Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第七章 Classes and Interfaces(类与接口)
作为一种面向对象编程语言,Python 支持各种特性,如继承、多态和封装。在 Python 中完成任务通常需要编写新的类,并定义它们如何通过接口和关系进行交互。
类与继承机制使得用对象来表述 Python 程序的预期行为变得十分简便。它们使您能够随着时间的推移不断完善和扩展功能。在需求不断变化的环境中,这些机制提供了灵活性。熟练掌握类与继承的使用方法,有助于您编写易于维护的代码。
Python 也是一种多范式语言 ,它鼓励采用函数式编程 风格。函数对象属于第一类,这意味着它们可以像普通变量一样被传递。Python 还允许你在同一程序中使用混合的面向对象风格与函数式风格特性,这种方式可能比各自独立使用任何一种风格都更为强大。
Item 52:使用 @classmethod 方法多态性通用地构造对象
在 Python 中,不仅对象支持多态性,类也同样具备这种特性。这究竟意味着什么,又有着怎样的益处呢?
多态性使层次结构中的多个类能够实现各自独有的方法版本。这意味着许多类可以同时满足相同的接口或抽象基类,同时提供不同的功能(有关信息,请参阅 Item 49:"优先采用面向对象的多态而非带有 isinstance 检查的函数"和 Item 57:"为自定义容器类型继承自 collections.abc 类")。
例如,假设我正在编写一个 map-reduce 实现的代码,并希望有一个通用类来代表输入数据。在此处,我定义了这样一个类,并为其设定了必须由子类定义的读取方法:
class InputData:
def read(self):
raise NotImplementedError我还有一个 InputData 的具体子类,它能够从磁盘上的文件中读取数据:
class PathInputData(InputData):
def __init__(self, path):
super().__init__()
self.path = path
def read(self):
with open(self.path) as f:
return f.read()我可以创建任意数量的 InputData 子类,例如 PathInputData,而每个子类均可实现标准的接口以进行读取,从而将数据返回到处理流程中。其他 InputData 子类则可以从网络中读取数据,对数据进行透明解压等操作。
我希望给以标准方式处理输入数据的 map-reduce 工作者提供一个类似的抽象接口:
class Worker:
def __init__(self, input_data):
self.input_data = input_data
self.result = None
def map(self):
raise NotImplementedError
def reduce(self, other):
raise NotImplementedError在此处,我定义了具体的子类 Worker,用于实现我要应用的特定 map-reduce 函数------一个简单的换行计数器:
class LineCountWorker(Worker):
def map(self):
data = self.input_data.read()
self.result = data.count("\n")
def reduce(self, other):
self.result += other.result这个实现看起来似乎进展顺利,但是我遇到了最大的障碍:将所有这些部分连接起来的是什么?我有一组不错的类,它们具有合理的接口和抽象,但是只有在创建了对象之后才有用。哪个组件负责构建对象并协调 map-reduce 呢?最简单的方法是使用一些辅助函数手动构建并连接各个对象。在此处,我列出了某个目录的内容,并为其中包含的每个文件创建了一个 PathInputData 实例:
import os
def generate_inputs(data_dir):
for name in os.listdir(data_dir):
yield PathInputData(os.path.join(data_dir, name))接下来,我使用由 generate_inputs 返回的 InputData 实例创建换行计数器实例:
def create_workers(input_list):
workers = []
for input_data in input_list:
