roboflow/supervision:计算机视觉工程里的"胶水层",为什么值得关注?
摘要:
roboflow/supervision不是一个训练框架,也不是新的视觉模型,而是一个面向计算机视觉应用开发的 Python 工程库。它的核心价值,是把 YOLO、SAM、Transformers、Roboflow Inference、Detectron2、MMDetection、VLM 等不同来源的模型输出,统一成sv.Detections,再围绕这个统一对象做可视化、过滤、跟踪、区域计数、视频处理、数据集转换和指标评估。对于正在做视觉 demo、视频分析、机器人视觉、工业质检、交通统计、安防巡检的开发者来说,supervision更像模型到业务系统之间的稳定胶水层。
TL;DR:supervision 到底解决什么问题?
一句话说:supervision 解决的是"模型已经有了,如何把模型输出变成可处理、可展示、可统计、可评估、可落地的工程结果"。
很多计算机视觉项目卡住,并不是因为模型完全不能用,而是因为模型输出之后的工程链路太散:不同模型返回不同格式,视频逐帧处理代码容易写乱,画框和标签到处是 OpenCV 样板代码,目标跟踪和区域计数很容易重复造轮子,数据集格式转换和评估流程也常常变成临时脚本。
supervision 的定位不是替代 PyTorch、Ultralytics、SAM 或 Roboflow Inference,而是站在它们之后,做视觉应用开发的中间层。
它最值得关注的点有四个:
- 用
sv.Detections统一不同模型输出。 - 用 Annotator、Zone、Slicer、Dataset、Metric 等小工具组合视觉应用管线。
- 降低 OpenCV 绘图、视频处理、区域统计、格式转换的重复劳动。
- 让业务代码少依赖某个模型 SDK 的私有输出格式。
supervision 在视觉技术栈中的位置
现代视觉应用大致可以拆成四层。
第一层是数据层:图片、视频、标注文件、数据集划分、YOLO/COCO/Pascal VOC 等格式。
