Ultralytics:解读Attention模块

前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- YOLOs-CPP:一个免费开源的YOLO全系列C++推理库(以YOLO26为例)
- PaddleOCR:Win10上安装使用PPOCRLabel标注工具
- 目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 图像分割:PyTorch从零开始实现SegFormer语义分割
- 图像超分:使用自己的数据集微调Real-ESRGAN-x4plus进行超分重建
- 图像生成:PyTorch从零开始实现一个简单的扩散模型
- Stable Diffusion:使用自己的数据集微调 Stable Diffusion 3.5 LoRA 文生图模型
- 图像超分:使用自己的数据集微调Real-ESRGAN-x2plus进行超分重建
- Anomalib:使用Anomalib 2.1.0训练自己的数据集进行异常检测
- Anomalib:在Linux服务器上安装使用Anomalib 2.1.0
- 人工智能混合编程实践:C++调用封装好的DLL进行异常检测推理
- 人工智能混合编程实践:C++调用封装好的DLL进行FP16图像超分重建(v3.0)
- 隔离系统Python:源码编译3.11.8到自定义目录(含PGO性能优化)
- 在线机的Python环境迁移到离线机上
- Nuitka 将 Python 脚本封装为 .pyd 或 .so 文件
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)
相关介绍
Ultralytics 简介
Ultralytics 基于多年的计算机视觉和人工智能基础研究,创建了最先进的 (SOTA) YOLO 模型。我们的模型不断更新性能和灵活性,快速、准确且易于使用。他们擅长对象检测、跟踪、实例分割、语义分割、图像分类和姿势估计任务。
前提条件
- 熟悉Python、Pytorch
实验环境
bash
Package Version
------------------------ ------------
Python 3.11.8
absl-py 2.4.0
accelerate 1.13.0
annotated-doc 0.0.4
anyio 4.13.0
calflops 0.3.2
certifi 2026.4.22
charset-normalizer 3.4.7
click 8.3.3
colorama 0.4.6
contourpy 1.3.3
cycler 0.12.1
filelock 3.29.0
flatbuffers 25.12.19
fonttools 4.62.1
fsspec 2026.4.0
grpcio 1.80.0
h11 0.16.0
hf-xet 1.5.0
httpcore 1.0.9
httpx 0.28.1
huggingface_hub 1.14.0
idna 3.15
Jinja2 3.1.6
kiwisolver 1.5.0
Markdown 3.10.2
markdown-it-py 4.2.0
MarkupSafe 3.0.3
matplotlib 3.10.9
mdurl 0.1.2
ml_dtypes 0.5.0
mpmath 1.3.0
