从零开始:用原生 Node.js 徒手拆解 RAG 与向量检索底层原理
- 前言
- [一、 从传统文本匹配到自然语义搜索](#一、 从传统文本匹配到自然语义搜索)
-
- [1.1 传统文本匹配的局限性](#1.1 传统文本匹配的局限性)
- [1.2 自然语义搜索的崛起](#1.2 自然语义搜索的崛起)
- [1.3 RAG 检索流程](#1.3 RAG 检索流程)
- [二、 基础环境搭建与大模型服务模块化](#二、 基础环境搭建与大模型服务模块化)
-
- [2.1 初始化工程](#2.1 初始化工程)
- [2.2 大模型服务的模块化封装](#2.2 大模型服务的模块化封装)
- [2.3 跑通最小可行性验证(MVP)](#2.3 跑通最小可行性验证(MVP))
- [三、 知识库离线构建:批量数据向量化与持久化](#三、 知识库离线构建:批量数据向量化与持久化)
-
-
- [3.1 原始数据形态](#3.1 原始数据形态)
- [3.2 批量向量化脚本实现](#3.2 批量向量化脚本实现)
- [3.3 深度原原理:为什么要对 `input` 进行文本拼接?](#3.3 深度原原理:为什么要对
input进行文本拼接?)
-
- [四、 核心数学算法:纯 JavaScript 实现余弦相似度](#四、 核心数学算法:纯 JavaScript 实现余弦相似度)
-
- [4.1 什么是余弦相似度?](#4.1 什么是余弦相似度?)
- [4.2 代码实现与逐行解析](#4.2 代码实现与逐行解析)
- [五、 在线检索系统:构建终端动态交互界面](#五、 在线检索系统:构建终端动态交互界面)
-
- [5.1 交互流程设计思想](#5.1 交互流程设计思想)
- [5.2 完整检索代码实现](#5.2 完整检索代码实现)
- [5.3 关键数据流追踪与设计拆解](#5.3 关键数据流追踪与设计拆解)
- [六、 总结](#六、 总结)
前言
在人工智能技术爆发的今天,大语言模型(LLM)展现出了惊人的文本生成与理解能力。然而,在面对特定垂直领域知识或企业内部私有数据时,通用大模型常常会显得力不从心,甚至产生"幻觉"(即一本正经地胡说八道)。为了解决这一痛点,RAG(Retrieval-Augmented Generation,检索增强生成) 架构应运而生。
RAG 的核心思想极其朴素:在将问题提交给大模型之前,先从业界或企业内部的"知识库"中检索出与问题相关的本地资料,然后将这些资料作为上下文补充给提示词(Prompt),从而让大模型基于可靠的现实依据进行回答。
在 RAG 的整个技术闭环中,检索(Retrieval) 是决定最终生成质量的关键第一步。本文将脱离复杂的企业级框架(如 LangChain 或 LlamaIndex),从零开始,使用原生 Node.js 构建一个完整的自然语义搜索系统。我们将一起剖析为什么传统搜索会失效,自然语义搜索的设计思想是什么,并徒手用数学公式实现向量相似度比对,从而带你真正打通 RAG 底层的数据与算法链路。
一、 从传统文本匹配到自然语义搜索
在深入代码之前,我们先来探讨一个本质问题:为什么大模型时代需要自然语义搜索?
1.1 传统文本匹配的局限性
传统的文本检索主要依赖于关键词精确匹配(如正则表达式、SQL 中的 LIKE '%vue%' 语句)。这种方式在处理结构化数据或精确文本查找时非常高效。然而,人类的自然语言是极其丰富且具备复杂上下文的。
思考这样一个场景:
- 用户输入查询:
"马铃薯怎么做?" - 知识库中存有一篇文章:
"酸辣土豆丝的做法....."
