高阶智驾SoC晶圆设计采用八大核心功能分区架构:NPU算力核心区(35%-45%)专注矩阵运算与DSA加速;NoC与片内缓存区(20%-25%)实现TB/s级数据调度;CPU集群(15%-20%)处理OS与规控逻辑;硬件安全岛(5%-8%)确保ASILD级功能安全;ISP阵列(5%-10%)优化图像信号处理;I/O控制区(5%)集成硬件DMA;显存接口(5%-8%)保障高带宽访存;片间级联区(3%-5%)支持多芯片协同。该架构通过硬件级优化实现算法加速、数据零拷贝和安全隔离,满足智能驾驶对大算力与高可靠性的双重需求。
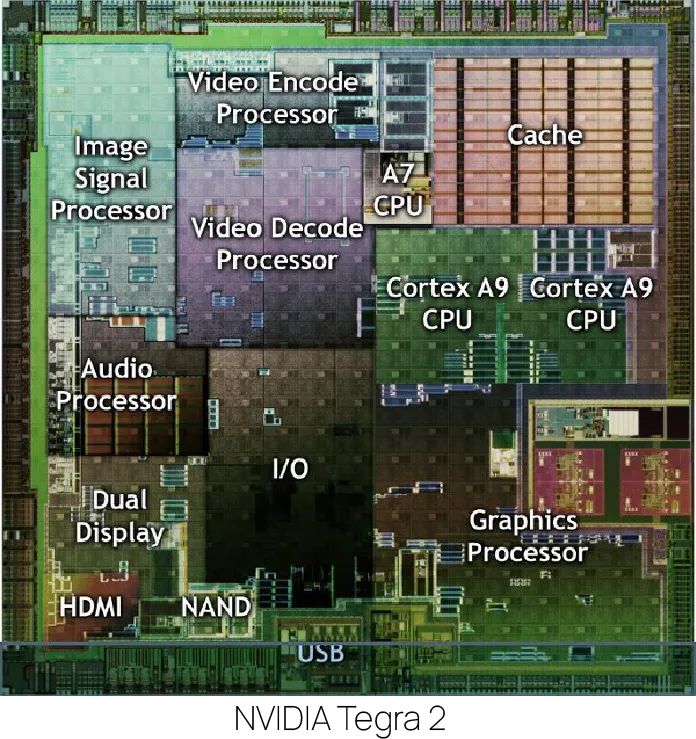
在高阶智驾 SoC(如 NVIDIA THOR、Tesla AI 5、小鹏图灵)的晶圆设计版图(Die Layout)中,为了满足端到端大模型高维概率吞吐 与车规级安全铁闸 的冲突需求,整块硅片(Silicon Die)被极其严密地划分为以下八大核心硬核功能分区(IP Block Clusters)。
理解这八大版图块的电荷流向,是系统首席架构师反向定义硬件的基石:
1. NPU 算力核心区:DSA 特定领域架构加速仓(AI Execution Core)
这是版图上面积最大的主战场,是专门处理 Attention(自注意力)矩阵乘法、时空体素(Occupancy)和向量/张量计算的硬件马达。
-
微架构组成 :通常由巨大的 Tensor Core 阵列、脉动阵列(Systolic Array)、以及针对大模型微码化固化的专用硬件计算单元(如 Tesla 的 Vector/Matrix Engine)组成。
-
软硬对账流向:数据流进场后,NPU 内部的控制器执行零气泡的流水线排布,把数据直接焊死在晶圆电路上,榨干每一颗晶体管的 MAC(乘加单元)利用率。
2. 片上网络与中央静态缓存区:NoC 与 巨量片内 SRAM 纵深(NoC & Large On-chip SRAM)
这是版图上的"骨干交通枢纽"与"物理粮仓"。
-
微架构组成 :包括高密度的网格拓扑片上网络(Mesh NoC Router)以及极度奢侈的、占据巨大晶圆面积的 SRAM 静态缓存池(地平线 J6 和自研片阵营的标志设计)。
-
软硬对账流向 :NoC 负责在不同核心(CPU/NPU)之间提供 TB/s(兆字节每秒)级 的微观吞吐带宽。超大片内 SRAM 充当高速暂存池,数据在晶圆内部直接对账,阻断电荷跨越引脚去片外显存换页造成的换页死锁(Cache Miss)。
3. CPU 核心集群区:通用标量算力仓(General Purpose CPU Cluster)
负责运行车载 Hypervisor、Linux/QNX 操作系统、以及复杂的车辆状态机和规控逻辑分支。
-
微架构组成 :行业老钱(英伟达、高通等)通常部署高能效的 ARM Neoverse V2 或自研 Oryon/鲲鹏 CPU 架构核心簇(包含 L1/L2 独立缓存和 L3 共享缓存)。
-
软硬对账流向 :当规控算法出现大量
if-else的非线性逻辑跳转时,NPU 无法处理,必须由 CPU 进行高频标量解算与中断仲裁。
4. 硬件安全岛:ASIL D 锁步监控仓(Safety Island / Safety Core)
这是 SoC 内部独立于大模型算力热仓的"铁血保底密室"。
-
微架构组成 :由多核硬件锁步(Lock-Step)的 ARM Cortex-R52 或 Cortex-M7 核心、以及独立的系统看门狗(Watchdog Timer)组成。
-
软硬对账流向:安全岛拥有独立的电源轨和时钟源。通过 NoC 内部的硬件防火墙(Memory Protection Unit, MPU)执行总线染色。一旦 NPU 仓的大模型突发 Panic,安全岛会在晶圆级一拍闭闸挂起 vCPU,强制熔断,剥离主权。
5. 高性能视频/图像处理区:自研硬核 ISP 阵列(Advanced Image Signal Processor)
负责将多路高像素周视相机的模拟视讯,在前级物理门口洗刷为干净的数字特征。
-
微架构组成:包含像素级高动态范围(HDR)硬件对账电路、全局快门(Global Shutter)像素对齐硬件、以及多路复用器(MUX)。
-
软硬对账流向:前级原始 Raw 图砸进引脚后,硬核 ISP 在微秒门口直接执行去噪、光子校正,擦除夜间强光眩光与多径鬼影(对应蔚来神玑的优势),让喂给后级大模型隐空间(Latent Space)的数据极其纯净。
