前言
去年九月份,Virtual Cell Challenge开展之后,虚拟细胞(扰动预测)开始在生信领域火了
所以看了看相关的文章
基本信息
论文名:CellFlow enables generative single-cell phenotype modeling with flow matching
代码:theislab/CellFlow: Modeling complex perturbations with CellFlow
发表时间:2025.4.17
前作cellFlow发表在ICLR2024上,但CellFlow似乎只挂在了biorxiv上。
数据类型:scRNA-seq,细胞×基因的表达量矩阵
数据集:
Parse 10 Million PBMC(人外周血单核细胞)
ZSCAPE(斑马鱼胚胎)
sciPlex3(癌细胞系A549、MCF7、K562)
combosplicer(A549)
基因过表达数据(biolord论文,K562)
基因敲除+细胞因子刺激(6种癌细胞系)
4i数据集(黑色素瘤细胞系)
iNeuron(iPSC分化神经元)
类器官(脑神经元)
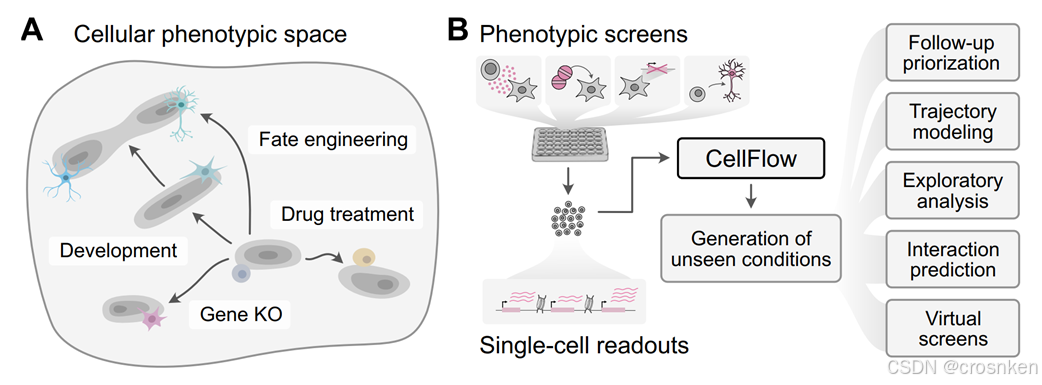
任务:基因表达量预测
1、细胞因子响应预测
2、基因敲除响应预测