如果使用传统的关键词匹配,由于"马铃薯"和"土豆"在字面上完全不重合,系统会直接判定为"不匹配",从而返回空结果。但从人类的认知来看,这两者指代的是同一种食物,两句话在语义上具有极高的相关性。
1.2 自然语义搜索的崛起
自然语义搜索的核心就在于突破字面限制,转而理解文本背后的真实含义(语义) 。为了让计算机能够"计算"两句话的含义是否相近,科学家们引入了 Embedding(向量化/嵌入) 技术。
向量化的本质是将一段现实世界的文本(字、词、句子甚至整篇文章),通过预训练的深度学习模型映射到一个高维的数学向量(通常是一个由数百到数千个浮点数组成的数组)中。
设计思想 :在多维向量空间中,语义越接近的文本,其对应的向量在空间中的几何距离就越近;反之,语义差距越大的文本,其向量距离就越远。通过这种方式,
"马铃薯"与"土豆"的向量由于高频出现在相似的语境中,它们在空间中的位置会非常接近。
1.3 RAG 检索流程
在技术社区的搜索场景中,完整的 RAG 语义搜索通常包含两个阶段:
- 离线预处理(数据灌入) :提前将知识库中的所有文章、文档抽取出来,调用 Embedding 模型将其转化为向量,并将其持久化存储到专门的向量数据库(如 Milvus、PostgreSQL 等支持向量存储的数据库)中。
- 在线检索(实时响应):当用户输入问题时,实时将用户的提问进行 Embedding 向量化,随后在向量数据库中进行高维空间的距离计算,筛选出相似度最高的前几篇文档,完成精准检索。
接下来,我们将使用 Node.js 完整再现这一工程流程。
二、 基础环境搭建与大模型服务模块化
由于我们要操作本地文件系统(I/O)并处理大规模异步 API 请求,具备优秀异步控制能力的 Node.js 是极为理想的后端开发环境。
2.1 初始化工程
首先,我们在项目根目录下进行项目初始化,并安装大模型对接所需的官方 SDK 以及环境变量管理工具:
bash
npm init -y
pnpm i openai dotenvnpm init -y:快速生成默认的package.json配置文件,标志着一个 Node.js 后端项目的开始。openai:官方提供的 SDK。虽然我们使用的是阿里云百炼大模型(DashScope),但由于其完美兼容了 OpenAI 的 API 协议,因此我们可以直接复用该 SDK,降低代码的学习与迁移成本。dotenv:用于将根目录下的.env文件中配置的敏感密钥自动加载到 Node.js 的process.env环境变量中,避免将密钥硬编码到代码中导致的安全泄露。
2.2 大模型服务的模块化封装
在开发大模型应用时,频繁地实例化客户端会导致代码冗余且不易维护。优秀的大模型项目往往具备清晰的架构划分(即"大模型项目的风骨")。我们将通用的 LLM 客户端连接抽象到 app.service.mjs 中,以便在后续的向量化脚本和检索脚本中进行全局复用。
在根目录下创建 .env 文件,填入你的阿里云百炼 API 密钥:
DASHSCOPE_API_KEY=YOUR_ALIYUN_DASHSCOPE_API_KEY接着创建 app.service.mjs(注意:.mjs 后缀代表启用 Node.js 原生的 ES Modules 模块规范,允许直接使用 import/export):
javascript
import OpenAI from 'openai';
import dotenv from 'dotenv';
// 激活并加载 .env 文件中的配置到全局环境变量中
dotenv.config();
/**
* 模块化输出大模型客户端连接实例
* 目的:实现全局单例复用,简化外部调用流程
*/
export const client = new OpenAI({
// 从环境变量中读取安全的 API Key
apiKey: process.env.DASHSCOPE_API_KEY,
// 配置阿里云百炼提供的 OpenAI 兼容模式基础端点
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1',
});2.3 跑通最小可行性验证(MVP)
在推进核心业务前,我们先写一个最简单的基准测试脚本,来验证我们与阿里云百炼的 Embedding 接口是否已经成功连通,并观察向量的真实长相。
创建测试脚本 test-embedding.mjs:
javascript
import OpenAI from 'openai';
import dotenv from 'dotenv';
dotenv.config();
const client = new OpenAI({
apiKey: process.env.DASHSCOPE_API_KEY,
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1',
});
// 使用顶级 await 发起异步向量化请求
const response = await client.embeddings.create({
model: "text-embedding-v4", // 指定阿里云百炼的高性能文本向量化模型
input: "moss is coming" // 需要被向量化的源文本
});
// 打印并观察返回的稠密向量数组
console.log("生成的向量数据:", response.data[0].embedding);当你在终端运行该脚本时,会输出一个由海量浮点数组成的超长一维数组。这,就是大模型眼中关于 "moss is coming" 这句话的数学表征。
