智谱 ZCode Harness for GLM-5.2:国产 Coding Agent 从"模型能力"走向"工程执行环境"

TL;DR
- 场景:AI 编程工具的竞争已经不再是"会不会写代码",而是"能不能在真实工程环境里持续工作几十分钟到几小时,自己规划、自己执行、自己验证并交付可审查的代码改动"。
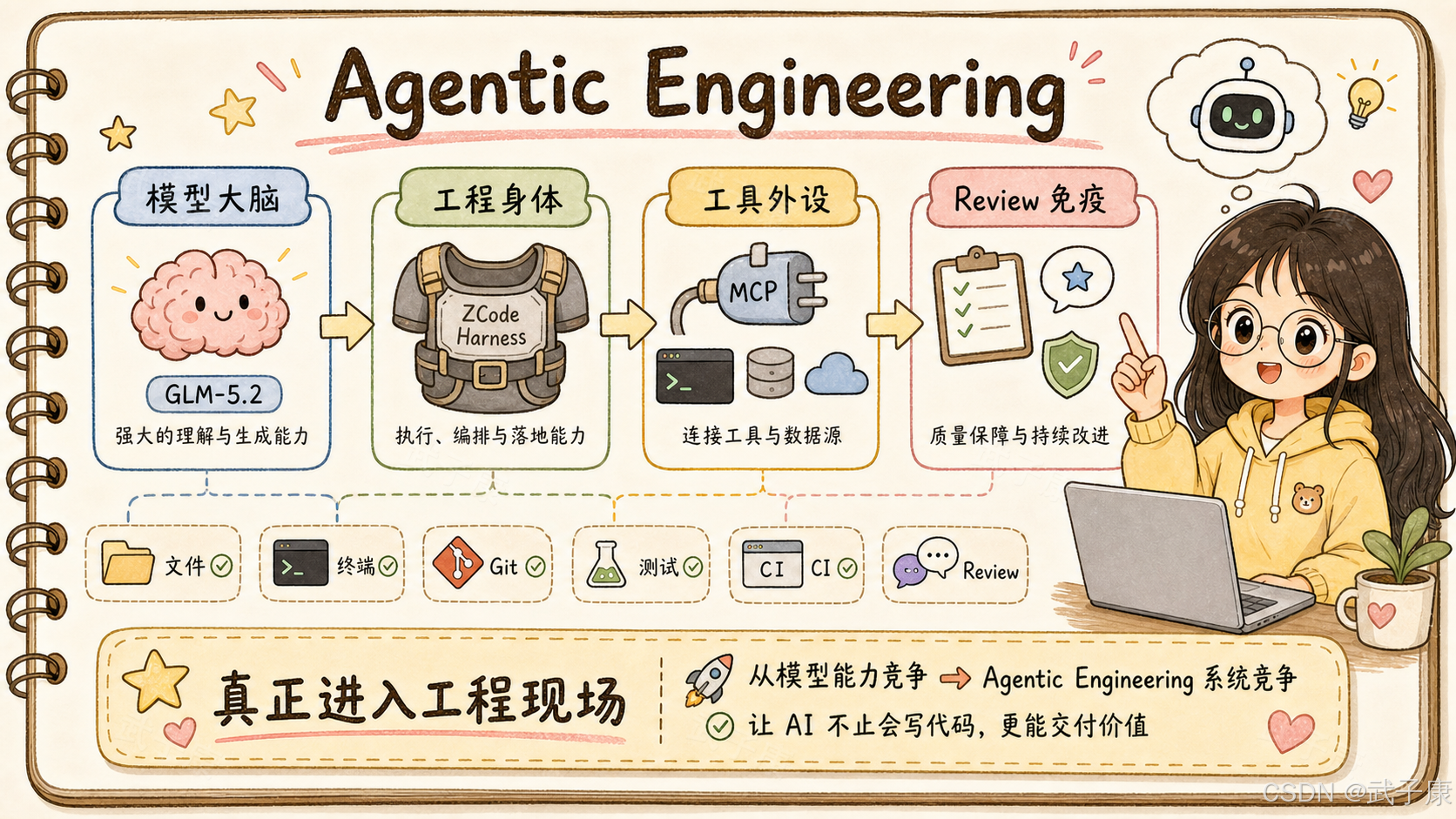
- 结论:GLM-5.2 在模型侧把 1M token context、long-horizon task、可调 thinking effort、IndexShare 稀疏注意力复用、MTP speculative decoding 等能力做出来;ZCode 作为官方 Harness(Agentic Development Environment)补上文件 / 终端 / Git / 远程开发 / Goal Mode / Subagents / MCP / Review 等工程身体。模型是工程大脑,Harness 是工程身体。
- 产出:一份围绕"模型能力 → 工程执行环境"的判断框架------为什么 Harness 不只是包装、为什么 GLM-5.2 必须配 Harness、ZCode 当前桌面版 v3.2.2 的产品形态、与 Claude Code / Codex CLI 的产品取向差异、团队落地 Coding Agent 的工程规范。
关键词:ZCode Harness、GLM-5.2、智谱、Agentic Development Environment、Coding Agent、长程任务、1M token context、IndexShare、MTP、MoE 744B-A40B、Goal Mode、Subagents、MCP Servers、Remote Development、Claude Code、Codex CLI、Agentic Engineering、国产 AI 编程、Z.ai、Harness 设计、桌面 ADE、Coding Plan、CSDN 技术博客、武子康。
版本矩阵
| 功能 / 概念 | 状态 | 说明 |
|---|---|---|
| GLM-5.2 2026-06-13 面向 GLM Coding Plan 全量用户开放 | ✅ 已验证 | 智谱官方公告,覆盖 Lite / Pro / Max / 团队版,API 与开源计划下周上线 |
| GLM-5.2 2026-06-17 上线并开源(MIT 协议,无地域限制) | ✅ 已验证 | 央广网、智谱官方公告、QQ 新闻一致报道 |
| GLM-5.2 稳定 1M token context | ✅ 已验证 | 多家媒体(智谱公告、CSDN、博客园)一致描述为"稳定可用 100 万 Token" |
| GLM-5.2 744B-A40B MoE 架构 | ✅ 已验证 | 总参数 744B、活跃 40B,OpenCSG 模型页与多家媒体一致 |
| IndexShare 复用 sparse attention indexer,per-token FLOPs -2.9x | ⚠️ 待验证 | 出现在用户原文与部分深度评测;建议核对智谱官方技术报告 / arXiv |
| MTP layer 改进,speculative decoding 接受长度 +20% | ⚠️ 待验证 | 同上,建议核对官方报告具体数字 |
| 可调 thinking effort | ⚠️ 待验证 | 用户原文描述,建议核对 GLM-5.2 模型卡 / API 文档 |
| ZCode 桌面版 v3.2.2(截至 2026-07-02) | ⚠️ 待验证 | 用户提供版本号,zcode.z.ai 域名未独立核实 |
| ZCode Goal Mode(目标驱动自动迭代 + 验证) | ⚠️ 待验证 | 用户提供;zcode.z.ai/en/docs/goal 链接未独立验证 |