networkx 3.6.1
numpy 1.26.4
nvidia-cublas-cu12 12.8.3.14
nvidia-cuda-cupti-cu12 12.8.57
nvidia-cuda-nvrtc-cu12 12.8.61
nvidia-cuda-runtime-cu12 12.8.57
nvidia-cudnn-cu12 9.7.1.26
nvidia-cufft-cu12 11.3.3.41
nvidia-cufile-cu12 1.13.0.11
nvidia-curand-cu12 10.3.9.55
nvidia-cusolver-cu12 11.7.2.55
nvidia-cusparse-cu12 12.5.7.53
nvidia-cusparselt-cu12 0.6.3
nvidia-nccl-cu12 2.26.2
nvidia-nvjitlink-cu12 12.8.61
nvidia-nvtx-cu12 12.8.55
onnx 1.19.0
onnxruntime-gpu 1.26.0
onnxslim 0.1.94
opencv-python 4.6.0.66
packaging 26.2
pillow 12.2.0
pip 24.0
polars 1.40.1
polars-runtime-32 1.40.1
protobuf 7.34.1
psutil 7.2.2
pycocotools 2.0.11
Pygments 2.20.0
pyparsing 3.3.2
python-dateutil 2.9.0.post0
PyYAML 6.0.3
regex 2026.5.9
requests 2.34.1
rich 15.0.0
safetensors 0.7.0
scipy 1.16.0
setuptools 65.5.0
shellingham 1.5.4
six 1.17.0
sympy 1.14.0
tabulate 0.10.0
tensorboard 2.20.0
tensorboard-data-server 0.7.2
tokenizers 0.22.2
torch 2.7.1+cu128
torchaudio 2.7.1+cu128
torchvision 0.22.1+cu128
tqdm 4.67.3
transformers 5.8.1
triton 3.3.1
typer 0.25.1
typing_extensions 4.15.0
ultralytics 8.4.58
ultralytics-thop 2.0.19
urllib3 2.7.0
Werkzeug 3.1.8Attention(轻量级多头自注意力模块)
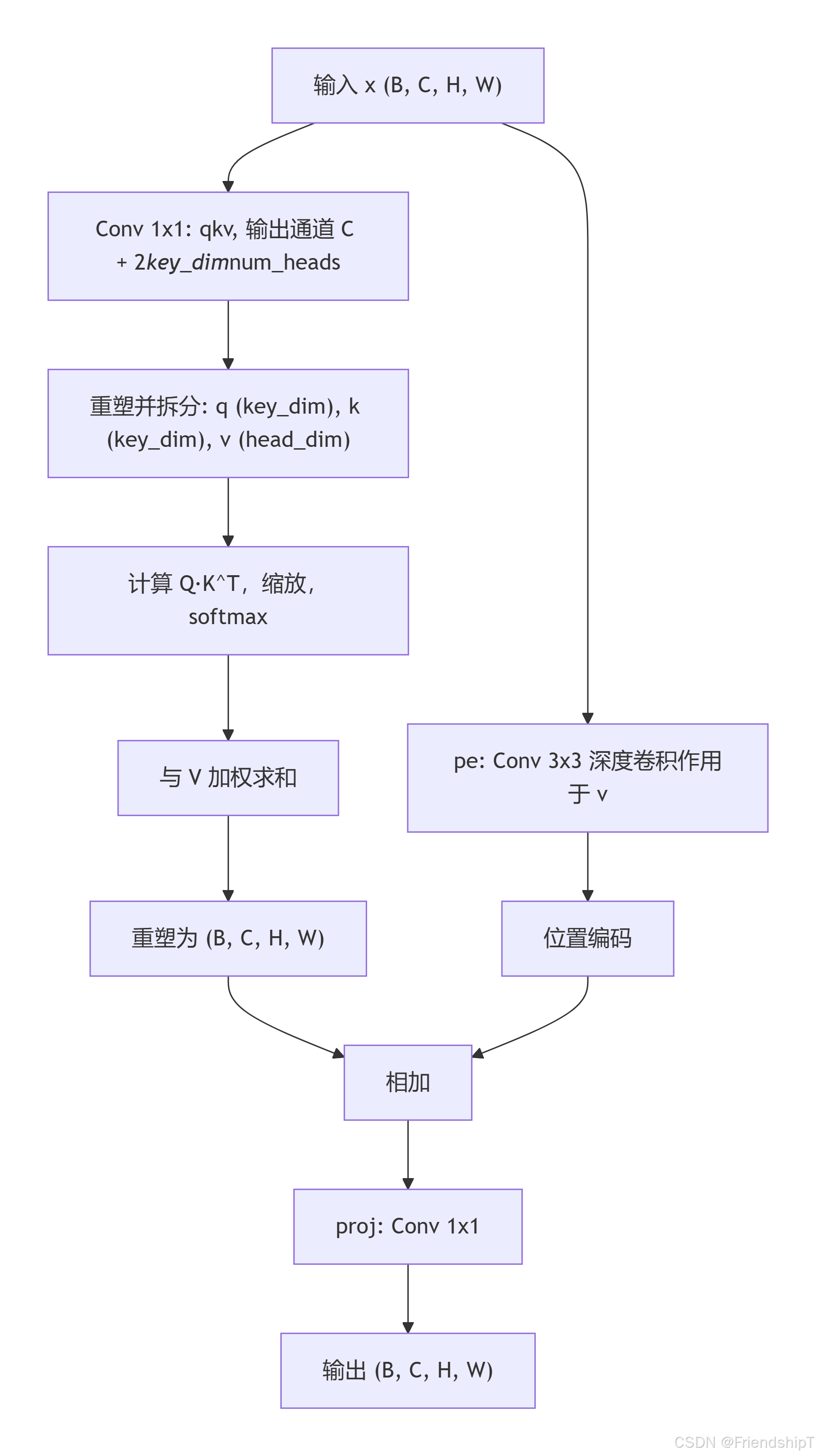
Attention 是一种针对 2D 特征图 设计的轻量级多头自注意力模块,它使用 卷积层 而非全连接层进行投影,并集成了 位置编码 ,在保持较高计算效率的同时捕获全局依赖。该模块常见于 YOLOv8 等轻量级网络中的 C2f 模块,用于增强特征表示。
代码实现
python
import cv2
import math
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution module with batch normalization and activation.
