Ubuntu26.04 搭建 Hadoop3.5.0 完全分布式
| lihaozhe01 | lihaozhe02 | lihaozhe03 |
|---|---|---|
| 192.168.11.101 | 192.168.11.102 | 192.168.11.103 |
| zookeeper | zookeeper | zookeeper |
| namenode | namenode | |
| recource manager | recource manager | |
| journalnode | journalnode | journalnode |
| datanode | datanode | datanode |
| nodemanager | nodemanager | nodemanager |
| job history server | ||
| job log | job log | job log |
1. 准备
nodejs python scala maven 是为 其他集群和开发环境准备的 如果只是搭建hadoop集群可以忽略
1.1 升级操作系统和软件
1.1.1 备份 apt 源配置文件
bash
sudo mv /etc/apt/sources.list.d/ubuntu.sources /etc/apt/sources.list.d/ubuntu.sources.bak1.1.2 编写 apt 源配置文件
bash
sudo vim /etc/apt/sources.list.d/ubuntu.sources内容如下:
bash
Types: deb
URIs: https://mirrors.aliyun.com/ubuntu
Suites: resolute resolute-updates resolute-backports
Components: main universe restricted multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
Types: deb
URIs: https://mirrors.aliyun.com/ubuntu
Suites: resolute-security
Components: main universe restricted multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg1.1.3 更新APT源
bash
sudo apt update1.1.4 升级软件
bash
sudo apt -y dist-upgrade1.2 设置时区
bash
sudo timedatectl set-timezone Asia/Shanghai1.3 修改主机名
分别在不同的主机节点
bash
sudo hostnamectl set-hostname lihaozhe01
bash
sudo hostnamectl set-hostname lihaozhe02
bash
sudo hostnamectl set-hostname lihaozhe031.4 修改IP地址
lihaozhe01
bash
sudo tee /etc/netplan/00-installer-config.yaml > /dev/null << 'EOF'
network:
version: 2
renderer: networkd
ethernets:
ens32:
dhcp4: no
addresses:
- 192.168.11.101/24
routes:
- to: default
via: 192.168.11.2
nameservers:
addresses:
- 192.168.11.2
EOF
bash
sudo chmod 600 /etc/netplan/00-installer-config.yaml
bash
sudo netplan applylihaozhe02
bash
sudo tee /etc/netplan/00-installer-config.yaml > /dev/null << 'EOF'
network:
version: 2
renderer: networkd
ethernets:
ens32:
dhcp4: no
addresses:
- 192.168.11.102/24
routes:
- to: default
via: 192.168.11.2
nameservers:
addresses:
- 192.168.11.2
EOF
bash
sudo chmod 600 /etc/netplan/00-installer-config.yaml
bash
sudo netplan applylihaozhe03
bash
sudo tee /etc/netplan/00-installer-config.yaml > /dev/null << 'EOF'
network:
version: 2
renderer: networkd
ethernets:
ens32:
dhcp4: no
addresses:
- 192.168.11.103/24
routes:
- to: default
via: 192.168.11.2
nameservers:
addresses:
- 192.168.11.2
EOF
bash
sudo chmod 600 /etc/netplan/00-installer-config.yaml
bash
sudo netplan apply1.5 修改hosts配置文件
bash
sudo vim /etc/hosts修改内容如下:
bash
192.168.11.101 lihaozhe01
192.168.11.102 lihaozhe02
192.168.11.103 lihaozhe031.6 上传软件配置环境变量
以下软件并非全部用于 hadoop 而是为 后续集群和开发环境准备
创建软件下载目录
bash
mkdir ~/opt安装python
-
安装python
bashsudo apt -y install python3 python3-venv python3-pip -
配置pip国内镜像源
bashpip config set global.index-url https://mirrors.aliyun.com/pypi/simple
安装nodejs
-
下载
bashwget -P ~/opt https://nodejs.org/dist/v24.18.0/node-v24.18.0-linux-x64.tar.xz -
解压并修改目录名称
bashtar -xvf ~/opt/node-v24.18.0-linux-x64.tar.xz -C ~/opt mv ~/opt/node-v24.18.0-linux-x64 ~/opt/node-v24 -
配置环境变量,在
~/.profile末尾追加:bashexport NODE_HOME=$HOME/opt/node-v24 export PATH=$PATH:$NODE_HOME/bin -
激活编辑变量
bashsource ~/.profile -
设置 npm 国内镜像源
bashnpm config set registry https://registry.npmmirror.com -
使用 npx nrm 快速切换镜像源
bashnpx nrm use taobao -
全局安装升级npm pnpm yarn
bashnpm install -g npm npm install -g pnpm npm install -g cnpmbashnpm config set allow-scripts=yarn --location=user npm install -g yarn -
设置 pnpm yarn 国内镜像源
bashpnpm config set registry https://registry.npmmirror.combashyarn config set registry https://registry.npmmirror.com
安装java
-
下载
bashwget -P ~/opt https://download.oracle.com/java/25/latest/jdk-25_linux-x64_bin.tar.gz -
解压并修改目录名称
bashtar -zxvf ~/opt/jdk-25_linux-x64_bin.tar.gz -C ~/opt mv ~/opt/jdk-25.0.3 ~/opt/jdk-25 -
配置环境变量,在
~/.profile末尾追加:bashexport JAVA_HOME=$HOME/opt/jdk-25 export PATH=$PATH:$JAVA_HOME/bin -
激活编辑变量
bashsource ~/.profile
安装maven
-
下载
bashwget -P ~/opt https://dlcdn.apache.org/maven/maven-3/3.9.16/binaries/apache-maven-3.9.16-bin.tar.gz -
解压并修改目录名称
bashtar -zxvf ~/opt/apache-maven-3.9.16-bin.tar.gz -C ~/opt mv ~/opt/apache-maven-3.9.16 ~/opt/maven -
配置环境变量,在
~/.profile末尾追加:bashexport MAVEN_HOME=$HOME/opt/maven export PATH=$PATH:$MAVEN_HOME/bin -
修改配置文件
$HOME/opt/maven/conf/settings.xml