| ZCode Subagents(general-purpose / Explore + 用户自定义) | ⚠️ 待验证 | 用户提供;zcode.z.ai/en/docs/subagents 链接未独立验证 |
| ZCode MCP Servers(stdio / HTTP / SSE + 配置导入) | ⚠️ 待验证 | 用户提供;zcode.z.ai/en/docs/mcp-services 链接未独立验证 |
| ZCode Remote Development(SSH + Docker workspace) | ⚠️ 待验证 | 用户提供;zcode.z.ai/en/docs/remote-development 链接未独立验证 |
| GLM-5 / GLM-5.2 GitHub 仓库 zai-org/GLM-5 | ✅ 已验证 | SourceForge 镜像、GitHub Discussions 页均存在 |
| Code Arena 盲测 GLM-5.2 全球可用模型第一 | ✅ 已验证 | 智谱官方与央广网公告一致 |
| LiveBench 综合第 7(GLM-5.2 max) | ✅ 已验证 | 个人技术博客引用,LiveBench 官方榜单未单独核 |
| Artificial Analysis Intelligence Index v4.0 = 50 分(GLM-5 系) | ✅ 已验证 | 多家 CSDN 评测文章一致引用 50 分 |
| Claude Code(github.com/anthropics/claude-code) | ✅ 已验证 | 真实存在的 agentic coding 工具 |
| OpenAI Codex CLI(developers.openai.com/codex/cli) | ⚠️ 待验证 | URL 路径推测为真,OpenAI 官方文档站需对照当前路径 |
| "Vibe Coding → Agentic Engineering" 范式转移 | ✅ 已验证 | 智谱 PPIO 首发稿、博客园多篇文章均用此叙事 |
ZCode 试图补的就是这层 Harness:模型负责推理,Harness 负责把推理翻译成受控、可验证、可审查的工程动作。
一句话概括:
text
GLM-5.2 提供长程推理大脑,ZCode 负责给它接上工程身体。1. 竞争焦点变了:从"会写代码"到"能持续做工程"
过去一年,AI 编程工具的竞争逻辑变化很快。
早期大家问的是:模型会不会写一个函数、补一段 SQL、解释一段代码。
后来问题变成:它能不能看懂整个仓库?能不能跨文件改代码?能不能跑测试并根据报错继续修?
到了 GLM-5.2 和 ZCode 这一代,真正的问题已经是:
text
模型能不能在一个真实工程环境里持续工作几十分钟、几小时,
保持上下文不断裂,
自己规划、自己执行、自己验证,
最后交付一组可审查的代码改动?这就是 ZCode Harness for GLM-5.2 的意义。
官方文档把 ZCode 定位为面向 GLM-5.2 的 Agentic Development Environment,用来把 GLM-5.2 的长上下文、长程任务和 agentic coding 能力带进真实编码工作流。ZCode 首页也把自己称为 GLM-5.2 的 official harness,并强调把 AI agents 和现有工具链结合,让用户完成 planning、coding、review、deploy 等流程。
这里的核心词不是"聊天",而是"环境"。
单独一个模型,再强也只是大脑。它需要看到文件,需要知道当前分支,需要运行命令,需要理解测试失败,需要管理任务边界,需要控制权限,需要记录历史,需要在上下文压缩后仍然知道自己为什么这样改。没有这套外壳,模型能力会在真实项目里迅速折损。