第二层是模型层:YOLO、DETR、SAM、Grounding DINO、RF-DETR、Detectron2、MMDetection、Transformers、VLM 等。
第三层是后处理与应用逻辑层:结果转换、过滤、可视化、跟踪、区域计数、视频写出、指标评估。
第四层是业务系统层:交通分析、工业质检、机器人系统、安防告警、商超客流、Web 后台、数据库和任务调度。
supervision 主要位于第三层。它向下适配模型输出和数据集格式,向上服务业务系统。
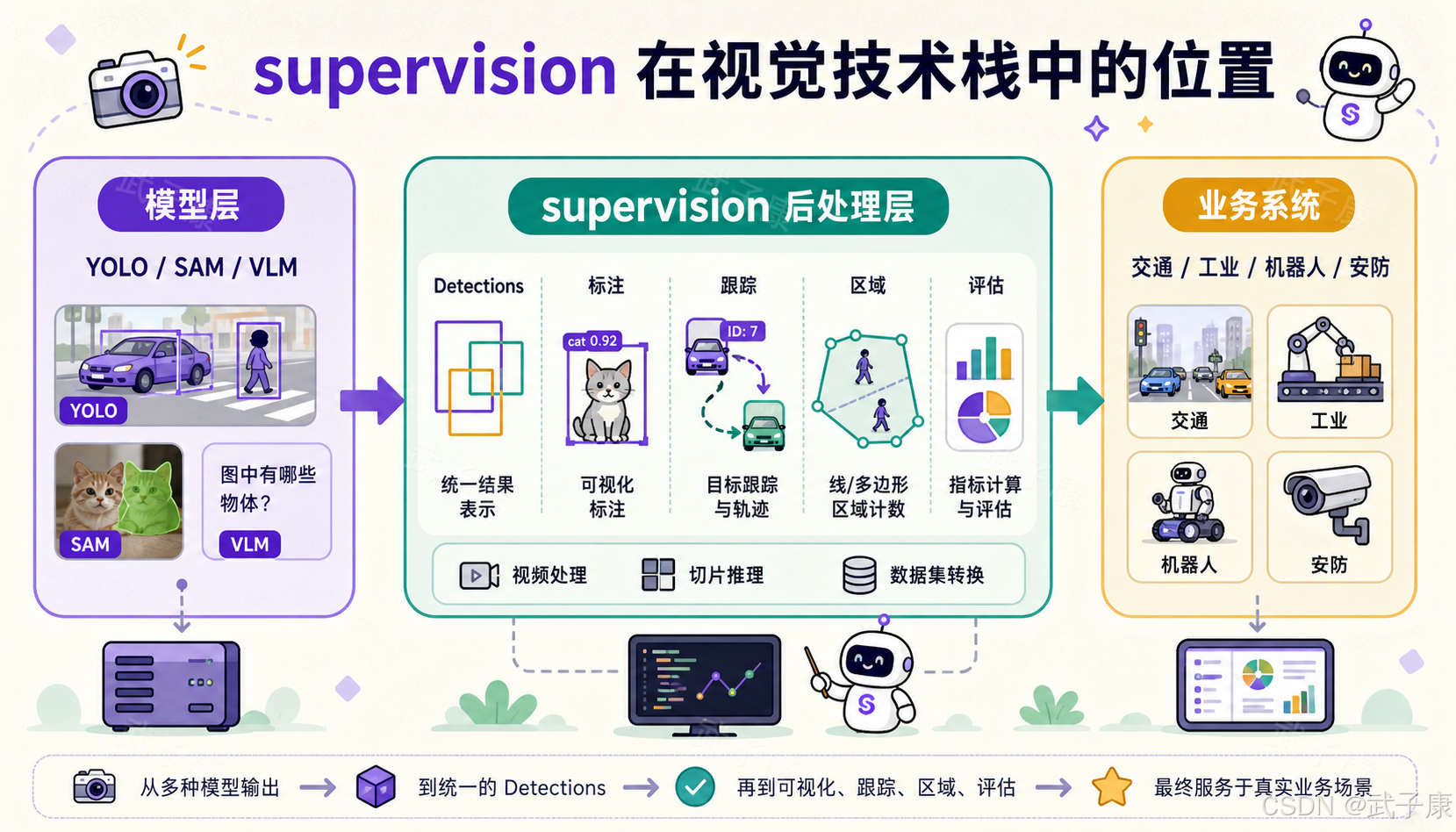
这也是它和模型库最大的区别。模型库关心"推理结果是什么",supervision 更关心"拿到结果之后怎么办"。
比如 Ultralytics 返回自己的 Results 对象,Transformers 返回张量和字典结构,SAM 返回 mask,VLM 可能返回文本或 JSON。如果一个项目里同时接入多个模型,业务代码很快会被各种输出格式绑死。
supervision 的做法是:先把不同模型输出转换成统一的 sv.Detections,后面的标注、过滤、统计、评估尽量只围绕这个统一对象写。
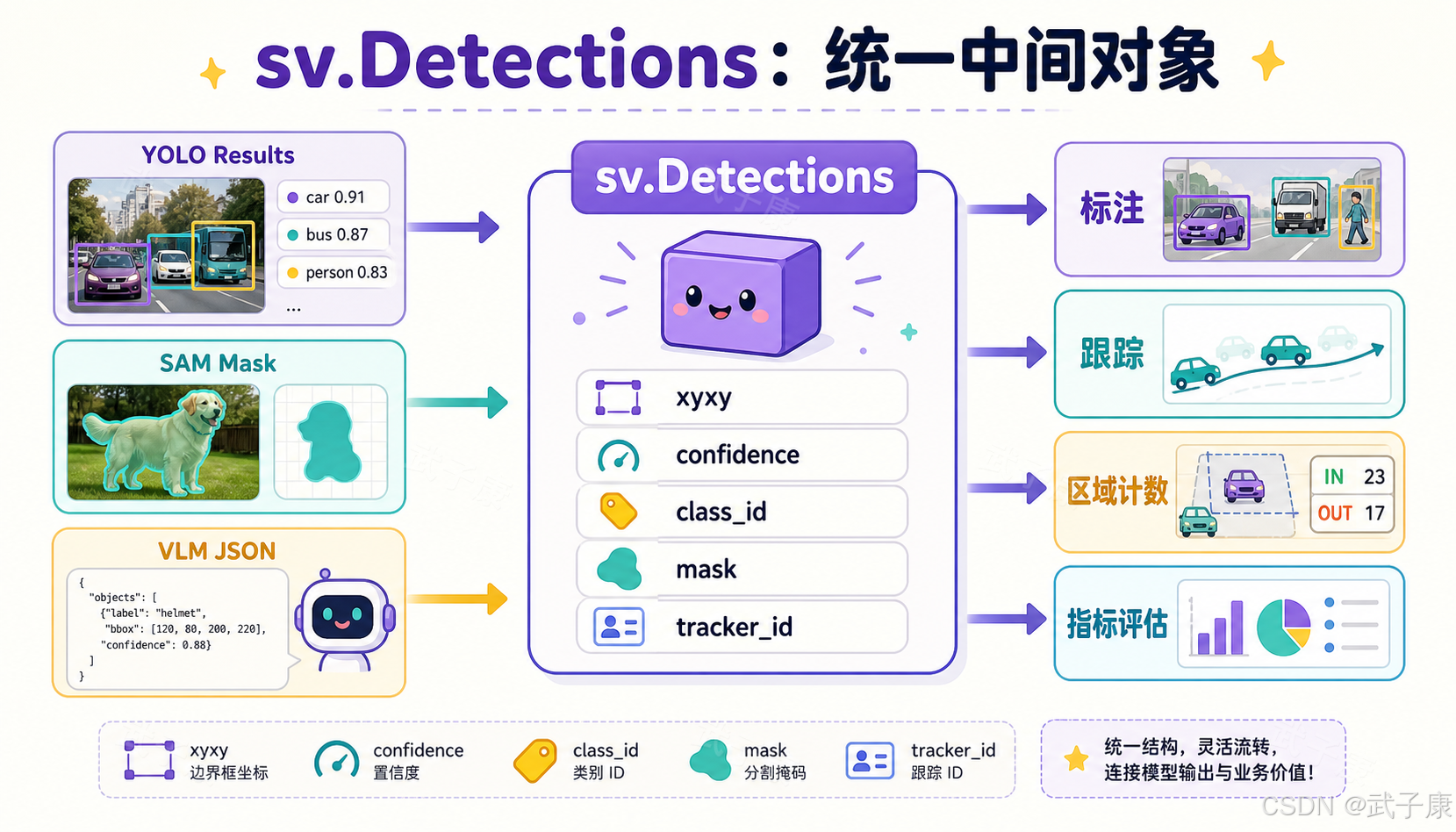
核心抽象:sv.Detections
sv.Detections 是 supervision 最重要的数据结构。它不是某个模型专属的结果对象,而是一个统一的检测/分割结果容器。
它通常承载这些信息:
xyxy:目标框坐标。confidence:置信度。class_id:类别 ID。tracker_id:跟踪 ID。mask:实例分割 mask。data:类别名、自定义字段、VLM 解析结果等扩展信息。
有了这个统一对象,后续代码就可以少关心模型来自哪里。
python
import cv2
import supervision as sv
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
image = cv2.imread("image.jpg")
result = model(image)[0]