3、药物组合/形态因子组合扰动响应预测,
4、类器官迁移
5、虚拟筛选
数据预处理:HVGs分析+PCA降维,获得细胞特征
模型结构
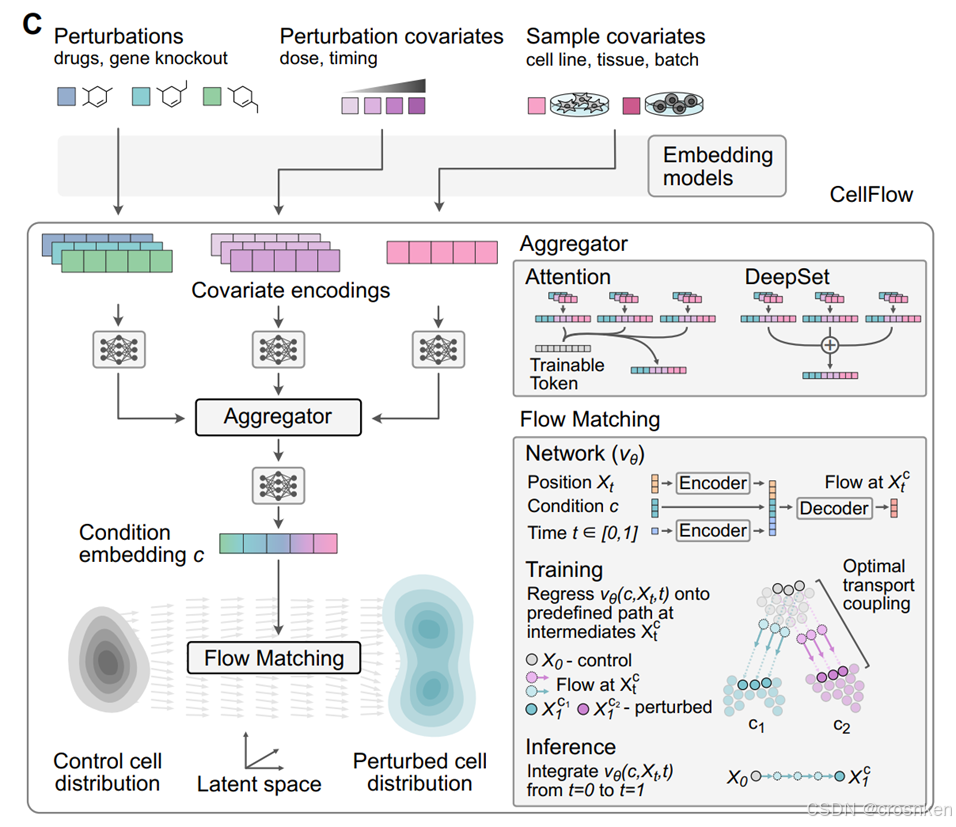
1、嵌入层:
扰动变量:
药物采用摩根指纹嵌入
基因、细胞因子采用对应蛋白质的ESM2嵌入
扰动协变量:剂量、时间
样本协变量:细胞系类型、来源组织、批次效应
采用多头注意力或者deepset进行聚合,然后通过一层MLP输出条件嵌入c
2、训练样本采样
先随机采样条件,获得条件嵌入c
再从符合该条件的数据集中采样对照组细胞和扰动细胞
采用Sinkhorn计算最优传输
设𝜋_𝑂𝑇是最优传输矩阵,将OT问题中的熵写为KL散度的形式,并且可以将问题改写为不平衡的形式
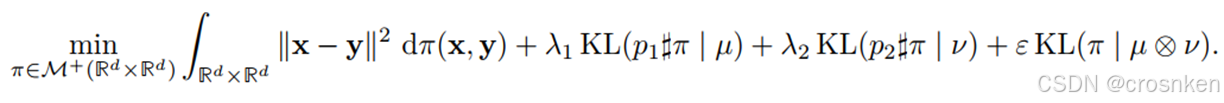
(KL散度和𝜋_𝑂𝑇熵的关系, ♯前推操作,只从某一维看分布)
这里的价值矩阵采用𝐶_𝑖𝑗=‖𝑥_𝑖−𝑦_𝑗 ‖^2,其中𝑥_𝑖来自对照组细胞特征, 𝑦_𝑗来自扰动后的细胞特征。
对每一个对照细胞,以𝜋_𝑂𝑇对应行作为权重进行采样,获得目标的扰动细胞,构成训练集中的一个匹配对。