Attributes:
conv (nn.Conv2d): Convolutional layer.
bn (nn.BatchNorm2d): Batch normalization layer.
act (nn.Module): Activation function layer.
default_act (nn.Module): Default activation function (SiLU).
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given parameters.
Args:
c1 (int): Number of input channels.
c2 (int): Number of output channels.
k (int): Kernel size.
s (int): Stride.
p (int, optional): Padding.
g (int): Groups.
d (int): Dilation.
act (bool | nn.Module): Activation function.
"""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor.
Args:
x (torch.Tensor): Input tensor.
Returns:
(torch.Tensor): Output tensor.
"""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Apply convolution and activation without batch normalization.
Args:
x (torch.Tensor): Input tensor.
Returns:
(torch.Tensor): Output tensor.
"""
return self.act(self.conv(x))
class Attention(nn.Module):
"""Attention module that performs self-attention on the input tensor.
Args:
dim (int): The input tensor dimension.
num_heads (int): The number of attention heads.
attn_ratio (float): The ratio of the attention key dimension to the head dimension.
Attributes:
num_heads (int): The number of attention heads.
head_dim (int): The dimension of each attention head.
key_dim (int): The dimension of the attention key.
scale (float): The scaling factor for the attention scores.
qkv (Conv): Convolutional layer for computing the query, key, and value.
proj (Conv): Convolutional layer for projecting the attended values.
pe (Conv): Convolutional layer for positional encoding.
"""
def __init__(self, dim: int, num_heads: int = 8, attn_ratio: float = 0.5):
"""Initialize multi-head attention module.
Args:
dim (int): Input dimension.
num_heads (int): Number of attention heads.
attn_ratio (float): Attention ratio for key dimension.
"""
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim**-0.5
nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass of the Attention module.
Args:
x (torch.Tensor): The input tensor.
Returns:
(torch.Tensor): The output tensor after self-attention.