xml<?xml version="1.0" encoding="UTF-8"?> <!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to you under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --> <!-- | This is the configuration file for Maven. It can be specified at two levels: | | 1. User Level. This settings.xml file provides configuration for a single user, | and is normally provided in ${user.home}/.m2/settings.xml. | | NOTE: This location can be overridden with the CLI option: | | -s /path/to/user/settings.xml | | 2. Global Level. This settings.xml file provides configuration for all Maven | users on a machine (assuming they're all using the same Maven | installation). It's normally provided in | ${maven.conf}/settings.xml. | | NOTE: This location can be overridden with the CLI option: | | -gs /path/to/global/settings.xml | | The sections in this sample file are intended to give you a running start at | getting the most out of your Maven installation. Where appropriate, the default | values (values used when the setting is not specified) are provided. | |--> <settings xmlns="http://maven.apache.org/SETTINGS/1.2.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.2.0 https://maven.apache.org/xsd/settings-1.2.0.xsd"> <!-- localRepository | The path to the local repository maven will use to store artifacts. | | Default: ${user.home}/.m2/repository <localRepository>/path/to/local/repo</localRepository> --> <!-- interactiveMode | This will determine whether maven prompts you when it needs input. If set to false, | maven will use a sensible default value, perhaps based on some other setting, for | the parameter in question. | | Default: true <interactiveMode>true</interactiveMode> --> <!-- offline | Determines whether maven should attempt to connect to the network when executing a build. | This will have an effect on artifact downloads, artifact deployment, and others. | | Default: false <offline>false</offline> --> <!-- pluginGroups | This is a list of additional group identifiers that will be searched when resolving plugins by their prefix, i.e. | when invoking a command line like "mvn prefix:goal". Maven will automatically add the group identifiers | "org.apache.maven.plugins" and "org.codehaus.mojo" if these are not already contained in the list. |--> <pluginGroups> <!-- pluginGroup | Specifies a further group identifier to use for plugin lookup. <pluginGroup>com.your.plugins</pluginGroup> --> </pluginGroups> <!-- TODO Since when can proxies be selected as depicted? --> <!-- proxies | This is a list of proxies which can be used on this machine to connect to the network. | Unless otherwise specified (by system property or command-line switch), the first proxy | specification in this list marked as active will be used. |--> <proxies> <!-- proxy | Specification for one proxy, to be used in connecting to the network. | <proxy> <id>optional</id> <active>true</active> <protocol>http</protocol> <username>proxyuser</username> <password>proxypass</password> <host>proxy.host.net</host> <port>80</port> <nonProxyHosts>local.net|some.host.com</nonProxyHosts> </proxy> --> </proxies> <!-- servers | This is a list of authentication profiles, keyed by the server-id used within the system. | Authentication profiles can be used whenever maven must make a connection to a remote server. |--> <servers> <!-- server | Specifies the authentication information to use when connecting to a particular server, identified by | a unique name within the system (referred to by the 'id' attribute below). | | NOTE: You should either specify username/password OR privateKey/passphrase, since these pairings are | used together. | <server> <id>deploymentRepo</id> <username>repouser</username> <password>repopwd</password> </server> --> <!-- Another sample, using keys to authenticate. <server> <id>siteServer</id> <privateKey>/path/to/private/key</privateKey> <passphrase>optional; leave empty if not used.</passphrase> </server> --> </servers> <!-- mirrors | This is a list of mirrors to be used in downloading artifacts from remote repositories. | | It works like this: a POM may declare a repository to use in resolving certain artifacts. | However, this repository may have problems with heavy traffic at times, so people have mirrored | it to several places. | | That repository definition will have a unique id, so we can create a mirror reference for that | repository, to be used as an alternate download site. The mirror site will be the preferred | server for that repository. |--> <mirrors> <!-- mirror | Specifies a repository mirror site to use instead of a given repository. The repository that | this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used | for inheritance and direct lookup purposes, and must be unique across the set of mirrors. | <mirror> <id>mirrorId</id> <mirrorOf>repositoryId</mirrorOf> <name>Human Readable Name for this Mirror.</name> <url>http://my.repository.com/repo/path</url> </mirror> --> <!-- 阿里云中央仓库 --> <mirror> <!-- 镜像的唯一标识,maven 内部用,随便写但别重复 --> <id>aliyunmaven</id> <!-- 把 Maven 自带的"central"仓库(repo1.maven.org)全部重定向到阿里云 --> <mirrorOf>central</mirrorOf> <!-- 可读性名字,列表或报错时给人看 --> <name>阿里云公共仓库</name> <!-- 真实的镜像地址;注意你贴的那行有嵌套 <url> 标签,实际要写成纯文本 --> <url>https://maven.aliyun.com/repository/public</url> </mirror> </mirrors> <!