值得注意的是:这里的迭代形式所使用的分布,是以数据集中一类细胞的特征的狄拉克函数来构建的,也就是有数据的地方,是一个质点(概率密度极大)。这样方便离散计算。但如果考虑系统误差或者偶然误差,这些点只是我们的观测值,实际值在周围也会形成一个小的分布。这样做的话需要重新计算传输代价矩阵,并且重新推导迭代公式,特别是后续KL散度的计算将会更加复杂。
3、Flow Matching训练目标
一般的Flow Matching模型训练目标:
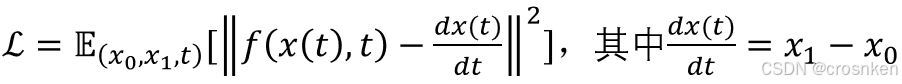
CellFlow模型的训练目标(这里只以平衡最优传输为例(不平衡的情况只是换了一个采样分布))
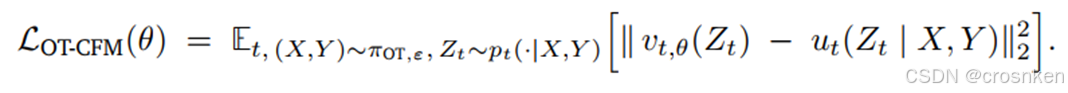
其中𝑣_(𝑡,𝜃)为模型, 𝑍_𝑡为𝑋到𝑌的轨迹上进度为t的点,其中:
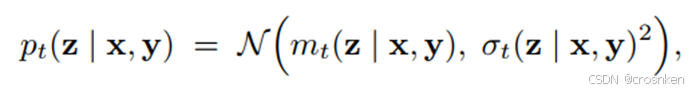
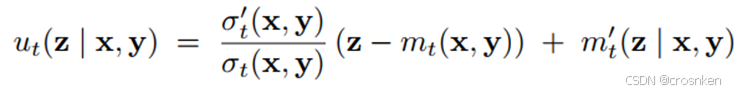
根据选择的噪声形式不同,采用不同的参考速度ut:(第二种噪声(Brownian bridge)推导到参考轨迹的方法在此不展开)。其中m_t(x,y)=t*x+(1-t)*y,
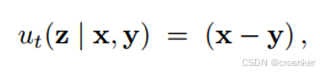
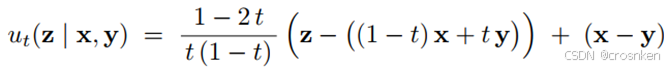