6. 外设 I/O 接口控制区:数字引脚大门口(Peripherals & High-Speed Interfaces)
SoC 晶圆与外部世界进行物理连接的边界管脚。
-
微架构组成 :包括 MIPI CSI-2 数字控制器、PCIe Gen5/Gen6 物理层控制器、以及高速以太网 MAC 层控制器。
-
软硬对账流向 :数据由此进场。以小鹏图灵为例,在 MIPI 控制器门口焊死了硬件级 DMA(直接内存访问)通道,片外 A-PHY 解串芯片翻译好的数字像素一过引脚,直接由硬件 DMA 直灌 SRAM 共享显存指针,在晶圆大门口彻底斩断底软解包和 CPU 搬运时延。
7. 高带宽显存接口区:LPDDR5X / HBM 控制器物理层(DRAM PHY / Memory Controller)
芯片与外部物理显存颗粒(DRAM)疯狂对账的唯一电荷通道。
-
微架构组成 :由极为密集的 LPDDR5X PHY(物理层电路)或 HBM(高带宽显存)控制器 组成,通常呈环状布设在晶圆的最边缘。
-
软硬对账流向:大模型自回归序列推演时,需要在此处吞吐海量的权重 Tokens。此区域的布线密度直接决定了芯片的物理访存带宽红线(数百 GB/s 至 TB/s)。
8. 片间高速级联硬核:Chiplet 互联矩阵(Chiplet Interconnect / Fabric)
大芯片放弃"单片神话"、走向大兵团级联的物理法兰。
-
微架构组成 :如 NVIDIA 的 NVLink-C2C 控制器接口,或者华为的 HCCS 级联硬核。
-
软硬对账流向 :两颗晶圆在主板上并联时,编译器在最底层执行矩阵跨片垂直切片,计算完半个表格后,通过该区域在 1 毫秒内执行算子级 All-Reduce 瞬态合并,分担单片 50% 的发热与热斑风险。
📊 2026 高阶智驾 SoC 晶圆版图核心分区及电荷流向总账
| 版图功能分区 | 占据晶圆面积权重 | 核心硬核 IP 逻辑职责 | 面试/技术汇报对账话术(首席系统架构师视角) |
|---|---|---|---|
| 1. NPU 算力核心区 | 35% ~ 45% (最大) | 负责 Attention 矩阵乘法与 DSA 神经网络算子级流水线加速。 | "我们不迷信标称 TOPS,我们看的是通过算法硬件化将 NPU 算子榨干率卡死在 ≥ 88%。" |
| 2. NoC 与片内缓存区 | 20% ~ 25% | TB/s 级片上网络调度,通过巨量片内 SRAM 掐死跨引脚访存延迟。 | "利用前级流控微架构,数据在晶圆 SRAM 内部高频对账,彻底断绝显存换页死锁(Cache Miss)。" |
| 3. CPU 核心集群区 | 15% ~ 20% | 运行 Hypervisor、高刚性 OS、规控标量算法分支与状态机。 | "采用大集群高能效 CPU 核,专门负责大模型无法解算的非线性逻辑跳转与一类中断仲裁。" |
| 4. 硬件安全岛防区 | 5% ~ 8% | 独立电源轨的多核锁步 ASIL D 核心,全时死守功能安全底线。 | "利用 NoC MPU 防火墙进行物理总线染色,Android 哪怕卡死也绝对无法抢占规控内存带宽。" |
| 5. 高性能 ISP 阵列 | 5% ~ 10% | 前级图像信号物理清洗,洗净夜间眩光与多径多回波鬼影。 | "像素进场在微秒门口执行非线性光子校正,净化前级特征,从源头上抹除大模型概率幻觉。" |
| 6. 外设 I/O 控制区 | 5% | MIPI CSI-2、PCIe Gen5 控制器,集成硬件级 DMA 零拷贝流控。 | "引脚原生对接板级片外 A-PHY 解串芯片,硬件 DMA 直灌显存指针,晶圆门口斩断底软解包时延。" |
| 7. 显存接口物理层 | 5% ~ 8% (边缘) | LPDDR5X PHY / HBM 内存控制器,死卡芯片物理访存带宽红线。 | "环状布设在晶圆最边缘,高频吞吐自回归大模型权重 Tokens,决定了芯片的动态电流抽吸上限。" |
| 8. 片间高速级联区 | 3% ~ 5% | NVLink-C2C / HCCS 硬核,执行跨芯片级联的物理法兰。 | "软件底层执行矩阵垂直切片,通过级联硬核执行算子级 All-Reduce 合并,将单片热斑风险压减 50%。" |