-- profiles | This is a list of profiles which can be activated in a variety of ways, and which can modify | the build process. Profiles provided in the settings.xml are intended to provide local machine- | specific paths and repository locations which allow the build to work in the local environment. | | For example, if you have an integration testing plugin - like cactus - that needs to know where | your Tomcat instance is installed, you can provide a variable here such that the variable is | dereferenced during the build process to configure the cactus plugin. | | As noted above, profiles can be activated in a variety of ways. One way - the activeProfiles | section of this document (settings.xml) - will be discussed later. Another way essentially | relies on the detection of a property, either matching a particular value for the property, | or merely testing its existence. Profiles can also be activated by JDK version prefix, where a | value of '1.4' might activate a profile when the build is executed on a JDK version of '1.4.2_07'. | Finally, the list of active profiles can be specified directly from the command line. | | NOTE: For profiles defined in the settings.xml, you are restricted to specifying only artifact | repositories, plugin repositories, and free-form properties to be used as configuration | variables for plugins in the POM. | |--> <profiles> <!-- profile | Specifies a set of introductions to the build process, to be activated using one or more of the | mechanisms described above. For inheritance purposes, and to activate profiles via <activatedProfiles/> | or the command line, profiles have to have an ID that is unique. | | An encouraged best practice for profile identification is to use a consistent naming convention | for profiles, such as 'env-dev', 'env-test', 'env-production', 'user-jdcasey', 'user-brett', etc. | This will make it more intuitive to understand what the set of introduced profiles is attempting | to accomplish, particularly when you only have a list of profile id's for debug. | | This profile example uses the JDK version to trigger activation, and provides a JDK-specific repo. <profile> <id>jdk-1.4</id> <activation> <jdk>1.4</jdk> </activation> <repositories> <repository> <id>jdk14</id> <name>Repository for JDK 1.4 builds</name> <url>http://www.myhost.com/maven/jdk14</url> <layout>default</layout> <snapshotPolicy>always</snapshotPolicy> </repository> </repositories> </profile> --> <!-- | Here is another profile, activated by the property 'target-env' with a value of 'dev', which | provides a specific path to the Tomcat instance. To use this, your plugin configuration might | hypothetically look like: | | ... | <plugin> | <groupId>org.myco.myplugins</groupId> | <artifactId>myplugin</artifactId> | | <configuration> | <tomcatLocation>${tomcatPath}</tomcatLocation> | </configuration> | </plugin> | ... | | NOTE: If you just wanted to inject this configuration whenever someone set 'target-env' to | anything, you could just leave off the <value/> inside the activation-property. | <profile> <id>env-dev</id> <activation> <property> <name>target-env</name> <value>dev</value> </property> </activation> <properties> <tomcatPath>/path/to/tomcat/instance</tomcatPath> </properties> </profile> --> <profile> <id>jdk-25</id> <activation> <activeByDefault>true</activeByDefault> <jdk>25</jdk> </activation> <properties> <maven.compiler.source>25</maven.compiler.source> <maven.compiler.target>25</maven.compiler.target> <maven.compiler.compilerVersion>25</maven.compiler.compilerVersion> <maven.compiler.encoding>utf-8</maven.compiler.encoding> <project.build.sourceEncoding>utf-8</project.build.sourceEncoding> <project.reporting.outputEncoding>utf-8</project.reporting.outputEncoding> <maven.test.failure.ignore>true</maven.test.failure.ignore> <maven.test.skip>true</maven.test.skip> </properties> </profile> <profile> <id>jdk-21</id> <activation> <activeByDefault>true</activeByDefault> <jdk>21</jdk> </activation> <properties> <maven.compiler.source>21</maven.compiler.source> <maven.compiler.target>21</maven.compiler.target> <maven.compiler.compilerVersion>21</maven.compiler.compilerVersion> <maven.compiler.encoding>utf-8</maven.compiler.encoding> <project.build.sourceEncoding>utf-8</project.build.sourceEncoding> <project.reporting.outputEncoding>utf-8</project.reporting.outputEncoding> <maven.test.failure.ignore>true</maven.test.failure.ignore> <maven.test.skip>true</maven.test.skip> </properties> </profile> <profile> <id>jdk-17</id> <activation> <activeByDefault>true</activeByDefault> <jdk>17</jdk> </activation> <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> <maven.compiler.compilerVersion>17</maven.compiler.compilerVersion> <maven.compiler.encoding>utf-8</maven.compiler.encoding> <project.build.sourceEncoding>utf-8</project.build.sourceEncoding> <project.reporting.outputEncoding>utf-8</project.reporting.outputEncoding> <maven.test.failure.ignore>true</maven.test.failure.ignore> <maven.test.skip>true</maven.test.skip> </properties> </profile> <profile> <id>jdk-8</id> <activation> <activeByDefault>true</activeByDefault> <jdk>8</jdk> </activation> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <maven.compiler.compilerVersion>8</maven.compiler.compilerVersion> <maven.compiler.encoding>utf-8</maven.compiler.encoding> <project.build.sourceEncoding>utf-8</project.build.sourceEncoding> <project.reporting.outputEncoding>utf-8</project.reporting.outputEncoding> <maven.test.failure.ignore>true</maven.test.failure.ignore> <maven.test.skip>true</maven.test.skip> </properties> </profile> </profiles> <!