三、 知识库离线构建:批量数据向量化与持久化
有了大模型连接能力后,我们需要对本地的"知识库"进行批量洗数与离线向量化。
3.1 原始数据形态
我们的项目结构中包含一个 data 目录。在该目录下存放着一个名为 posts.json 的文件,代表着我们私有的技术文章知识库:
json
[
{
"title": "如何使用 Nuxt.js 进行服务器端渲染",
"category": "前端开发"
},
{
"title": "使用 Nest.js 和 TypeScript 构建一个简单的微服务应用",
"category": "后端开发"
},
{
"title": "如何在 Vue.js 中使用 Vuetify 实现 Material Design 风格",
"category": "前端开发"
},
{
"title": "如何使用 Nuxt.js 和 Firebase 实现服务器端渲染的无后端应用",
"category": "前端开发"
},
{
"title": "使用 Nest.js 和 TypeORM 构建一个简单的数据驱动的 RESTful API",
"category": "后端开发"
},
{
"title": "如何使用 Vue.js 和 Electron 开发桌面应用程序",
"category": "前端开发"
},
{
"title": "使用 Nuxt.js 和 Storybook 构建可视化组件库",
"category": "前端开发"
},
{
"title": "如何使用 Nest.js 和 Passport 实现用户认证",
"category": "后端开发"
},
{
"title": "如何使用 Vue.js 和 D3.js 创建可交互的数据可视化",
"category": "前端开发"
},
{
"title": "使用 Nest.js 和 GraphQL 构建一个简单的 GraphQL 服务",
"category": "后端开发"
},
{
"title": "如何在 React 中实现无限滚动",
"category": "前端开发"
},
{
"title": "使用 Flask 和 Python 构建 RESTful API",
"category": "后端开发"
},
{
"title": "如何使用 React Native 开发跨平台移动应用",
"category": "移动开发"
},
{
"title": "掌握 Pandas 中的分组和聚合操作",
"category": "数据科学"
},
{
"title": "如何在 Vue.js 中使用 Vuex 进行状态管理",
"category": "前端开发"
},
{
"title": "使用 Django 和 Python 构建一个简单的博客应用",
"category": "后端开发"
},
{
"title": "如何使用 React Hooks 构建可复用的组件",
"category": "前端开发"
},
{
"title": "如何使用 TensorFlow 进行图像分类任务",
"category": "数据科学"
},
{
"title": "如何使用 Flutter 开发一个简单的计数器应用",
"category": "移动开发"
},
{
"title": "使用 Node.js 和 Express 构建一个简单的 RESTful API",
"category": "后端开发"
},
{
"title": "如何使用 D3.js 创建可交互的数据可视化",
"category": "前端开发"
},
{
"title": "如何使用 Scikit-learn 进行机器学习任务",
"category": "数据科学"
},
{
"title": "如何使用 React Router 实现客户端路由",
"category": "前端开发"
},
{
"title": "使用 Ruby on Rails 构建一个简单的电商网站",
"category": "后端开发"
},
{
"title": "如何使用 Kotlin 和 Android Studio 开发一个简单的 Todo 应用",
"category": "移动开发"
},
{
"title": "如何使用 PyTorch 进行深度学习任务",
"category": "数据科学"
},
{
"title": "使用 VSCode 和 Git 进行团队协作开发",
"category": "开发工具"
},
{
"title": "如何使用 Insomnia 进行 API 接口测试",
"category": "开发工具"
},
{
"title": "如何使用 TypeScript 编写高质量的 JavaScript 代码",
"category": "前端开发"
},
{
"title": "如何使用 CSS 实现网页响应式布局",
"category": "前端开发"
},
{
"title": "使用 JavaScript 实现一个简单的计算器应用",
"category": "前端开发"
},
{
"title": "使用 Next.js 和 Tailwind CSS 构建一个简单的博客应用",
"category": "前端开发"
},
{
"title": "如何使用 Vue.js 和 Tailwind CSS 创建响应式布局",
"category": "前端开发"
},
{