"""
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, self.key_dim * 2 + self.head_dim, N).split(
[self.key_dim, self.key_dim, self.head_dim], dim=2
)
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + self.pe(v.reshape(B, C, H, W))
x = self.proj(x)
return x功能
- 多头自注意力:将输入特征图在空间维度展平,计算每个位置对全局的注意力权重,实现全局上下文建模。
- 卷积投影:使用 1×1 卷积替代全连接层,保留空间结构,适用于 2D 特征图。
- 轻量设计 :通过
attn_ratio控制键(key)的维度,减少计算量。 - 位置编码:通过深度卷积(3×3,分组数等于通道数)对值(value)进行空间编码,弥补自注意力缺乏位置信息的缺陷。
初始化参数
| 参数 | 类型 | 说明 |
|---|---|---|
dim |
int | 输入特征图的通道数(同时也是输出通道数) |
num_heads |
int | 注意力头数(默认 8,dim 必须能被其整除) |
attn_ratio |
float | 键(key)维度与头维度的比例(默认 0.5),控制注意力计算成本 |
前向方法
forward(x):输入x([B, C, H, W]),输出[B, C, H, W]。
计算流程:
- 展平空间维度:
N = H * W。 qkv = self.qkv(x):1×1 卷积,输出通道数为dim + 2 * (key_dim * num_heads)。- 重塑并拆分:将
qkv重排为(B, num_heads, key_dim*2 + head_dim, N),然后沿通道维拆分为q(key_dim)、k(key_dim)、v(head_dim)。 - 计算注意力权重:
attn = (q.transpose(-2,-1) @ k) * scale,然后softmax。 - 加权求和:
x = (v @ attn.transpose(-2,-1)),重塑为(B, C, H, W)。 - 添加位置编码:
x = x + self.pe(v.reshape(B, C, H, W))(位置编码来自对v的深度卷积)。 - 输出投影:
x = self.proj(x),返回。
使用示例

python
if __name__ == '__main__':
# 1. 创建随机输入
x = torch.randn(1, 64, 32, 32)
# 2. 创建 Attention 模块
attn = Attention(dim=64, num_heads=8, attn_ratio=0.5)
# 3. 前向传播
with torch.no_grad():
out = attn(x)
print("输入形状:", x.shape) # [1, 64, 32, 32]
print("输出形状:", out.shape) # [1, 64, 32, 32]
# 4. 使用真实图像演示(需将图像转为特征图)
img_path = "cat_640x640.png"
img_bgr = cv2.imread(img_path)
if img_bgr is not None:
# 缩放到 64x64,转为灰度图
img_gray = cv2.cvtColor(cv2.resize(img_bgr, (64, 64)), cv2.COLOR_BGR2GRAY)
img_tensor = torch.from_numpy(img_gray).float().unsqueeze(0).unsqueeze(0) # [1,1,64,64]
# 扩展通道数至 64(模拟特征图)
x_img = img_tensor.repeat(1, 64, 1, 1) # [1,64,64,64]
# 创建 Attention(dim=64)
attn_img = Attention(dim=64, num_heads=8)
with torch.no_grad():
out_img = attn_img(x_img) # [1,64,64,64]
# 可视化:输入通道0、输出通道0
inp_ch0 = x_img[0, 0].cpu().numpy()
out_ch0 = out_img[0, 0].cpu().numpy()
def norm(arr):
return (arr - arr.min()) / (arr.max() - arr.min() + 1e-8)
plt.figure(figsize=(12, 5), constrained_layout=True)
plt.subplot(1, 3, 1)
plt.imshow(img_gray, cmap='gray')
plt.title("Original Gray")
plt.axis("off")
plt.subplot(1, 3, 2)
plt.imshow(norm(inp_ch0), cmap='gray')
plt.title("Input Ch0")
plt.axis("off")
plt.subplot(1, 3, 3)
plt.imshow(norm(out_ch0), cmap='gray')
plt.title("Attention Output Ch0")
plt.axis("off")
plt.savefig("attention_demo.png", dpi=150)