-- activeProfiles | List of profiles that are active for all builds. | <activeProfiles> <activeProfile>alwaysActiveProfile</activeProfile> <activeProfile>anotherAlwaysActiveProfile</activeProfile> </activeProfiles> --> </settings> -
当前用户 maven 配置文件
bashmkdir $HOME/.m2bashcp -v $HOME/opt/maven/conf/settings.xml $HOME/.m2 -
激活编辑变量
bashsource ~/.profile
安装scala
-
下载
bashwget -P ~/opt https://github.com/scala/scala/releases/download/v2.13.18/scala-2.13.18.tgz
bash
tar -zxvf ~/opt/scala-2.13.18.tgz -C ~/opt
mv ~/opt/scala-2.13.18 ~/opt/scala-2-
配置环境变量,在
~/.profile末尾追加:bashexport SCALA_HOME=$HOME/opt/scala-2 export PATH=$PATH:$SCALA_HOME/bin -
激活编辑变量
bashsource ~/.profile
安装zookeeper
-
下载
bashwget -P ~/opt https://dlcdn.apache.org/zookeeper/zookeeper-3.9.5/apache-zookeeper-3.9.5-bin.tar.gz -
解压并修改目录名称
bashtar -zxvf ~/opt/apache-zookeeper-3.9.5-bin.tar.gz -C ~/opt mv ~/opt/apache-zookeeper-3.9.5-bin ~/opt/zookeeper-3 -
配置环境变量,在
~/.profile末尾追加:bashexport ZOOKEEPER_HOME=$HOME/opt/zookeeper-3 export PATH=$PATH:$ZOOKEEPER_HOME/bin -
激活编辑变量
bashsource ~/.profile
安装hadoop
-
下载
bashwget -P ~/opt https://dlcdn.apache.org/hadoop/common/hadoop-3.5.0/hadoop-3.5.0.tar.gz -
解压并修改目录名称
bashtar -zxvf ~/opt/hadoop-3.5.0.tar.gz -C ~/opt mv ~/opt/hadoop-3.5.0 ~/opt/hadoop-3 -
配置环境变量,在
~/.profile末尾追加:bashexport HDFS_NAMENODE_USER=lhz export HDFS_SECONDARYNAMENODE_USER=lhz export HDFS_DATANODE_USER=lhz export HDFS_ZKFC_USER=lhz export HDFS_JOURNALNODE_USER=lhz export HADOOP_SHELL_EXECNAME=lhz export YARN_RESOURCEMANAGER_USER=lhz export YARN_NODEMANAGER_USER=lhz export HADOOP_HOME=$HOME/opt/hadoop-3 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
激活编辑变量
bashsource ~/.profile
1.8 完整环境变量
bash
export NODE_HOME=$HOME/opt/node-v24
export JAVA_HOME=$HOME/opt/jdk-25
export MAVEN_HOME=$HOME/opt/maven
export SCALA_HOME=$HOME/opt/scala-2
export ZOOKEEPER_HOME=$HOME/opt/zookeeper-3
export HDFS_NAMENODE_USER=lhz
export HDFS_SECONDARYNAMENODE_USER=lhz
export HDFS_DATANODE_USER=lhz
export HDFS_ZKFC_USER=lhz
export HDFS_JOURNALNODE_USER=lhz
export HADOOP_SHELL_EXECNAME=lhz
export YARN_RESOURCEMANAGER_USER=lhz
export YARN_NODEMANAGER_USER=lhz
export HADOOP_HOME=$HOME/opt/hadoop-3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$NODE_HOME/bin:$JAVA_HOME/bin:$MAVEN_HOME/bin:$SCALA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin2. zookeeper
2.1 编辑配置文件
bash
rm -rf $ZOOKEEPER_HOME/docs
bash
cd $ZOOKEEPER_HOME/conf
bash
vim zoo.cfg注释版:不推荐使用
bash
# 心跳单位,2s
tickTime=2000
# zookeeper-3初始化的同步超时时间,10个心跳单位,也即20s
initLimit=10
# 普通同步:发送一个请求并得到响应的超时时间,5个心跳单位也即10s
syncLimit=5
# 内存快照数据的存储位置
dataDir=/home/lhz/data/zookeeper-3/data
# 事务日志的存储位置
dataLogDir=/home/lhz/data/zookeeper-3/datalog
# 当前zookeeper-3节点的端口
clientPort=2181
# 单个客户端到集群中单个节点的并发连接数,通过ip判断是否同一个客户端,默认60
maxClientCnxns=1000
# 保留7个内存快照文件在dataDir中,默认保留3个
autopurge.snapRetainCount=7
# 清除快照的定时任务,默认1小时,如果设置为0,标识关闭清除任务
autopurge.purgeInterval=1
#允许客户端连接设置的最小超时时间,默认2个心跳单位
minSessionTimeout=4000
#允许客户端连接设置的最大超时时间,默认是20个心跳单位,也即40s,
maxSessionTimeout=300000
#zookeeper-3 3.5.5启动默认会把AdminService服务启动,这个服务默认是8080端口
admin.serverPort=9001
#集群地址配置
server.1=lihaozhe01:2888:3888
server.2=lihaozhe02:2888:3888
server.3=lihaozhe03:2888:3888纯净版:推荐使用
bash
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/lhz/data/zookeeper-3/data
dataLogDir=/home/lhz/data/zookeeper-3/datalog
clientPort=2181
maxClientCnxns=1000
autopurge.snapRetainCount=7
autopurge.purgeInterval=1
minSessionTimeout=4000
maxSessionTimeout=300000
admin.serverPort=9001
server.1=lihaozhe01:2888:3888
server.2=lihaozhe02:2888:3888
server.3=lihaozhe03:2888:38882.2 保存后根据配置文件创建目录
在每台服务器上执行
bash
mkdir -p /home/lhz/data/zookeeper-3/data /home/lhz/data/zookeeper-3/datalog2.3 myid
lihaozhe01
bash
echo 1 > /home/lhz/data/zookeeper-3/data/myid
more /home/lhz/data/zookeeper-3/data/myidlihaozhe02
bash
echo 2 > /home/lhz/data/zookeeper-3/data/myid
more /home/lhz/data/zookeeper-3/data/myidlihaozhe03
bash
echo 3 > /home/lhz/data/zookeeper-3/data/myid
more /home/lhz/data/zookeeper-3/data/myid2.4 编写zookeeper-3开机启动脚本
在/etc/systemd/system/文件夹下创建一个启动脚本zookeeper-3.service
注意:在每台服务器上编写
bash
cd /etc/systemd/system