detections = sv.Detections.from_ultralytics(result)
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated = image.copy()
annotated = box_annotator.annotate(scene=annotated, detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections)这段代码的重点不是"会画框",而是模型输出先变成 sv.Detections,标注器只处理 sv.Detections。以后如果从 YOLO 切到 Roboflow Inference、Transformers、Detectron2 或其他模型,只要能转换到 sv.Detections,下游逻辑就不必全部推倒。
这很像大模型应用里的统一 Message、Tool Call、Document 抽象。视觉应用也需要自己的中间表示,而 sv.Detections 就是在做这件事。
supervision 的主要能力模块
1. 模型输出转换
官方文档里,supervision 明确提供统一的 Detections 对象,并支持从 Ultralytics、Roboflow Inference、Transformers、SAM、Detectron2、MMDetection、YOLO-NAS、PaddleDet、NCNN、Azure AI Vision、VLM parsers 等来源转换结果。
这类能力非常实用。真实项目很少永远只用一个模型。今天用 YOLO 做检测,明天用 SAM 做分割,后天又想接入 VLM 做开放词表检测。如果每换一次模型,下游业务代码都要重写,工程会越来越乱。
supervision 把转换逻辑集中管理,让模型可以变化,下游处理尽量稳定。
2. 图像和视频标注
视觉项目里最常见的需求是可视化。检测模型输出一堆坐标,人是看不懂的。你需要画框、标签、置信度、mask、轨迹、关键点和区域。
很多人一开始会用 OpenCV 手写:
python
cv2.rectangle(...)