所以 Harness 不是简单包装,而是把模型推理变成工程动作的一套约束、连接、调度和执行系统。

2. GLM-5.2 为什么需要这样的 Harness
GLM-5.2 的卖点不是普通单轮问答。
官方 GitHub 仓库把 GLM-5.2 描述为面向 long-horizon tasks 的旗舰模型,相比 GLM-5.1 在长程任务能力上提升明显,并首次把这种能力建立在稳定可用的 1M token 上下文上。仓库列出的关键能力包括:
- 稳定 1M token context,用来支撑长程工作;
- 更强 coding 能力,并支持不同 thinking effort 来平衡性能和延迟;
- IndexShare 架构,在 1M context 下复用 sparse attention layers 的 indexer,将 per-token FLOPs 降低 2.9 倍;
- 改进 MTP layer,用于 speculative decoding,接受长度最高提升 20%;
- GLM-5.2 与 GLM-5.2-FP8 权重均为 744B-A40B,并提供 BF16 / FP8 下载。
这些信息说明一个方向:模型侧在努力让"长上下文"不只是宣传参数,而是能在持续任务中真正跑起来。
但对 Coding Agent 来说,长上下文只是底座。
真实工程任务不是"把更多文件塞给模型"这么简单。比如你让 Agent 修复一个模块,它通常要经历:
text
读目录 -> 定位入口 -> 理解调用链 -> 修改代码
-> 运行测试 -> 分析报错 -> 再修改
-> 检查 Git diff -> 总结风险 -> 等待人类 review这类任务的瓶颈不只是模型智商,而是持续执行能力。
长上下文解决"能不能装下更多信息";Harness 解决"这些信息如何被组织成持续工作流"。
ZCode 文档里有一句很关键:借助 GLM-5.2 的稳定 1M context 和 long-horizon task capability,ZCode Agent 可以把 goal、files、terminal results、browser context、execution modes 和 Git state 放在同一个 task 中,让复杂开发工作从 planning 走到 implementation 和 verification 时减少连续性丢失。
这句话背后其实是 Agent 工程的基本问题:
text
上下文不是越长越好,而是要能被持续维护、持续引用、持续校验。3. ZCode 的产品形态:更像桌面版 Agent 工作台
ZCode 当前不是纯 CLI,而是桌面应用。
截至 2026-07-02,ZCode 官方下载页显示当前桌面版本为 v3.2.2,支持 macOS Apple Silicon / Intel、Windows x64 / ARM64,以及 Linux x64 / ARM64 的 deb 和 AppImage 包。Linux 标注为 Beta。
这个形态说明 ZCode 不只是面向命令行重度用户,而是想做一个可视化 Agent 工作台。
它有几个明显特征。
第一,任务是核心对象。
用户不是只和模型聊天,而是创建任务、查看任务进度、管理文件变更、追踪 token、查看迭代次数和结果。对 Coding Agent 来说,任务比消息更重要,因为工程目标通常跨很多轮。
第二,工程状态进入 Agent 上下文。
文件树、终端、Git、执行结果、历史改动、浏览器上下文,不再是零散信息,而是 Agent 可以反复读取和操作的工作环境。
第三,它强调 Review。
AI 写代码不是最终结果。能不能让人审查、理解、回滚,才决定它能不能进入生产流程。
第四,它支持远程开发。