sudo vim zookeeper.service内容如下:
bash
[Unit]
Description=zookeeper
After=syslog.target network.target
[Service]
Type=forking
Environment=ZOO_LOG_DIR=/home/lhz/data/zookeeper-3/datalog
Environment=JAVA_HOME=/home/lhz/opt/jdk-25
ExecStart=/home/lhz/opt/zookeeper-3/bin/zkServer.sh start
ExecStop=/home/lhz/opt/zookeeper-3/bin/zkServer.sh stop
Restart=always
User=lhz
Group=lhz
[Install]
WantedBy=multi-user.target
bash
sudo systemctl daemon-reload
# 等所有主机配置好后再执行以下命令
sudo systemctl start zookeeper
sudo systemctl enable zookeeper
sudo systemctl status zookeeper3. hadoop
bash
rm -rf $HADOOP_HOME/share/doc修改配置文件
bash
cd $HADOOP_HOME/etc/hadoop
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- workers
- mapred-site.xml
- yarn-site.xml
hadoop-env.sh 文件末尾追加
bash
# =========================================================================== #
# 以下为用户自定义环境变量
# 优先级: 各 xxx-env.sh > 本文件 > 内置默认值
# =========================================================================== #
# ------------------------------ Java 环境 ------------------------------
# JDK 安装路径 (所有节点必须一致)
export JAVA_HOME=/home/lhz/opt/jdk-25
# JNI/Hadoop native 库搜索路径, 指向 ${HADOOP_HOME}/lib/native
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
# ------------------------------ 通用日志 ------------------------------
# HDFS/YARN/MR 各类守护进程的日志统一存这里
export HADOOP_LOG_DIR=/home/lhz/data/hadoop/logs
# ------------------------------ HDFS 运行用户 ------------------------------
# 无 Kerberos 时必须显式声明, 否则 start-dfs.sh 会以 root 拉起 (不推荐)
# 要求: 各节点均存在同名用户, 并能在节点间免密 SSH
export HDFS_NAMENODE_USER=lhz
export HDFS_SECONDARYNAMENODE_USER=lhz
export HDFS_DATANODE_USER=lhz
export HDFS_ZKFC_USER=lhz
export HDFS_JOURNALNODE_USER=lhz
# Shell 子命令 (hdfs/yarn/mapred) 的执行用户
export HADOOP_SHELL_EXECNAME=lhz
# ------------------------------ YARN 运行用户 ------------------------------
export YARN_RESOURCEMANAGER_USER=lhz
export YARN_NODEMANAGER_USER=lhz
# =========================================================================== #
# 以下为各守护进程 JVM 堆内存配置
# 调优依据 (硬件: 4 vCPU / 7.2 GiB RAM, HA 三节点):
# a) NameNode/ResourceManager: 元数据/资源调度, 内存占用大, 各 1~2 GB
# b) DataNode/NodeManager/JournalNode/ZKFC: 转发型, 512 MB 足够
# c) SecondaryNameNode: HA 集群中不需要, 若启用堆设为 512 MB
# d) 所有 Xmx 之和 (NN+2NN+DN+ZKFC+JN+RM+NM ≈ 6 GB) 不得超过物理内存,
# 否则启动时 JVM 会自动降级或被 OOM Killer 杀掉
# 注: HADOOP_GC_SETTINGS 用于统一 GC 日志, 可选
# =========================================================================== #
# 通用 GC 日志 (NameNode/ResourceManager 较常用)
export HADOOP_GC_SETTINGS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps"
# --- NameNode ---
# 调优依据: 元数据全部驻堆, 至少 1 GB 起; 测试集群给 2 GB 足够, 生产建议 8 GB+
export HDFS_NAMENODE_OPTS="-Xms1g -Xmx2g $HADOOP_GC_SETTINGS"
# --- SecondaryNameNode (HA 集群可关闭, 仍保留配置) ---
export HDFS_SECONDARYNAMENODE_OPTS="-Xms512m -Xmx1g"
# --- DataNode ---
# 调优依据: 仅做块存储转发, 512 MB 够用
export HDFS_DATANODE_OPTS="-Xms256m -Xmx512m"
# --- JournalNode ---
export HDFS_JOURNALNODE_OPTS="-Xms256m -Xmx512m"
# --- ZKFC (DFS/ZK Failover Controller) ---
export HDFS_ZKFC_OPTS="-Xms256m -Xmx512m"
# --- ResourceManager ---
# 调优依据: 资源调度状态全在堆里, 与 NN 同级
export YARN_RESOURCEMANAGER_OPTS="-Xms1g -Xmx2g $HADOOP_GC_SETTINGS"
# --- NodeManager ---
# 调优依据: NM 资源池限制 3072 MB, 自身常驻 512 MB 后还剩 2.5 GB 给容器
export YARN_NODEMANAGER_OPTS="-Xms256m -Xmx512m"
# --- JobHistory Server ---
export MAPRED_HISTORYSERVER_OPTS="-Xms512m -Xmx1g"core-site.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!--
core-site.xml Hadoop 集群级公共配置 (HDFS/YARN/MR 都读取)
加载顺序: core-default.xml < 本文件 < 命令行 -D 参数
-->
<configuration>
<!-- 一、文件系统入口 -->
<!--
默认文件系统的 URI, 客户端读 / 写 / ls 缺省会走这里
HA 集群必须写命名空间名 (lihaozhe), 不要写具体 nn1/nn2
端口 8020 为 NameNode RPC 默认端口
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://lihaozhe:8020</value>
</property>
<!-- 二、本地工作目录 -->
<!--
Hadoop 运行期临时目录, 用于存放:
- NameNode fsimage / edits 草稿
- DataNode 块数据 (若未单独配置 dfs.datanode.data.dir)
- YARN NM 本地目录 (若未单独配置 yarn.nodemanager.local-dirs)
- 各种 pid / 临时上传文件
一律放在 HADOOP_CONF_DIR 同级之上, 避免与安装目录冲突
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/lhz/data/hadoop</value>
</property>
<!-- 三、HA / Zookeeper 协调服务 -->
<!--
Zookeeper 仲裁节点, 用于:
1. NameNode 自动故障转移 (dfs.ha.automatic-failover.enabled=true)
2. YARN ResourceManager HA
必须为奇数台, 推荐 3/5 台
-->
<property>
<name>ha.zookeeper.quorum</name>
<value>lihaozhe01:2181,lihaozhe02:2181,lihaozhe03:2181</value>
</property>
<!-- 四、安全 & 权限 -->
<!--
是否启用 HDFS 权限检查 (POSIX ACL)
生产环境务必 true; 测试/学习环境为了减少干扰可设为 false
-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--
Web UI 静态访问用户:
当浏览器匿名访问 HDFS / MR / YARN 的 Web 页面时,
远端请求会以该用户身份执行, 用于在页面上查看文件/作业
-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>lhz</value>
</property>
<!--
五、超级代理用户 (Hive / Oozie / Spark 等 doAS 依赖)
Hadoop 默认拒绝超级用户之外的 doAS, 这里给 lhz 开后门
-->
<!-- 允许 lhz 从哪些主机代理: * 表示任意主机 -->
<property>
<name>hadoop.proxyuser.lhz.hosts</name>