cv2.putText(...)手写当然可以,但需求一复杂就会变成样板代码:标签不要超出画面边界,同类目标要同色,不同 tracker_id 要不同色,mask 要半透明覆盖,轨迹要保留最近 N 帧,多行标签要排版,区域和计数线要叠加。
supervision 提供 BoxAnnotator、LabelAnnotator、MaskAnnotator、TraceAnnotator、PolygonZoneAnnotator、LineZoneAnnotator、KeyPointAnnotator 等一组标注器。它们的意义不只是"画得好看",更是调试效率。误检、漏检、跟踪 ID 跳变、区域判断错误,很多问题只有画出来才容易定位。
3. 视频处理和目标跟踪
图像检测是单帧问题,视频分析才更接近真实业务。视频里你要逐帧读取、推理、过滤、跟踪、标注,再写出新视频。
supervision 提供 process_video 这类工具,把视频处理变成 callback 风格:输入一帧,输出一帧。
python
import supervision as sv
def callback(frame, index):
result = model(frame)[0]
detections = sv.Detections.from_ultralytics(result)
annotated = box_annotator.annotate(scene=frame.copy(), detections=detections)
return annotated
sv.process_video(
source_path="input.mp4",
target_path="output.mp4",
callback=callback,
)目标跟踪则回答另一个问题:不同帧里的目标是不是同一个对象?
检测只能告诉你"这一帧有多少辆车",跟踪才能让你知道"这辆车是不是刚才那辆车"。只有有了稳定的 tracker_id,才能做车辆穿线计数、区域停留、轨迹分析和速度估计。
这里要特别注意版本变化:官方文档显示,ByteTrack 从 supervision 0.28.0 开始 deprecated,并计划在 0.30.0 移除;新代码应该关注独立的 trackers 包,使用 ByteTrackTracker 一类接口。这一点很适合写进项目依赖规范里,避免复制旧教程踩坑。
4. LineZone、PolygonZone 与区域计数
很多视觉业务并不是简单识别目标,而是回答更具体的问题:
- 有多少人进入了这个区域?
- 有多少车从左往右通过了这条线?
- 禁入区域里是否有人?
- 货架前有多少顾客停留?
- 机器人危险区域内是否出现行人?
这些属于区域逻辑。supervision 提供 LineZone 和 PolygonZone,可以和检测、跟踪结果组合,完成穿线计数和多边形区域判断。
如果自己手写这类逻辑,会遇到很多边界问题:目标框用哪个点判断?中心点、底部中心点还是角点?目标在边界上怎么算?抖动导致反复跨线怎么办?这些不是模型问题,而是应用逻辑问题。
supervision 把这类常见模式封装起来,工程价值很高。
5. InferenceSlicer:大图切片推理
在工业质检、遥感、航拍、医学影像和安防高分辨率图像中,经常会遇到大图和小目标问题。