4、推理过程
输入正常情况细胞,采用相同的HVGs与PCA主成分计算细胞特征,多模态融合,计算扰动特征
利用训练好的𝑣_(𝑡,𝜃)模型,计算细胞特征的速度向量
多轮迭代,利用数值积分计算细胞轨迹
没什么好说的,符合直觉。
实验结果
细胞因子响应预测
Parse 10 Million数据集 12个供体,90个细胞因子(扰动)
Identity:直接使用对照组表达值;Mean donor2cytokine:取该供体对细胞因子平均响应
Mean cytokine2donor:取细胞因子在各个供体中的平均响应
评价指标:

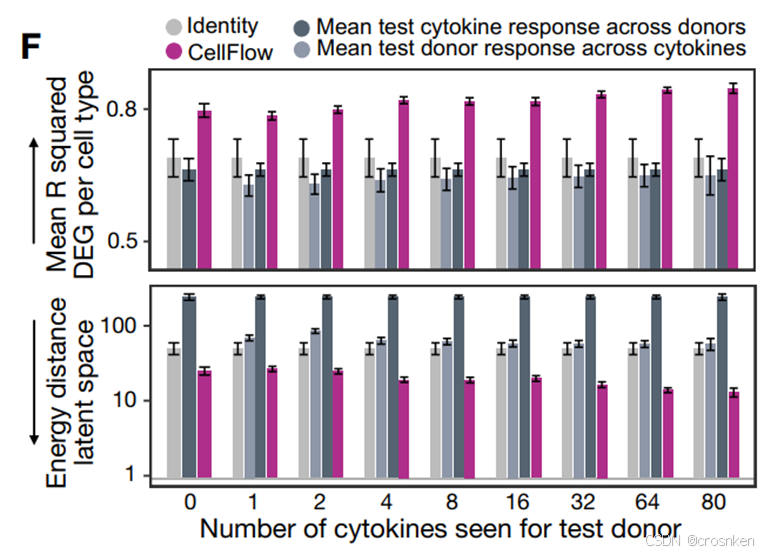
这里比较的baseline都是比较简单的做法。不过可以发现模型也呈现了一定的scaling law的规律
斑马鱼胚胎基因敲除预测、胚胎分化时序预测
数据集:ZSCAPE7(扰动胚胎,包含细胞类型的聚类标注)
评价指标:能量距离、细胞类型比例变化的Pearson相关系数
用CellFlow预测表达量+加权KNN分类预测细胞类型
耗竭率:1-对照组细胞特征的邻域中扰动组细胞的占比
KO:敲除基因的组合,abundance:某细胞类型的丰度,hpf:受精后时间
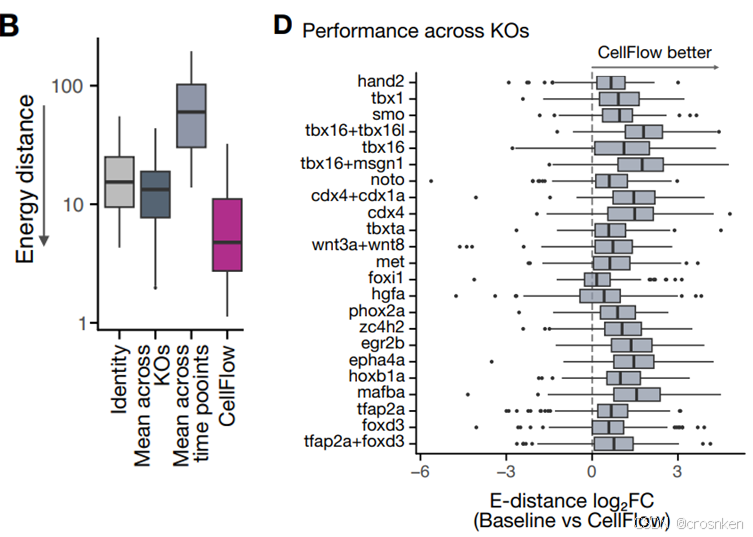