"title": "如何在 React 中使用 Tailwind CSS 实现 Material Design 风格",
"category": "前端开发"
},
{
"title": "使用 Tailwind CSS 和 Alpine.js 构建一个简单的交互式表单",
"category": "前端开发"
}
]3.2 批量向量化脚本实现
我们需要编写一个脚本(creat-embedding.mjs),实现以下完整链路:
- 文件读取:调用 Node.js 底层系统 API,将硬盘中的 JSON 文本加载到内存中。
- 数据加工与拼接:循环遍历每一条文章数据,将"标题"与"分类"融合成一段更具上下文语义的组合文本,并提交给 Embedding 模型。
- 节流控制(Sleep机制):由于大模型 API 通常伴随有每分钟请求频率限制(QPS/RPM Limit),在长循环中加入延迟函数是非常必要的工程实践。
- 持久化落地:将带有向量字段的数据重新转化为 JSON 字符串,长期存储到硬盘上。
创建 creat-embedding.mjs,编写如下代码:
javascript
import fs from 'fs/promises'; // 引入 Node.js 2015(ES6) 后推出的原生支持 Promise 的文件系统模块
import { client } from './app.service.mjs'; // 复用已封装的大模型客户端
// 定义输入和输出的文件路径
const inputFilePath = './data/posts.json';
const outputFilePath = './data/posts-embedding.json';
// 从硬盘读取原始的二进制/文本文件,并以 utf-8 编码转化为 JavaScript 字符串
const data = await fs.readFile(inputFilePath, 'utf-8');
// 将字符串解析为结构化的 JavaScript 数组对象
const posts = JSON.parse(data);
/**
* 节流控制函数
* 目的:阻断代码执行指定的毫秒数,防止高频调用引发远程 API 的 Rate Limit(限流错误)
* @param {number} ms - 睡眠的毫秒数
*/
const sleep = (ms) => new Promise(resolve => setTimeout(resolve, ms));
// 用于存储融合了向量数据的新数组
const postsWithEmbedding = [];
// 采用高效、可读性强的 for...of 循环依次处理
for (const { title, category } of posts) {
console.log(`正在对文章进行向量化: [${category}] ${title}`);
// 调用百炼接口,获取向量
const response = await client.embeddings.create({
model: 'text-embedding-v4',
// 设计细节:将标题和分类融合成固定格式,为模型提供更细腻的混合检索语义
input: `标题:${title},分类:${category}`
});
// 将原数据与生成的稠密向量数组组合,推入新数组中
postsWithEmbedding.push({
title,
category,
embedding: response.data[0].embedding // 提取模型返回的浮点数数组
});
// 每次请求后强制休眠 200 毫秒,保护 API 调用频率
await sleep(200);
}
console.log('所有数据向量化完毕,正在写入本地持久化文件...');
// 使用 fs/promises 的 writeFile 方法将数据落盘
// JSON.stringify(..., null, 2) 能够让输出的 JSON 文件具备换行和 2 个空格缩进,极大提升了文件的可读性
await fs.writeFile(
outputFilePath,
JSON.stringify(postsWithEmbedding, null, 2)
);
console.log('持久化成功!生成的向量文件路径为:', outputFilePath);
3.3 深度原原理:为什么要对 input 进行文本拼接?
在上面的代码中,我们并没有直接传递 title,而是传递了:
javascript
input: `标题:${title},分类:${category}`这是非常实用的工程小技巧。如果仅将 title(例如 "如何使用 Vue.js 和 Electron 开发桌面应用程序")送入向量化模型,由于缺乏上下文,模型可能无法完全对齐"桌面端开发"和"前端"的强关联属性。当我们把 分类:前端开发 一并拼接进去后,生成的向量特征就会同时捕捉到"Vue.js"和"前端开发"的双重语境。在后续的相似度计算中,其语义分布将更加精准。
四、 核心数学算法:纯 JavaScript 实现余弦相似度
在完成了本地知识库的向量化落盘后,我们进入了 RAG 系统的核心------检索(Retrieval) 环节。
当用户输入一个问题时,我们同样会将其转化为一维浮点数向量。那么,如何通过数学公式计算出两个高维向量之间的"语义距离"呢?在工业界和学术界,最常用的度量指标之一就是余弦相似度(Cosine Similarity)。
4.1 什么是余弦相似度?