一张 4K 或 8K 图片里可能有很小的缺陷、车辆、行人或零件瑕疵。直接缩放到模型输入尺寸,小目标会丢失。常见做法是把大图切成多个重叠 patch,分别推理,再把结果合并回原图坐标系。
这就是 tiled inference。supervision 的 InferenceSlicer 负责把这套流程工程化。它说明小目标检测不只是模型问题,也常常是输入策略问题。
6. 数据集转换和模型评估
计算机视觉项目的数据格式非常碎片化。YOLO、COCO、Pascal VOC、分类、检测、分割、自定义目录结构之间经常需要互转。
supervision 提供 DetectionDataset 等对象,用于加载、保存、合并、划分数据集。它也提供 mAP、mAR、Precision、Recall、F1、Confusion Matrix 等指标模块,适合做模型版本对比。
这些能力不一定"炫",但非常实用。很多团队训练了多个模型,却没有稳定的评估和可视化流程。把评估流程代码化,才更接近生产工程。
一个推荐的工程接入方式
如果我要在项目里引入 supervision,不会把它当成架构核心,而会放在"视觉后处理层"。
text
vision_app/
models/
detector.py
segmenter.py
adapters/
yolo_adapter.py
roboflow_adapter.py
vlm_adapter.py
pipeline/
detection_pipeline.py
tracking_pipeline.py
zone_pipeline.py
visualization/
annotators.py
evaluation/
metrics.py
services/
video_service.py
camera_service.py核心原则是:
- 模型层可以换。
- 推理服务可以换。
- 业务层不要直接依赖具体模型输出。
- 尽早把模型输出转换成
sv.Detections或项目自己的标准对象。 - 可视化、过滤、统计、评估都围绕标准对象处理。
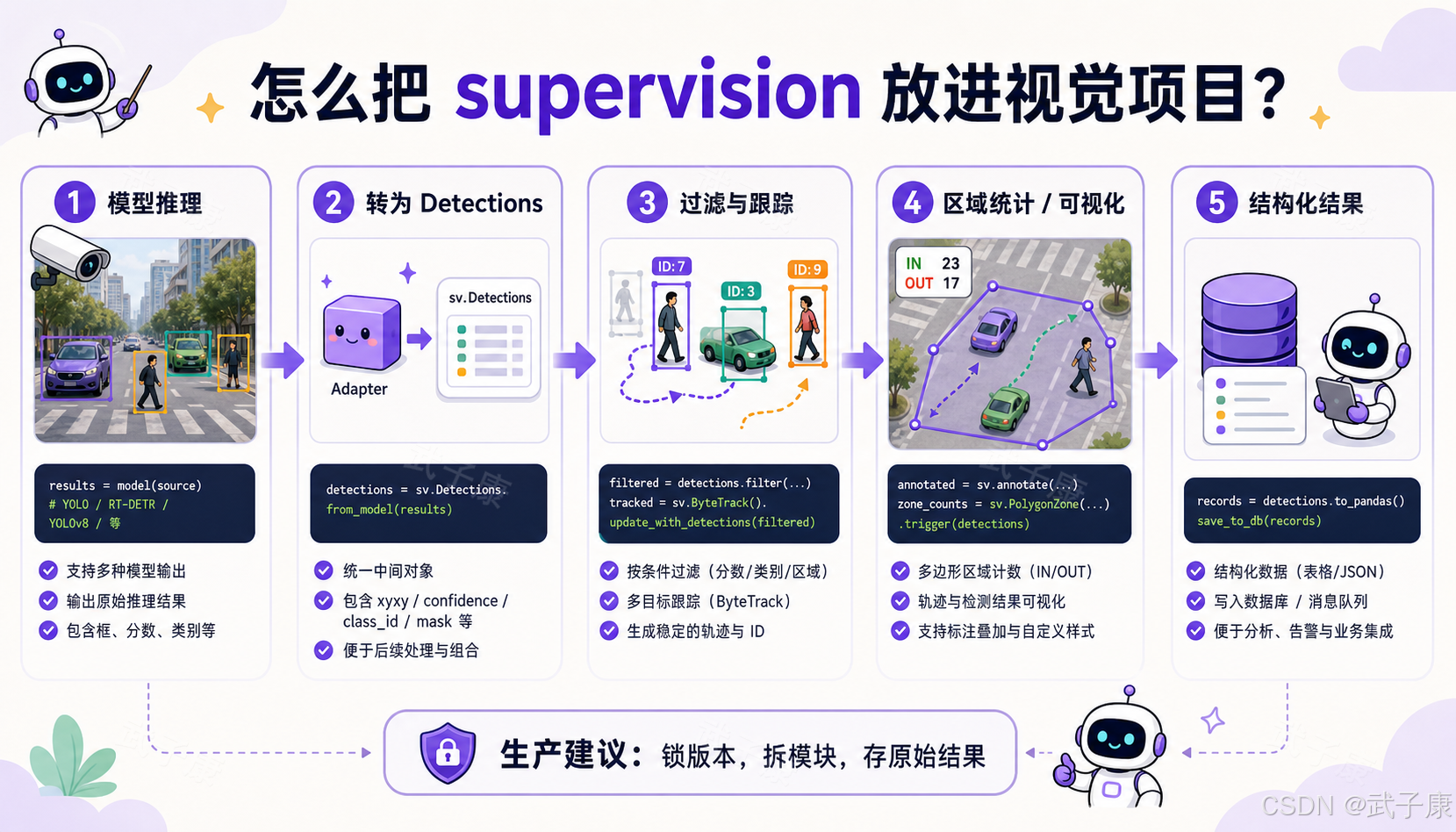
这样做的好处是,未来从 YOLO 换成 RF-DETR,从传统检测换成 VLM,系统不至于完全重写。
使用 supervision 的实践规范
第一,统一入口转换。所有模型输出进入系统后,第一时间转换为 sv.Detections 或项目标准对象。不要让 Ultralytics Results、Transformers dict、Roboflow Inference response 到处传。
第二,业务逻辑不要直接写在 callback 里。demo 可以这样写,生产项目应该把检测、过滤、跟踪、统计、标注拆成独立函数或类。
第三,保存原始结果和处理结果。调试时要能区分是模型问题、转换问题、过滤问题,还是跟踪/区域判断问题。
第四,锁定版本。生产项目不要长期裸装 pip install supervision,而应该固定版本,升级前跑回归测试。
第五,关注 tracker 迁移。新代码不要过度依赖即将移除的旧 sv.ByteTrack API。
第六,视频处理要关注时间戳。停留时长、速度估计、事件持续时间不能只靠帧数粗略判断。
第七,不要把标注视频当成最终结果。标注视频适合调试和展示,业务结果应该结构化保存为 JSON、数据库记录或事件日志。
supervision 不适合什么?