<value>*</value>
</property>
<!-- 允许 lhz 代理到哪些用户组: * 表示任意组 -->
<property>
<name>hadoop.proxyuser.lhz.groups</name>
<value>*</value>
</property>
<!-- 允许 lhz 代理为哪些用户: * 表示任意用户 -->
<property>
<name>hadoop.proxyuser.lhz.users</name>
<value>*</value>
</property>
</configuration>hdfs-site.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!--
hdfs-site.xml NameNode / DataNode / JournalNode / ZKFC 配置
加载顺序: hdfs-default.xml < 本文件 < 命令行 -D 参数
-->
<configuration>
<!-- 一、HA 命名空间与 NameNode 实例 -->
<!--
命名空间逻辑名, 客户端连接 & RPC 寻址的逻辑入口
同一个 nameservices 下可以有多个 namenode 实例做 HA
-->
<property>
<name>dfs.nameservices</name>
<value>lihaozhe</value>
</property>
<!-- nameservices=lihaozhe 下的 NameNode 实例 id 列表 至少 2 个, 通常命名为 nn1/nn2 -->
<property>
<name>dfs.ha.namenodes.lihaozhe</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 的 RPC 地址: 客户端写元数据走这里 -->
<property>
<name>dfs.namenode.rpc-address.lihaozhe.nn1</name>
<value>lihaozhe01:8020</value>
</property>
<!-- nn2 的 RPC 地址 -->
<property>
<name>dfs.namenode.rpc-address.lihaozhe.nn2</name>
<value>lihaozhe02:8020</value>
</property>
<!-- nn1 的 HTTP (Web UI) 地址 -->
<property>
<name>dfs.namenode.http-address.lihaozhe.nn1</name>
<value>lihaozhe01:9870</value>
</property>
<!-- nn2 的 HTTP (Web UI) 地址 -->
<property>
<name>dfs.namenode.http-address.lihaozhe.nn2</name>
<value>lihaozhe02:9870</value>
</property>
<!-- 二、共享存储 (QJM) -->
<!--
edits 日志共享目录, 走 QJM 协议:
qjournal://host1:port;host2:port;host3:port/<nameserviceId>
推荐 3 台, 写时过半即可, 容忍 1 台宕机
-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://lihaozhe01:8485;lihaozhe02:8485;lihaozhe03:8485/lihaozhe</value>
</property>
<!-- JournalNode 磁盘目录, 每台 JNode 都要有, 本地路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/lhz/data/hadoop/journalnode/data</value>
</property>
<!-- 三、故障转移 (Failover) -->
<!-- 是否启用自动故障转移 (依赖 Zookeeper) 设为 true 时 NN 启动会向 ZK 注册, ZKFC 负责主备切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 客户端使用的 RPC 代理实现: 基于配置的轮询选取 NN -->
<property>
<name>dfs.client.failover.proxy.provider.lihaozhe</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- Fencing 方法: 切换时把旧 NN 踢下台, 防止脑裂 sshfence 表示 SSH 到旧 NN 执行 fuser -k 杀掉相应端口 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- sshfence 使用的私钥: 要求 HDFS 用户免密 SSH 到所有 NN 节点 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/lhz/.ssh/id_rsa</value>
</property>
<!-- 四、安全模式阈值 -->
<!--
NN 退出安全模式的最小副本满足率 (0, 1]
1f = 必须 100% 副本就绪才退出 (测试环境常用)
默认 0.999f
影响: 启动速度 / 数据写入时的可用副本数判断
-->
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>1f</value>
</property>
<!--
五、副本与块大小 (测试环境调优)
优化依据 (硬件: 4 vCPU / 7.2 GiB / 80 G 磁盘):
a) dfs.replication=1: 单节点测试不需要 3 副本, 省 2/3 磁盘
b) dfs.blocksize=64MB: 数据集小, 减小块大小可让更多 Map 并行
c) handler.count 与线程数对齐, 避免 RPC 队列堆积
-->
<!-- 文件副本数 (测试环境 1, 生产建议 3) -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- HDFS 块大小 (字节), 64 MB 适合小数据集 -->
<property>
<name>dfs.blocksize</name>
<value>67108864</value>
</property>
<!-- NameNode RPC Server 的工作线程数, 4 vCPU 节点足够 -->
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
<!-- DataNode RPC Server 的工作线程数 -->
<property>
<name>dfs.datanode.handler.count</name>
<value>10</value>
</property>
</configuration>workers
bash
# =============================================================
# DataNode / NodeManager 节点列表
# 作用:
# start-dfs.sh 启动时会 SSH 到这里列出的每一台主机拉起 DataNode;
# start-yarn.sh 同理拉起 NodeManager
# 注意: 每一行一个主机名/IP, 不要有空行, 不要有注释行混在中间
# =============================================================
lihaozhe01
lihaozhe02
lihaozhe03mapred-site.xml
xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<!-- mapred-site.xml MapReduce on YARN (MRv2/YARN) 配置
加载顺序: mapred-default.xml < 本文件
-->
<configuration>
<!-- 一、执行框架 -->
<!--
MR 的执行框架:
local = 本地模式, 单 JVM 内跑 (调试)
classic = MRv1 经典模式 (已废弃)
yarn = 跑在 YARN 上 (生产唯一选项)
-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR 应用 classpath: YARN 启动 AM/Map/Reduce 容器时加载的 JAR 必须显式列出, 否则会出现 ClassNotFoundException -->
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<!--
二、任务内存
必须满足:
yarn.scheduler.minimum-allocation-mb (512)
mapreduce.{map|reduce}.memory.mb
yarn.scheduler.maximum-allocation-mb (3072)
优化依据 (硬件: 7.2 GiB RAM, NM 资源池 3072 MB):
- 容器 512 MB 可让 3 G 资源池同时跑 ~6 个并发 Map, 提升小作业吞吐
- 容器 1024 MB 留给 Reduce (Shuffle/排序阶段更耗内存)
-->
<!-- 每个 Map Task 容器申请的内存 (MB) -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>512</value>
</property>
<!-- 每个 Reduce Task 容器申请的内存 (MB)
Reduce 阶段 Shuffle/Sort 内存开销大, 保持 1024 MB -->
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
</property>
<!-- 三、JobHistory Server 用于保存已完成的作业历史, Web UI 可查询历史作业信息 -->
<!-- JobHistory Server 的 RPC 监听地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>lihaozhe01:10020</value>
</property>
<!-- JobHistory Server 的 Web UI 地址 浏览器访问 http://lihaozhe01:19888 查看历史作业 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>lihaozhe01:19888</value>