workers.append(LineCountWorker(input_data))
return workers我通过将 map 步骤分散到多个线程中来执行这些 Worker 进程(有关信息,请参阅 Item 68:"使用线程处理阻塞 I/O;避免用于并行处理")。接着,我反复调用 reduce 函数,将结果合并为一个最终值:
from threading import Thread
def execute(workers):
threads = [Thread(target=w.map) for w in workers]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
first, *rest = workers
for worker in rest:
first.reduce(worker)
return first.result最后,我将所有环节整合到一个函数中,该函数会逐一执行各个步骤:
def mapreduce(data_dir):
inputs = generate_inputs(data_dir)
workers = create_workers(inputs)
return execute(workers)使用一组测试输入文件调用此函数效果极佳:
import os
import random
def write_test_files(tmpdir):
os.makedirs(tmpdir)
for i in range(100):
with open(os.path.join(tmpdir, str(i)), "w") as f:
f.write("\n" * random.randint(0, 100))
tmpdir = "test_inputs"
write_test_files(tmpdir)
result = mapreduce(tmpdir)
print(f"There are {result} lines")
>>>
There are 4360 lines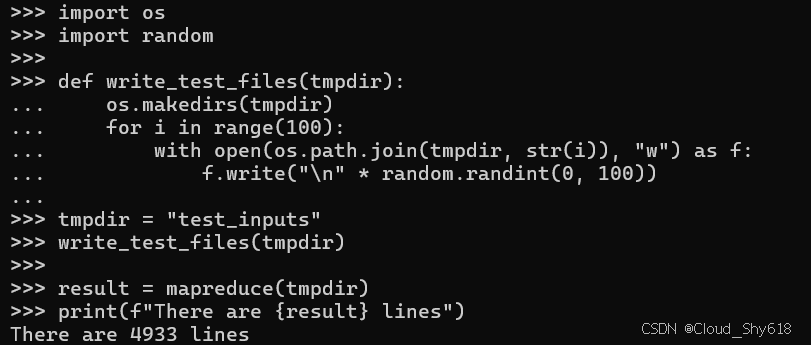
问题出在哪儿呢?最大的问题在于 mapreduce 函数根本不具备通用性。如果我想编写另一个 InputData 或 Workers 子类,我还得重新改写 generate_inputs、create_workers 和 mapreduce 函数,以使其与之相匹配。
这个问题归结为需要一种通用的方法来构造对象。在其他语言中,您可以使用构造函数多态性来解决这个问题,要求每个 InputData 子类提供一个特殊的构造函数,该构造函数可以由编排 map-reduce 的帮助器方法通用使用(类似于工厂模式)。问题在于 Python 只允许使用单个构造函数方法 (__init__)。 要求每个 InputData 子类都有一个兼容的构造函数是不合理的。
解决此问题的最佳方法是通过类方法多态性来实现。这完全类似于我为 InputData.read 函数所采用的实例方法多态性,只不过它适用于整个类而非其构建的对象。
让我将这一思路应用到 map-reduce 类上。在此处,我扩展了 InputData 类,添加了一个通用 @classmethod 方法,该方法负责使用一个通用接口创建新的 InputData 实例
class GenericInputData:
def read(self):
raise NotImplementedError
@classmethod
def generate_inputs(cls, config):
raise NotImplementedError我已生成一个包含一组配置参数的字典,这些参数是通用 InputData 的具体子类需要解读的。在此处,我借助 config 参数来查找用于列出输入文件的目录:
class PathInputData(GenericInputData):
def __init__(self, path):
super().__init__()
self.path = path
def read(self):
with open(self.path) as f:
return f.read()
@classmethod
def generate_inputs(cls, config):
data_dir = config["data_dir"]
for name in os.listdir(data_dir):
yield cls(os.path.join(data_dir, name))同样地,我可将 create_workers 辅助部分并入到 GenericWorker 类中。在此处,我使用了 input_class 参数,该参数必须为 GenericInputData 的子类,以生成所需的输入数据:
class GenericWorker:
def __init__(self, input_data):
self.input_data = input_data
self.result = None
def map(self):
raise NotImplementedError
def reduce(self, other):
raise NotImplementedError
@classmethod
def create_workers(cls, input_class, config):
workers = []
for input_data in input_class.generate_inputs(config):
workers.append(cls(input_data))
return workers请注意,上面对于 input_class.generate_inputs 的调用正是我试图展示的类多态性。你还可以看到 create_workers 调用 cls 提供了除直接使用 __init__ 方法外构建 GenericWorker 对象的另一种方式。
这对我创建的具体子类 GenericWorker 的影响无非就是更改了其父类:
class LineCountWorker(GenericWorker): # Changed
def map(self):
data = self.input_data.read()
self.result = data.count("\n")
def reduce(self, other):
self.result += other.result最终,我可以通过调用 create_workers 类方法来重新编写 mapreduce 函数,使其具备完全的通用性:
def mapreduce(worker_class, input_class, config):
workers = worker_class.create_workers(input_class, config)
return execute(workers)在新 worker 上运行一组测试文件所得到的结果与旧实现方式相同。不同的是,mapreduce 函数需要更多的参数,以便能够进行通用操作:
config = {"data_dir": tmpdir}
result = mapreduce(LineCountWorker, PathInputData, config)
print(f"There are {result} lines")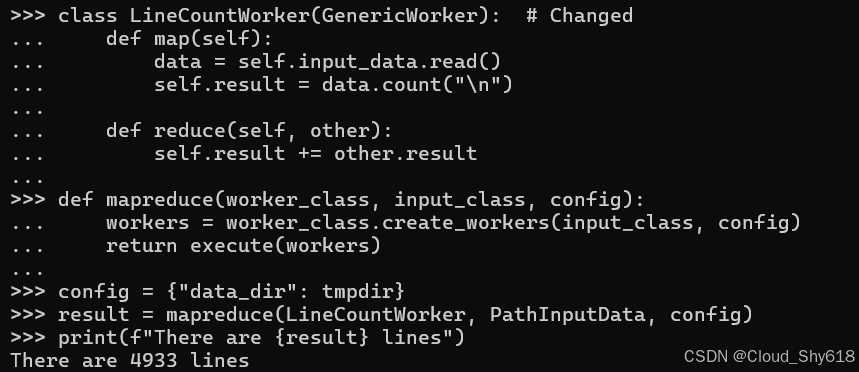
现在我可以根据需要编写其他通用输入数据和通用工作子类,而无需重写任何粘合代码。
注意:
- Python 每个类只支持一个构造函数:
__init__方法。 - 使用 @classmethod 为您的类定义可替代的构造函数。
- 使用类方法多态性提供构建和连接许多具体子类的通用方法。
Item 53:使用 super 初始化父类
从子类初始化父类的古老而简单的方法是直接使用子实例调用父类的 __init__ 方法:
class MyBaseClass:
def __init__(self, value):
self.value = value
class MyChildClass(MyBaseClass):
def __init__(self):
MyBaseClass.__init__(self, 5)这种方法适用于基本类层次结构,但在许多情况下会失败。
如果一个类受到多重继承的影响(一般要避免;请参阅 Item 54:"考虑使用混合类来组合功能"),直接调用超类的 __init__ 方法可能会导致不可预测的行为。
一个问题是没有在所有子类中指定 __init__ 调用顺序。例如,这里我定义了两个对实例的 valuefield 进行操作的父类:
class TimesTwo:
def __init__(self):
self.value *= 2
class PlusFive:
def __init__(self):
self.value += 5该类以一种顺序定义其父类:
class OneWay(MyBaseClass, TimesTwo, PlusFive):
def __init__(self, value):
MyBaseClass.__init__(self, value)
TimesTwo.__init__(self)
PlusFive.__init__(self)构造它会产生与父类顺序匹配的结果:
foo = OneWay(5)
print("First ordering value is (5 * 2) + 5 =", foo.value)
>>>
First ordering value is (5 * 2) + 5 = 15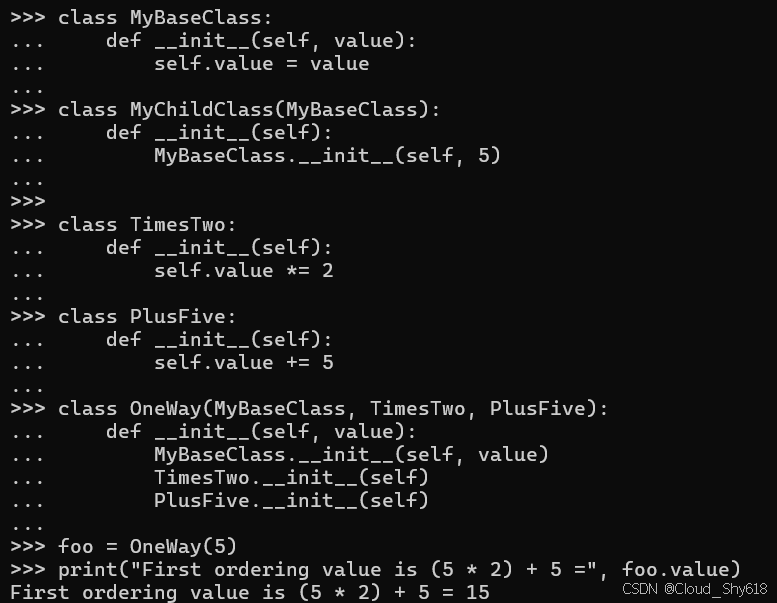
这是另一个类,它定义了相同的父类,但顺序不同(加五后跟乘数二,而不是相反):
class AnotherWay(MyBaseClass, PlusFive, TimesTwo):
def __init__(self, value):
MyBaseClass.__init__(self, value)
TimesTwo.__init__(self)
PlusFive.__init__(self)但是,我保留了对父类构造函数的调用(Plus Five.__init__ 和 Times Two.__init__),其顺序与以前相同,这意味着该类的行为与其定义中父类的顺序不匹配。继承基类的顺序和 __init__ 调用之间的冲突很难发现,这使得代码的新读者尤其难以理解:
bar = AnotherWay(5)
print("Second ordering should be (5 + 5) * 2, but is", bar.value)
>>>
Second ordering should be (5 + 5) * 2, but is 15
钻石继承(多重继承)还存在另一个问题。当子类继承自两个单独的类,而这两个类在层次结构中的某个位置具有相同的超类时,就会发生钻石继承。Diamond 继承会导致共同超类的 __init__ 方法运行多次,从而导致意外行为。 例如,这里我定义了两个继承自 MyBaseClass 的子类:
class TimesSeven(MyBaseClass):
def __init__(self, value):
MyBaseClass.__init__(self, value)
self.value *= 7
class PlusNine(MyBaseClass):
def __init__(self, value):
MyBaseClass.__init__(self, value)
self.value += 9然后我定义一个从这两个类继承的子类,使 MyBaseClass 成为菱形的顶部:
class ThisWay(TimesSeven, PlusNine):
def __init__(self, value):
TimesSeven.__init__(self, value)
PlusNine.__init__(self, value)
foo = ThisWay(5)
print("Should be (5 * 7) + 9 = 44 but is", foo.value)
>>>
Should be (5 * 7) + 9 = 44 but is 14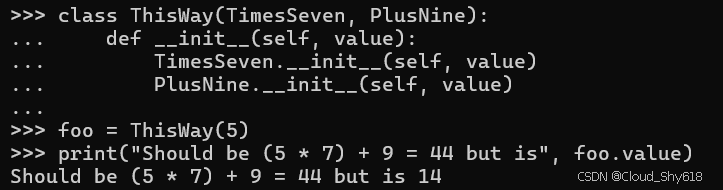
当第二次调用 MyBaseClass.__init__ 时,对第二个父类的构造函数 PlusNine.__init__ 的调用会导致 self.value 重置回 5。这导致 self.value 的计算结果为 5 + 9 = 14,完全忽略了 Times Seven.__init__ 构造函数的影响。这种行为令人意外,并且在更复杂的情况下可能很难调试。
为了解决这些问题,Python 拥有 super 内置函数和标准方法解析顺序(MRO)。 super 确保菱形(钻石)层次结构中的公共超类仅运行一次(有关另一个示例,请参阅 Item 62:"使用 __init_subclass__ 验证子类")。MRO 定义 super 初始化的顺序,遵循称为 C3 线性化的算法:
这里我再次创建了一个菱形的类层次结构,但是这次我使用 super 来初始化父类:
class MyBaseClass:
def __init__(self, value):
self.value = value
class TimesSevenCorrect(MyBaseClass):
def __init__(self, value):
super().__init__(value)
self.value *= 7
class PlusNineCorrect(MyBaseClass):
def __init__(self, value):
super().__init__(value)