supervision 不是训练框架。如果你的核心问题是改网络结构、调 loss、做分布式训练,它不是主角。
它也不是高性能推理引擎。TensorRT、ONNX Runtime、OpenVINO、NCNN、CUDA kernel 优化不是它负责的。
它更不是完整业务平台。用户管理、权限、数据库、告警、任务调度、设备管理、边缘节点运维,都需要你自己的系统来做。
所以更准确的定位是:supervision 是视觉应用工程库,不是视觉系统的全部。
最终判断:视觉应用正在从"模型中心"走向"管线中心"
过去几年,大家关注最多的是模型:YOLO 更快,SAM 出现,DETR 改进,VLM 能看图,开放词表检测更强。
但真正落地时,模型只是系统的一部分。模型越多,输出格式越多,应用管线越复杂。如果团队没有稳定的中间层和工具层,就会被模型生态拖着走。
supervision 的价值在于,它站在"管线中心"的位置。
它不和模型竞争,而是接住模型输出。它不承诺训练最强模型,而是让你更容易把模型变成应用。它关注的是视觉系统中长期存在的问题:结果表示、可视化、视频处理、跟踪、区域、数据集和评估。
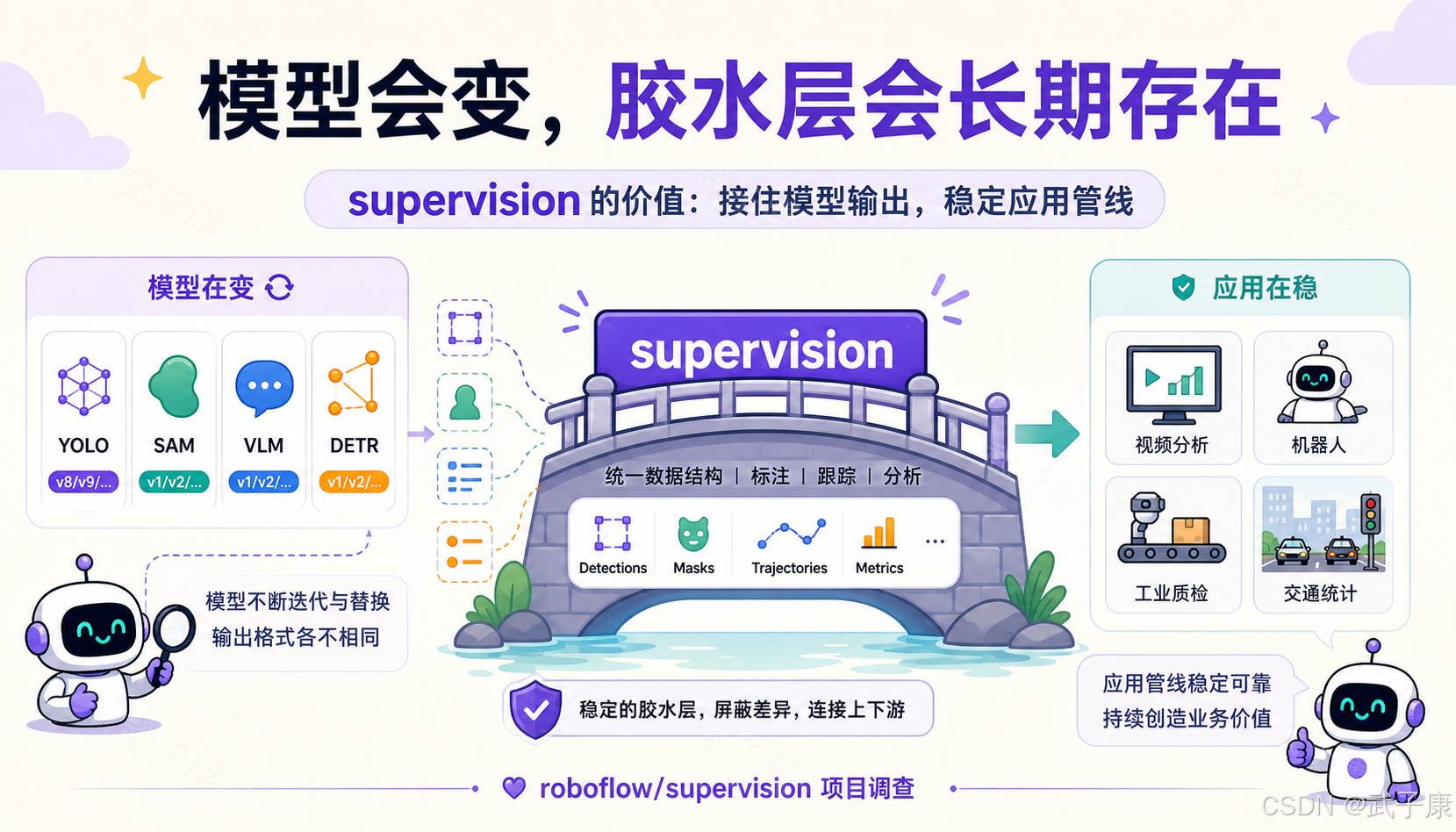
如果你正在做计算机视觉应用,尤其是已经有模型,但卡在后处理、可视化、视频、跟踪、区域统计、数据集格式和评估流程上,supervision 值得引入。
如果你只是研究模型结构,它不是主角。
我的判断是:roboflow/supervision 的长期价值不在于某个单点 API,而在于它提供了一套"视觉工程胶水层"的标准写法。未来视觉模型会继续变化,但模型输出到业务应用之间永远需要这样一层工具。这个位置很稳,也很有工程生命力。
SEO 摘要(约 250 字)
roboflow/supervision 是 2026 年计算机视觉工程领域持续受到关注的 Python 工具库,最新稳定版本为 0.28.0(2026-04 发布)。它不是模型训练框架,也不参与网络结构设计,而是定位于"模型到应用"之间的工程胶水层。核心抽象 sv.Detections 把 Ultralytics YOLO、Transformers、SAM、Roboflow Inference、Detectron2、MMDetection、VLM 等异构模型的输出统一成同一对象,使可视化、过滤、跟踪、区域计数、视频处理、数据集转换与模型评估可以围绕这一统一表示进行。配套模块覆盖 BoxAnnotator / MaskAnnotator / TraceAnnotator 等标注器、LineZone / PolygonZone 区域与计数工具、InferenceSlicer 大图切片推理、DetectionDataset 与 mAP/Confusion Matrix 等评估组件。2026 年值得注意的版本变化:ByteTrack 自 0.28.0 起 deprecated,并计划在 0.30.0 移除,新项目应迁移到独立 trackers 包。对正在搭建工业质检、交通分析、机器人视觉或安防系统的工程师,supervision 能显著降低模型输出到业务落地之间的重复劳动。
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
sv.Detections 统一数据抽象 |
✅ 已验证 | 官方文档明确提供,作为 supervision 核心对象贯穿全库 |
| 多模型输出转换(Ultralytics / Transformers / SAM / Roboflow Inference / Detectron2 / MMDetection / YOLO-NAS / PaddleDet / NCNN / Azure / VLM) | ✅ 已验证 | 官方支持矩阵覆盖上述来源 |