</property>
</configuration>yarn-site.xml
xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- yarn-site.xml ResourceManager / NodeManager 配置 加载顺序: yarn-default.xml < 本文件 -->
<configuration>
<!-- 一、NodeManager 容器 Java 环境 -->
<!--
YARN 容器内执行 Java 任务的 java 可执行文件绝对路径
必须每个 NM 节点上此路径都可用, 否则 AM/Map/Reduce 启动失败
-->
<property>
<name>yarn.nodemanager.java.path</name>
<value>/home/lhz/opt/jdk-25/bin/java</value>
</property>
<!-- 二、ResourceManager HA -->
<!-- 是否启用 RM 高可用 (主备切换) -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- RM 集群逻辑名, 同一集群内唯一 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!-- 本集群内的 RM 实例 id 列表 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- rm1 主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>lihaozhe01</value>
</property>
<!-- rm2 主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>lihaozhe02</value>
</property>
<!-- rm1 的 Web UI 地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>lihaozhe01:8088</value>
</property>
<!-- rm2 的 Web UI 地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>lihaozhe02:8088</value>
</property>
<!-- RM HA 选举所用的 ZK 集群地址, 与 core-site 中 ha.zookeeper.quorum 一致 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>lihaozhe01:2181,lihaozhe02:2181,lihaozhe03:2181</value>
</property>
<!-- 三、NodeManager 通用设置 -->
<!--
容器环境变量白名单: 允许从客户端/NM 传递到容器内的环境变量
没列进去的环境变量在容器里看不到, 否则会被 strip 掉
常用 JAVA_HOME / HADOOP_HOME / PATH 必须放进去
-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<!--
NM 上的辅助服务:
mapreduce_shuffle = MR ShuffleHandler (MR 必选)
spark_shuffle = Spark 必选
可逗号分隔多个
-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 四、MapReduce 容器环境变量 (YARN 启动时注入) 这里给出 JDK 与 HADOOP_HOME, 避免容器内脚本找不到 java -->
<!-- ApplicationMaster (AM) 启动时容器内环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>JAVA_HOME=/home/lhz/opt/jdk-25,HADOOP_MAPRED_HOME=/home/lhz/opt/hadoop-3</value>
</property>
<!--
ApplicationMaster JVM 启动参数 (-Xmx)
调优依据: AM 申请 container=1024 MB, JVM 堆不宜占满, 留 256 MiB 给 JVM 自身/本地库
-->
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx768m</value>
</property>
<!-- Map Task 容器内环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>JAVA_HOME=/home/lhz/opt/jdk-25,HADOOP_MAPRED_HOME=/home/lhz/opt/hadoop-3</value>
</property>
<!-- Reduce Task 容器内环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>JAVA_HOME=/home/lhz/opt/jdk-25,HADOOP_MAPRED_HOME=/home/lhz/opt/hadoop-3</value>
</property>
<!--
五、调度器资源 (内存 / CPU)
优化依据 (硬件: 4 vCPU / 7.2 GiB RAM / 三节点 HA):
a) NM 进程自身常驻 ~500 MiB; OS + ZK + JournalNode 共用至少 1 GiB
=> NM 资源池控制在 3 GiB (3072 MB), 给系统留 ~4 GiB 缓冲
b) 内存分配必须满足:
yarn.scheduler.minimum-allocation-mb
<= container_request_memory (mapreduce.map/reduce.memory.mb)
<= yarn.scheduler.maximum-allocation-mb
<= yarn.nodemanager.resource.memory-mb
c) CPU 显式声明, 避免按物理核自动分配造成 NM 进程过载
-->
<!--
单台 NM 能分配给所有容器的物理内存总量 (MB)
调优依据: 7.2 GiB 物理内存 - 1 GiB (OS/ZK/JN) - 0.5 GiB (NM/AM 常驻) ≈ 3 GiB
-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
</property>
<!-- 单个容器最少可申请内存 (MB) 调为 512 让小作业也能灵活调度; 若保持 1024, 3 G 池只能跑 3 个容器 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 单个容器最多可申请内存 (MB), 不能超过 NM 总资源 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3072</value>
</property>
<!-- 单台 NM 能分配给所有容器的 CPU 虚拟核数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 单个容器最少可申请 CPU 核数 -->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<!-- 单个容器最多可申请 CPU 核数 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>4</value>
</property>
<!-- 六、内存超限检查 (测试环境建议关闭) -->
<!-- 是否检测容器物理内存超限, 超限则 kill 测试环境常设为 false, 避免误杀容器 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否检测容器虚拟内存超限 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 七、日志聚集 任务结束后把容器日志上传到 HDFS 统一目录, 便于查询 -->
<!-- 启用日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- HDFS 上日志保留时长 (秒), 默认 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- Web UI 上"查看日志"链接的跳转地址 (JobHistory Server) -->
<property>
<name>yarn.log.server.url</name>
<value>http://lihaozhe:19888/jobhistory/logs</value>
</property>
</configuration>4. 配置ssh免密钥登录
创建本地秘钥并将公共秘钥写入认证文件
bash
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
bash
ssh-copy-id lhz@lihaozhe01
bash
ssh-copy-id lhz@lihaozhe02
bash
ssh-copy-id lhz@lihaozhe035. 分发密钥
bash
scp -r ~/.ssh/ lhz@lihaozhe02:~/
scp -r ~/.ssh/ lhz@lihaozhe03:~/6. 分发并激活环境变量
bash
scp -r ~/.profile lhz@lihaozhe02:~/
scp -r ~/.profile lhz@lihaozhe03:~/在各节点执行以下命令
bash
source ~/.profile分发 hadoop
bash
scp -rv ~/opt/hadoop-3 lhz@lihaozhe02:~/opt
scp -rv ~/opt/hadoop-3 lhz@lihaozhe03:~/opt如果其它节点已经安装了hadoop那么只分发配置文件即可
bash
scp -rv ~/opt/hadoop-3/etc/hadoop lhz@lihaozhe02:~/opt/hadoop-3/etc
scp -rv ~/opt/hadoop-3/etc/hadoop lhz@lihaozhe03:~/opt/hadoop-3/etc7. 启动zookeeper
7.1 myid
lihaozhe01
bash
echo 1 > /home/lhz/data/zookeeper-3/data/myid
more /home/lhz/data/zookeeper-3/data/myidlihaozhe02
bash
echo 2 > /home/lhz/data/zookeeper-3/data/myid