ZCode 官方 remote development 文档说明,workspace 可以跑在远程主机或本地容器里。连接成功后,文件读取、终端命令、Git 操作和 Agent 执行都发生在目标环境中;桌面客户端负责账号、模型配置、任务入口和界面。
这点对真实项目很关键。很多项目不适合在本机跑:依赖复杂、需要 GPU、需要内网数据库、必须在特定 Linux 环境里构建。ZCode 支持 SSH 和 Docker,本质上是在降低 Agent 进入真实开发环境的门槛。
4. Goal Mode:从"继续一下"到"目标式执行"
ZCode 里最值得关注的功能之一,是 /goal。
官方 Goal Mode 文档说明:面对长时间复杂任务,用户可以用 /goal 设置明确目标。设置之后,ZCode Agent 会围绕目标持续迭代。每轮结束时,它会自动做 goal verification。如果目标没有完成,就进入下一轮;如果验证通过,任务才结束。
这不是一个小交互。
它标志着 AI 编程从"对话式辅助"走向"目标式执行"。
以前你可能要反复说:
text
继续。
再跑一次测试。
根据报错改。
再检查一下。
现在总结。Goal Mode 试图把这些人肉推进动作变成系统机制。用户只需要给出一个可验证目标,例如:
text
修复所有 TypeScript 编译错误,并确保 pnpm test 通过。Agent 就应该进入一个循环:
text
执行 -> 观察 -> 判断 -> 再执行 -> 验证完成标准真正的分水岭在这里。
一个能写代码的模型,只能回答问题。
一个能围绕目标自动验证和迭代的系统,才开始接近软件工程代理。
当然,这不意味着可以完全无人值守。长程循环越强,权限控制越重要。ZCode 文档也强调 Goal Mode 可以和 execution modes 配合:目标定义什么时候算完成,执行模式定义哪些动作需要确认。
这条设计方向是对的。Agent 不应该只有"全自动"和"全手动"两档,而应该按动作风险分层。

5. 多 Agent:从一个上下文硬扛,到角色化分工
ZCode 3.0 之后的另一个重点是 Subagents。
官方 Subagents 文档把 subagent 定义为:主 Agent 可以启动的专门 Agent,它在隔离上下文中处理任务,然后把结果总结回主对话。ZCode 内置 general-purpose 和 Explore 两类 subagent,并支持用户级自定义 subagent,当前标注为 Beta。
这个方向非常实际。
真实工程任务很少是线性的。比如你让 Agent 重构一个模块,它同时要做几件事:
- 搜索调用链;
- 理解历史兼容逻辑;
- 修改核心代码;
- 补测试;
- 检查文档;
- 评估风险。
如果所有事情都塞进一个主上下文,Agent 很容易混乱。Subagent 的价值,是把复杂任务拆成相对独立的子问题,让不同角色在隔离上下文里工作。
尤其是 Explore 这个只读子 Agent,很适合做代码库搜索、架构发现、调用链梳理和风险调查。因为它只读,不改文件,适合在正式动手前先做侦察。
这和人类工程团队很像:不是一上来就改代码,而是先查清楚边界、依赖和风险,再动手。
6. MCP 和插件:Coding Agent 不能只活在文件系统里
ZCode 也支持 MCP Servers。
官方 MCP 文档说明,MCP 可以把文件系统、浏览器自动化、记忆、数据库等外部能力连接给 Agent。ZCode 支持在一个地方管理 MCP 配置,支持 stdio、HTTP、SSE 等方式,也可以从 Claude Code、Codex CLI、OpenCode 等外部 Agent 的配置中导入 MCP server。
这说明 ZCode 没有把自己做成完全封闭生态,而是在兼容当前 Agent 工具链的通用协议。
MCP 对 Coding Agent 的意义很直接:
text
模型本身不知道你的浏览器、数据库、内部工具、记忆系统在哪里。