| Annotator 套件(Box / Label / Mask / Trace / PolygonZone / LineZone / KeyPoint) | ✅ 已验证 | 官方 Annotators 文档列出全部模块 |
process_video 视频流式处理 |
✅ 已验证 | 文档示例演示 callback 风格逐帧处理 |
LineZone / PolygonZone 区域与计数 |
✅ 已验证 | 用于穿线、区域进出判断、停留时长等 |
InferenceSlicer 大图切片推理 |
✅ 已验证 | Issue #368 后已扩展支持分割模型 |
DetectionDataset 与 mAP / Confusion Matrix 评估 |
✅ 已验证 | 官方文档提供数据格式互转与指标模块 |
sv.ByteTrack 旧接口 |
⚠️ 计划移除 | 0.28.0 起 deprecated,预计 0.30.0 移除;新代码请迁移到独立 trackers 包 |
| 训练框架 / 网络结构 / Loss 设计 | ❌ 不适用 | supervision 不替代 PyTorch、Ultralytics 等训练栈 |
| 高性能推理引擎(TensorRT / ONNX / OpenVINO) | ❌ 不适用 | 推理优化不在 supervision 职责范围 |
| 完整业务平台(用户/权限/任务调度/边缘运维) | ❌ 不适用 | 需自建上层系统 |
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
from supervision import ... 报 PackageNotFoundError: supervision |
本地以源码方式运行但 __init__.py 读取不到版本元数据 |
在 supervision 仓库目录执行 pip install -e . 后再 import |
改用可编辑安装:pip install -e .,或在 __init__.py 中读取版本失败时回退到默认值 |
OpenCV cv2.imshow 报错 The function is not implemented |
opencv-python 缺 GUI 后端(Windows/Linux 常见),且 supervision 示例默认用 imshow | 检查终端是否在无 GUI 环境(容器、SSH、WSL 无 X) | 用 opencv-python-headless 替代,或改用 sv.process_video 直接写视频文件 |
| 换模型后画框代码大面积报错 | 业务代码直接依赖了 Ultralytics Results / Transformers dict / Roboflow Inference response 等私有结构 |
grep 项目里 from ultralytics from transformers from inference_sdk 等是否渗入业务层 |
在 adapter 层统一转换为 sv.Detections,业务层只依赖 sv |
tracker_id 频繁跳变、同一目标在不同帧 ID 不一致 |
跟踪器选择不当、检测置信度过低、目标框抖动或旧 sv.ByteTrack 接口已 deprecated |
打印 detections.tracker_id 看帧间稳定性;检查 supervision 版本是否 ≥ 0.28.0 |