图D纵轴是被敲除的基因组合名称,横轴是Baseline到CellFlow的能量距离的log2FoldChange
可以看到均值基本在1~1.5左右,Baseline的能量距离是CellFlow的两倍~三倍左右
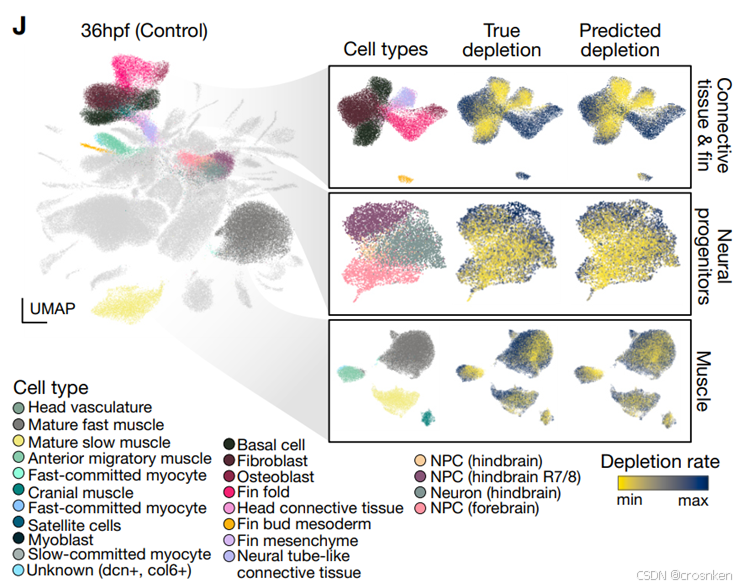
J是对细胞类型预测的UMAP分析,WKNN预测细胞类型,在计算KNN的时候顺便可以计算对照细胞的depletion rate,可以看到,耗竭率和实际情况基本上是大差不差的,除了第三张图可能预测的耗竭率偏低。
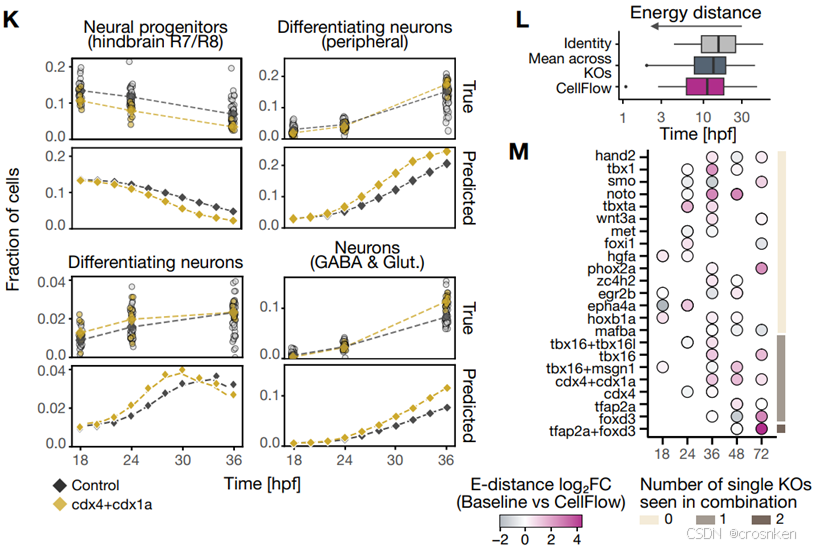
接下来K图研究的是在cdx4+cdx1a敲除情况下斑马鱼胚胎发育过程中的某细胞占比的变化趋势,可以看到预测出来的趋势是对的,拟合程度也不错。
不过看M图,可以发现,其实在某些组合下的时序预测效果也一般,K图挑出来的几个都是红色的,所以效果看起来挺好。
药物扰动预测、癌细胞基因过表达预测
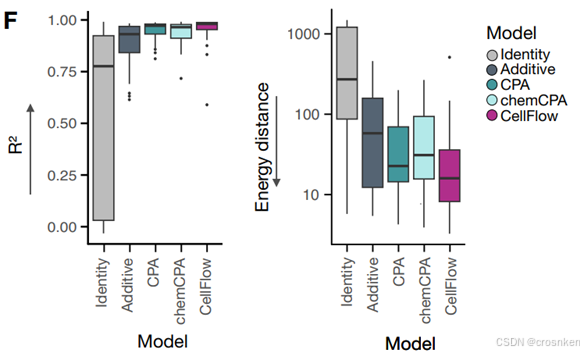
在A549癌细胞系下进行实验,对比模型有CondOT、chemCPA、biolord
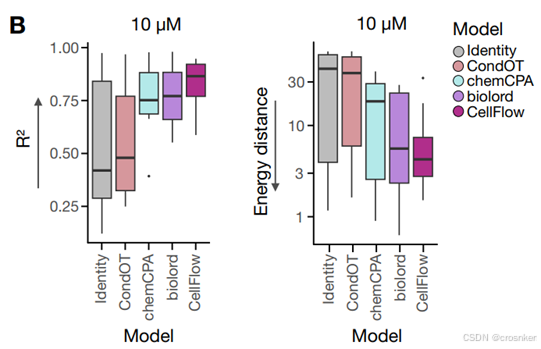
