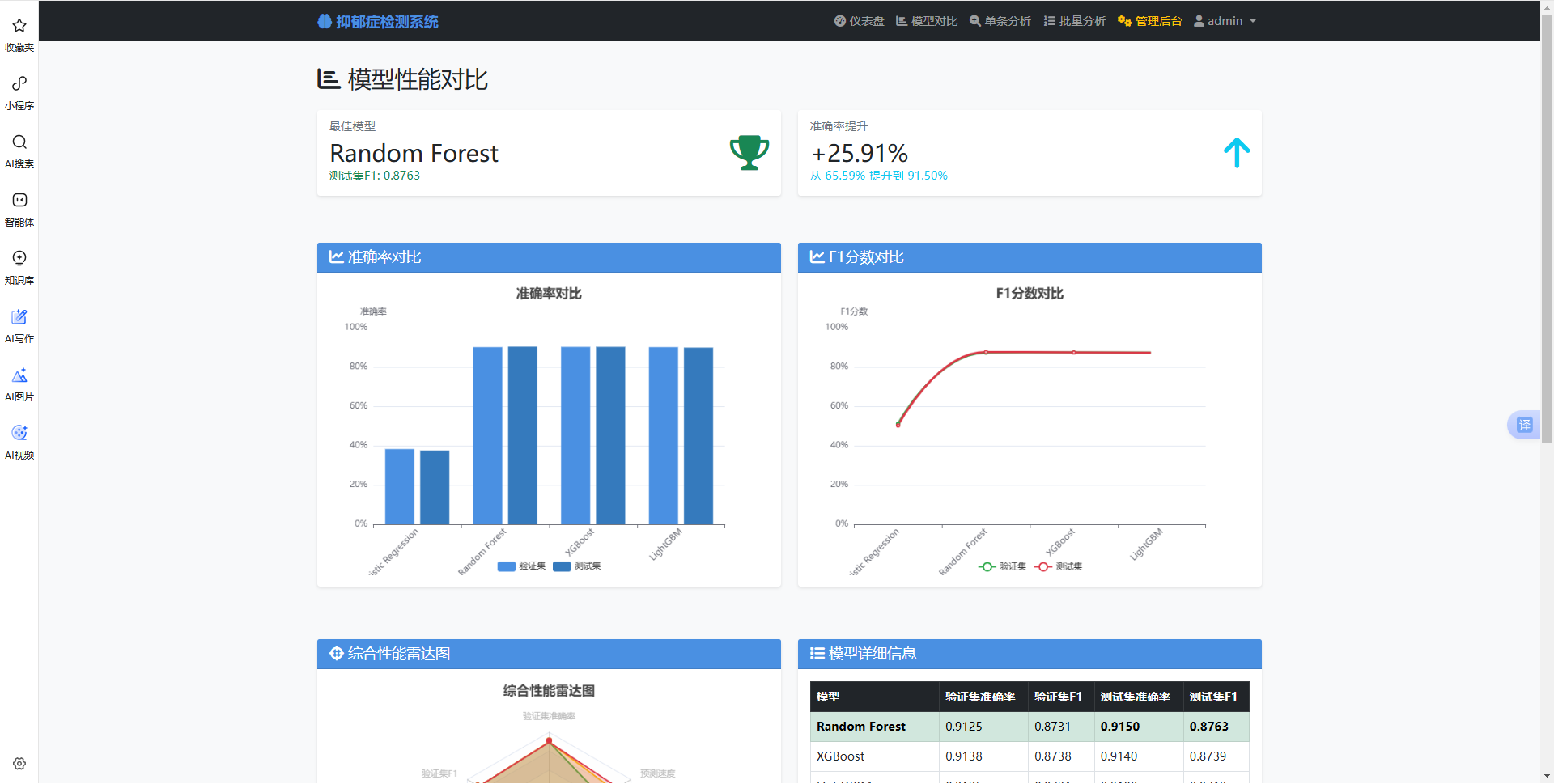
图 5-4 模型训练与评估页面
5.2.5 数据可视化实现
数据可视化采用ECharts实现,在dashboard页面展示风险等级分布饼图、预测历史趋势图、置信度分布图等。前端通过Ajax请求获取统计数据,动态渲染图表。
图 5-5 数据可视化页面