MCP 相当于给 Agent 插外设。没有 MCP,Agent 主要能读代码、写代码、跑命令。有 MCP,它可以接入更完整的工程上下文。
但 MCP 越强,权限风险越高。
一个 Agent 如果同时能读文件、跑 shell、查数据库、开浏览器、访问内部服务,它已经不只是代码助手,而是一个带执行权限的自动化员工。企业使用时必须考虑最小授权、密钥隔离、审计、敏感命令确认和高风险动作复核。
这也是 ZCode 文档里反复强调安全确认的原因:敏感命令、文件变更和高权限动作,需要在执行前经过确认。
7. 和 Claude Code、Codex CLI 的关系:同一趋势,不同产品取向
ZCode 不是在空白市场里出现。
Claude Code 官方 GitHub 描述它是运行在终端里的 agentic coding tool,可以理解代码库、执行日常任务、解释复杂代码,并处理 Git 工作流。
OpenAI Codex CLI 官方文档则把它描述为可以在本地终端运行的 coding agent,可以在选定目录里读取、修改并运行代码,并且是开源、Rust 构建。
这几个工具的共同点是:都在把 LLM 从"代码生成器"推进到"能操作开发环境的 Agent"。
差异在产品取向。
Claude Code 更偏终端原生,适合习惯 CLI 和 Git 工作流的开发者。
Codex CLI 也强调本地终端、轻量代理和 OpenAI 模型体系。
ZCode 则更偏桌面 ADE,把任务、文件、远程环境、移动控制、Bot 通道、多 Agent、MCP 和 Review 做成统一产品界面。
所以 "Official Harness for GLM-5.2" 的真正含义,不只是"接了 GLM API"。它更像是 GLM-5.2 的官方工程载体:把模型能力包装成一套可持续执行的工作台。
8. 当前成熟度:方向清晰,但仍在快速打磨
ZCode 的方向很清晰,但不能神化。
官方 changelog 显示,ZCode 在 2026 年 6 月下旬到 7 月 1 日有多次 3.1.x 到 3.2.2 的更新。v3.2.2 增加了内置插件更新/卸载、文件 rewind 安全摘要、prompt command trigger 建议等能力,也修复了外部工具连接失败提示、subagent 编辑和工具用量统计、停止目标状态可见性、日志敏感数据脱敏等问题。
再往前看,v3.2.1 / v3.2.0 里也出现了远程 workspace 恢复、符号链接导致文件树卡死、Mermaid 渲染崩溃、大会话切换卡顿、流式内容丢失、长文本粘贴、任务停止后仍继续推进、暂停任务继续迭代等修复。
这些问题并不意外。
Agentic IDE 本身就是复杂系统。它要同时处理 UI、文件系统、终端、Git、远程连接、模型流式输出、权限控制、任务状态、上下文压缩、插件、MCP、多 Agent 并行。任何一个环节不稳定,用户体感都会下降。
所以对 ZCode 的判断应该分两层。
方向上,它是对的:GLM-5.2 需要这样的 Harness 才能变成工程生产力。
成熟度上,它还需要大量真实项目打磨。尤其是长任务稳定性、上下文压缩质量、权限边界、远程开发可靠性、插件安全、成本可观测性,会决定它能不能进入专业团队的主力工作流。
9. 对开发者意味着什么
对个人开发者来说,ZCode 最值得试的场景,不是"从零写一个玩具 demo",而是目标明确、反馈可验证、失败可回滚的工程任务。
比如:
- 修复一批明确可验证的编译错误;
- 跑测试,根据报错持续修改;
- 理解陌生仓库并生成结构说明;
- 做小范围重构,并保持测试通过;
- 补 README、类型、注释、单元测试;
- 处理前端页面细节、样式适配、构建错误;
- 在远程 Linux / Docker 环境里跑本机不方便跑的项目。