余弦相似度通过计算两个向量在几何空间中夹角的余弦值来衡量它们之间的相似性。
其数学公式定义如下:
Similarity = cos ( θ ) = A ⋅ B ∥ A ∥ ∥ B ∥ = ∑ i = 1 n A i B i ∑ i = 1 n A i 2 × ∑ i = 1 n B i 2 \text{Similarity} = \cos(\theta) = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \times \sqrt{\sum_{i=1}^{n} B_i^2}} Similarity=cos(θ)=∥A∥∥B∥A⋅B=∑i=1nAi2 ×∑i=1nBi2 ∑i=1nAiBi
公式看似复杂,但在代码层面,它可以被拆解为三个极其简单的纯数字计算步骤:
- 计算点积(Dot Product) :将两个向量对应位置的数值相乘,并将所有乘积相加。即 ∑ A i B i \sum A_i B_i ∑AiBi。
- 计算向量 A 的模长(Length/Norm) :将向量 A 中每个元素的平方相加,然后再开平方根。即 ∑ A i 2 \sqrt{\sum A_i^2} ∑Ai2 。
- 计算向量 B 的模长 :同理,计算出向量 B 的几何长度 ∑ B i 2 \sqrt{\sum B_i^2} ∑Bi2 。
- 最终结果:点积除以两个模长的乘积。余弦值越接近 1,说明夹角越小,语义越相似;越接近 0 或 -1,说明差异越大。
4.2 代码实现与逐行解析
下面是使用 JavaScript 原生的高阶函数 reduce 实现的通用余弦相似度计算函数:
javascript
/**
* 计算两个高维向量的余弦相似度
* @param {number[]} v1 - 向量A(如本地知识库某篇文章的向量)
* @param {number[]} v2 - 向量B(如用户当前提问的向量)
* @returns {number} 相似度得分(范围在 -1 到 1 之间)
*/
const cosineSimilarity = (v1, v2) => {
// 1. 计算向量的点积(对应位置相乘后累加)
// acc 是累加器,curr 是当前遍历的元素,i 是当前元素的索引
const dotProduct = v1.reduce((acc, curr, i) => acc + curr * v2[i], 0);
// 2. 计算向量 v1 的模长(每个元素平方和,再开根号)
const lengthV1 = Math.sqrt(v1.reduce((acc, curr) => acc + curr * curr, 0));
// 3. 计算向量 v2 的模长
const lengthV2 = Math.sqrt(v2.reduce((acc, curr) => acc + curr * curr, 0));
// 4. 边界防御:防止分母为 0 导致程序崩溃
if (lengthV1 === 0 || lengthV2 === 0) return 0;
// 5. 根据公式计算余弦相似度
const similarity = dotProduct / (lengthV1 * lengthV2);
return similarity;
};v1.reduce((acc, curr, i) => acc + curr * v2[i], 0):这是该算法的核心。利用第三个参数i(当前索引),我们可以让v1的当前元素curr与v2[i]精准相乘,并通过acc实现不借助传统for循环的优雅累加。Math.sqrt:JavaScript 内置的开平方根函数,配合reduce完成了模长的几何计算。
五、 在线检索系统:构建终端动态交互界面
有了数学武器,我们就可以把离线准备好的数据文件(posts-embedding.json)加载进来,创建一个持续监听终端输入的实时语义搜索工具。
5.1 交互流程设计思想