升级后迁移到独立 trackers 包的 ByteTrackTracker 等新接口,并设置合理的 minimum_consecutive_frames |
| LineZone 计数反复加一,目标在线附近抖动 | 判定点选择不合理(用中心点而非底部中心点)或缺少最小位移阈值 | 在 callback 里打印检测框底部点坐标,观察是否反复穿越 | 切换为底部中心点 + 设置 minimum_crossing_distance 抑制抖动 |
| 大图小目标几乎全部漏检 | 直接把 4K/8K 图像 resize 到 640×640,小目标被抹掉 | 看原图与推理输入尺寸差异;统计 recall 是否随分辨率下降 | 改用 sv.InferenceSlicer 做 tiled inference,分块推理后合并回原图坐标 |
| 不同模型切换后 mAP 数值无法对齐 | 评估时各模型输出未统一为同一 Detections,IoU 阈值和类别映射不一致 |
比对各模型转换路径与 class_id 映射表 |
全部经过 sv.Detections.from_* 后用 sv.DetectionDataset + 统一 metric 模块评估 |
pip install supervision 后依赖冲突导致训练代码崩 |
supervision 把 OpenCV、NumPy 等版本约束带进项目 | 跑 pip check 看冲突包 |
supervision 与训练环境分开建虚拟环境,或固定 supervision==x.y.z 后跑回归 |
| 写出的可视化视频体积巨大或帧率异常 | sv.process_video 默认按源视频参数编码,部分编码器在容器中不可用 |
用 ffprobe 检查输出文件编码 |
显式传入 target_path 时加自定义 ffmpeg 参数,或换用 imageio[ffmpeg] |
| 区域停留/速度估计误差极大 | 仅用帧数估算时间,未读取视频帧时间戳 | 看代码里是否出现 index / fps 这类粗略换算 |
在 process_video callback 中读取帧时间戳,统一换算成秒再写入事件日志 |
| 把标注视频当作最终交付结果 | 标注视频只适合调试,业务结果未结构化 | 检查输出目录是否有 .json / 数据库表 / 事件流 |
业务结果写 JSON / DB,标注视频仅留作可视化调试产物 |
参考来源
- Roboflow Supervision 官方文档:https://supervision.roboflow.com/
- Supervision Annotators 文档:https://supervision.roboflow.com/develop/detection/annotators/
- Supervision ByteTrack / Trackers 文档:https://supervision.roboflow.com/develop/trackers/
- Roboflow Trackers 文档:https://trackers.roboflow.com/latest/learn/about/
- supervision 0.28.0 发布记录:https://sourceforge.net/projects/supervision.mirror/files/0.28.0/
- supervision 0.27.0.post2 发布记录:https://sourceforge.net/projects/supervision.mirror/files/0.27.0.post2/
作者:武子康的个人博客