这些任务有共同特点:完成标准清楚,Agent 可以自己观察反馈,人类可以审查 diff。
对团队来说,ZCode 更像一个低成本初级工程执行层。它不替代资深工程师做架构判断,但可以承担大量明确、重复、可验证的工程劳动。
团队真正要建设的,是一套 Agent 使用规范:
text
哪些目录允许改?
哪些命令必须确认?
哪些任务必须先 Explore 再修改?
哪些文件必须人工 review?
哪些测试是完成标准?
怎样写项目级 Skill / Command / Subagent?
怎样记录 Agent 改动和失败原因?一旦进入这个阶段,竞争就不只是"谁的模型更强",而是"谁的工程组织方式更适合 Agent"。

10. 对国产 AI 编程生态意味着什么
ZCode + GLM-5.2 的组合,说明国产大模型正在从"聊天模型竞争"进入"Agent 工程系统竞争"。
这比单纯刷 benchmark 更重要。
因为真实生产力不发生在排行榜上,而发生在项目目录里、终端里、CI 报错里、Git diff 里、代码评审里。
GLM-5.2 提供长上下文和长程任务能力;ZCode 提供桌面环境、任务系统、Goal Mode、Subagents、MCP、远程开发和权限控制。两者合在一起,才构成一个完整的 Coding Agent 产品。
未来 AI 编程工具大概率会走向这种形态:
text
模型像工程大脑;
Harness 像工程身体;
MCP / 插件 / 远程环境像外部器官;
项目规范、测试、CI、Review 像免疫系统。没有 Harness,模型只能给建议。
有 Harness,模型才能真正进入工程现场。
11. 最终判断
ZCode Harness for GLM-5.2 的核心价值,不在于它又做了一个 AI 编程工具,而在于它把 GLM-5.2 的模型能力翻译成了工程执行能力。
它代表的是一个明确趋势:AI 编程不再只是补全、问答、生成代码片段,而是进入目标驱动、工具执行、持续验证、多 Agent 协作、权限可控的 Agentic Engineering 阶段。
短期看,它会和 Claude Code、Codex CLI、Cursor Agent、Windsurf 等工具正面竞争。
长期看,真正的壁垒可能不是单个模型,而是模型、Agent Runtime、上下文工程、权限系统、远程环境、MCP 生态、团队工作流之间的组合效率。
ZCode 如果能把稳定性、成本透明度、权限安全和真实项目成功率继续打磨下去,它就不只是 GLM-5.2 的官方 Harness,而可能成为国产 Agentic Coding 生态的关键入口。
参考来源
- ZCode 官网
- ZCode for GLM-5.2 文档
- ZCode Goal Mode 文档
- ZCode Subagents 文档
- ZCode MCP Servers 文档
- ZCode Remote Development 文档
- ZCode changelog
- GLM-5 / GLM-5.2 GitHub 仓库
- Claude Code GitHub 仓库
- OpenAI Codex CLI 官方文档
错误速查卡(ZCode Harness for GLM-5.2 工程化)
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 1M token 宣传但 Agent 跑到中途"上下文到达条件限制" | 上一代模型(如 GLM-5.1)的有效上下文窗口有限 | 看模型版本号与 release date;看 token 计数器在长任务中提前撞墙 | 升级到 GLM-5.2(2026-06-17 开源,稳定 1M context);或在 Harness 侧做上下文压缩 / 分段加载 |