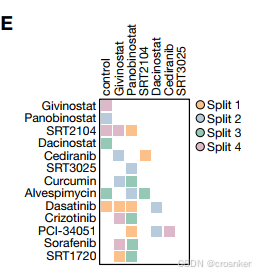
图E是数据集集的划分情况,药物组合图
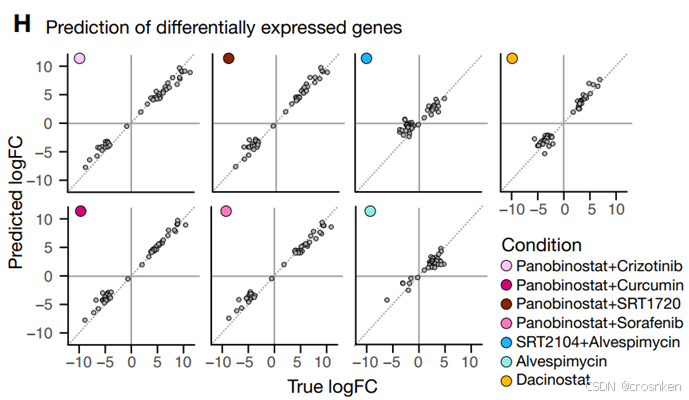
图H是不同药物组合中,预测与真实值的log2FC图
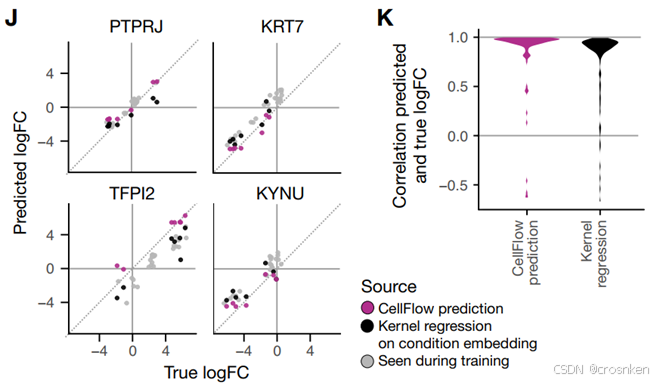
图J是对肺癌抑制基因进行治疗后的预测结果,baseline是对CellFlow嵌入用线性层预测。
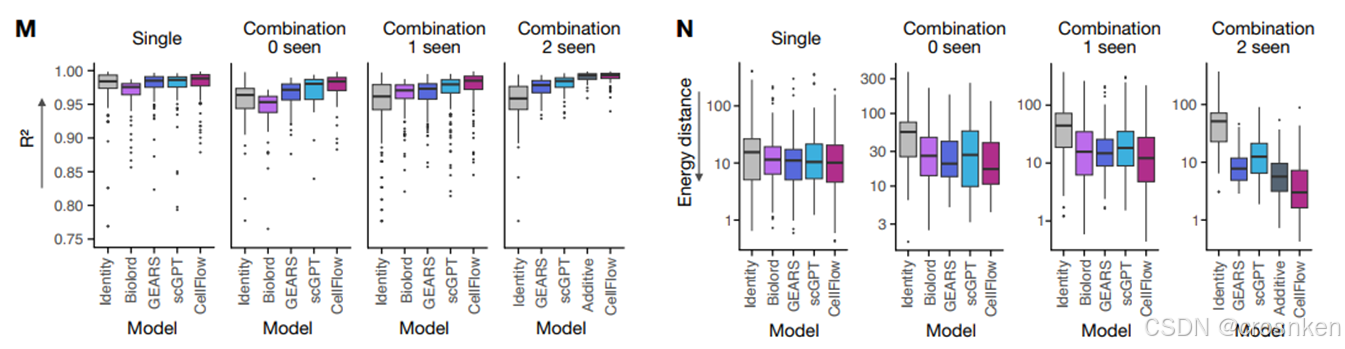
图M、N是对组合基因过表达的zero-shot和few-shot能力测试,可以看出来,CellFlow的能力还是不错的
论文认为这部分的泛化能力来自于ESM2对基因特征提取。
神经元命运工程
问题:如何通过多种形态因子的组合,诱导iPSC向特定亚型的神经元分化。
iNeuron数据集:先对iPSC诱导NGN2(神经元分化的转录因子)表达,然后加各种形态因子的组合,然后测scRNA-seq
三种神经元类型:兴奋、抑制、去甲肾上腺素能。脑区标记。
任务:预测未见形态因子组合下的细胞类型分布。
指标:余弦相似度、能量距离
对比模型有CPA、biolord
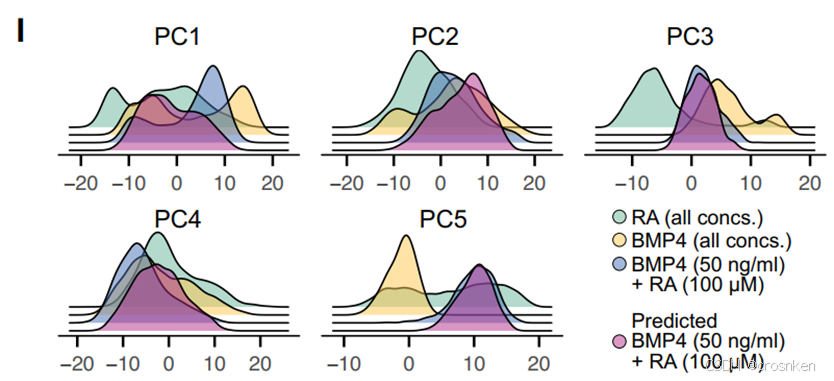
