🍦 从冰柜雪糕到火车车厢:栈、队列、链表,真的没那么难
很多同学初学"栈和队列"时,大脑里只有两个字:"受限"。
------ 这不就是个阉割版的数组吗?有什么好学的?
直到后来才明白,这种"操作受限"正是它们最高贵的血统。它能帮助我们明确数据的"使用场景",让程序逻辑清晰如画,bug无处遁形。
今天,我们就从最熟悉的数组出发,把栈、队列、链表这三座大山,用雪糕、排队和火车厢彻底讲透。
阅读收获:
- 用雪糕吃透"栈"
- 用食堂排队理解"队列"
- 用火车车厢可视化解构"链表"
- JS 数组的隐藏彩蛋(它居然不一定是数组?)
- 海量代码示例与性能思考
一、那个"灵活到肥胖"的数组
在 JavaScript 里,数组是我们最好的朋友。它能吃能睡------哦不,能增删改查,样样精通。
js
const arr = [1, 2, 3];
// 尾部增加
arr.push(4); // [1,2,3,4]
// 头部增加
arr.unshift(0); // [0,1,2,3,4]
// 任意位置删除/增加 splice
arr.splice(2, 1, 'x'); // 从索引2删1个,插入'x' => [0,1,'x',3,4]
// 头部删除
arr.shift(); // [1,'x',3,4]看起来很美好,但问题藏在水下 。
push / pop 只在尾巴上折腾,还好;但 unshift / shift 一旦操作头部,后面的所有元素都必须集体搬家------复杂度 O(n)。splice 更是删了又补,底层相当于 slice + replace,纯粹的内存搬运工。

这就像在火车站排队改签:如果你在队伍最前面加塞一个人,后面所有人都得往后退一步;但若你只是在队尾加个人,那就轻松愉快。
结论:数组在频繁的非尾部增删时,会暴露出 O(n) 的移动成本。这时候,我们就需要请出今天的两位主角------栈和队列。
二、栈(Stack)------ 冰柜里的雪糕
栈是一种 后进先出(LIFO, Last In First Out) 的数据结构。
它就像一个只允许从顶部拿放的冰柜。你最后放进去的那根巧乐兹,总是第一个被你摸出来吃掉。最先放进去的东北大板,却被压在底下无人问津。
!图片提示词:一个透明的冰柜,里面垂直叠放着四个雪糕,从下到上分别是东北大板、可爱多、梦龙、巧乐兹。一只手从顶部伸入,正要拿走最上方的巧乐兹,突出"后进先出"
在 JS 中,用数组模拟栈实在太轻松了------只用 push 和 pop。
js
const stack = []; // 空栈
stack.push("东北大板");
stack.push("可爱多");
stack.push("梦龙");
stack.push("巧乐兹");
// 现在栈顶元素是 "巧乐兹"
console.log(stack[stack.length - 1]); // "巧乐兹"
// 把雪糕吃完(清空栈)
while (stack.length) {
const top = stack[stack.length - 1]; // 看一眼栈顶(peek)
console.log('正在吃:', top);
stack.pop(); // 真正的出栈
}
// 输出顺序:巧乐兹 梦龙 可爱多 东北大板栈的经典应用:
- 函数调用栈:JS 引擎就是用栈来追踪函数执行的(你调用的最后一个函数最先执行完)。
- 撤销操作:Ctrl+Z 就是不断把栈顶的历史状态弹出。
- 括号匹配:左括号入栈,右括号与栈顶匹配。
提示:栈的
peek(看一眼栈顶但不取出)并不是标准操作,但我们可以用stack[stack.length - 1]变相实现。
三、队列(Queue)------ 食堂排队打饭
队列是 先进先出(FIFO, First In First Out) 的代表。
谁先排队,谁先投篮。新人必须从队尾开始排。
我们用 push 和 shift 来模拟:
js
const queue = [];
queue.push("詹姆斯"); // 詹姆斯入队
queue.push("杜兰特");
queue.push("库里");
queue.push("伦纳德");
while (queue.length) {
const front = queue[0]; // 查看队头
console.log('正在投篮:', front);
queue.shift(); // 队头出队
}
// 输出顺序:詹姆斯 杜兰特 库里 伦纳德但请注意一个性能陷阱 :shift() 同样会引起所有剩余元素前移一位,时间复杂度 O(n)。
如果队列很长,每次出队都让所有人往前挪一步,食堂阿姨不累吗?
