导读:
为提升氢能产业数据价值,实现数据服务支撑氢能产业智能决策,研发了氢能产业链决策服务系统。该系统应用数据治理技术,将氢能产业政策、专利和文献等多源数据融合;采用自然语言处理算法,分析融合数据的语义特征;通过知识图谱技术,呈现氢能产业发展趋势;借助熵权TOPSIS算法,监测产业发展情况。系统应用氢能产业的数据服务、计算服务和信息服务三层架构,实现了产业链信息导航、关键技术图谱和产业技术监测功能,支撑了氢能产业科技创新发展和技术攻关前瞻研究。
作者信息:
刘力鸣, 刘 超, 陈晓玲*:吉林省科技创新研究院,吉林 长春;贾 超:吉林省翰德人才咨询有限公司,吉林 长春
论文详情
在氢能计算服务功能模块中,研究采用潜在狄利克雷分配(Latent Dirichlet Allocation, LDA) 主题模型对文本数据进行深度挖掘,以精准提取关键信息;同时运用熵权法与优劣解距离法(Technique for Order Preference by Similarity to Ideal Solution, TOPSIS)相结合的算法,构建科学的产业节点评价模型,提升 评价结果的客观性与可靠性。在信息服务功能模块,则通过知识图谱相关技术,系统性构建覆盖多维度 信息的氢能产业知识图谱,为用户提供结构化、可视化的信息查询与整合服务。
流程示意图见图 1。
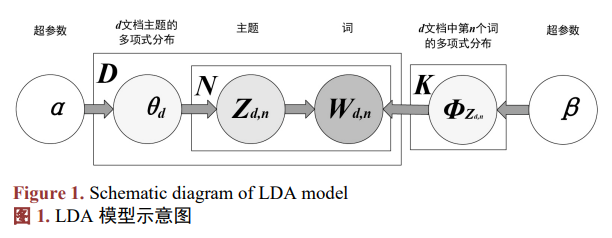
围绕产业数据采集与治理、数据分析和挖掘、产业节点评价模型展开设计,应用成熟可靠的开源框 架进行快速开发,部署在云环境中进行统一的系统运维管理。
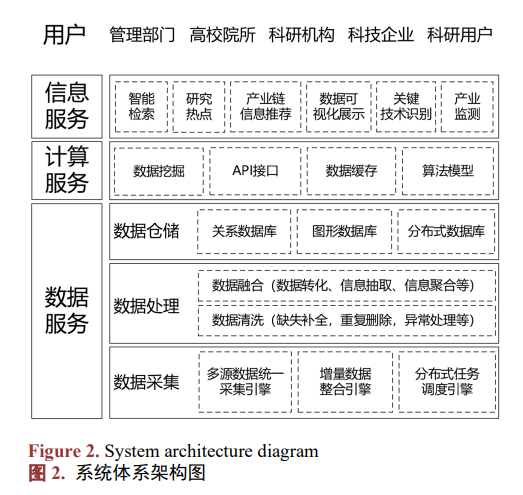
通过分析业务和系统负载状况,将系统解耦成三层服务结构(如图 2 所示)。
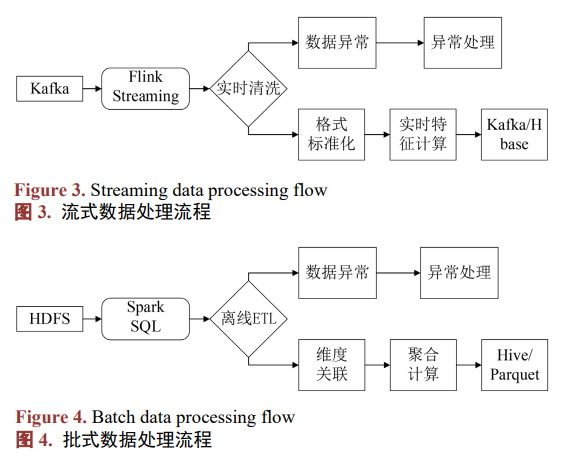
对于 Kafka 中流式数据内容,使用 Flink 进行数据有效性校验、敏感字段脱敏以及实时统计指标计 算等消费活动,清洗后的数据分别写入 Kafka 实时 Topic 和 HBase 实时存储,供下游服务消费(如图 3 所 示)。对于离线批数据使用 Spark 每 6 小时定时处理 HDFS 原始数据,进行维度关联、全量统计指标计算 和数据质量审计,最终将结果以 Parquet 格式存储到 HDFS 并注册到 Hive 表中(如图 4 所示)。
在数据存储阶段,系统采用分层存储策略,对原始数据、实时数据和聚合数据采用不同的存储方 式(如表 1 所示)。

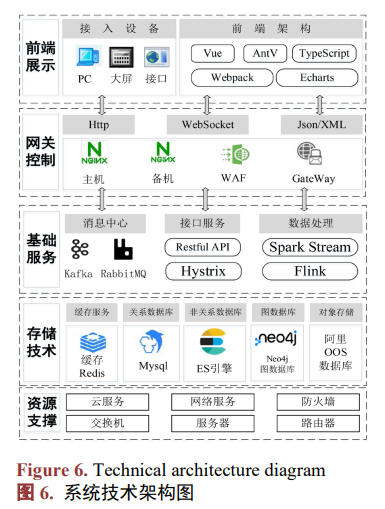
氢能信息平台是面向用户展示的数据可视化服务平台,主要包含了产业链信息导航、产业关键技术 图谱和产业节点监测功能。系统技术架构图如图 6 所示。
在产业节点监测功能实现中,系统使用了基于熵权法结合 TOPSIS 的评价模型,结合企业分布和专 利分布的综合性关键技术指标(如表 2 所示),对产业链上下游的关键技术节点发展情况进行评估(如图 9 所示)。

该系统通过大数据和人工智能技术,实现多源异构数据的融合与集中管理,构建关联共享的智能化服务平台,整合氢能产业链的多维度信息,为政府、企业和投资者提供精准的决策支持,助力产业在复 杂市场环境中稳健发展。通过实时监测产业链节点数据,系统帮助科技管理者全面掌握产业链完整性及 节点强弱情况,为政策制定和技术创新提供科学依据,有效推动了氢能产业的高质量发展和持续升级。
基金项目:
2024 年吉林省科技发展计划项目重点研发,项目名称"基于决策驱动的科技资源智能感知系统研发 与应用"(项目编号:20240302071GX)。