print("可视化已保存为 attention_demo.png")输出示例:
输入形状: torch.Size([1, 64, 32, 32])
输出形状: torch.Size([1, 64, 32, 32])
可视化已保存为 attention_demo.png流程示意图
代码解读
-
__init__:head_dim = dim // num_heads:每个头的维度,需整除。key_dim = int(head_dim * attn_ratio):键的维度,通常小于等于头维度,以节省计算。scale = key_dim ** -0.5:缩放因子,用于稳定注意力分数。nh_kd = key_dim * num_heads:所有头的键总维度。h = dim + nh_kd * 2:qkv卷积的输出通道数(dim用于值,nh_kd各用于查询和键)。self.qkv:1×1 卷积,无激活,用于生成 Q、K、V。self.proj:1×1 卷积,无激活,用于输出投影。self.pe:3×3 深度卷积(g=dim),无激活,用于对 V 进行位置编码。
-
forward:qkv = self.qkv(x),输出形状(B, h, H, W)。- 通过
view和split将qkv拆分为q、k、v,形状分别为(B, num_heads, key_dim, N)、(B, num_heads, key_dim, N)、(B, num_heads, head_dim, N)。 - 注意力计算:
attn = (q.transpose(-2,-1) @ k) * scale,得到(B, num_heads, N, N),softmax 后在最后一维归一化。 - 加权求和:
v @ attn.transpose(-2,-1),得到(B, num_heads, head_dim, N),重塑为(B, C, H, W)。 - 位置编码:对
v重塑为(B, C, H, W)后,应用self.pe(深度卷积),再与注意力输出相加。 - 最后通过
self.proj投影输出。
注意事项
- 输入输出通道一致:该模块不改变通道数,仅用于特征细化。
- 空间尺寸不变:所有卷积步长为 1,填充自动 same,空间尺寸保持不变。
attn_ratio影响效率 :降低attn_ratio可减少key_dim,从而减少 Q 和 K 的张量大小,降低计算量,但可能影响注意力表达能力。- 位置编码:使用深度卷积(3×3)对 V 进行空间编码,使得注意力能利用局部位置信息,比单纯的自注意力更有效。
- 与标准 Transformer 的差异 :
- 使用 1×1 卷积而非线性层,保持空间结构。
- 位置编码采用卷积而非正弦/可学习嵌入。
- 无 LayerNorm 和残差(但可通过外部添加)。
优缺点
优点
- 轻量高效:相比标准 Transformer,使用卷积投影和深度卷积位置编码,参数更少,推理更快。
- 全局感受野:自注意力机制让每个位置能直接关注所有位置,捕获长距离依赖。
- 即插即用 :可嵌入 YOLOv8 的
C2f等模块,提升特征表达能力。 - 灵活性 :通过
attn_ratio控制计算成本,适应不同资源场景。
缺点
- 计算量与序列长度平方相关 :当空间尺寸较大时(如 64×64),注意力矩阵
(N, N)显存占用大,限制了高分辨率特征图的使用。 - 无显式残差:需外部添加残差连接,否则可能影响梯度流。
- 位置编码固定:深度卷积的权重是可学习的,但不如正弦编码那样具有明确的几何意义。
- 对维度敏感 :
dim必须能被num_heads整除,限制了设计自由度。
在 YOLOv8 中,Attention 通常作为 C2f 的增强组件,用于替换部分 Bottleneck,以提升检测精度。使用时建议根据显存和任务调整 num_heads 和 attn_ratio,并在高分辨率特征图上谨慎使用。
参考文献
1 https://docs.ultralytics.com/
2 https://github.com/ultralytics/ultralytics.git
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- YOLOs-CPP:一个免费开源的YOLO全系列C++推理库(以YOLO26为例)
- PaddleOCR:Win10上安装使用PPOCRLabel标注工具
- 目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 图像分割:PyTorch从零开始实现SegFormer语义分割
- 图像超分:使用自己的数据集微调Real-ESRGAN-x4plus进行超分重建
- 图像生成:PyTorch从零开始实现一个简单的扩散模型
- Stable Diffusion:使用自己的数据集微调 Stable Diffusion 3.5 LoRA 文生图模型
- 图像超分:使用自己的数据集微调Real-ESRGAN-x2plus进行超分重建
- Anomalib:使用Anomalib 2.1.0训练自己的数据集进行异常检测
- Anomalib:在Linux服务器上安装使用Anomalib 2.1.0
- 人工智能混合编程实践:C++调用封装好的DLL进行异常检测推理
- 人工智能混合编程实践:C++调用封装好的DLL进行FP16图像超分重建(v3.0)
- 隔离系统Python:源码编译3.11.8到自定义目录(含PGO性能优化)
- 在线机的Python环境迁移到离线机上
- Nuitka 将 Python 脚本封装为 .pyd 或 .so 文件
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)