解决方案:
- 双指针数组 (配合前端
head索引和tail索引),避免移动元素。 - 或者干脆用链表来实现队列,增删全在 O(1) 搞定。
四、链表(Linked List)------ 火车车厢,自由连接
数组和链表都是有序 的线性结构,每个元素都有唯一的前驱和后继。
但数组是大通铺 (连续内存),链表是一节节独立车厢(离散内存),通过指针连接。
在 JS 中,链表节点可以用对象字面量轻松构建:
js
function ListNode(val) {
this.val = val;
this.next = null;
}
const node1 = new ListNode(1);
const node2 = new ListNode(2);
node1.next = node2; // 1 -> 2这种离散存放带来的最大优势就是增删极其高效。
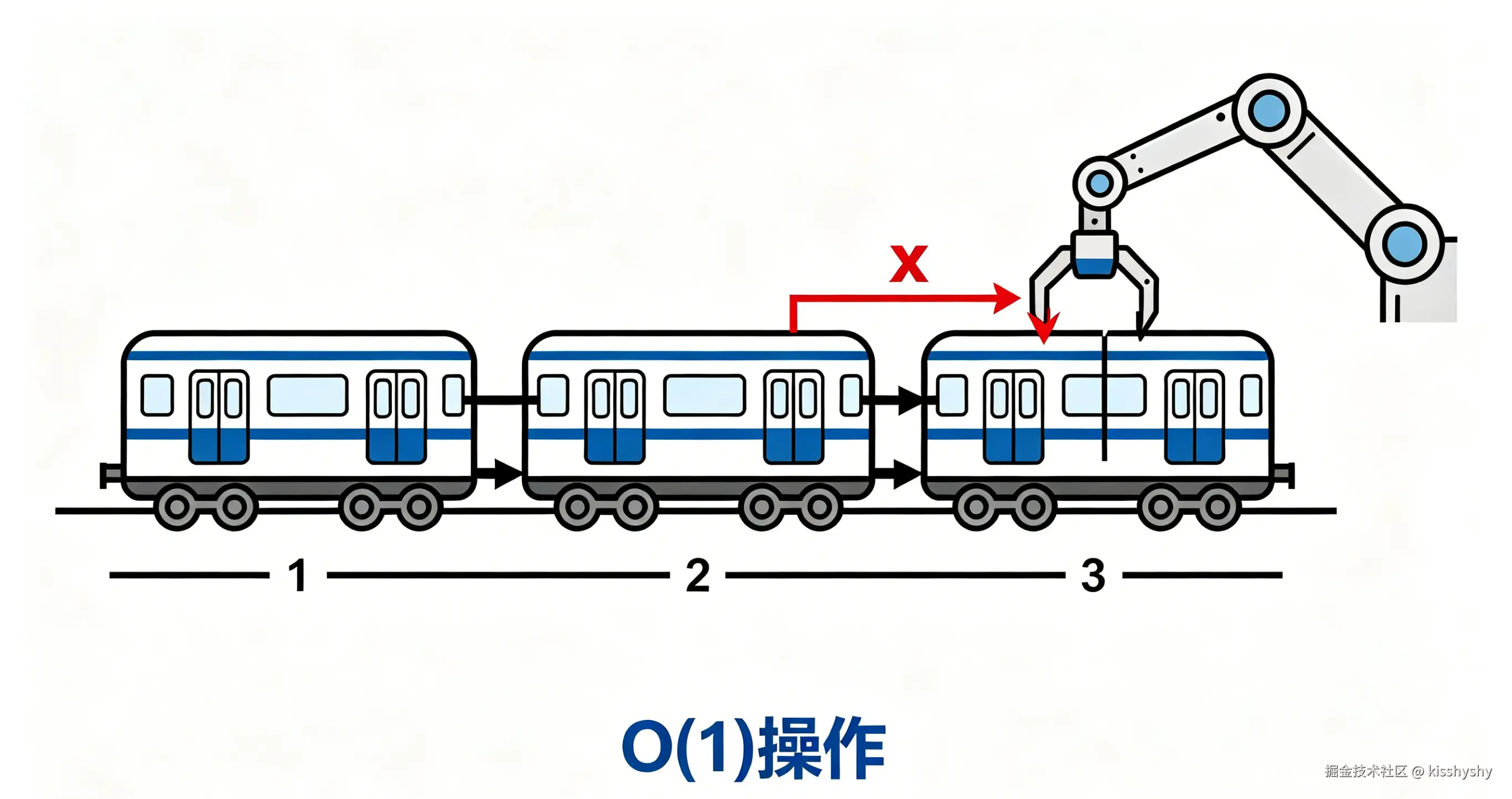
- 插入节点 :改变前驱节点的
next指向新节点,新节点指向原来的后继节点。 - 删除节点 :让前驱节点的
next直接跳过目标节点,指向其后继。
上述操作都只需要修改一两个指针,时间复杂度 O(1)。
但代价是:访问元素必须从头节点开始逐个遍历,最坏 O(n)。