self.value += 9现在,菱形的顶部部分 MyBaseClass.__init__ 仅运行一次。其他父类按照类语句中指定的顺序运行:
class GoodWay(TimesSevenCorrect, PlusNineCorrect):
def __init__(self, value):
super().__init__(value)
foo = GoodWay(5)
print("Should be 7 * (5 + 9) = 98 and is", foo.value)
>>>
Should be 7 * (5 + 9) = 98 and is 98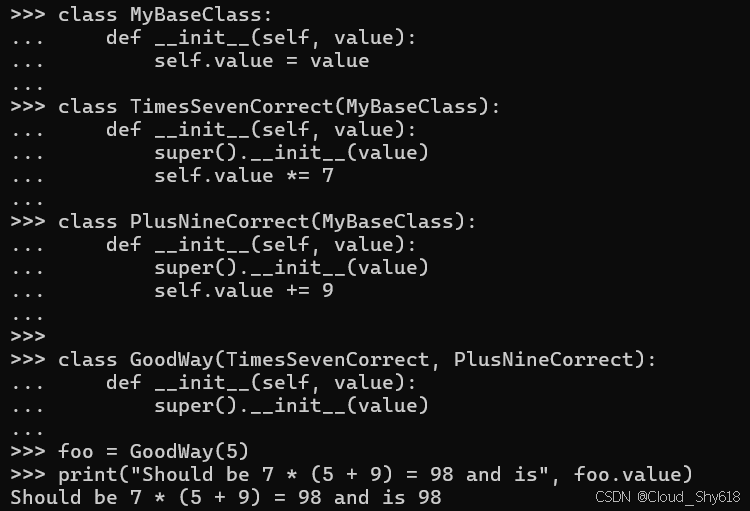
这个顺序可能看起来很落后。Times Seven Correct.__init__ 不应该先运行吗? 结果不应该是 (5 * 7) + 9 = 44 吗? 答案是否定的。此顺序与 MRO 为此类定义的顺序相匹配。MRO 排序可通过名为 __mroor__ 的类方法获得,该方法缓存在名为 __mro__ 的类属性中:
mro_str = "\n".join(repr(cls) for cls in GoodWay.__mro__)
print(mro_str)
>>>
<class '__main__.GoodWay'>
<class '__main__.TimesSevenCorrect'>
<class '__main__.PlusNineCorrect'>
<class '__main__.MyBaseClass'>
<class 'object'>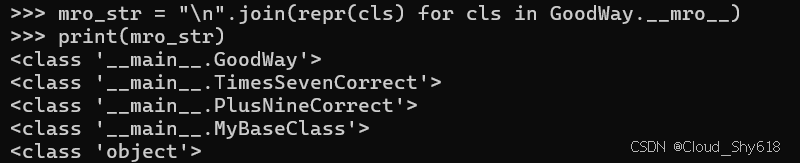
当我调用 Good Way(5) 时,它调用 Times Seven Correct.__init__,前者又调用 PlusNineCorrect.__init__,前者又调用 MyBaseClass.__init__。 一旦到达菱形的顶部,所有初始化方法实际上都按照与调用 __init__ 函数相反的顺序进行工作。MyBaseClass.__init__ 将值分配给 5, PlusNineCorrect.__init__添加 9 以使值等于 14, TimesSevenCorrect.__init__ 将其乘以 7 以使值等于 98。
除了使多重继承变得健壮之外,对 super().__init__ 的调用也比直接从子类中调用 MyBaseClass.__init__ 更易于维护。我稍后可以将 MyBaseClass 重命名为其他名称,或者让 TimesSevenCorrect 和 PlusNineCorrect 从另一个超类继承,而无需更新它们的 __init__方法来匹配。
super 函数也可以使用两个参数来调用:第一个是您尝试访问其 MRO 父视图的类的类型,然后是要访问该视图的实例。在构造函数中使用这些可选参数如下所示:
class ExplicitTrisect(MyBaseClass):
def __init__(self, value):
super(ExplicitTrisect, self).__init__(value)
self.value /= 3
assert ExplicitTrisect(9).value == 3但是,对象实例初始化不需要这些参数。当在类定义中使用零参数调用 super 时,Python 编译器会自动为您提供正确的参数(__class__ 和 self)。这意味着所有这三种用法都是等效的:
class AutomaticTrisect(MyBaseClass):
def __init__(self, value):
super(__class__, self).__init__(value)
self.value /= 3
class ImplicitTrisect(MyBaseClass):
def __init__(self, value):
super().__init__(value)
self.value /= 3
assert ExplicitTrisect(9).value == 3
assert AutomaticTrisect(9).value == 3
assert ImplicitTrisect(9).value == 3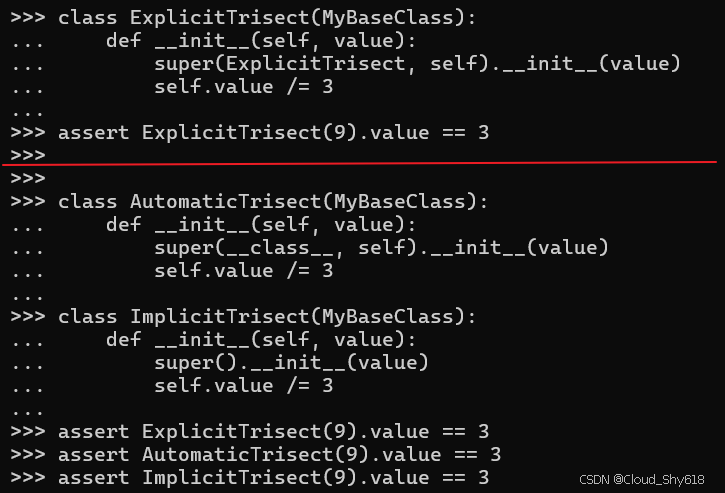
只有当您需要从子类访问超类实现的特定功能时(例如,为了包装或重用功能),您才应该向 super 提供参数。
注意:
-
Python 的标准 MRO 解决了超类初始化顺序和钻石继承的问题。
-
使用无参数的 super 内置函数来初始化父类并调用父方法。