为了让系统具备真实的搜索引擎体验,我们需要:
- 维持长连接会话 :通过 Node.js 原生的
readline模块捕获用户的标准输入。 - 实时特征提取:每次用户提交问题,实时发给阿里云百炼大模型转成"问题向量"。
- 全局暴力扫描排序 :将"问题向量"与本地多条数据的向量依次进行
cosineSimilarity计算,得到一个相似度得分数组。 - Top-K 过滤与格式化输出:按照相似度从高到低进行降序排列,筛选出最相关的前 3条结果反馈给用户,并递归等待下一次提问。
5.2 完整检索代码实现
创建检索脚本 semantic-search.mjs:
javascript
import fs from 'fs/promises';
import readline from 'readline'; // 引入 Node.js 内置的读取标准输入输出流模块
import { client } from './app.service.mjs';
const inputFilePath = './data/posts-embedding.json';
// 1. 异步读取在第三章中持久化落盘的带有向量数据的知识库
const data = await fs.readFile(inputFilePath, 'utf-8');
const posts = JSON.parse(data);
// 2. 纯数学实现的余弦相似度算法
const cosineSimilarity = (v1, v2) => {
const dotProduct = v1.reduce((acc, curr, i) => acc + curr * v2[i], 0);
const lengthV1 = Math.sqrt(v1.reduce((acc, curr) => acc + curr * curr, 0));
const lengthV2 = Math.sqrt(v2.reduce((acc, curr) => acc + curr * curr, 0));
return lengthV1 === 0 || lengthV2 === 0 ? 0 : dotProduct / (lengthV1 * lengthV2);
};
// 3. 创建命令行交互接口实例
const rl = readline.createInterface({
input: process.stdin, // 指向进程的标准输入(键盘)
output: process.stdout // 指向进程的标准输出(屏幕)
});
/**
* 用户输入回调的核心处理函数(支持异步请求)
* @param {string} answer - 用户在终端敲入的文本
*/
const handleInput = async (answer) => {
// 边界检查:如果输入为空,则跳过本次检索
if (!answer.trim()) {
rl.question("\n请输入你要搜索的内容: ", handleInput);
return;
}
console.log(`\n正在为你进行语义搜索: "${answer}" ...`);
// 4. 将用户的提问实时转化为 Embedding 向量
const response = await client.embeddings.create({
model: "text-embedding-v4",
input: answer
});
const { embedding } = response.data[0];
// 5. 核心流式数据处理链
const results = posts
// 第一步:映射新对象,计算并注入当前提问与各知识库条目的相似度得分
.map(item => ({
...item,
similarity: cosineSimilarity(item.embedding, embedding)
}))
// 第二步:根据相似度得分进行降序排列(得分最高的排在数组最前)