图I是对细胞特征进行PCA降维后的5个维度分别绘制组合形态因子诱导下的分布。
类器官协议筛选
类器官:利用干细胞的自组织能力,通过信号分子、环境诱导干细胞向某一个特定的器官分化。
协议:指一组特定浓度的信号分子、形态因子、环境等因素的组合。
模型任务:通过已知的类器官协议数据,来预测未测试的协议。
数据集:三个已知的人脑类器官数据集,23中形态因子、176个条件。
预处理:先用scANVI将三个数据集的细胞特征投影到同一个空间。
训练集:只使用单形态因子的数据。
评价指标:能量距离、余弦相似度。
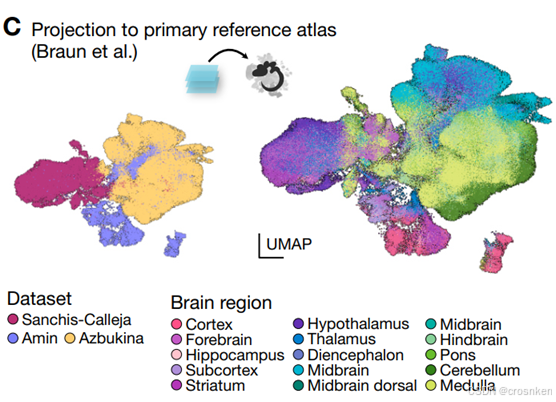
图C是数据集整合后的UMAP图
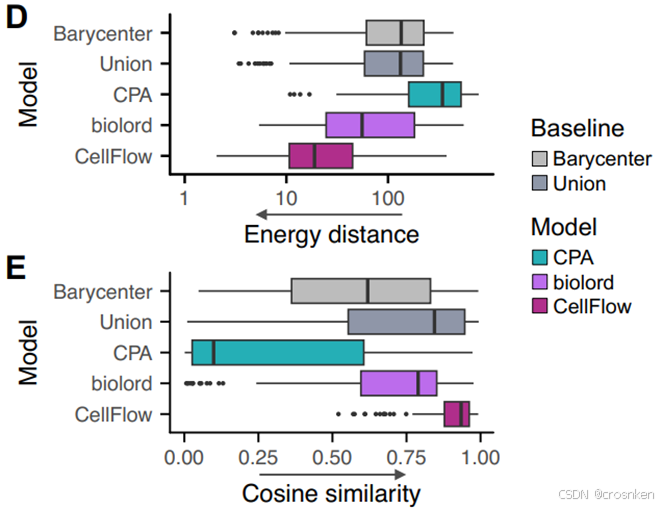
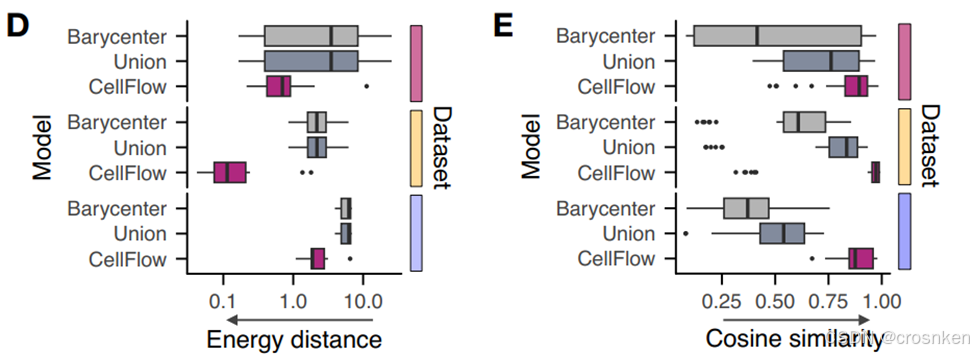
图D、E是和baseline的对比试验结果
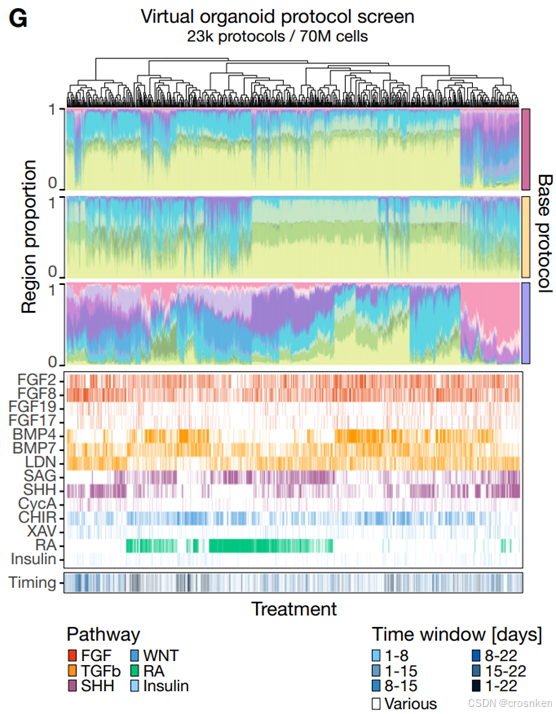
图G上部是预测细胞分化结果,中部是使用的形态因子组合,下方是时间。图H也是预测结果。
Discussion
1、ESM2、分子指纹不足以直接预测分子的功能效应
2、高阶组合(三因子及以上)预测效果较差
3、从PCA重构HVGs表达量较为困难。
4、缺乏对不确定性的量化(分类与回归)