| 启用 Goal Mode 后任务停不下来 / 反复执行已通过的验证 | Goal verification 不收敛或目标定义不清 | 看 Goal 描述是否可验证;看每轮 verification 的输出 | 目标改写为可二值判断的验收标准;引入完成度上限 / 最大轮数 / 单步超时 |
| 长任务上下文被截断后,Agent 忘了"为什么这么改" | 仅靠裸模型上下文,无 Harness 状态持久化 | 看对话历史是否完整;看 Agent 是否能复述任务背景 | 用 ZCode 这类 ADE 把 goal / files / terminal / Git state 持久化进同一个 task;启用 Review / 文件 rewind 安全摘要 |
| Subagent 改坏了不该改的文件 | 没有"先 Explore 再修改"的隔离约束 | 看 Subagent 类型(Explore 应只读);看权限 scope | 优先用 Explore 子 Agent 做侦察;写代码交给 general-purpose;按目录分层授权 |
| MCP 接通后,Agent 能执行 shell / 调数据库 / 发外部消息,安全事故 | MCP 是能力扩展,但默认权限过大 | 看 MCP 配置的 tool scope 与 secret 来源 | 引入最小授权:MCP tool 区分 read / write;高风险动作(rm、curl、db.write、mail.send)走 Review 确认;敏感凭据走 OS keyring |
| 远程 workspace 跑任务时,本地看起来"还在转"但实际已经卡死 | 远程断连 / workspace resume 失败 | 看客户端连接状态;看 v3.2.0 / v3.2.1 已知修复(远程 workspace 恢复) | 升级 ZCode 至最新桌面版;用 Docker workspace 替代裸 SSH;启用停止目标状态可见性 + 日志脱敏 |
| 团队让 Agent 直接改生产目录,导致事故 | 没有项目级 Agent 使用规范 | 看 Agent 改动的目录 / 命令类型 | 落地"权限分层 + 先 Explore + 人工 Review"六步清单;CI / Git hook 拦截高风险命令;agent 改动与人工 diff 同 review 流 |
| AI 写完代码没人看懂,改了等于没改 | Harness 只做"生成"不做"审查可见性" | 看 review 界面、Git Diff、commit message 是否清晰 | 强制 Agent 输出可审查交付:Git Diff + 风险说明 + 验证步骤;Review 清单(逻辑清晰 / 边界处理 / 命名规范 / 注释说明) |
| 长时间 Goal Mode 把 token / API 费用烧穿 | 缺乏成本可观测性与每轮预算 | 看账户 token 用量曲线;看每轮 prompt / completion | 加成本面板:每任务 / 每轮 token 上限;自动暂停超阈值任务;优先用 FP8 / thinking effort 低档跑探索 |
| Cursor / Claude Code 风格的"对话式补全"和 ZCode 的"任务式执行"混用,团队工作流断裂 | 没有把 Harness 类型与场景匹配 | 看任务是一次补全还是目标驱动 | 短补全走 IDE / CLI;长任务 / 跨文件重构走 ZCode Goal Mode + Subagents;CI / 批处理走 OpenCode 类无头 harness |
| 把 ZCode 神化成"GLM-5.2 完全体",忽视其仍在快速打磨的事实 | 误把方向正确当成熟可用 | 看 changelog 仍密集修复(流式丢失 / 文件树卡死 / Mermaid 崩溃 / 长粘贴丢失等) | 团队落地时按"灰度 + 备份 + 人工 review"接入;把 ZCode 当作初级工程执行层,架构与高风险改动仍由人主导 |