.sort((a, b) => b.similarity - a.similarity)
// 第三步:工程裁剪,截取最相关的 Top 3 结果
.slice(0, 3)
// 第四步:格式化映射为前端/终端友好的高可读性文本数组
.map((item, index) => `${index + 1}. [相似度: ${(item.similarity * 100).toFixed(2)}%] ${item.title} - ${item.category}`)
// 第五步:使用换行符将其融合成单一字符串
.join("\n");
// 6. 打印输出最终的检索增强上下文
console.log(`\n 搜索结果:\n${results}`);
// 7. 递归调用,让终端界面保持常驻,等待用户的下一次检索输入
rl.question("\n请输入你要搜索的内容: ", handleInput);
};
// 8. 启动交互引导程序
rl.question('\n请输入你要搜索的内容: ', handleInput);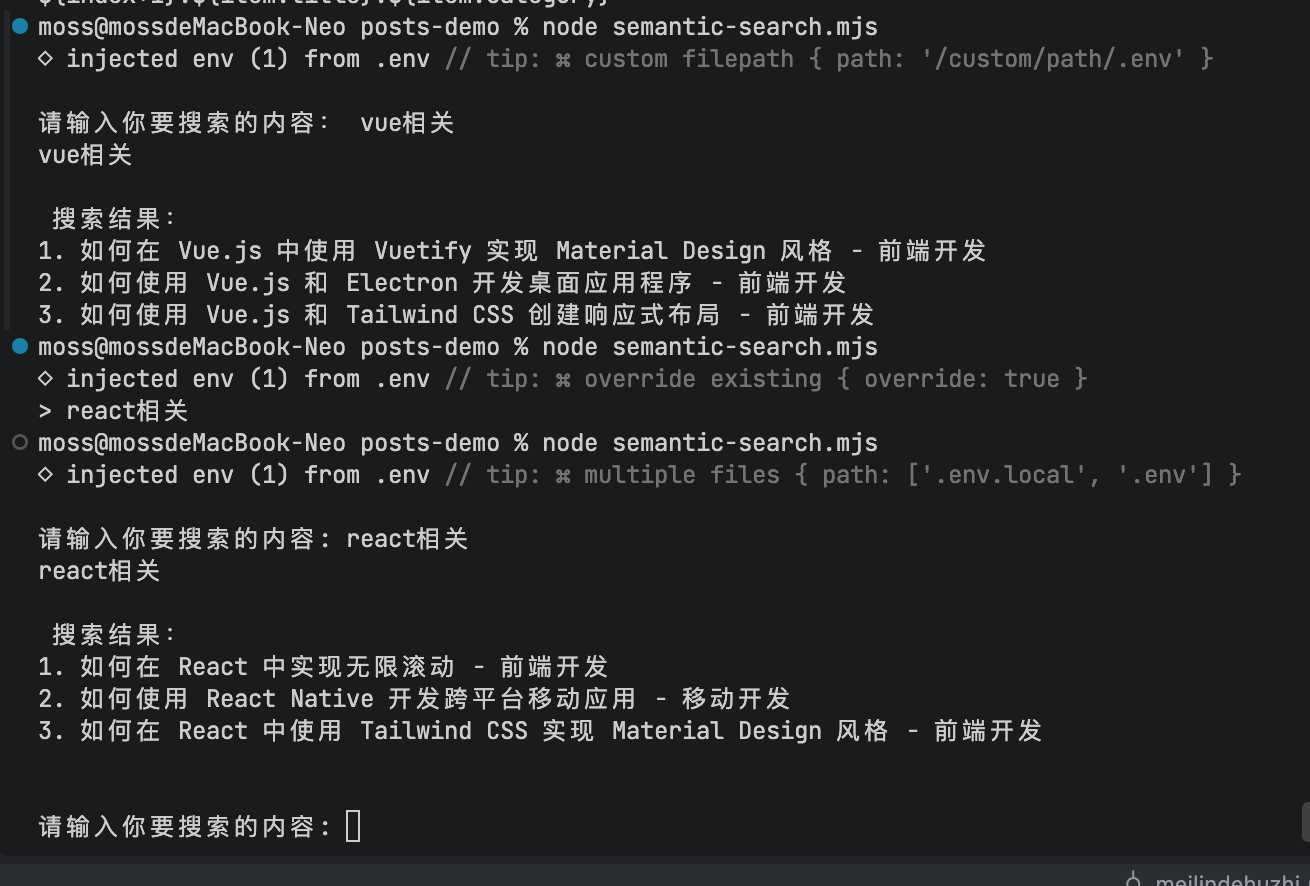
5.3 关键数据流追踪与设计拆解
为了帮助大家彻底看透这段代码的运作本质,我们对关键的数据处理链(即代码中的链式调用)进行解剖:
.map(item => ({ ... , similarity })):这个阶段数据并没有减少。它的任务是借助解构运算符...item保留原有的标题和分类,同时利用我们刚刚编写的数学函数计算出similarity值并挂载到每一个对象上。.sort((a, b) => b.similarity - a.similarity):这是经典的 JavaScript 数组排序逻辑。因为相似度越端越接近 1 越相关,所以我们采用b - a的降序策略,将语义最贴近的文章顶到最上方。.slice(0, 3):这是控制 RAG"上下文窗口"和防止 Token 浪费的重要手段。即使知识库有成千上万条数据,通过slice动作,我们也只精准保留最为精准的核心前三项。
当你在控制台输入类似"跨平台客户端"这样的模糊概念时,系统不会因为你的知识库只有"Electron"这个具体单词而不知所措。相反,由于百炼模型的语义对齐能力,包含"Electron 桌面应用程序"的技术文章会被成功打出高分并被率先检索出来。
六、 总结
至此,我们已经不依赖任何大型编排框架,仅通过区区几十行原生的 Node.js 代码,就手拉手实现并打通了 RAG 检索增强生成的全链路逻辑。
我们在本文中完成了以下工程跨越:
- 理解了为什么传统的正则或模糊匹配无法应对自然语言的多样性,从而引入了 Embedding 向量空间的设计思想。
- 利用 Node.js 的文件流(
fs/promises)完成了离线知识库的清洗、API 节流保护(sleep函数)以及向量数据的本地持久化落盘。 - 纯手写实现了高维空间的余弦相似度(Cosine Similarity)算法,掌握了计算语义差距的数学底层逻辑。
- 利用
readline模块构建了常驻式的交互搜索终端,实现了"用户提问 → \rightarrow → 实时向量化 → \rightarrow → 数学比对排序 → \rightarrow → 输出 Top-K 结果"的完整闭环。
这就是 RAG 的基石。在真实的生产环境或面对百万级海量数据时,暴力循环计算相似度会带来严重的性能瓶颈,这也是我们需要将落盘的 posts-embedding.json 替换为专属向量数据库(如 Milvus、PostgreSQL 向量存储等)的原因。但无论工程外壳如何演变,底层的语义转化与相似度计算的内核永远未变。
掌握了检索部分后,你只需要将这 Top 3 的搜索结果与用户的问题一起拼接进 Prompt,再次投递给通用大模型,大模型就能据此给出完全消除了幻觉、准确可靠的垂直技术解答。这,正是检索增强生成(RAG)的无穷魅力。