数组 vs 链表:
| 操作 | 数组 | 链表 |
|---|---|---|
| 随机访问 | O(1) | O(n) |
| 头部增删 | O(n) | O(1) |
| 尾部增删 | O(1) | O(1)(有尾指针) |
| 内存连续性 | 连续 | 离散 |
工程哲学:
- 数据规模小、需要频繁索引 → 用数组。
- 数据规模大、频繁增删头部/中间 → 用链表。
五、💣 JS 数组的彩蛋:它不一定是个"真数组"
我们总以为 const arr = [1,2,3] 在内存里一定是连续存储的。错!
在 V8 引擎中:
- 如果数组元素类型一致(如全是小整数),引擎会给它分配一块连续内存,它就是真正意义上的数组(快数组)。
- 如果元素类型五花八门 (比如
['a', 1, {a:1}]),连续存放毫无意义(不同类型占据内存大小不同),引擎会将其降级为以哈希表为基础的"慢数组",底层更像一个用索引做 key 的字典。
js
const arr = [1, 2, 3]; // 快数组,连续内存
const arr2 = ['a', 1, {a:1}]; // 慢数组,哈希结构所以你会发现,JS 数组即使有空洞(稀疏数组)也能正常访问,这得益于它的底层自动切换机制。
另一个容易踩的坑是数组的 sort() 方法:
js
let arr = [10, 2, 5];
arr.sort(); // 默认按字符串Unicode码点排序 → [10, 2, 5]必须传入比较函数:
js
arr.sort((a, b) => a - b); // [2, 5, 10]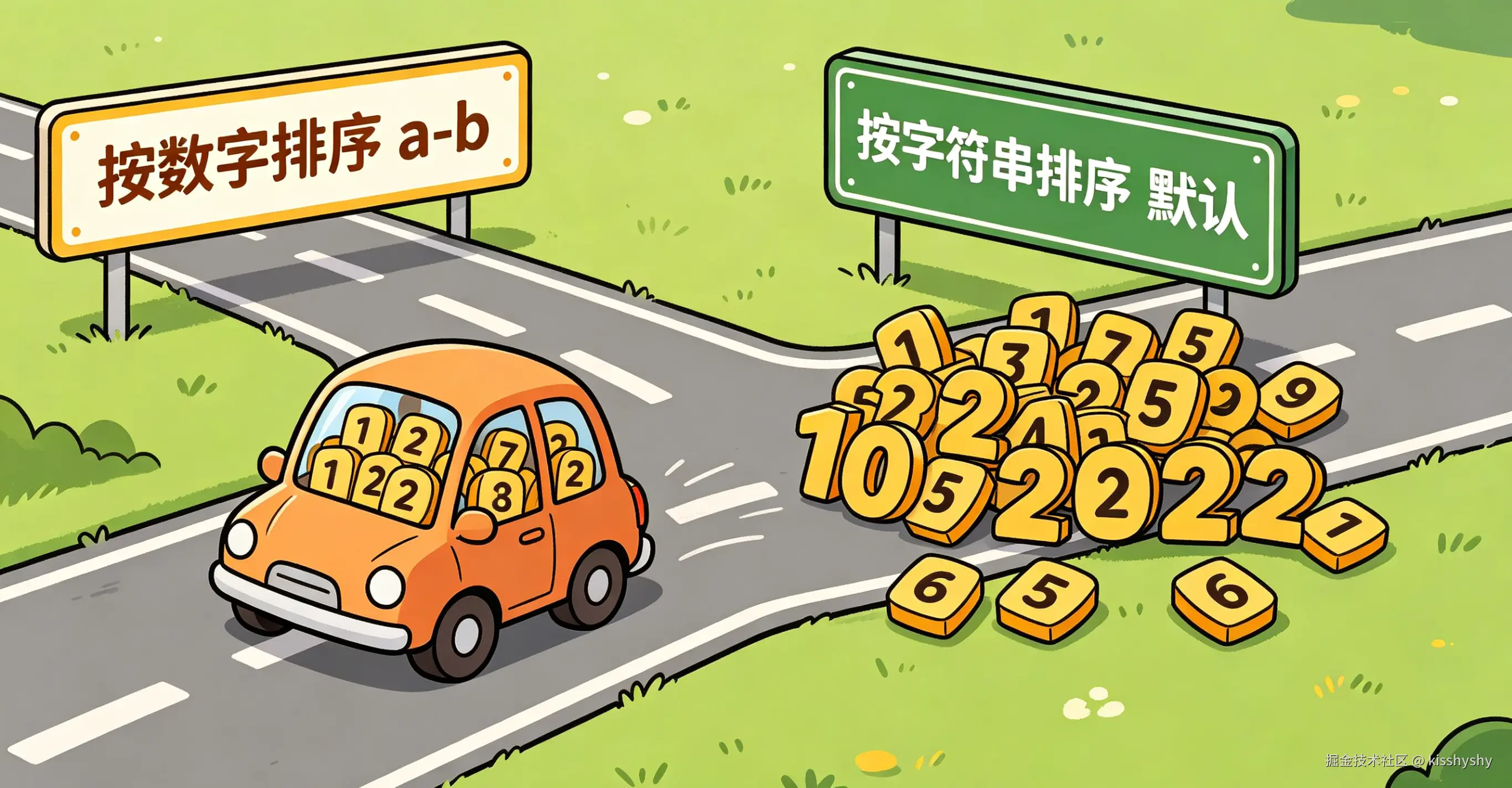
总结:数据结构是思维的形状
栈、队列、链表,它们不仅仅是"被限制的数组",而是我们为了清晰表达数据的流动逻辑而精心设计的容器。
- 需要"历史记录回溯" → 栈(LIFO)
- 需要"任务排队处理" → 队列(FIFO)
- 需要"频繁中间插队,又不关心索引" → 链表
理解这些结构如何映射到 JS 的具体实现,理解内存背后的故事,能让我们在面对性能调优和复杂业务时,做出更精准的架构决策。
终极思考 :JS 里没有原生的链表和栈/队列类,我们一直用数组模拟。但在某些海量数据处理时,手写一个基于链表的队列,能彻底告别
shift带来的 O(n) 噩梦。这就是算法基础给你的底气。
如果觉得这篇"冰柜雪糕风格"的讲解对你有帮助,请点赞收藏,让更多徘徊在数据结构门口的同学吃到这根"巧乐兹"~ 有疑问欢迎在评论区一起讨论!