more /home/lhz/data/zookeeper-3/data/myidlihaozhe03
bash
echo 3 > /home/lhz/data/zookeeper-3/data/myid
more /home/lhz/data/zookeeper-3/data/myid7.2 启动服务
在各节点执行以下命令
bash
sudo systemctl daemon-reload
sudo systemctl start zookeeper
sudo systemctl enable zookeeper
sudo systemctl status zookeeper7.3 验证
bash
jps
bash
zkServer.sh status8. Hadoop初始化
bash
1. 启动三个zookeeper:zkServer.sh start
2. 启动三个JournalNode:
hadoop-daemon.sh start journalnode 或者 hdfs --daemon start journalnode
3. 在其中一个namenode上格式化:hdfs namenode -format
4. 把刚刚格式化之后的元数据拷贝到另外一个namenode上
a) 启动刚刚格式化的namenode :
hadoop-daemon.sh start namenode 或者 hdfs --daemon start namenode
b) 在没有格式化的namenode上执行:hdfs namenode -bootstrapStandby
c) 启动第二个namenode:
hadoop-daemon.sh start namenode 或者 hdfs --daemon start namenode
5. 在其中一个namenode上初始化 hdfs zkfc -formatZK
6. 停止上面节点:stop-dfs.sh
7. 全面启动:start-all.sh
8. 启动resourcemanager节点
yarn-daemon.sh start resourcemanager 或者 start-yarn.sh
http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.5.0.tar
不需要执行第 8 步
9. 启动历史服务
mapred --daemon start historyserver
10 11 12 不需要执行
10、安全模式
hdfs dfsadmin -safemode enter
hdfs dfsadmin -safemode leave
11、查看哪些节点是namenodes并获取其状态
hdfs getconf -namenodes
hdfs haadmin -getServiceState lihaozhe01
12、强制切换状态
hdfs haadmin -transitionToActive --forcemanual lihaozhe01重点提示:
bash
# 关机之前 依关闭服务
stop-yarn.sh
stop-dfs.sh
# 开机后 依次开启服务
start-dfs.sh
start-yarn.sh或者
bash
# 关机之前关闭服务
stop-all.sh
# 开机后开启服务
start-all.sh
bash
#jps 检查进程正常后开启胡哦关闭在再做其它操作9.重名名启动关闭脚本
便于与日后 spark 集群 启动脚本名称重复 修复启动和关闭脚本
bash
mv $HADOOP_HOME/sbin/start-all.sh $HADOOP_HOME/sbin/start-hadoop.sh
mv $HADOOP_HOME/sbin/stop-all.sh $HADOOP_HOME/sbin/stop-hadoop.sh 分发到其它节点
bash
scp $HADOOP_HOME/sbin/start-hadoop.sh lhz@lihaozhe02:$HADOOP_HOME/sbin
scp $HADOOP_HOME/sbin/stop-hadoop.sh lhz@lihaozhe02:$HADOOP_HOME/sbin
scp $HADOOP_HOME/sbin/start-hadoop.sh lhz@lihaozhe03:$HADOOP_HOME/sbin
scp $HADOOP_HOME/sbin/stop-hadoop.sh lhz@lihaozhe03:$HADOOP_HOME/sbin10. 修改windows下hosts文件
C:\Windows\System32\drivers\etc\hosts
追加以下内容:
bash
192.168.11.101 lihaozhe01
192.168.11.102 lihaozhe02
192.168.11.103 lihaozhe03Windows11 注意 修改权限
- 开始搜索 cmd
找到命令头提示符 以管理身份运行
-
进入 C:\Windows\System32\drivers\etc 目录
cmdcd drivers/etc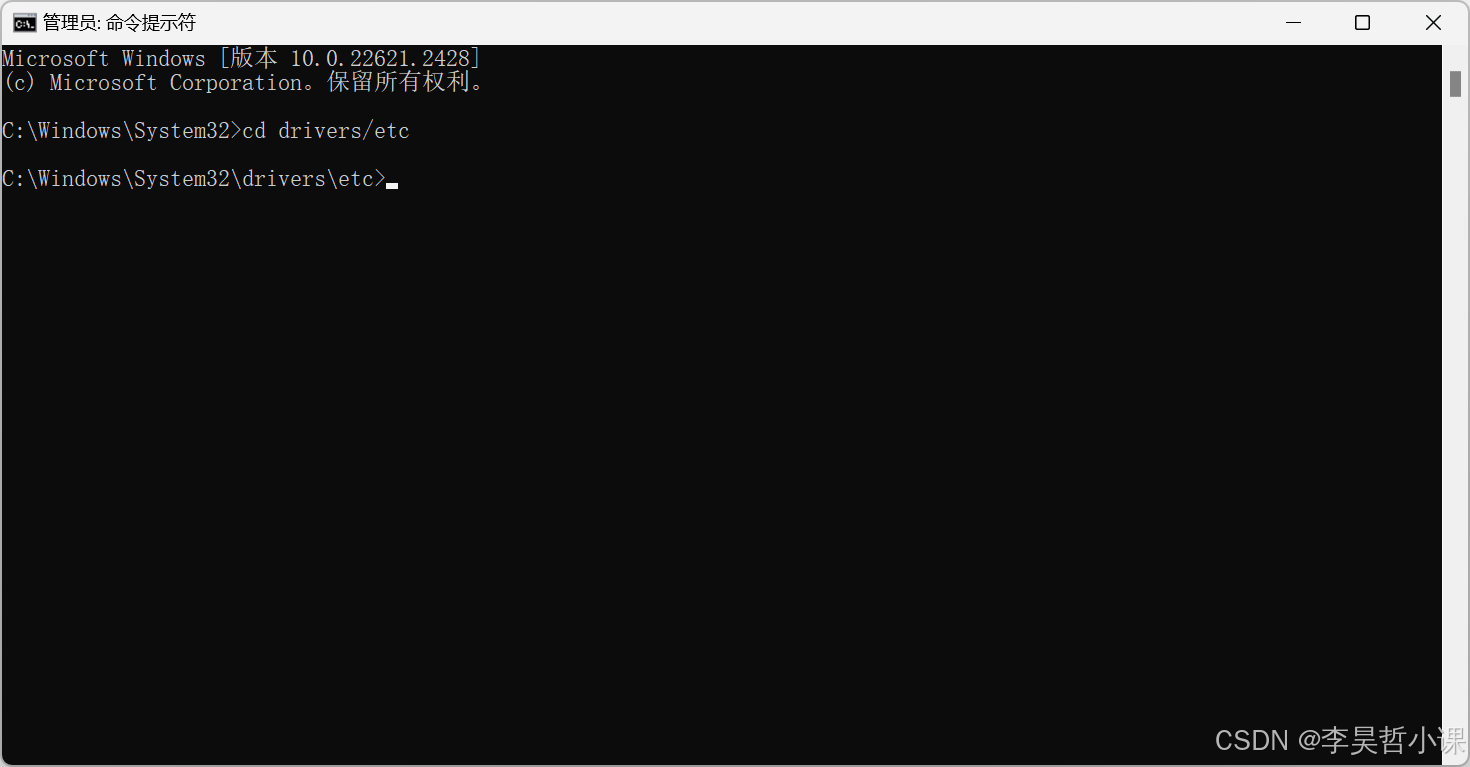
-
去掉 hosts文件只读属性
cmdattrib -r hosts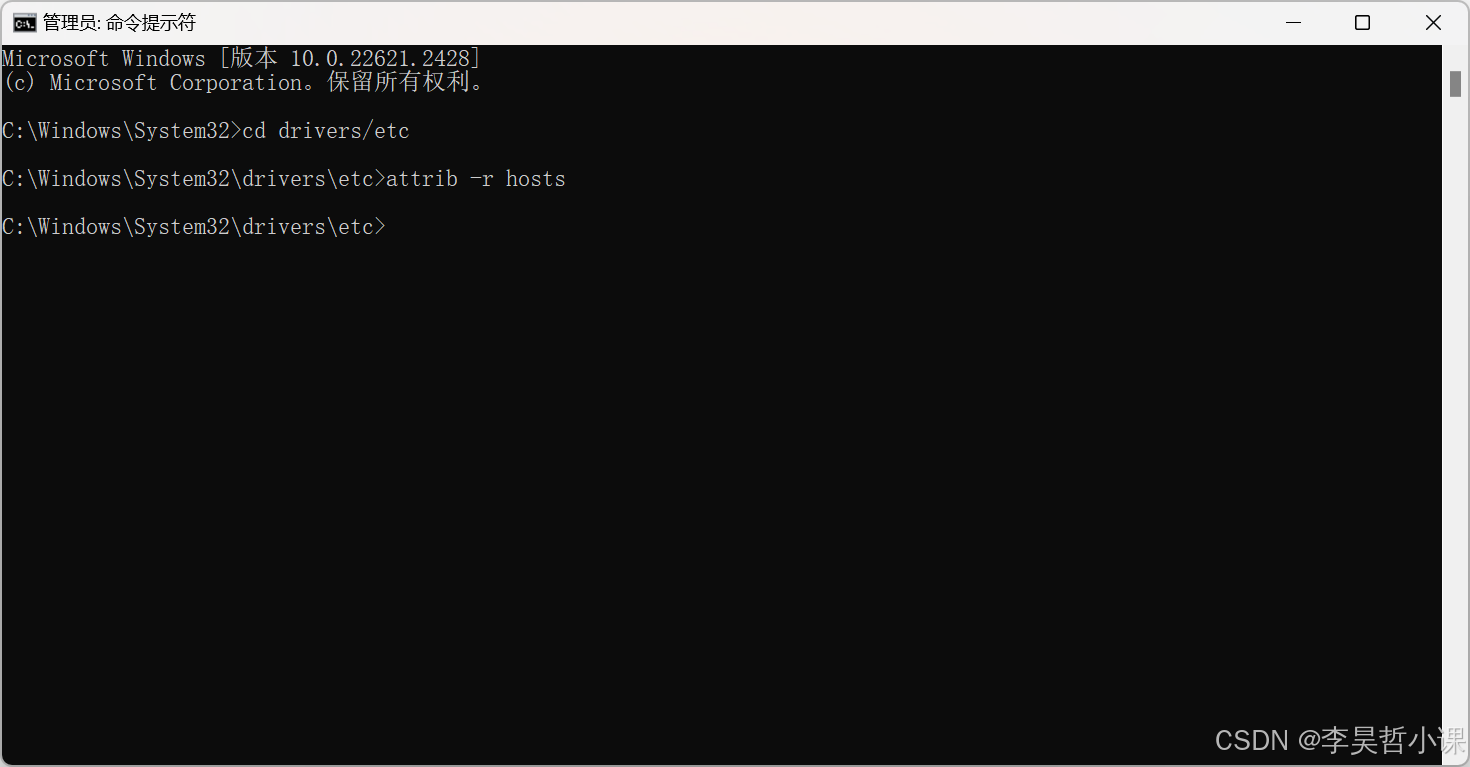
-
打开 hosts 配置文件
cmdstart hosts
-
追加以下内容后保存
bash192.168.11.101 lihaozhe01 192.168.11.102 lihaozhe02 192.168.11.103 lihaozhe03
11. 测试
11.1 浏览器访问hadoop集群
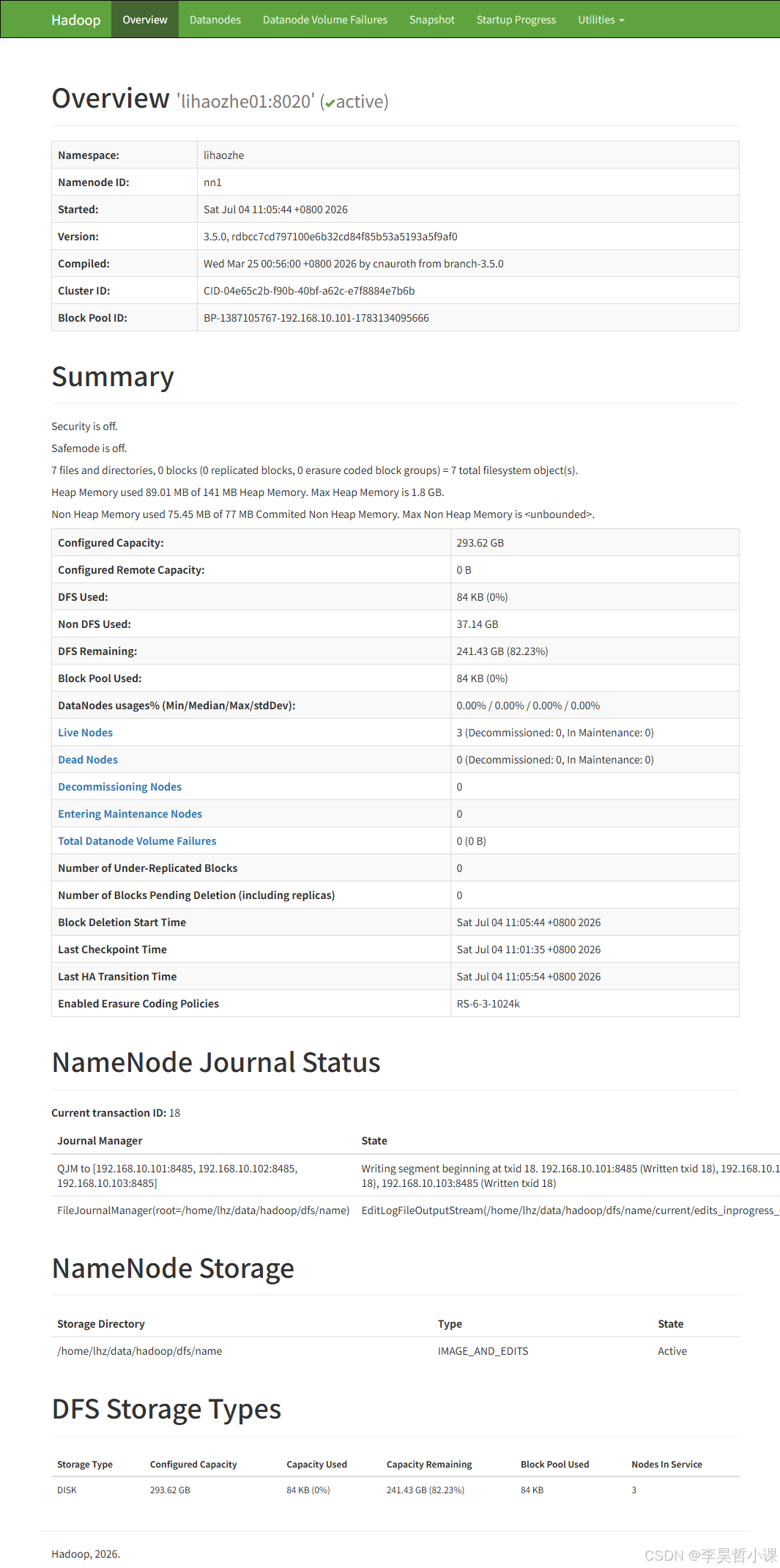
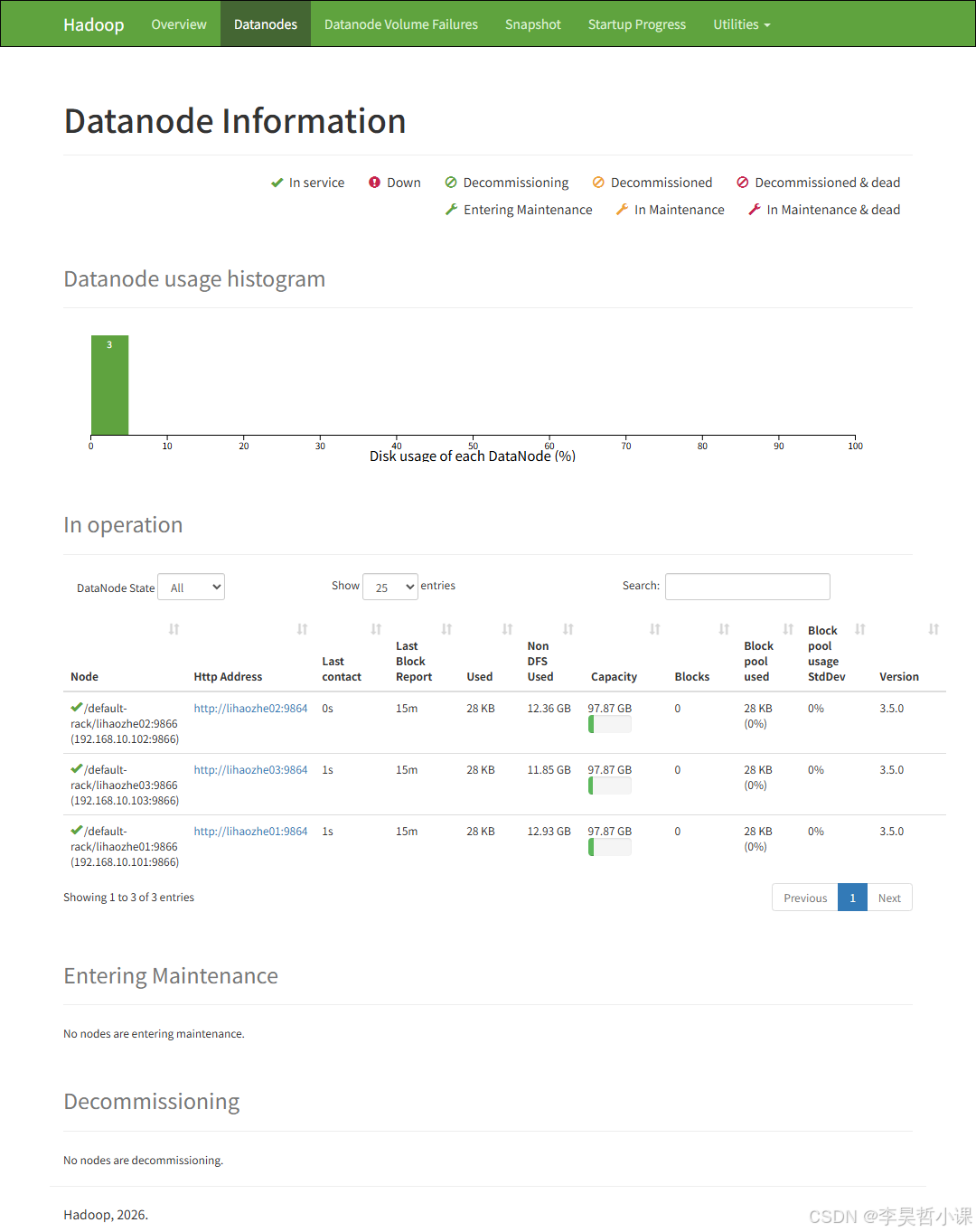
浏览器访问: http://lihaozhe01:9870
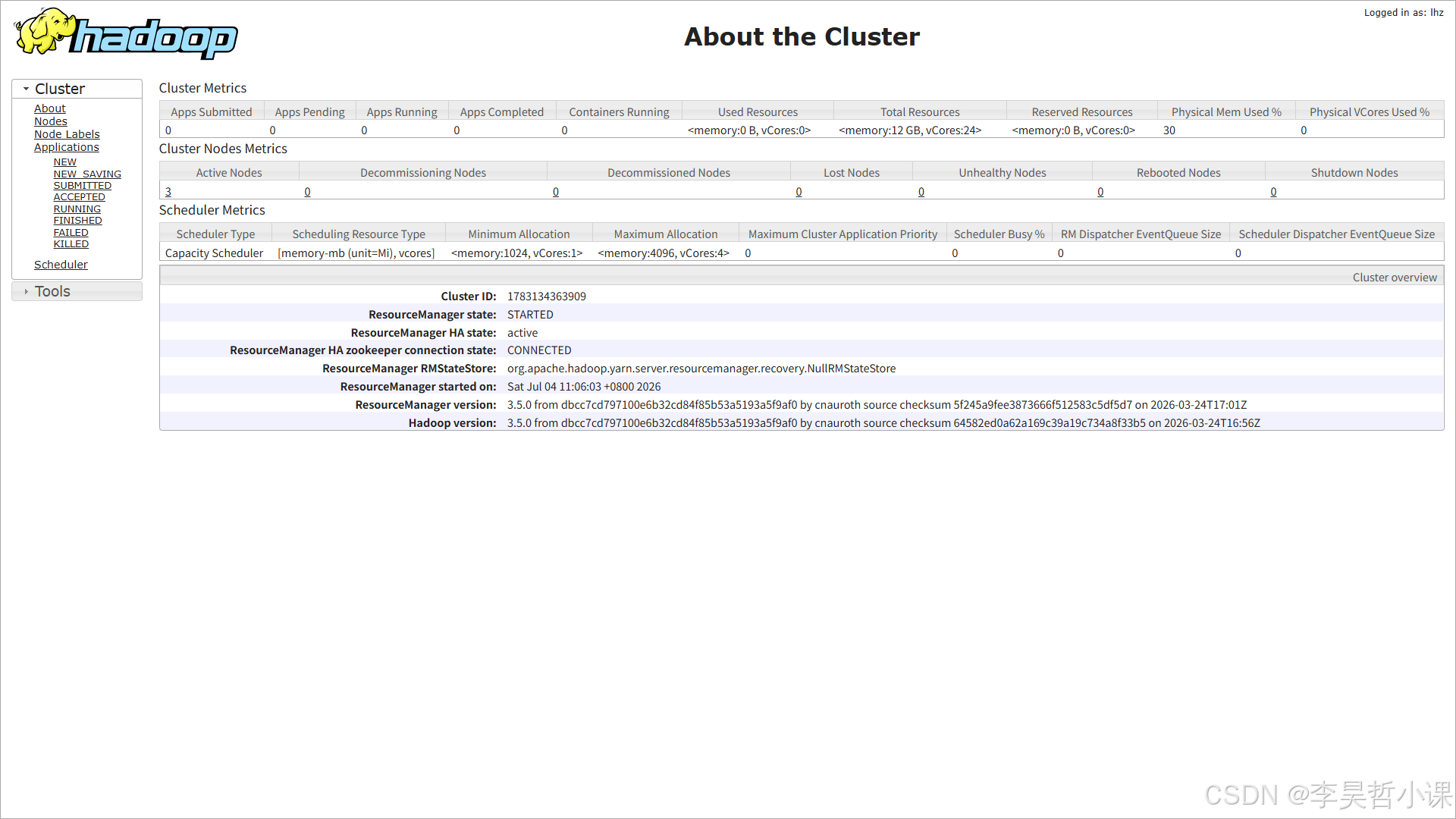
浏览器访问:http://lihaozhe01:8088
浏览器访问:http://lihaozhe01:19888
11.2 测试 hdfs
本地文件系统创建 测试文件 wcdata.txt
bash
vim wcdata.txt
bash
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop lihaozhe HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
lihaozhe HBaseHive Flink
Storm Hadoop HBase lihaozheFlinkHBase
StormHBase Hadoop Hive在 HDFS 上创建目录 /wordcount/input
bash
hdfs dfs -mkdir -p /wordcount/input查看 HDFS 目录结构
bash
hdfs dfs -ls /
bash
hdfs dfs -ls /wordcount
bash
hdfs dfs -ls /wordcount/input上传本地测试文件 wcdata.txt 到 HDFS 上 /wordcount/input
bash
hdfs dfs -put wcdata.txt /wordcount/input检查文件是否上传成功
bash
hdfs dfs -ls /wordcount/input
bas
hdfs dfs -cat /wordcount/input/wcdata.txt11.3 测试 mapreduce
计算 PI 的值
bash
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.5.0.jar pi 10 10单词统计
bash
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.5.0.jar wordcount /wordcount/input/wcdata.txt /wordcount/result
bash
hdfs dfs -ls /wordcount/result
bash
hdfs dfs -cat /wordcount/result/part-r-0000012. 元数据
lihaozhe01
bash
cd /home/lhz/data/hadoop/dfs/name/current
bash
ls看到如下内容:
bash
VERSION
edits_0000000000000000001-0000000000000000002
edits_0000000000000000003-0000000000000000004
edits_0000000000000000005-0000000000000000006
edits_0000000000000000007-0000000000000000015
edits_0000000000000000016-0000000000000000017
edits_0000000000000000018-0000000000000000019
edits_0000000000000000020-0000000000000000021
edits_0000000000000000022-0000000000000000023
edits_0000000000000000024-0000000000000000025
edits_0000000000000000026-0000000000000000029
edits_0000000000000000030-0000000000000000031
edits_0000000000000000032-0000000000000000033
edits_0000000000000000034-0000000000000000035
edits_0000000000000000036-0000000000000000036
edits_0000000000000000037-0000000000000000251
edits_0000000000000000252-0000000000000000326
edits_inprogress_0000000000000000327
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid查看fsimage
bash
hdfs oiv -p XML -i fsimage_0000000000000000000将元数据内容按照指定格式读取后写入到新文件中
bash
hdfs oiv -p XML -i fsimage_0000000000000000000 -o /opt/soft/fsimage.xml查看edits
将元数据内容按照指定格式读取后写入到新文件中
bash
hdfs oev -p XML -i edits_inprogress_0000000000000000327 -o /opt/soft/edit.xml